重叠加权(Overlap Weighting OW)在真实世界研究(仿RCT研究)的应用
摘要:真实世界研究(RWS)作为随机对照试验(RCT)的重要补充,通过重叠加权(OW)方法在非理想化场景中评估医疗干预效果。本文对比了四种协变量调整方法(未调整、倾向评分匹配、逆概率加权和重叠加权),发现重叠加权在平衡组间差异(SMD≈0)和保留样本量方面表现最优,其权重算法稳定可靠。通过R语言实例分析,验证了OW方法在模拟RCT三大核心属性(目标人群相关性、协变量平衡性和估计精确性)上的优势,与
真实世界研究(Real-World Study, RWS) 是一种在真实医疗或生活环境中收集数据、评估医疗干预措施(如药物、器械、治疗方案)效果和安全性的研究方法。它与传统的*、随机对照试验(RCT)形成互补,更注重在非理想化、多样化的现实场景中观察医疗实践的结果。

咱们都知道,RCT的证据力度很强,那为什么强呢?主要是人群经过筛选后,人群的特征相似(年龄、性别等),而且观察变量X是随机分配的,这样有很强的可比性。真实世界研究也有叫仿RCT研究,就是把人群进行筛选匹配,达到类似RCT的目的。目前很多顶刊都发表了关于仿RCT的研究,说明现阶段这个是能冲高分的。
在真实世界研究中,重叠加权(Overlap Weighting ,OW)是个非常重要的内容,重叠加权是一种模仿随机临床试验属性的倾向评分方法,比如刚开放的seer数据库,很多粉丝咨询我说想做模拟RCT研究。

目前咱们匹配数据通常有倾向评分匹配和逆概率加权,
1.倾向评分匹配 PSM的是通过匹配具有相似倾向性评分的个体,来平衡处两组之间的协变量分布。缺点:评分差距大,容易丢失数据过多
-
逆概率加权 传统 IPTW 为治疗患者分配 1/PS 的权重,为未治疗的患者分配 1/(1 − PS)的权重。因果推理中流行的逆概率加权方法经常受到极端倾向得分的阻碍,导致估计有偏差和过度方差。一种常见的补救措施是修剪评分极高的患者(即,将其从加权分析中删除)。然而,这种方法通常对临界点的选择很敏感,并丢弃了很大一部分样品。
-
重叠加权是一种PS方法,试图模仿随机临床试验的重要属性:具有临床相关性的目标人群、协变量平衡和精确度。目标人群是得出结论的患者群体。 平衡指的是治疗过程中患者特征的相似性,这是避免偏差的重要条件。精确度表示对治疗与感兴趣的结果之间关联估计的确定性;更精确的估计具有更窄的置信区间和更大的统计功效
为什么使用重叠加权?
优势:
1.模拟RCT:重叠加权能够模拟RCT的三个重要属性:临床相关的目标人群:得出结论的患者群体;协变量均衡:在治疗过程中患者特征的相似性,这是避免偏倚的重要条件;精确度:对治疗和相关结果之间关联的估计的确定性,更精确的估计有更窄的置信区间(CIs)和更强的统计效能。
2.避免极端权重:与逆概率加权(IPTW)相比,重叠加权避免了极端权重值的问题,因为其权重值在0到1之间。这使得重叠加权在处理数据时更加稳定,减少了由于极端权重导致的估计偏差。
3.样本量保留:与倾向性评分匹配(PSM)不同,重叠加权不会舍弃任何样本。因此在样本量较少的研究中,重叠加权仍然可以有效地使用所有可用数据,从而提高研究的统计效能。
下面我用一个具体数据演示一下,
library(tableone)
library(survey)
library(reshape2)
library(ggplot2)
library(Matching)
library(scitable)
data(lindner, package = "twang")
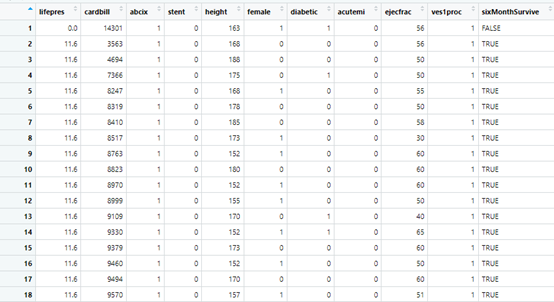
数据来自twang包,我们研究的abcix是两种治疗方式,其他的可以看作协变量,咱们先定义协变量
cov1<-c('stent' , 'height' , 'female' , 'diabetic' , 'acutemi' , 'ejecfrac' , 'ves1proc')
使用我写的sciiptw函数可以秒生成重叠加权权重和逆概率加权权重,支持二分类变量和多分类变量加权,生成原始权重和标准化权重,供不同的需求。使用的是一种非常权威的算法,绝对放心可靠。
###可以两组或多组加权
dt<-sciiptw(data = lindner,x="abcix",cov =cov1,normalize = F)
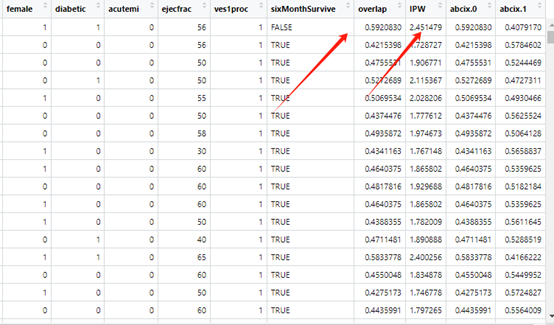
接下来咱们进行4种方法比较变量间的组间差异,分别是没有调整前,倾向评分匹配,逆概率加权,重叠加权
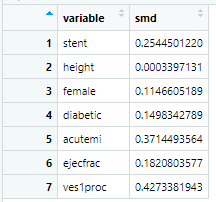
先来个没调整前的,plot0里面记录各个变量的smd
unWeighted <- CreateTableOne(vars = cov1, strata = "abcix", data = dt, test = FALSE)
plot0<-scismd(unWeighted)
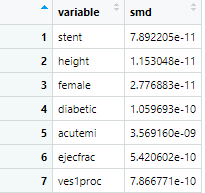
接下来是重叠加权
#####overlap
olp <- svydesign(ids = ~ 1, data = dt, weights = ~ overlap)
olpWeighted <- svyCreateTableOne(vars = cov1, strata = "abcix", data = olp, test = FALSE)
plot1<-scismd(olpWeighted)
逆概率加权
###ipw
ipw <- svydesign(ids = ~ 1, data = dt, weights = ~ IPW)
ipwWeighted <- svyCreateTableOne(vars = cov1, strata = "abcix", data = ipw, test = FALSE)
plot2<-scismd(ipwWeighted)
倾向评分匹配
###ps
listMatch <- Match(Tr = (dt$abcix == 1), # Need to be in 0,1
## logit of PS,i.e., log(PS/(1-PS)) as matching scale
X = log(dt$abcix.1/ dt$abcix.0),
## 1:1 matching
M = 1,
## caliper = 0.2 * SD(logit(PS))
caliper = 0.2,
replace = FALSE,
ties = TRUE,
version = "fast")
rhcMatched <- dt[unlist(listMatch[c("index.treated","index.control")]), ]
tabMatched <- CreateTableOne(vars = cov1, strata = "abcix", data = rhcMatched, test = FALSE)
plot3<-scismd(tabMatched)
咱们把4个数据合并在一起看下,明显重叠加权的smd非常小
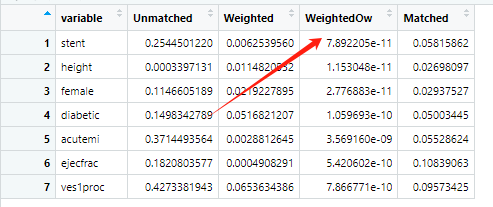
咱们把宽数据转长数据,再整理一下
dataPlotMelt <- melt(data = dataPlot,
id.vars = c("variable"),
variable.name = "Method",
value.name = "SMD")
varNames <- as.character(dataPlot$variable)[order(dataPlot$Unmatched)]
dataPlotMelt$variable <- factor(dataPlotMelt$variable,
levels = varNames)
绘图
ggplot(data = dataPlotMelt,
mapping = aes(x = variable, y = SMD, group = Method, color = Method)) +
geom_line() +
geom_point() +
geom_hline(yintercept = 0.1, color = "black", linewidth = 0.1) +
coord_flip() +
theme_bw() +
theme(legend.key = element_blank())
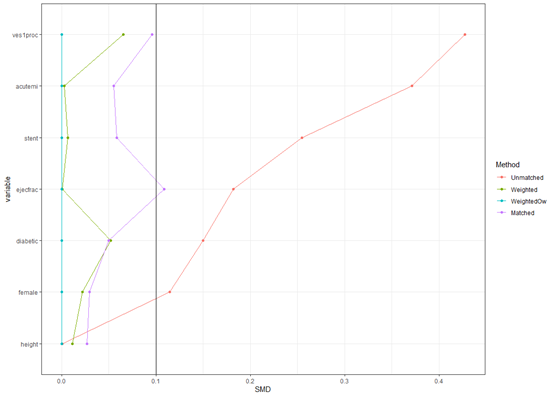
上图可以看到没调整前红色线组间差异很大,倾向评分匹配后的紫色线smd明显变小,逆概率加权的绿色线smd进一步变小,最牛的就是重叠加权的蓝色线,smd几乎为0了,匹配效果非常好。
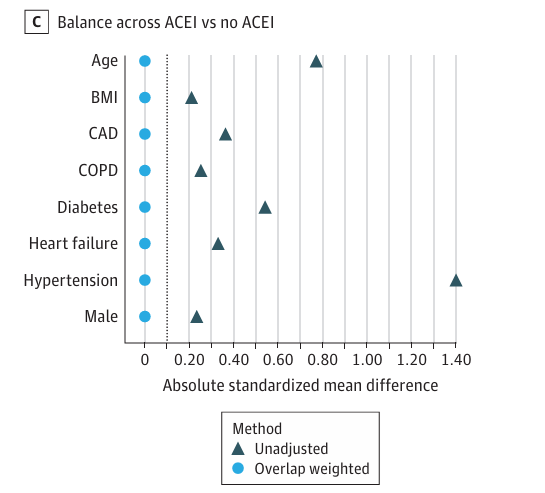
这个结论和这篇jama文章的结论也是一致的

下面还有视频介绍,更加详细
重叠加权(Overlap Weighting OW)在真实世界研究的应用

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)