grpo论文
在概率论中,条件概率 $P(B|A)$ 表示在事件 $A$ 发生的条件下,事件 $B$ 发生的概率。在大模型中条件 ($A$):用户输入的指令(Prompt),记为 $x$。结果 ($B$):模型生成的回答,记为 $y$。数学表达:SFT 的目标就是建立一个模型 $\pi_\theta$,这个模型本质上是一个巨大的概率分布函数$P(y|x;\theta)$。序列分解。
为什么这里用到大语言模型而不用yolo模型?
简单来说,虽然 YOLO 在“找东西”上极快,但它在“理解复杂逻辑”和“解释为什么这么数”上是缺失的。
1. 任务本质的差异:检测 vs. 推理
-
YOLO 的局限(单纯的检测):
-
YOLO 是为目标检测(Object Detection)设计的。它能告诉你图像里有“鸡蛋”,并画出框,但它不具备逻辑推断能力 。
-
如果问题是“巢里有几个蛋?”,YOLO 可能会把视野内所有的蛋都框出来(包括巢外的),因为它无法理解“在巢里(in the nest)”这个空间关系约束 。
-
-
GRIT 的优势(锚定推理):
-
GRIT 训练的大语言模型不仅在找蛋,它还在思考 。
-
如 Figure 1 所示,模型会先分析“为了确定巢里蛋的数量,我们需要数巢内可见的蛋” 。它将空间位置(坐标)与语义逻辑(在巢内、不同颜色)结合在了一起 。
-
2. 为什么不用 YOLO?
3. GRPO 算法在这里起到了关键作用
你上传的公式展示了 GRPO 如何优化这种推理能力。它通过组归一化优势 $A_i$,让模型在生成的多个版本中,自动筛选出那个“既找对了位置(格式奖励 $r_{format}$),又数对了数量(准确率奖励 $r_{ans}$)”的最佳路径 。
这种**“奖励导向”**的训练,让模型自发产生了一种“先指位、再判断、后总结”的类人思维模式,而 YOLO 这种基于回归的端到端检测器是无法通过这种逻辑奖励来进化的 。
总结:不仅仅是“看到”,更要“看懂”
正如论文结论所言,GRIT 实现了**“让模型结合图像推理,而非仅仅围绕图像推理”** 。YOLO 只是一个优秀的“扫描仪”,而 GRIT 是一个拥有“眼睛”且能“讲道理”的智能体。
哥只是个传说 01:06
对肯定做目标检测肯定是很厉害的,但是为什么这里要用到大语言模型而不用什么 yolo 模型,这是第一个问题,明白吗?这第一个问题。而且你复试的时候可能会被问到这就要区分了。首先为什么,首先你看我这里是不是一段文字,明白吗?那我是不是最终要得到他的目标?的数量,但有问题,假设我这里,当然他问题还是太笼统了,如果会再换一个精细一点问题,比如说,然后当然你这个题还行,你看这个是什么?如果我把这几个词删掉,你看我把这几个词删掉,那是不是把他图片里面全部的蛋都给数出来了,是不是我加入的限定词?是不是在这个鸟巢里面去了,那是不是这些就不会被数掉了,明白了吗?你看123456是不是六个,是不是没有数其他的是不是对于模型来说,它要理解什么,它要理解图像里面。是什么意思?这是不是在鸟巢里面,就要求模型要得到这种性能,也或者是涌现这种能力,明白的意思吗?这是普通的 yolo 模型是做不到的,明白吗?
哥只是个传说 18:42
所以说我们为什么说监督微调之后要再继续衔接一段强化学习,原因就在这里了,监督微调是远远不够的,明白吗?他只是做了一种背书的操作,但是遇到难一点或者是没有见过的题目,他就不行了,这是我们很多次实验都是发现这个问题的。
所以我们加一段强化学习,让模型真正的进行微调,前面是为了给强化学习做铺垫的,为什么,因为强化学习一般的题目都是比较偏难一点点的,相对于监督微调来说,就相对于监督微调来说。场外学习的训练题,它会稍微难一点点明白吗?这样的模型是不是才有更强的能力
那么在微调强化学习微调的时候。我们这个模型就开始了,他是不是在前期已经学会了,就因为他背书是不是学会了这一套思考的过程,思考的方式或者是思考的模板或者是做题的模板?明白吗?他有了这个之后是不是以后做的题会更就是会更加得心应手一点,相比于没有背模板来说,强化学习之前铺垫sft就是让模型能够在一些比较好的套路或者是模板上能够更好的去得到解决的方法和答案,就这么一回事的。第一节课是这样说的,就是说我们这里其实是分开做的sft和rl主要做对比,哪像很多强化学习是不是是这样的模式呢?那么。并且强化学习。在监督微调之后,要选择一些难一点的训练集,这样的模型,才能够真正会做题,而不是老是做监督微调这种简单题,为什么监督微调都要选择简单题,是因为你从一个模型啥都不会就是对于你这种领域的题
模型还是比较薄弱的,明白吗?那么你一上来让他做难的,你觉得他能做对吗?是不是训练起来很难收敛,明白吗?
所以说我们说监督微调,他就很简单,他就靠背书,并且他的题目会比较简单,这样他才会能够背我们精髓是让他会背出这一个思考的习惯跟。过程就行了,然后强化学习才是做真正难的一点的题目好,那么我们说到说回什么叫做 GRPO,什么叫 PPO,其实上 GRPO 算法就是 PPO 的演变。
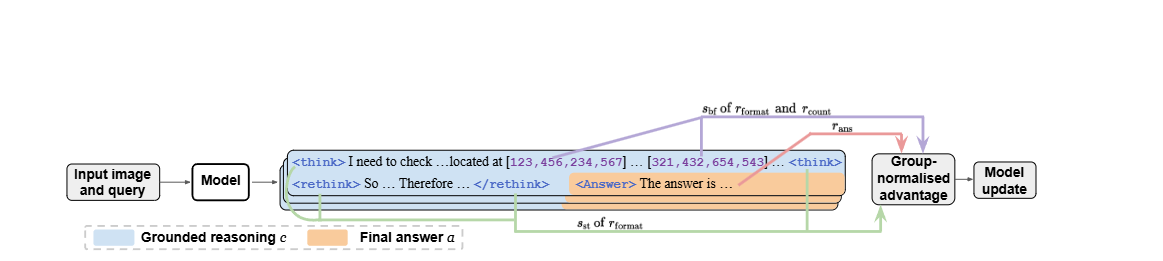
你看他首先你看他是不是输入一个图像跟他的问题,看到没有,然后输入给模型,然后模型的话,按照我们正常来说,在训练的时候我们就得训练它有一种格式,是不是这种格式?这种格式训练出来之后进行打分,哪种是哪种分,它的作者的奖励函数设置在这里,看到没有一种是格式分。
一种是什么?最终答案分明白吗?能理解我的意思吗?你应该看到这篇文章你有印象,明白我的意思吗?你看什么叫格式分就跟你这个思维链的格式,你能不能遵循这个格式,因为我们说格式我们觉得很好,才让模型仿照我们人为的思考的方式,能有这个过程。如果他没有的话,是不是这个格式分就为零了,明白吗?然后这个是最终答案的得分,比如说你数出来是六,但是答案是五是不是也得零蛋了,明白吗?就然后它就进入 GRPU 算法计算优势函数,然后进行一次更新,什么叫更新,就参数更新,其实就是梯度下降,机器学习里面梯度下降。
然后我们特别要注意什么?从几个地方出发第一个。第一个作者的数据集它是怎么样构造的,明白吗?数据集是怎么样构造的,这是第一个,这是你非常需要非常关心的问题,作者的训练集是怎么样构造的。第二个
监督微调,它的思维链的格式是怎么样的明白吗? 并且知道监督微调它本身的原理跟意义是这个含义是什么?为什么要监督微调。第三个,为什么要用强化学习?OK 吧,然后强化学习里面 GRPO 算法是如何进行计算的,就我刚刚说到的明白吗?第四点是什么?你看你训练,最终我们不是要训练完一个模型吗?是不是训练完,假设我们已经训练完了,我们是不是要测试一下它的性性能怎么样,你看你是不是有这些测试集,你看那问题最后一个问题,使用这些数据集有什么理由吗?这些测试题考察的模型的什么性能,明白吗?我举个例子,比如说TallyQA 这个数据集,我举个例子给你说这个数据集,它主要是考察了模型,能不能对比较复杂场景下的一个技术。比如说图上有好几头牛,你能不能数完明白吗?好,这个 ACC 是什么?代表是我们这个准确率明白吗?就是比如说有六头牛,然后你模型也输出了六头牛对的?那么这个 GIOU 是什么?比如说我们这里不是要画框吗?你看就或者是裁剪区域吗?你看这里是不是有这个区域,假设我们这个训练集或者数据集或者测试集,它本身已经包含了一个标签,什么标签?每一个物体,他的所处于位置的区域是在什么坐标里面的明白吗?比如说我举个例子。
我的框框 OK 比如说我用蓝色代表这个题目的答案,也就是这个标签,也就说这个蛋。我们真实答案这个蛋是符合在哪个地方,比如说这个坐标这个150,160 250 270 ,然后我们现在的模型它定位到哪里?定位到这里,你看明白了吗?是不是虽然有点偏差,但是还能接受的,明白吗?那么我们说 IO 这就是 IOU 了,你把它,你把这个红色的框跟蓝色的框,也就是我们模型真实预测出就是定位出来的地方跟真实答案真正坐标地方进行一个重叠计算,看一下他们重叠能多多少,这个就叫 iou 了,明白吗?这个叫重叠系数就来 IOU 越大就代表你这个答案越加更加接接,接近真实的这个定位的区域,明白吗?
另外一个最重要,绝对最重要的就是你看作者的分数虽然很高,但是他仍有进步空间,那么我们会想,为什么模型在这个方面?它会发生,就是它不能达到百分百全对。当然百分百全对很难,但是为什么难,模型为什么会还是有进步空间。就是说为什么有一些题目他还是做不出来,我们要分析这个问题。明白吗
所以说你在简历上你得必须写上这一句,也就是我们在这个模型里面对于做不出来的例子,我们举主要具体分析的有哪些原因,然后我们发现有可以用哪种方法可以缓解这种现象,这个是不是很好?
1. 数据集是怎么得来的?
GRIT 的数据获取路径非常独特,体现了**“以小博大”**的策略
-
训练集构成:包含仅 20 个 唯一的“图像-问题-答案”三元组(triplets)。
-
本文的这20个数据集用来训练,这个数据集是数据通过autoif数据合成提炼的高质量数据,也就是蒸馏,蒸馏是让小模型学习大模型的的表现,在这里就是先给teacher模型大量的指令得到答案和思维过程,最终得到一个问题,思维链,答案的数据再通过sft,你蒸馏出来的东西就是为了cot(思维链)
-
教师模型(如 GPT-4o)生成高质量的、带有复杂逻辑(如坐标、推理链)的训练样本 。
-
能力迁移:学生模型通过这些样本,学习教师模型如何通过“指着图说话”来解决问题,从而在极小的数据规模下实现能力突现 。
蒸馏是上位概念(目标:知识迁移)。AutoIF 是实现手段之一(工具:自动化数据合成)。 -
结果:利用 GPT-4o(教师)的博学,通过 AutoIF 提炼出纯净的指令数据(蒸馏物),最后通过 SFT(或 LoRA 这种轻量化手段) 或 GRPO(强化学习) 喂给 Qwen 或 InternVL(学生),让它们学会带着图像思考 。
-
所以蒸馏的数据给sft得到一个遵循指令的回答 -
stf和lora的关系?
-
SFT (Supervised Fine-Tuning,有监督微调) 是大模型训练的一个阶段。它的目的是让预训练好的模型学会按照人类的指令说话 。
LoRA (Low-Rank Adaptation,低秩自适应) 是一种具体的参数更新策略(微调方法)。
它们的关系可以类比为:
-
SFT 是“去健身房健身”这个目标。
-
LoRA 是“只练核心肌群”这种省力的方法。
-
因此,SFT 的过程可以包含 LoRA,也可以不包含。如果你有极强的算力,你可以进行“全参数微调”(Full Fine-Tuning);如果算力有限,你就会选择用 LoRA 来进行 SFT。
-
SFT 包含 LoRA 吗? 取决于你。现在的 SFT 教程默认通常都推荐使用 LoRA 这种高效方式。
-
关系:LoRA 是实现 SFT 的一种高效工具。你可以说“我正在用 LoRA 的方式做 SFT 训练”。
-
蒸馏出来的数据为什么给sft,而不是直接rl?
这是一个非常深入且具有实操性的问题。在 GRIT 论文及其背后的技术逻辑中,将蒸馏数据先喂给 SFT(有监督微调) 而不是直接进行 RL(强化学习),主要是为了解决强化学习面临的“冷启动”和“搜索空间”难题。
以下是详细的原因分析:
1. 解决“冷启动”难题(Warm Start)
强化学习(RL)需要模型在初始状态下就能产生一部分“正确”的动作,否则模型会因为拿不到任何奖励信号而无法更新。
-
SFT 的作用:通过蒸馏出的高质量数据(如教师模型生成的锚定推理链),SFT 训练能让模型先学会基本的“说话套路”和“画框格式” 。
-
为什么要先 SFT:如果直接开始 RL,由于初始模型生成的坐标全是随机的乱码,它几乎永远拿不到格式奖励 (rformat) 或准确性奖励 (rans)。这就像让一个还没学会写字的孩子直接去参加高考并根据分数自学 。
-
2. 缩小策略搜索空间
大模型的输出空间是极其巨大的(词表大小的指数级组合)。
-
约束行为:SFT 相当于给模型设定了一个初始的“行为基准”。它告诉模型:你的思考路径应该长得像
<think> [坐标] ... <rethink> ... <answer>这样 。 -
提高效率:有了这个基准后,RL 只需要在这些已经比较靠谱的路径附近进行细微的概率微调(即偏置现有模式),而不是在茫茫的随机序列中大海捞针 。
-
3. 构建“可验证性”的基础
在 GRIT 的实验中,蒸馏数据通常通过 AutoIF(自动化指令遵循)合成,具有极强的格式特征。
模仿与泛化:先通过 SFT 让模型掌握这种“可验证”的格式 。 -
RL 的后续进阶:在模型已经懂格式的基础上,RL 才能发挥真正的作用——通过 Ai(组归一化优势)在多个“格式正确”的候选答案中,找出逻辑最严密、最符合图像事实的那个 。
-
4. 整体工作流的配合
在实际的 AI 工业界(包括 GRIT 的实现),通常遵循 “预训练 -> 蒸馏数据进行 SFT -> RL 优化” 的流水线:
-
蒸馏 + SFT:建立基础的指令遵循能力和格式规范 。
-
RL (GRPO-GR):利用任务级的奖励信号(如答案对错、坐标精度),让模型真正实现“结合图像思考”的能力融合,解决 SFT 阶段只会模仿表面、逻辑不扎实的弱点 。
-
你可以把这个过程类比为**“考研复习”**:
-
蒸馏出的数据给 SFT:相当于你先看“参考书”和“例题”,模仿学霸的解题思路和答题格式(打基础)。
-
直接 RL:相当于你书也不看,直接去刷真题。如果你连知识点都不会,直接刷题只会反复错,根本无法通过分数获得进步。
-
结论:SFT 负责**“懂规矩”(Know-how),RL 负责“拿高分”**(Optimization)。两者结合才是目前最强的训练范式 。
-
一个是监督微调,它的本质是什么,然后它数学的本质原理是什么?对吧,另外一个监督微调的话,容易发生灾难性遗忘,那么这个是什么东西,为什么会发生这种问题?
1. 监督微调(SFT)的本质:建立“映射”
本质定义: SFT 的本质是**“行为对齐”** 。预训练模型(Base Model)像一个博学但随性的天才,它看过全人类的知识,但不知道怎么按规矩回答问题。SFT 就是通过给它看成千上万个“指令-答案”对,教会它在特定输入下,输出符合人类逻辑和格式的响应 。
数学本质原理:极大似然估计 (MLE) 从数学上看,SFT 是一个条件概率建模问题。
什么是“条件概率建模”?
在概率论中,条件概率 $P(B|A)$ 表示在事件 $A$ 发生的条件下,事件 $B$ 发生的概率。
-
在大模型中:
-
条件 ($A$):用户输入的指令(Prompt),记为 $x$。
-
结果 ($B$):模型生成的回答,记为 $y$。
-
-
数学表达:SFT 的目标就是建立一个模型 $\pi_\theta$,这个模型本质上是一个巨大的概率分布函数 $P(y|x; \theta)$ 。
-
序列分解:由于回答 $y$ 是由多个词(Token)组成的序列 $y_1, y_2, \dots, y_t$,根据概率乘法公式,这个条件概率可以拆解为:
$$P(y|x; \theta) = \prod_{t=1}^{T} P(y_t | x, y_{<t}; \theta)$$
这表示:在给定输入指令和之前已经生成的词的条件下,预测下一个词出现的概率 。
2. 极大似然估计 (MLE) 的本质
极大似然估计(Maximum Likelihood Estimation) 的核心思想是:既然这组训练数据(人工标注的正确答案)已经真实发生了,那么我们的参数 $\theta$ 应该让这组数据出现的概率(似然度)达到最大。
-
模型训练的目标:我们有一堆高质量的“指令-答案”对 $(x, y)$ 。
-
似然函数:对于所有的训练样本,我们希望 $P(y|x; \theta)$ 越大越好。

-
对数变换:为了方便求导计算,我们通常对概率取对数,转化为最小化 负对数似然(NLL),这在神经网络中就是交叉熵损失函数(Cross-Entropy Loss)。
3. SFT 的数学过程:强制对齐
在 SFT 过程中,数学逻辑是**“强迫模型模仿”**:
-
输入:给模型看问题 $x$。
-
强制教师信号:不让模型随便乱猜,而是直接把正确答案 $y$ 摆在模型面前。
-
计算 Loss:计算模型预测的概率分布与真实标签(One-hot 向量)之间的差异 。
-
梯度更新:通过反向传播,调整参数 $\theta$,使得下一次遇到 $x$ 时,模型输出正确词 $y_t$ 的概率 $P$ 变得更高 。
4. 总结:这跟 GRIT 里的强化学习有什么区别?
理解了 SFT 的 MLE 本质,你就能明白为什么论文中要引入 GRPO 强化学习了:
-
SFT (MLE):本质是**“填空题”**。模型只学习如何复现给定的 $y$,它不知道为什么这个 $y$ 是好的,只是在机械地拟合分布 。
-
RL (GRPO):本质是**“选择题”**。模型针对一个问题生成多个可能的 $y$(组采样),然后通过奖励信号 $r$(比如最终答案是否正确、坐标是否符合格式)来评估哪个更好 。
2. 灾难性遗忘 (Catastrophic Forgetting)
它是什么?
灾难性遗忘是指模型在学习新任务(如 GRIT 中的“带坐标推理”)时,突然剧烈丧失了在预训练阶段习得的原有能力(如写通用作文、翻译或基础常识) 。
为什么会发生?(原理深度解析)
-
权重的“覆盖”与“漂移”: 神经网络的知识存储在参数 $\theta$ 的权重分布中。当你针对特定任务(比如只有 20 个样本的接地推理)进行全参数微调时,优化器为了降低当前任务的 Loss,会剧烈修改那些原本支撑通用能力的权重 。
-
目标函数的单一性: 在 SFT 阶段,Loss 函数只关注当前微调数据集的准确度 。模型为了“讨好”当前的训练集,会陷入过拟合,导致参数空间移动到了一个远离原始通用知识的区域。
-
神经元的高度耦合:
深度学习中的特征表示是分布式存储的。修改一个神经元的权重可能会影响多个不相关的任务,这种“牵一发而动全身”的特性导致了旧知识的崩塌。
3. 如何解决?(关联 GRIT 的做法)
为了防止灾难性遗忘,业界和 GRIT 论文采取了不同的策略:
-
LoRA(低秩自适应): 通过冻结原模型参数,只训练旁路的小矩阵,保护了原有的知识库不被修改。
-
GRPO 中的 KL 散度惩罚: 在你看到的优化目标公式中:
$$- \beta D_{KL}(\pi_\theta || \pi_{ref})$$
这一项的数学作用就是约束当前策略 $\pi_\theta$ 不要偏离初始参考策略 $\pi_{ref}$ 太远 。
-
本质: 它在数学上强迫模型在“变聪明”的同时,必须保留预训练阶段的“底色”,从而在根本上缓解了灾难性遗忘 。
-
还有一点就是监督微调,它的一般来说训练一个3B或者7B的模型,它一般要设置多少个训练的epoch,或者是说一般数据量要有多大才行?
根据你提供的 GRIT 论文案例,它展现了一个极端的例子:仅用 20 条 数据就能跑通 。但那是基于特定的强化学习(RL)目标。对于常规的 SFT,你可以参考以下标准:
1. 训练轮数(Epochs)的权衡
在 SFT 中,Epochs 通常设置得非常小,一般在 1 到 3 轮 之间。
2. 数学本质:多项式次数过高
从函数拟合的角度看,过拟合通常发生在模型复杂度(参数量)远超数据信息量的时候。
3. 为什么会发生过拟合?(结合 408 考研背景)
根据你之前关心的 SFT 和 GRIT 论文,过拟合通常由以下原因诱发:
解决方案:
总结:
过拟合就是模型**“走火入魔”**了——它太关注细节,以至于忘记了全局。
在 GRIT 论文中,为了在极小样本下避免过拟合,作者使用了 GRPO 强化学习 配合 KL 散度惩罚,这本质上就是给模型戴上了“紧箍咒”,防止它偏离预训练的通用分布。
4. 如何判断和解决?
判断方法:
观察 Loss 曲线。如果训练集 Loss 持续下降,但验证集 Loss 在下降到一定程度后开始反弹(上升),这就是典型的过拟合标志。
-
为什么要少?(防过拟合):SFT 的数据集通常质量极高,如果跑太多轮,模型会开始死记硬背训练集的字句,导致前文提到的“灾难性遗忘” 。
-
简单来说,过拟合(Overfitting) 是机器学习中的一种“死记硬背”现象。模型在训练集上表现近乎完美,但遇到没见过的测试数据时,表现却一塌糊涂。
1. 直观理解:学霸 vs. 刷题机器
-
正常学习:学生通过做题领悟了数学公式的推导逻辑,考试时遇到变体题也能解出来(泛化能力强)。
-
过拟合:学生把 100 道练习题的答案连同题目里的干扰数字(噪声)全部背了下来。一旦考试题目的数字变了,他就会按记忆里的答案乱填。
-
低维规律:假设数据的真实规律是一个简单的线性函数 $y = ax + b$。
-
高维拟合:过拟合的模型会试图用一个极高次的多项式(如 100 次方)去穿过每一个训练数据点。
-
后果:为了强行经过那些含有误差(噪声)的点,函数图像会变得剧烈抖动。在训练点之外的地方,函数值会发生巨大的偏离。
-
数据量太小:正如你提到的,数据量小于 100 条时,模型很容易记住每一个样本的特征,而不是学习通用逻辑。
-
模型太复杂:3B 或 7B 参数的模型拥有极强的拟合能力,如果没有约束,它能轻易“背下”所有训练集。
-
训练轮数(Epoch)过多:模型在训练集上反复“磨刀”,最后磨得太薄,失去了韧性。
-
噪声干扰:训练数据中包含错误或无关信息,模型把这些垃圾信息也当成了真理。
-
正则化(Regularization):在 Loss 函数中加入惩罚项(如 L1/L2 正则),约束权重不要太大。
-
Dropout:在训练时随机“关闭”一部分神经元,强迫模型不依赖特定路径,提高鲁棒性。
-
使用 LoRA:通过低秩约束减少可训练参数,天然限制了模型的“作弊”空间。
-
提前停止(Early Stopping):在验证集 Loss 开始反弹前及时收手。
-
例外情况:如果你的数据集非常小(比如只有几百条),为了让模型学会社交礼仪或特定格式(如 GRIT 中的坐标格式),可能会增加到 5-10 轮 。
然后我们说强化学习跟或者是DPO跟这个监督微调也就SFT之间,他们这一个数据格式有什么不同吗,为什么?
1. SFT(监督微调):单样本映射格式
SFT 的目标是极大似然估计(MLE),即让模型学会复现人类给出的“标准答案”。
-
数据结构:
Prompt (问题) + Response (标准答案) -
数学逻辑:模型学习 $P(y|x)$,即在给定 $x$ 的条件下,逐个 Token 预测 $y$ 的概率。
-
格式示例:
Instruction: “请计算图中有多少个鸡蛋。”
Output: “图中一共有 6 个鸡蛋。”
2. DPO(直接偏好优化):成对对比格式
DPO 不需要模型死记硬背,而是通过“二选一”让模型理解人类的偏好。
-
数据结构:
Prompt + Chosen (更好的回答) + Rejected (较差的回答) -
数学逻辑:利用隐含的奖励函数,增大 Chosen 的生成概率,同时压低 Rejected 的概率。
-
格式示例:
Prompt: “解释什么是马尔可夫链。”
Chosen: “马尔可夫链是一个状态转移模型,其核心是无记忆性...”
Rejected: “这是一种数学公式,非常复杂,我也解释不清楚。”
3. RL(强化学习/GRPO):采样与规则反馈格式
这是 GRIT 论文的核心。RL 阶段不需要人工标注的答案,而是需要一个判别标准(Reward Function)。
-
数据结构:
Prompt + Environment/Rule (判题逻辑/验证函数) -
数学逻辑:模型针对一个问题生成 $N$ 个不同的答案 $\{o_1, o_2, ..., o_N\}$,算法计算组内相对优势 $A_i$。
-
格式示例(以 GRIT 为例):
Prompt: “图中左侧的物体是什么?请给出坐标。”
采样输出:模型生成 5 条不同的推理链(有的带坐标,有的没带)。
反馈信号:
-
格式奖励:坐标是否符合
[x,y,x,y]格式? -
准确性奖励:最终答案是否被判题器判定为正确?
-
深度对比总结
为什么 GRIT 选择 RL 而非 SFT/DPO?
因为“锚定推理”(Grounded Reasoning)包含大量的坐标计算。如果用 SFT,人类很难手写出成千上万个精确的像素坐标;但如果用 RL,只需给出一个判题规则(例如:坐标框内是否包含目标物体),模型就能通过 GRPO 的组相对优势算法,在自我探索中进化出最准的坐标预测能力。
2. 为什么格式不同?(底层逻辑深度分析)
SFT:极大似然估计 (MLE)
-
逻辑:SFT 是在“模仿”。它告诉模型:看到 $X$,就必须背出 $Y$。
-
数学本质:拟合一个固定的条件概率分布 $P(y|x)$。
-
数据需求:因此它只需要一个“标准答案”。模型通过交叉熵损失函数,让自己的输出不断接近这个唯一的答案。
DPO:相对偏好学习
-
逻辑:DPO 不需要模型去死记硬背,而是让模型学会“分辨好坏”。
-
数学本质:利用两个答案的概率比值来优化。它告诉模型:相比于 Rejected,我更喜欢 Chosen。
-
数据需求:必须成对出现。如果只有一个答案,模型就失去了对比的基准,无法理解什么是“更好”。
RL (如 GRIT 中的 GRPO):自我探索与反馈
-
逻辑:RL 是在“进化”。模型针对一个问题生成 $N$ 个不同的答案(组采样),然后由环境(奖励函数)打分。
-
数学本质:最大化期望奖励。它计算组内相对优势 $A_i$,奖励那些表现拔尖的路径。
-
数据需求:它甚至不需要标准答案,只需要一个能判断对错的“规则”(比如 Python 脚本或判题器)。
-
在 GRIT 中:模型通过采样生成推理链,GRPO 根据答案准确率和格式合规性给予奖励信号,从而优化生成策略。
-
3. 三者的进阶关系
作为 11408 考研人,你可以这样串联理解:
-
SFT 是“打地基”:让模型先学会基本的说话格式和知识。它的数据最贵,因为需要人工标注高质量答案。
-
DPO 是“校准”:通过人类的偏好,让模型说话更符合人类的价值观或审美。它的数据是相对的。
-
RL 是“冲刺”:在特定任务(如 GRIT 的锚定推理)上,通过大量的自我模拟和硬性规则反馈,压榨出模型的逻辑极限。它的数据最便宜(只需问题和规则),但计算量最大。
1. DPO 与 SFT 的底层逻辑关系
在大模型(LLM)的生命周期中,它们扮演着完全不同的角色:
-
SFT (监督微调) 是“打基础”:
-
作用:让模型学会“说人话”和“守规矩”。
-
数据:使用高质量的问答对 $(Q, A)$。
-
结果:产生了一个初步具备指令遵循能力的模型。
-
-
DPO (直接偏好优化) 是“拔高/对齐”:
-
作用:在模型已经“会说话”的基础上,让它说出“更好的话”。
-
原理:通过对比(Chosen vs Rejected),让模型在多个候选答案中学会选择人类更喜欢的那个。
-
依赖性:DPO 不能直接跑在原始模型(Base Model)上,因为它需要模型先具备基本的语言表达能力。这就好比你不能教一个还没学会写字的孩子如何写出“优美”的文章。
-
2. LoRA 权重的“叠罗汉”架构
你提到的“合并顺序”其实描述了一个**增量更新(Incremental Update)**的过程:
第一步:基础模型 + SFT LoRA
-
物理意义:原始模型被贴上了一层“SFT 补丁”。这层补丁里记录了如何回答问题、如何生成
<think>标签和坐标等格式信息。 -
状态:此时的模型已经是一个合格的助手了。
第二步:SFT 模型 + DPO LoRA
-
物理意义:在 SFT 补丁的基础上,又贴了一层“DPO 补丁”。
-
为什么依赖? DPO 的训练目标是基于 SFT 模型的概率分布进行微调的。如果去掉了 SFT LoRA,DPO LoRA 就像一个失去了地基的阁楼,其内部记录的权重参数($\Delta W$)将完全无法与原始模型对齐,导致模型输出乱码。
3. 为什么要进行“最终合并 (Merge)”?
合并的本质是将这些 LoRA 补丁(低秩矩阵 $A \times B$)通过矩阵加法直接融合进基础模型的参数中:
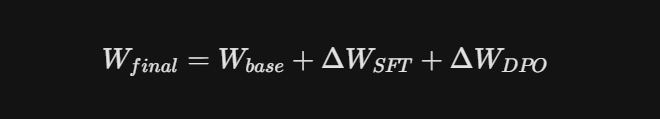
-
推理性能:如果不合并,推理时每一层都要多算两个矩阵乘法,速度变慢。
-
部署便捷:合并后,
model_c_merged就变成了一个单一的权重文件。它既记住了 SFT 教会的格式和知识,也记住了 DPO 优化后的逻辑偏好。
4. 整体框架总结
总结: DPO 是对 SFT 效果的二次精炼。你看到的 adapter_name_or_path 指向 SFT,就是为了告诉 DPO 算法:“请在这个已经懂规矩的模型基础上,继续教它如何变得更优秀。”
那么dpo它本质上是什么进行的?就是说他应该是在训练过程中,dpo算法它是怎么样去计算的流程?




另外一点是dpo的训练集要求是怎么样的格式。为什么大家发论文的时候都普遍青睐于强化学习里面的GRPO,而不是DPO算法呢?


dpo要求对比,一正一负,这种数据还需要蒸馏,ai
另外一点就是我们说人类偏好的强化学习,为什么叫人类偏好呢?
这是一个非常深刻的定义问题。作为 11408 考研人,你可以从计算机系统的“输入/输出”以及人工智能的“目标对齐(Alignment)”这两个维度来拆解。
之所以叫“人类偏好的强化学习”(Reinforcement Learning from Human Feedback, RLHF),核心原因在于:有些任务的“对错”无法用数学公式定义,只能由人来“感觉”。
1. 为什么需要“人类偏好”?(对比逻辑)
在传统的强化学习(比如 AlphaGo 或玩超级玛丽)中,奖励函数(Reward Function)是硬性的:
-
围棋:赢了就是 +1,输了就是 -1。
-
游戏:得分越高,奖励越高。
但在处理人类语言时,情况变得复杂了:
-
例子:如果用户问“如何写一首赞美春天的诗?”,电脑怎么判断模型写得好不好?
-
统计词频?(没用)
-
检查语法?(正确但不一定美)
-
-
结论:这种高度主观、涉及情感、审美和价值观的东西,无法写成
if-else代码。唯一能作为“判题官”的只有人类。
2. “偏好” (Preference) 的数学精髓:二选一
为什么叫“偏好”而不是“打分”?这涉及到了人类心理学和标注效率:
-
打分很难:让你给一个回答打分(1-10分),不同人的标准天差地别(有人手松,有人手严)。
-
对比很简单:给你两个回答 A 和 B,让你选哪个更好,人类的共识度极高。
-
数学转化:DPO 算法正是利用这种“A > B”的偏好关系,通过 Bradley-Terry 模型将其转化为模型概率的优化目标。
3. RLHF/DPO 的三个层级:从“人类”到“AI”
随着技术演进,“人类偏好”的内涵也在扩大:
-
真正的 RLHF:早期阶段(如 GPT-3.5),真的是雇佣成千上万的人类标注员,一行一行去勾选哪个回答更好。
-
RLAIF (AI 反馈):发现人太贵了,于是让更强的模型(如 GPT-4)去模仿人类的价值观进行标注。虽然是 AI 在标,但它的底层逻辑依然是模拟人类的偏好。
-
DPO 阶段:直接将这种偏好数据喂给模型,略过中间商(奖励模型),实现高效对齐。
4. 为什么 GRIT 这种论文更青睐“硬规则”?
在 GRIT 这种涉及**视觉锚定(Grounding)**的任务中,情况发生了变化:
-
坐标是客观的:一个框有没有框住鸡蛋,这是客观事实,不需要人类的“偏好”来判断。
-
GRPO 的逻辑:它被称为“强化学习”,但它在 GRIT 里更多是 RL from Rule Feedback(基于规则反馈的强化学习)。
-
因为在数学、代码、空间定位这些领域,“对错”比“好坏”更重要。
-
DPO 是“借强化学习之名,行监督学习之实”dpo不属于强化学习
1. 传统强化学习(RL)的“标准三件套”
在深度学习中,标准的强化学习(如 PPO 或 GRIT 中提到的 GRPO)必须具备以下三个核心组件,而 DPO 把它们全删了:
-
奖励模型 (Reward Model):需要一个额外的模型来给答案打分。
-
在线采样 (Online Sampling):训练过程中,模型需要不断地“试错”,实时生成大量随机答案。
-
策略梯度 (Policy Gradient):通过复杂的数学公式(如优势函数 $A_i$)来缓慢更新参数。
2. DPO 的本质:一个数学上的“捷径”
DPO 论文的核心贡献是推导出了一个数学恒等式。它证明了:如果你已经有了人类的偏好数据(A > B),你根本不需要去训练奖励模型,也不需要去进行在线采样。
-
数学代换:DPO 将强化学习的“最大化奖励”目标,通过数学变换,直接转变成了一个**二元交叉熵损失(Binary Cross-Entropy Loss)**问题。
-
分类器本质:在 DPO 的训练过程中,模型本质上是在做一个二分类任务——给定一个问题和两个答案,模型学习如何给“好答案”分配更高的概率,给“坏答案”分配更低的概率。


















虽然训练的时候用了八张A100的卡训练了100个小时,实际上用两张A100卡跑1天半就可以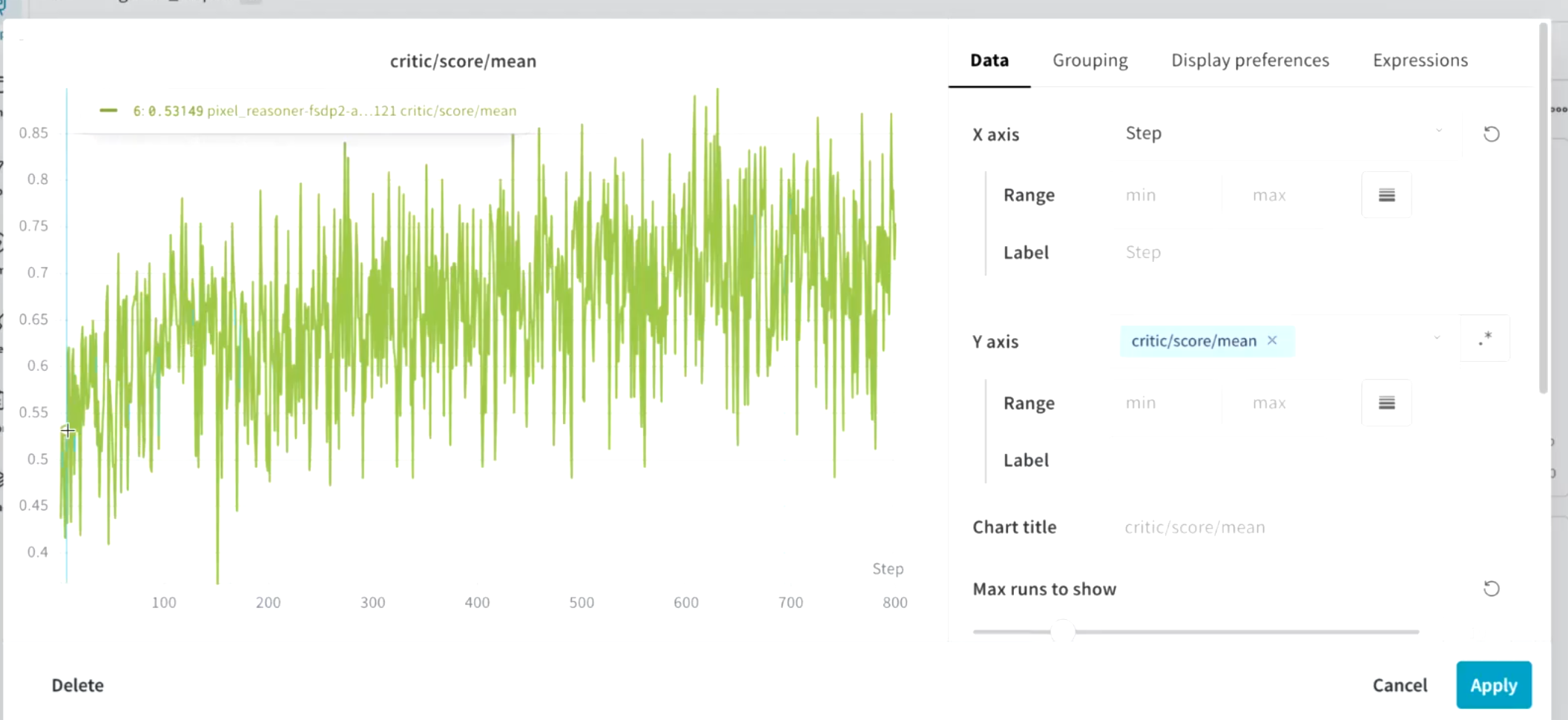 看这张图,在一开始经过sft训练后主要学习的是推理的格式,做的都是简单题,学的是think的格式,在强化学习阶段要提高的他的泛化能力能做难题,这时刚进入强化学习阶段模型需要一个磨合期,衔接一下从简单到难这种过渡期,然后作者就是说并没用说答对就对打错就错,这个时候奖励格式分的作用就来了,缓解了模型前期得不到分的尴尬,一开始答不对题但是模型还是能拿到格式分,前期大部分都是格式分,所以慢慢通过梯度下降的方式往能拿到格式的方向回答来拿到格式分。看到整体的趋势,总体上是平均分越来越高,但为什么他的波动程度这么大呢?因为强化学习本质上是探索,再没见过的题目上和难度高的题目上有对有错 ,在尝试过程中难免回答错,这很正常,为什么尝试多种解法,因为会让模型的温度为1,虽然这样可能有更多的幻觉,但会被我们的奖励分一直惩罚这样会减少幻觉的可能性,同时高温度可以头脑风暴,总会有一个没有尝试的解法然后找到正确答案,然后被强化,所以grpo这种算法总会用这种峰值的波动,但总体趋势是往好的方向去走
看这张图,在一开始经过sft训练后主要学习的是推理的格式,做的都是简单题,学的是think的格式,在强化学习阶段要提高的他的泛化能力能做难题,这时刚进入强化学习阶段模型需要一个磨合期,衔接一下从简单到难这种过渡期,然后作者就是说并没用说答对就对打错就错,这个时候奖励格式分的作用就来了,缓解了模型前期得不到分的尴尬,一开始答不对题但是模型还是能拿到格式分,前期大部分都是格式分,所以慢慢通过梯度下降的方式往能拿到格式的方向回答来拿到格式分。看到整体的趋势,总体上是平均分越来越高,但为什么他的波动程度这么大呢?因为强化学习本质上是探索,再没见过的题目上和难度高的题目上有对有错 ,在尝试过程中难免回答错,这很正常,为什么尝试多种解法,因为会让模型的温度为1,虽然这样可能有更多的幻觉,但会被我们的奖励分一直惩罚这样会减少幻觉的可能性,同时高温度可以头脑风暴,总会有一个没有尝试的解法然后找到正确答案,然后被强化,所以grpo这种算法总会用这种峰值的波动,但总体趋势是往好的方向去走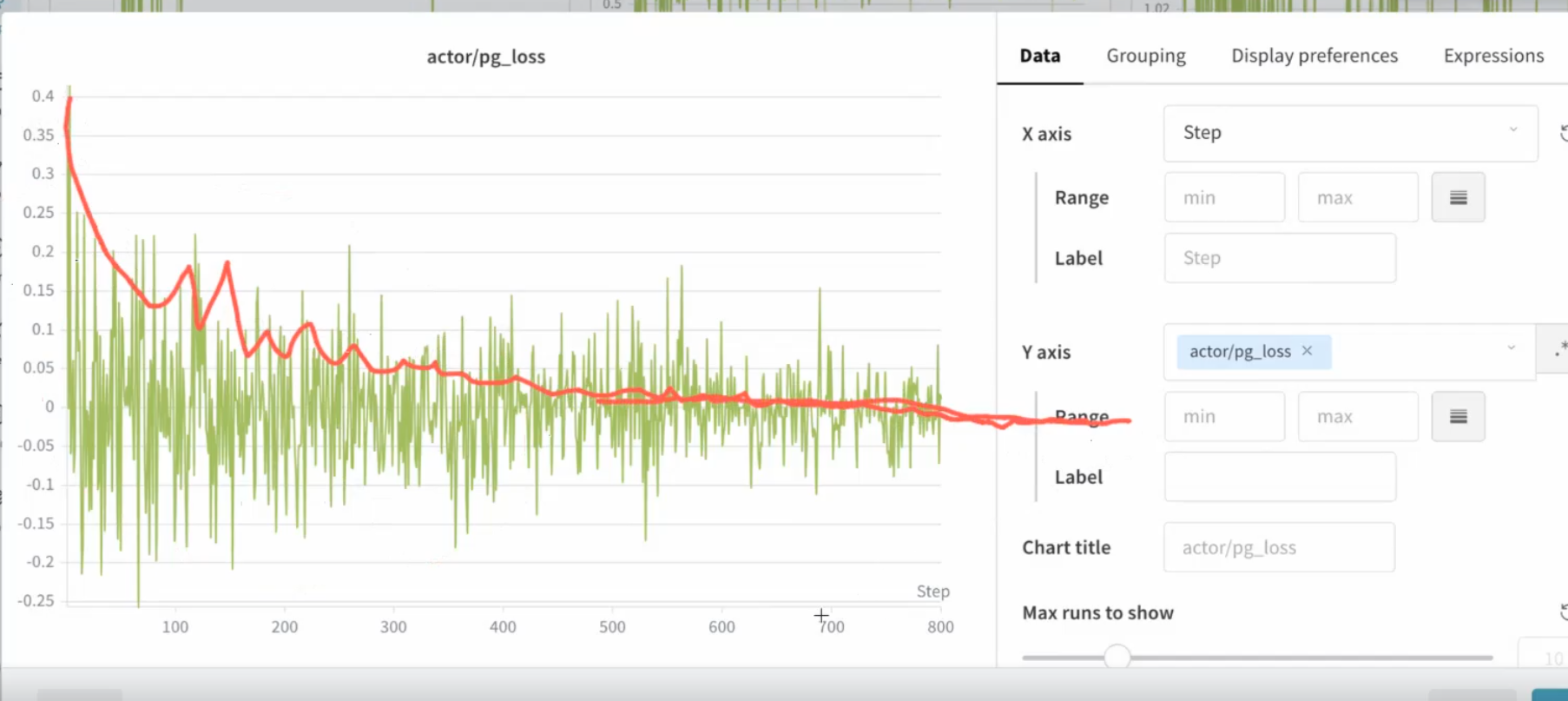
batch-size是32,loss按照红线收敛就这样说,step比较多,跑的比较久。大概训练了800步,因为batch-size比较小,算力比较小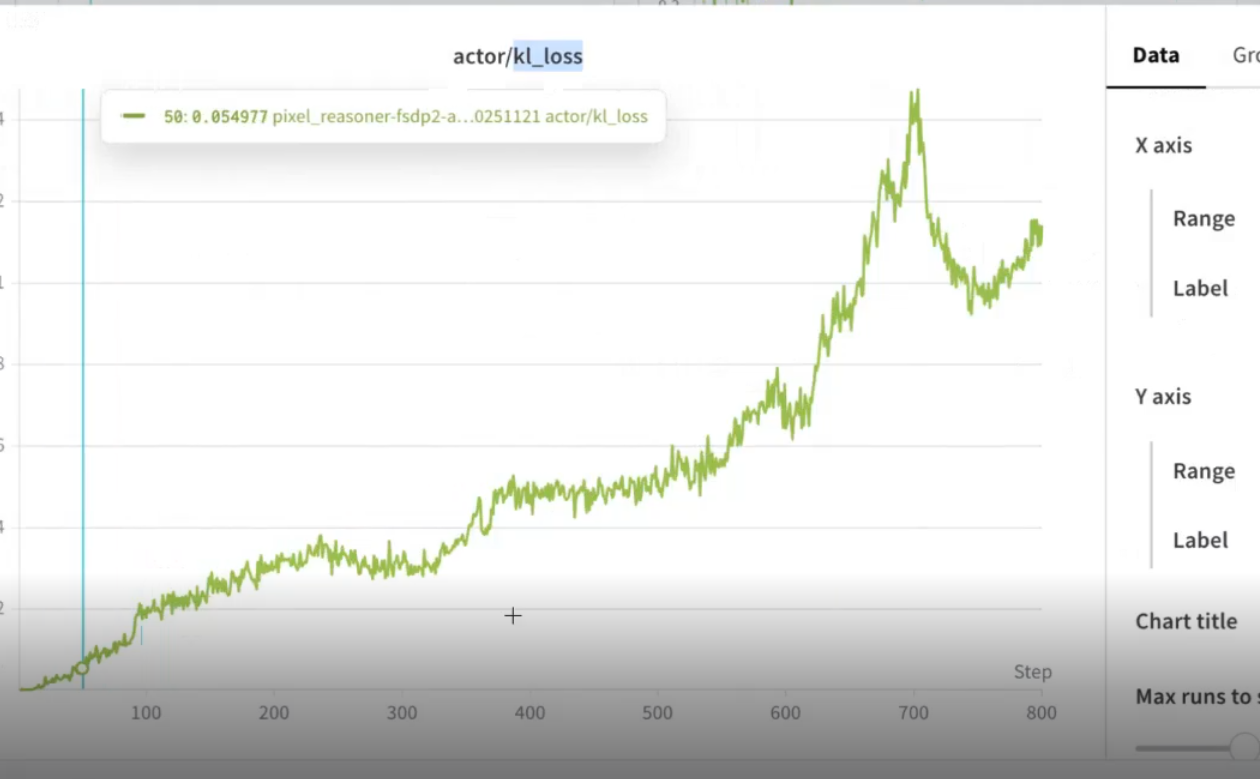
kl散度本质上就两个概率分布做一个距离比较,越大代表差异性越大,最后看到这个散度下降了,其实就是探索,当模型有点走火入魔了可以拉回来导致他下降,后面趋向于平衡
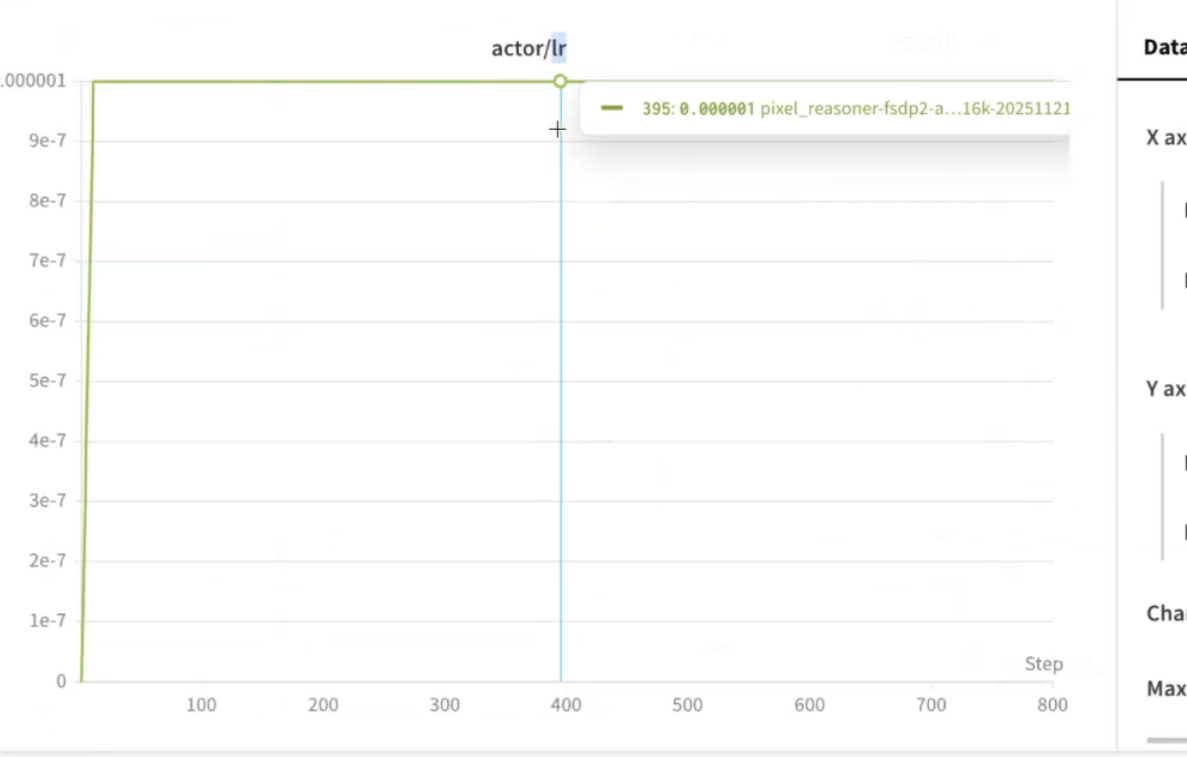
学习率是动态改变的,是由框架动态调整的
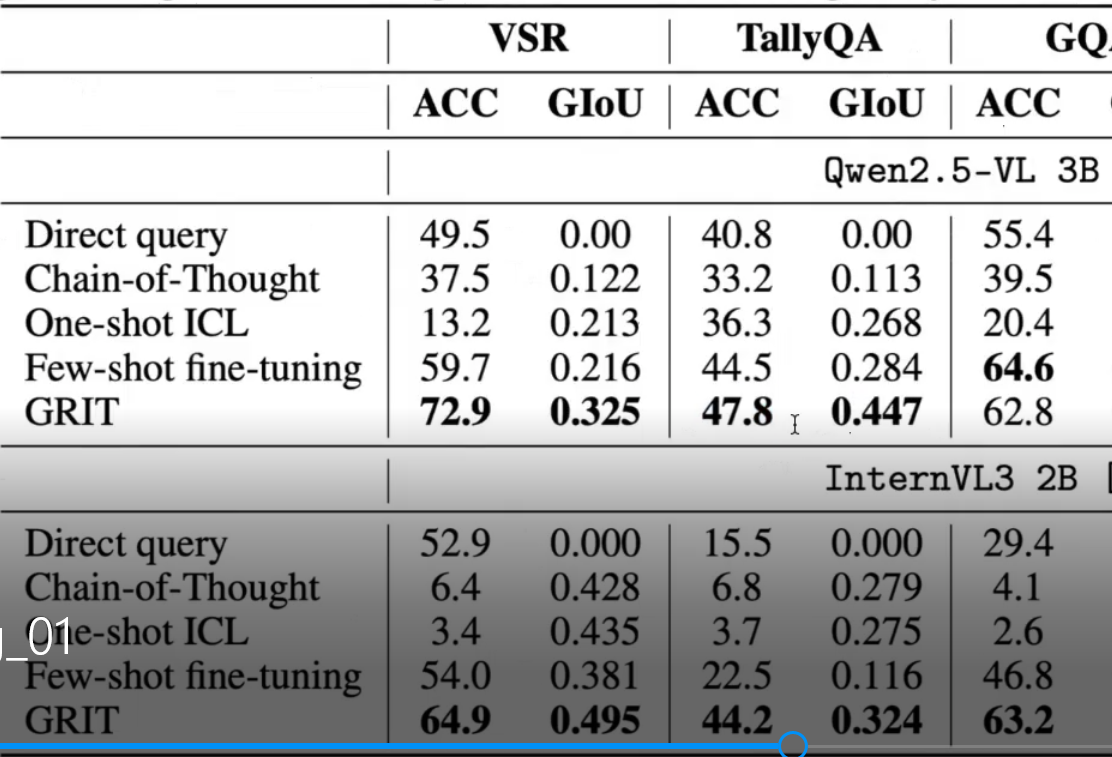
这里的准确率47.8写到44左右,因为我们卡相对作者少,batch小,我们是32,而作者128,batch越大他就能在一个batch里面进行一个相互的学习,有一个对比的过程,batch小的时候样本就少,太小的问题就是训练非常的慢,太大就很耗算力也提升不了太多,所以batch要保持平衡吗,这里的准确度用的是@1
然后这里准确率47.8其实没太多用,因为作者用的是3B的模型,3B和7B的模型就是幼儿园和小学生的差别,还是比较大的,这里作者主要是通过强调少量的样本就能达到比较好的效果 。用3b算力少不用训练那么久,投机取巧,作者的意思就是只要能达到效果就可以

像这种图片,模型的能力是不够的,需要更加前沿的方法才能实现更加准确的计数,这样训练格式是做不到的,只能说说靠的模型在他预训练时赋予的能力,只是通过在强化学习的阶段把这种能力激发出来,回忆出来,并没有新的手段,只是激发和回忆他的数学能力, 所以想提高他的准确率除了提高模型的参数,还有就是就是用智能体的方法,让模型学会调用工具,比如图像修复,比如让模型更加清晰,现在这个论文主要是用少量数据激发模型更加好的推理能力
名称:基于视觉语言大模型图像目标计数
背景:原本大语言模型图像理解尤其是在计数方面有一些欠缺,第一点模型对于计数的时候往往会把两个目标融为一体,比如把那两个斑马看成一个,第二点时模型并不能逐步推理或者是有一个可解释性的过程(模型的答案是3正确答案是3但是这个答案是模型碰巧做对的还是真正会的,我们需要看到模型的解题过程,但传统的llm除非说你在给的问题上说需要这种逐步推理可解释过程,我们需要模型带着准确的格式和模板带着问题同时兼顾可解释性),第二点也引出了模型有一个回答问题的模板就好了。第三点是现有的小参数模型比如这个3B这个模型在这个目标计数的领域上特别的差,现在又有很多的agent的模型,利用复杂的工具调用的逻辑提高模型在计数上的正确率,虽然很好,但是计算量是非常的大,提出一个在资源受限,比如算力不足,数据集很少的情况下能够在小模型也能够得到比较好的准确率
如何实现?
首先了收集了数据集,按照人类的习惯比如第一个鸡蛋在那个坐标,第二个。。。这样模型就不会遗漏,对于大模型模型是符合人类偏好的,这是模板的问题这种think的方式需要合成,用教师模型gpt或者是qiwen-72b-256b模型都可以,即蒸馏。怎么去合成设计呢,就是通过调用教师模型的api来蒸馏一些带有这些think过程的思维链的数据来充当我们sft的训练集,用sft来学习这个套路,得到这些数据集之后需要清洗,有一些教师模型得到的答案不一定是对的,保留对的,sft对这个清洗后的数据进行训练,用的是llma-factory的框架,因为本论文数据集少,sft只用训练一个epoch就可以了,因为训练多了对导致模型过拟合我们只让他记住他的格式并不是让他记住他的题目,因为sft主要就是学习推理的模板,实际让他计数是不行的,我么也尝试过用sft后的模型在一些测试集上去做只有少量的提升,提升不高
然后做rl,拿一些难一点的题,如何衡量难题和简单题,通过筛选或者原有的数据集比如说在训练的时候有一些数据集是特地人工收集的 从hugingface上拿到这种原题,只是把这种原题加了一个思维链,比如说搜集了简单的给到sft,难一点的题给到rl
我们这里的分类的简单题和难题,我不太理解是我理解的是sft做简单题可以但是做难题不太行,所以我们用了强化学习,但是在这个项目为啥我们要分难题和简单题,我们最主要的目标是看到效果,所以用的数据集不一样都是一样吗,就是统一用难题给到sft和rl,然后去对比他们的效果就好了,不应该这样吗?就是其实直接从hugingface上直接拿过来的吧,是我们自己人工识别难题和简单题吗?
就是你看,监督微调跟GRP算法它算是两个不同的阶段,对不对?每个阶段它都要输入数据集的。那么在监督微调的时候,我们是输入筛选过后比较简单的题目的。然后另外,你训练完这个模型,也就是在训练完这个监督微调这个阶段之后,是不是又得对这个模型继续再次进行强化训练啊?那么在这个强化学习训练的时候,你也得再输入一个新的数据集给他,那么这个数据集就是我们筛选出来比较难的题
我之前自己也说过,因为你我们说监督微调的本质上就是学一些推理的格式啊,也就是思维链对吧,他就是学习这个的,他本身就是模仿学习另外一个。你要想想既然他只是学习他的推理的套路跟做题的模板,是不是就不要求他说一定要做会难题之类的对不对?另外就是第一个模型,它一开始如果是对一些没有做过的领域的题的话,它是很难收敛很难学习的。我们既然我们说监督微调只是要他学一个简单的套路,也就是思维链这种格式,那是不是只要给他简单题就行了?这样的话,又可以快速训练收敛,也能达到我们的要求。那么第2个为什么要上难题呢?是因为我们说你做简单题很容易就做对,但是它只是仅限于帮助你快速学习这些格式
那么,你既然强化学习本质上就是要提高泛化能力,是不是要出难题?是不是就要借助你在监督微调上学习到的一些做题的套路,还有格式用来做题会好一些啊?所以,就这样子的
所以为什么我们就说监督微调用的是简单题,强化学习用的是比较难一点的题
所以,就是难题给强化学习,简单题给监督微调。而不是两个数据集混在一起,先输入给监督微调,然后又两个混在一起,又输入给GRPO,不是这样子的
所以就是用简单的题目的数据去训练模型,让模型具备一定的能力,然后开始强化学习,这个时候我们拿难题的数据集给到模型进行强化学习
数据集合成,sft,rl,强化学习用的grpo不需要思维链,我们准备两款数据集,一个是带有思维链的简单问题专门用来学模板的,第二个是专门拿来给强化学习用的不需要思维链,只需要最终答案就可以了 ,
结果:我们在vsr,tallyqa,gqa三个测试集上评估,我们均得到了相比原本的千问模型得到了一定的提升,要解决一个问题为什么要选这三个数据集,hugingface上有这个三个数据集在线预览
要解决的问题:既然模型能力得到提升,但是还是有一些问题做不对?第一个是原本的千文模型3b参数小,推理能力有上限,算力受限如果在7b上应该会大幅上涨,但是上涨多少我们不知道,算力有限
第二点是我们完全没有依靠智能体工具来间接提升模型推理的能力,完全是原生的千文的模型,只是用rl激发它原有的能力
第三点是数据集尤其是tallyqa太难了,特别是一大一小的很容易让模型误导,模型本身抗干扰能力不足,可能只看到大的没看到小的,另外一点是颜色干扰,模型容易被干扰
如何解决呢?提高模型的参数大小,提高数据集的规模,我们这里的数据集是few-shot就是用很少量的数据就能得到很大的提升。未来可以介入智能体相关的工具,使用工具调用来提高模型推理能力的上限
数据集:我们先从网上搜集一些数据,从hugingface上拿到的开源的数据集,找到coco的数据集,coco数据集是什么?coco本身就包含问题和答案这种计数的,也有人分类了简单和难的数据,就直接照搬用了,但为了得到思维链,当然这个数据只用问题和答案和图像, 此时没用think的模板,我们用llm蒸馏,调用教师模型,用了qiwen72b的模型,调了api,得到think的模板,然后进行清洗就完事了,然后作为sft的的训练集,
强化学习阶段只是准备好了强化学习的训练集,设置了奖励函数,格式分和最终奖励得分,简单又简单的好,约束越多限制了解空间,让模型自由的学,格式奖励不需要太负责,所以rl我们只改了
学习率怎么调出来的?llma-factory学习率只用设置一个默认的初值,会自动自适应的调整,一般3b或者7b都有最优的初始学习率。0.001
sft的epoch一般不能超过3次,设置两次是最好的,
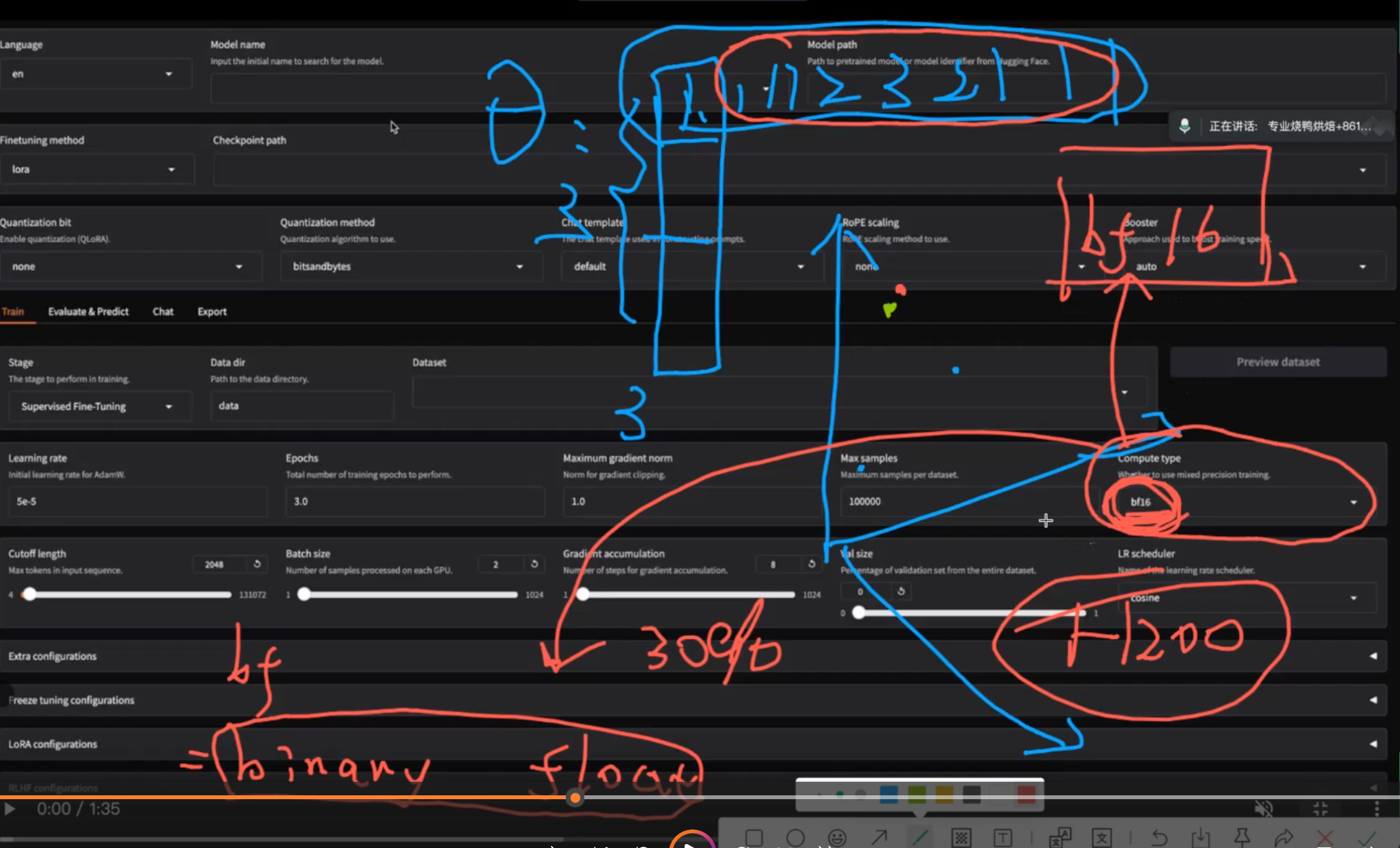
精度要用bf16,混合浮点数,默认bf16不用改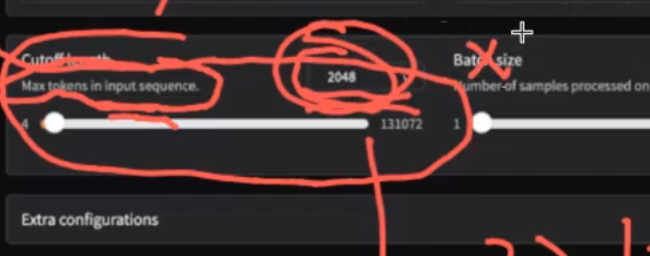
用2*2048个token就可以了,这个参数是每次处理的token数量。模型如果输出了超过这个范围就被截断了
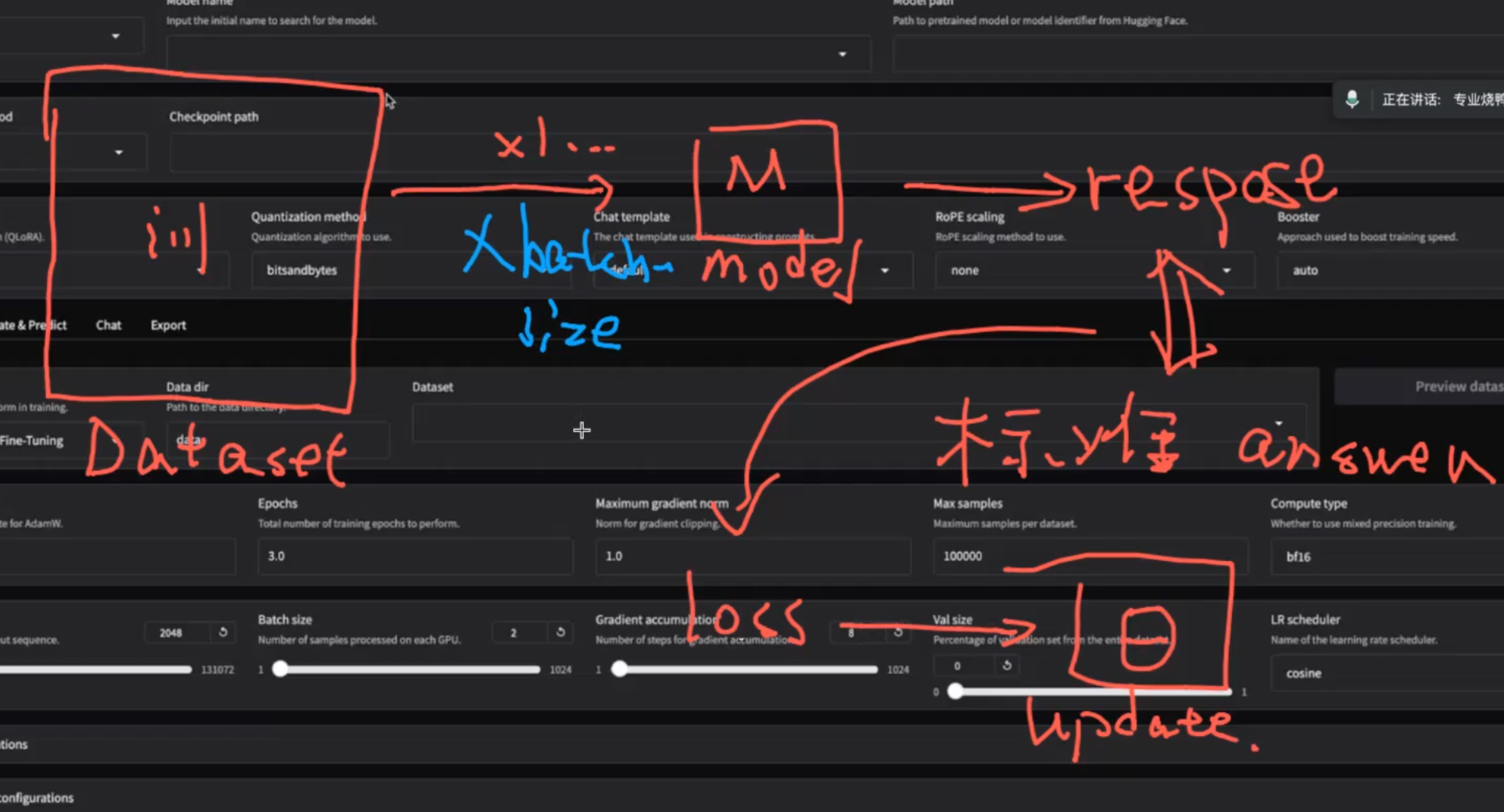
一次性从数据集里拿出一批次(batch-size)个数据训练,同时训练对答案修改,提高效率
但是batch-size不能调大,16就可以,局限算力瓶颈,但是太大不太好,会导致学的走火入魔
训练集和验证集8:2比较好 首先对数据集分难度,简单的数据集给到sft,分类好把简单的给教师模型蒸馏出来思维链出来扩充为具有思维链的数据集,这时候才会变成sft所需要的数据集
首先对数据集分难度,简单的数据集给到sft,分类好把简单的给教师模型蒸馏出来思维链出来扩充为具有思维链的数据集,这时候才会变成sft所需要的数据集
强化学习不需要思维链,也不需要纠正他必须这样思考,奖励函数会给他一个监督信号让他既能作对答案又能作对格式方式走
蒸馏是源于deepseek提出来的,以前是申请一个api或者本地部署一个厉害的模型,比如qiwen的2.35b,但是再厉害的模型难免有不稳定的时候但如果把模型总是作对的思路学习起来,去其糟粕取其精华。就是给出输入问题给到模型或者api之后得到一个输出思维链和最终答案,然后清洗错误的,得到的数据输入sft训练集的候选名单
这个是强化学习用的框架,verl已经封装好ppo,dpo,grpo的方法,我们这个项目只修改了grpo的奖励函数和超参数,超参数是一个问题采样八次,batch-size设置为128,初始学习率0.001,epoch3步
这个奖励函数怎么修改呢?可以理解为这个框架已经预先留给你空位了,专门再有一个地方写奖励函数的代码,reward(接受模型给的回复),得到模型给的回复要检验格式,引入一个评估模型可以是本地部署的,输入模型给到reponse,然后给到一个提示词要按照什么什么要求检验,看一下是不是符合这个格式的,是就是√。。。对的就给0.5错的就是0分,reward里有标准答案,response里也夹杂了他得到的答案,和我们的标准答案去匹配,相当于字符串的匹配,匹配成功给0.5不成功给0,然后return回去让模型自己做梯度下降,用verl这个框架很方便,grpo的代码不需要写,这个奖励函数在verl是如何修改,这个引入评估模型是怎么引入呢?考试可以这样说吗?这个引入评估模型就是找一个大模型做我们的需求即可
这里说彻底免除对昂贵的密集推理链和边界框标注数据的依赖?通过蒸馏的到我们的需求
然后sft的训练没有用到lora那用的是什么呢?因为我看llma里面有个微调方法我看课上默认的是lora?这里因为只用了3b的模型算力有限,数据也少参数少,所以全参数微调即可
两张卡来跑,是在atodl租卡吗,一般租不是租一张卡吗,用两张卡step我就800步,而论文八张卡用200步,2张卡跑三天强化学习,而监督微调就跑了一天
他有了这个之后是不是以后做的题会更就是会更加得心应手一点,相比于没有背模板来说,强化学习之前铺垫sft就是让模型能够在一些比较好的套路或者是模板上能够更好的去得到解决的方法和答案,就这么一回事的。模型如果不先做sft那如果直接开始 RL,由于初始模型生成的坐标全是随机的乱码,它几乎永远拿不到格式奖励 (rformat) 或准确性奖励 (rans)。这就像让一个还没学会写字的孩子直接去参加高考并根据分数自学,这里就是先蒸馏在sft在强化学习,sft和强化学习做的对比就是只做了sft和在sft的基础上做了强化学习
GRIT 具备极致的数据效率,仅需从现有数据集抽取 20? 个图像 - 问题 - 答案三元组即可完成训练,这现有的20个数据集是直接从hugingface上收集的是吧,我们先从网上搜集一些数据,从hugingface上拿到的开源的数据集,找到coco的数据集,coco数据集是什么?coco本身就包含问题和答案这种计数的,也有人分类了简单和难的数据,就直接照搬用了,但为了得到思维链,当然这个数据只用问题和答案和图像, 此时没用think的模板,我们用llm蒸馏,调用教师模型,用了qiwen72b的模型,调了api,得到think的模板,然后进行清洗就完事了,然后作为sft的的训练集,


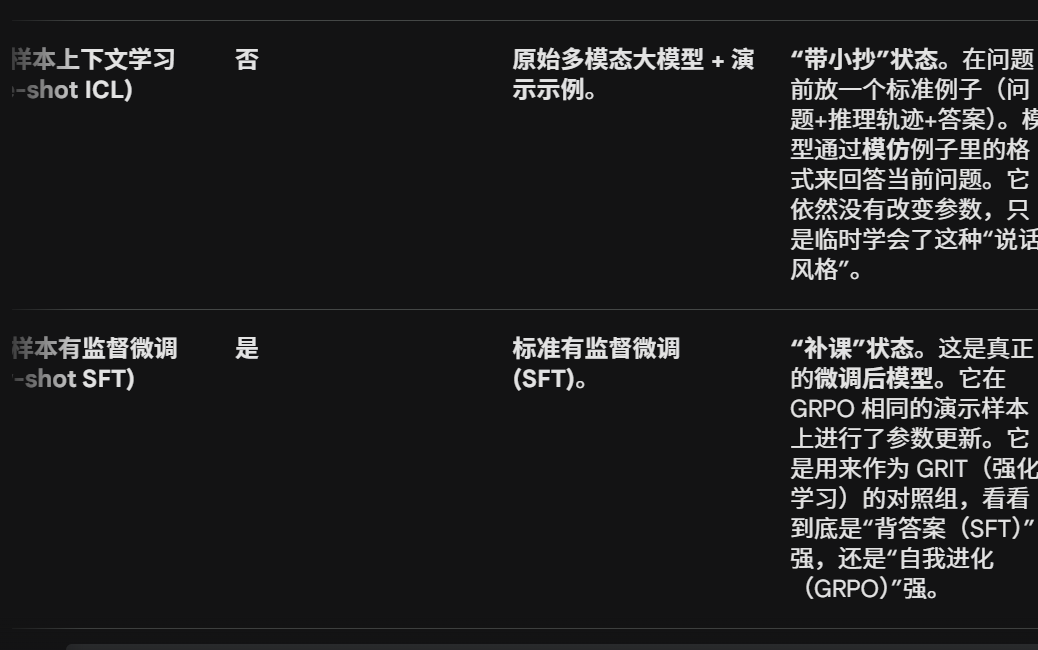
2. 深度分析:它们是如何得到的?
这些基线模型的设置是为了形成一个严密的**消融实验(Ablation Study)**链条:
-
从 1 到 2:测试“提示词”是否有用。如果 2 比 1 好,说明模型需要引导才能发挥推理潜力。
-
从 2 到 3:测试“格式模仿”是否有用。One-shot 提供了具体的锚定思维轨迹,看看模型能不能现学现卖。
-
从 1/2/3 到 4:测试“固定参数更新”是否有用。SFT 让模型把这种推理格式彻底“记在脑子里”,而不是靠临时提示。
3. 核心差异点:为什么要对比 SFT?
在图片 1 中提到,GRIT 训练只需要 67 秒 且只有 9 步更新。
-
Few-shot SFT (第4类):代表了传统做法。由于数据量极小(仅 37 条),SFT 非常容易导致过拟合(我们之前分析过),模型可能只学会了复读那 37 条数据的答案。
-
GRIT (强化学习版):虽然也只用了这些数据,但通过 GRPO 的组内竞争和结果监督,模型学到的是通用的“画框+思考”的逻辑能力,而不是死记硬背。
考研人的架构总结
-
1、2、3 都是在 OS 层(提示工程)做文章,没有动 硬件/底层代码(模型参数)。
-
4 是直接修改了 二进制文件(参数微调),但因为改动数据太少,系统可能变不稳定(过拟合)。
一句话总结: 除了第 4 类(Few-shot SFT)是真正改了模型“大脑”的,前三类都是在教模型“怎么组织语言”。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)