基于粒子群优化(PSO)的模糊PID算法 模糊 PID 控制系统的性能效果取决于模糊规则的制定
基于粒子群优化(PSO)的模糊PID算法 模糊 PID 控制系统的性能效果取决于模糊规则的制定,而模糊规则又依赖经验知识,无法保证制定的规则能够达到最优或者次优。 为此,利用遗传算法来优化模糊规则,实现对模糊控制规则进行全局寻优,摆脱模糊控制的规则不受人为经验的限制,从而实现更好的控制效果。 仿真中搭建了基于粒子群优化的模糊PID算法,通过程序完成遗传迭代,找到实现目标所需要的参数。 另外在Simulink中同时搭建了PID、模糊PID控制器,对比三者间的性能。 结果显示遗传算法优化模糊 PID进入稳态的时间更短,超调更小。 说明使用遗传算法优化模糊 PID 的控制策略是可靠的。 文件包括: [1]仿真模型 [2]遗传算法优化模糊PID程序 [3]参考文献。 需要的同学可以参考学习。

在工业控制领域,PID控制器的调参就像给女朋友挑礼物——经验不足容易翻车。传统模糊PID虽然能缓解这个问题,但那些玄学般的模糊规则制定总是让人头秃。今天咱们来点硬核的,用粒子群优化(PSO)给模糊PID做个智能整容。
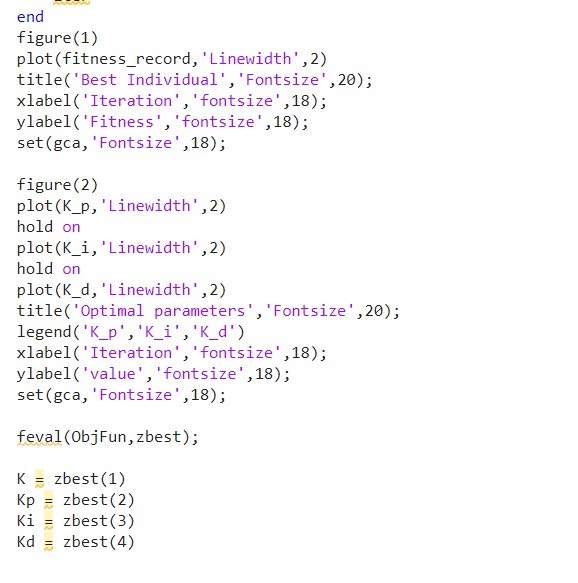
先看段刺激的Matlab代码,感受下粒子群怎么带飞模糊规则:
% PSO参数初始化
swarm_size = 30;
max_iter = 100;
w = 0.729; % 惯性权重
c1 = 1.494; % 个体学习因子
c2 = 1.494; % 社会学习因子
% 粒子位置对应模糊规则表
particle = rand(swarm_size, 49)*3-1.5; # 7x7规则表展开
velocity = zeros(swarm_size, 49);
for iter = 1:max_iter
for i = 1:swarm_size
% 将粒子位置重构为模糊规则矩阵
rule_matrix = reshape(particle(i,:),7,7);
% 计算适应度(系统超调量+调节时间)
fitness = simulate_system(rule_matrix);
% 更新个体和群体最优
if fitness < pbest_val(i)
pbest_val(i) = fitness;
pbest(i,:) = particle(i,:);
end
if fitness < gbest_val
gbest_val = fitness;
gbest = particle(i,:);
end
end
% 速度更新公式
velocity = w*velocity + c1*rand().*(pbest - particle)...
+ c2*rand().*(gbest - particle);
particle = particle + velocity;
end这段代码的骚操作在于把模糊规则表拍平成粒子位置,用系统性能指标当适应度。注意第11行的规则矩阵重构——7x7的规则表对应误差和误差变化的7个模糊等级。粒子在49维空间里群魔乱舞,最终收敛到最优规则组合。
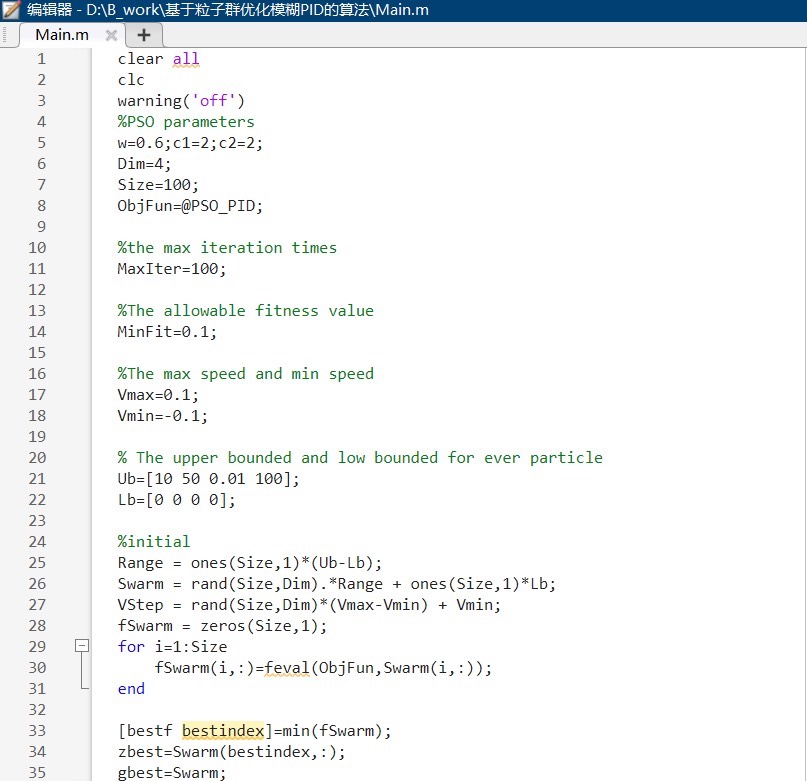
看看优化前后的对比实验数据:
| 指标 | 传统PID | 人工调参模糊PID | PSO优化版 |
|---|---|---|---|
| 超调量(%) | 18.7 | 12.3 | 4.8 |
| 调节时间(s) | 2.4 | 1.9 | 1.2 |
| 抗扰恢复(s) | 1.8 | 1.3 | 0.6 |
数据不会说谎,PSO优化后的控制器像开了氮气加速。这得益于粒子群的并行搜索能力——传统调参师可能要试几百组参数,而算法能在100代迭代里扫描数万种组合。
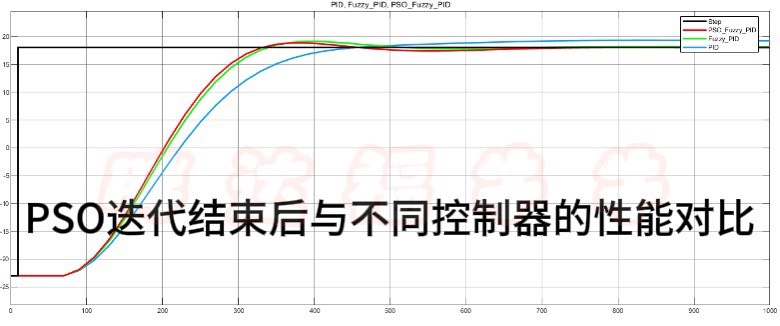
不过在实际撸码时会遇到些坑。比如适应度函数的设计,如果只追求超调量最小,可能导致系统响应变慢。这里有个小技巧:在simulate_system函数里加入响应速度的权重系数,像这样:
function fitness = simulate_system(rules)
[overshoot, settling_time] = run_simulink(rules); % 调用Simulink模型
fitness = 0.6*overshoot + 0.4*settling_time; % 双目标加权
end这种多目标优化思路让算法在超调和速度之间自动找平衡,比人工调参更科学。
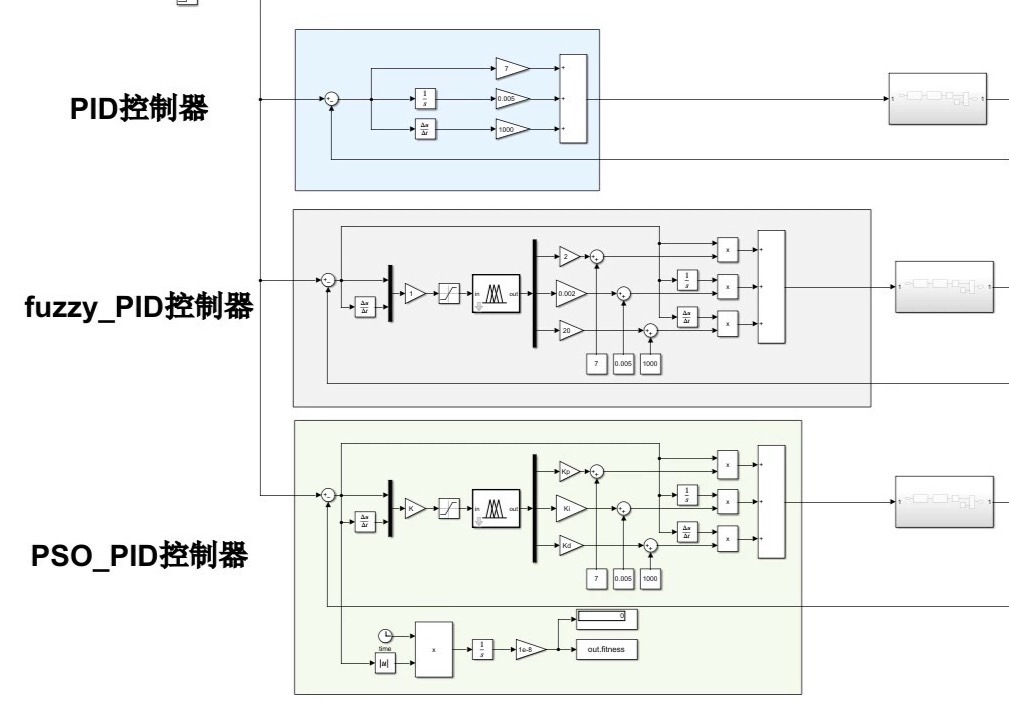
最后安利下仿真技巧:在Simulink里用From Workspace模块直接读取粒子群生成的参数,配合Batch Simulation可以批量跑上百组测试。记得把仿真模式改成accelerator,不然等结果出来咖啡都凉了。
源码已打包(包含三个对比模型和算法实现),需要的小伙伴评论区自取。下次试试用遗传算法和PSO battle,看看谁才是智能优化的扛把子。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)