深度相机yolo识别目标检测测距实现
嘿嘿,懒得总结了!!@¥#%@#¥%\n总代码放这里了import cv2print("设备信息:", dev.get_device_info())print("无法获取彩色画面")break。
文章目录
一、项目简述与预览
本项目通过融合YOLO目标检测算法与OpenNI2深度视觉技术,构建了一套智能环境感知系统,其核心逻辑在于将色彩识别与空间测距实时闭环。系统启动时,通过SDK分别驱动彩色相机与深度相机,并强制将两者分辨率统一为640x480,确保图像坐标空间高度对齐。在主循环中,YOLO模型作为大脑实时解析彩色视频流,精准捕捉物体位置并生成边界框与置信度;
与此同时,深度相机作为感知系统,向空间中发射红外信号并采集每个像素点的物理毫米级距离数据。程序随后提取检测框的几何中心点,并映射至深度矩阵查询相应数值,最终将物体分类、识别置信度以及实时距离动态绘制于屏幕显示。该项目不仅展示了现代机器视觉中“看”与“知”的结合,还克服了单一传感器在感知维度的局限。虽然受限于硬件物理盲区与模型推理算力,但该架构为智能避障、自动驾驶辅助及工业安全预警等领域提供了基础技术范式。通过SDK屏蔽底层复杂的驱动与通信协议,开发者能够专注于上层业务逻辑,实现对物理世界感知数据的深度挖掘与应用,是学习人工智能与硬件交互开发的绝佳入门级实践工程。

二、Orbbec-Astra相机windows系统下Python配置使用
可以参考这篇文章,详细的讲解SDK如何配置:3D视觉开发者社区的文章 - 知乎 https://zhuanlan.zhihu.com/p/563844587
SDK是啥???
SDK(软件开发工具包)不是一个单一文件,它是厂商打包好的一整套工具:
专属硬件驱动(让操作系统能识别相机)
封装好的 API 接口(接下来代码里的openni2.initialize()、depth_stream.read_frame()都是 SDK 提供的)
它的核心作用,就是把复杂的硬件底层操作,封装成几行代码就能调用的简单功能,让我们不用关心硬件底层怎么通信、数据怎么传输。
三、代码实现
1.硬件初始化
在该项目中,我们需要同时调用三个摄像头:一个是用于捕捉图像的普通 RGB摄像头,另一对是用于探测空间的摄像头。要让两者协同工作,初始化阶段的配置至关重要。
深度相机不像普通摄像头那样通过简单的驱动就能读取,它需要遵循 OpenNI2 的工业协议。如果不初始化,不安装SDK,就无法使用相机的其他功能,直接使用只会默认调用普通 RGB摄像头。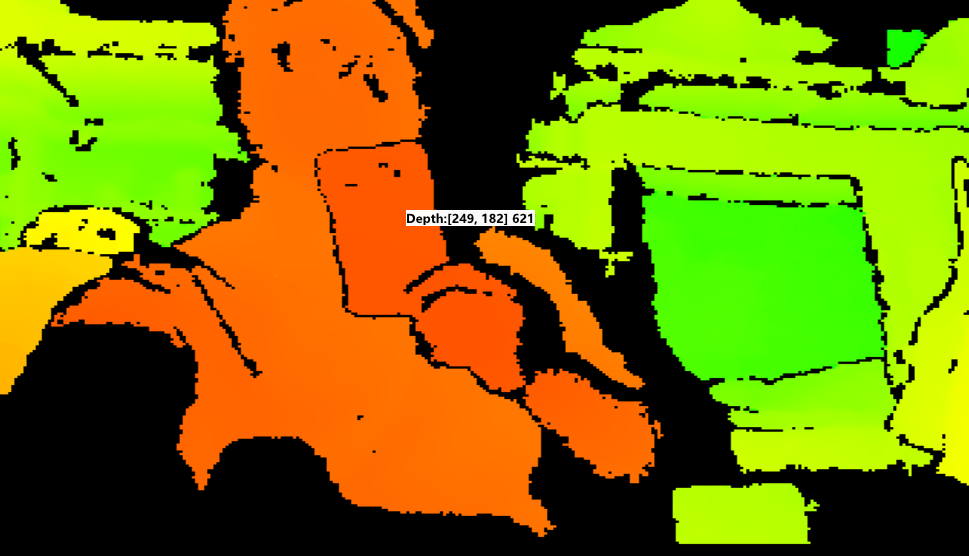
代码如下(示例):
# 初始化深度相机
openni2.initialize() # 开启驱动环境
dev = openni2.Device.open_any() # 搜索并连接第一个可用的深度设备
depth_stream = dev.create_depth_stream() # 创建数据流管道
depth_stream.start() # 开始向管道中注入数据
openni2.initialize()为什么需要它?
必须的前置步骤:在使用 OpenNI2 的任何功能前,必须先调用 initialize() 来启动库。为 OpenNI2 分配内存、线程和其他系统资源,以支持实时深度数据处理。
dev.create_depth_stream()是深度数据获取的前提:在 OpenNI2 中,所有深度图像数据必须通过深度流对象获取,直接从设备无法读取深度帧。创建流后可进一步配置其参数(如分辨率、帧率、数据格式)。
2.深度图与彩色图像匹配对齐
为了让彩色图与深度数据(深度图)精确匹配,我们必须强制要求彩色相机的分辨率与深度相机的分辨率一致(笔者这设为 640x480)。
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640) # 强制设定宽度为640
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480) # 强制设定高度为480
为什么要手动设定分辨率? 如果不设置,彩色相机的默认分辨率可能是 1920x1080。此时若直接将识别到的坐标映射到 640x480 的深度图中,就会出现“测距点严重偏移”的问题。
分辨率一致性是测距准确的前提:只有当 color_frame 和 depth_frame 的像素坐标一一对应时,我们获取到的 dpt[cy, cx] 才是物体中心的真实距离。
3.加载预训练模型
在完成上述功能后,我们需要加载 YOLO 模型并创建一个可视化窗口,将检测过程和预测结果实时呈现出来.
# 加载 YOLO 模型
# 这里的路径指向本地的权重文件
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\yolo11n.pt")
# 创建一个名为 'Color Detection' 的窗口,并设为自动调整大小
cv2.namedWindow('Color Detection', cv2.WINDOW_AUTOSIZE)
建议:如果你在运行过程中发现识别不够准,可以尝试将 yolo11n.pt 替换为 yolo11s.pt
4.深度数据提取
从深度相机流中读取一帧原始深度数据(16位)后,我们需要将该数据拆成 2 个 8 位数据 来传输。为什么?深度相机测距范围一般是:0 ~ 65535 毫米(约 65 米)这个范围需要 16 位二进制才能存下,但传输只能按 8 位来传,因为USB、网卡、驱动底层,一次只传 8 位,只能切成两半,深度数据(16位)于是在数组里就变成了 2 通道,第0通道存低8位,第1通道存高8位,等所有数据传过来,按低8位 + 高8位得到真实深度值。注意拼接时要记得将传过来的dpt2进位,所以要dpt2 = 256(就比如从从十进制来看,18,分成‘1’,‘8’,18=110+8)。
frame_depth = depth_stream.read_frame()# 从深度相机流中读取一帧原始深度数据
# 将相机输出的原始二进制数据 转换为 numpy数组
# 并重新转成 480行 640列 2通道 的格式
# 2通道 = 第0通道存低8位,第1通道存高8位(拼接成16位深度值)
dframe_data = np.array(frame_depth.get_buffer_as_triplet()).reshape([480, 640,2])
dpt1 = np.asarray(dframe_data[:, :, 0], dtype='float32')# 提取深度图像的低8位通道数据并转换为32位浮点数格式
dpt2 = np.asarray(dframe_data[:, :, 1], dtype='float32')# 提取深度图像的高8位通道数据并转换为32位浮点数格式
dpt2 *= 256# 使8位通道数据进位
dpt = dpt1 + dpt2 # 拼接低8位 + 高8位,得到最终的真实深度值(单位: mm)
4.Yolo预测结果与深度数据结合
这段代码实现 YOLO 实时检测目标,获取框坐标与类别还有置信度,计算目标中心并读取深度数据在图像中心显示距离,使用Open cv在画面绘制框、中心点、距离及类别标签。
# 对彩色画面进行 YOLO 目标检测
# source=color_frame:输入当前彩色帧
# stream=False:普通单次推理,只处理一张图片,处理完直接返回最终结果,不持续输出
# verbose=False:程序只输出最终核心结果,不打印中间过程、调试信息、进度条等冗余内容
results = model.predict(source=color_frame, stream=False, verbose=False)
# 取出当前帧的检测结果(results 是列表,[0] 代表第一张图/当前帧)
result = results[0]
# 遍历所有检测到的目标框
# 先判断是否有检测框,避免空数据报错
if result.boxes is not None:
for box in result.boxes: # 逐个遍历每个目标的检测框
# 将检测框的浮点坐标转为整数(OpenCV 画框必须用整数像素)
# box.xyxy[0] = [x1, y1, x2, y2] → 左上、右下角坐标
x1, y1, x2, y2 = map(int, box.xyxy[0])
# 获取当前目标置信度(0~1,代表检测准确率)
conf = float(box.conf[0])
# 获取目标类别索引(0:人,1:自行车...)
cls = int(box.cls[0])
# 拼接标签文字:类别名 + 置信度(保留两位小数)
label_text = f"{model.names[cls]} {conf:.2f}"
# 中心点 X = (左 + 右) // 2
cx = (x1 + x2) // 2
# 中心点 Y = (上 + 下) // 2
cy = (y1 + y2) // 2
# 边界保护:确保中心点坐标在图像范围内,防止数组越界报错
if 0 <= cx < 640 and 0 <= cy < 480:
# 深度图 [行, 列] → 对应 [cy, cx]
distance = dpt[cy, cx]
else:
distance = 0.0 # 越界则距离设为 0
# 画矩形框:画面、左上角、右下角、颜色(BGR)、线条粗细
# (0,0,255) = 红色框
cv2.rectangle(color_frame, (x1, y1), (x2, y2), (0, 0, 255), 2)
# 绘制目标中心点(红色实心圆)
# -1 代表实心填充
cv2.circle(color_frame, (cx, cy), 5, (0, 0, 255), -1)
# 格式化距离字符串:取整 + 单位 mm
dist_str = f"{distance:.0f} mm"
# 在中心点右侧显示距离(红色字体)
cv2.putText(color_frame, dist_str, (cx + 8, cy - 8),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# 计算标签文字的宽度和高度,用于适配背景框大小
(text_w, text_h), _ = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
# 绘制绿色实心背景块(-1 = 填充)
cv2.rectangle(color_frame, (x1, y1 - 20), (x1 + text_w, y1), (0, 255, 0), -1)
# 在绿色背景上写黑色类别文字
cv2.putText(color_frame, label_text, (x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
四.深度相机的“盲区”
细心的小伙伴跑完代码,运行结果会发现,当物体与深度相机距离小于500mm时,中心点旁的距离会显示为0mm,这是为什么呢?其实这与上述代码中的
if 0 <= cx < 640 and 0 <= cy < 480:
distance = dpt[cy, cx]
else:
distance = 0.0
这段代码无关,它的作用是做好边界保护,防止因为检测框超出画面导致报错,真正的原因是深度相机的工作原理通常是靠红外光发射器向外打光,再由红外摄像头接收反射光。当物体距离相机太近(例如小于 400mm-600mm)时,发射器发出的光和接收器看到的视野会产生严重的视差错误,导致传感器无法计算出有效的深度数据,所以当物体进入这个盲区,相机输出的深度数据直接输出 0。(这里我离相机距离小于500mm,相机输出的结果)
五.总结
嘿嘿,懒得总结了!!@¥#%@#¥%\n总代码放这里了
from ultralytics import YOLO
from openni import openni2
import numpy as np
import cv2
if __name__ == "__main__":
openni2.initialize()
dev = openni2.Device.open_any()
print("设备信息:", dev.get_device_info())
depth_stream = dev.create_depth_stream()
depth_stream.start()
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\yolo11n.pt")
cv2.namedWindow('Color Detection', cv2.WINDOW_AUTOSIZE)
while True:
frame_depth = depth_stream.read_frame()
dframe_data = np.array(frame_depth.get_buffer_as_triplet()).reshape([480, 640, 2])
dpt1 = np.asarray(dframe_data[:, :, 0], dtype='float32')
dpt2 = np.asarray(dframe_data[:, :, 1], dtype='float32')
dpt2 *= 256
dpt = dpt1 + dpt2
ret, color_frame = cap.read()
if not ret:
print("无法获取彩色画面")
break
results = model.predict(source=color_frame, stream=False, verbose=False)
result = results[0]
if result.boxes is not None:
for box in result.boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = float(box.conf[0])
cls = int(box.cls[0])
label_text = f"{model.names[cls]} {conf:.2f}"
cx = (x1 + x2)//2
cy = (y1 + y2)//2
if 0 <= cx < 640 and 0 <= cy < 480:
distance = dpt[cy, cx]
else:
distance = 0.0
cv2.rectangle(color_frame, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.circle(color_frame, (cx, cy), 5, (0, 0, 255), -1)
dist_str = f"{distance:.0f} mm"
cv2.putText(color_frame, dist_str, (cx + 8, cy - 8),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
(text_w, text_h), _ = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
cv2.rectangle(color_frame, (x1, y1 - 20), (x1 + text_w, y1), (0, 255, 0), -1)
cv2.putText(color_frame, label_text, (x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
cv2.imshow('Color Detection', color_frame)
key = cv2.waitKey(1)
if int(key) == ord('q'):
break
depth_stream.stop()
dev.close()
cap.release()
cv2.destroyAllWindows()
8 8 6~~

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)