ICLR 2026 VLA 研究现状深度剖析
VLA 的定义在社区内出人意料地存在争议,尚未形成明确共识。近期一篇综述论文给出了一个广义定义:“视觉-语言-动作 (VLA) 模型是一个系统,它将视觉观察和自然语言指令作为必要输入,并可能整合其他感官模态。它通过直接生成控制指令来产生机器人动作。是否在某种类型的互联网规模视觉-语言数据上进行过预训练。VLA 是一个使用预训练骨干网络的模型,该骨干网络在互联网规模的视觉-语言数据上训练过,并随后被

作者:Moritz Reuss • 2025年10月
摘要:本文旨在概述和分析 ICLR 2026 中视觉-语言-动作 (VLA) 模型的研究趋势。ICLR 的开放提交流程为我们提供了一个难得的、实时的窗口,让我们一窥全球机器学习社区的最新动态。本文将深入探讨 VLA 领域的几个核心问题:什么是 VLA(以及为何这个定义至关重要)?当前的研究热点有哪些(例如离散扩散、具身推理、新型动作分词器)?如何正确解读 VLA 研究中的基准测试结果?以及,仿真排行榜背后那道难以察觉的前沿差距。
每年秋天,ICLR 都会在截稿后几周内公开发布所有匿名提交的论文。这提供了一个独特的实时快照,让我们能够看到世界各地的最新研究成果,而不像其他顶级会议那样通常有长达六个月的延迟。基于我个人的研究兴趣,我深入分析了今年提交的视觉-语言-动作 (VLA) 模型相关论文,并希望在此分享我的见解。
在这篇博客中,我将:
- 简要解释 VLA 的定义。
- 分享我对当前 VLA 研究趋势与挑战的发现,并重点介绍一些提交给 ICLR 2026 的有趣论文。
- 提供一份解读 VLA 基准测试结果的实用指南,帮助研究者和从业者更好地理解现状。
- 探讨前沿实验室与学术研究机构在 VLA 领域存在的“隐形差距”——这种差距仅仅通过阅读论文是无法感知的。
以下是我从今年的提交中总结出的总体研究趋势,并为每个类别挑选了一些我认为值得关注的论文。请注意,这仅代表我个人的选择和观点,可能遗漏了其他同样出色的工作。如果您有其他值得推荐的论文,欢迎随时告知。
目录
- 什么是视觉-语言-动作 (VLA) 模型?
- VLA 研究的爆炸式增长
- 从业者必读:如何解读 VLA 基准测试结果
- ICLR 2026 VLA 研究趋势
- 离散扩散 VLA (Discrete Diffusion VLAs)
- 推理型 VLA 与具身思维链 (ECoT)
- 新型离散动作分词器 (New Discrete Tokenizers)
- 高效 VLA (Efficient VLAs)
- 强化学习在 VLA 中的应用 (RL for VLAs)
- VLA 与视频预测 (VLA + Video Prediction)
- VLA 的评估与基准 (Evaluation and Benchmarking)
- 跨动作空间学习 (Cross-Action-Space Learning)
- 其他值得关注的论文
- 前沿 VLA 与研究性 VLA 之间的隐形差距
- 总结与展望
1. 什么是视觉-语言-动作 (VLA) 模型?
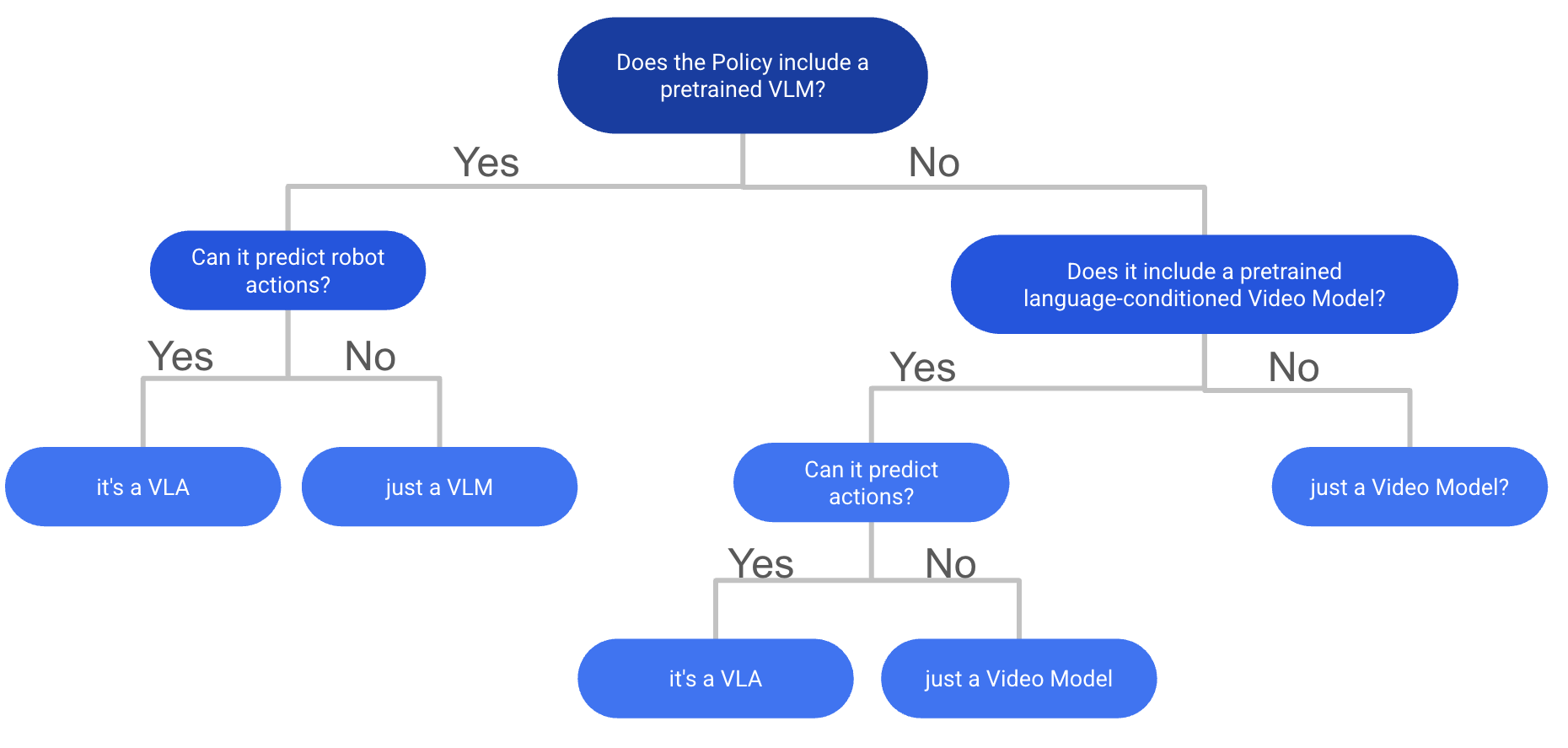
VLA 的定义在社区内出人意料地存在争议,尚未形成明确共识。近期一篇综述论文给出了一个广义定义:“视觉-语言-动作 (VLA) 模型是一个系统,它将视觉观察和自然语言指令作为必要输入,并可能整合其他感官模态。它通过直接生成控制指令来产生机器人动作。”
虽然这是一个有效的定义,但我个人认为,它忽略了 VLA 与其他多模态策略最关键的区别:是否在某种类型的互联网规模视觉-语言数据上进行过预训练。
我的个人定义是:VLA 是一个使用预训练骨干网络的模型,该骨干网络在互联网规模的视觉-语言数据上训练过,并随后被用于生成控制指令。 这些控制指令可以是机器人关节角度、末端执行器位姿、汽车的转向角、潜在动作,或是虚拟智能体的鼠标键盘命令。这一定义也包含了使用预训练视频生成模型作为骨干的“视频-动作策略”。如果没有经过互联网规模的预训练,我倾向于将它们称为“多模态策略”而非 VLA。定义变得模糊的地方在于,当一个模型同时使用了预训练的文本编码器(如 CLIP-text)和单独预训练的视觉编码器(如 DINOv2)时,我个人更倾向于将其归为多模态策略,因为它缺少了联合的视觉-语言预训练。
这一定义之所以重要,是因为理论上,互联网规模的预训练赋予了 VLA 核心护城河:更强的语言指令遵循能力和跨任务、跨环境的泛化能力。至少,这是它的承诺。但现实是,目前大多数 VLA 在零样本泛化和复杂任务上仍然表现不佳,更像是“没那么笨的多模态策略”,而非真正通用的“机器人大脑”。但其潜力巨大,为研究者们留下了许多激动人心的开放性问题。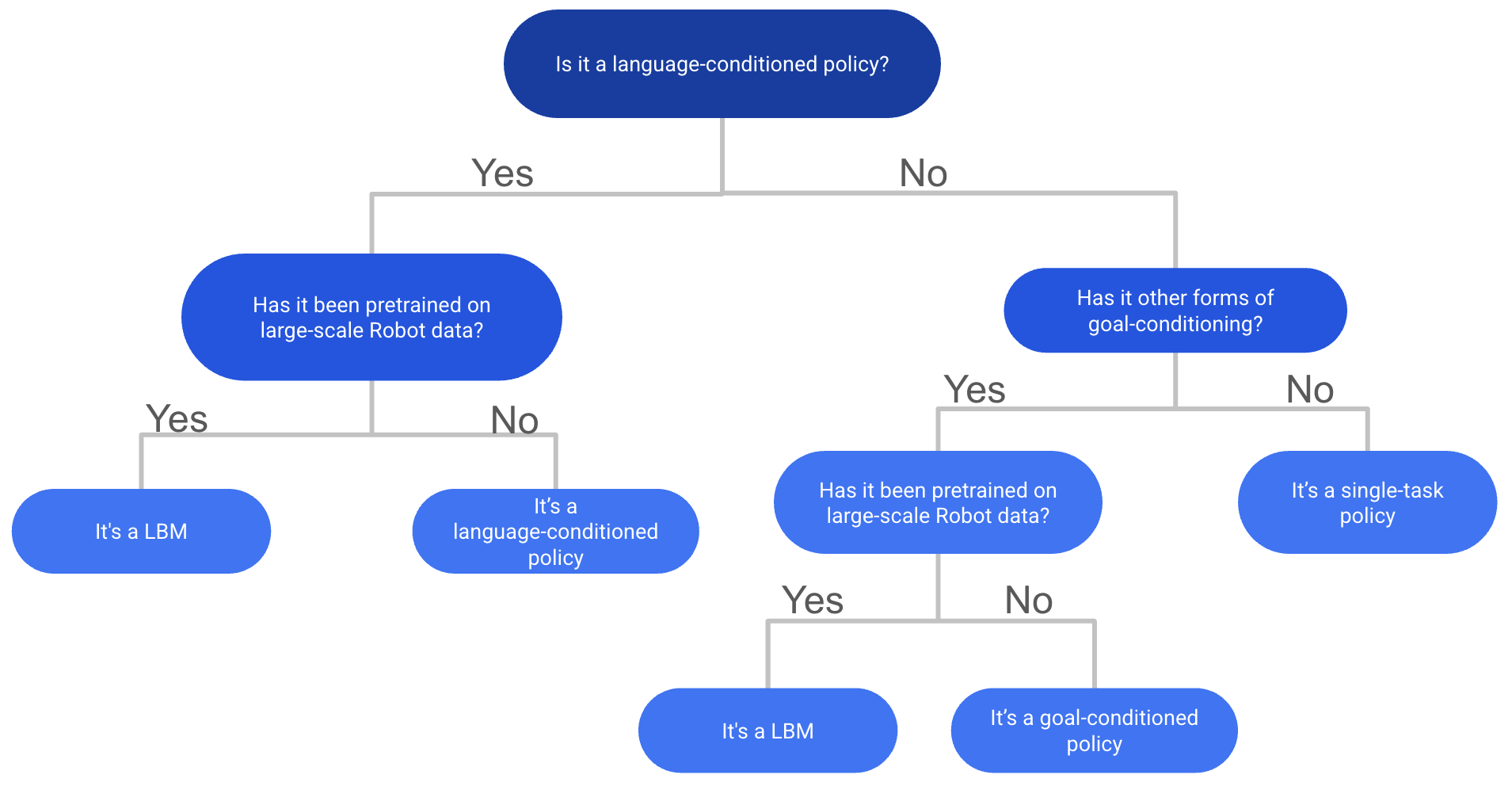
与 VLA 相关且互补的一个概念是大型行为模型 (Large Behavior Models, LBMs)。这个术语由丰田研究院 (TRI) 提出,指代在大型、多任务的机器人演示数据上训练的策略,但它们不要求必须有互联网规模的视觉-语言预训练或 VLM 背景。可以这样理解:所有在大型机器人数据上训练的 VLA 也是 LBM,但并非所有 LBM 都是 VLA。这两个术语共同覆盖了所有类型的机器人基础模型。
2. VLA 研究的爆炸式增长
在过去两年里,VLA 领域经历了惊人的增长。根据 OpenReview 上的关键词搜索统计,ICLR 会议的提交数量生动地展示了这一趋势:
- ICLR 2024: 仅 1 篇被拒论文包含关键词 “Vision-Language-Action”。
- ICLR 2025: 6 篇被接收,3 篇被拒。
- ICLR 2026: 164 篇提交论文包含该关键词——短短一年内增长了 18 倍!
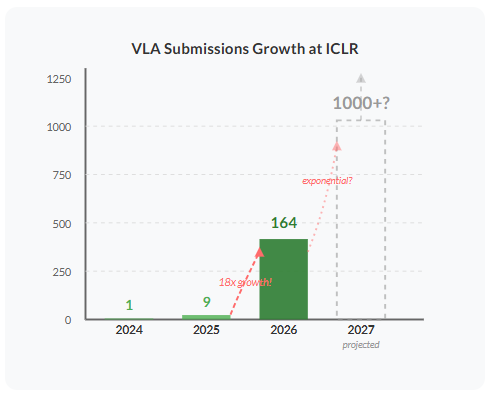
这种指数级的增长表明,VLA 模型正迅速受到欢迎,吸引了大量来自计算机视觉等其他领域的学者进入机器人学习这个激动人心的领域。面对这一趋势,我既感到兴奋,又对可能在 ICLR 2027 审阅超过 2100 篇 VLA 论文的前景感到一丝“恐惧”。
3. 从业者必读:如何解读 VLA 基准测试结果

我想为从业者提供一个快速指南,教你如何解读 VLA 论文中的基准测试结果。当你读到一篇新的 VLA 论文时,如何判断其声称的结果是否真的出色?
首先要明确,基于当前主流的仿真基准,我们很难断言哪个模型是“最佳”的,因为大多数论文都只在 LIBERO、SIMPLER 或 CALVIN 这几个常见环境上进行相互比较。
- LIBERO: 这个基准基本已被攻克。展示 99% 与 98% 的成功率意义不大。有趣的是,LIBERO 最初是为终身学习设计的,但 99% 的论文只是在完整数据集上训练,并未进行任何持续学习。在这个基准上,不同模型(如各种离散扩散 VLA)的性能都集中在 95-98% 之间,几乎触及天花板,因此很难判断优劣。
- 经验法则:
- 在 LIBERO Spatial, Goal, Object 版本上,>95% 是预期水平。
- 在 Long 版本上,90-95% 是必需的,低于 90% 通常只适用于特殊设定(如仅静态相机或少样本学习)。
- 经验法则:
- CALVIN: 这个基准也几乎被当前 SOTA 模型(如 FLOWER)饱和。
- 经验法则: 主要关注 ABC 设定(测试泛化能力),得分高于 4.5 属于 SOTA 水平。
- SIMPLER: 结果难以跨论文比较,因为不同设置下成功率从 40% 到 99% 不等。在 Google Robot 版本上,当前 SOTA 模型能达到 70%-80% 的成功率。
- 真实世界结果: 任何真实世界的实验结果都非常重要。由于参数量巨大的 VLA 模型(如 7B+)在仿真环境中很容易过拟合,因此纯仿真的结果可信度有限。
4. ICLR 2026 VLA 研究趋势
在浏览了大部分 ICLR 2026 VLA 相关的提交后,我总结出以下几个关键趋势。
趋势 1:离散扩散 VLA (Discrete Diffusion VLAs)
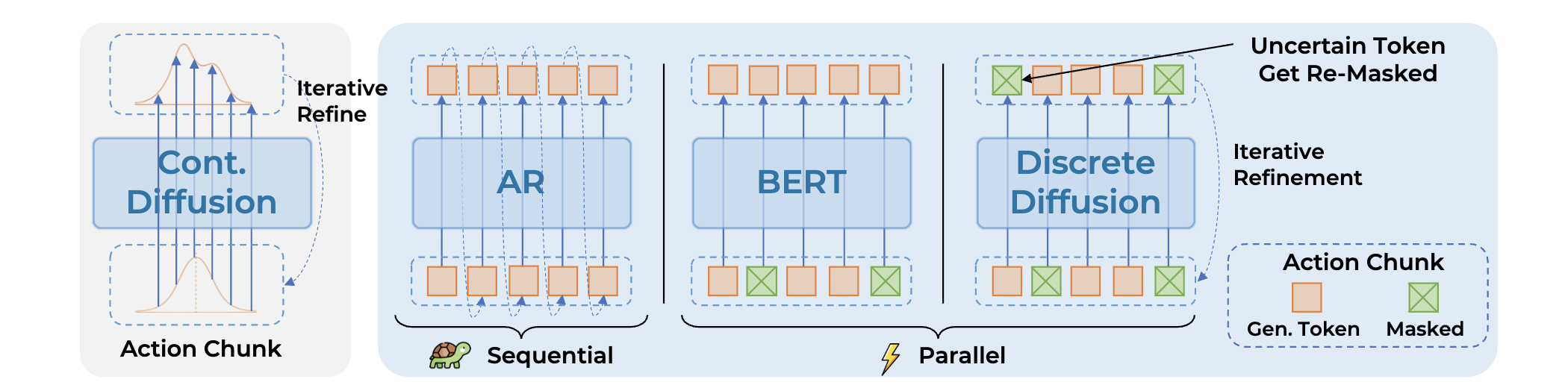
鉴于离散扩散模型在文本 (MDLM) 和 VLM (LLaDA-V) 等领域的成功,这一趋势进入 VLA 研究也就不足为奇了。离散扩散的优势在于并行生成,可以一次性生成长序列的离散动作 token,解决了自回归模型需要逐个 token 生成的低效问题。
代表性论文:
DISCRETE DIFFUSION VLA: 将离散扩散应用于动作解码,实现基于动作块的快速生成。
论文链接:https://arxiv.org/abs/2508.20072dVLA: 结合离散扩散和具身思维链 (ECoT),并行生成未来的图像帧、文本和动作。
论文链接:https://arxiv.org/abs/2509.25681DIVA: 另一个离散扩散 VLA,侧重于推理过程中如何替换 token 以提升性能。
论文链接:https://openreview.net/forum?id=mNya9d1DA2UNIFIED DIFFUSION VLA: 通过联合离散去噪扩散过程,共同生成未来帧和离散动作。
论文链接:https://arxiv.org/abs/2511.01718
趋势 2:推理型 VLA 与具身思维链 (ECoT)
推理能力被认为是提升 VLA 泛化性和复杂任务表现的关键。受 LLM 中思维链 (CoT) 的启发,研究者们开始将类似思想应用于 VLA,即具身思维链 (Embodied Chain-of-Thought, ECoT)。核心思想是在生成动作前,先产生中间的视觉和文本推理步骤(如子任务、物体边界框),帮助 VLA 更好地理解任务。但其主要瓶颈是自回归生成速度慢,且依赖有限的标注数据。
代表性论文:
ACTIONS AS LANGUAGE: 将机器人动作重新标注为文本描述(如“向左移动”),在微调 VLM 时避免灾难性遗忘,同时保留其推理能力。
论文链接:https://arxiv.org/abs/2509.22195VISION-LANGUAGE-ACTION INSTRUCTION TUNING: 提出一个两阶段指令微调流程,解耦多模态推理和动作生成,以保留 VLM 的原有能力。
论文链接:https://arxiv.org/abs/2507.17520EMBODIED-R1: 训练一个“指向型”VLM,通过生成指向关键物体或位置的坐标点来进行具身推理。
论文链接:https://arxiv.org/abs/2508.13998HYBRID TRAINING FOR VISION-LANGUAGE-ACTION MODELS: 将 ECoT 预训练分解为“思考、行动、遵循”等子任务,在保持性能的同时提升推理速度。
论文链接:https://arxiv.org/abs/2510.00600
趋势 3:新型离散动作分词器 (New Tokenizers)
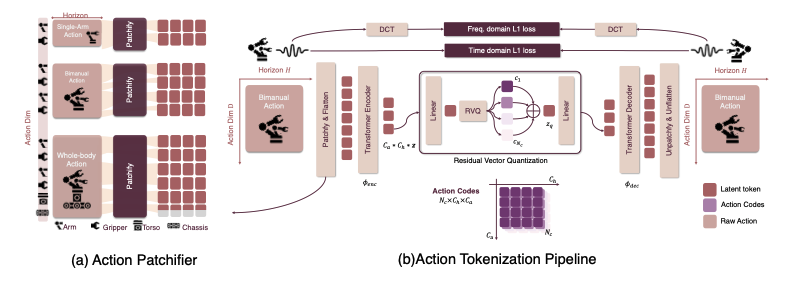
VLM 处理离散 token 效率最高,而机器人控制需要高频连续值。如何将连续的动作序列高效地转换为离散的 token 是一个核心问题。理想的动作分词器应具备高压缩率、生成平滑的动作轨迹,并能无缝集成到现有 VLM 架构中。今年的研究在 Residual Vector Quantization (RVQ)、B-Spline 参数化等方面取得了进展。
代表性论文:
FASTER: 提出一种名为 FASTer 的新型分词器,结合 RVQ、频域损失和时域损失,实现了比早期方法更高的压缩率。
论文链接:https://arxiv.org/abs/2501.09747OMNISAT: 借鉴 BEAST 论文中的 B-Spline 思想,对动作块进行紧凑表示,并在多个基准上优于 FAST 和 BEAST。
论文链接:https://arxiv.org/abs/2510.09667
趋势 4:高效 VLA (Efficient VLAs)
如何在有限的计算资源下训练和运行 VLA 是一个非常实际的问题。今年的研究主要分为两类:一是通过设计更小的模型或更高效的分词器来降低训练成本;二是通过量化、蒸馏等技术优化推理效率。
代表性论文:
HYPERVLA: 使用超网络 (Hypernetworks) 根据任务指令和初始图像生成一个小型、任务特定的策略,从而在执行时只需激活这个紧凑策略,大幅降低推理成本。
论文链接:https://arxiv.org/abs/2510.04898AUTOQVLA: 对 OpenVLA 进行量化分析,提出一种改进的量化方法,能在保持性能的同时将显存需求降低至 30%。
论文链接:https://openreview.net/forum?id=TpL2nXanru
趋势 5:强化学习在 VLA 中的应用 (RL for VLAs)
如何将 VLA 在真实世界的成功率从 70-80% 提升到 99%?强化学习 (RL) 微调被寄予厚望。今年的研究探索了多种新方法。
代表性论文:
SELF-IMPROVING VISION-LANGUAGE-ACTION MODELS...: 采用残差 RL 方法,用一个小型残差策略收集高质量的恢复行为数据,再通过监督微调 (SFT) 改进主 VLA。
论文链接:https://arxiv.org/abs/2511.00091PROGRESSIVE STAGE-AWARE REINFORCEMENT...: 将任务分解为语义阶段(如“伸出→抓取→运输→放置”),并对每个阶段进行奖励,通过离线偏好学习和在线 RL 进行优化。
论文链接:https://openreview.net/forum?id=qBcgyxDeMM
趋势 6:VLA 与视频预测 (VLA + Video Prediction)
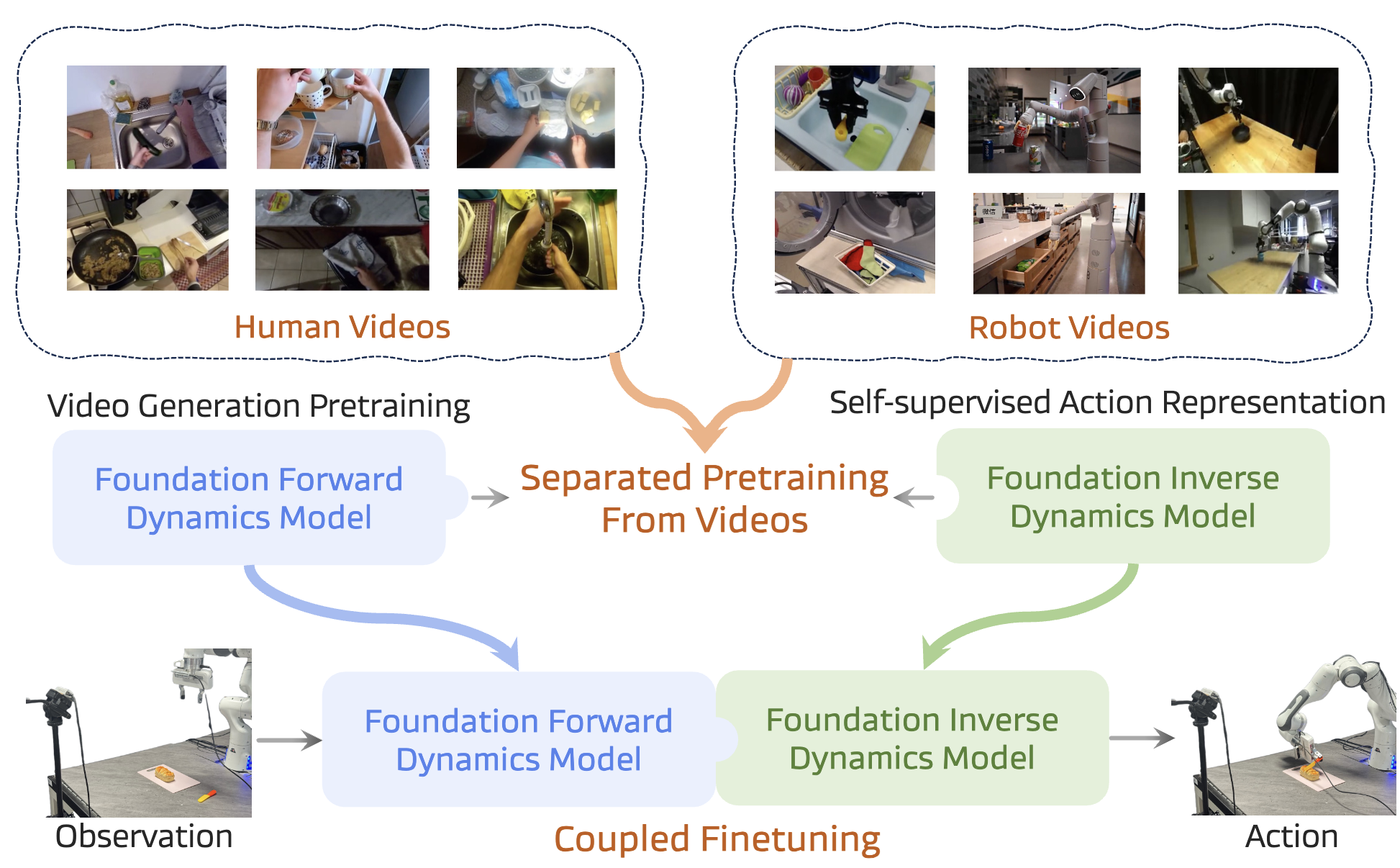
视频生成模型学习了丰富的物理动态表征,可为机器人控制提供有价值的先验知识。这类研究通常有两种路径:一是从 VLM 出发,增加对未来帧的预测任务;二是从视频基础模型出发,修改其架构以生成动作。这类方法的主要挑战是计算成本高昂且推理速度慢。
代表性论文:
DISENTANGLED ROBOT LEARNING...: 通过分别预训练前向和逆向动力学模型,再将它们结合进行微调。
论文链接:https://openreview.net/forum?id=DdrsHWobR1UNIFIED VISION–LANGUAGE–ACTION MODEL: 将视觉、语言和动作统一建模为单一的离散 token 流,用一个 8.5B 的自回归模型进行训练。
论文链接:https://arxiv.org/abs/2506.19850COSMOS POLICY: 微调 NVIDIA 的 Cosmos 视频基础模型用于动作预测,在潜空间中注入动作块或价值函数等信息。
论文链接:https://openreview.net/forum?id=wPEIStHxYH
趋势 7:VLA 的评估与基准 (Evaluation and Benchmarking)

现有基准的饱和问题亟待解决。幸运的是,一些新工作正试图通过引入新基准或创新的评估方法来弥补这一不足。
代表性论文:
ROBOTARENA ∞: 提出一个 real-to-sim 的基准框架,可自动构建环境并进行评估,类似于 RoboArena 的评分系统。
论文链接:https://www.arxiv.org/abs/2510.23571ROBOCASA365: 扩展了 RoboCasa 仿真环境,包含 365 个任务、2000+ 厨房场景和超过 2000 小时的遥操作数据。
论文链接:https://openreview.net/forum?id=tQJYKwc3n4WORLDGYM: 提出使用一个以动作为条件的视频生成模型(世界模型)作为评估环境,策略在生成的虚拟世界中执行任务,并由一个 VLM 提供奖励。
论文链接:https://arxiv.org/abs/2506.00613
趋势 8:跨动作空间学习 (Cross-Action-Space Learning)
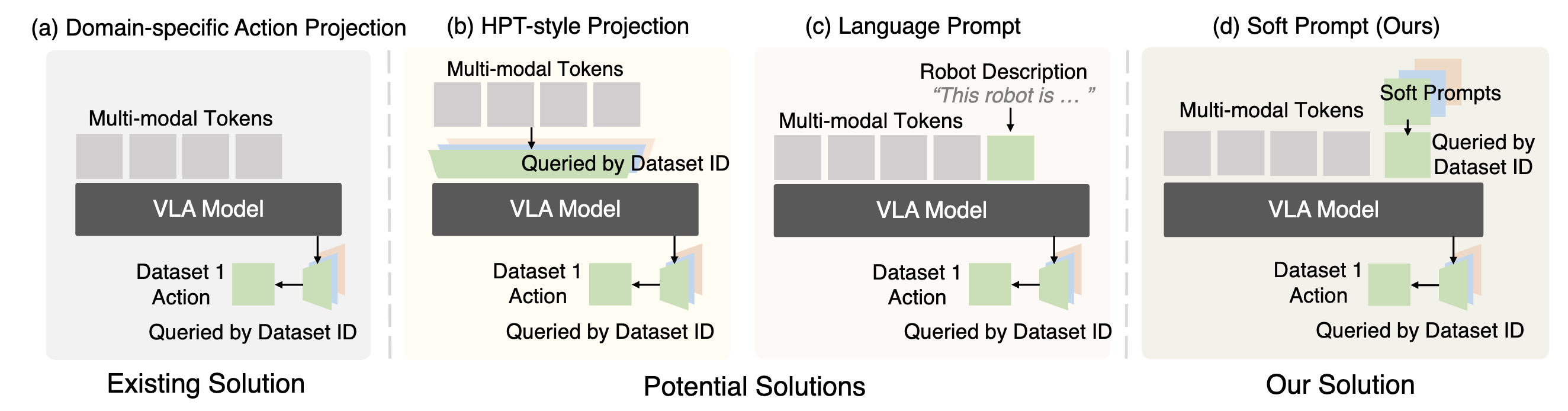
如何让 VLA 在不同机器人(具有不同动作空间)的数据上进行预训练并实现正向迁移,是一个极具挑战性的前沿领域。值得注意的是,DeepMind 最近发布的 Gemini Robotics 1.5 展示了一种名为“运动迁移 (motion transfer)”的技术,似乎在该方向上取得了成功。
代表性论文:
X-VLA: 使用软提示 (soft-prompting) token 来处理跨不同数据集的动作空间,实现了出色的跨实体学习效果。
论文链接:https://arxiv.org/abs/2510.10274XR-1: 提出“统一视觉-运动编码 (UVMC)”,用一个共享码本的 VQ-VAE 联合编码视觉动态和机器人运动,从而更好地结合人类和机器人的演示数据。
论文链接:https://openreview.net/forum?id=XJclc9EabdHIMOE-VLA: 采用层级式混合专家 (Hierarchical MoE) 架构,以更好地适应新机器人的动作空间。
论文链接:https://openreview.net/forum?id=TX3oGD99CJ
9. 其他值得关注的论文
还有一些有趣的论文,它们探索了 VLA 设计的各个方面,例如记忆模块和策略组合。
HAMLET: 提出一个即插即用的记忆模块,通过“时刻 token”捕捉历史信息,使策略具备时间感知能力。
论文链接:https://arxiv.org/abs/2510.00695COMPOSE YOUR POLICIES!: 提出一种在测试时组合多个基于扩散或流模型的 VLA 策略的方法,通过凸优化来提升性能。
论文链接:https://arxiv.org/abs/2510.01068VLM4VLA: 系统性地比较了多种 VLM作为 VLA 骨干的性能,发现 VLM 在标准基准上的表现与下游 VLA 任务的性能没有相关性。
论文链接:https://openreview.net/forum?id=tc2UsBeODW
5. 前沿 VLA 与研究性 VLA 之间的隐形差距
从论文上看,开源 VLA 在仿真基准上甚至超越了像 RT-2 这样的前沿模型,差距似乎很小。但实际上,存在一道巨大的鸿沟,而这道鸿沟恰恰出现在当前论文很少评估的地方:预训练后的零样本、开放世界泛化能力。例如,不久前在 CoRL 大会上展示的 Gemini-Robotics VLA 可以在任意物体和多样化的语言指令下完成各种新任务。我自己的 VLA 模型 FLOWER 虽然在 CALVIN 基准上是 SOTA,但远未达到那种零样本鲁棒性。
这道差距为何存在?
-
基准饱和掩盖了真实进展: 当分数都接近天花板时,“提升0.5%”并不能证明模型有实质性进步。
-
高质量数据的鸿沟: 当前开源数据的多样性和规模有限,限制了通用模型的训练。更重要的是,我们对如何定义和获取“高质量”演示数据还缺乏深刻理解。
-
评估范围狭窄: 大多数论文只报告仿真或小规模微调的结果,极少测试自由形式的零样本语言遵循和处理新物体的能力。
-
运营限制: 学术研究团队缺乏大规模运行真实机器人试验所需的人力、时间和资金。
-
同行评审激励错位: 主流会议的审稿人倾向于看到与已有模型在标准仿真环境中的直接比较,这虽然有助于论文发表,但与开放世界性能的相关性很弱。
如何缩小这一差距? -
使用公平的公开零样本基准: 推广像 RoboArena 这样的平台,由独立方来测试模型的预训练后泛化能力。
-
更好的预训练配方: 我们需要更多像 X-VLA 这样详细剖析预训练设计选择及其影响的论文,分享成功的经验和失败的教训。
6. 总结与展望
总的来说,我对 VLA 研究的现状和进展感到非常乐观。上述趋势表明,从架构设计到训练策略,社区的贡献热情高涨。然而,除了零样本性能差距外,当前研究还有两个被忽视的问题:
- 数据质量: 尽管数据至关重要,但今年的提交中很少有关注数据收集和管理的。如何量化模仿学习中的数据质量,仍然是 VLA 领域最关键的未解难题之一。
- 上下文学习 (In-context Learning): 鉴于其在 LLM 和 VLM 中的巨大成功,我原以为会看到更多 VLA 在这方面的探索,但实际上寥寥无几。如何为 VLA 设计有效的上下文学习机制,以处理复杂的物理任务,仍然是一个开放问题。
尽管存在这些挑战,我仍然相信该领域将继续快速发展。随着我们逐步解决数据质量和上下文学习等根本性问题,我们将离能够真正在复杂、非结构化环境中泛化的 VLA 更近一步。
引用本文
如果您想引用本文,请使用以下 BibTeX 格式:
@misc{reuss2025state-vla-iclr26,
title = {State of VLA Research at ICLR 2026},
author = {Reuss, Moritz},
year = {2025},
month = {October},
howpublished = {\url{https://mbreuss.github.io/blog_post_iclr_26_vla.html}},
note = {Blog post},
}

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)