TY-RIST:用于实时红外小目标检测的战术YOLO技巧
尽管红外小目标检测(IRSTD)对于国防和监视至关重要,但由于以下原因,它仍然是一项具有挑战性的任务:(1) 目标特征极少导致目标丢失,(2) 复杂环境中的虚警,(3) 低显著性导致的漏检,以及 (4) 高计算成本。为了解决这些问题,我们提出了 TY-RIST,一种优化的 YOLOv12n 架构,具有以下特点:(1) 具有细粒度感受野的步长感知骨干网络,(2) 高分辨率检测头,(3) 级联坐标注意
摘要
尽管红外小目标检测(IRSTD)对于国防和监视至关重要,但由于以下原因,它仍然是一项具有挑战性的任务:(1) 目标特征极少导致目标丢失,(2) 复杂环境中的虚警,(3) 低显著性导致的漏检,以及 (4) 高计算成本。为了解决这些问题,我们提出了 TY-RIST,一种优化的 YOLOv12n 架构,具有以下特点:(1) 具有细粒度感受野的步长感知骨干网络,(2) 高分辨率检测头,(3) 级联坐标注意力块,以及 (4) 一种分支修剪策略,可将计算成本降低高达 ~25.5%,同时略微提升性能并实现实时推理。此外,我们引入了归一化高斯 Wasserstein 距离(NWD)以提高回归稳定性。在四个基准测试和跨越 20 个不同模型上的大量实验证明了其最先进的性能,将 mAP@50 提高了 +7.9%,精确度提高了 +3%,召回率提高了 +10.2%,同时在单个 GPU 上运行速度高达 ~123 FPS。在第五个数据集上的跨数据集验证进一步证实了其强大的泛化能力。更多结果和细节发布于 https://github.com/moured/TY-RIST。.

图 1. 我们的模型 TY-RIST 与基线的定性比较,展示了步长缩减、更高分辨率的特征图 (C2)(C_{2})(C2) 及其检测头 (P2)(P_{2})(P2) 以及模型修剪的效果。绿色框表示真阳性;红色框表示假阴性。
1. 引言
在目标检测领域,小目标被正式定义为占据图像总面积少于 0.5%、表现出弱对比度(通常低于 0.15)且具有低信噪比(SNR)的物体[2]。IRSTD 专注于检测嵌入在杂乱和嘈杂红外背景中的小且通常移动的目标。IRSTD 对于关键应用具有重要意义,包括军事侦察[29]、交通监控和管理[43]以及海上搜救行动[30]。然而,由于几个固有的困难,IRSTD 仍然是一项极具挑战性的任务。首先,目标的最小尺寸和弱信号强度常常导致关键特征的丢失,影响可靠检测。其次,杂乱或有纹理的背景导致高虚警率。第三,低目标显著性和对比度常常导致漏检。第四,先进检测框架的高计算需求限制了其在实时应用中的实际部署。
IRSTD 方法根据特征利用、问题表述和算法方法进行分类。关于特征提取,算法分为单帧方法(SIRST)[49],它处理单帧的空间特征,以及多帧方法(MIRST)[24],它利用视频序列中的时间特征来以增加的计算成本为代价增强检测性能。从问题表述的角度来看,SIRST 实现可以采用基于检测的范式[49]或基于分割的方法[16]。另一方面,由于缺乏合适的基于多帧分割的数据集,MIRST 迄今为止仅被表述为一个检测问题。在算法上,虽然诸如滤波[1]和局部对比度增强[11]之类的经典技术展示了计算效率,但它们对专家驱动的参数调整的依赖性限制了其泛化能力。
相比之下,基于深度学习的方法最近在 IRSTD 中取得了显著成功,在复杂的红外场景中提供了高精度和强泛化能力。其中,基于 YOLO 的检测器[18, 49]由于能够有效平衡检测性能和实时推理效率而受到广泛关注。YOLOv12 [31]是 YOLO 系列的最新进展,引入了一种新颖的注意力机制——区域注意力(Area Attention),它增强了特征表示,超越了传统的卷积架构,同时保持了有竞争力的推理速度。
我们提出了 TY-RIST(用于实时红外小目标检测的战术 YOLO 技巧),这是一个基于 YOLOv12n 基线的统一框架,解决了上述挑战。首先,我们引入了一个步长感知卷积骨干网络,以构建细粒度的感受野,从而改善空间定位。其次,我们添加了一个高分辨率特征图和一个专用的微小目标检测头,以抑制虚警。第三,我们在新添加的检测头上集成了级联坐标注意力(CA)[14]块,以减少漏检。第四,我们用 NWD [35] 替换了经典的完全交并比(CIoU)[46]损失,以提高回归稳定性和收敛性,解决了边界框回归对红外小目标的敏感性问题。第五,我们通过修剪冗余分支来优化架构,实现了高达 ~25.5% 的 GFLOPs 减少和高达 ~25.6% 的参数数量减少,同时提供了性能的渐进式改进并以实时速度运行。图 1 定性说明了所提出的一些实验对模型性能的影响,展示了减少的漏检和实时推理能力。
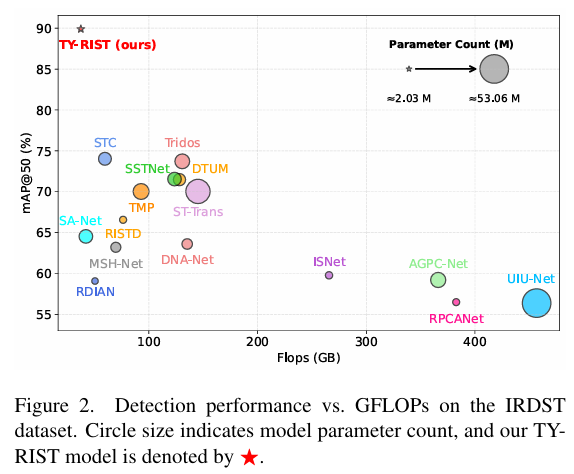
我们在两个多帧基准(ITSDT15k [50] 和 IRDST [28])和两个单帧基准(NUAA-SiRST [6] 和 NUDT-SIRST [16])上评估了我们的模型,在 ITSDT15k 基准上,mAP@50 提高了高达 7.9%,精确度提高了 3%,召回率提高了 10.2%。此外,我们的模型在四个基准测试中(IRDST 基准的结果如图 2 所示)优于 14 个 SIRST 和 6 个 MIRST 的最先进(SOTA)算法,同时在单个 NVIDIA RTX3080Ti GPU 上保持高达 ~123 FPS 的实时推理速度。最后,在未见过的 IRDST-1k [44] 基准上进行的跨数据集验证证实了强大的泛化能力。
2. 相关工作
2.1. 数据驱动的 SIRST 范式
基于学习的 SIRST 方法通过利用注意力机制、高级特征建模和上下文推理,已成为 IRSTD 的主导方法。通道和空间注意力模块[6, 16, 40, 44, 45, 48]增强了精细细节、形状线索和全局-局部相关性。其他方法集成了多尺度和混合特征提取[13,28, 37,38, 41]以更好地捕捉微小目标。最近的工作也强调数据集和损失设计,包括负样本增强[23]和具有新颖损失的多尺度头[21],表明架构和数据中心的创新同样重要。
2.2. 数据驱动的 MIRST 范式
多帧 SIRST 方法通过利用序列中的时间特征来增强检测,这有助于抑制虚警和增强弱目标。基于 ConvLSTM 的时空融合网络[3, 9, 19, 50]捕捉运动线索、互补特征和方向信息以加强时间一致性。受 Transformer 在视觉领域成功的启发[7],最近的工作将其扩展到 IRSTD,通过建模帧间依赖关系[32]或联合学习空间、时间和通道相关性[51]。虽然基于 Transformer 的模型实现了强大的性能,但它们的计算需求对实时部署提出了挑战。
3. 方法论
3.1. 整体架构
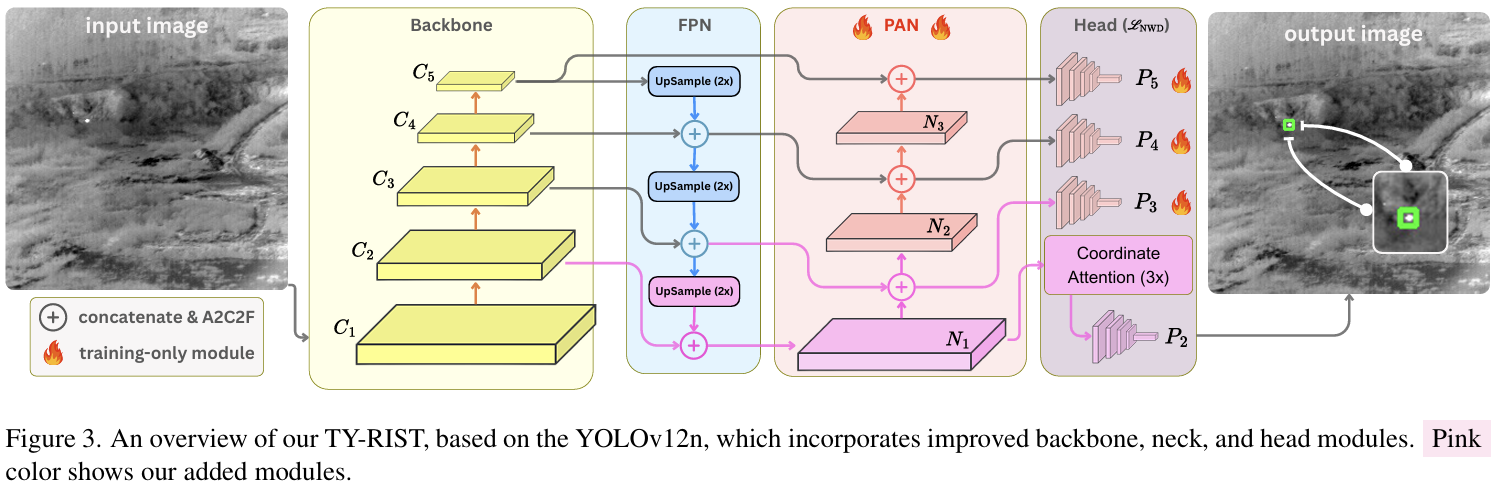
所提出框架的整体架构总结在图 3 中。它基于 YOLOv12n [31] 架构,在流水线的每个阶段都应用了一系列改进。本节详细解释了进行的每个实验。
3.1.1. 步长效应
IRSTD 受限于微小物体有限的空间特征。虽然增加输入分辨率或应用超分辨率可以缓解这个问题,但此类方法[12, 18,26, 42]通常依赖于两阶段流水线,阻碍了实时应用。受此启发,我们提出了一种新方法,避免放大输入图像,而是通过将第一个 CNN 块中的步长从 2 减少到 1 来放大骨干网络的特征图,从而使整个模型中产生的特征图复制因子为两倍。

图 4 可视化了有和没有步长缩减的两个模型获得的特征图。减少步长保留了关键的精细细节,这些细节被传播到骨干网络的后续层中,而步长为 2 则导致此类关键特征的丢失。
3.1.2. 通过 NWD 函数的回归损失
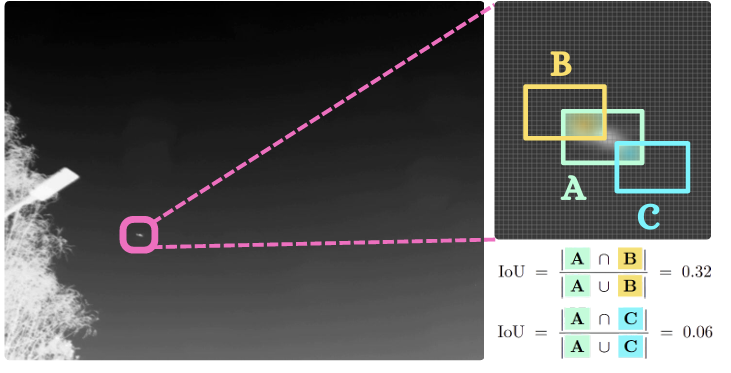
基于交并比(IoU)的度量,例如 CIoU 函数[46],通常用于通用目标检测中的边界框回归。然而,在小目标检测的背景下,它们非常敏感,预测框和真实框之间的微小位置偏差都可能导致 IoU 的显著下降。例如,如图 5 所示,尽管只有很小的位置差异,真实边界框 A 与预测框 B 和 C 之间的 IoU 从 0.32 急剧下降到 0.06。
遵循相关文献[17,41, 47],我们采用 NWD 函数[35]来替代 CIoU 函数,因为它通过将边界框建模为 2D 高斯分布并使用 Wasserstein 距离测量它们之间的相似性来解决上述问题,使其对物体尺度的差异不敏感,并且对极小或无重叠具有鲁棒性。两个 2D 高斯分布 μ1=N(m1,Σ1)\mu_{1}=N(\mathbf{m_{1}},\mathbf{\Sigma _{1}})μ1=N(m1,Σ1) 和 μ2=N(m2,Σ2)\mu_{2}=N(\mathbf{m_{2}},\mathbf{\Sigma _{2}})μ2=N(m2,Σ2) 之间的 2D Wasserstein 距离在公式 1 中定义:
W22(μ1,μ2)=∥m1−m2∥22+∥Σ112−Σ212∥F2,W_{2}^{2}(\mu_{1},\mu_{2})=\|\mathbf{m}_{1}-\mathbf{m}_{2}\|_{2}^{2}+\|\mathbf{\Sigma _{1}^{\frac{1}{2}}}-\mathbf{\Sigma _{2}^{\frac{1}{2}}}\|_{F}^{2},W22(μ1,μ2)=∥m1−m2∥22+∥Σ121−Σ221∥F2,
其中 ∥⋅∥F\lVert\cdot\rVert_{F}∥⋅∥F 是 Frobenius 范数,m 是均值向量,Σ 是协方差矩阵。由边界框 A=(cxa,cya,wa,ha)A=(c x_{a},c y_{a},w_{a},h_{a})A=(cxa,cya,wa,ha) 和 B=(cxb,cyb,wb,hb)B=(c x_{b},c y_{b},w_{b},h_{b})B=(cxb,cyb,wb,hb) 建模的两个高斯分布 Na,Nb\mathcal{N}_{a},\mathcal{N}_{b}Na,Nb 之间的距离可以写成公式 2:
W22(Na,Nb)=∣∣([cxa,cya,wa2,ha2]⊤−[cxb,cyb,wb2,hb2]⊤)∣∣22,\begin{array}{r l}&{W_{2}^{2}(\mathcal{N}_{a},\mathcal{N}_{b})=\Big|\Big|\Big(\big[c x_{a},c y_{a},\frac{w_{a}}{2},\frac{h_{a}}{2}\big]^{\top}}\\ &{\quad-\big[c x_{b},c y_{b},\frac{w_{b}}{2},\frac{h_{b}}{2}\big]^{\top}\Big)\Big|\Big|_{2}^{2},}\end{array}W22(Na,Nb)= ([cxa,cya,2wa,2ha]⊤−[cxb,cyb,2wb,2hb]⊤) 22,
其中 cxc_{x}cx 和 cyc_{y}cy 表示边界框中心的坐标,w 和 h 分别表示其宽度和高度。将其指数归一化到 0−10-10−1 的范围,得到公式 3 中的 NWD [35] 函数。
NWD(Na,Nb)=exp(−W22(Na,Nb)C),N W D(\mathcal{N}_{a},\mathcal{N}_{b})=\exp\left(-\frac{\sqrt{W_{2}^{2}(\mathcal{N}_{a},\mathcal{N}_{b})}}{C}\right),NWD(Na,Nb)=exp(−CW22(Na,Nb)),
其中 C 是一个依赖于数据集的常数,被视为超参数并需要微调。
3.1.3. 更高分辨率的特征和超小头
IRSTD 受高虚警率的影响,表现为低精确度。虽然 YOLOv12n 使用多尺度头 (P3(\mathrm{P}_{3}(P3 P4,P5)\mathrm{P_{4},P_{5})}P4,P5) 来检测小、中、大物体,但它依赖于严重下采样的特征图,导致关键空间细节的丢失,使其对超小型红外目标无效。现有架构的主要限制是它们排除了浅层 C2\mathbf{C}_{2}C2 特征图,该特征图由于其高分辨率,对于检测弱小微目标至关重要。
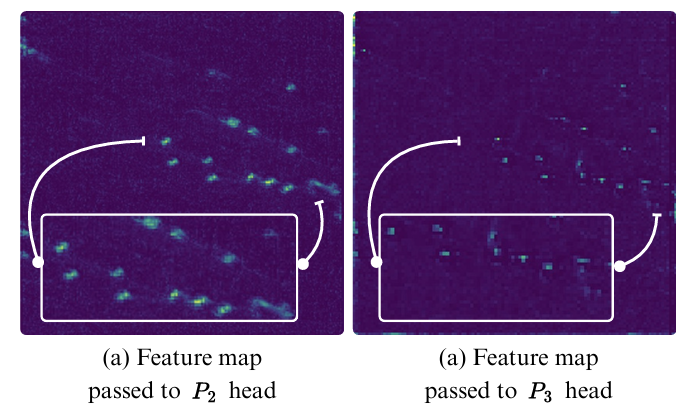
图 6. 传递给 P2P_{2}P2 和 P3P_{3}P3 的特征图比较。在 (a) 中,与 (b) 相比,目标特征以更高分辨率更清晰地可见。
受先前工作[4, 18, 25]的启发,我们在 C3,C4\mathrm{C_{3},C_{4}}C3,C4 和 C5\mathbf{C}_{5}C5 之外加入了 C2(在图 3 中显示为粉色拼接符号),修改颈部以产生 P2\mathbf{P}_{2}P2 特征图,并使用 Head 2(在图 3 中显示为粉色头部模块)扩展检测头,专门用于微小目标检测。图 6 说明了传递给 P2P_{2}P2 和 P3P_{3}P3 头的特征图分辨率差异。从 P2P_{2}P2 头提取的特征图具有更高的分辨率,因此具有更丰富的含义。
3.1.4. 添加坐标注意力块
在 IRSTD 中,漏检(假阴性)会因未能识别真实目标而降低召回率。为了解决这个问题,遵循相关文献[5, 18, 27],我们在最高分辨率的检测头分支(P2P_{2}P2 头,在图 3 中显示为粉色块)上集成了坐标注意力[14](CA),这使得网络不仅能够理解图像的哪些部分重要,还能知道它们的位置。传统的注意力机制,如卷积块注意力模块(CBAM)[36]和压缩与激励(SE)[15],通常强调重要特征,但由于在两个空间维度上进行全局池化而丢失了精确的位置信息。另一方面,坐标注意力[14]通过将空间池分解为两个一维操作来解决这个限制:一个沿水平方向,另一个沿垂直方向。这允许网络在一个方向上捕获长程依赖关系,同时在另一个方向上保留位置信息。

图 7 呈现了应用三个坐标注意力块之前和之后特征图 P2P2P2 的视觉比较。弱目标特征在应用 CA 块后得到了丰富和更集中。
3.1.5. 模型优化
实时 IRSTD 需要轻量级算法,以确保在资源受限平台上快速、准确的性能,从而在动态应用中实现及时响应。原始 YOLOv12n 模型采用三个检测头用于小、中、大物体,并辅以一个专门为超小物体设计的额外 P2P_{2}P2 头。为了评估每个头的贡献,并受相关文献[34, 39]的启发,我们进行了一个修剪实验,在推理过程中系统地一次禁用一个头(在图 3 中用火焰图标表示)。在 ITSTD-15k 基准测试[50]上,仅使用 P2P_{2}P2 头不仅保持了性能,而且通过减少来自其他头的误差传播和模型复杂性,略微提高了性能,这由更低的 FLOPS 和更少的参数证明。这种改进是因为 P2P_{2}P2 头处理最高分辨率的特征图 (C2)(C_{2})(C2),在预测之前通过三个 CA 块增强,使其非常适合 IRSTD。然而,在 NUAA-SIRST 基准测试[6]上,由于存在 P2P_{2}P2 头未能完全检测到的较大尺寸物体,需要两个头 (P2(P_{2}(P2 和 P3)P_{3})P3) 才能获得最佳性能。为了进一步研究其他头引入的误差,我们在推理过程中用单位矩阵替换了 PAN 网络(在 ITSTD15 基准测试中完全替换,在 NUAA-SIRST 基准测试中部分替换以产生用于生成 P3P_{3}P3 头的 N1\mathrm{N_{1}}N1 特征图,如图 3 所示),有效地消除了特征聚合。性能与使用相关头时相当,但复杂性降低了。这证实了 PAN 网络的下采样(为了将特征分发到未使用的头所必需的)通过可能丢弃关键目标特征而降低了性能。因此,(完全或部分)移除 PAN 网络没有不利影响,这与我们早期关于下采样缺点的发现一致。
4. 实验设置
4.1. 基准数据集
我们在五个带有边界框标注的公开可用数据集上进行了实验:两个基于序列的数据集(IRDST [28] 和 ITSDT-15k [50])和三个单帧数据集(NUAA-SIRST[6]、NUDT-SIRST[16] 和 IRDST-1k[44])。ITSDT-15k[50] 源自原始的 87 序列 ITSDT 数据集[10],包含具有遮挡、模糊和旋转的具有挑战性的空对地移动车辆场景。IRDST 包括 85 个真实和 317 个模拟的地对空序列,用于飞行目标检测。对于 IRDST,我们遵循[3]定义的训练和验证分割。单帧数据集最初在像素级别进行标注,涵盖了各种复杂的背景,如云、城市、河流、道路、海洋和田野。对于我们的实验,我们使用了[41]提供的边界框标注和数据集分割。
4.2. 评估指标
遵循通过检测范式解决 IRSTD 的常见实践,我们使用精确度(%)、召回率(%)、F1 分数(%)和平均精确度(%)(例如 mAP50)来评估性能。此外,我们报告了以百万(M)为单位的模型参数数量和以千兆(G)为单位的浮点运算次数(FLOPS)计算成本。
4.3. 实现细节
我们的实验包括三个部分。首先,对于多帧基准测试(IRDST [28] 和 ITSDT-15k [50]),我们按照[3]将输入图像调整为 512 × 512,使用 COCO [20] 权重初始化 YOLOv12n,并使用 AdamW [22] 和学习率为 0.0001、批量大小为 4 训练 100 个周期。此设置用于涉及步长缩减、用 NWD [35] 替换 CIoU [46] 以及添加 P2P_{2}P2 和超小头模块的实验。对于 CA [14] 实验,我们采用了两阶段训练策略,冻结骨干网络和颈部,使用 COCO 权重重新初始化头部,仅将 CA 块添加到超小头分支,并对添加的 CA 和头部部分进行 100 个周期的微调。其次,对于单帧基准测试(NUAA-SIRST [6]、NUDT-SIRST [16]),我们使用相同的设置,只是将图像分辨率增加到 640×640640\times640640×640,按照[41],并训练 200 个周期。最后,我们通过组合 NUAA-SiRST 和 NUDT-SIRST 进行训练并在 IRDST-1k [44] 上进行验证,进行了跨数据集验证实验。我们的训练实验在配备单个 NViDIA A40 GPU(45 GB 内存)的集群节点上进行,而推理实验在配备单个 NVIDIA RTX 3080 Ti GPU 的笔记本电脑上进行。我们报告单次训练试验的结果。建议重复实验以获得更可靠的统计分析。
5. 定量结果
定量结果分为四个部分呈现。首先,我们在两个多帧数据集(ITSDT-15k [50] 和 IRDST [28])上对 TY-RST 进行了基准测试,将其性能与 SIRST 和 MIRST 算法进行了比较。为了进一步突出其在多样化现实场景中的有效性,我们还在两个单帧数据集(NUAA-SIRST [6] 和 NUDT-SIRST [16])上对其进行了评估。总体而言,TY-RST 表现出明显的优势,甚至优于时空模型,并在四个基准数据集上相对于 20 个不同模型实现了 SOTA 性能。接下来,为了评估其泛化能力,我们通过在上进行训练并在未见过的 IRDST-1k 基准测试[50]上进行评估,进行了跨数据集验证实验。最后,我们在 ITSDT-15k 基准测试上准备了两个消融研究。
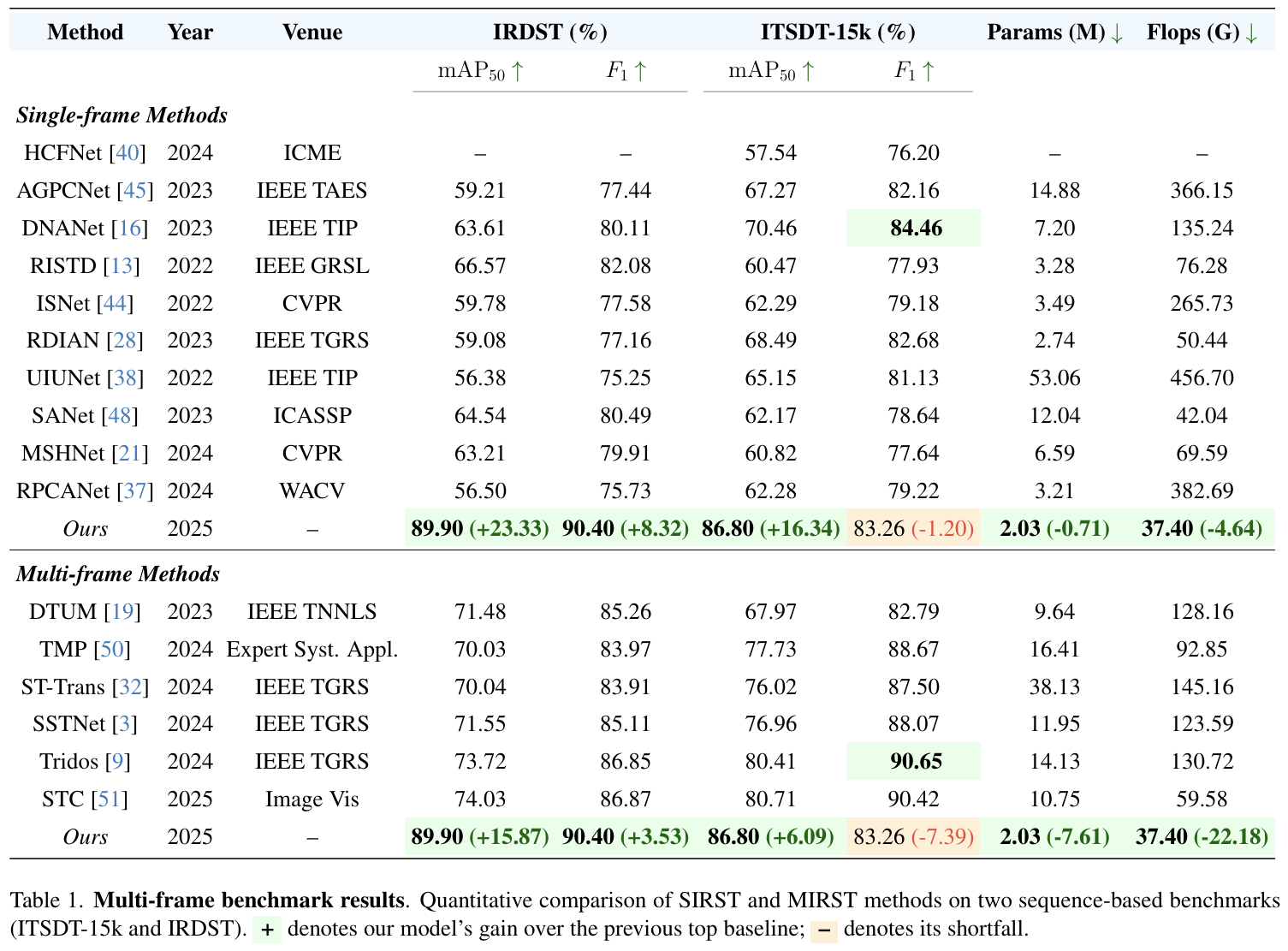
5.1. 多帧基准测试结果
与其他 SOTA 算法相比,我们主要关注基于学习的方法,因为它们具有先进且有竞争力的性能。由于大多数 SOTA SIRST 算法都是基于分割的,我们从 Chen 等人[3]的工作中获取了它们的检测性能结果,并采用相同的数据分割和图像分辨率以确保公平比较。表 1 总结了我们的模型与 10 个 SIRST 和 6 个 MIRST 算法在 ITSDT-15k 和 IRDST 基准测试上的性能比较。
对于 ITSDT-15k 数据集上的 SIRST 算法,我们的模型取得了最佳结果,mAP@50 为 86.80%,比第二好的算法 DNANet [16] 高出 16.34%。在 F1F_{1}F1 分数方面,我们的模型取得了第二好的成绩,分数为 83.26%,比 DNANet 的最高分 84.46% 低 1.20。然而,我们的模型在参数量上轻约 3.5 倍(2.03M 对比 7.2M),在 FLOPs 计算量上复杂程度低约 3.6 倍(37.40 GFLOPs 对比 135.24 GFLOPs)。
对于 IRDST 数据集上的 SIRST 算法,我们的模型在 mAP@50 和 F1F_{1}F1 分数上都取得了最佳结果,分别优于第二好的模型(RISTD [13])23.33% 和 8.32%。在模型效率方面,我们的模型也领先,参数量比第二轻的模型 RDIAN [28] 少 0.71M,计算量比第二快的模型 SANet [4] 少 4.64 GFLOPS。
在 ITSDT-15k 基准测试上,对于 MIRST 算法,我们的模型取得了最佳的 mAP@50 分数 86.80%,优于下一个最佳模型 STC [51] 6.09%。在 F1F_{1}F1 分数方面,我们的模型比表现最好的算法 Tridos [9] 低 7.39%。然而,我们的模型在参数量上轻约 7 倍(2.03M 对比 14.13M),并且运行速度快约 1.6 倍(37.40 GFLOPS 对比 59.58 GFLOPS)。
在 IRDST 基准测试上,对于 MIRST 算法,我们的模型再次在 mAP@50 和 F1F_{1}F1 分数上取得了最佳性能,分别优于下一个最佳模型 15.87% 和 3.53%。在效率方面,
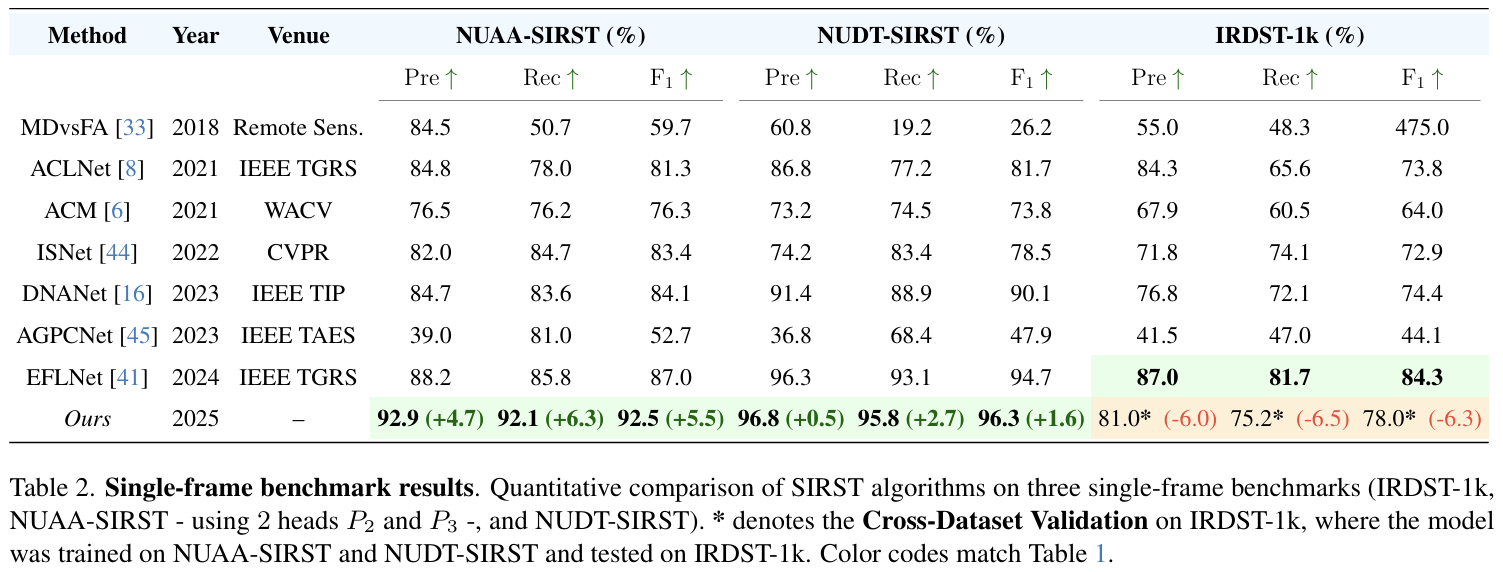
我们的模型创下了最佳记录,参数量比第二轻的模型 DTUM[19] 少 7.61M,计算量比第二快的模型 STC [51] 少 22.18 GFLOPS。
最后,为了测试我们模型的实时性能能力,我们在单个 NVIDIA RTX 3080 Ti 笔记本电脑 GPU 上运行它。在 ITSDT-15k 基准测试上,仅使用 P2P_{2}P2 头并通过移除整个 PAN 网络,我们的模型达到了 ~123 FPS。
5.2. 单帧基准测试结果
为了进一步验证我们模型的有效性,我们在两个单帧数据集(NUAA-SIRST [6] 和 NUDT-SIRST [16])上进行了基准测试,这些数据集具有多样化和复杂的现实生活和合成挑战,具有不同的背景,如海洋、建筑物和城市场景。由于本实验中选择的大多数 SIRST 算法都是基于分割的,我们使用了 Yang 等人[41]工作中的检测性能结果,并采用相同的数据分割和图像分辨率以确保公平比较。值得注意的是,这项工作[41]没有报告 mAP 结果;因此,我们在评估中排除了 mAP。根据表 2,我们的模型在 NUDT-SIRST 基准测试上使用单个 P2P_{2}P2 头,在 NUAA-SIRST 基准测试上使用两个头 (P2(P_{2}(P2 和 P3)P_{3})P3),在三个评估指标:精确度、召回率和 F1F_{1}F1 分数上都取得了最佳结果。最后,在 FPS 方面,由于使用了 P2P_{2}P2 和 P3P_{3}P3 头以及部分 PAN 网络,我们的模型达到了 ~105 FPS。
5.3. 跨数据集验证结果
在这个实验中,我们旨在评估我们的模型在未见过的数据集上的泛化能力。我们谨慎地选择在 NUAA-SIRST 和 NUDT-SIRST 数据集上训练我们的模型,并在未见过的 IRDST-1k 数据集[50]上评估它,因为训练数据集的背景特征与验证集的背景特征非常相似。换句话说,所有三个数据集共享类似的具有复杂背景的挑战性场景,包括云、海、建筑物和田野。但是,具体的实例图像不同,确保该实验评估模型对来自相似分布的新数据的泛化能力。结果呈现在表 2 中,其中我们的模型标记有 * 表示在 IRDST-1k 上进行跨数据集验证。我们的模型展示了强大的泛化能力,在 F1F_{1}F1 分数和召回率方面排名第二,在精确度方面排名第三,优于多达六个在 IRDST-1k 基准测试上训练的算法。
5.4. 消融研究
这项工作中的消融研究包括三个主要部分。首先,我们对基线 YOLOv12n 模型上进行的每个实验的影响进行了详细分析,以得出我们提出的 TY-RIST 模型的最终版本。其次,我们提出了嵌入在 NWD 回归损失函数中的 CCC 参数的调优研究。最后,我们提出了一个在 YOLOv12s [31] 上复制实验的案例研究。
5.4.1. 每个组件的影响
为了突出我们六个实验中每一个对模型性能的影响,我们在 ITSDT-15k 基准测试上进行了全面的消融研究,结果呈现在表 3 的上半部分。第一个实验涉及在 ITSDT-15k 基准测试上评估原始 YOLOv12n 模型,实现了 78.9% 的 mAP@50,这表明所选模型具有很强的基线性能。减少步长将 mAP@50 提高了 5.2%,表明提取了更高质量的特征,从而解决了最小特征挑战,但导致了 19 GFLOPS 的额外计算成本。用 NWD 函数替换 CIoU 由于解决了 CIoU 函数中的不稳定性挑战,将 mAP@50 提高了 1%,而没有增加计算成本。添加更高分辨率的特征图 C2C_{2}C2 及其相应的检测头 P2P_{2}P2 进一步将精确度提高了 3.1%,从而降低了虚警率,但计算量 ~翻倍。在 P2P_{2}P2 头上集成 CA 块导致召回率提高了 0.7%,从而降低了漏检率,但导致计算成本微增 0.2 GFLOPS。移除 P3P_{3}P3 P4P_{4}P4 和 P5P_{5}P5 检测头将 mAP@50 提高了 0.3%,更重要的是,将计算成本降低了 6.8 GFLOPS,而停用 PAN 网络在保持性能的同时将参数量减少了 0.53M,计算量减少了 6 GFLOPS。总体而言,模型修剪实验将计算量减少了 ~25.5%,参数量减少了 ~25.6%。在表 3 的下半部分,呈现了关于 NUAA-SIRST 数据集使用的头数量的消融研究。添加额外的头和部分 PAN 网络将参数量增加了 0.07M,计算量增加了 2.9 GFLOPS。此外,引入第二个头将召回率提高了 8.9%,精确度提高了 0.7%。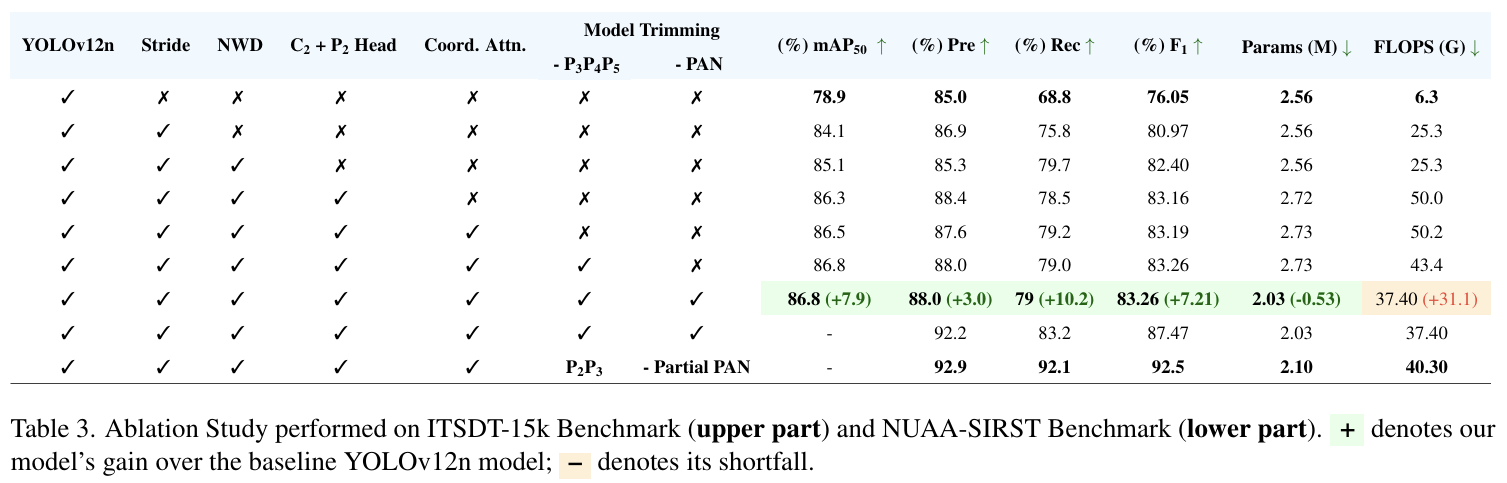
5.4.2. 微调 NWD 中的 C 参数
正如前面第 4.2 节提到的,NWD 函数包含一个可调的、针对每个数据集的参数 C。表 4 总结了为 ITSDT15k 基准测试选择最佳 C 值(从集合 {9,11,13,15,17} 中)进行的消融研究,确定 17 为性能最佳的值。这些测试值受到[41]工作的启发。这项研究的一个关键观察是,某些 C 值可能导致性能下降,与原始 CIoU 损失函数相比。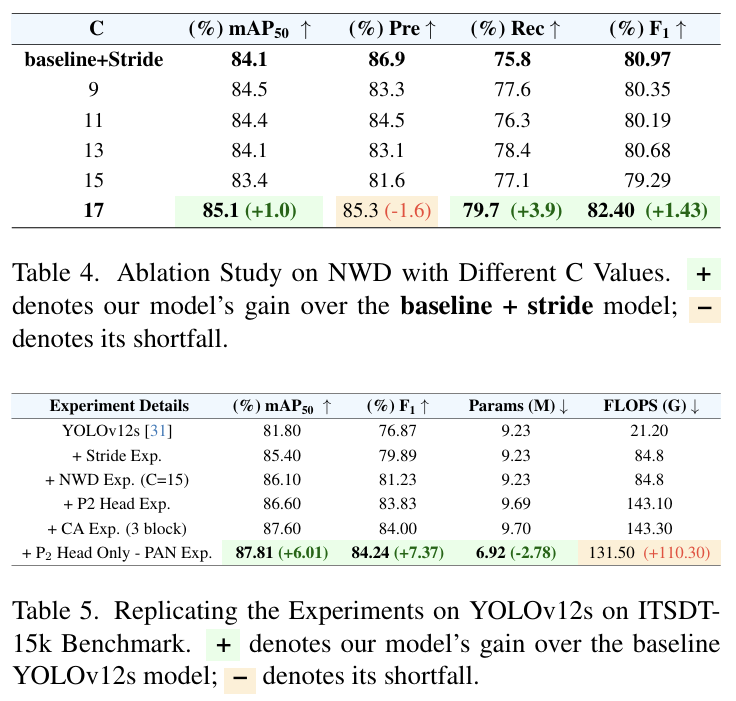
5.4.3. 在 YOLOv12s 上复制实验
表 5 总结了在 YOLOv12s [31] 上复制的实验,进一步证明了它们在不同 YOLO 模型间的可推广性。
6. 结论
这项工作提出了 TY-RIST,一种基于最新的 YOLO 系列成员 YOLOv12n 的高效实时红外小目标检测算法。通过一系列实验,TY-RIST 相对于 20 个不同的模型实现了 SOTA。尽管如此,仍有改进的空间,特别是在通过集成时间特征并将其与空间特征有效融合来进一步减少虚警和漏检方面——这是为未来工作保留的领域。
7. 致谢
我们感谢湖南大学的郑佳明教授(InSAI 实验室)的合作。这项工作是在 bwForCluster Helix 上进行的,得到了巴登-符腾堡州通过 bwHPC 和德国研究基金会的支持。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)