【CVPR2025】DepthSplat:使用几何一致深度估计增强前馈GS方法
本文是ETH对于前馈GS方法中关于使用cost- volume预测深度的尝试,被CVPR2025收录,文章内容不难,实验效果较多,有幸拜读大佬们的great work,做笔记!
一、概况
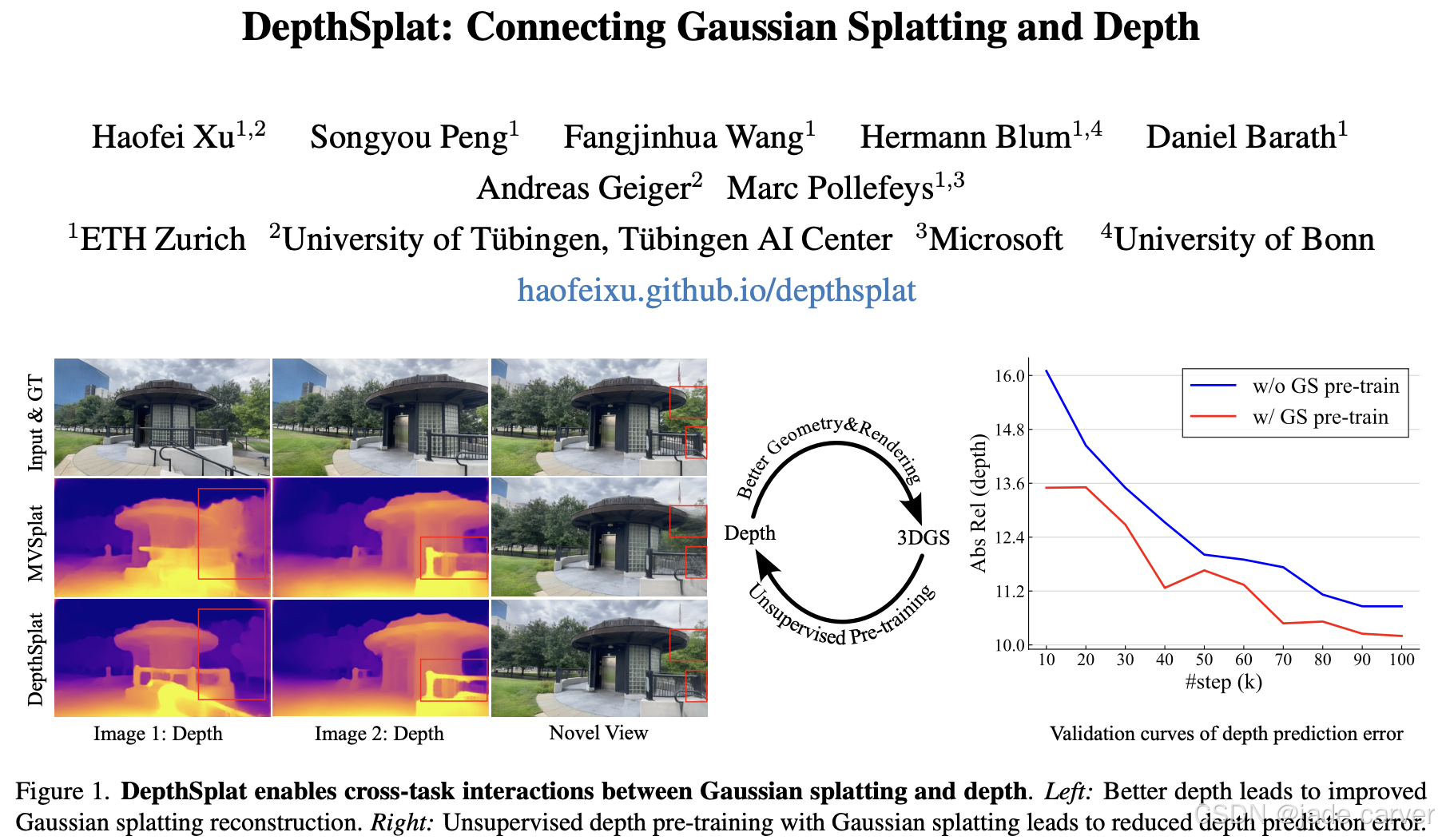
Gaussian splatting与单视角深度估计通常被独立研究。本文提出的DepthSplat首次将二者结合,并探究其相互作用机制。具体而言,我们首先通过利用预训练的单目深度特征,构建出鲁棒的多视角深度模型,从而实现了高质量的前馈式3D高斯泼溅重建。我们还证明,高斯泼溅可作为无监督预训练目标,帮助从大规模多视角位姿数据中学习强大的深度模型。通过大量消融实验和跨任务迁移验证,我们证实了这两种技术的协同效应。DepthSplat在ScanNet、RealEstate10K和DL3DV数据集上同时实现了深度估计与新视角合成的性能突破,充分展现了任务联动的双向优势。此外,该方法仅需0.6秒即可完成12张输入视图(512×960分辨率)的前馈式重建。
近期,前馈式3DGS模型[7, 9, 48]的进步进一步减少了对逐场景优化的依赖,并实现了少视角3D重建。当前最先进的少视角方法MVSplat[9] 依赖基于特征匹配的多视角深度估计[65]来定位3D高斯分布的位置,这使得它与其他多视角深度方法[18, 25, 44, 56, 71]一样,在遮挡、无纹理区域和反光表面等场景中表现受限。
另一方面,单目深度估计也取得了重大进展,最新模型[19, 22, 28, 40, 69, 74]能够在多样化真实数据上实现鲁棒的预测。然而,这些深度估计结果通常在不同视角间缺乏尺度一致性,限制了其在3D重建[59, 73]等下游任务中的表现。
将3DGS与单目深度估计相结合,可以克服各自技术的局限性,同时增强其优势。为此,我们提出了DepthSplat,它利用少视角前馈式3DGS和鲁棒的单目深度估计的互补性,提升两项任务的性能。我们首先通过将预训练的单目深度特征[70]整合到多视角特征匹配分支,构建了一个鲁棒的多视角深度模型。该方法不仅保持了多视角深度模型的一致性,还在难以匹配的场景(如遮挡、无纹理区域和反光表面)中提供了更稳定的结果。预测的多视角深度图随后被反投影至3D空间作为高斯中心,并通过一个轻量级网络预测其余高斯参数,最终结合泼溅操作[29]实现新视角合成。
尽管先前的方法[1, 11, 31]也尝试融合单目和多视角深度,但它们通常依赖复杂的架构。相比之下,我们充分利用现成的预训练单目深度模型,提出用单目特征增强多视角代价体积(cost volume),从而实现了更简单的模型和更强的性能。
得益于改进的多视角深度模型,基于高斯泼溅的新视角合成质量显著提升(见图1左)。此外,我们的高斯泼溅模块完全可微分,仅需光度监督即可优化所有组件。这为无需真实几何信息的大规模多视角位姿数据集预训练深度模型提供了一种新的无监督方法。预训练的深度模型可进一步微调用于特定深度任务,并显著优于从头训练的结果(见图1右,无监督预训练提升了性能)。
二、方法

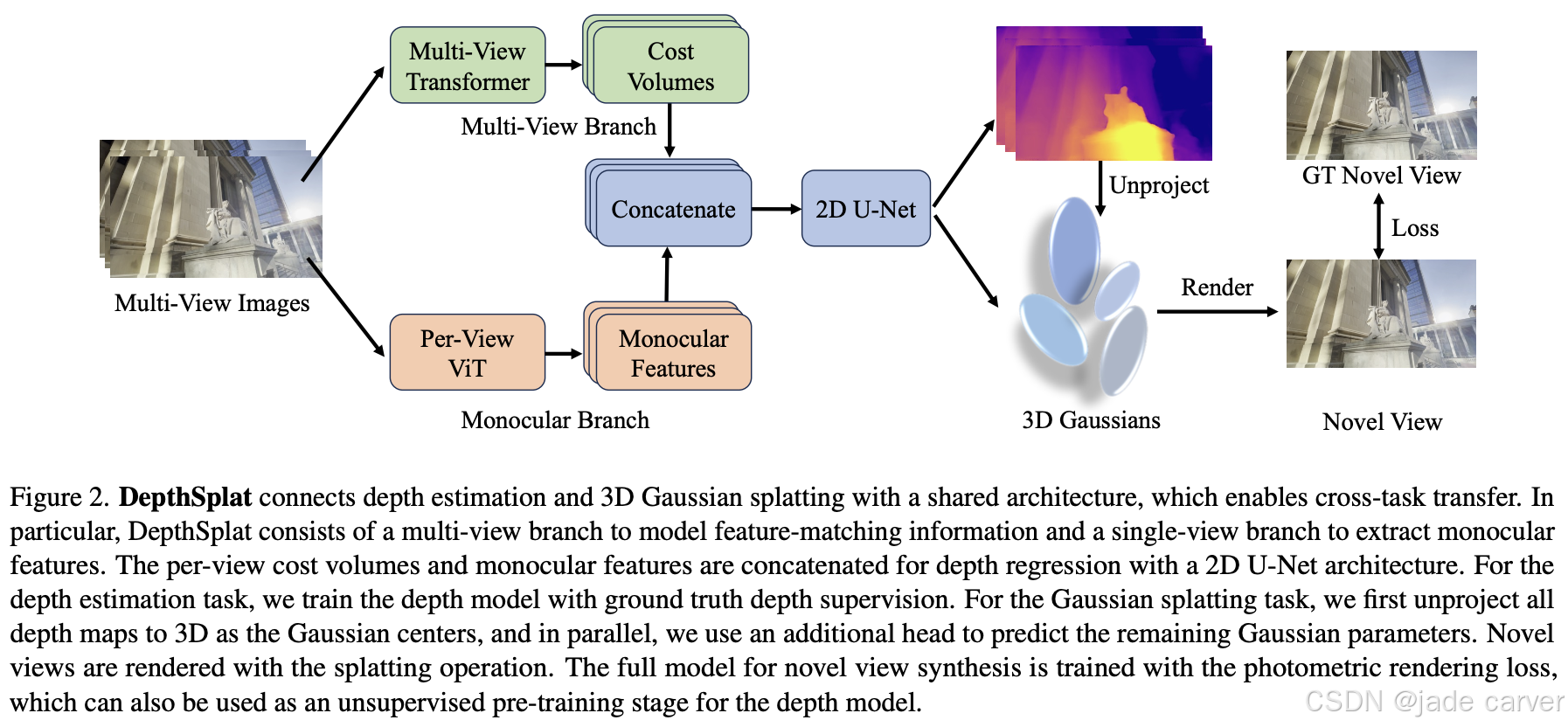
2.1. Multi-View Feature Matching
我们采用多视角Transformer架构提取多视角特征,并为每个输入视角构建对应的代价体。这样,我们的模型估计的深度具有多视角一致性。
多视角特征提取
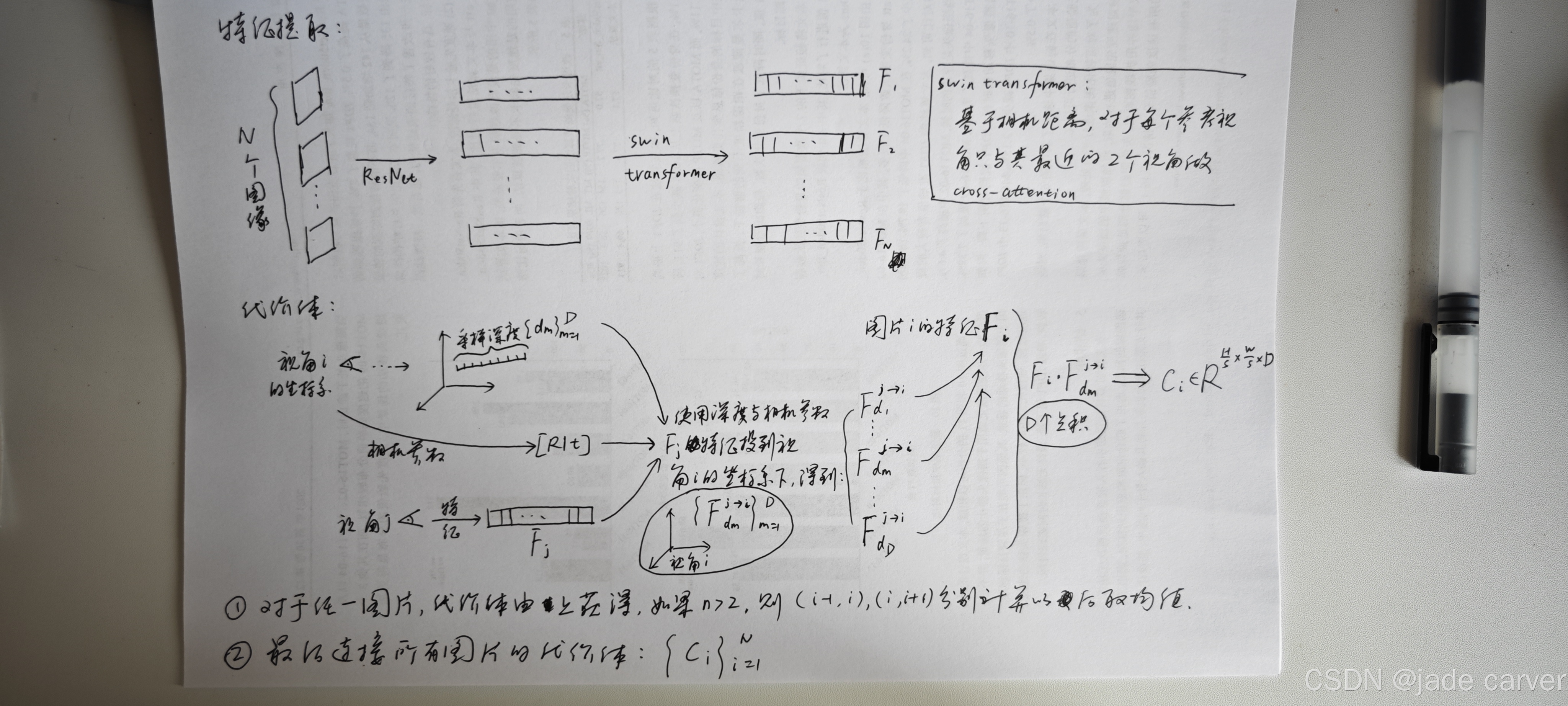
对于N张输入图像,首先采用轻量级权重共享的ResNet[27]架构独立获取每张图像的s倍降采样特征。为适配不同图像分辨率,通过控制步长为2的3×3卷积层数量实现灵活调整降采样因子s(例如:使用两层步长2卷积时s=4,三层时s=8)。随后通过包含六层自注意力与交叉注意力堆叠的多视角Swin Transformer[34,64,65]实现跨视角信息交互,最终获得具有多视角感知的特征集合![]() ,C为特征维度。当输入图像超过两幅(N>2)时,我们基于相机距离为每个参考视角选择最邻近的两个视角进行交叉注意力计算,该策略显著提升了多视角输入时的计算效率。
,C为特征维度。当输入图像超过两幅(N>2)时,我们基于相机距离为每个参考视角选择最邻近的两个视角进行交叉注意力计算,该策略显著提升了多视角输入时的计算效率。
利用特征匹配构建代价体
采用plane-sweep stereo[13,65]编码跨视角特征匹配信息。具体实现时:1) 对每个视角i,在深度近远范围内均匀采样D个候选深度![]() ;2) 根据相机投影矩阵将视角j的特征Fj按每个深度dm反投影至视角i坐标系,获得D个变形特征
;2) 根据相机投影矩阵将视角j的特征Fj按每个深度dm反投影至视角i坐标系,获得D个变形特征![]() ;3) 通过点积运算[9,63]计算变形特征与原始特征Fi的相关性;4) 堆叠所有相关性构成视角i的代价体
;3) 通过点积运算[9,63]计算变形特征与原始特征Fi的相关性;4) 堆叠所有相关性构成视角i的代价体![]() ;5)最后我们获得所有图像的代价体
;5)最后我们获得所有图像的代价体![]() 。对于超过两个输入视角的情况,延续交叉注意力计算时的策略——仅选择最邻近的两个视角进行特征相关性计算,并通过均值融合两者的相关性结果。该方案在保证精度的同时实现了高效的多视角代价体构建,在计算速度与准确率之间取得优异平衡。
。对于超过两个输入视角的情况,延续交叉注意力计算时的策略——仅选择最邻近的两个视角进行特征相关性计算,并通过均值融合两者的相关性结果。该方案在保证精度的同时实现了高效的多视角代价体构建,在计算速度与准确率之间取得优异平衡。
流程图手画
2.2. Monocular Depth Feature Extraction
尽管基于多视角特征匹配的深度估计方法[57, 65, 71]和高斯泼溅技术[9]取得了显著进展,但这些方法在遮挡区域、无纹理区域和反光表面等挑战性场景中仍存在固有局限。为此,我们提出将预训练的单目深度特征整合到代价体中,以应对难以匹配或无法匹配的场景。
我们采用了近期Depth Anything V2[70]模型中的预训练单目深度骨干网络,该模型在多样化的真实场景数据上表现出色。输入图片,使用它来提取到单目深度特征!我们通过双线性插值将单目特征的空间分辨率调整至与3.1节中代价体相同的分辨率,从而为输入图像Ii获取单目特征![]() ,其中C_mono为单目特征的维度。该过程对所有输入图像并行执行,最终得到单目特征集合
,其中C_mono为单目特征的维度。该过程对所有输入图像并行执行,最终得到单目特征集合![]() ,这些特征将用于后续的逐视角深度图估计。
,这些特征将用于后续的逐视角深度图估计。
2.3. Feature Fusion and Depth Regression
融合代价体与depth anything框架的深度特征增加深度估计的鲁棒性:

2.4. Gaussian Parameter Prediction
在3D高斯泼溅任务中,我们直接利用相机参数将逐像素深度图反投影至3D空间,作为高斯中心μj。为预测其他剩余的高斯参数——αj(不透明度)、Σj(协方差矩阵)和cj(颜色),我们额外引入一个DPT头[41],该模块以拼接后的图像、深度及特征信息作为输入,输出所有待求的高斯参数。最终,基于这些预测的3D高斯体,可通过高斯泼溅操作[29]实现新视角的渲染。
2.5. Training Loss
loss包括两部分,一部分是深度loss,另一部分是渲染loss:
仅训练深度估计模块(不含高斯泼溅头)时,采用预测逆深度与真值之间的ℓ1损失与梯度损失联合优化:

完整模型训练时,结合GS渲染图像与真值之间的均方误差(MSE)与感知损失(LPIPS[78]):

三、实验
3.1模型变体与实验设计
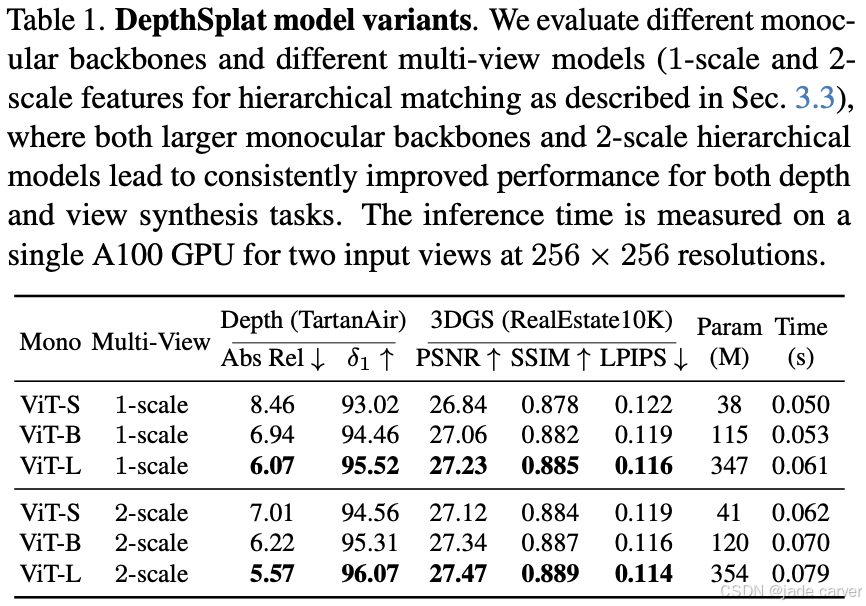
深度估计实验在大规模合成数据集TartanAir[58]上进行,该数据集包含室内外场景并提供完美真值深度;高斯泼溅实验则在标准RealEstate10K[82]数据集上实施。遵循学界标准,我们报告了深度评估指标[20](Abs Rel:相对L1误差,δ1:阈值内正确估计像素占比)和新视角合成指标[29](PSNR、SSIM、LPIPS)。表1结果显示,更大规模的单目骨干网络和双尺度分层模型能持续提升两项任务的性能。我们定义了三种模型规格:
-
Small:ViT-S单目骨干+单尺度多视角
-
Base:ViT-B单目骨干+双尺度多视角
-
Large:ViT-L单目骨干+双尺度多视角
最终结论是改进深度网络架构与优化初始化策略均能显著提升新视角合成效果。
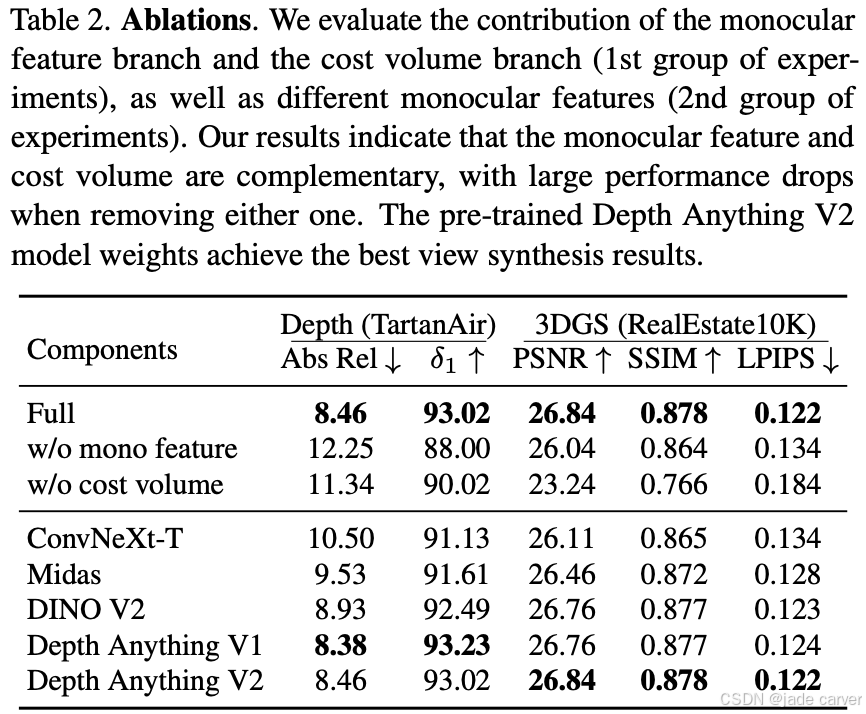
3.2消融实验
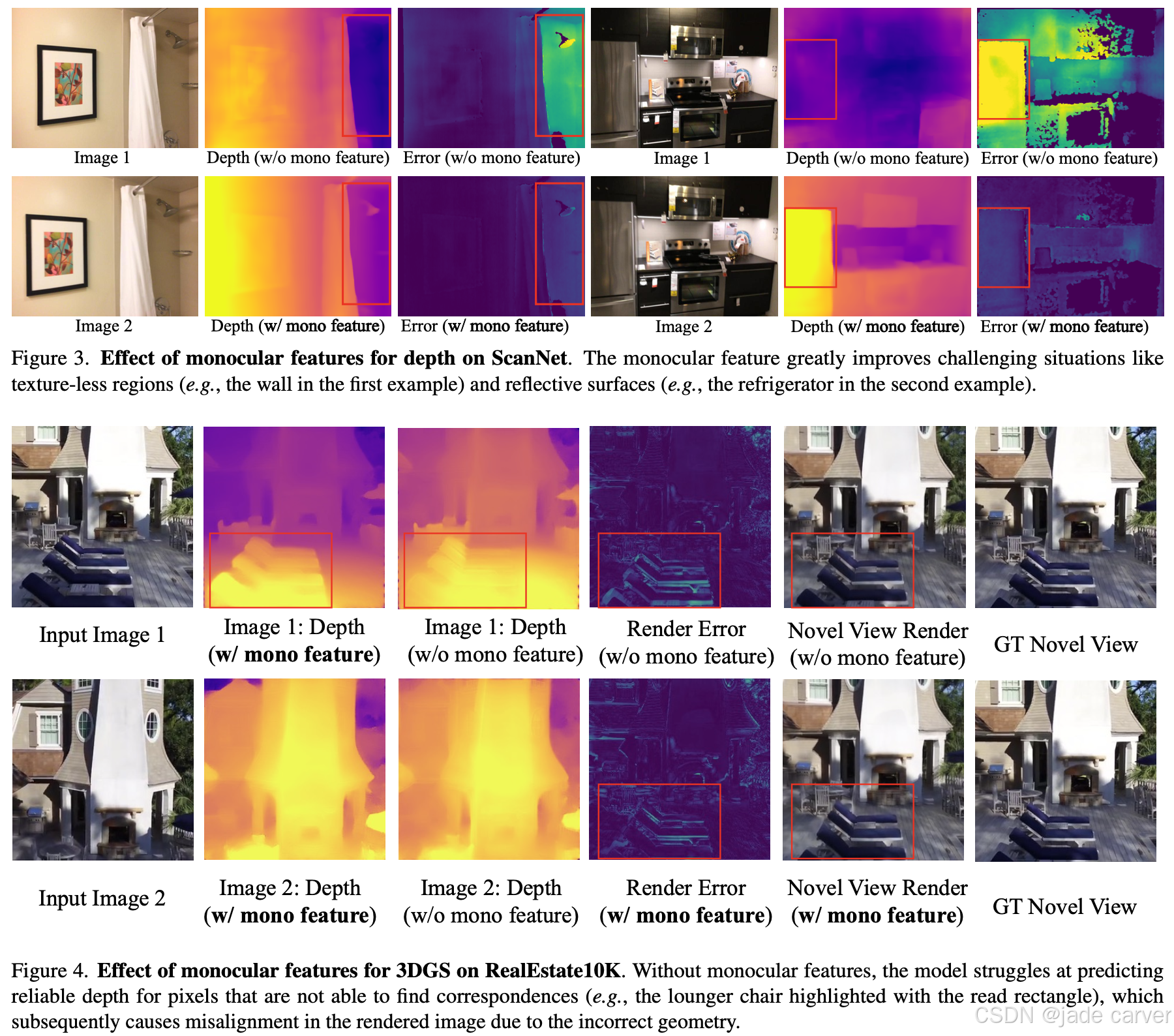
在本节中,我们研究了TartanAir数据集(深度)和RealEstate10K数据集(高斯溅射视图合成)上关键组件的属性。如表2以及图3图4:
3.3. Unsupervised Depth Pre-Training with Gaussian Splatting
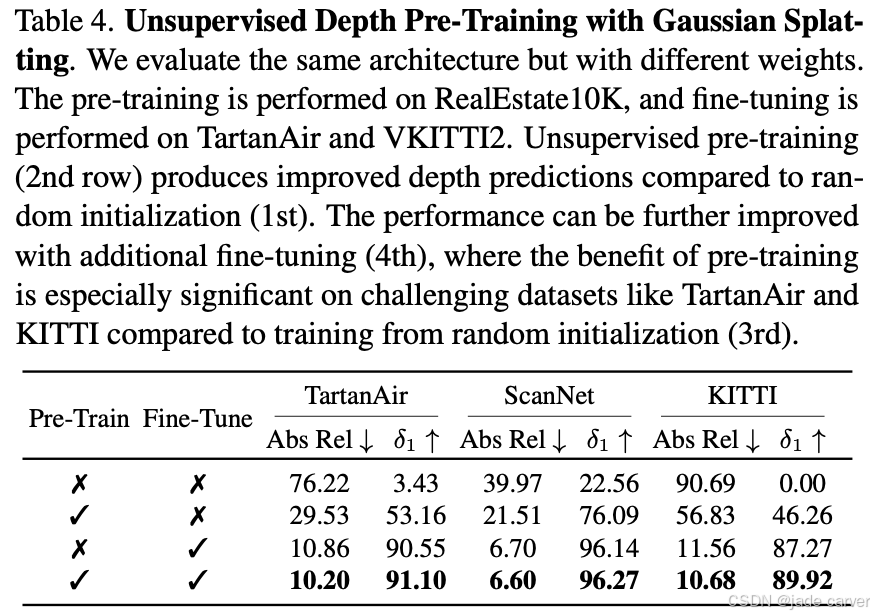
通过将高斯泼溅与深度估计相结合,我们的DepthSplat提出了一种完全无监督的深度模型预训练方法。具体而言,我们首先在大规模多视角带位姿数据集RealEstate10K(包含约6.7万段YouTube视频)上,仅使用高斯泼溅渲染损失(公式(2))对完整模型进行训练,而无需任何深度预测的直接监督。预训练完成后,取预训练好的深度模型,进一步在混合数据集TartanAir[58]和VKITTI2[5]上利用深度真值监督进行微调。表4展示了在域内测试集TartanAir以及零样本泛化测试集ScanNet和KITTI上的性能评估,结果显示预训练带来的性能提升在TartanAir和KITTI等挑战性数据集上尤为显著。这一结果与文献[21]的发现高度吻合——预训练起到了正则化作用,引导模型收敛至更优的极小值点,从而提升对分布外数据的泛化能力(可视化对比结果见附录)。随着视角合成[61,81]与多视角生成模型[3,45]的日益普及,以及新型多视角数据集[32]和模型[55]的不断涌现,我们的方法为利用大规模多视角带位姿图像数据集预训练深度模型提供了可行方案。
我们观察到,预训练在纹理较少的区域会带来更好的结果。但是肉眼看起来没什么差别或者差别不大?

3.4. Benchmark Comparisons
1.ScanNet and RealEstate10K
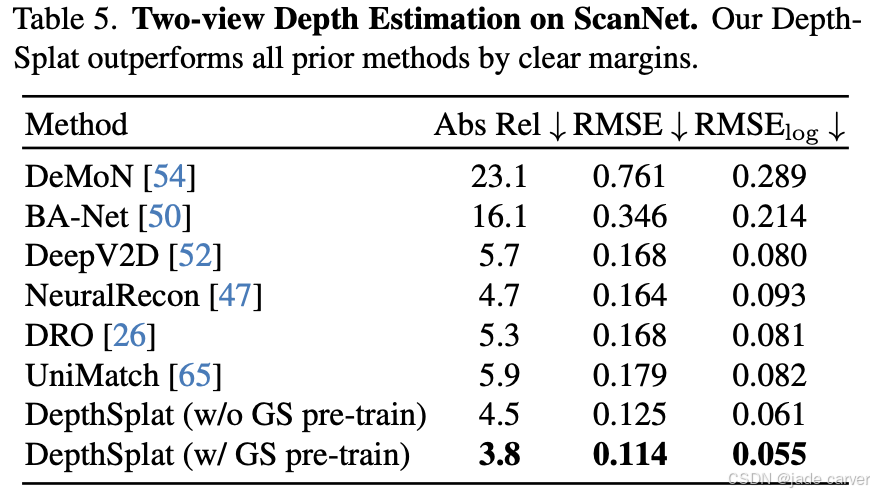
表5与表6分别在ScanNet和RealEstate10K标准基准测试上对比了深度估计与新视角合成的性能表现。实验数据清晰表明,我们的DepthSplat模型在两项任务上均实现了最先进的性能。图5的视觉对比结果显示,本方法在无纹理区域和遮挡等挑战性场景下的表现显著优于现有方法。
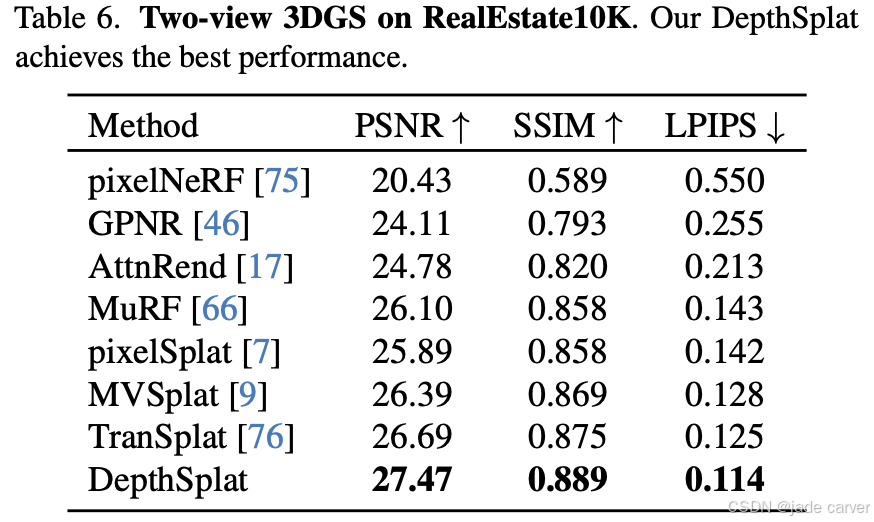

2.DL3DV
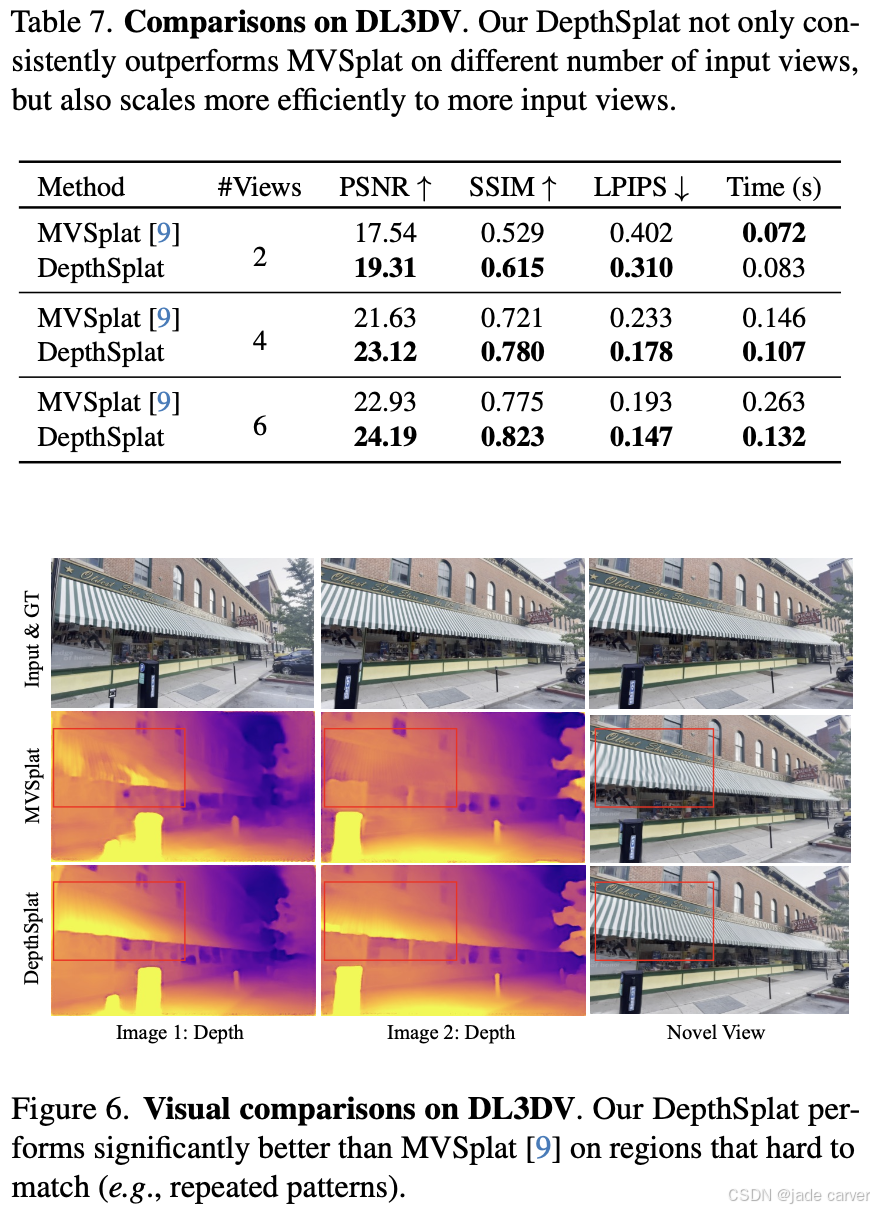
为评估模型在复杂真实场景下的性能,我们在最新推出的DL3DV数据集[32]上与代表性模型MVSplat[9]进行对比实验,并测试了不同输入视角数量(2、4、6)的影响。我们将MVSplat与经过RealEstate10K预训练的DepthSplat模型在DL3DV训练集上微调后,表7展示了基准测试集的量化结果:DepthSplat在所有指标上均稳定优于MVSplat,且输入视角越少时优势越显著,这表明我们的模型对稀疏视角具有更强鲁棒性。图6的DL3DV视觉对比显示,由于特征匹配失败导致的深度估计误差,MVSplat会产生模糊失真的渲染结果,而我们的方法则能保持更高质量的合成效果(更多对比见附录)。值得注意的是,得益于3.1节提出的轻量级局部特征匹配策略(相比MVSplat耗能的全局匹配方案),我们的方法能更高效地扩展至多视角输入。

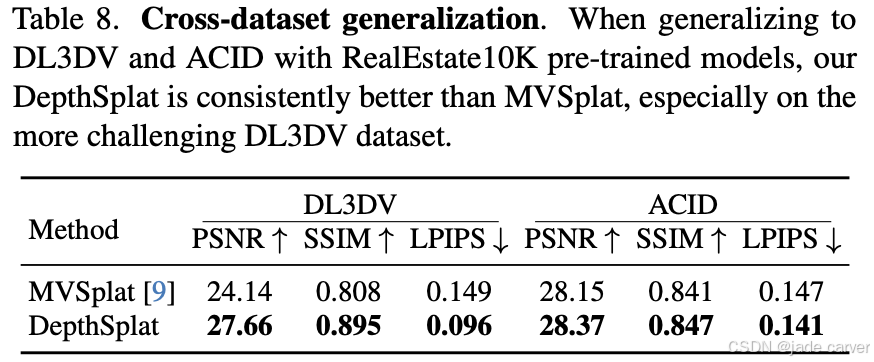
3.跨数据集泛化能力
我们直接将RealEstate10K[82]预训练模型在DL3DV[32]和ACID[33]数据集上进行零样本评估。表8结果显示,DepthSplat在两个数据集上均超越MVSplat,尤其在场景结构更复杂的DL3DV数据集上优势更为明显
效果如下:

4.高分辨率的情况
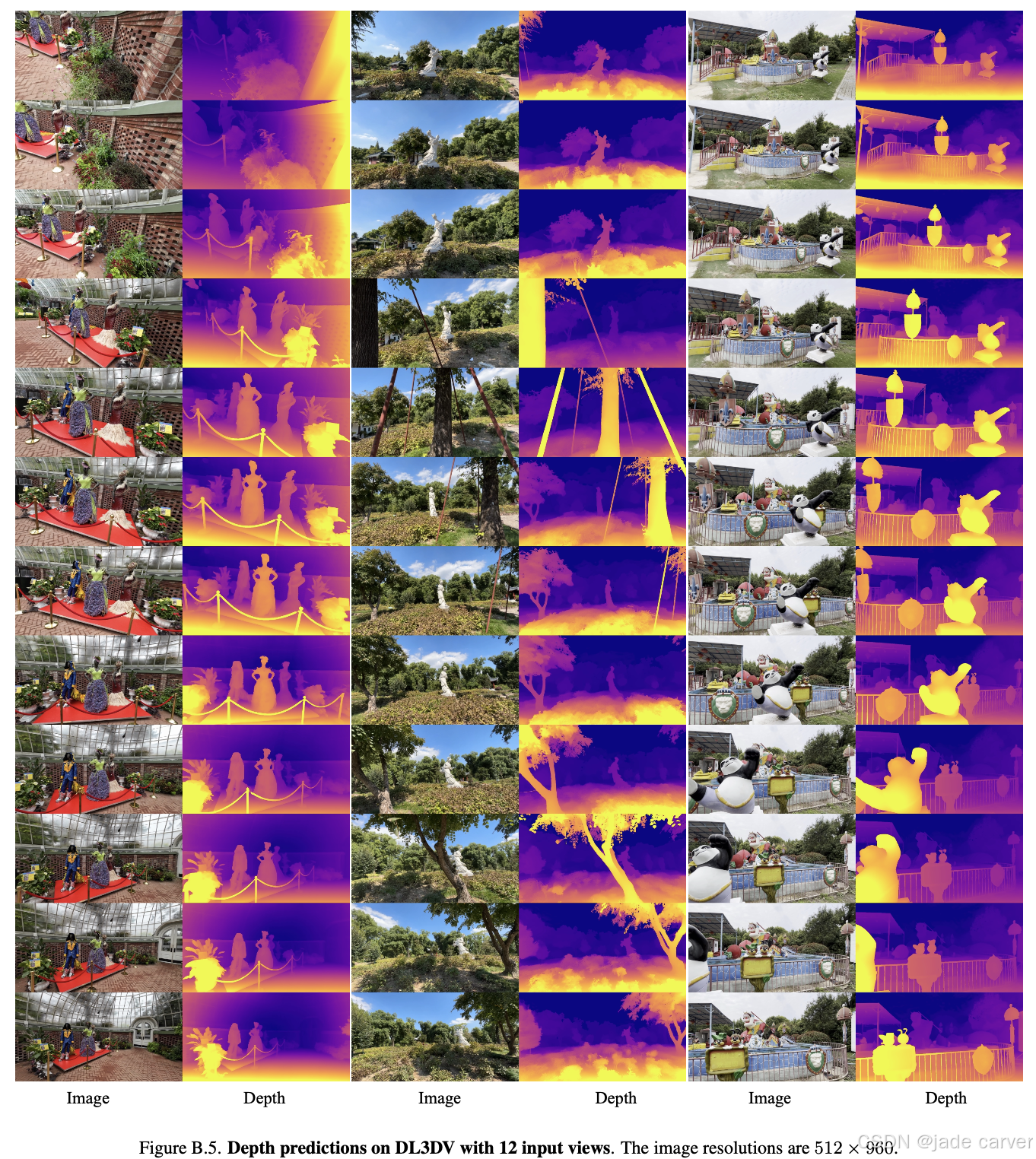
除256×256分辨率的RealEstate10K和256×448分辨率的DL3DV基准测试外,还提供了512×960高分辨率的定性结果,我们的方法能够从更多输入视角中重建更大规模或360°全景场景。

5.深度图的多视角一致性
可以看到,估计出来的深度具有多视角一致性!
四、 Conclusion
DepthSplat通过创新性地结合高斯泼溅与深度估计,在ScanNet、RealEstate10K和DL3DV数据集上实现了深度估计与新视角合成任务的最先进性能。我们证明了该模型能够利用高斯泼溅渲染损失进行无监督深度预训练,为利用大规模带位姿多视角图像数据集训练更具鲁棒性和泛化能力的多视角深度模型提供了新范式。
局限性:当前模型需要输入多视角图像及其对应相机位姿,在输入视角极度稀疏时可能面临位姿获取难题。未来可探索免位姿模型[72,80]以消除这一限制。此外,模型预测的像素对齐高斯体在处理大量输入视图时[60,79]会导致高斯体数量激增,如何优化几何表示并提升多视角扩展性将是值得探索的方向。
这是目前前馈高斯模型的通病,要么难以pose-free,要么像素级别的高斯数量导致计算成本大幅增加,故而难以真正扩展到高分辨率,比如2k图像等情况,anysplat那一篇文章是在这之后的工作,它是pose-free + 八叉树压缩的方法解决了这两个问题,目前暂未开源,感兴趣的读者可以看我另外一篇文章专门讲解!
参考文献:[2410.13862] DepthSplat: Connecting Gaussian Splatting and Depth

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)