BEVFusion:多任务多传感器融合的统一鸟瞰图表示框架
本文是对论文《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation》的深度解读。在自动驾驶感知领域,多传感器融合面临几何失真与语义损失的双重挑战。MIT 团队提出的 BEVFusion 框架,创新性地将多模态特征统一到共享鸟瞰图空间,通过优化 BEV 池化实现 40 倍效率提升,兼
一、引言
在自动驾驶领域,精准可靠的环境感知是实现安全行驶的核心前提,而多传感器融合技术则是提升感知性能的关键。自动驾驶车辆通常搭载多种传感器,例如 Waymo 的自动驾驶汽车配备了 29 个摄像头、6 个雷达和 5 个激光雷达(LiDAR)。不同传感器各具优势:摄像头能捕捉丰富的语义信息,LiDAR 可提供精确的空间几何信息,雷达则擅长即时速度估计。这些传感器数据互为补充,为全面感知周围环境提供了基础。
然而,不同传感器的数据模态存在本质差异:摄像头采集的是透视视图数据,LiDAR 输出的是 3D 点云数据,雷达数据也有其独特的表示形式。如何解决这种视图差异,实现多模态特征的有效融合,成为多传感器融合领域的核心挑战。
早期的融合思路主要分为两类:一类是将 LiDAR 点云投影到相机平面,利用 2D CNN 处理 RGB-D 数据,但这种投影会导致严重的几何失真(如图 1a 所示),对于 3D 目标检测等几何相关任务效果不佳;另一类是将相机特征投影到 LiDAR 点云,通过增强 LiDAR 点云的语义信息来进行融合,但这种方式存在严重的语义损失(如图 1b 所示)。对于典型的 32 线 LiDAR,仅有 5% 的相机特征能与 LiDAR 点匹配,其余大量语义信息被丢弃,这使得此类方法在 BEV 地图分割等语义导向任务中表现糟糕。
为解决上述问题,本文提出了 BEVFusion 框架,一种高效通用的多任务多传感器融合方案。该框架创新性地将多模态特征统一到共享的鸟瞰图(BEV)表示空间中,既保留了 LiDAR 的几何结构信息,又完整保留了摄像头的语义密度信息(如图 1c 所示)。同时,针对视图转换中的效率瓶颈,提出了优化的 BEV 池化操作,将延迟降低 40 倍以上。BEVFusion 具有任务无关性,无需大幅修改架构即可无缝支持多种 3D 感知任务,在 nuScenes 基准测试中取得了 state-of-the-art 性能。

图 1 展示了三种不同的特征融合方式:(a) 将 LiDAR 点云投影到相机视图,存在几何损失;(b) 将相机特征投影到 LiDAR 视图,存在语义损失;(c) BEVFusion 的共享 BEV 空间融合方式,同时保留几何结构和语义密度。
原文链接:https://arxiv.org/pdf/2205.13542
代码链接:https://github.com/mit-han-lab/bevfusion
沐小含持续分享前沿算法论文,欢迎关注...
二、相关工作
2.1 基于 LiDAR 的 3D 感知
早期研究主要集中在单阶段 3D 目标检测器,例如利用 PointNets 或 SparseConvNet 提取点云特征,并在 BEV 空间中进行检测。后续研究进一步探索了无锚点单阶段检测方案,以及在单阶段检测器基础上添加 RCNN 网络的两阶段检测架构,不断提升 LiDAR-based 感知的精度和效率。
2.2 基于相机的 3D 感知
由于 LiDAR 传感器成本较高,基于相机的 3D 感知方案受到广泛关注。部分方法通过扩展 2D 检测器,添加 3D 回归分支实现 3D 目标检测;还有一些方法借鉴 LiDAR-based 检测器的设计思路,通过视图转换器将相机透视视图特征转换为 BEV 特征。近年来,基于注意力机制的视图转换方法也被应用于该领域,进一步提升了相机单模态感知的性能。
2.3 多传感器融合
现有多传感器融合方法主要分为提案级融合(proposal-level)和点级融合(point-level)两类。提案级融合方法在 3D 空间中生成目标提案,再将其投影到图像中提取特征,此类方法以目标为中心,难以推广到 BEV 地图分割等非目标导向任务。点级融合方法则通常将图像语义特征映射到前景 LiDAR 点上,再基于增强后的点云进行检测,这类方法同时依赖目标和几何信息,但语义损失问题严重,同样不适用于语义导向任务。
与现有方法不同,BEVFusion 在共享 BEV 空间中进行传感器融合,平等对待前景与背景、几何与语义信息,是一种通用的多任务多传感器感知框架。
三、方法详解
BEVFusion 的核心框架如图 2 所示,主要包括模态特异性特征提取、高效视图转换、全卷积融合和多任务头四个部分。
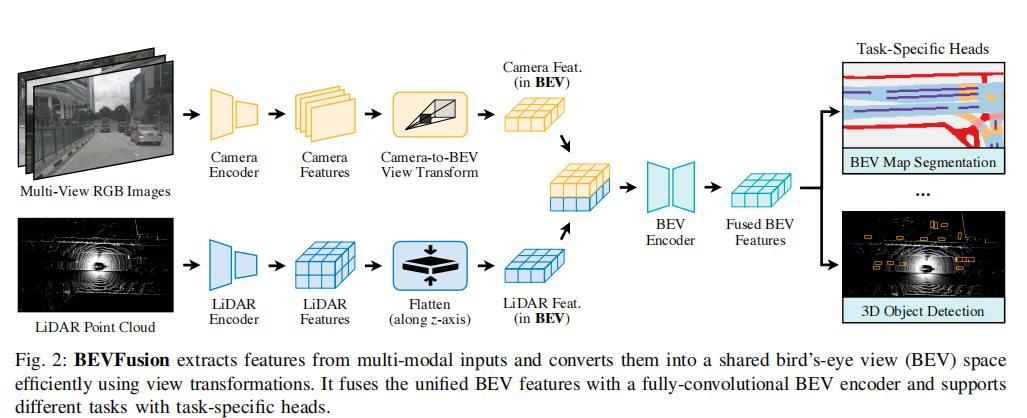
图 2 展示了 BEVFusion 的整体架构:从多视图 RGB 图像和 LiDAR 点云中提取特征,通过高效视图转换将其转换为 BEV 特征,经全卷积融合后,由特定任务头完成 3D 目标检测和 BEV 地图分割任务。
3.1 统一表示空间:鸟瞰图(BEV)选择
3.1.1. 三种表示空间对比
- 相机视图:将 LiDAR 点云投影到相机平面会导致几何失真,两个在 2D 深度图上相邻的点,在 3D 空间中可能相距甚远,不利于几何相关任务。
- LiDAR 视图:相机特征到 LiDAR 点云的投影存在严重语义损失,由于两种传感器数据密度差异巨大,大部分相机语义特征无法被利用,影响语义导向任务性能。
- BEV 视图:BEV 视图天然适用于大多数自动驾驶感知任务,因为这些任务的输出空间通常也是 BEV 格式。更重要的是,LiDAR 到 BEV 的投影仅沿高度维度展平,不会产生几何失真;而相机到 BEV 的投影通过将每个像素映射到 3D 空间中的射线,能够生成密集的 BEV 特征图,完整保留相机的语义信息。
3.1.2. BEV 的优势
BEV 空间作为统一融合表示,同时满足两个关键要求:所有传感器特征都能在几乎无信息损失的情况下转换到该空间;该空间适用于多种 3D 感知任务,为多任务学习提供了基础。
3.2 高效相机到 BEV 的转换
相机到 BEV 的转换是实现多模态融合的关键步骤,但传统方法存在严重的效率瓶颈。BEVFusion 通过预计算和区间缩减两种优化策略,大幅提升了转换效率。
3.2.1. 相机到 BEV 转换的基本原理
借鉴 LSS 的思路,首先预测每个相机像素的离散深度分布,将每个特征像素沿相机射线分散到 D 个离散点,并根据深度概率对特征进行加权。生成的 3D 特征点云沿 y 轴以步长 r(例如 0.4m)量化,通过 BEV 池化操作聚合每个 r×r BEV 网格内的特征,并沿 z 轴展平,得到 BEV 特征图。
3.2.2. 效率瓶颈分析
传统 BEV 池化操作效率极低,在 RTX 3090 GPU 上单次场景处理耗时超过 500ms,而模型其他部分仅需约 100ms。这是因为相机特征点云规模庞大,对于典型场景,每帧可能生成约 200 万个点,密度是 LiDAR 点云的两个数量级。
3.2.3. 优化策略
- 预计算(Precomputation):BEV 池化的第一步是将点云与 BEV 网格关联。由于相机内参和外参在标定后固定不变,点云的 3D 坐标和 BEV 网格索引也固定。因此可以预计算这些信息,并按网格索引对所有点排序,记录每个点的排名。推理时只需根据预计算的排名重新排序特征点,将网格关联的延迟从 17ms 降至 4ms。
- 区间缩减(Interval Reduction):网格关联后,同一 BEV 网格内的点在张量中连续分布。传统方法通过前缀和计算网格内特征聚合值,存在大量无效计算和 DRAM 写入操作。BEVFusion 设计了专用 GPU 内核,为每个网格分配一个 GPU 线程,直接计算区间和并写回结果,消除了输出依赖和无效操作,将特征聚合延迟从 500ms 降至 2ms。
3.2.4. 优化效果
通过上述两种优化,相机到 BEV 的转换速度提升了 40 倍以上,延迟从 500ms 以上降至 12ms,仅占模型端到端运行时间的 10%,且在不同特征分辨率下均具有良好的扩展性(如图 3 所示)。
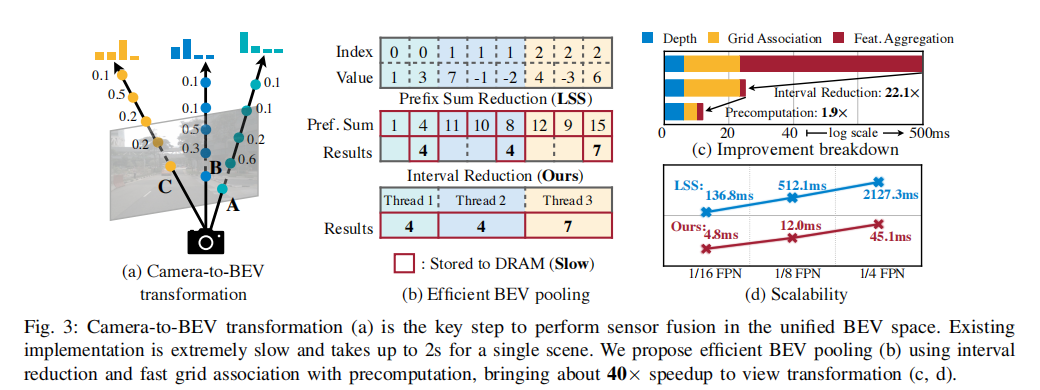
图 3 展示了相机到 BEV 转换的优化细节:(a) 相机到 BEV 转换的基本流程;(b) 高效 BEV 池化的实现原理;(c) 各优化策略的延迟降低贡献;(d) 不同特征分辨率下的扩展性对比。
3.3 全卷积融合
尽管所有传感器特征都已转换到 BEV 空间,但由于视图转换器中的深度估计存在误差,LiDAR BEV 特征和相机 BEV 特征可能存在局部空间错位。为解决这一问题,BEVFusion 采用基于卷积的 BEV 编码器(包含多个残差块),补偿局部错位,进一步提升融合特征的一致性。未来研究可通过引入真实深度监督等方式提升深度估计精度,为融合性能带来额外增益。
3.4 多任务头
BEVFusion 通过添加特定任务头,可灵活支持多种 3D 感知任务:
- 3D 目标检测:采用类特异性中心热力图头预测目标中心位置,并通过多个回归头估计目标的尺寸、旋转和速度。
- BEV 地图分割:由于不同地图类别可能存在重叠(如人行横道属于可驾驶区域的子集),将该任务建模为多二进制语义分割问题,每个类别独立进行二分类。采用标准的 focal 损失训练分割头,确保模型对类别不平衡数据的适应性。
四、实验验证
4.1 实验设置
4.1.1. 模型配置
- 图像骨干网络采用 Swin-T,LiDAR 骨干网络采用 VoxelNet。
- 利用 FPN 融合多尺度相机特征,生成 1/8 输入尺寸的特征图;相机图像下采样至 256×704,LiDAR 点云体素化分辨率为 0.075m(检测任务)和 0.1m(分割任务)。
- 针对不同任务对 BEV 特征图空间范围和尺寸的需求,在任务头前采用双线性插值的网格采样进行特征转换。
4.1.2. 数据集
实验在 nuScenes 和 Waymo 两个大规模 3D 感知数据集上进行,两个数据集均包含超过 40k 个带标注场景,每个样本均配备 LiDAR 和多视角相机数据,涵盖了不同天气、光照和场景条件,具有很强的代表性。
4.2 3D 目标检测结果
4.2.1. nuScenes 数据集
表 1 展示了 BEVFusion 在 nuScenes 数据集上的 3D 目标检测性能。BEVFusion 在测试集上的 mAP 和 NDS 分别达到 70.2% 和 72.9%,相较于现有方法,在提升 1.3% 性能的同时,计算量降低 1.9 倍,延迟降低 1.3 倍。与代表性点级融合方法相比,BEVFusion 在速度提升 1.6 倍、计算量降低 1.5 倍的情况下,mAP 提升 3.8%。
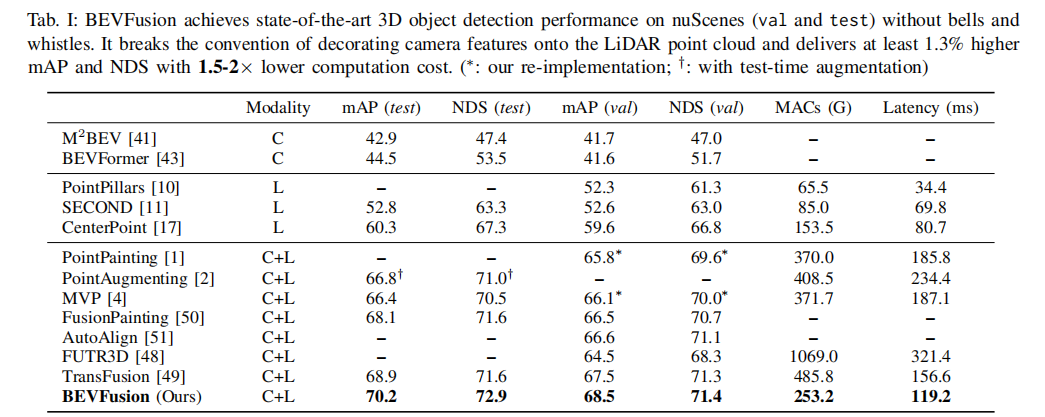
注:†表示使用测试时增强;∗表示重新实现;C 表示相机单模态;L 表示 LiDAR 单模态;C+L 表示多模态融合。
4.2.2. Waymo 数据集
表 2 展示了 BEVFusion 在 Waymo 开放数据集上的性能。BEVFusion 在仅使用 3 帧输入且采用测试时增强的情况下,mAP/L1 达到 85.7%,mAPH/L1 达到 84.4%,超过了之前的 state-of-the-art 多模态检测器。值得注意的是,部分对比方法采用了 25 个模型集成和测试时增强,而 BEVFusion 仅通过单个模型和测试时增强就实现了更优性能,充分证明了其有效性。
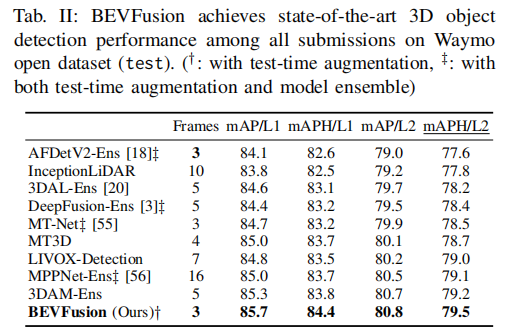
注:†表示使用测试时增强;‡表示同时使用测试时增强和模型集成。
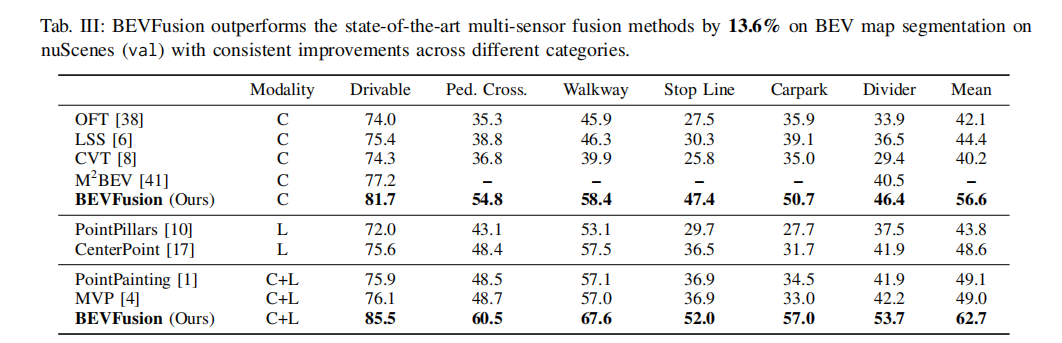
4.3 BEV 地图分割结果
表 3 展示了 BEVFusion 在 nuScenes 数据集上的 BEV 地图分割性能。由于地图分割是语义导向任务,相机单模态 BEVFusion 模型的 mIoU 达到 81.7%,超过 LiDAR 单模态基线 8-13%,这与 3D 目标检测任务中 LiDAR 单模态占优的情况形成鲜明对比。在多模态设置下,BEVFusion 的 mIoU 进一步提升至 85.5%,相较于现有传感器融合方法提升超过 13%。这是因为现有融合方法以目标和几何为中心,无法有效支持地图组件分割,而 BEVFusion 的共享 BEV 空间融合方式能够充分利用相机的语义信息和 LiDAR 的几何信息,实现语义分割性能的大幅提升。
4.4 鲁棒性分析
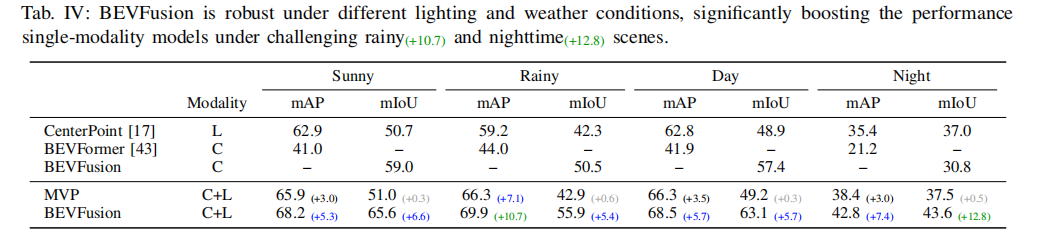
4.4.1. 不同天气和光照条件
表 4 展示了 BEVFusion 在不同天气和光照条件下的性能。LiDAR 单模态模型在雨天由于传感器噪声,检测性能显著下降,而 BEVFusion 利用相机传感器的鲁棒性,mAP 提升 10.7%,大幅缩小了晴天和雨天的性能差距。在夜间低光照条件下,相机单模态分割性能明显下降,但多模态 BEVFusion 的 mIoU 提升 12.8%,甚至超过白天的提升幅度,证明了在相机传感器失效时,LiDAR 的几何信息能够有效补充,提升模型鲁棒性。
注:括号内为相较于 LiDAR 单模态的性能提升。
4.4.2. 不同目标尺寸和距离
图 4a 和 4b 分别展示了 BEVFusion 在不同目标尺寸和距离下的性能。对于尺寸小于 4m 的小目标和距离大于 30m 的远距目标,BEVFusion 的性能提升更为显著,这是因为这些目标在 LiDAR 点云中的采样密度较低,而相机的密集语义信息能够有效补充,提升感知精度。对于尺寸大于 4m 的大目标,由于其 LiDAR 点云密度较高,MVP 等点级融合方法的提升有限,而 BEVFusion 仍能保持稳定提升。
4.4.3. 不同 LiDAR 稀疏度
图 4c 展示了 BEVFusion 在不同 LiDAR 稀疏度下的性能。随着 LiDAR 线数减少(点云更稀疏),Point 级融合方法的性能急剧下降,而 BEVFusion 由于不依赖于 LiDAR 点云的密度,在 1 线 LiDAR 场景下仍能保持较高性能,相较于 LiDAR 单模态提升 12%,充分证明了其在稀疏传感器配置下的优越性。
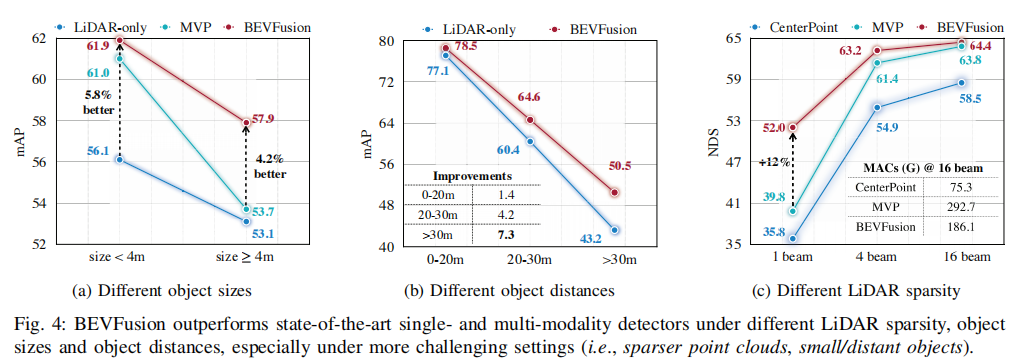
图 4 展示了 BEVFusion 在不同场景下的性能:(a) 不同目标尺寸下的 mAP 对比;(b) 不同目标距离下的 mAP 对比;(c) 不同 LiDAR 稀疏度下的 NDS 对比。
五、结论与展望
BEVFusion 提出了一种高效通用的多任务多传感器 3D 感知框架,通过将多模态特征统一到共享 BEV 空间,同时保留几何结构和语义信息,解决了现有融合方法的几何失真和语义损失问题。通过预计算和区间缩减优化,将相机到 BEV 的转换速度提升 40 倍以上,实现了高效推理。在 nuScenes 和 Waymo 数据集上的实验表明,BEVFusion 在 3D 目标检测和 BEV 地图分割任务中均取得 state-of-the-art 性能,且计算量和延迟显著低于现有方法。
BEVFusion 的创新点在于重新思考了多传感器融合的范式,证明了 BEV 空间作为统一融合表示的优越性。未来研究可进一步探索更精准的深度估计方法,扩展至雷达等更多传感器类型,以及支持 3D 目标跟踪和运动预测等更复杂的感知任务,为自动驾驶提供更全面、可靠的环境感知能力。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)