别再二选一了!一文看懂On-Policy与Off-Policy的本质分歧(含GRPO深度拆解)
GRPO 是一种 on-policy 策略优化方法,它在传统 Advantage 函数的基础上引入“动作组内的相对优势”作为优化依据,从 Q(s,a) 的角度看,它不是直接优化 Q 值,而是间接对 Q(s,a) 与 V(s) 的差值进行 group-wise 归一化,从而提升策略更新的稳定性与鲁棒性。On-policy 强调“靠自己经验成长”的策略闭环,Off-policy 强调“借助他人经验学习

©作者 | 吴宇斌
单位 | 摩尔线程
研究方向 | GUI agent
在强化学习(Reinforcement Learning,RL)中,on-policy 和 off-policy 是两种核心的学习策略,它们之间的区别在于:
学习使用的数据是否来自当前策略本身,还是来自其他策略。
要想真正理解这两个概念,我们不仅要从算法原理入手,还要把握其本质。下面我将从基本定义 → 原理区别 → 数学表达 → 实例类比 → 矛盾分析几个层次进行深入剖析。

基本定义:本质在于“是否自食其果”


原理层面深入理解
2.1 On-policy原理
On-policy算法强调现学现用:你只能根据你当前行为策略做出的决策来学习。也就是说,你走路摔了跤,那就根据你自己的经验总结教训;别人的教训你学不了。
代表算法:
-
SARSA(State-Action-Reward-State-Action)
-
PPO(Proximal Policy Optimization)
特点:
-
数据和策略紧耦合,稳定但样本利用率较低
-
策略收敛稳定,适合动态调整策略的情境
2.2 Off-policy原理
Off-policy 算法则允许站在前人肩膀上学习:你不一定非要亲身经历一切,也可以观察别人是怎么做的,并据此调整自己的策略。
代表算法:
-
Q-learning
-
DQN(Deep Q-Network)
-
DDPG / TD3 / SAC(深度强化学习中的 Actor-Critic)
特点:
-
数据可以反复使用,样本利用率高
-
训练灵活,可以分离采样与训练过程
-
但更容易产生偏差或不稳定(因策略不一致)

数理表达区别
3.1 On-policy示例(SARSA)
更新公式:
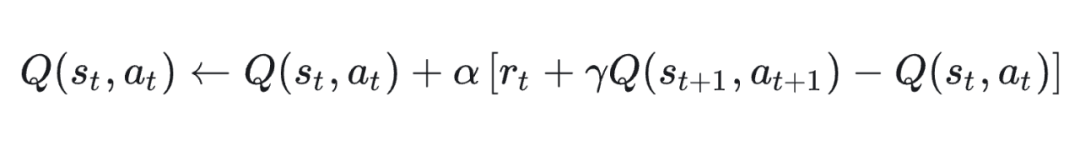
这里 是当前策略下选择的动作,强调数据和策略一致。
3.2 Off-policy示例(Q-learning)
更新公式:
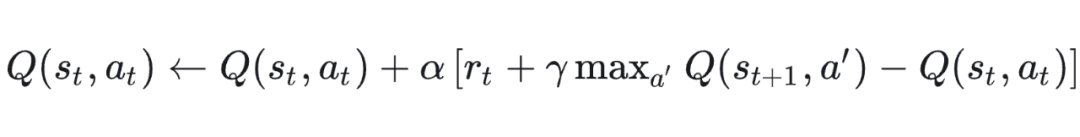
这里是对最优策略的估计,和实际采样策略(行为策略)不一致。

形象类比解释:打篮球学技术
4.1 On-policy:自己打球、自己总结
你在场上亲自尝试不同的投篮动作,每次成功或失败都由你来承担,然后你根据这些经验修正打法。这就像 PPO 或 SARSA。
特点:
-
经验真实、反馈直接
-
但成长缓慢,试错成本高
4.2 Off-policy:看视频学篮球
你通过观察 NBA 球星比赛录像,总结他们的动作套路来改进自己打法,即便你还没亲自上场。
特点:
-
可以用大量现有资源来训练
-
但如果模仿不当,学的不是精华而是“习气”

从辩证法角度分析:对立统一的范式
5.1 矛盾的主要方面:数据与策略的一致性
-
On-policy 强调“统一”,即数据来源与策略完全一致,强调策略演化的闭环性 → 学得稳。
-
Off-policy 强调“对立”,策略和数据可以不一致,带来了灵活性和效率,但也可能导致偏差。
5.2 二者的转化关系与辩证统一
在现代强化学习系统中,这两种范式并非截然对立,而是互为补充、相互转化的:
-
PPO 本质上是 on-policy,但会引入经验缓存(如 mini-batch 采样)来模拟部分 off-policy 优势;
-
Off-policy 算法如 SAC 引入目标网络、软更新等机制,来缓解策略偏移的问题,实现“偏中有正”。
这种融合方式体现了矛盾双方的动态转化和统一:在实际应用中,我们不是拘泥于某一策略范式,而是动态地根据样本效率、策略稳定性、环境可探索性来权衡取舍,寻找矛盾的主要方面,掌握其变化规律。

一句话总结
On-policy 强调“靠自己经验成长”的策略闭环,Off-policy 强调“借助他人经验学习”的策略解耦,本质区别在于数据来源与策略更新的是否一致,体现了强化学习中探索与利用的矛盾运动。
再补充一些关于 GRPO(Group Relative Policy Optimization)是属于 on-policy 还是 off-policy 问题的回答:
一、GRPO 属于 on-policy 吗?
答案是:是的,GRPO 属于 on-policy 方法。
GRPO 的全称是 Group Relative Policy Optimization,它是 PPO(Proximal Policy Optimization)的一种改进与推广,其核心思想是:在优化策略时,不仅考虑单个动作相对于旧策略的改进,还考虑在一个“动作组”(group)上的相对优势(relative advantage),从而更稳定地更新策略。
而 PPO 是典型的 on-policy 算法——每次策略更新依赖于用当前策略生成的新一批轨迹(trajectories),不会反复使用旧数据。这种训练方式也延续到了 GRPO 中,因此 GRPO 同样是 on-policy 的。
二、如何从 Q(s,a) 的视角理解 GRPO?
Q(s,a) 是动作值函数,表示在状态 s 下执行动作 a,所能获得的期望回报值。GRPO 和 Q(s,a) 并不直接估计 Q 值,但它的优化目标间接依赖于 Advantage,即 A(s,a) = Q(s,a) - V(s),而这正是理解 GRPO 的切入点。
GRPO 的目标函数类似于 PPO:
GRPO 并不是 Q-learning 那样直接回归 Q 值,而是构造了一个策略梯度目标,通过对 Advantage 的处理间接优化 Q 值对应的策略期望。
GRPO 的主要更新目标是:
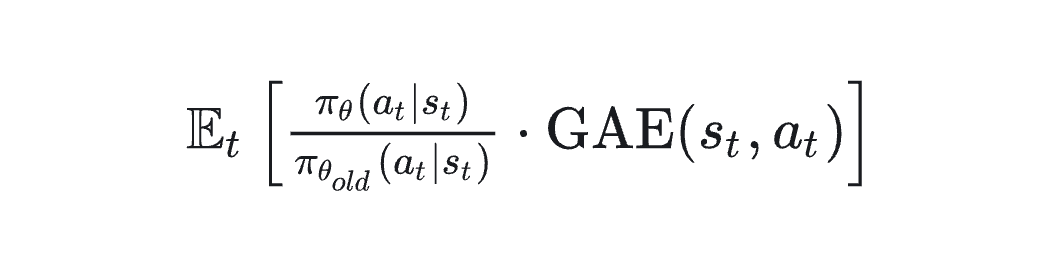
而 GRPO 的主要创新在于:它将 GAE(或 Advantage)进一步分组归一化处理,使得策略更新更关注“在当前组中是否表现得更优”,而不是只看个体差值。
三、GRPO 的 Group Relative Advantage 与 Q(s,a) 的关系
GRPO 引入了一种“Group Relative Advantage”的概念,本质是将 Advantage 做了归一化处理:
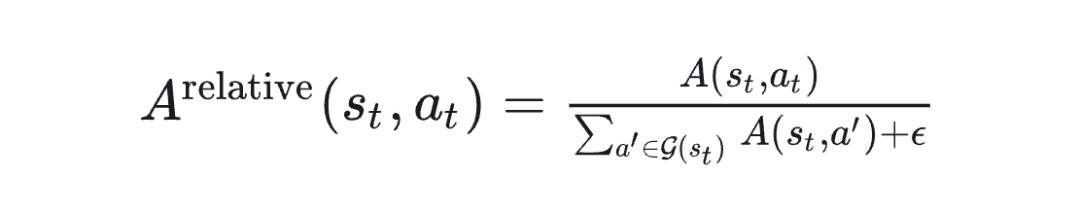
这里, 表示在状态 下的一个动作组,可以是某类动作、或是所有动作的集合(具体由设计定义)。通过这种方式,GRPO 不再盲目放大所有正的 Advantage,而是更关注相对优秀的动作,这与传统 Q(s,a) 中追求最大值的策略略有不同。
因此:
-
Q(s,a) 是对单个动作绝对好坏的估计;
-
GRPO 则强调在某一“组”内部相对的好坏。
这体现了从“绝对评价”向“相对排序”的转变,实际上引入了矛盾的相对性分析视角。
四、总结
GRPO 是一种 on-policy 策略优化方法,它在传统 Advantage 函数的基础上引入“动作组内的相对优势”作为优化依据,从 Q(s,a) 的角度看,它不是直接优化 Q 值,而是间接对 Q(s,a) 与 V(s) 的差值进行 group-wise 归一化,从而提升策略更新的稳定性与鲁棒性。
GRPO 是 on-policy 的,但我们能否将 off-policy 的优点(如样本效率高、经验可重用)引入到 GRPO 中?
1. on-policy 的 GRPO 有什么瓶颈?
先分析当前 GRPO 所面临的“主要矛盾”:
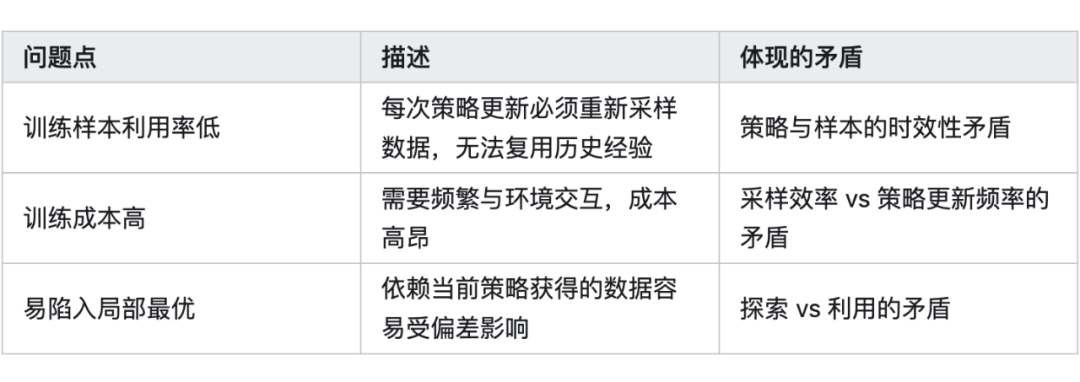
所以,我们希望能吸收 off-policy 的长处:
-
可以用历史经验(replay buffer)
-
多次重用经验,提升样本效率
-
灵活的数据采样方式
2. 如何让 GRPO 支持 off-policy?
有两个可能的方向将 off-policy 的思想融入 GRPO:
️方案一:使用“重要性采样(Importance Sampling)”来调整旧数据
核心思想:
用历史策略生成的数据样本,通过重要性权重校正其在当前策略下的贡献,从而弥补策略偏移的问题。
在 PPO 中已经使用了以下项:
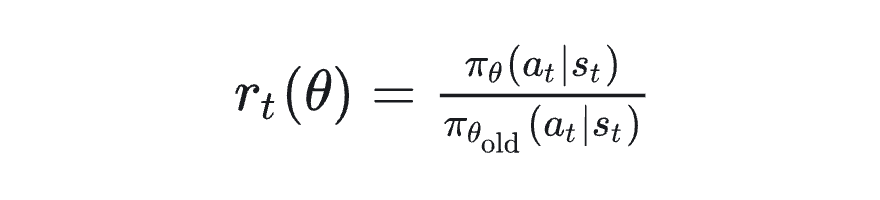
在 GRPO 中我们同样可以保留这一比例项,但将样本来自 replay buffer 而非每轮重采。
操作要点:
-
建立经验回放池(Replay Buffer)
-
每次训练从 buffer 中采样一批旧数据
-
结合 GRPO 原始目标 + ratio 校正做优化
-
可加权重剪裁避免 variance 过大
优点:
-
仍保持 GRPO 的 group-relative 逻辑
-
明确区分数据分布差异,数学上自洽
️方案二:结合“双策略”框架(双轨道优化)
引入一种“行为策略” μ 和“目标策略” π 分离的方式:
1. 采样动作轨迹用旧策略 μ
2. 学习策略是目标策略 π,优化 group-relative 的目标
3. 用 off-policy correction 技术,如 Retrace(λ)、V-trace 等方法来调整梯度
这是 DDPG、TD3、IMPALA 常用的结构。
好处:
-
可以批量采样 + 并行训练
-
保证学习策略收敛性
但难点在于:
-
如何保持 group 内归一化 advantage 的可靠性
-
比传统 off-policy 更复杂,因为 group-relative 会放大 variance
3. 引入 off-policy 的 GRPO 目标函数(示意)
假设我们保留 group-relative 的结构,同时加入 off-policy correction 权重 r(s,a),可得:
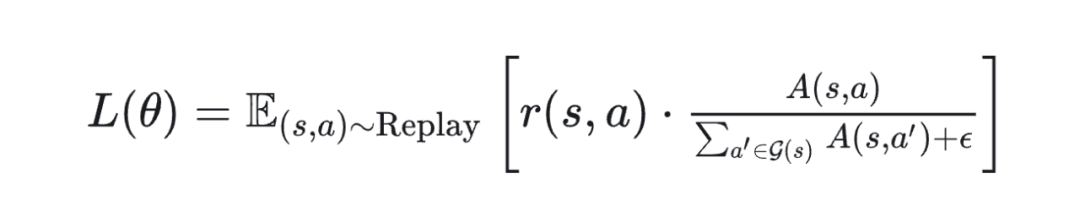
其中:
-
Advantage 来自一个 Q(s, a) - V(s) 模型(或 GAE)
-
可选用 critic 网络做辅助估计
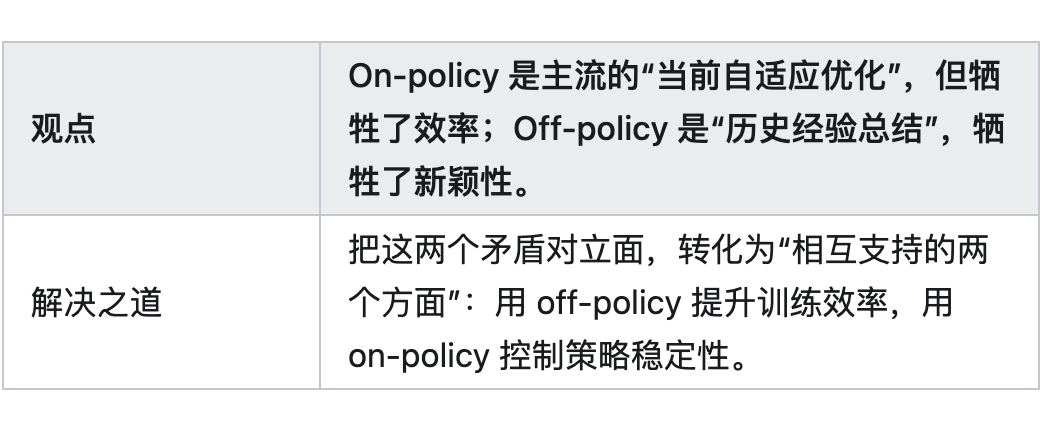
四、从辩证法视角看“融合”的意义
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)