基于视觉语言动作的竞速无人机自主导航RaceVLA深度代码解析
摘要: RaceVLA项目首次将视觉语言动作(VLA)模型应用于高速竞速无人机,实现端到端的自主导航。该系统基于OpenVLA模型优化,通过处理第一视角视频和自然语言指令,直接生成4D飞行控制向量(线速度+偏航角速度),显著提升了动态环境下的泛化能力。采用分布式架构设计,服务器端运行VLA模型(4Hz实时推理),无人机端配备定制硬件(T265相机、NUC计算机),实现了连续控制策略,飞行轨迹更接近
论文链接:https://arxiv.org/pdf/2503.02572
项目主页:https://racevla.github.io/
代码仓库:https://github.com/SerValera/RaceVLA
0. 简介
RaceVLA项目标志着具身智能在无人机领域的重大突破。这是首次将视觉语言动作(Vision-Language-Action,VLA)模型成功应用于高速竞速无人机的自主导航系统。与传统的基于规划或轨迹生成的方法不同,RaceVLA实现了从视觉感知到飞行控制的端到端学习,能够理解自然语言指令并在动态环境中执行复杂的飞行任务。
该项目的核心创新在于将斯坦福大学开发的OpenVLA模型成功移植并优化到无人机平台上,通过处理第一视角(FPV)视频流和自然语言指令,直接生成包含三个线性速度和偏航角速度的4D控制向量。这种设计使得无人机能够像人类飞行员一样,基于视觉信息和任务理解做出实时的飞行决策,在不熟悉的环境中展现出卓越的导航能力。更令人瞩目的是,RaceVLA在泛化能力方面的表现尤为突出,在动态环境测试中,该系统在运动泛化和语义泛化方面显著优于OpenVLA,在所有泛化维度上全面超越RT-2模型。同时,通过精心的模型优化和硬件配置,系统实现了4Hz的实时操作频率,完全满足高速竞速无人机的严苛性能要求。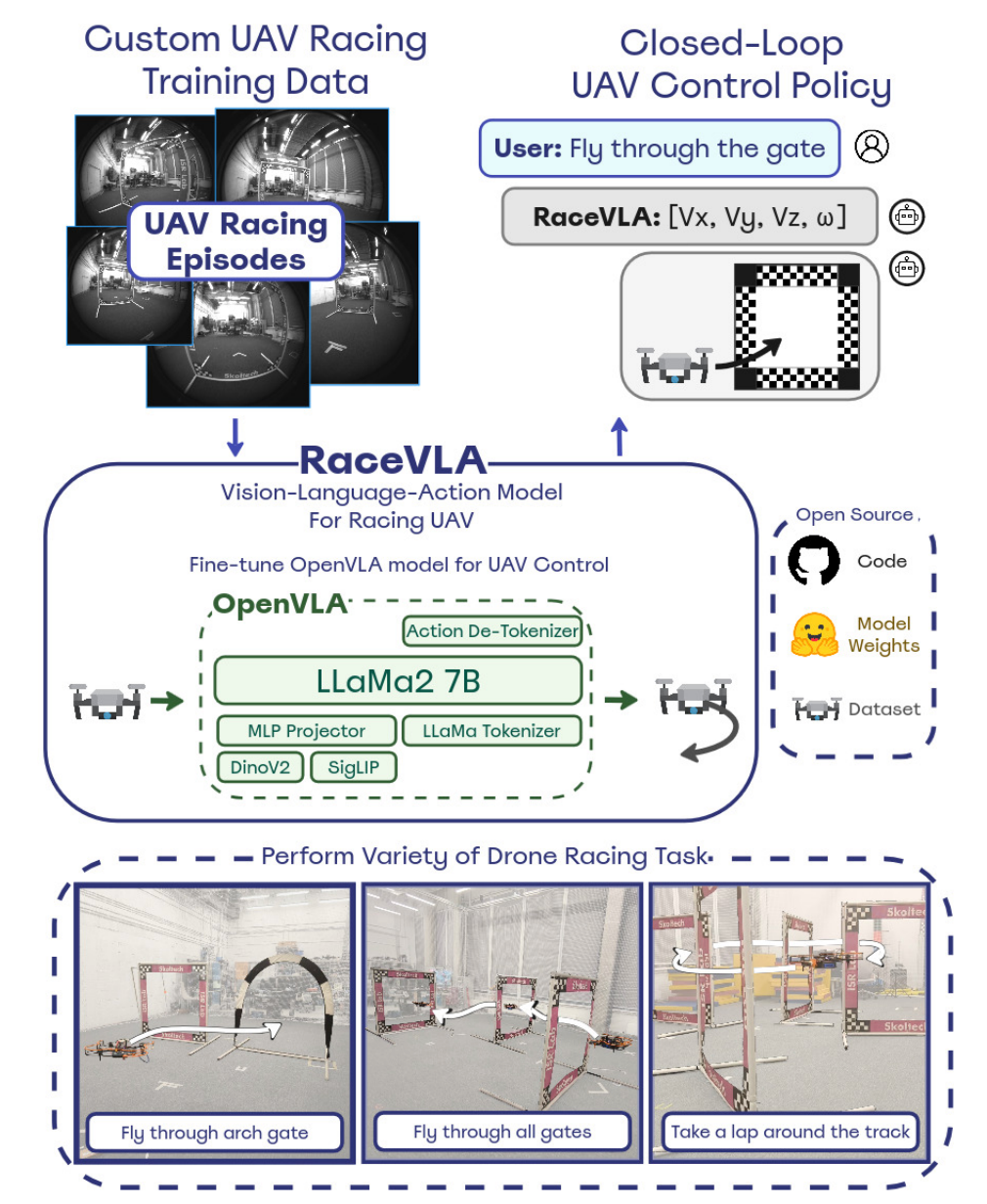
1. 研究背景
认知机器人技术正在快速发展,这类机器人能够通过自然语言在动态环境中执行复杂任务。从人形机器人到四足机器人,从移动机器人到机械臂,各种平台都在VLA模型的赋能下展现出前所未有的智能水平。然而,无人机作为具有高度动态特性的三维移动平台,在VLA模型应用方面仍然是一个相对空白的领域,面临着独特的技术挑战。传统的无人机导航方法主要依赖基于Transformer的模型,这些方法通常专注于路径规划、轨迹生成或技能选择等特定功能模块。虽然在静态或半静态环境中表现尚可,但在面对动态场景时,这些方法往往表现出适应性差、实时性不足的问题,难以泛化到未曾训练过的新任务或新环境中。更重要的是,这些传统方法缺乏对自然语言的理解能力,无法实现人机间的直观交互。
RaceVLA的出现填补了这一技术空白。通过将先进的VLA模型引入无人机领域,该项目不仅解决了传统方法的局限性,更开创了一种全新的无人机控制范式:基于视觉感知和语言理解的端到端飞行控制。这种方法使得无人机能够像具有认知能力的智能体一样,理解任务目标、感知环境变化,并做出相应的飞行决策。
2. 系统架构
RaceVLA系统采用了精心设计的分布式架构,巧妙地平衡了计算性能、实时性和系统稳定性的需求。整个系统由两个核心组件构成:运行VLA模型的高性能服务器端和搭载传感器的无人机端,两者通过高效的网络通信协议实现无缝协作。这种架构设计不仅充分发挥了GPU服务器的强大计算能力,还保证了无人机端控制系统的实时性要求。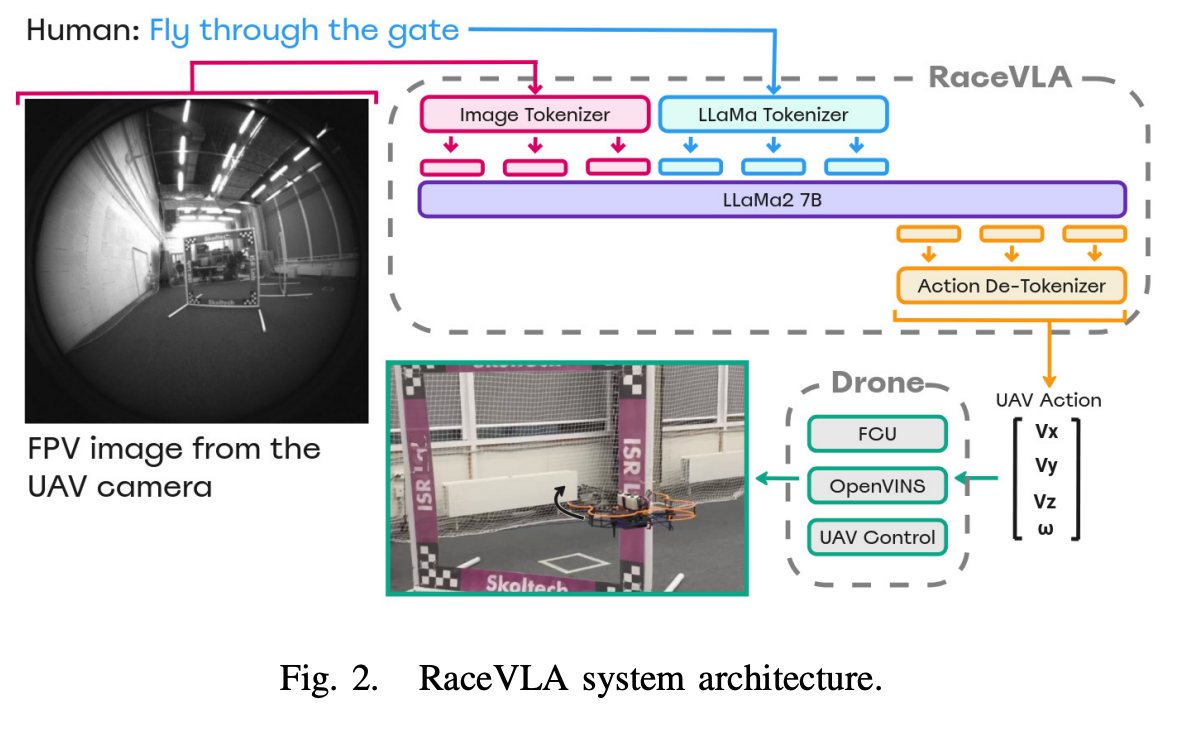
VLA模型作为系统的核心是基于OpenVLA模型定制开发的无人机专用版本。该模型继承了OpenVLA的强大多模态处理能力,同时针对无人机的特殊需求进行了深度优化。模型的输入包括来自无人机FPV相机的实时图像帧和描述飞行任务的自然语言指令,输出则是直接控制无人机飞行的4D动作向量。这里的关键创新在于动作空间的重新设计:原始的OpenVLA模型为机械臂任务设计,输出7维动作向量(包括三个平移、三个旋转和一个夹爪控制),而RaceVLA将其优化为适合无人机的4维控制空间:三个线性速度分量(Vx、Vy、Vz)和偏航角速度(ω)。
# VLA模型的核心推理代码 - server.py
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import torch
# 加载针对无人机竞速任务微调的VLA模型
vla = AutoModelForVision2Seq.from_pretrained(
"/path/to/drone_finetuned_model",
attn_implementation="flash_attention_2", # 优化推理速度
torch_dtype=torch.bfloat16, # 平衡精度与性能
low_cpu_mem_usage=True,
trust_remote_code=True
).to("cuda:0")
@app.route('/predict_action', methods=['POST'])
def predict_action():
"""
VLA模型推理接口:接收图像和语言指令,返回飞行控制动作
输入:FPV图像 + 自然语言任务描述
输出:4D动作向量 [vx, vy, vz, ω_yaw]
"""
# 获取多模态输入
image_file = request.files['image']
instruction = request.form['instruction']
# 图像预处理
image = Image.open(io.BytesIO(image_file.read())).convert("RGB")
# 构建提示词模板 - 关键的prompt engineering
prompt = f"In: What action should the robot take to {instruction}?\nOut:"
# 多模态输入编码
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0", dtype=torch.bfloat16)
# VLA模型推理 - 从视觉+语言到动作的端到端映射
action = vla.predict_action(
**inputs,
unnorm_key="drone_set3", # 数据归一化参数,对应训练数据集
do_sample=False # 确定性推理,保证飞行稳定性
)
# 格式化4D控制输出
formatted_action = {
"velocities": {
"x": action[0], # 前进速度 (m/s)
"y": action[1], # 左右速度 (m/s)
"z": action[2] # 升降速度 (m/s)
},
"delta_yaw": action[5] # 偏航角速度 (rad/s)
}
return jsonify(formatted_action)
无人机端采用了定制的8英寸竞速无人机平台,这个平台经过精心设计以满足高速飞行和实时控制的双重需求。硬件配置包括SpeedyBee F405飞行控制器、Intel RealSense T265相机和Intel NUC机载计算机,每个组件都经过优化以确保系统的整体性能。系统的实时性能通过多层优化实现:VLA模型在服务器端运行,利用NVIDIA RTX 4090 GPU的强大计算能力,通过Flask API与无人机进行通信;机载Intel NUC计算机处理本地的传感器数据融合、定位估计和底层控制任务;而高层的智能决策则交由服务器端的VLA模型完成。
3. 迭代控制策略
RaceVLA系统采用的迭代控制策略是其技术创新的重要体现。不同于传统的基于路径点的导航方法,RaceVLA实现了真正的连续控制。给定一个任务描述后,无人机持续处理FPV图像和语言指令,实时计算并执行下一步的飞行动作。系统不会等待无人机到达指定点后才处理下一帧,而是立即分析新的图像帧并实时调整飞行轨迹。这种连续控制策略的优势在于能够保证飞行的平滑性和连贯性,这对于高速竞速无人机来说至关重要。传统方法中的离散路径点会导致飞行轨迹出现不自然的停顿和急转,而RaceVLA的连续决策能够产生更加自然、类似人类飞行员的飞行轨迹。
3.1 硬件配置详解
无人机硬件平台:
无人机平台采用定制的8英寸竞速无人机,专为高速飞行和实时控制优化。核心硬件包括SpeedyBee F405飞行控制器(基于STM32F405 ARM处理器),运行ArduPilot v4.4.4固件,提供稳定可靠的底层飞行控制。视觉传感器采用Intel RealSense T265相机,不仅提供高质量的FPV图像,其内置的视觉惯性里程计还为系统提供精确的定位信息。机载计算使用Intel NUC(Ubuntu 22.04),作为ROS 1 (Noetic)中间件的载体,处理本地数据融合、通信协调和安全监控任务。
服务器硬件配置:
服务器端采用高性能配置以满足VLA模型的计算需求。核心是NVIDIA RTX 4090 GPU,专门用于VLA模型推理,配合Flask API服务器框架实现高效的网络通信。系统的推理性能经过精心优化,单帧处理时间控制在0.25秒以内,整体运行频率稳定在4Hz,完全满足竞速无人机的实时控制要求。
┌─────────────────┐ 图像+指令 ┌─────────────────┐
│ 无人机平台 │ ──────────────► │ 服务器端 │
│ │ │ │
│ • T265相机 │ │ • VLA模型 │
│ • Intel NUC │ │ • Flask API │
│ • 飞控系统 │ │ • NVIDIA GPU │
│ │ ◄────────────── │ │
└─────────────────┘ 控制指令 └─────────────────┘
3.2 硬件配置详解
无人机硬件平台:
- 机架:定制8英寸竞速无人机机架
- 飞控:SpeedyBee F405飞行控制器(基于STM32F405 ARM)
- 固件:ArduPilot v4.4.4
- 视觉传感器:Intel RealSense T265相机
- 机载计算:Intel NUC(Ubuntu 22.04)
- 中间件:ROS 1 (Noetic)
服务器硬件配置:
- GPU:NVIDIA RTX 4090(用于VLA模型推理)
- 通信:Flask API服务器
- 推理性能:单帧处理时间0.25秒,运行频率4Hz
3.3 项目代码结构解析
整个RaceVLA项目的代码结构清晰明了,体现了良好的软件工程实践。项目分为服务器端和无人机端两大模块,每个模块都有明确的职责分工和接口定义。
项目目录结构
RaceVLA/
├── server/ # 服务器端代码
│ └── server.py # VLA模型服务器主程序
├── drone/ # 无人机端代码
│ ├── readme.md # 无人机端使用说明
│ └── vla_ws/ # ROS工作空间
│ └── src/
│ └── vlm_drone/ # 核心ROS包
│ ├── scripts/ # 可执行脚本
│ │ ├── drone.py # 主控制脚本
│ │ └── vla_start.sh # 系统启动脚本
│ └── launch/ # ROS启动文件
│ ├── apm.launch # ArduPilot配置
│ └── node.launch # 节点启动配置
└── README.md # 项目说明文档
4. 数据集构建与训练流程
4.1 多样化训练数据的精心设计

RaceVLA项目的成功很大程度上得益于精心构建的训练数据集。该数据集包含200个飞行片段和约20,000张高质量图像,覆盖了多种竞速场景,包括通过拱门、方形门、圆形赛道等各种复杂环境。这种多样性确保了模型能够学习到丰富的飞行策略和环境适应能力。
数据收集过程采用了先进的多传感器融合技术。Vicon运动捕捉系统以高精度记录无人机的三维运动轨迹和速度信息,而RealSense T265相机以30Hz的频率同步捕捉视觉信息。每个数据样本都包含完整的状态信息:三维位置坐标、速度分量、姿态角度变化以及对应的视觉帧,同时附有描述任务目标的自然语言指令。这种数据组织方式使得VLA模型能够学习视觉感知、语言理解和动作执行之间的复杂映射关系。
4.2 高效的LoRA微调策略
RaceVLA采用了先进的LoRA(Low-Rank Adaptation)技术对OpenVLA-7B模型进行微调,这种方法既保持了预训练模型的强大能力,又能高效地适应无人机特定任务。训练过程在单个NVIDIA A100 GPU上进行,通过精心设计的超参数配置实现了快速而稳定的收敛。
训练过程中监控多个关键指标,包括训练损失、动作预测准确性和L1损失等,确保模型能够准确学习从视觉输入和语言指令到飞行动作的映射关系。LoRA技术的使用不仅提高了训练效率,还降低了对计算资源的需求,使得这种先进的VLA技术能够在相对有限的硬件条件下实现。
5. 服务器端VLA模型实现
5.1 VLA模型服务器(server.py)详细解析
服务器端是整个RaceVLA系统的"大脑",负责运行微调后的OpenVLA模型,处理来自无人机的图像和指令,并返回飞行控制动作。
from flask import Flask, request, jsonify
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import torch
import numpy as np
import io
import time
app = Flask(__name__)
# VLA模型加载和初始化
processor = AutoProcessor.from_pretrained(
"/home/isr-lab-4/openvla/models/drone3_cycle/runs/openvla-7b+drone_set3+b16+lr-0.0005+lora-r32+dropout-0.0/",
# "openvla/openvla-7b", # 原始OpenVLA模型路径(注释掉)
trust_remote_code=True
)
# 加载微调后的VLA模型
vla = AutoModelForVision2Seq.from_pretrained(
"/home/isr-lab-4/openvla/models/drone3_cycle/finetuned_model/openvla-7b+drone_set3+b16+lr-0.0005+lora-r32+dropout-0.0/",
# "openvla/openvla-7b", # 原始模型路径(注释掉)
attn_implementation="flash_attention_2", # 使用Flash Attention 2优化推理速度
torch_dtype=torch.bfloat16, # 使用bfloat16精度平衡性能和精度
low_cpu_mem_usage=True, # 优化CPU内存使用
trust_remote_code=True
).to("cuda:0") # 部署到GPU
关键设计要点:
-
模型优化策略:
- 使用Flash Attention 2加速注意力计算
- bfloat16精度减少内存占用
- GPU加速推理
-
微调模型路径:
- 使用LoRA(Low-Rank Adaptation)技术微调
- 学习率0.0005,rank=32,dropout=0.0
- 专门针对无人机竞速任务训练
5.2 API接口实现
@app.route('/predict_action', methods=['POST'])
def predict_action():
"""
VLA模型推理API接口
接收图像和自然语言指令,返回4D控制动作
"""
try:
# 1. 获取输入数据
image_file = request.files['image'] # 从无人机获取的FPV图像
instruction = request.form['instruction'] # 自然语言任务指令
# 2. 图像预处理
image = Image.open(io.BytesIO(image_file.read())).convert("RGB")
# image.show() # 调试时可以显示图像
# 3. 构建提示词模板
prompt = f"In: What action should the robot take to {instruction}?\nOut:"
# 4. 输入数据预处理
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0", dtype=torch.bfloat16)
# 5. 模型推理计时
time0 = time.perf_counter()
action = vla.predict_action(
**inputs,
unnorm_key="drone_set3", # 数据归一化键,需根据训练数据集选择
do_sample=False # 确定性推理,不使用随机采样
)
time1 = time.perf_counter()
print(f"Prediction time = {time1 - time0} sec")
# 6. 动作后处理
if isinstance(action, torch.Tensor):
action = action.tolist()
elif isinstance(action, np.ndarray):
action = action.tolist()
# 7. 格式化输出(4D动作向量)
formatted_action = {
"velocities": {
"x": action[0], # X轴线速度 (m/s)
"y": action[1], # Y轴线速度 (m/s)
"z": action[2] # Z轴线速度 (m/s)
},
"delta_yaw": action[5], # 偏航角速度 (rad/s)
}
print(formatted_action)
return jsonify(formatted_action)
except Exception as e:
print(f"Error: {str(e)}")
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000) # 监听所有接口,端口5000
5.3 VLA模型工作原理深度解析
…详情请参照古月居
```8. 完整使用指南
8.1 环境准备
硬件要求:
- 服务器端:NVIDIA RTX 4090或同等性能GPU
- 无人机:8英寸竞速无人机 + SpeedyBee F405飞控
- 传感器:Intel RealSense T265相机
- 机载计算:Intel NUC (Ubuntu 22.04)
软件环境安装:
# 1. 安装ROS Noetic
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
sudo apt install curl
curl -s https://raw.githubusercontent.com/ros/rosdistro/master/ros.asc | sudo apt-key add -
sudo apt update
sudo apt install ros-noetic-desktop-full
# 2. 安装MAVROS
sudo apt install ros-noetic-mavros ros-noetic-mavros-extras
wget https://raw.githubusercontent.com/mavlink/mavros/master/mavros/scripts/install_geographiclib_datasets.sh
sudo bash ./install_geographiclib_datasets.sh
# 3. 安装Intel RealSense SDK
sudo apt-key adv --keyserver keys.gnupg.net --recv-key F6E65AC044F831AC80A06380C8B3A55A6F3EFCDE
sudo add-apt-repository "deb https://librealsense.intel.com/Debian/apt-repo $(lsb_release -cs) main"
sudo apt update
sudo apt install librealsense2-dkms librealsense2-utils librealsense2-dev
# 4. 安装OpenVINS
cd ~/catkin_ws/src
git clone https://github.com/rpng/open_vins/
cd ~/catkin_ws && catkin_make
# 5. 安装Python依赖
pip install transformers torch torchvision flask pillow numpy opencv-python requests
8.2 系统启动流程
服务器端启动:
# 启动VLA模型服务器
cd RaceVLA/server
python server.py
无人机端启动:
# 使用一键启动脚本
cd RaceVLA/drone/vla_ws/src/vlm_drone/scripts
chmod +x vla_start.sh
./vla_start.sh
8.3 故障排除
常见问题及解决方案:
-
VLA服务器无响应
# 检查GPU状态 nvidia-smi # 重启服务器 pkill -f server.py python server.py -
MAVROS连接失败
# 检查串口权限 sudo chmod 666 /dev/ttyACM0 # 重启MAVROS rosnode kill /mavros roslaunch racing_vla apm.launch -
图像传输延迟
# 检查网络延迟 ping 192.168.50.2 # 调整图像质量 # 在drone.py中修改JPEG压缩参数
9. 总结与展望
RaceVLA项目不仅是技术创新的成功案例,更是人工智能向着真正智能化发展的重要里程碑。通过将视觉感知、语言理解和动作执行有机结合,这项技术展现了未来智能系统的发展方向:更加自然的人机交互、更强的环境适应能力、更高的任务执行效率。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)