深入浅出目标检测损失函数:从 CE/L1 到 FL/GFL/DFL
本文将从最基础的交叉熵损失(CE)和 L1 损失讲起,逐步深入到 Focal Loss(FL)、Generalized Focal Loss(GFL)及其核心组件 Distribution Focal Loss(DFL),最后结合 YOLOv8 的工业级代码实现,帮你彻底搞懂目标检测损失函数的演进脉络与实际应用。
本文将从最基础的交叉熵损失(CE)和 L1 损失讲起,逐步深入到 Focal Loss(FL)、Generalized Focal Loss(GFL)及其核心组件 Distribution Focal Loss(DFL),最后结合 YOLOv8 的工业级代码实现,帮你彻底搞懂目标检测损失函数的演进脉络与实际应用。
目录
- 引言:目标检测的两大核心任务
- 基础损失函数:CE 与 L1
- Focal Loss(FL):解决分类样本不平衡
- Generalized Focal Loss(GFL):FL 的扩展版
- YOLOv8 代码实战:DFL 与 BboxLoss 的实现
- 延伸阅读:其他 IoU 变体与端到端检测
- 总结与参考资料
引言:目标检测的两大核心任务
目标检测的本质是同时完成两个任务:
- 分类(Classification):判断 “是什么”(比如是猫还是狗);
- 定位(Localization):判断 “在哪里”(用边界框
(x1,y1,x2,y2)表示)。
损失函数就是用来衡量 “模型预测” 和 “真实标注(GT)” 之间差距的指标,通过优化损失函数,模型才能不断学习提升。
基础损失函数:CE 与 L1
这是目标检测最基础的两个损失函数,分别对应分类和定位任务。
1. 交叉熵损失(Cross Entropy Loss, CE)
用途:分类任务,衡量 “预测概率分布” 和 “真实标签分布” 的距离。公式(单分类任务简化版):
![]()
其中:
- C 是类别数;
- yi 是真实标签(0 或 1,one-hot 编码);
- pi 是模型预测的第i类概率。
例子:如果真实标签是猫(第 0 类,y0=1),模型预测猫的概率p0=0.8,则
![]()
2. L1 损失(Mean Absolute Error, MAE)
用途:回归任务,衡量 “预测连续值” 和 “真实连续值” 的绝对差。公式:
![]()
其中:
- ygt 是真实值(比如 GT 框的坐标);
- ypred 是模型预测值。
Focal Loss(FL):解决分类样本不平衡
背景
一阶段检测器(如 YOLOv1-v3)中,正负样本比例极度悬殊(比如 1:1000):
- 正样本:包含物体的框,数量很少;
- 负样本:背景框,数量极多。
大量简单的负样本会主导损失函数,导致模型学不到正样本的特征。
核心思想
在 CE 的基础上,加一个调制因子(1−pt)γ,让模型:
- 自动降低简单样本的损失权重(比如容易分类的背景);
- 更关注难样本的损失(比如模糊的物体)。
公式
![]()
其中:
- pt:模型对真实类别的预测概率(正样本pt=p,负样本pt=1−p);
- (1−pt)γ:调制因子,γ越大,对简单样本的抑制越强(通常γ=2);
- αt:平衡正负样本的权重(通常α=0.25)。
与 CE 的关系
当γ=0时,FL 就退化为 CE,因此FL 是 CE 的改进版。
参考资料:Focal Loss 原始论文 Focal Loss for Dense Object Detection
Generalized Focal Loss(GFL):FL 的扩展版
FL 只解决了分类的样本不平衡,但目标检测还有两个核心问题:
- 分类与定位不一致:分类置信度高的框,定位不一定准(IoU 低);
- 回归的模糊性:直接用 L1 回归连续坐标,忽略了边界的不确定性(比如遮挡、运动模糊)。
GFL 把 FL 的思想从 “离散分类” 扩展到 “连续标签”,分为两个子损失:
- Quality Focal Loss(QFL):处理 “分类 + 定位质量” 的联合预测;
- Distribution Focal Loss(DFL):处理 “边界框回归” 的分布预测。
参考资料:GFL 原始论文 Generalized Focal Loss: Towards Efficient Representation Learning for Dense Object Detection
1. Quality Focal Loss(QFL):分类与定位质量对齐
核心思想
把分类标签从 “离散的 0/1” 改成 “连续的质量分数s”(比如用预测框和 GT 的 IoU 作为s),让模型同时学习 “是什么” 和 “准不准”。
公式
![]()
其中:
- s:连续的质量标签(0≤s≤1,比如 IoU);
- p:模型预测的质量分数;
- ∣s−p∣β:调制因子,让模型更关注质量预测不准的样本。
2. Distribution Focal Loss(DFL):用分布建模回归
这是 GFL 的核心创新,也是现代检测器的常规配置。
核心思想
把边界框的连续坐标偏移量(比如预测点到 GT 框左边界的距离l)离散化为一个概率分布,用交叉熵让预测分布对齐 GT 分布。
具体步骤
- 离散化偏移量:假设偏移量范围是[0,16],分成 17 个 bin(对应整数0,1,...,16);
- 构造 GT 分布:如果 GT 偏移量是3.2,则:
- 整数部分i=3,小数部分j=0.2;
- GT 分布:P(3)=0.8,P(4)=0.2,其他 bin 概率为 0;
- 计算 DFL Loss:用交叉熵让预测分布对齐 GT 分布:
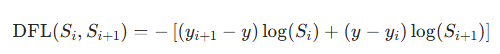
- 推理时还原坐标:用预测分布的期望(加权求和)得到最终坐标:lpred=∑i=016i⋅pi
与 L1 的关系
DFL用 CE 替代了 L1:
- 传统回归:用 L1 直接优化 “坐标值的差”;
- DFL 回归:用 CE 优化 “坐标分布的对齐”,精度更高,尤其是对小目标和模糊边界。
YOLOv8 代码实战:DFL 与 BboxLoss 的实现
我们结合 YOLOv8 的工业级代码,拆解 DFL 的实际应用。
参考资料:YOLOv8 官方代码库 ultralytics/ultralytics
1. bbox2dist:GT 框到偏移量的转换
这是连接 GT 标注和 DFL Loss 的关键桥梁,作用是将 GT 框从绝对坐标(x1,y1,x2,y2)转换为相对于预测中心点的偏移量(l,t,r,b)。
import torch
def bbox2dist(anchor_points, target_bboxes, reg_max):
"""
将GT框(x1,y1,x2,y2)转换为相对于anchor_points的偏移量(l,t,r,b)
:param anchor_points: 预测中心点,形状[N, 2]
:param target_bboxes: GT框,形状[Batch, N, 4]
:param reg_max: DFL偏移量的最大范围
:return: target_ltrb,形状[Batch, N, 4]
"""
# 拆分GT框坐标
gt_x1, gt_y1, gt_x2, gt_y2 = target_bboxes.chunk(4, dim=-1)
# 拆分预测中心点坐标
anchor_x, anchor_y = anchor_points.chunk(2, dim=-1)
# 计算四个偏移量:l(左)、t(上)、r(右)、b(下)
left_dist = anchor_x - gt_x1
top_dist = anchor_y - gt_y1
right_dist = gt_x2 - anchor_x
bottom_dist = gt_y2 - anchor_y
# 拼接偏移量并限制范围(防止超出DFL的bin区间)
target_ltrb = torch.cat([left_dist, top_dist, right_dist, bottom_dist], dim=-1)
target_ltrb = target_ltrb.clamp_(min=0, max=reg_max)
return target_ltrb
关键细节:
- 偏移量是小数:因为 GT 框和 anchor_points 的坐标都是浮点数(归一化 / 缩放后),差值自然是小数;
clamp限制范围:确保偏移量在 DFL 的离散化 bin 区间内。
2. DFLoss:分布焦点损失的计算
严格对应 DFL 的数学公式,计算预测分布和 GT 分布的交叉熵。
import torch
import torch.nn as nn
import torch.nn.functional as F
class DFLoss(nn.Module):
"""Distribution Focal Loss (DFL)的实现"""
def __init__(self, reg_max=16) -> None:
super().__init__()
self.reg_max = reg_max # DFL偏移量的最大离散范围
def __call__(self, pred_dist, target):
"""
计算DFL Loss
:param pred_dist: 模型预测的分布,形状[N, reg_max]
:param target: GT偏移量,形状[N, 4]
:return: DFL Loss,形状[N, 1]
"""
# 步骤1:限制target范围,防止超出bin区间
target = target.clamp_(0, self.reg_max - 1 - 0.01)
# 步骤2:拆分GT为左bin(tl)和右bin(tr)
tl = target.long() # 整数部分,比如3.2→3
tr = tl + 1 # 整数部分+1,比如3.2→4
# 步骤3:计算左右bin的权重(对应GT分布的概率)
wl = tr - target # 左bin权重,比如3.2→0.8
wr = 1 - wl # 右bin权重,比如3.2→0.2
# 步骤4:计算DFL Loss(交叉熵+权重加权)
return (
# 左bin的交叉熵×权重
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
# 右bin的交叉熵×权重
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True) # 对4个坐标(l/t/r/b)的loss取平均
关键细节:
reduction="none":保留每个样本的独立 loss,方便后续加权;.mean(-1):对最后一维(4 个坐标)取平均,让 4 个坐标的 loss 贡献更均衡;keepdim=True:保持维度为[N, 1],方便后续和weight相乘。
3. BboxLoss:CIoU 与 DFL 的组合
YOLOv8 的边界框损失同时优化框的整体形状(CIoU)和边界的分布精度(DFL)。
class BboxLoss(nn.Module):
"""边界框损失:CIoU Loss + DFL Loss"""
def __init__(self, reg_max=16):
super().__init__()
self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else None
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""
计算边界框损失
:param pred_dist: 模型预测的坐标分布
:param pred_bboxes: 还原后的预测框
:param anchor_points: 预测中心点
:param target_bboxes: GT框
:param target_scores: GT质量分数
:param target_scores_sum: 质量分数总和(归一化用)
:param fg_mask: 前景掩码(标记正样本)
:return: loss_iou(CIoU损失), loss_dfl(DFL损失)
"""
# 步骤1:计算损失权重(用质量分数加权)
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
# 步骤2:计算CIoU Loss(优化框的整体形状)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# 步骤3:计算DFL Loss(如果启用)
if self.dfl_loss:
# 将GT框转换为偏移量
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1)
# 计算DFL Loss
loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
关键细节:
- 质量分数加权:让更准的样本权重更大,引导模型关注高质量正样本;
- 前景掩码
fg_mask:只在正样本上计算损失,避免无效计算。
延伸阅读:其他 IoU 变体与端到端检测
1. 其他 IoU 变体
除了 CIoU,还有很多 IoU 变体可以优化边界框回归:
- GIoU:解决 IoU 为 0 时无法优化的问题;
- DIoU:加入中心点距离,加速收敛;
- PIoU:考虑像素级重叠,对旋转框和小目标更友好;
- Inner-IoU:只计算框内部的重叠,减少背景干扰。
在 YOLOv8 的代码中,你可以轻松替换这些 IoU 变体:
# 替换CIoU为PIoU
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, PIoU2=True)
2. 端到端检测:DETR 与 YOLOv10
传统检测器需要 NMS 后处理去重,而端到端检测器(如 DETR、YOLOv10)通过集合预测和二分图匹配,直接输出唯一的预测框,不需要 NMS:
- DETR:用 Transformer 的自注意力机制,让预测框之间 “互相看见”,避免重复;
- YOLOv10:用双向分配(训练时一对多 + 一对一,推理时一对一),既保留收敛快的优点,又实现无 NMS 推理。
总结与参考资料
总结
目标检测损失函数的演进是问题驱动的:
- CE/L1:基础的分类和回归损失;
- FL:解决分类样本不平衡;
- GFL:扩展 FL 到连续标签,QFL 解决分类与定位不一致,DFL 用分布建模回归;
- YOLOv8:组合 CIoU(整体形状)和 DFL(边界精度),实现高效精准的边界框学习。
参考资料
- Focal Loss 论文:Focal Loss for Dense Object Detection
- GFL 论文:Generalized Focal Loss: Towards Efficient Representation Learning for Dense Object Detection
- YOLOv8 官方代码:ultralytics/ultralytics
- DETR 论文:End-to-End Object Detection with Transformers
- YOLOv10 论文:YOLOv10: Real-Time End-to-End Object Detection
你对目标检测损失函数的哪个部分最感兴趣?或者有什么问题想讨论?欢迎在评论区留言!如果觉得本文对你有帮助,别忘了点赞、收藏、关注哦~

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)