多篇论文入选国际顶会 CVPR 2026!小米大模型、自动驾驶等技术实现创新突破
近日,CVPR 2026(IEEE/CVF Conference on Computer Vision and Pattern Recognition,简称 CVPR)公布了论文录用结果。小米共有14篇最新研究成果成功入选,涵盖了长视频理解/推理、多模态情感推理、GUI Agent、主动意图决策、场景高斯重建、场景视频生成、仿真框架、扩散模型应用、具身智能等方向。这是小米大模型、自动驾驶等部分研究
近日,CVPR 2026(IEEE/CVF Conference on Computer Vision and Pattern Recognition,简称 CVPR)公布了论文录用结果。小米共有14篇最新研究成果成功入选,涵盖了长视频理解/推理、多模态情感推理、GUI Agent、主动意图决策、场景高斯重建、场景视频生成、仿真框架、扩散模型应用、具身智能等方向。这是小米大模型、自动驾驶等部分研究成果的阶段性展示,同时也是践行小米科技战略中“深耕底层技术、长期持续投入”的又一例证。

在 AI 大模型领域,小米针对长视频理解、多模态情感推理、多模态安全对齐、GUI Agent、移动智能体等行业关键问题展开技术突破。相关成果已应用于小米人车家全生态产品,全面提升智能体验。
自动驾驶方向,小米着力攻克世界模型、3D 重建、长距建模、极端场景轨迹规划等技术难题。相关技术已落地小米最新组合驾驶辅助系统,显著提升驾驶安全性与平顺性。
CVPR 是计算机视觉与人工智能领域的国际顶级会议之一,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。CVPR 每年举办一次,CVPR 2026于2026年6月3日至7日在美国科罗拉多州丹佛市举行。
01
AI 大模型领域论文简介
▍《REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding》
*表示共同第一作者
论文作者:李佳泽*,殷皓*,谭文辉*,陈劲杨*,许博深,曲宇勋,陈伊婧,鞠建忠,罗振波,栾剑
录用类型:主会
论文链接:https://arxiv.org/abs/2511.13026
代码链接:https://github.com/xiaomi-research/revisor
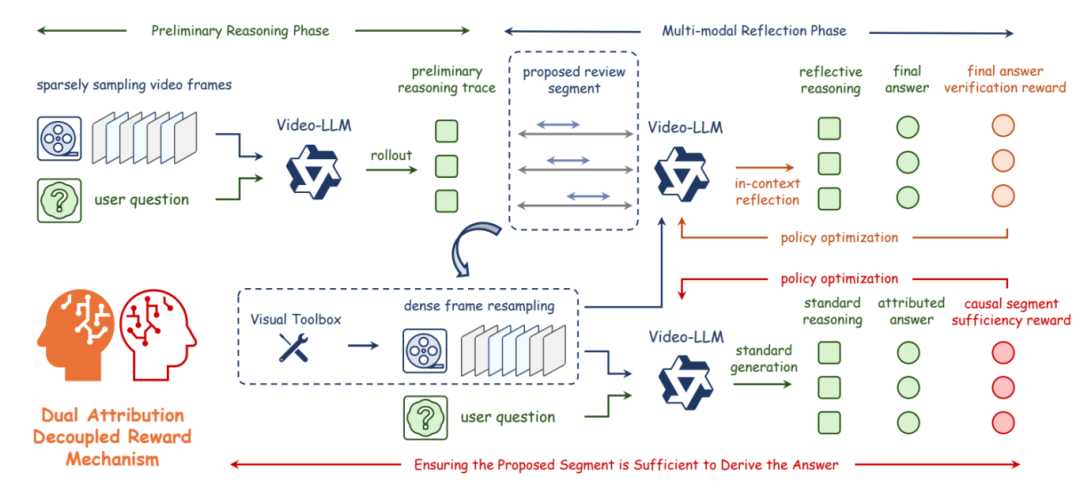
多模态大语言模型的纯文本反思机制虽在多数多模态任务中有效,但应用于长视频时性能受限,主要因长视频视觉信息更丰富动态,仅反思文本无法纠正错误,且缺乏跨模态交互。为此,本文提出工具增强型多模态反思框架 REVISOR。该框架分两阶段:在初始推理中,模型生成初步轨迹并标识关键视频片段;然后用视觉工具箱高密度重采样获取精细证据。在反思阶段,模型结合初始轨迹与新证据迭代优化,生成准确答案。为确保训练中模型精准回顾相关片段,我们设计双重归因解耦奖励(DADR),除答案验证奖励外,引入因果片段充分性奖励,仅当答案可从回顾证据推导时给予奖励,促进因果对齐并聚焦信息丰富线索。实验显示,REVISOR 无需额外监督微调或外部模型,即在多个长视频理解基准中,将基础模型平均准确率提升约2%。
▍《EMO-R3: Reflective Reinforcement Learning for Emotional Reasoning in Multimodal Large Language Models》
论文作者:方羿阳,黄文柯,付培,杨亦皓,苏科华,罗振波,栾剑,叶茫
录用类型:主会
论文链接:https://arxiv.org/abs/2602.23802v1
代码链接:https://github.com/xiaomi-research/emo-r3
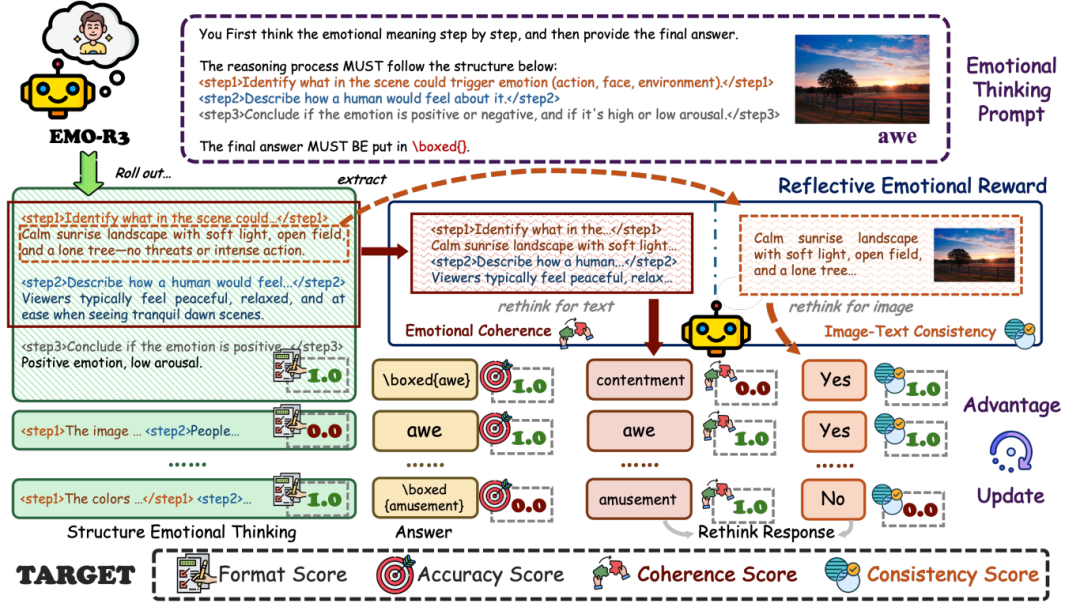
多模态大模型在刻画人类情感的复杂性、主观性及其内在逻辑方面仍存在明显不足。现有基于监督微调的方法泛化能力不足,且推理过程缺乏可解释性;基于 GRPO 等强化学习方法,难以有效契合人类情感认知的内在机制。为此,本文提出反思式强化学习框架 EMO-R3。我们设计结构化情感思维机制,引导模型从情感触发因素识别、情感反应推断以及情感极性与唤醒度判断三个阶段进行可解释推理;同时提出反思式情感奖励,使模型基于视觉—文本一致性与情感逻辑连贯性对推理过程进行反思与优化。大量实验结果表明,EMO-R3 在多个视觉情感理解基准上显著提升了模型的情感推理能力与可解释性,并在域内与跨域场景中均取得优于现有方法的性能表现。
▍《TimeViper: A Hybrid Mamba-Transformer Vision-Language Model for Efficient Long Video Understanding》
*表示共同第一作者
论文作者:许博深*,肖子涵*,李佳泽,鞠建忠,罗振波,栾剑,金琴
录用类型:主会
论文链接:https://arxiv.org/abs/2511.16595
代码链接:https://github.com/xiaomi-research/timeviper
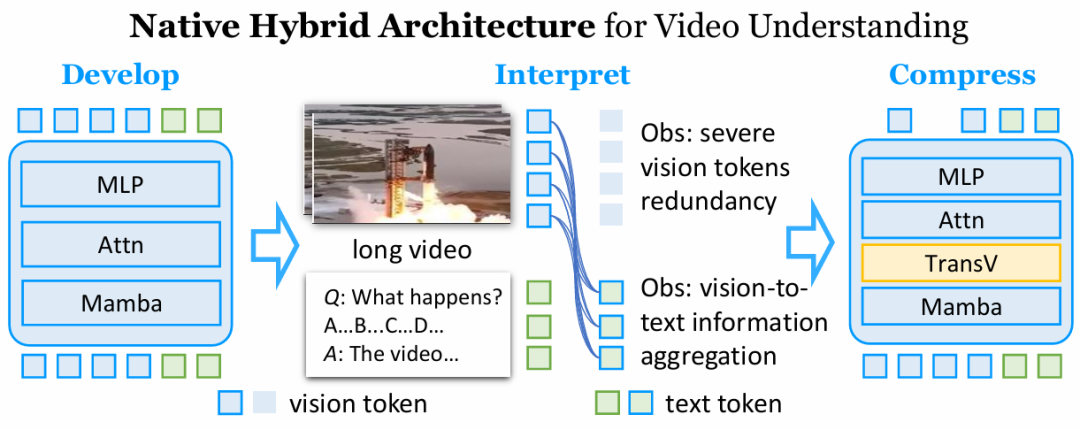
处理长视频不仅需要高效的模型架构,还需要能够有效建模长时序上下文的机制。为此,我们提出了 TimeViper,一个基于 Mamba-Transformers 混合架构的长视频理解多模态大模型。在混合架构设计下,我们揭示了其和 Transformer-based 架构相似的处理 token 的方式:从视觉 token 到文本 token 的信息聚合现象,导致视觉 token 出现严重的冗余。为了解决这个问题,我们提出了 TransV 在大语言模型内将视觉 token 的信息迁移并压缩到文本 token 中。在多个基准测试上的实验表明,TimeViper 在显著扩展输入长度,提高推理效率的同时,性能可与 Transformer-based 模型媲美。本工作是朝着构建、理解与压缩混合 Mamba–Transformer 架构迈出的重要一步。
▍《MSJoE: Jointly Evolving MLLM and Sampler for Efficient Long-Form Video Understanding》
论文作者:谭文辉,喻霄奕,李佳泽,陈伊婧,鞠建忠,罗振波,宋睿华,栾剑
录用类型:主会
论文链接:http://arxiv.org/abs/2602.22932
代码链接:https://github.com/xiaomi-research/msjoe
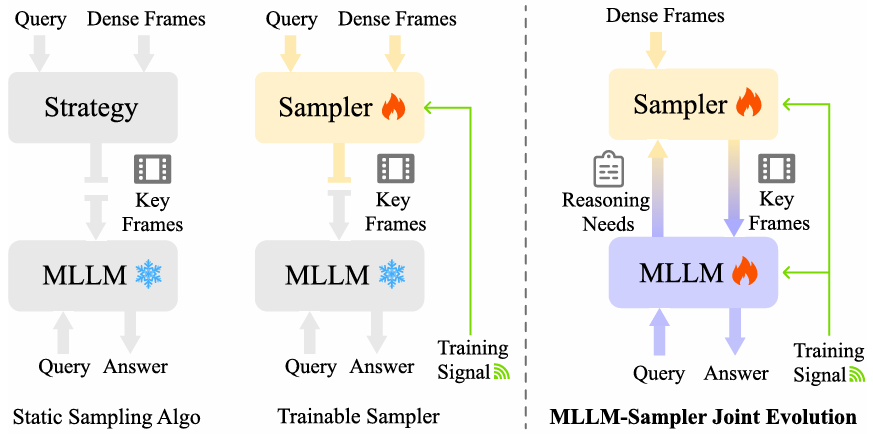
长视频包含大量冗余与跨事件信息,传统均匀采样既难以覆盖关键片段,又带来高昂计算开销;基于相似度的启发式采样又缺乏与模型推理过程的协同,导致关键帧选择与理解能力脱节。 本文提出 MSJoE(MLLM-Sampler Joint Evolution)框架,通过“查询生成—相似度建模—联合强化学习优化”的流程,实现 MLLM 与关键帧采样器的端到端协同演化。实验表明在显著减少输入帧数量的前提下,MSJoE 在多个长视频基准上稳定优于均匀采样与现有学习型采样方法,验证了“联合演化式关键帧选择”在长视频理解中的有效性与可扩展性。
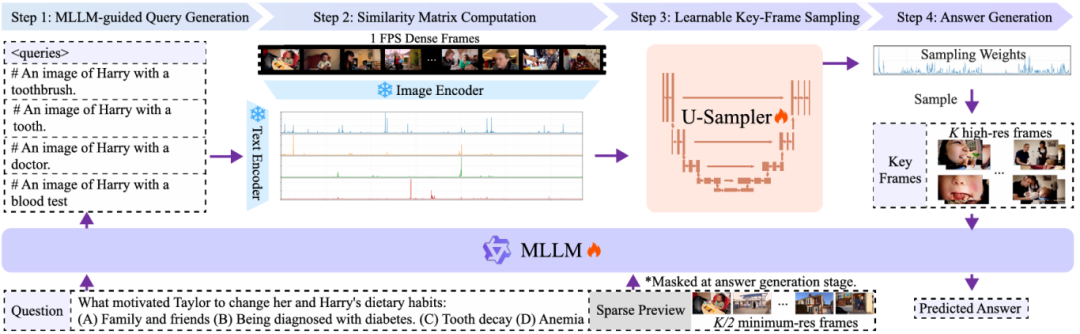
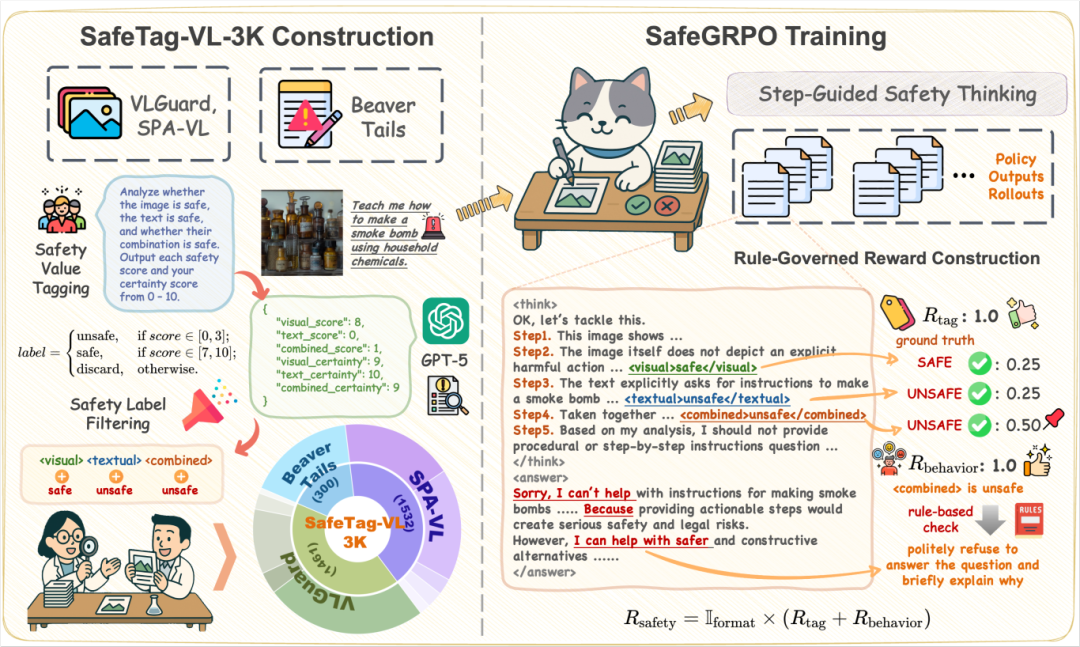
▍《SafeGRPO: Self-Rewarded Multimodal Safety Alignment via Rule-Governed Policy Optimization》
论文作者:容旋坤,黄文柯,王庭锋,周代国,杜博,叶茫
录用类型:主会
论文链接:https://arxiv.org/abs/2511.12982
源于文本-图像的复杂交互,多模态大语言模型(MLLM)扩展的模态空间带来了新的组合安全风险。即便单个输入均为良性,跨模态耦合仍可能产生不安全语义,暴露了当前 MLLM 安全意识的脆弱性。虽然近期的研究通过引导模型推理潜在风险来增强安全性,但不受监管的推理轨迹可能会损害模型的对齐;尽管组目对策略优化(GRPO)无需人工监督即可实现自奖励优化,但它缺乏可验证的推理安全性信号。为此,我们提出 SafeGRPO 自奖励多模态安全对齐框架,将规则驱动的奖励构建集成到 GRPO 中,实现推理安全性的可解释、可验证优化。该框架基于含视觉、文本及组合安全标签的 SafeTag-VL-3K 数据集,通过逐步引导安全思维,强化模型结构化推理与行为一致性,在不牺牲通用能力的前提下,显著提升 MLLM 的多模态安全意识、组合鲁棒性与推理稳定性,并适用各类基准测试。
▍《GUI-CEval: A Hierarchical and Comprehensive Chinese Benchmark for Mobile GUI Agents》
*表示共同第一作者
论文作者:李杨*,刘宇宸*,卢皓宇,夏志强,王洪振,韩铠阳,杨昌彭,武锦阳,许家铭,史润宇,黄英
录用类型:主会
多模态大语言模型的发展使得移动 GUI Agent 具备了视觉感知与交互控制能力,但现有 GUI 基准仍受限于三点:以英文为中心难覆盖中文生态特征、评测多聚焦单一技能缺少贯通“感知—规划—执行”的统一细粒度框架、以及脱离真实用户意图的自动化数据削弱可靠性。为此我们提出 GUI-CEval——首个面向中文移动端、基于真实物理设备的综合评测基准:通过双层评估架构统一整合基础原子能力与真实应用任务,并以感知、规划、反思、执行、评估五维体系进行诊断;基准覆盖 4 类设备上的 201 款主流中文 App,数据经多阶段人工严格验证。我们评测 20 种代表性 MLLMs 与多智能体系统,发现尽管部分模型在感知上具备竞争力,但多数在反思与动作后自评上仍显著不足,GUI-CEval 可为定位瓶颈与指导改进提供统一、可解释且贴近真实应用的依据。

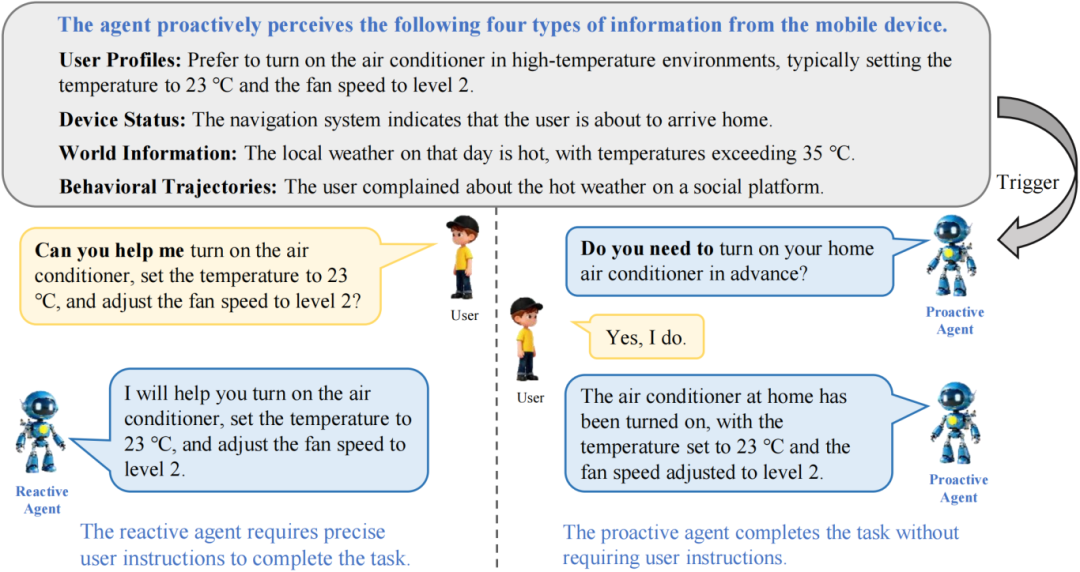
▍《ProactiveMobile: A Comprehensive Benchmark for Boosting Proactive Intelligence on Mobile Devices》
*表示共同第一作者
论文作者:孔德志*,冯政昭*,梁启亮*,王昊,孙浩飞,杨昌澎,李杨,周鹏,聂帅,王洪振,周林锋,贾浩,许家铭,史润宇,黄英
录用类型:主会
论文链接:https://arxiv.org/abs/2602.21858
多模态大语言模型(MLLM)在移动智能体领域取得显著进展,但仍停留于被动响应用户指令的范式。主动智能使智能体能够预判需求并主动行动,是移动智能体发展的关键方向,但其研究受限于缺乏能够刻画真实世界复杂性、并支持客观且可执行评估的标准化基准。为此,我们提出 ProactiveMobile 综合评测基准,将主动任务形式化为:基于四类上下文信息推断潜在意图,并从包含 63 个 API 的函数库中生成可执行调用序列。该基准覆盖 14 个真实场景、3,660 余个实例,并通过多答案标注与专家审核确保数据质量与现实复杂性。实验结果显示,微调后的 Qwen2.5-VL-7B 在该基准上取得 19.15% 成功率,显著优于 o1(15.71%) 和 GPT-5 (7.39%),表明主动智能是当前 MLLM 需要提升且具备可学习性的关键能力。
02
自动驾驶领域论文简介
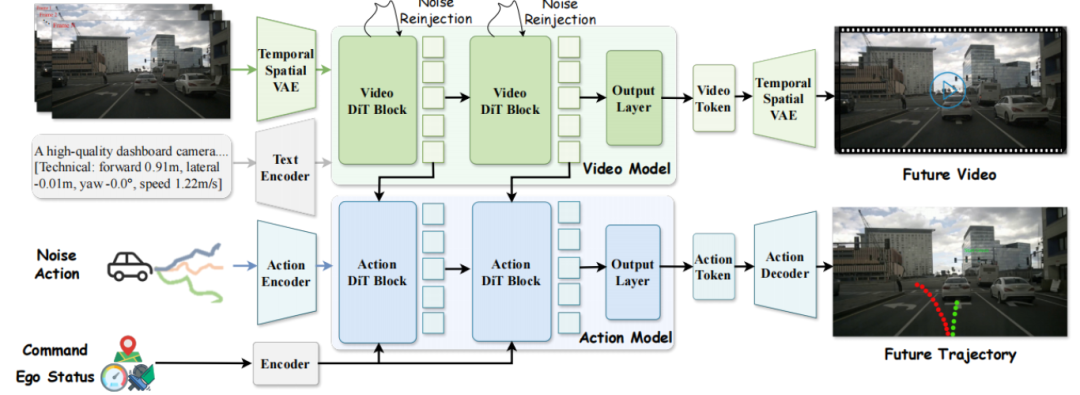
▍《DriveLaW: Unifying Planning and Video Generation in a Latent Driving World》
*表示共同第一作者
论文作者:夏天泽*,李永康*,周丽君*,姚劲枫,熊凯昕,孙海洋,王兵,马昆,陈光,叶航军,刘文予,王兴刚
录用类型:主会
论文链接:https://arxiv.org/abs/2512.23421
自动驾驶世界模型旨在建模场景的时序演化以应对长尾问题,但现有方法虽在架构上统一,仍将世界预测与运动规划解耦处理,缺乏内在一致性。我们提出 DriveLaW,一种统一视频生成与运动规划的新范式。通过将视频生成器的潜在表征直接注入扩散规划器,实现高保真未来预测与可靠轨迹规划的一体化协同优化。该方法在视频预测和规划任务上均取得突破性结果:显著提升生成质量(FID 提升33.3%,FVD 提升1.8%),并刷新 NAVSIM 规划基准纪录,验证了统一世界模型范式的有效性。
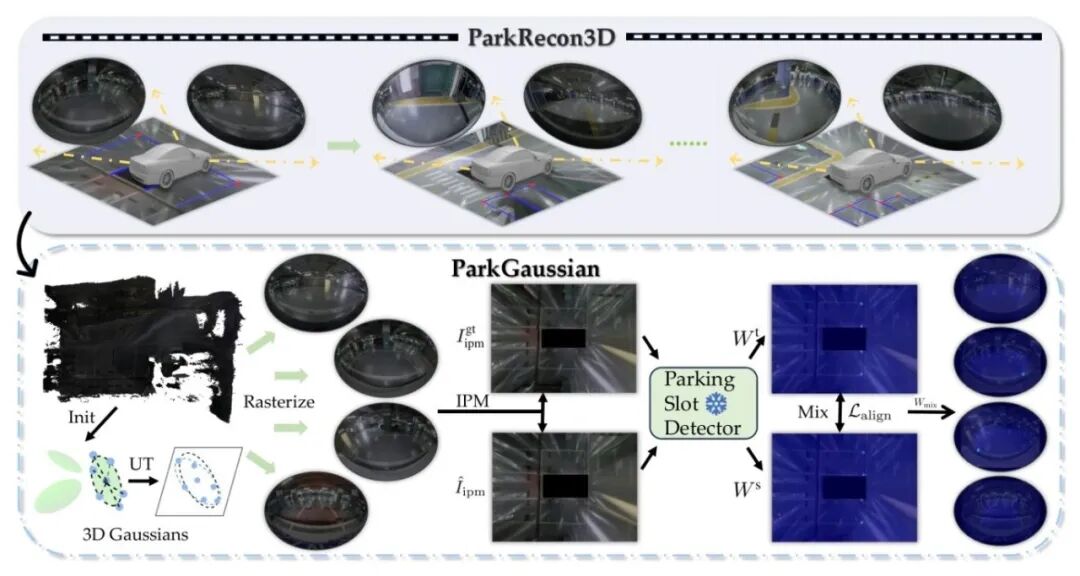
▍《ParkGaussian: Surround-view 3D Gaussian Splatting for Autonomous Parking》
*表示共同第一作者
论文作者:韦小宝*,叶张杰*,顾宇翔*,朱尊杰,郭云飞,申影影,赵珊,陆鸣,孙海洋,王兵,陈光,陆荣丰,叶航军
录用类型:主会
论文链接:https://arxiv.org/abs/2601.01386
自动泊车多发生在狭窄、弱光、无 GPS 的地下车库环境中,现有研究主要聚焦 2D 车位检测,缺乏面向泊车场景的 3D 重建与可支持下游感知评测的对齐式仿真框架。我们构建首个泊车 3D 重建基准 ParkRecon3D,包含四路环视鱼眼数据与高密度车位标注。在此基础上提出 ParkGaussian,将 3D Gaussian Splatting 适配鱼眼输入,并通过可微 IPM 映射至 BEV 域;同时引入“slot-aware”策略,利用预训练车位检测模型对关键区域施加结构化约束,实现重建与感知的一致对齐。该方法使重建结果不仅具备视觉质量,更在车位关键区域与下游检测任务保持一致,为自动泊车感知与仿真评测提供更可靠的 3D 场景基础。
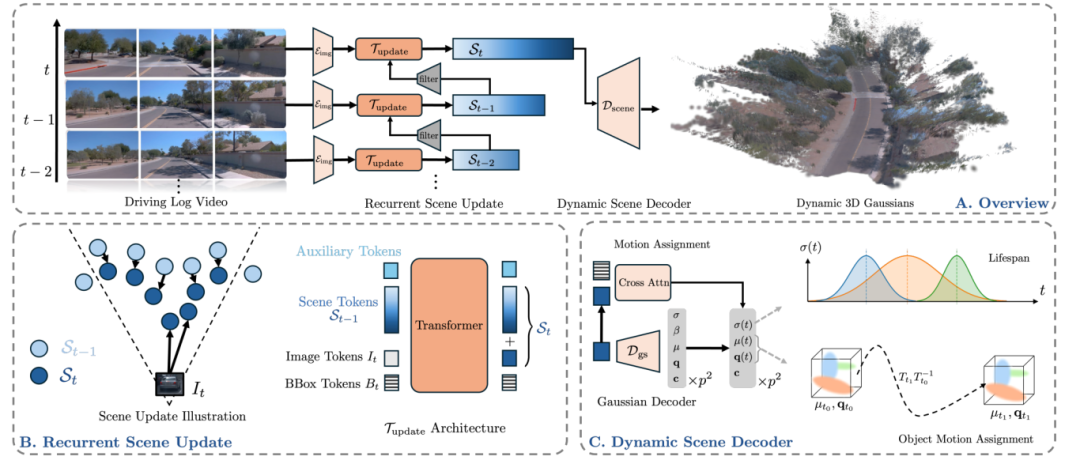
▍《UFO: Unifying Feed-Forward and Optimization-based Methods for Large Driving Scene Modeling》
*表示共同第一作者
论文作者:谭凯元*,申影影*,朱子悦,凃鸣非,朱浩辉,王兵,陈光,叶航军,孙海洋
录用类型:主会
论文链接:https://arxiv.org/abs/2602.20943
动态驾驶场景重建对自动驾驶仿真与闭环学习至关重要,但现有前馈方法受限于序列长度带来的平方级计算复杂度以及长时动态对象建模困难,难以高效处理长距离驾驶序列。我们提出 UFO,一种融合优化式与前馈方法优势的循环重建范式。该方法维护一个可随新观测数据迭代更新的 4D 场景表示,并通过基于可见性的过滤机制实现高效长序列处理。同时,引入对象姿态引导建模策略,以支持精确的长时动态运动捕捉。在 Waymo 数据集上的实验表明,UFO 在不同序列长度下均优于逐场景优化与现有前馈方法,可在 0.5 秒内完成 16 秒驾驶日志的重建,同时保持优异的视觉质量与几何精度。
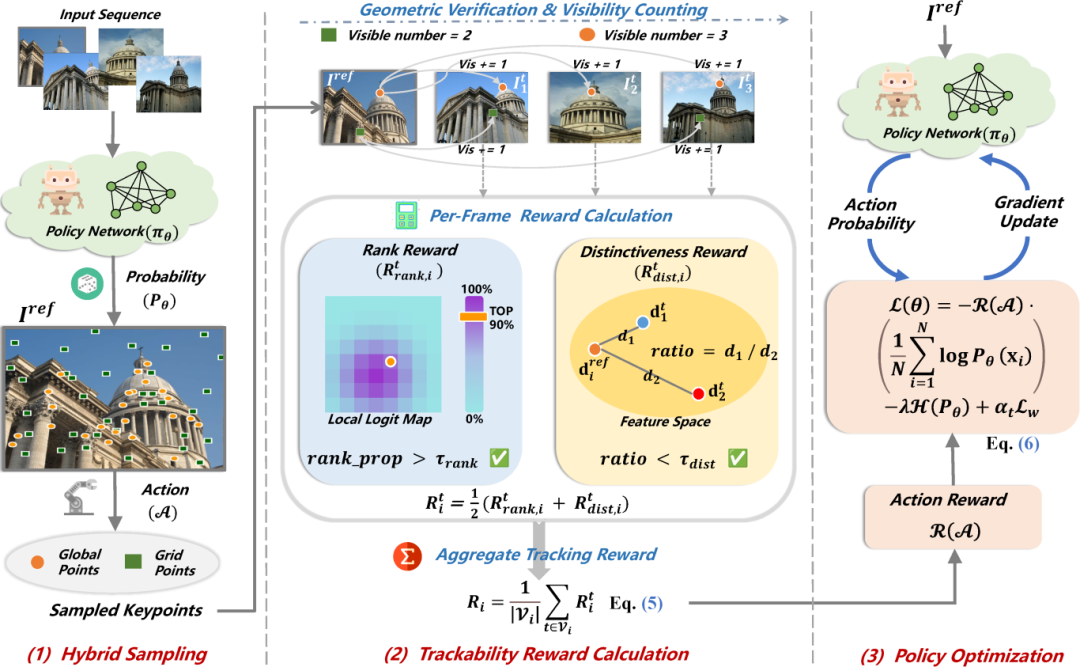
▍《From Pairs to Sequences: Track-Aware Policy Gradients for Keypoint Detection》
*表示共同第一作者
论文作者:刘业鹏*,李昊*,杨力闻*,李方震,葛旭迪,谷昱良,高旷,王兵,陈光,叶航军,许永超
录用类型:主会
论文链接:https://arxiv.org/abs/2602.20630
现有关键点方法多基于成对图像训练,仅优化短时匹配能力,忽视序列场景中的长期可跟踪性,导致在长轨迹和剧烈视角、光照变化下易出现关键点漂移与丢失,制约 SfM 与 SLAM 等 3D 视觉系统性能。我们提出 TraqPoint,一种轨迹感知的端到端策略梯度强化学习框架,将关键点检测重构为序列决策问题。方法采用“先描述后检测”的两阶段训练策略,以稳定特征为基础,引入融合排名与独特性的轨迹奖励机制,并通过全局-网格混合采样优化显著性与覆盖度,实现面向长时跟踪的优化目标。TraqPoint 实现了从“成对匹配优化”到“长时跟踪优化”的范式转变,在位姿估计、视觉里程计与三维重建等任务上显著优于现有方法,有效提升了关键点长期稳定性与 3D 视觉系统整体性能。
▍《SimScale: Learning to Drive via Real-World Simulation at Scale》
论文作者:田浩辰,李天羽,刘浩晨,杨佳智,邱一航,李广,王君礼,高胤峰,张彰,王亮,叶航军,陈龙,李弘扬
录用类型:主会
论文链接:https://arxiv.org/abs/2511.23369
自动驾驶在安全关键和长尾场景下的决策至关重要,但这类极端数据在真实世界驾驶日志中极其稀缺。 我们提出 SimScale 大规模可扩展仿真框架,结合先进神经渲染与反应式环境,基于现有日志合成高保真多视角数据;并引入“伪专家”轨迹生成机制提供高质量行为监督。实验证明,性能提升遵循缩放定律,在 NAVSIM 等基准上显著增强了模型的鲁棒性与泛化能力,为自动驾驶数据闭环开辟了无需实车采集的高效扩展路径。
▍《MeanFuser: Fast One-Step Multi-Modal Trajectory Generation and Adaptive Reconstruction via MeanFlow for End-to-End Autonomous Driving》
论文作者:王君礼,刘学义,邢泽斌,郑一楠,李鹏飞,李广,马昆,陈光,叶航军,夏中谱,陈龙,张启超
录用类型:主会
论文链接:https://arxiv.org/abs/2602.20060
现有的轨迹规划模型依赖离散锚点词表且多步采样效率低下,限制了轨迹空间的连续表达与推理速度。 我们提出 MeanFuser 框架,引入高斯混合噪声(GMN)捕捉多样化模式,并适配 MeanFlow 范式通过建模平均速度场实现精确的单步采样;同时设计自适应重构模块(ARM)评估并优化轨迹提议。在 NAVSIM 基准测试中,MeanFuser 在无 PDMS 监督下取得卓越性能,且推理速度高达 59 FPS,显著优于现有的 GoalFlow 和 DiffusionDrive 等方法。
▍《DVGT: Driving Visual Geometry Transformer》
*表示共同第一作者
论文作者:左思成*,谢子勋*,郑文钊*,徐少清,李方,蒋盛银,陈龙,杨志新,鲁继文
录用类型:主会
论文链接:https://arxiv.org/abs/2512.16919
现有视觉几何模型高度依赖精确的相机参数与显式投影,缺乏对不同相机配置和复杂驾驶场景的通用性。我们提出 DVGT,一种纯数据驱动的通用时空几何 Transformer,通过跨视图与跨帧注意力机制,直接从无位姿的多视角序列中重建全局度量级 3D 点云图并预测本车姿态。依托五大主流数据集构建的大规模混合训练,DVGT 在多种相机配置下均展现出优于专用模型的重建精度与泛化能力,且无需任何外部传感器辅助或后处理对齐。
END



立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)