CVPR2025自动驾驶VLM论文笔记(一):OmniDrive,SOLVE
OmniDrive,SOLVE详解
·
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning [CVPR2025]
- Motivation
- 3D空间理解:缺乏一个全面且系统的方法,将MLLMs的二维理解能力扩展到复杂的三维场景中
- 主流二维MLLM架构(如LLaVA-1.5)只能处理低分辨率图像输入
- Contribution
- OmniDrive-Agent: 3D Q-Former架构;联合编码动态物体和静态地图元素,为感知-行动对齐提供了一个紧凑的世界模型
- OmniDrive-nuScenes Benchmark:涵盖场景描述、交通规则、三维定位、反事实推理、决策制定和规划等全面的视务觉问答(VQA)任务
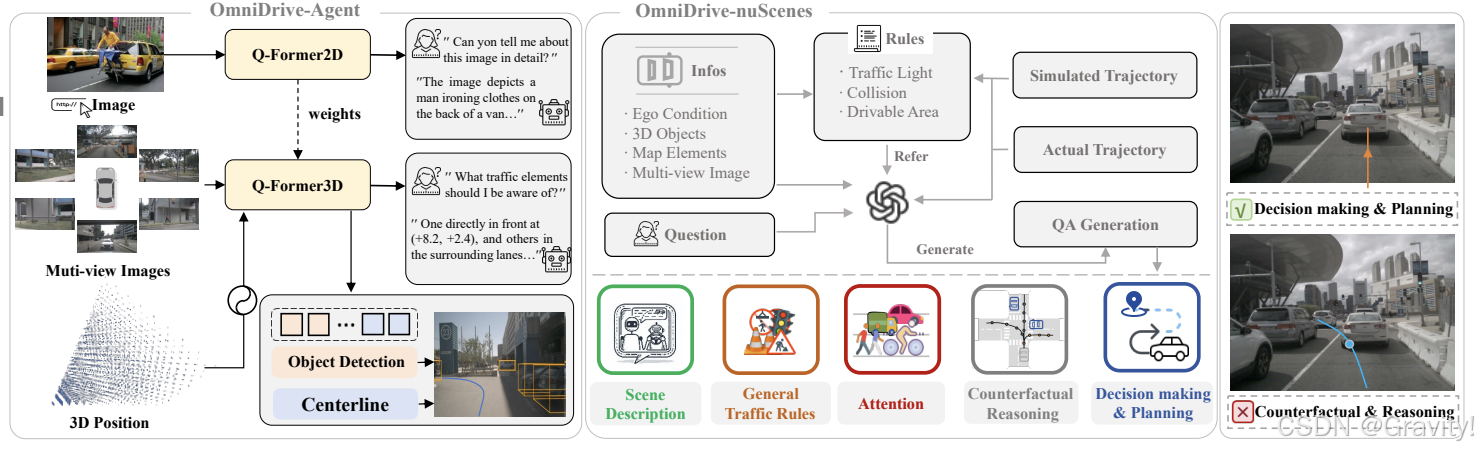
- OmniDrive-nuScenes
- 自动化的QA生成流程: 将3D感知+交通规则和规划模拟 → GPT-4 → QA对
- Prompt类型:
- 场景描述(帮助模型理解环境)
- 车道-目标关联 (描述车道线与交通目标之间的空间关系)
- 模拟轨迹(提供基于不同驾驶意图的模拟轨迹,用于反事实推理)
- 专家轨迹(提供真实轨迹数据,用于评估模型生成的轨迹是否安全)

- 对话类型:
- 注意力识别(识别当前场景中需要关注的交通元素)
- 反事实推理 (评估不同决策的潜在后果)
- 决策制定与规划(生成安全的驾驶轨迹)
- 其他对话(进行多轮对话,涉及对象计数、颜色、相对位置等)

- Online Question-Answering: 在训练过程中动态生成问答对,以实时评估模型的性能
- 任务类型
- 2D-to-3D Grounding:给定一个2D bounding box,模型需要提供对应目标的三维属性(如类别、位置、尺寸、方向和速度)
- 3D Distance:基于随机生成的三维坐标,识别该位置附近的交通元素,并提供其三维属性
- Lane-to-Objects:基于随机选择的车道中心线,列出该车道上的所有目标及其三维属性
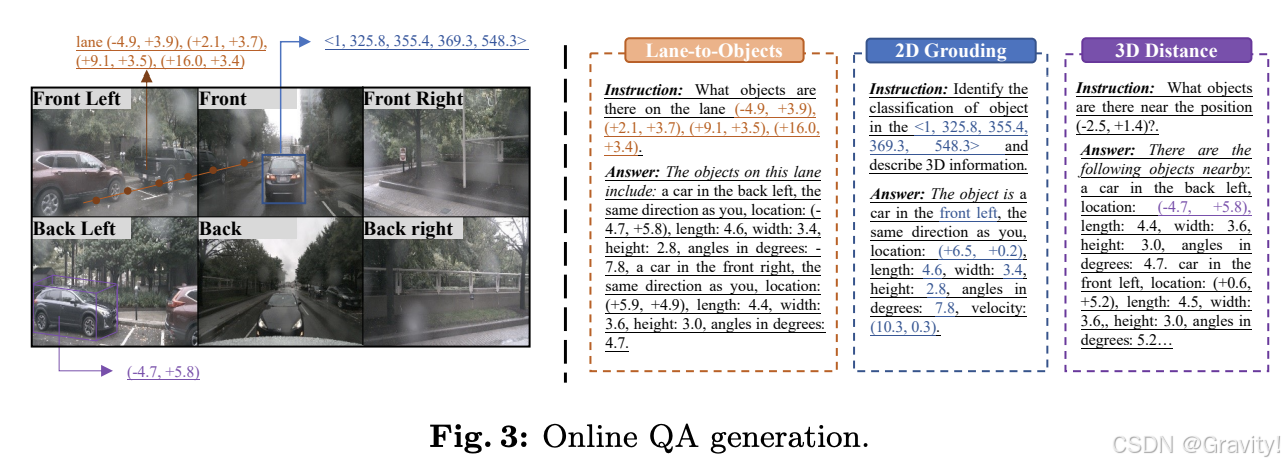
- 任务类型
- OmniDrive-Agent
- Overall Architecture
- 目标:在多视角图像特征中高效获取3D空间信息
- 核心:将Multi-view images特征通过Q-Former3D模块转换为稀疏查询,实现从感知到推理的无缝对接
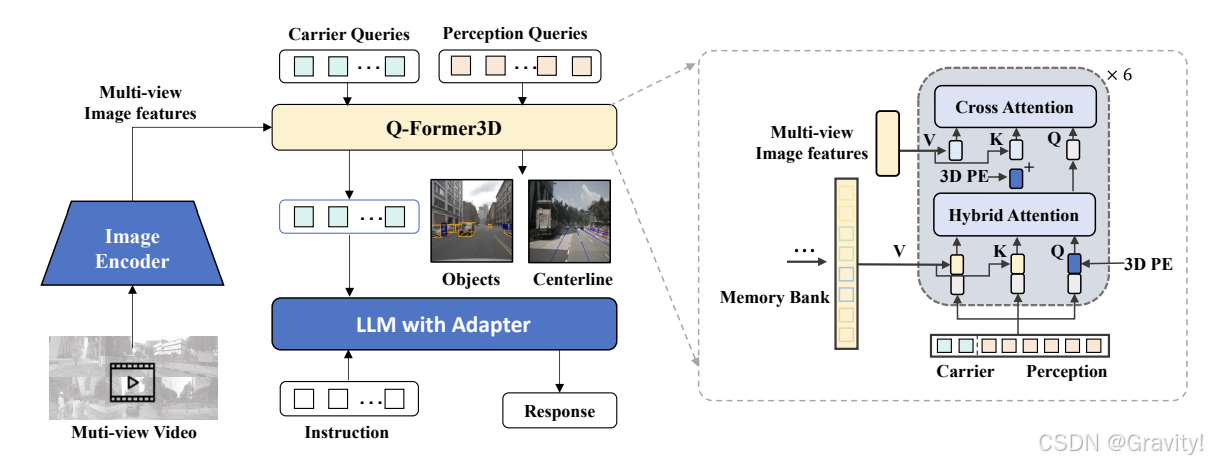
- Q-Former3D
- 目标
- 高效处理高分辨率多视角输入
- 具备3D空间理解能力
- 与LLM对齐
- 初始化query
- Perception Query:预测前景元素的类别和坐标
- Caririer Query: 与LLM的维度对齐,并进一步用于文本生成
- 3D位置编码的添加
- 为了将2D特征提升到3D空间,需要在特征图中添加3D位置编码(与特征图维度相同的张量,其中每个位置的值表示该位置在3D空间中的坐标信息)
- Memory Bank
- 一个固定大小的缓冲区,用于存储最近几帧的感知查询
- 将当前帧的感知查询存储到记忆库中,在每个时间步中,记忆库中的查询会向前传播,以便在后续帧中使用
- 目标
- 训练策略
- 阶段一:2D Pretraining【获取语义理解能力】
- 初始化:冻结除Q-Former外的所有参数,训练模型以对齐图像特征和语言模型
- 指令微调:使用LLaVA v1.5的指令调整数据集,仅冻结图像编码器,微调其他参数
- 阶段二:3D Finetuning【增强模型的三维空间定位和感知能力】
- 增强模块:在Q-Former中引入三维位置编码(3D Position Encoding)和时间模块(Temporal Modules)
- 训练数据:使用与自动驾驶相关的三维任务数据,如运动规划(Motion Planning)和三维定位(3D Grounding)
- 阶段一:2D Pretraining【获取语义理解能力】
- Overall Architecture
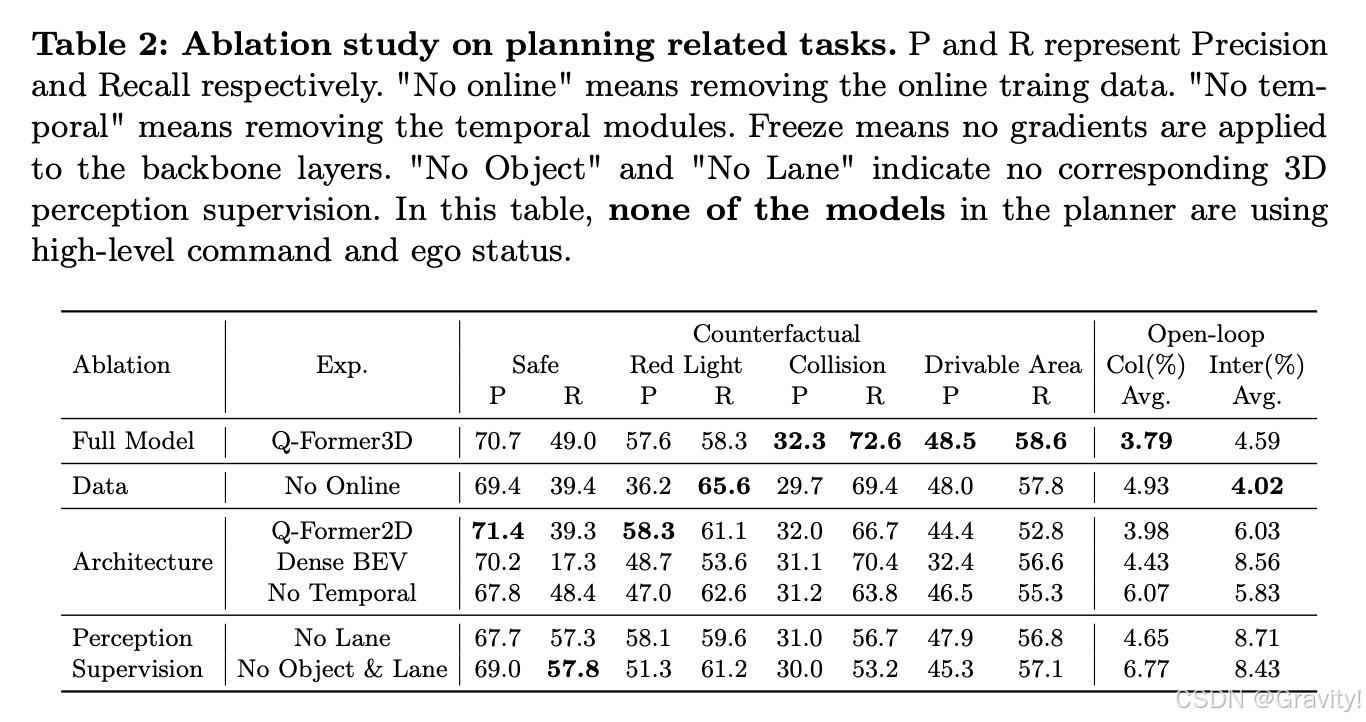
- 实验
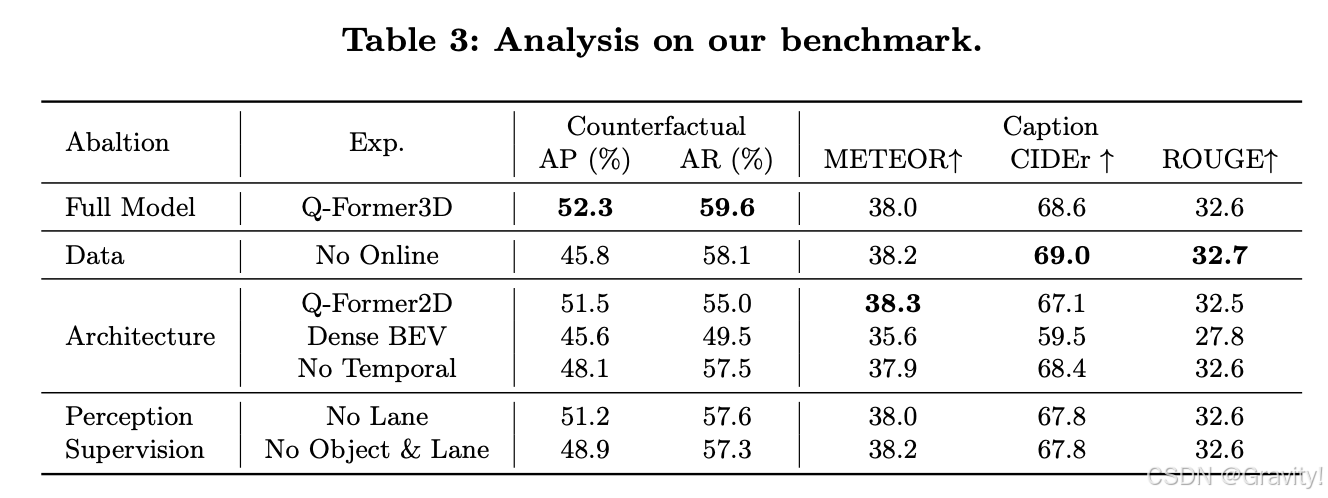
论文2:SOLVE: Synergy of Language-Vision and End-to-End Networks for Autonomous Driving [MMLab, CUHK]
- Background
- 端到端自动驾驶现有挑战:复杂性学习不佳、缺乏常识推理、有限的可解释性和因果混淆(如将载有交通锥的卡车误认为是路障,将广告牌上的车辆图像误认为是真实障碍物)
- VLMs的优势:在多样化数据集上进行广泛训练(简化学习复杂性),更强的逻辑能力和常识知识
- VLMs的局限:效率和3D感知
- Motivation
- 过去的工作(如DriveVLM)仅在轨迹层面结合VLM和E2E模型,但两者独立运行,限制信息和知识共享
- 本工作SOLVE:促进VLM和E2E模型之间的协同作用,强调知识和规划的整合
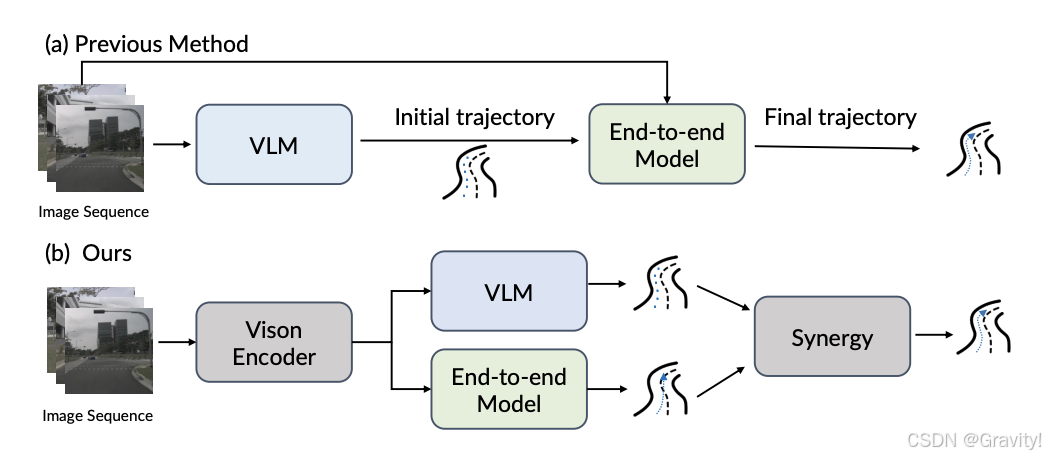
- Framework
- 核心1: SQ-Former(Sequential Q-Former)
- VLM和E2E模型共享视觉编码器
- 目标:从输入的多视角图像序列中提取有用的视觉信息,并将其压缩为一组紧凑的视觉查询(visual queries)
- 关注信息:场景级静态信息(如天气、时间、交通状况等),动态参与者(如车辆和行人),动态地图线索(车道线)
- 初始收集查询(Collector Queries)→ Transformer Decoder【获取场景静态信息】→ 拼接任务查询(Task-specific Queries)和记忆库(用于引入驾驶场景的时间动态性) → 目标检测、车道理解Transformer Decoder【获取不同任务能力】
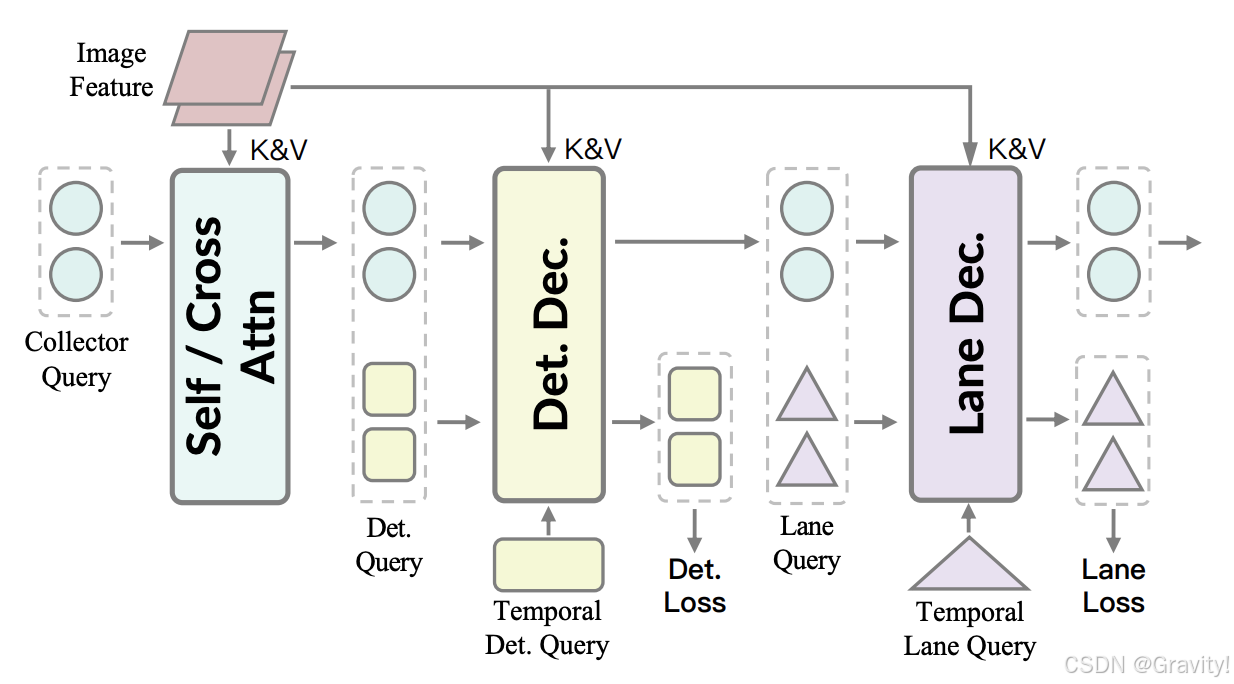
- 高效性:与OmniDrive使用的512个查询相比,SQ-Former仅使用384个查询就能实现更好的性能
- 核心2:Trajectory Chain-of-Thought
- 逐步细化轨迹预测,减少轨迹生成的不确定性并提高预测精度
- 轨迹库(Trajectory Bank):k-means对训练集中的轨迹进行聚类,为每个导航命令(如直行、左转、右转)生成一组预定义的候选轨迹(自车状态和历史轨迹信息)
- 轨迹选择(Trajectory Selection):
- 根据当前自车状态和历史轨迹,计算与轨迹库中轨迹的相似度,并通过top-k选择与当前状态最接近的
条轨迹
- 将每条候选轨迹编码为一个轨迹标记(trajectory token),并将其插入到文本提示中。例如,Prompt可以是:“这里有预定义的轨迹 <Traj1>, <Traj2>, ..., <Trajkl+1>。请根据当前场景选择最适合自车的轨迹”。让VLM从候选轨迹中选择最合适的轨迹
- 根据当前自车状态和历史轨迹,计算与轨迹库中轨迹的相似度,并通过top-k选择与当前状态最接近的
- 轨迹细化(Trajectory Refinement)
- Prompt:“以选定的轨迹 <Point1>, <Point2>, ..., <Pointn> 为参考,请为自车提供规划轨迹,其速度为 SPEED m/s,加速度为 ACCEL m/s²。”
- VLM根据细化提示生成最终的规划轨迹
- T-CoT优势:减少不确定性、降低计算成本、提高轨迹多样性
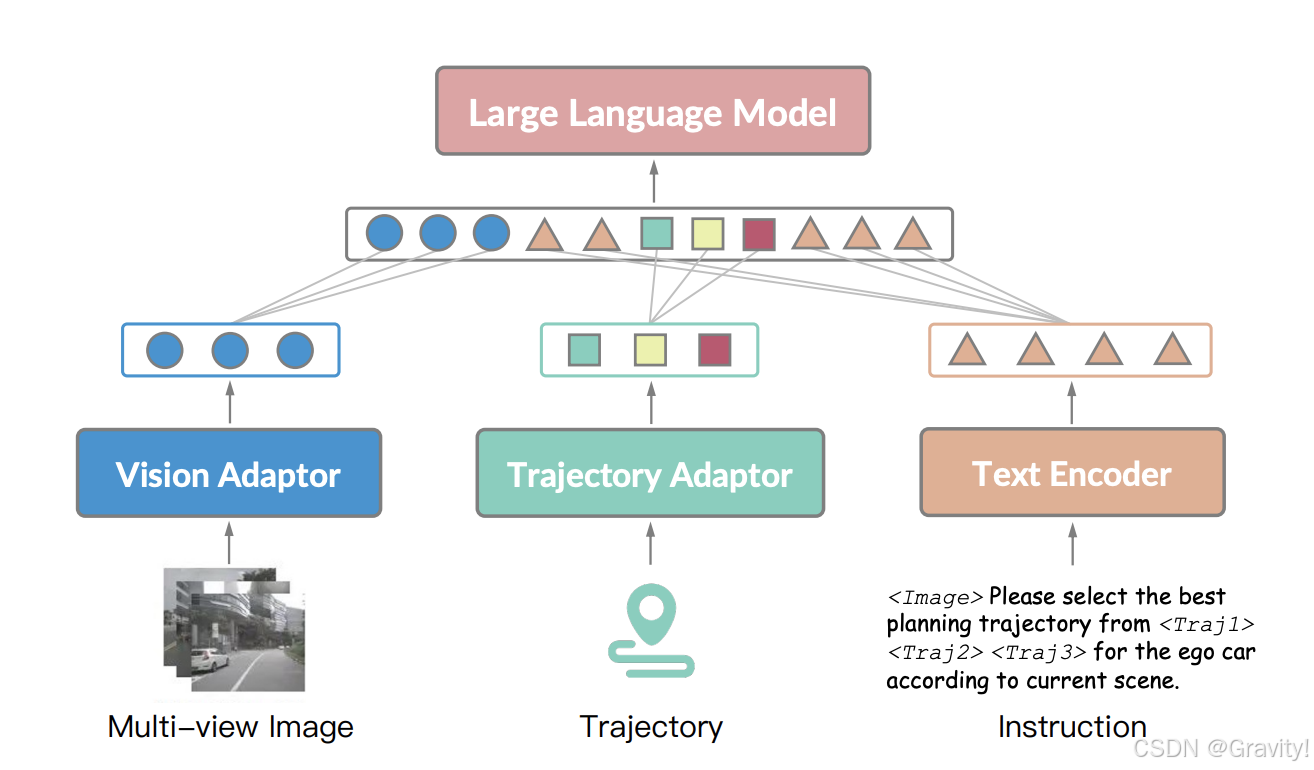
- 核心3:Time-decoupled Synergy Prediction(时间解耦协同预测)
- 核心思想:让VLM和E2E模型在不同的时间尺度上运行,并通过一个内存机制进行协同
- VLM负责长时轨迹预测(较高的准确性和可靠性)
- E2E负责实时轨迹预测(保持实时性)
- 轨迹存储:
- VLM生成的轨迹被存储在一个内存中,以便E2E模型在需要时可以访问
- E2E模型从内存中获取VLM生成的轨迹作为初始化先验
- 训练策略:
- 训练需要解决的问题
- 如何优化VLM的推理能力,使其能够生成高质量的轨迹预测
- 如何训练E2E模型,使其能够利用VLM的输出,同时保持实时性能
- 如何通过特征共享和联合训练,增强VLM和E2E模型之间的协同作用
- Stage 1 VLM QAs微调:
- 使用与OmniDrive QA pairs,通过LoRA层对VLM进行微调
- 帮助VLM学习如何从视觉和语言信息中提取关键特征
- Stage 2 Trajectory Adapter训练:
- 训练编码trajectory tokens的能力,使其能够被VLM正确理解和处理
- Stage 3 E2E Planning Head:
- 让Planning Head能够利用SQ-Former提取的视觉特征生成轨迹预测
- Stage 4 VLM和E2E联合优化:
- 使用Trajectory Chain-of-Thought机制,增强VLM的推理能力
- Stage 5 轨迹级协同优化:
- 在E2E模型的训练过程中,引入VLM在历史帧中生成的轨迹作为初始化先验
- 训练需要解决的问题
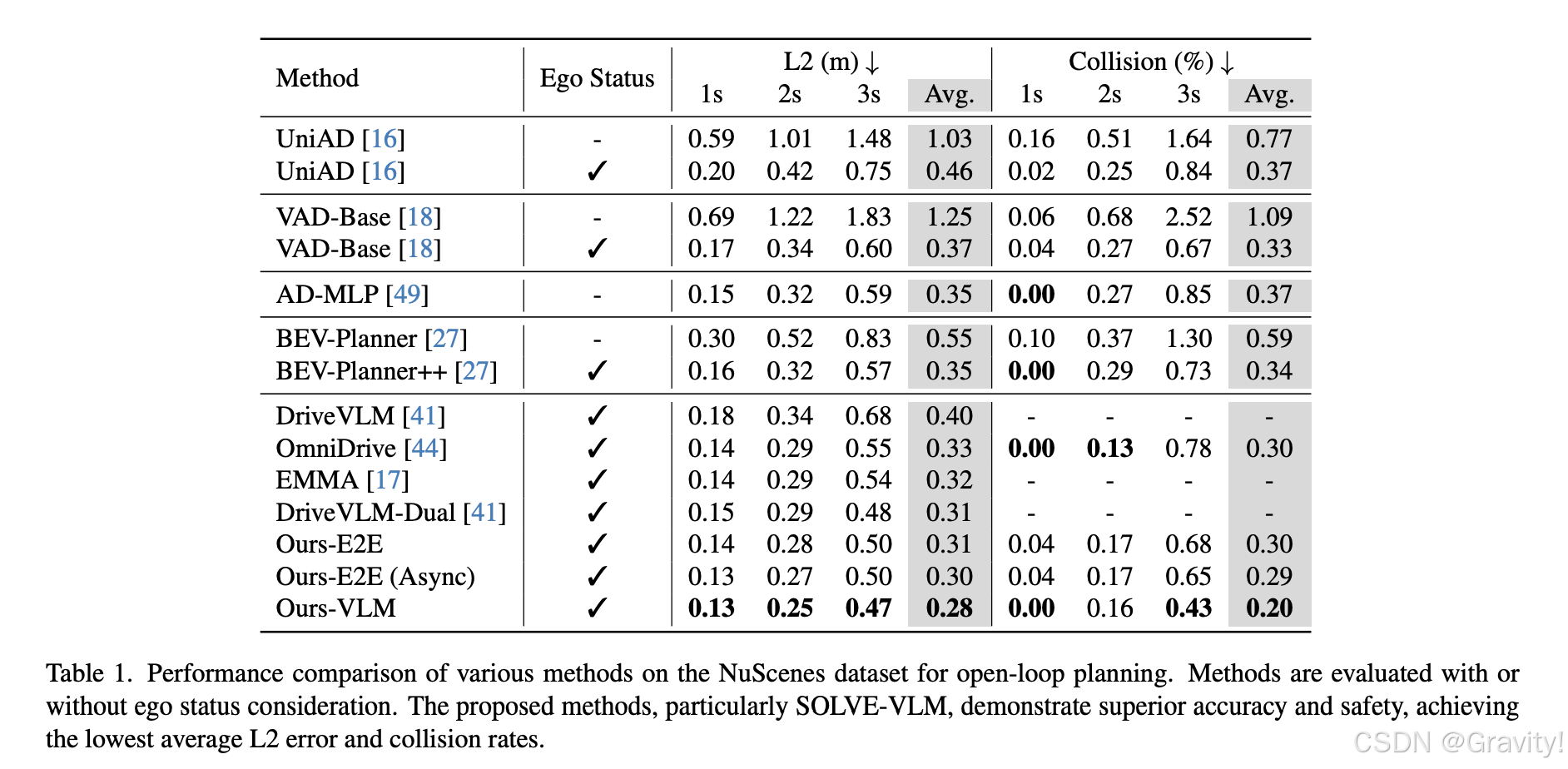
- 实验

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)