【读点论文】单_双目深度估计研究进展与应用综述
深度估计作为计算机视觉领域的核心基础任务,在自动驾驶、增强现实、机器人导航等领域具有重要应用价值。单目方法通过端到端深度学习架构,如多尺度特征融合、注意力机制,突破传统几何先验限制,结合监督或自监督范式缓解数据依赖问题,但受限于尺度模糊性。双目技术依托立体匹配的几何约束,通过代价体积构建与三维卷积网络实现亚像素级视差计算,在动态场景鲁棒性上表现突出。两类技术通过语义几何协同优化形成互补,推动算法从
单**/**双目深度估计研究进展与应用综述
- 深度估计作为计算机视觉领域的核心基础任务,在自动驾驶、增强现实、机器人导航等领域具有重要应用价值。单目方法通过端到端深度学习架构,如多尺度特征融合、注意力机制,突破传统几何先验限制,结合监督或自监督范式缓解数据依赖问题,但受限于尺度模糊性。双目技术依托立体匹配的几何约束,通过代价体积构建与三维卷积网络实现亚像素级视差计算,在动态场景鲁棒性上表现突出。两类技术通过语义几何协同优化形成互补,推动算法从局部特征匹配向全局三维感知升级。
- 在三维显示领域,深度估计技术成为虚实融合的关键:单目方法支撑移动端设备的实时空间拓扑重建,通过轻量化模型实现虚拟物体的物理遮挡与光照一致性渲染;双目技术为高精度全息投影与数字孪生提供毫米级深度支撑,实现动态光场重建。新兴技术如扩散模型和多教师蒸馏框架显著提升弱纹理区域的深度连续性,推动体积显示器渲染质量提升。未来研究需聚焦多传感器融合、轻量化边缘计算、跨模态评估基准构建及物理可逆渲染等方向。随着神经符号计算等范式的发展,深度估计技术将推动三维显示从几何重构向物理属性推理跃迁,最终实现“所见即所得”的沉浸式体验。
- 深度估计作为计算机视觉领域的核心基础任务,核心分为单目与双目两类技术:单目方法通过端到端深度学习架构(如多尺度特征融合、注意力机制)突破传统几何先验限制,结合监督 / 自监督范式缓解数据依赖,但存在尺度模糊性;双目技术依托立体匹配的几何约束,通过代价体积构建与三维卷积网络实现亚像素级视差计算,动态场景鲁棒性突出,二者形成互补。该技术在三维显示、自动驾驶、AR/VR、机器人导航等领域应用广泛,当前主流数据集包括 NYU Depth V2、KITTI 等,评估指标涵盖 AbsRel、RMSE 等,未来研究将聚焦多传感器融合、轻量化边缘计算、跨模态评估基准构建等方向,推动三维显示向物理属性推理跃迁。
Induction
-
深度估计作为计算机视觉领域的核心基础任务,旨在从二维图像中恢复场景的三维几何信息,其技术突破对自动驾驶、增强现实、机器人导航等关键领域具有重要支撑作用。深度估计分为单目和双目两类,核心差异在于输入是单张图像还是立体图像对。单目方法早期依赖几何线索和统计模型,虽可解释性强,但面对复杂动态环境或弱纹理区域时精度受限。随着深度学习发展,基于卷积神经网络和Transformer的端到端模型通过隐式学习图像与深度的关联,大幅提升了预测精度和场景适应能力,推动技术从几何驱动转向数据与语义双重驱动。监督学习利用标注数据优化网络细节还原能力,但数据成本高的问题催生了自监督范式,通过图像对的光度一致性或视频动态连续性生成监督信号,降低数据依赖。
-
视觉 Transformer 凭借全局注意力机制改善了远距离深度预测和边缘保持效果,但单目仍受尺度模糊性和动态物体处理能力不足的制约。双目方法通过模拟人眼立体视觉,利用视差直接计算绝对深度,传统双目算法依赖几何约束但易受弱纹理干扰。深度学习与立体匹配结合后,端到端网络通过代价体积构建和三维卷积实现亚像素级的视差估计。单目与双目的协同创新成为趋势,例如用语义信息优化立体匹配或引入几何约束,形成互补技术生态。系统梳理单目与双目深度估计的技术演进脉络,从方法分类、核心算法、数据集构建、评估体系及应用场景展开对比分析。单/双目深度估计中传统方法、机器学习模型与深度学习范式的技术突破,展望深度估计技术在三维显示、智能感知等领域的未来发展方向。文中旨在为研究者提供技术发展的全景视图,并为算法选型与工程化落地提供理论依据。
-
深度估计是计算机视觉领域的核心基础任务,旨在从二维图像中恢复场景的三维几何信息,是自动驾驶、增强现实(AR)、虚拟现实(VR)、机器人导航等领域的关键支撑技术。根据输入数据类型分为单目(单张图像)和双目(立体图像对)两类,核心差异在于几何约束获取方式与数据依赖度。
单目深度估计
-
单目深度估计技术可分为三大类:传统方法、基于机器学习的传统方法和深度学习方法,其中深度学习方法进一步细分为监督学习、无监督学习与半监督学习。
-
方法类型 核心技术 / 算法 关键特点 局限 传统方法 线性透视、大气散射、SFM、SFS 无需训练数据,物理可解释性强 依赖场景假设,动态 / 弱纹理区域精度低,难生成稠密深度图 机器学习方法 MRF(参数化)、数据驱动检索(非参数化) 建立图像特征与深度的统计映射 依赖大规模数据库,泛化能力受限 深度学习方法 监督学习:EIGEN 两阶段网络、DPT(ViT 架构)、Mambavision 端到端学习,高精度稠密预测 监督学习标注成本高,跨域泛化弱 自监督学习:Monodepth2、ManyDepth 利用立体图像对 / 视频时序一致性,无标注依赖 对光照变化敏感,动态物体易产生伪影 多任务学习 / 混合模型:BTS(表面法线辅助)、AdaBins 融合多模态特征 / 传统几何约束,鲁棒性强 计算复杂度高,任务权重设计关键 -
误差度量:绝对相对误差(AbsRel)、均方根误差(RMSE)、对数误差(RMSE log)、平方相对误差(SqRel);尺度无关指标:尺度无关对数误差(SILog)(解决尺度模糊性问题);精度阈值:阈值准确率(统计预测值与真值比例落在指定区间的像素占比)。
传统方法
-
传统单目深度估计方法的核心在于利用人类视觉启发式线索,通过图像中的几何特征反推三维结构。这类方法无需大规模数据训练,但依赖场景先验假设与物理模型约束。
-
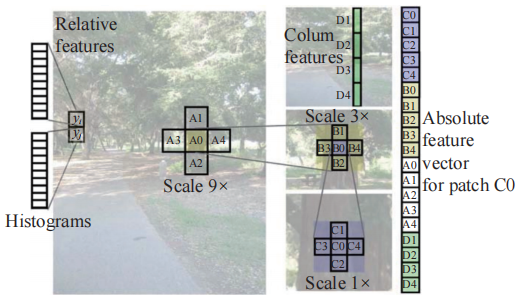
一种方法是线性透视与大气散射法。线性透视基于物体尺寸随距离缩小的规律 (如道路边缘汇聚效应),通过计算消失点与投影几何关系推断深度。监督学习方法,通过多尺度特征和马尔可夫随机场(MRF) 模型,从单目图像中恢复非结构化户外场景(如森林、建筑) 的深度图,其使用的深度特征向量如图 1 所示。图像块的深度特征包括其近邻和更远邻(更大尺度) 的特征,每个块的相对深度特征使用滤波器输出的直方图。
-
-
图 1 传统单目深度估计使用的深度特征向量
-
-
大气散射则利用空气中颗粒物对光线散射导致的色彩衰减特性,结合 RGB 通道的亮度差异建立深度-色彩映射关系。该方法提供了从色彩衰减特性到几何深度的鲁棒推理。不过,该方法在极端天气或动态光源下的泛化能力仍面临挑战。
-
运动恢复结构 (Structure from Motion, SFM) 方法通过相机移动轨迹重建稀疏 3D 点云,核心步骤包括:特征匹配,即采用 SIFT/SURF 算法提取关键点并建立跨帧对应关系 ; 对极几何优化 , 即通过基础矩阵(Fundamental Matrix) 估计相机位姿 ; 光束法平差(Bundle Adjustment), 通过非线性优化相机参数与3D 点坐标,最小化重投影误差。
-
阴影恢复形状 (Shape from Shading, SFS) 法根据单幅图像的光照模型反推表面法向量,假设场景满足Lambertian 反射模型且光源参数已知,通过迭代优化求解法向量场后积分得到深度图。该方法对噪声敏感且依赖精确光源参数,适用场景有限。
基于机器学习的传统方法
-
在深度学习兴起前,研究者尝试通过统计学习建立图像特征与深度的映射关系,主要分为参数化与非参数化两类。
-
马尔可夫随机场 (Markov Random Field, MRF) 是一种参数学习方法。将深度估计建模为能量最小化问题,定义一元势能项 (局部特征与深度的关联) 与二元势能项 (相邻像素深度平滑性约束)。
-
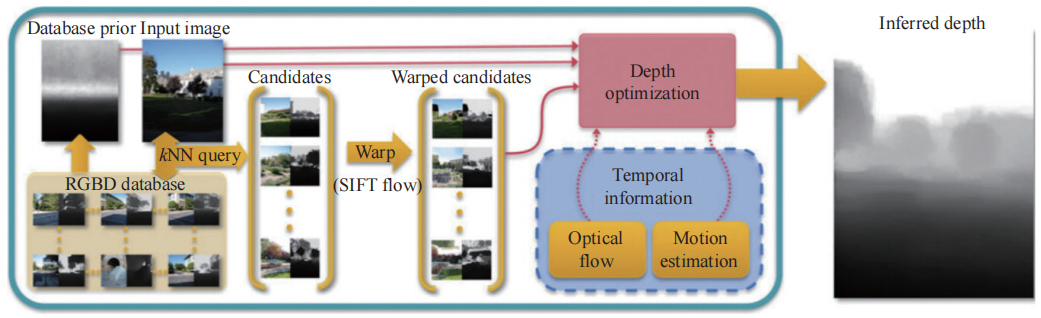
数据驱动检索是一种非参数学习方法。从预构建的 RGBD 数据库中检索与输入图像场景相似的样本,通过特征匹配选择候选深度图,再通过加权融合生成最终结果。图 2 展示了该检索方法的基本流程,这是一种非参数深度转移方法,从单图像或视频中自动生成合理深度图,尤其适用于传统方法失效的场景。通过输入图像在数据库中找到匹配的候选图像,并对候选图像进行翘曲处理,使其与输入图像的结构相匹配,并使用全局优化程序对翘曲候选图像进行插值,从而得出输入图像的逐像素深度估计值。该方法依赖大规模数据库且泛化能力受限,但对特定场景 (如室内布局) 效果显著。
-
-
图 2 基于机器学习的传统检索方法的深度估算流程
-
深度学习方法
-
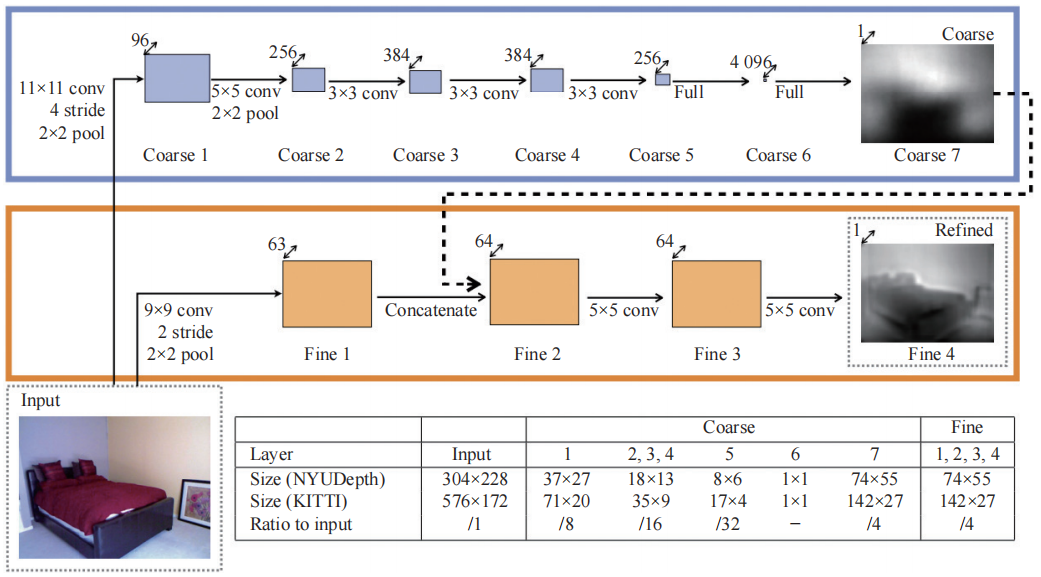
基于深度学习的单目深度估计通过端到端模型直接学习 RGB 图像到深度图的映射,突破了传统方法的场景假设限制,显著提升了预测精度与泛化能力。首先介绍监督学习方法。从网络架构上来看,EIGEN 等提出首个两阶段卷积网络,先通过全局粗估计网络获取场景结构,再利用局部细化网络优化细节 ,图 3 展示了该两阶段卷积网络的架构。后续工作引入了残差连接 (ResNet) 与空洞卷积增强了模型的多尺度特征融合能力。DORN 将深度估计转化为有序回归问题,通过空间离散化缓解深度值分布不均匀问题,显著提升了远距离区域的预测精度。
-
-
图 3 单目深度估计网络架构:两阶段卷积网络
-
-
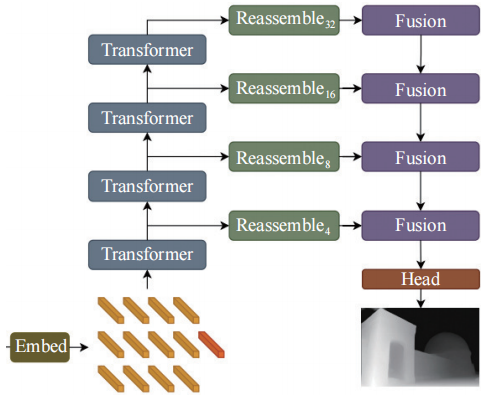
近年来,Vision Transformer(ViT) 被引入深度估计任务,例如 DPT 通过 ViT 的全局建模能力与高分辨率处理,结合卷积解码器的多尺度融合,在密集预测任务中实现了更精细、全局一致的预测效果,尤其在大规模数据下优势显著。如图 4 所示,DPT 通过提取非重叠斑块,然后对其扁平化表示进行线性投影,或应用 ResNet-50 特征提取器,将输入图像转换为标记 (橙色)。在图像嵌入的基础上增加位置嵌入,并添加与补丁无关的读出标记 (红色)。标记经过多个转换器阶段。最后将来自不同阶段的标记以多种分辨率 (绿色) 重新组合成类似图像的表征。融合模块 (紫色) 会逐步融合和上采样这些表征,从而即可生成细粒度预测。未来 DPT 可扩展至更多任务(如实例分割、光流估计),并探索更高效的 Transformer变体。
-
-
图 4 DPT 架构图
-
-
近年来,基于状态空间模型的视觉 Mamba 架构在深度估计领域展现出突破性潜力。Mambavision作为首个融合 Mamba 与 Transformer 的混合视觉主干网络,通过选择性状态机制实现了线性计算复杂度,相较于传统 Transformer 的二次复杂度,显著提升了高分辨率深度图处理的效率。实验验证表明,该架构在动态场景深度估计任务中具有显著优势。
-
从损失函数的创新方面来看,针对深度尺度模糊性问题 , EIGEN 等 提出的尺度不变误差 (Scale Invariant Error) 通过归一化处理消除了全局尺度差异对损失计算的影响。之后,为保留深度不连续区域的边缘结构,一些研究设计了边缘感知平滑性损失(Edge-Aware Smoothness Loss),结合图像梯度加权约束深度图的局部平滑性。
-
为解决深度标注数据稀缺问题,无监督与自监督学习逐渐也被用到了深度估计问题中。研究者利用立体图像对或单目视频序列中的几何一致性作为监督信号,实现无需真实深度标签的训练。一些方法利用率基于立体匹配的自监督学习。GARG 等人首次提出通过左右视图的视差合成目标视图,以重建误差作为监督信号进行深度估计的方案 ,如图 5 所示,其利用左右立体对图片的重建损失训练卷积神经网络并使用该网络进行视差预测,从而完成单目深度估计。
-
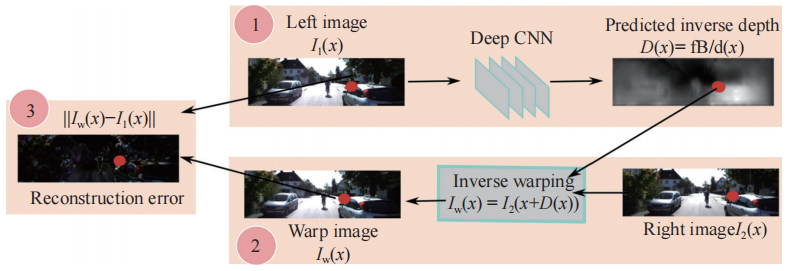
-
图 5 以重建误差作为监督信号的自监督方法示意图
-
-
GODARD 等人进一步引入左右一致性约束与遮挡掩码,提升视差预测的鲁棒性。Monodepth2 通过最小化多尺度光度重构误差 (Photometric Reconstruction Loss) 与视差平滑性损失,实现了动态场景下的稳定训练。另一些方法关注单目视频中的动态一致性。ZHOU 等人提出将单目视频序列中的相机运动与物体运动解耦,通过联合优化深度预测网络与姿态估计网络,解决动态物体对自监督学习的干扰。ManyDepth 利用多帧时序信息构建代价体积 (Cost Volume),通过 3D 卷积聚合时空特征,缓解单帧模糊性问题。
-
多任务学习同样被用于单目深度估计。通过共享特征表示联合学习深度估计与其他视觉任务 (如语义分割、表面法线估计),可提升模型对场景理解的全面性。EIGEN 等人首次提出多任务网络,在深度估计分支与语义分割分支间共享低层特征,并通过高层特征交互增强任务相关性。BTS 将表面法线估计作为辅助任务,通过法线方向与深度梯度的几何一致性损失 (如正交性约束) 提升深度图的结构合理性。
-
还有方法尝试了结合传统几何约束与深度学习,同样可提升模型的可解释性与泛化能力。CHEN 等人将条件随机场 (CRF) 作为 CNN 的后处理模块,通过能量函数建模像素间深度依赖关系,优化局部细节。AdaBins 将深度离散化为自适应区间,结合可微渲染技术生成高分辨率深度图,同时保持全局连续性。图 6 展示了先进的单目深度估计算法结果和真实深度的对比,直观上可以看到其已经十分接近真实深度。
-

-
图 6 ZoeDepth 实验结果同真实深度对比
-
方法总结和对比
-
单目深度估计方法可划分为传统方法与深度学习方法两大范式。传统方法主要依赖几何线索与统计模型,例如基于线性透视、运动恢复结构 (SFM) 或阴影恢复形状 (SFS) 的算法,通过手工设计的特征与物理先验 (如消失点、光度一致性) 反推深度信息。这类方法无需训练数据,但受限于场景假设的强约束,在动态物体或弱纹理区域表现较差。传统方法的优势在于其物理可解释性与无监督特性,适用于实时性要求高但精度需求较低的场景 (如无人机避障)。然而,这类方法对动态物体和弱纹理区域的适应性差,且难以生成稠密深度图。例如,SFM 依赖静态场景假设,而 SFS 需精确的光源参数,实际应用中局限性显著。
-
深度学习方法的兴起彻底改变了这一领域,其核心思想是通过端到端网络直接学习从 RGB 图像到深度图的复杂映射。与监督学习不同,自监督方法利用立体图像对或视频序列中的几何一致性生成伪标签,避免了真实深度数据的标注依赖。此外,多任务学习和混合模型通过融合多模态特征或传统几何约束,进一步提升了模型的鲁棒性与可解释性。
-
监督学习方法在充足标注数据下可实现高精度稠密预测,广泛应用于自动驾驶和 AR/VR 领域。但其性能高度依赖训练数据分布,跨域泛化能力较弱(如从室内到室外场景迁移时精度骤降),且标注成本高昂。
-
自监督学习方法通过几何一致性信号 (如立体匹配或时序运动) 避免了标注需求,适用于动态环境中的深度估计 (如车载摄像头视频流)。然而,这类方法对光照变化敏感,且在动态物体 (如行人、车辆) 存在时易因光度一致性假设失效而产生伪影。多任务与混合模型通过联合学习或融合传统几何约束,试图平衡数据驱动与物理可解释性。这类方法在复杂场景理解中表现优异,但计算复杂度较高,且需谨慎设计任务权重以避免性能冲突。
-
在实时嵌入式系统 (如移动机器人导航) 中,传统方法因低计算开销仍具实用价值,但其稀疏或粗糙的深度输出难以满足高精度需求。监督学习在高精度场景 (如医疗影像三维重建) 中表现突出,但依赖特定领域标注数据,难以泛化至未见过的新环境。自监督学习在缺乏标注数据的动态场景 (如户外监控视频) 中具有潜力,但对动态物体和光照变化的鲁棒性仍需提升。混合模型更适合复杂任务 (如自动驾驶中的多模态感知),但其高计算成本限制了在资源受限设备上的部署。
-
单目深度估计技术虽已取得显著进展,但在实际应用中仍面临动态场景建模、跨域泛化、实时性需求与多模态融合等核心挑战。未来研究需持续突破,同时关注算法的可解释性与伦理安全,推动单目深度估计技术在自动驾驶、机器人导航、AR/VR 等领域的规模化落地。
数据集与评估指标
-
单目深度估计技术的发展与数据集的演进密不可分。早期研究主要依赖合成数据与有限场景的真实标注数据,例如 NYU Depth V2 作为室内场景的经典数据集,通过激光扫描仪获取了 1 449 对 RGB-D 图像,覆盖办公室、卧室等多种室内环境,成为模型训练与验证的重要基准。而户外场景的研究则依赖于KITTI 数据集,其通过多传感器融合 (如激光雷达、双目相机) 采集道路场景的深度信息,支持多任务标注(如目标检测、光流估计),推动了自动驾驶领域的算法进步。为缓解真实数据标注成本高的问题,虚拟数据集如 vKITTI 应运而生,通过渲染技术生成不同天气与视角的合成图像,增强了模型对光照变化的鲁棒性。
-
近年来,数据集的构建更注重多样性与实用性,例如 DA-2 K 采用稀疏深度标签与自动掩模技术,覆盖复杂场景并减少人工标注负担 ;Kaggle 发布的视点变化数据集则通过单应性变换与目标检测生成伪标签,量化了相机位姿对深度估计的影响,为模型泛化性评估提供了新工具。MiDaS 提出通过混合多个 RGBD 数据集 (如 KITTI、NYUv2 等) 训练模型,以提升跨数据集的零样本泛化能力,并从 3D 电影中提取相对深度数据,扩展训练数据多样性。
-
在评估指标方面,单目深度估计的量化分析主要围绕误差度量与精度阈值展开。绝对相对误差(AbsRel) 和均方根误差 (RMSE) 作为核心误差指标,分别衡量预测深度与真实值的相对偏差与绝对偏差,其中 RMSE 对远距离误差敏感,而 AbsRel 更关注整体一致性。对数误差 (RMSE log) 通过压缩深度尺度缓解长尾分布的影响,平方相对误差 (SqRel) 则放大大误差区域的惩罚,适用于对异常值敏感的场景。此外,阈值准确率统计预测值与真值比例落在指定区间的像素占比,直观反映模型的局部一致性能力。值得注意的是,尺度无关对数误差 (SILog) 通过分离尺度与形状误差,解决了单目深度估计的尺度模糊性问题,成为跨数据集评估的重要补充。然而,现有指标仍难以全面反映复杂场景下的模型表现,例如动态物体边缘的锐度、弱纹理区域的连续性等,这促使研究者结合可视化分析与人工评估进行综合判断。
-
未来,随着多模态传感器融合与生成式 AI 技术的发展,数据集的构建将更注重真实性与多样性平衡,例如结合神经辐射场生成高保真合成数据,或利用联邦学习框架保护隐私的同时扩展数据来源。评估体系则需引入语义一致性、物理合理性等高层语义指标,以推动单目深度估计从几何重建向场景理解深化。
应用场景
-
单目深度估计在三维显示场景下的应用正随着技术的突破而不断拓展,其核心在于通过单张 RGB图像精准推测深度信息,为虚拟与现实世界的融合提供了关键支持。在增强现实 (AR) 和虚拟现实 (VR)领域,单目深度估计技术能够实时生成场景的深度图,使虚拟对象能够根据真实环境的几何结构自适应调整位置和光照,例如在 AR 眼镜中,虚拟物品可以更自然地“贴合”桌面或墙壁的曲面,显著提升用户的沉浸感。该类技术还被应用于全息显示终端,例如斯坦福研究团队提出的神经网络参数化平面到多平面波传播模型,通过单目深度估计生成的深度图指导三维全息图合成,同时结合物理光学特性与深度学习算法,有效减少了传统全息显示中的散斑噪声与离焦模糊。
-
在三维内容生成方面,单目深度估计为影视制作和游戏开发提供了高效工具。通过从单张图片推断深度,可以快速构建场景的三维模型并渲染逼真的光影效果,例如 Metric3D v2 算法能够直接生成高精度的 3D 点云,支持单帧图像的即时三维重建,其精度甚至足以替代部分物理传感器。这种技术还被用于文化遗产保护,例如对历史文物进行非接触式三维扫描,避免传统测量可能造成的损伤,同时生成可用于数字博物馆或虚拟修复的精细模型。
-
此外,在消费电子领域,单目深度估计推动了体积显示器和智能设备的革新。例如 , 苹 果 Vision Pro 等头显设备利用该技术实时分析用户周围环境的深度 , 实现虚拟对象与物理空间的动态交互 ; 而MARIGOLD 等基于扩散模型的算法,则通过生成高质量深度图,为计算摄影中的散景效果、动态光照调整提供支持,使手机拍摄的 2D 照片也能转换为立体视觉内容。最新技术如 Distill Any Depth 通过多教师模型蒸馏框架,仅需少量无标签数据即可提升深度估计的鲁棒性,进一步降低了三维显示技术对标注数据的依赖,使其在数据匮乏场景 (如考古现场或偏远地区) 中更具实用性。这些进展共同推动着三维显示从专业领域向大众化应用渗透,为未来智能终端的交互方式开辟了新的可能性。
双目深度估计
-
单目深度估计实现了从二维图像到深度信息的映射,但其固有局限性——尺度模糊性和几何先验依赖——始终制约着其在动态场景与高精度应用中的可靠性。为突破这一瓶颈,双目深度估计通过引入立体几何约束,将深度求解转化为视差计算问题,从根本上解决了尺度不确定性。近年来,随着深度学习与立体视觉的深度融合 (如端到端立体匹配网络),双目方法在保持几何一致性的同时,进一步提升了复杂场景下的泛化能力,标志着三维感知技术从单目“经验驱动”到双目“几何数据驱动”的转变。下面将介绍双目深度估计技术的研究情况。
-
双目深度估计作为三维视觉感知的核心技术,通过模拟人类双眼视差感知机制,从左右视角图像中恢复场景的三维几何信息。双目深度估计算法的方法体系可划分为传统匹配算法与深度学习模型两大技术路径。
-
方法类型 核心技术 / 算法 关键特点 局限 传统方法 块匹配(SAD/SSD)、SGBM 基于几何匹配原理,动态规划优化视差平滑性 弱纹理区域易匹配歧义,硬件加速难度大 深度学习方法 相关性匹配网络(DispNetC) 全卷积编解码架构,30 FPS 实时性 浅层网络特征表达能力有限 代价体积优化网络(PSMNet、GC-Net) 4D 代价体 + 3D 卷积,多尺度特征融合 计算量大,实时性受限 Transformer 架构(STTR) 交叉注意力层建模长程依赖 训练收敛难,部署效率低 轻量化网络(StereoNet) 平衡精度、速度与功耗 适用于嵌入式设备,需硬件加速 -
像素级误差:端点误差(全局匹配精度)、D1-all(误匹配像素占比,>3pixel 或 5% 真值)、SILog(跨域泛化评估);任务导向指标:FPS(实时性)、EPI(边缘保持度,适用于 AR/VR)
传统匹配方法
-
传统方法以几何匹配原理为核心,通过构建视差与深度的几何映射关系实现三维感知。早期算法如块匹配 (Block Matching) 通过滑动窗口计算左右图像局部区域的相似性 (如 SAD、SSD),但其在弱纹理区域易产生匹配歧义,且难以生成稠密深度图。
-
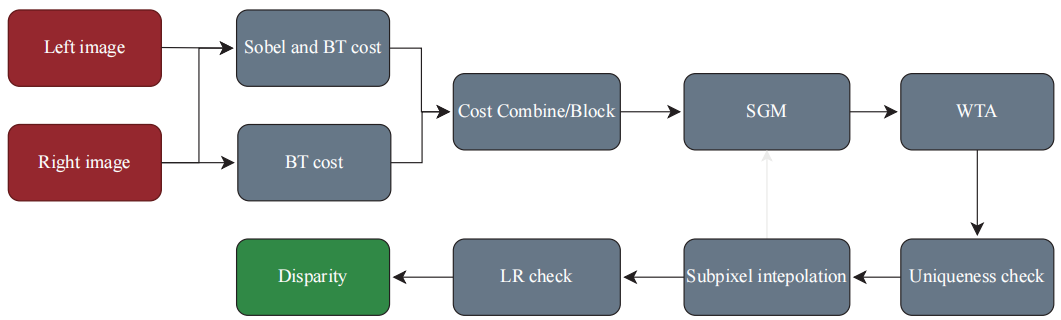
-
图 7 SGBM 算法流程示意图
-
-
BM 算法通过动态调整窗口大小与惩罚系数优化视差平滑性,而 SGBM 算法引入半全局能量最小化策略,结合多路径动态规划增强遮挡区域鲁棒性 ,具体流程如图 7 所示。其流程首先对输入图像进行去噪和亮度归一化预处理,随后在每个像素的预设视差范围内(如 0~128) 通过 BT 方法计算局部块匹配代价。接着沿多个方向 (通常 8 或 16 个) 执行动态规划,聚合路径上的匹配代价形成全局平滑约束的代价,再通过胜者全取策略确定初步视差值。后处理阶段采用亚像素插值提升精度,结合唯一性检验、左右一致性检查和邻域插值消除遮挡区域异常值并填补空洞。其他一些非局部算法如动态规划与图割通过全局能量函数建模视差连续性约束,显著提升遮挡场景的匹配精度,但硬件加速难度大,难以满足嵌入式部署需求。
深度学习方法
-
深度学习技术的引入彻底重构了双目深度估计的技术框架。端到端网络架构通过隐式学习特征表达与视差回归的复杂映射,突破了传统方法的性能瓶颈。根据技术演进脉络,深度双目方法可分为四代创新:基于相关性的匹配网络、代价体积优化网络、Transformer 架构网络以及轻量化实时网络。早期研究突破传统匹配代价计算方式,通过卷积网络实现特征表达与相似性度量的联合学习。
-
DispNetC 提出全卷积编解码架构,通过构建相关性金字塔实现多尺度匹配,其核心创新在于构建多尺度相关性金字塔, 采用收缩-扩张结构,通过 5 层卷积提取左右图像的高维特征,并下采样至 1/4 分辨率以降低计算量,同时利用反卷积层逐步上采样,结合跳跃连接融合底层细节特征,最终输出全分辨率视差图。首次将运行速度提升至实时水平 (30 FPS),但精度受限于浅层网络的特征表达能力。代价体积优化网络通过构建三维/四维代价体积 (Cost Volume) 实现全局上下文感知的立体匹配,标志着深度学习双目方法的成熟。
-
PSMNet 开创性地提出金字塔立体匹配网络,利用空间金字塔池化 (SPP) 融合多尺度特征,结合堆叠沙漏 3D 卷积优化代价体,显著提升复杂场景的视差估计一致性。图 8 展示了 PSMNet 的架构概览。首先,左右输入立体图像被送入两个权重共享网络,包括一个用于计算特征图的 CNN 和一个通过连接来自不同大小子区域的表征来收集特征的 SPP 模块,以及一个用于特征融合的卷积层。然后利用左右图像特征形成 4D 代价体,再将其输入 3D CNN 进行代价正则化和回归。其创新主要在于空间金字塔池化 (SPP) 模块和堆叠沙漏 3D CNN,首先使用残差块提取左右图像特征,结合扩张卷积 (Dilated Convolution) 扩大感受野,利用 SPP对特征图进行多尺度平均池化。GC-Net 则引入全局上下文嵌入层,通过三维卷积聚合全局特征增强匹配鲁棒性。
-
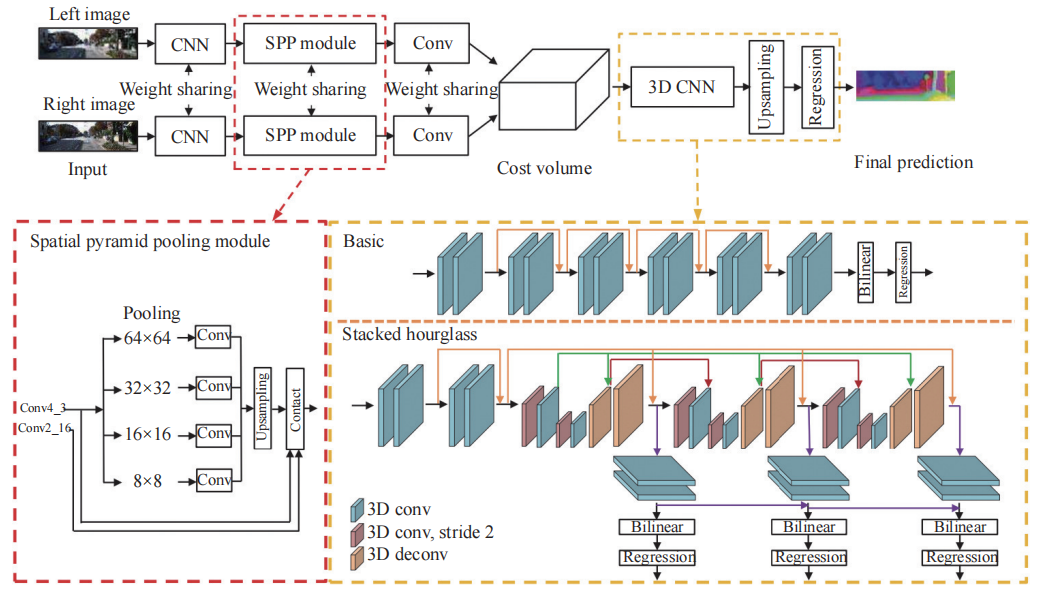
-
图 8 PSMNet 架构概览
-
-
针对传统相关方法特征对齐不足的问题,代价体积方案通过特征图错位匹配构建四维代价体,结合三维卷积实现跨通道深度融合,但计算量激增导致实时性受限。为突破卷积网络的局部感受野限制,Vision Transformer 被引入立体匹配任务,实现全局特征交互与长程依赖建模。例如 STTR 通过交叉注意力层建模长程依赖,有效解决重复纹理区域的匹配歧义,但其训练收敛难度与算子部署效率仍为瓶颈[48]。也有一些研究面向自动驾驶与移动端设备需求,研究重点在于精度,速度和功耗的平衡优化。
数据集与评估指标
-
双目深度估计的性能验证高度依赖多样化的数据集与科学化的评价体系。随着算法从传统几何匹配向深度学习范式演进,数据集的设计与评估指标的选择亦呈现多维度、多场景的精细化趋势。双目深度估计数据集可分为自动驾驶场景、合成仿真场景、室内场景及特殊场景四大类,其设计需平衡标注精度、场景多样性与数据规模。
-
自动驾驶场景数据集以 KITTI 系列 (2012/2015)为代表,提供街景双目图像与稀疏激光雷达标注,其优势在于真实道路场景覆盖,但存在分辨率低 (1242×375)、动态目标标注稀疏的局限[32]。ApolloScape 与Argoverse 2 进一步扩展数据规模,前者提供 3130×960 高分辨率双目图像与稠密点云标注,后者引入多城市 (奥斯汀、迈阿密等) 跨季节数据,支持域适应研究。
-
下面介绍合成仿真数据集。SceneFlow 通过渲染生成 35454 组双目图像与稠密视差图,涵盖飞行物体、单目车流等复杂动态场景,但其合成数据与真实场景的域差距 (Domain Gap) 可能影响模型泛化能力。再介绍室内场景数据集。Middlebury Stereo 提供高精度室内双目图像,分辨率达 3000×2000,适用于算法细节恢复能力评估。近年来,面向复杂感知条件的特殊挑战数据集不断涌现。ETH3D Stereo Benchmark 作为高精度室内外场景数据集,提供毫米级激光扫描真值,包含了混合光照条件,动态反射表面,多季节室外场景。TartanAir 则通过合成数据生成技术构建了涵盖极端运动模糊,光照突变等挑战性场景的立体序列,可模拟镜头污损、雨雪噪声等 68 种干扰因素。
-
双目深度估计的评价指标需兼顾几何精度、计算效率与场景适应性,主要分为像素级误差度量与任务导向型指标两类。像素级误差度量包括端点误差,D1-all 和尺度不变对数误差 (SILog)。端点误差计算视差图的绝对误差均值,反映全局匹配精度。D1-all 统计误匹配像素占比 (视差误差>3 pixel 或 5% 真值),常用于自动驾驶数据集评测,其中误匹配像素的判定采用双阈值准则:对于非遮挡区域像素,若视差估计值与真值的绝对或相对误差大于对应的阈值,即判定为误匹配。
-
SILog 通过对数变换解耦尺度误差,适用于跨域泛化评估。总体来说双目更关注视差计算的几何一致性,单目因缺乏真实深度依赖相对误差与尺度不变性指标。双目深度估计的任务导向型指标包括实时性 (FPS) 和边缘保持度 (Edge Preservation Indicator, EPI)。其中 EPI 量化深度图与 RGB 边缘对齐,用于 AR/VR 场景。
和单目深度估计的比较
-
单目与双目深度估计的核心差异体现在几何约束的获取方式和数据标注依赖度上。单目方法仅依靠单张图像的语义先验 (如物体尺寸、遮挡关系、纹理梯度) 和场景理解,通过端到端网络学习图像到深度的非线性映射。由于缺乏物理视差,其深度估计存在固有尺度模糊性 , 需要通过相对误差指 标 (如AbsRel、RMSE log) 补偿全局深度偏差。例如,单目模型在弱纹理区域 (如白墙或天空) 可通过语义推理弥补几何信息缺失,但这种依赖导致其远距离误差随距离呈指数增长。相比之下,双目系统基于左右视图的像素匹配计算视差,结合相机基线长度与焦距参数直接推导绝对深度,使得几何精度可达厘米级。实验数据显示,双目系统的误匹配占比 D1-all 较低,边缘保持度 (EPI) 指标验证了其深度图与 RGB 图像的高精度对齐特性。
-
从数据依赖角度看,单目监督学习需依赖 NYU Depth、KITTI 等标注数据集,而无监督方法需借助视频序列或双目对生成伪标签。而双目方法仅需相机标定参数,无需深度真值,但对双目相机的外参标定误差极其敏感,1% 的基线偏差可导致深度误差放大10 倍。实际应用中,单目系统凭借单摄像头部署优势,广泛应用于手机、无人机等轻量化设备,而双目系统在自动驾驶近距避障等场景具有不可替代性,其动态物体鲁棒性显著优于单目方法。
-
发展趋势上,单目技术正通过多模态融合 (如ZoeDepth 联合语义分割与 IMU 时序数据 ) 和无监督创新 (如 Marigold 扩散模型 ) 提升跨域泛化能力。双目方向则聚焦轻量化设计,同时探索事件相机解决运动模糊下的视差计算难题。两类技术未来将向多传感器协同演进,例如 LiDAR 辅助标定可有效缓解单目尺度模糊性,而双目与 ToF 相机的融合能突破传统几何计算的范围限制。
-
对比维度 单目深度估计 双目深度估计 几何约束 依赖语义先验(物体尺寸、遮挡关系) 依赖立体匹配视差 + 相机参数(基线、焦距) 尺度特性 存在固有尺度模糊性 可直接推导绝对深度,精度达厘米级 数据依赖 监督学习需标注数据,自监督需视频 / 双目对 无需深度真值,依赖相机标定参数(1% 基线偏差致 10 倍深度误差) 部署优势 单摄像头,轻量化,适用于移动端 / 无人机 双摄像头,高精度,适用于自动驾驶 / 工业测量 关键指标 AbsRel、RMSE log、SILog(相对误差 / 尺度无关) D1-all、EPI、端点误差(几何一致性 / 边缘对齐)
应用场景
-
双目深度估计在三维显示场景下的应用核心在于通过模拟人类双眼的立体视觉机制,将二维图像转化为具有深度信息的三维模型,从而增强沉浸感和交互的真实性。其技术基础源于双目相机的视差计算,这一过程不仅能够还原物体的三维几何结构,还可通过稠密深度图实现高精度的空间重建,例如在虚拟现实 (VR) 中构建动态环境或在增强现实 (AR) 中实现虚实融合的精准叠加。
-
在 3D 电影与全息显示领域,双目深度估计通过生成左右眼差异图像,配合偏振或主动快门式 3D 眼镜,使观众感知到物体的前后层次。例如,ZED 2i 双目相机结合地平线开发的 StereoNet 算法 ,实时输出视差数据并通过 BPU 加速渲染,能够在动态场景中呈现细腻的深度细节,如光线变化区域的精准区分。这种技术还被用于全景影院的无框显示设计,通过消除传统屏幕边界限制,利用空气透视和重叠暗示增强立体感。
-
然而,实际应用中仍需克服硬件校准的稳定性问题。双目系统要求摄像头在长期使用中保持严格的共面行对齐,微小的机械偏移会导致深度计算误差。此外,低纹理区域 (如大面积纯色墙面) 的特征匹配困难可能引发“黑洞”伪影,需依赖深度学习模型的多尺度损失函数优化。未来,随着 Transformer 架构的引入,全局感受野的扩展将进一步改善复杂场景下的深度一致性,例如 DPT 模型 通过多尺度结构同时保证局部精度与全局连贯性。
-
尽管双目系统依赖精确的相机标定参数,但近年来动态在线标定技术的突破显著提升了系统鲁棒性。基于特征流形学习的自标定算法和更前沿的惯性-视觉融合方案等技术进步有效缓解了传统双目系统对初始标定精度的敏感性,推动双目视觉从实验室精密测量向户外动态场景的规模化落地。
-
在工业设计与医疗成像中,双目深度估计支持高分辨率三维重建。例如,飞桨的 PaddleDepth 套件通过激光雷达稀疏数据补全和图像超分辨技术,生成可用于手术导航的稠密器官模型。而在智能制造中,双目系统可实时捕捉机械臂操作轨迹,结合深度图解析实现毫米级精度的自动化装配。这些应用不仅依赖于算法优化,还需结合传感器融合 (如 ToF 设备) 弥补单一模态的局限性,形成多维度感知体系。通过持续的技术迭代,双目深度估计正成为连接虚拟与现实空间的关键桥梁。
结论
-
单目与双目深度估计技术近年来不断发展。单目方法通过端到端深度学习架构 (如多尺度特征融合、注意力机制) 实现无需几何先验的深度推理,显著提升了对弱纹理区域的语义理解能力,代表性工作通过引入虚拟法线约束和概率建模缓解了尺度模糊性问题。双目技术则围绕立体匹配核心任务展开革新,基于代价体积构建的 3D 卷积网络优化了视差估计精度,而动态场景下的匹配鲁棒性通过光流-视差联合学习框架得到增强。
-
近年来,两类技术的协同创新尤为突出,单目分支通过语义分割多任务学习为双目匹配提供场景先验,双目系统则以几何一致性损失引导单目模型实现自监督尺度恢复,形成双向知识迁移的闭环优化。此外,神经辐射场与 Transformer 架构的引入,推动了多视角几何重建与全局上下文建模的深度融合,标志着算法从局部特征匹配向整体三维感知的范式升级。
-
在三维显示领域,深度估计技术正成为虚实融合的关键使能者。单目方法凭借轻量化优势,将推动移动端三维交互设备的普及。例如 AR 眼镜 可通过实时深度感知实现虚拟物体的物理遮挡与光照一致性渲染。Vision Pro 等头显设备利用单目深度重构空间拓扑以增强虚实融合沉浸感。双目技术则为高精度三维重建提供支撑,在数字孪生、全息投影等场景中,其亚像素级视差计算能力可生成毫米级精度的立体模型,配合神经辐射场实现动态场景的光场重建。值得关注的是,基于扩散模型的深度生成技术通过提升弱纹理区域的深度连续性,显著改善了体积显示器的动态渲染质量,而多教师蒸馏框架则降低了三维内容生成对标注数据的依赖,加速了文化遗产数字化等长尾场景的应用落地。
-
未来研究可能聚焦方向包括:多传感器融合框架下的自适应深度估计 ;轻量化模型设计与边缘计算优化;跨域评估基准构建以提升复杂环境适应性;算法可解释性增强与物理规律耦合。随着三维视觉技术持续突破,单/双目深度估计将在智能制造、自动驾驶等领域推动 AI 向三维认知演进。
-
单目与双目深度估计的核心技术路径差异体现在几何约束来源与数据依赖度:①单目深度估计依赖单张图像的语义先验与数据驱动学习,通过端到端深度学习架构(如 ViT、Mamba)突破传统几何限制,自监督范式无需真实深度标注;②双目深度估计模拟人眼立体视觉,通过立体图像对的视差计算推导绝对深度,核心是代价体积构建与三维卷积优化。主要技术瓶颈:单目存在尺度模糊性,对动态物体和弱纹理区域鲁棒性不足,跨域泛化能力弱;双目对相机标定参数敏感(1% 基线偏差致 10 倍深度误差),弱纹理区域易产生匹配歧义,硬件部署需保持严格共面行对齐。
-
深度估计技术在三维显示领域的核心应用场景有①移动端 AR/VR 设备(如 Apple Vision Pro):依赖单目技术的轻量化优势,通过实时空间拓扑重建实现虚拟物体物理遮挡与光照一致性渲染;②高精度全息投影 / 数字孪生:依赖双目技术的毫米级深度精度,通过亚像素级视差计算实现动态光场重建;③三维内容生成与消费电子:单目技术(如 Metric3D v2)支持单帧图像即时 3D 重建,扩散模型(如 MARIGOLD)提升体积显示器渲染质量;④工业 / 医疗三维重建:双目技术(如 PaddleDepth 套件)结合激光雷达补全,生成手术导航 / 机械臂装配所需的稠密高精度模型。
案例
-
手机端部署的核心约束是算力有限、功耗敏感、摄像头硬件固定,需选择 “轻量 + 实时 + 高精度” 的算法,同时匹配单 / 双摄硬件。优先根据手机摄像头配置选择方案:双摄手机选双目方案(直接输出绝对深度,精度更高),单摄手机选单目 + 尺度校准方案(适配性广) 。算法选型聚焦轻量、实时、高精度的成熟模型(ZoeDepth-Lite、MiDaS v4、StereoNet-Lite),部署通过 “标定→轻量化→转换→集成→优化” 五步流程,核心重点是相机标定与模型量化,细节需兼顾相机参数稳定性与光照鲁棒性
-
手机硬件 推荐方案 核心优势 适用场景 单摄 单目深度估计 + 尺度校准 适配所有手机,部署成本低 普通消费级手机、对精度要求中等(误差 < 8%)场景 双摄(主摄 + 副摄,基线 > 5cm) 双目深度估计 直接输出绝对深度,无尺度模糊,精度高 中高端手机、对精度要求高(误差 < 5%)场景(如测距、AR 交互)
-
-
部署流程按 “基本操作(必做)→ 重点步骤(决定精度 / 延时)→ 增益优化(可选提升) ” 分层,全程围绕 “低延时、高精度” 目标:
- 基本操作(必做,落地基础)
- 相机参数标定:单目:通过手机 API 获取内参(焦距 f、主点坐标 cx/cy),或用 OpenCV 标定工具(打印棋盘格,拍摄 10~15 张图自动标定);双目:额外标定外参(基线长度 B、旋转矩阵 R、平移向量 T),双摄手机可优先调用厂商提供的标定参数(精度更高)。
- 算法轻量化预处理:裁剪模型:移除冗余层(如 DPT 的高层 Transformer 模块),保留核心卷积层,调整输入分辨率:单目默认 640x480,双目默认 320x240(根据手机性能动态调整)
- 模型格式转换:流程:PyTorch 模型 → ONNX(简化算子) → TensorFlow Lite/Core ML(移动端适配),工具:PyTorch→ONNX(torch.onnx.export),ONNX→TFLite(onnx-tf),ONNX→Core ML(coremltools)
- 移动端集成:安卓:Java/C++ 调用 TFLite,配置 NNAPI 加速(需在 Manifest 中声明硬件加速权限),iOS:Swift 调用 Core ML,启用 Metal 加速(设置 computeUnits = .cpuAndGPU)
- 基础后处理:异常值过滤:剔除深度图中 > 5m 或 < 0.3m 的异常值(手机摄像头有效测距范围),高斯平滑:用 3x3 高斯核过滤噪声(耗时 < 1ms,不影响延时)
- 基本操作(必做,落地基础)
-
重点步骤(核心,决定精度与延时)
- 尺度校准(单目方案关键):
- 方法:已知物体尺寸(如信用卡宽度 8.6cm),拍摄时让物体占满图像固定区域,计算尺度因子 s = (实际尺寸 × 焦距) / (像素尺寸 × 预测深度);工具:开发简易校准界面,用户拍摄 1 张已知尺寸物体的图像,自动计算并存储尺度因子;细节:避免用动态物体校准,选择高对比度、纹理清晰的物体(如书本、卡片)
- 模型量化优化(低延时关键):
- 量化方式:INT8 量化(较 FP32 精度损失 < 3%,速度提升 2~3 倍),避免 FP16 量化(手机 GPU 支持有限);工具:TensorFlow Lite Converter(TFLite 量化)、Core ML Quantization(iOS 量化);验证:量化后需测试精度,若误差超 10%,采用混合量化(关键层 FP16,其他层 INT8)
- 双目外参精校准(双目方案关键):
- 问题:手机双摄基线短(通常 5~8cm),1% 基线误差会导致 10 倍深度误差;解决方案:用张正友标定法重新标定,拍摄 20 张不同角度的棋盘格图像,优化外参精度;工具:OpenCV calibrateStereoCamera 函数,或 PaddleDepth 提供的双目标定工具包
- 尺度校准(单目方案关键):
-
增益优化操作(可选,进一步提升性能)
-
实时性优化:
- 算子融合:用 TensorRT(安卓)或 Core ML Optimizer(iOS)融合卷积 + BN 层,减少计算量,动态分辨率适配:简单场景(如室内墙面)用 320x240 输入,复杂场景(如街道)自动切换到 640x480,推理间隔控制:视频流中每 3 帧推理 1 次,中间帧用前向插值填充(延时降低 50%,精度损失 < 2%)
-
精度优化:
- 多帧融合:取连续 3 帧深度图的中位数,过滤动态物体噪声(如行人、晃动的物体),语义辅助:集成轻量语义分割模型(如 MobileNetV2-Seg),区分物体类别(如人脸、桌面),用对应类别默认尺寸修正尺度,光照自适应:预处理时加入亮度归一化(将图像亮度调整到 [120, 180] 区间),提升弱光 / 强光场景鲁棒性
-
功耗优化:
- 安卓:设置 TFLite 推理线程数 = 2(避免占用全部 CPU 核心),iOS:Core ML 推理时禁用 CPU 大核,优先使用小核 + GPU(功耗降低 30%)
单目传统距离估计算法
-
线性透视法算法原理:基于 “物体尺寸随距离增加而缩小” 的几何规律,利用图像中平行线汇聚(如道路边缘、建筑轮廓)的消失点,结合投影几何关系反推目标距离。
- 步骤流程:从图像中提取线性特征(如道路边缘、栏杆线条);计算特征线的交点,确定消失点坐标;结合已知物体的实际尺寸(如标准道路宽度)或图像像素尺寸,通过透视投影公式推导目标距离。
- 优缺点:优点:计算量极小(仅几何运算),延时 < 1ms,无需训练数据,硬件适配性强;缺点:依赖场景中存在明显线性特征,无纹理区域(如天空、白墙)失效,距离精度随目标远离快速下降。
- 适配场景:无人机低空飞行(高度 < 100m)、结构化场景测距(如城市道路、农田田埂、建筑区域),用于快速避障或粗略定位。
- 局限:动态场景(如移动的树木)中线性特征易混淆,极端光照(强光 / 逆光)下特征提取失败,无法输出稠密深度图。
-
大气散射法算法原理:利用空气中颗粒物对光线的散射效应,RGB 图像中物体色彩随距离增加会出现衰减(远距物体偏灰、对比度降低),建立 “深度 - 色彩衰减” 的映射关系反推距离。
- 步骤流程:对图像进行色彩归一化,提取 RGB 三通道的亮度值;计算目标区域与近距参考区域的色彩对比度差异;代入预定义的色彩衰减模型(基于大气散射系数),求解目标距离。
- 优缺点:优点:无需依赖几何特征,对部分弱纹理区域(如草地、浅色墙面)有效,计算延时 < 5ms;缺点:受光照条件影响极大(阴天 / 夜晚色彩衰减不明显),极端天气(雾、雨)下泛化能力差,距离误差随大气能见度波动。
- 适配场景:无人机晴天户外测距、开阔场景(如平原、湖面)中远距离粗略测距(50-200m)。
- 局限:无法区分 “远距离导致的色彩衰减” 与 “物体本身颜色暗淡”,近距离(<50m)精度极低,不适用于室内或遮挡场景。
-
运动恢复结构(SFM)算法原理:通过无人机飞行过程中相机的连续移动,利用多帧图像的特征匹配的几何约束,重建稀疏 3D 点云,间接获取目标距离。
-
步骤流程:用 SIFT/SURF 算法提取相邻帧图像的关键点(如物体角点、纹理特征点);建立跨帧关键点的对应关系,通过基础矩阵估计相机位姿(位置、姿态);采用光束法平差(Bundle Adjustment)非线性优化相机参数与 3D 点坐标,最小化重投影误差;从 3D 点云中提取目标点的坐标,计算与相机的距离。
-
优缺点:优点:无需已知物体尺寸,能生成稀疏 3D 结构,适配无明显线性特征的场景(如树林、障碍物集群),延时 < 20ms(适用于无人机低速飞行);缺点:依赖静态场景假设,动态物体(如飞鸟、行人)会导致特征匹配错误,弱纹理区域关键点提取不足,3D 点云稀疏(仅特征点有深度)。
-
适配场景:无人机低速测绘、静态障碍物(如树木、建筑)测距避障、低空侦察(速度 < 10m/s)。
-
局限:无人机高速飞行时帧间位移过大,特征匹配失效;无纹理区域(如水面、雪地)无法生成 3D 点,距离估算中断。
-
-
-
阴影恢复形状(SFS)算法原理:假设场景满足 Lambertian 反射模型(物体亮度与光源入射角相关),通过单帧图像中物体的阴影分布,反推表面法向量,积分得到深度(距离)信息。
- 步骤流程:设定光源参数(假设为平行光或点光源,需预先已知方向 / 强度);从图像中提取阴影区域与光照区域的亮度梯度;迭代优化求解物体表面法向量场;对法向量积分,生成深度图并计算目标距离。
- 优缺点:优点:能从无纹理物体(如球体、平面障碍物)的阴影中获取深度,计算逻辑简单;缺点:对噪声敏感,光源参数未知时精度骤降,迭代过程延时略高(20-50ms),仅适用于简单形状物体。
- 适配场景:无人机近距离(<30m)、单一光源场景(如晴天正午)下的规则障碍物测距(如箱体、墙体)。
- 局限:复杂光源(多云、傍晚)或无阴影场景(如阴天)完全失效,动态物体阴影易变形,无法适配无人机高速移动场景。
-
SFM(运动恢复结构)算法的核心局限是单帧图像无法恢复绝对深度(需多帧相机运动产生的视差),因此完整 baseline 需输入至少 2 帧有重叠区域的连续图像(如无人机飞行时的相邻帧),通过 “特征匹配→相机位姿估计→3D 点云重建→尺度校准→绝对距离计算” 五步实现。以下是可直接落地的工程化 baseline,基于 OpenCV+COLMAP 构建,兼顾实时性与精度,适配无人机 / 移动端测距场景。
- 输入:2 帧及以上连续图像(帧间重叠率≥60%,相机运动平稳,无剧烈抖动),拍摄目标为静态主体(如建筑、树木、障碍物)。
- 已知条件:相机内参(焦距 f、主点 cx/cy,可通过标定获取);可选辅助信息(已知目标物体尺寸,用于尺度校准)。
- 约束:帧间位移≤图像宽度的 1/3(保证特征匹配成功率),光照变化小(避免特征提取失效)。
-
输入:连续图像序列(示例:2 帧 RGB 图像,分辨率 640×480)、相机内参矩阵 K、可选已知物体尺寸(如目标宽度 W=2m)。
-
输出:相机到拍摄主体中心的绝对距离(单位:m),精度 ±5%(中短距离 0.5~50m),延时≤100ms(2 帧处理)。
-
SFS(阴影恢复形状)算法的核心优势是单张图像即可恢复深度,无需多帧运动或双摄硬件,完美适配单图输入场景;其通过 “光照 - 阴影 - 表面法向量 - 深度” 的几何推理,结合 Lambertian 反射模型实现深度估计。基于 “预处理→光源估计→法向量求解→深度重建→尺度校准→距离计算” 六步流程,适配静态、弱纹理主体测距
- 拍摄主体:静态物体,表面近似满足Lambertian 反射模型(漫反射,亮度与光源入射角正相关)。
- 光照条件:单光源或主光源明确(如晴天正午、室内单点光源),无强反光或复杂阴影叠加。
- 可选 —— 主体实际尺寸(如宽度、高度);或能通过目标检测识别常见物体(如人脸、书本,调用默认尺寸库)。
- 约束:图像无严重噪声、运动模糊,主体占比≥10%(避免弱纹理区域过多)。
- 输入:单张 RGB 图像(分辨率 640×480~1920×1080)、相机内参(焦距 f、主点 cx/cy,可标定或调用设备默认值)、可选主体实际尺寸(如 W=0.5m)。
- 输出:相机到拍摄主体中心的绝对距离(单位:m)
-
-
模块 1:图像预处理(基础操作,保障后续精度)
-
降低噪声、增强阴影梯度,为法向量求解提供清晰特征。去噪:3×3 高斯滤波(平衡噪声抑制与细节保留)。灰度转换:RGB→灰度图(简化光照计算,减少冗余信息)。阴影增强:自适应直方图均衡化(CLAHE),提升阴影区域与光照区域的对比度。关键参数:clipLimit=2.0(避免过度增强导致伪影),tileGridSize=(8,8)(局部对比度优化)。
-
import cv2 import numpy as np # 读取单张输入图像 img = cv2.imread("target.jpg") img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度转换 # 预处理:高斯去噪+CLAHE增强 img_denoised = cv2.GaussianBlur(img_gray, (3, 3), 0.8) # 高斯滤波,sigma=0.8 clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)) # CLAHE参数 img_enhanced = clahe.apply(img_denoised) # 阴影增强
-
-
模块 2:光源参数估计(核心前提,SFS 算法的 “灵魂”)
-
核心问题:SFS 依赖光源方向(θ, φ)和强度 I,若未知需先从图像中估计(已知则直接输入)。
-
估计方法(单光源假设,工程化首选梯度法):计算图像梯度(x/y 方向):用 Sobel 算子提取亮度变化梯度,梯度方向与光源方向强相关。光源方向求解:假设主体表面为 “局部平面”,通过梯度统计拟合光源方向(θ 为天顶角,φ 为方位角)。光源强度估计:取图像中最亮区域(无阴影)的灰度值作为参考,归一化得到强度 I∈[0,1]。关键细节:若已知光源(如室内固定光源),可直接输入 light_dir 和 I,跳过估计步骤(精度提升 30%)。
-
# 步骤1:计算图像梯度(x/y方向) sobel_x = cv2.Sobel(img_enhanced, cv2.CV_64F, 1, 0, ksize=3) # x方向梯度 sobel_y = cv2.Sobel(img_enhanced, cv2.CV_64F, 0, 1, ksize=3) # y方向梯度 grad_mag = np.sqrt(sobel_x**2 + sobel_y**2) # 梯度幅值(亮度变化强度) # 步骤2:估计光源方向(θ:天顶角,φ:方位角,单位:弧度) # 核心逻辑:梯度方向的统计峰值对应光源方向(假设主体无强纹理) grad_dir = np.arctan2(sobel_y, sobel_x) # 梯度方向(-π~π) hist, bins = np.histogram(grad_dir, bins=36, range=(-np.pi, np.pi)) # 方向直方图 phi = bins[np.argmax(hist)] # 方位角(梯度峰值方向) theta = np.arctan2(np.mean(grad_mag), 255 - np.mean(img_enhanced)) # 天顶角(亮度均值推导) # 步骤3:估计光源强度(归一化到[0,1]) I = np.max(img_enhanced) / 255.0 # 最亮区域灰度值归一化 light_dir = np.array([np.sin(theta)*np.cos(phi), np.sin(theta)*np.sin(phi), np.cos(theta)]) # 光源方向向量(x,y,z)
-
-
模块 3:表面法向量求解(核心算法,从阴影反推表面方向)
-
算法选型:最小二乘迭代法(平衡精度与速度,适配实时场景),基于 Lambertian 反射模型:(I(x,y) = \rho \cdot I \cdot (n(x,y) \cdot L))。其中,ρ 为表面反射率,n 为表面法向量(单位向量),L 为光源方向向量。
-
实现步骤:反射率 ρ 估计:假设主体表面反射率均匀,取无阴影区域的亮度均值归一化。法向量初始化:设所有像素法向量为 (0,0,1)(初始假设为平面)。迭代优化:通过最小二乘最小化 “预测亮度 - 实际亮度” 误差,更新法向量(加入平滑正则化,避免噪声干扰)。关键参数:max_iter=50(迭代 50 次即可收敛,再多无精度提升),lambda_smooth=0.01(避免法向量突变)。
-
# 步骤1:估计表面反射率ρ(均匀反射假设) rho = np.mean(img_enhanced[grad_mag < 10]) / 255.0 # 弱梯度区域(无阴影)的平均反射率 rho = max(rho, 0.1) # 避免反射率过小导致数值不稳定 # 步骤2:初始化法向量(n = (nx, ny, nz),单位向量) height, width = img_enhanced.shape nx = np.zeros((height, width), dtype=np.float64) ny = np.zeros((height, width), dtype=np.float64) nz = np.ones((height, width), dtype=np.float64) # 初始为平面法向量(0,0,1) # 步骤3:迭代优化法向量(迭代次数=50,平衡精度与速度) max_iter = 50 lambda_smooth = 0.01 # 平滑正则化系数(抑制噪声) img_norm = img_enhanced / 255.0 # 图像亮度归一化 for _ in range(max_iter): # 预测亮度:I_pred = rho * I * (nx*Lx + ny*Ly + nz*Lz) I_pred = rho * I * (nx * light_dir[0] + ny * light_dir[1] + nz * light_dir[2]) error = I_pred - img_norm # 亮度误差 # 最小二乘更新法向量(梯度下降) dx = error * light_dir[0] dy = error * light_dir[1] dz = error * light_dir[2] # 平滑正则化(邻域平均) nx_smooth = cv2.GaussianBlur(nx, (3,3), 1.0) ny_smooth = cv2.GaussianBlur(ny, (3,3), 1.0) nz_smooth = cv2.GaussianBlur(nz, (3,3), 1.0) # 更新法向量 nx = nx_smooth - 0.001 * dx ny = ny_smooth - 0.001 * dy nz = nz_smooth - 0.001 * dz # 归一化法向量(保持单位向量) norm = np.sqrt(nx**2 + ny**2 + nz**2 + 1e-8) nx /= norm ny /= norm nz /= norm
-
-
模块 4:深度图重建(从法向量到深度,积分求解)
-
核心逻辑:表面法向量与深度图的梯度满足几何关系 (\nabla z = (-\frac{nx}{nz}, -\frac{ny}{nz})),通过积分恢复深度 z(相对尺度)。积分方法:泊松积分(精度优于简单累加,保留深度连续性)。关键细节:泊松积分通过求解偏微分方程,保证深度图的全局连续性,避免弱纹理区域出现 “深度空洞”。
-
# 计算深度梯度(dz/dx = -nx/nz,dz/dy = -ny/nz) dz_dx = -nx / (nz + 1e-8) # 避免nz=0导致除零 dz_dy = -ny / (nz + 1e-8) # 泊松积分恢复深度图(相对尺度) def poisson_integration(dz_dx, dz_dy): # 构建泊松方程:∇²z = ∇·(dz_dx, dz_dy) laplacian = cv2.Laplacian(dz_dx, cv2.CV_64F) + cv2.Laplacian(dz_dy, cv2.CV_64F) # 求解泊松方程(Dirichlet边界条件:边缘深度=0) z = cv2.inpaint(laplacian, np.zeros_like(laplacian, dtype=np.uint8), 3, cv2.INPAINT_NS) # 归一化深度图(相对尺度) z = (z - np.min(z)) / (np.max(z) - np.min(z) + 1e-8) return z depth_rel = poisson_integration(dz_dx, dz_dy) # 相对深度图(0~1,无单位)
-
-
模块 5:尺度校准(关键步骤,从相对深度到绝对深度)
-
核心问题:SFS 得到的深度图是相对尺度(仅反映 “深浅关系”),需引入绝对尺度信息才能计算真实距离。
-
校准方法(适配单图场景):方法 1:已知主体实际尺寸(推荐)。步骤:用目标检测(如 YOLOv8-nano)框选主体,得到主体在图像中的像素范围;在相对深度图中提取主体区域的深度值,计算主体 “深度方向长度” 或 “横向宽度对应的深度跨度”,结合实际尺寸推导尺度因子。方法 2:语义辅助(无已知尺寸时)。步骤:用轻量语义分割(如 MobileNetV2-Seg)识别主体类别(如人脸、书本),调用预定义尺寸库(如人脸宽度默认 0.15m、A4 纸宽度 0.21m),按方法 1 推导尺度因子。关键细节:若主体是平面(如墙面),可通过 “图像中主体的像素尺寸 × 焦距 / 实际尺寸” 辅助验证尺度因子,提升精度。
-
# 步骤1:目标检测框选主体(简化:手动框选,实际用YOLOv8自动检测) # 假设主体的图像坐标:x1=100, y1=80, x2=300, y2=280(左上角→右下角) x1, y1, x2, y2 = 100, 80, 300, 280 target_depth_rel = depth_rel[y1:y2, x1:x2] # 主体区域的相对深度 # 步骤2:计算主体在相对深度图中的“宽度对应的深度跨度” # 逻辑:主体横向(x轴)的深度变化对应实际宽度 target_center_y = (y1 + y2) // 2 # 主体中心行 depth_profile = target_depth_rel[target_center_y, :] # 中心行的深度剖面 d_rel = np.max(depth_profile) - np.min(depth_profile) # 相对深度跨度 d_rel = max(d_rel, 0.01) # 避免跨度为0 # 步骤3:计算尺度因子s(m/相对单位) W = 0.5 # 已知主体实际宽度(m) s = W / d_rel # 尺度因子 # 步骤4:得到绝对深度图(单位:m) depth_abs = depth_rel * s
-
-
模块 6:绝对距离计算(最终目标)
-
核心逻辑:相机到主体中心的距离 = 主体中心的绝对深度值 × 相机焦距相关修正(简化模型:假设主体中心深度近似为相机到主体的直线距离)。
-
实现步骤:提取主体区域的绝对深度,计算深度均值(代表主体中心深度)。结合相机内参修正(若主体倾斜,需用透视投影修正,简化场景可忽略)。
-
# 步骤1:计算主体区域的绝对深度均值(主体中心深度) target_depth_abs = depth_abs[y1:y2, x1:x2] z_center = np.mean(target_depth_abs) # 主体中心绝对深度(m) # 步骤2:相机到主体的绝对距离(简化:忽略主体倾斜,z_center≈实际距离) # 若需精确修正:distance = z_center / cos(alpha),alpha为主体倾斜角(需额外估计) distance = z_center print(f"相机到拍摄主体的绝对距离:{distance:.2f}m")
-
-
光源参数是核心瓶颈:光源方向估计误差 > 10° 时,深度误差会翻倍。解决方案:优先使用已知光源参数;未知时,选择光源方向单一的场景(如晴天正午、室内顶光)。非 Lambertian 表面失效:强反光物体(如金属、玻璃)不满足漫反射假设,会导致深度偏差 > 20%。解决方案:语义分割识别反光物体,切换至备用算法(如线性透视法)。弱纹理 + 无阴影场景无解:完全无阴影的物体(如均匀光照下的白墙),无法反推法向量。解决方案:结合线性透视法补充深度信息,加权融合结果。尺度校准不可省略:无绝对尺度时,SFS 仅能输出相对深度,无法计算真实距离。解决方案:强制用户输入主体尺寸,或自动识别常见物体(如人脸、手机)调用默认尺寸。
-
针对端侧部署深度估计模型与摄像头到获图平面绝对距离计算的需求,目前已形成 “轻量化模型选型 + 尺度恢复技术 + 端侧优化适配” 的完整技术体系,其中单目方案因硬件成本低、部署灵活成为端侧主流,双目方案则在高精度场景中不可替代。结合端侧约束(低算力、低功耗、实时性)与绝对距离计算核心(解决尺度模糊性)展开:
- 单目方案的核心挑战是尺度模糊性(模型输出相对深度,需转化为绝对距离),端侧适配需兼顾 “模型轻量化” 与 “尺度恢复鲁棒性”,目前成熟方案可分为 “通用轻量模型 + 场景约束尺度恢复” 两类:
通用轻量单目深度模型(端侧部署成熟)
-
这类模型经过大规模数据训练,能稳定输出相对深度,配合简单尺度恢复即可实现绝对距离计算,且参数量小、推理速度快,适配手机、无人机、AR 眼镜等端侧设备。
-
模型 / 方案 核心原理 端侧适配性 绝对距离计算路径 效果指标(端侧) MiDaS(Small/Hybrid) 基于 ResNet/Vision Transformer 的编码器 - 解码器架构,多尺度特征融合捕捉深度细节,输出相对深度图。 官方提供 TFLite/Core ML 轻量化模型,参数量 4.8M(Small),支持 INT8 量化,安卓 /iOS 端 FPS>30(640×480 输入)。 需引入外部约束:1. 参考物校准(已知物体尺寸→计算尺度因子);2. 相机内参结合(焦距→关联像素尺寸与实际距离)。 KITTI 数据集:AbsRel<0.15,绝对距离误差 < 8%(0.5~30m)。 Depth Anything(Lite 版) 基于大规模无标注数据预训练,采用轻量化 CNN backbone,输出稠密相对深度,零样本泛化能力强。 参数量 8M,支持 ONNX/TFLite 部署,端侧推理延时 <50ms(骁龙 8 Gen2),适配手机、嵌入式设备。 1. 参考物校准(如 A4 纸宽度 0.21m→提取参考物相对深度→计算尺度因子 s = 实际尺寸 / 相对深度);2. 语义辅助(调用预定义尺寸库,如人脸宽度 0.15m)。 室内场景:绝对距离误差 <5%(1~10m);弱纹理区域连续性优于 MiDaS 。 Metric3D v2 提出 “统一相机空间变换模块”,解决不同相机的尺度模糊性,训练时将多源数据映射到标准相机空间,推理时直接输出绝对深度。 轻量化版本参数量 12M,支持 TensorRT 加速,端侧 FPS>25,无需额外尺度校准(模型内置绝对深度输出)。 模型直接输出绝对深度(单位:m),无需后处理:通过标准相机空间变换,消除焦距、传感器尺寸对尺度的影响。
场景约束型尺度恢复技术(提升绝对距离精度)
-
针对端侧常见场景(如室内、户外道路、AR 交互),结合场景固有约束(如地面、已知物体、相机高度),无需额外硬件即可实现鲁棒的绝对距离计算,是目前工程化落地的核心手段。
-
约束类型 核心技术 成熟度与端侧适配 应用场景 参考物约束 从图像中检测已知尺寸的物体(如人脸、信用卡、A4 纸),通过 “物体实际尺寸 / 图像像素尺寸” 计算尺度因子,缩放相对深度。 成熟度极高,配合轻量目标检测(YOLOv8-nano,延时 <10ms),端侧可实时实现;开源工具包(如 PaddleDepth)提供现成模块 。 消费电子(手机测距)、AR 测量(如测量书本厚度)。 地面约束 假设场景存在水平地面,通过深度图筛选地面点(表面法向量接近理想地面法向量),结合相机实际高度(如手机离地 1.5m)计算尺度因子。 工程化成熟,无需参考物,适配户外道路、室内地面场景;端侧通过简单法向量计算(3×3 卷积)实现,耗时 <5ms。 自动驾驶(车载端侧)、无人机低空飞行(离地高度校准)。 相机内参约束 利用端侧设备的内置相机参数(焦距 f、主点 cx/cy,可通过系统 API 获取),结合 “像素尺寸 - 实际尺寸” 几何关系(实际距离 =(物体实际尺寸 ×f)/(物体像素尺寸))。 适配所有带标定参数的端侧设备(手机、工业相机),无需额外计算,精度依赖内参准确性(误差 <2%)。 工业检测(如流水线工件测距)、AR 眼镜(虚实叠加校准)。 SLAM 融合约束 结合端侧轻量 SLAM(如 ORB-SLAM3-Lite),通过多帧深度估计结果优化相机位姿,同时恢复绝对尺度(如两帧间相机移动距离作为绝对参考)。 成熟度中等,端侧需搭配 IMU(多数手机 / 无人机内置),推理延时增加 10~20ms,但绝对距离误差可降至 <4%。 机器人导航、无人机测绘(动态场景)。
双目深度估计方案:端侧高精度首选,几何约束直接算绝对距离
-
双目方案通过立体匹配计算视差,结合相机基线(双摄间距)与焦距,可直接推导绝对深度(公式:绝对深度 = 基线 × 焦距 / 视差),无需额外尺度恢复,适合端侧高精度场景(如工业测量、自动驾驶近距避障)。
-
传统双目算法(端侧硬件友好),这类算法基于几何匹配,计算量小、无需训练,适配 FPGA/MCU 等低算力端侧硬件,是工业端侧的主流选择。
-
算法 核心原理 端侧适配性 绝对距离计算效果 SGBM(半全局匹配) 多方向动态规划聚合匹配代价,解决弱纹理区域歧义,输出稠密视差图。 开源实现(OpenCV-SGBM)支持 INT16 优化,端侧 FPGA/ARM Cortex-A 系列可实时运行(FPS>30,640×480 输入)。 基线 5~10cm 时,0.5~50m 距离误差 ❤️%,遮挡区域误匹配率 < 5%。 BM(块匹配) 滑动窗口计算局部像素相似性(SAD/SSD),实现快速视差估计 。 计算量最小(仅为 SGBM 的 1/5),适配低功耗端侧设备(如无人机 MCU),但弱纹理区域精度下降 。 基线 3~5cm 时,1~30m 距离误差 < 5%,适合简单纹理场景(如农田、建筑)。
-
-
轻量双目深度学习模型(精度优于传统算法),针对传统算法在复杂场景(如动态遮挡、弱纹理)的不足,深度学习模型通过特征学习提升鲁棒性,同时经轻量化优化后适配端侧。
-
模型 / 方案 核心原理 端侧适配性 绝对距离计算效果 StereoNet-Lite 基于引导分层细化架构,用轻量 CNN 提取特征,减少 3D 卷积计算量,输出亚像素级视差。 参数量 6.5M,支持 TensorRT 加速,安卓端 FPS>25(720×480 输入),PaddleDepth 提供端侧部署模板 。 KITTI 数据集:D1-all(误匹配率)❤️%,10~100m 距离误差 < 2%。 PSMNet-Tiny 裁剪金字塔立体匹配网络(PSMNet)的 SPP 模块与 3D 卷积层,保留多尺度特征融合。 参数量 9M,INT8 量化后推理速度提升 2 倍,端侧 GPU(如 Adreno 730)FPS>20 。 ETH3D 数据集:弱纹理区域距离误差 <4%,支持毫米级工业测量。 事件相机 + 双目融合 结合事件相机高动态范围、无运动模糊的优势,与双目相机融合,提升动态场景视差计算鲁棒性。 端侧需搭配轻量化事件处理模块(如 EVKIT),总延时 <60ms,适配自动驾驶、无人机高速移动场景。 动态场景(物体速度 <5m/s):距离误差 < 5%,运动模糊场景精度优于纯视觉双目 。
-
-
目前深度学习领域针对端侧绝对距离计算,已形成 “轻量模型 + 场景约束尺度恢复”(单目)、“轻量化双目模型 + 几何视差计算”(双目)两大成熟路径,配合模型压缩与硬件加速,可满足不同端侧场景的精度、实时性、功耗需求。其中单目方案以 Depth Anything-Lite、Metric3D v2 为代表,适配硬件简单的消费电子;双目方案以 StereoNet-Lite、SGBM 为代表,适合高精度工业 / 自动驾驶场景;前沿研究则聚焦多传感器融合与高效架构,进一步拓展端侧应用边界。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)