【youcans论文精读】基于 DINOv3 的实时目标检测
本文提出DEIMv2实时目标检测器,创新性地融合DINOv3特征与空间调优适配器(STA),构建覆盖GPU、边缘及移动设备的8种模型尺寸。
欢迎关注『youcans论文精读』系列
【youcans论文精读】基于 DINOv3 的实时目标检测
0. 论文简介
0.1 基本信息
2025年 10月,Huang, S 等 在 arXiv 发布论文 【基于 DINOv3 的实时目标检测】(Real-Time Object Detection Meets DINOv3)。
本文提出 DEIMv2 实时目标检测器,融合 DINOv3 特征与空间调优适配器(STA),涵盖 8 种适配 GPU、边缘及移动设备的模型尺寸,通过简化解码器和升级 Dense O2O,在 COCO 数据集上实现全尺度场景下的性能突破,如 DEIMv2-X 以 50.3M 参数达 57.8 AP、DEIMv2-S 首破 10M 内 50 AP,全面超越现有 SOTA 方法。
论文下载: arxiv,Intellindust-ai-lab
项目地址:github
引用格式: Huang, S., Hou, Y., Liu, L., Yu, X., & Shen, X. (2025). Real-Time Object Detection Meets DINOv3. arXiv. [Online]. Available: https://arxiv.org/pdf/2509.20787
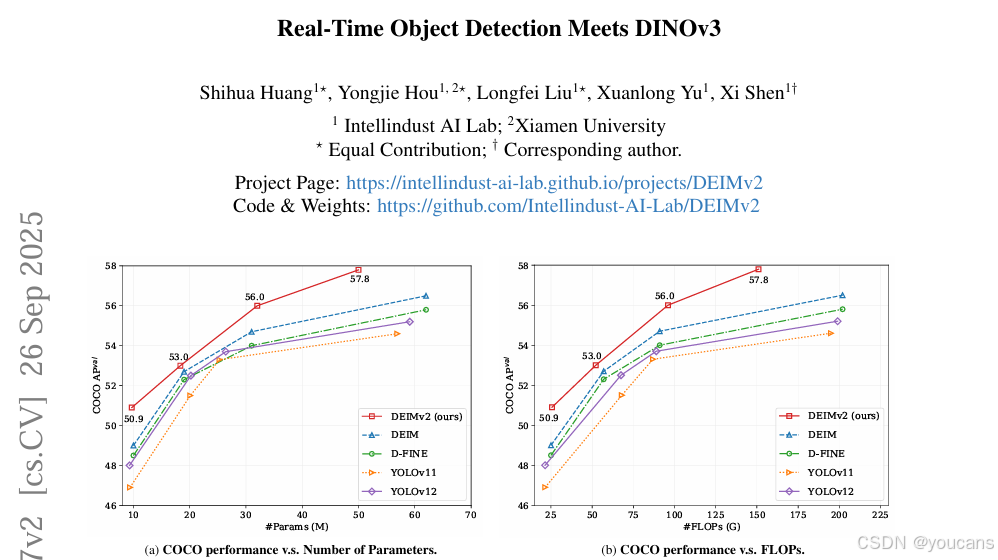
0.2 论文概览
本文提出 DEIMv2—— 一款融合 DINOv3 特征的实时目标检测器,涵盖从 X 到 Atto 的 8 种模型尺寸,适配 GPU、边缘及移动设备部署;其大尺寸模型(X/L/M/S)采用 DINOv3 预训练 / 蒸馏骨干网与空间调优适配器(STA) ,将单尺度输出转为多尺度特征,超轻量模型(Nano/Pico/Femto/Atto)基于剪枝后的 HGNetv2 构建;同时通过简化解码器(替换为 SwiGLUFFN 与 RMSNorm、共享查询位置嵌入)和升级Dense O2O(引入 Copy-Blend 增强),实现性能 - 成本平衡;在 COCO 数据集上,DEIMv2-X 以 50.3M 参数达 57.8 AP,DEIMv2-S(9.71M 参数)首破 50 AP,DEIMv2-Pico(1.5M 参数)匹配 YOLOv10-Nano(2.3M 参数)性能,全面超越现有 SOTA 方法。
主要贡献:
- 提出覆盖 GPU→边缘→移动设备的 8 尺寸统一框架,首次将 DINOv3 有效适配实时目标检测;
- 设计 STA 组件,参数无关地实现多尺度特征转换,补充细节信息;
- 优化解码器与 Dense O2O,在不损失精度的前提下降低计算成本;
- 实验验证 DEIMv2 在全尺寸范围超越现有方法,为不同部署场景提供高效解决方案。

0.3 摘要
得益于 Dense O2O(密集一对一匹配)和 MAL(匹配感知损失)的简洁性与有效性,DEIM 已成为实时 DETR(基于 Transformer 的目标检测器)的主流训练框架,其性能显著优于 YOLO 系列模型。
在本文中,我们为 DEIM 融入 DINOv3 特征,提出了改进版本 DEIMv2。DEIMv2 涵盖从 X 型到 Atto 型的 8 种模型尺寸,可适配 GPU、边缘设备及移动设备部署。
其中,X、L、M、S 四种型号采用经 DINOv3 预训练或蒸馏得到的骨干网络,并引入空间调优适配器(STA)—— 该适配器能高效将 DINOv3 的单尺度输出转换为多尺度特征,同时以细粒度细节补充强语义信息,从而提升检测性能;对于超轻量型号(Nano、Pico、Femto、Atto),我们采用经深度与宽度剪枝的 HGNetv2,以满足严格的资源预算要求。
结合简化解码器与升级后的 Dense O2O,这种统一设计使 DEIMv2 在不同场景下均能实现更优的性能 - 成本平衡,创下新的当前最优(SOTA)结果。值得注意的是,我们最大的模型 DEIMv2-X 仅用 5030 万参数就实现了 57.8 的 COCO 平均精度(AP),超越了此前需 6000 万以上参数才能达到 56.5 AP 的 X 型尺度模型;在轻量模型端,DEIMv2-S 是首个参数低于 1000 万(仅 971 万)却能在 COCO 数据集上突破 50 AP 的模型,最终达到 50.9 AP;即便超轻量型号 DEIMv2-Pico,仅用 150 万参数就实现了 38.5 AP,与 YOLOv10-Nano(230 万参数)性能相当,且参数数量减少约 50%。
1. 引言
实时目标检测 [6,18,22,29] 是众多实际应用中的关键组件,涵盖自动驾驶 [11]、机器人技术 [16] 以及工业缺陷检测 [8] 等领域。如何在检测性能与计算效率之间实现良好平衡,仍是一项核心挑战,对于适用于边缘设备和移动设备的轻量级模型而言,这一挑战尤为突出。
在主流实时目标检测器中,基于 DETR(检测 Transformer)的方法凭借其端到端设计以及 Transformer 所赋予的强大模型容量,吸引了越来越多的关注,实现了更优的(性能与效率)权衡。在这一范式下,DEIM 已成为一种性能出色的训练框架,推动了实时 DETR 的发展,并打造出该领域的领先模型。与此同时,DINOv3 [21] 在多种视觉任务中均展现出卓越的特征表示能力,但其在实时目标检测领域的潜力尚未得到充分挖掘。
本文中,我们提出 DEIMv2—— 一种基于此前 DEIM [7] 框架构建,并融合 DINOv3 [21] 特征的实时目标检测器。对于 DEIMv2 的大型型号(L 型和 X 型),为最大化特征丰富度,我们采用官方 DINOv3 预训练骨干网络(ViT-Small 和 ViT-Small+);而 S 型和 M 型则选用从 DINOv3 蒸馏得到的 ViT-Tiny 和 ViT-Tiny + 骨干网络,在性能与效率之间进行精细平衡。为应对超轻量级应用场景,我们进一步推出四种专用型号(Nano、Pico、Femto 和 Atto),使 DEIMv2 的可扩展性覆盖更广泛的计算资源预算范围。
为在实时性约束下,更好地利用经大规模数据预训练的 DINOv3 所具备的强大特征表示能力,我们设计了空间调优适配器(STA)。STA 与 DINOv3 并行工作,能以无参数方式将 DINOv3 的单尺度输出高效转换为目标检测所需的多尺度特征;同时,它对输入图像进行快速下采样,生成感受野极小的细粒度多尺度细节特征,以此补充 DINOv3 的强语义信息。
我们还借鉴 Transformer 领域的前沿进展,对解码器进行简化。具体而言,我们用 SwiGLUFFN [20] 和 RMSNorm [27] 分别替代传统的前馈网络(FFN)和层归一化(LayerNorm)—— 这两种组件已被证明能在不显著影响性能的前提下提升效率。此外,我们注意到,在迭代优化过程中,目标查询位置的变化极小,这一发现促使我们在所有解码层间共享查询位置嵌入。在此基础上,我们通过引入目标级 Copy-Blend 数据增强策略对 Dense O2O 进行改进,该策略可增强有效监督,进一步提升模型性能。
在 COCO [12] 数据集上开展的大量实验表明,DEIMv2 在多种模型尺度下均实现了当前最优(SOTA)性能,这一点可从图 1 中看出。尽管结构简洁,DEIMv2 系列模型仍展现出强劲性能:例如,我们最大的型号 DEIMv2-X 仅用 5030 万参数就在 COCO 数据集上实现了 57.6 的平均精度(AP),超越了此前性能最佳的 X 型尺度检测器 DEIM-X—— 后者需 6000 万以上参数,却仅能达到 56.5 AP;在轻量级模型端,DEIMv2-S 创下重要里程碑,成为首个参数少于 1000 万却能突破 50 AP 的模型,彰显了我们在轻量级模型设计上的有效性;此外,超轻量级型号 DEIMv2-Pico 仅用 150 万参数就实现了 38.5 AP,性能与 YOLOv10-Nano(230 万参数)相当,同时参数数量减少约 50%,从而重新定义了极轻量级模型领域的效率 - 精度边界。
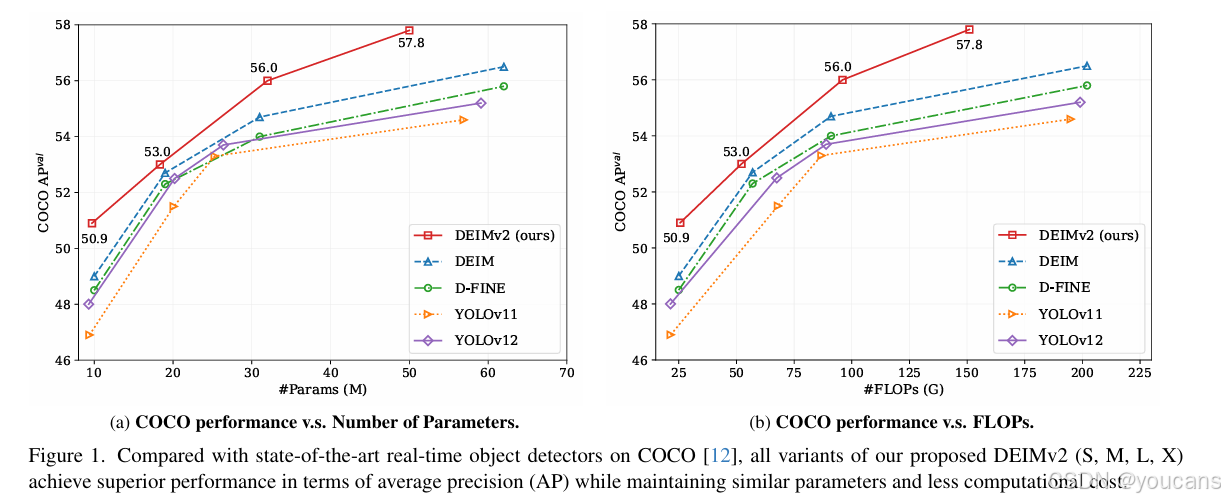
图1. 在 COCO [12] 上与当前最先进的实时目标检测器相比, DEIMv2(S、M、L、X)所有变体在平均精度(AP)上均取得更优性能,同时保持相近参数量与更低计算成本。
本文的研究表明,DINOv3 [21] 特征可有效适配于实时目标检测任务,并提供了一个涵盖超轻量级到高性能模型的通用框架。据我们所知,本文是实时目标检测领域首个同时覆盖如此广泛部署场景的研究工作。
本文的主要贡献总结如下:
- 提出 DEIMv2,该检测器提供 8 种模型尺寸,可覆盖 GPU、边缘设备及移动设备部署场景;
- 对于大型模型,利用 DINOv3 获取强语义特征,并引入 STA,将其高效整合到实时目标检测中;
- 对于超轻量级模型,借助专业知识对 HGNetv2-B0 的深度和宽度进行有效剪枝,以满足严格的计算资源约束;
- 除骨干网络外,进一步简化解码器并升级 Dense O2O,进一步突破性能边界;
- 最终在 COCO 数据集上证明,DEIMv2 在所有资源配置下均优于现有当前最优方法,创下新的 SOTA 结果。
2. 方法
2.1 整体架构
DEIMv2 的整体架构沿用 RT-DETR [14] 的设计框架,由骨干网络(backbone)、混合编码器(hybrid encoder)和解码器(decoder)三部分组成。
如表 1 所示,对于主流型号(X、L、M、S),其骨干网络基于 DINOv3 构建,并集成了本文提出的空间调优适配器(STA);其余超轻量级型号则采用 HGNetv2 [1] 作为骨干网络。
骨干网络输出的多尺度特征首先经过编码器处理,生成初始检测结果并筛选出 Top-K 候选边界框;随后解码器对这些候选框进行迭代优化,最终生成目标检测预测结果。
表 1. DEIMv2 各变体的架构细节与主要结果。我们列出了不同变体的配置,以及在 COCO 基准上的最终平均精度(Average Precision,AP)。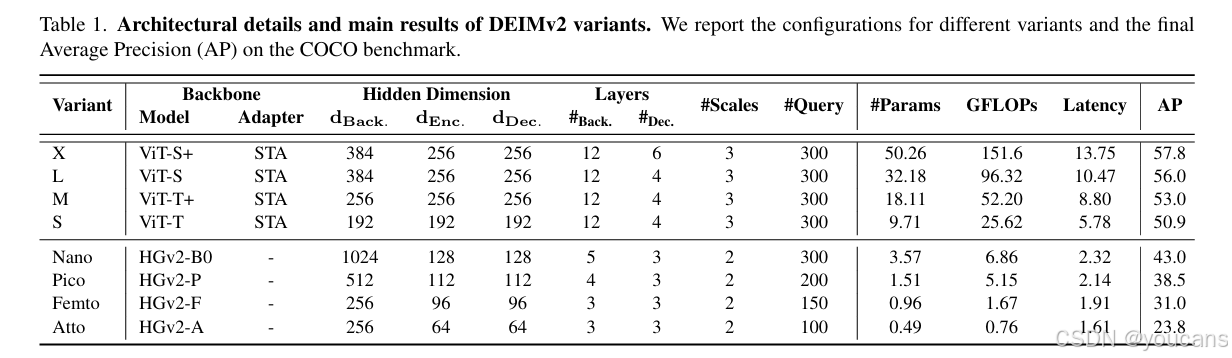
2.2 基于 ViT 的模型设计
针对 DEIMv2 的中大型型号(S、M、L、X),我们围绕视觉 Transformer(Vision Transformer, ViT)[3] 系列精心设计骨干网络,在模型容量与计算效率之间实现平衡。
- 对于 L 型和 X 型,我们采用两种公开的 DINOv3 模型 [21]——ViT-Small 和 ViT-Small+,这两种模型包含 12 层网络结构,隐藏层维度为 384,能够提供强大的语义特征表示。
- 对于更轻量化的 S 型和 M 型,我们直接从 ViT-Small DINOv3 中蒸馏出紧凑的骨干网络(ViT-Tiny 和 ViT-Tiny+):在保留 12 层网络深度的同时,将隐藏层维度分别降至 192 和 256。
这种设计为模型从 S→M→L→X 的尺度扩展提供了平滑路径,确保每个型号在适配不同效率需求的同时,仍能保持具有竞争力的检测精度。
2.3 基于 HGNetv2 的模型设计
HGNetv2 [1] 由百度飞桨团队研发,凭借其高效性被广泛应用于实时 DETR 框架(例如 D-FINE [17] 就采用了完整的 HGNetv2 系列作为骨干网络)。
在 DEIMv2 的超轻量级型号(Nano、Pico、Femto、Atto)中,我们同样以 HGNetv2-B0 为基础,但通过逐步剪枝其网络深度和宽度,以满足不同的参数预算要求。
具体剪枝策略如下:Pico 型号移除了 HGNetv2-B0 的第四阶段,仅保留分辨率降至 1/16 的特征输出;Femto 型号在 Pico 的基础上进一步优化,将最后一个阶段的网络块(block)数量从 2 个减至 1 个;Atto 型号则更进一步,将最后一个网络块的通道数从 512 压缩至 256。
2.4 2.4 空间调优适配器(STA)
为更好地将 DINOv3 特征适配于实时目标检测任务,我们提出了空间调优适配器(Spatial Tuning Adapter, STA),其结构如图 2 所示。STA 是一个全卷积网络,包含两个核心模块:一是用于提取细粒度多尺度细节特征的超轻量级前馈网络,二是用于进一步强化 DINOv3 特征表示的双向融合(Bi-Fusion)算子。
DINOv3 基于 ViT 骨干网络构建,天然输出单尺度(1/16 分辨率)的密集特征。然而在目标检测任务中,目标尺寸差异极大,多尺度特征是提升检测性能的关键手段之一。为此,ViTDet [10] 引入了 Feature2Pyramid 模块,通过反卷积从 ViT 的最终输出中生成多尺度特征。与之相比,本文提出的 STA 结构更为简洁:我们直接从 ViT 的多个网络块(如第 5 层、第 8 层、第 11 层)中提取 1/16 尺度特征,通过无参数的双线性插值(bilinear interpolation)将其转换为多尺度特征。随后,这些多尺度特征通过双向融合算子进一步增强 —— 该算子包含 1×1 卷积层和一个超轻量级 CNN,前者用于特征维度调整,后者用于提取细粒度细节特征,最终实现与 DINOv3 输出特征的互补融合。这种设计在效率与精度之间取得了优异平衡,非常适合实时检测场景。
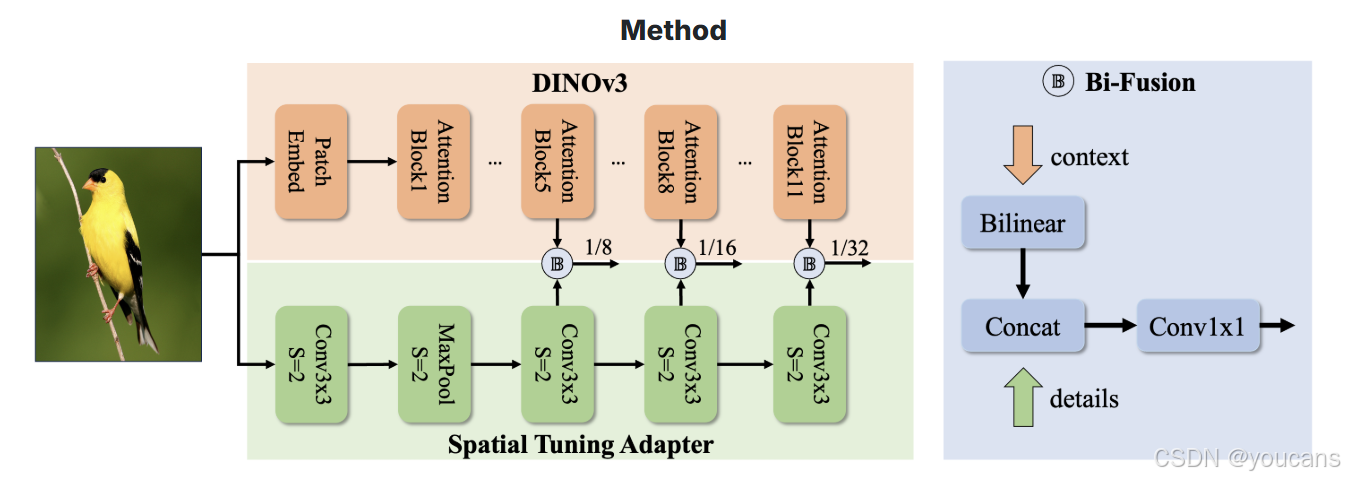
图2. 基于ViT的变体主干设计。我们将DINOv3与所提出的Spatial Tuning Adapter(STA)进行集成。
2.5 高效解码器
我们对标准可变形注意力解码器 [31] 进行改进,集成了 Transformer 领域中多种以效率为导向的技术,实现了更优的性能 - 成本权衡。
具体而言,我们引入 SwiGLUFFN [20] 以增强模型的非线性表示能力,同时采用 RMSNorm [27] 实现高效的训练稳定与加速。此外,我们观察到在迭代优化过程中,目标查询(object query)的位置变化极小,基于这一发现,我们提出在所有解码器层间共享单一的位置嵌入(position embedding),从而消除冗余计算,进一步提升效率。
2.6 增强型 Dense O2O
在我们此前提出的 DEIM [7] 框架中,Dense O2O 通过增加每张训练图像中的目标数量以提供更强的监督信号,从而加快模型收敛速度并提升检测性能。该机制的有效性最初通过图像级数据增强(如 Mosaic 和 MixUp [28])得以验证。
在 DEIMv2 中,我们进一步将 Dense O2O 扩展至目标级增强,提出 Copy-Blend 策略 —— 在不引入背景信息的前提下添加新目标。与 Copy-Paste [4](完全覆盖目标区域)不同,Copy-Blend 将新目标与原图进行融合,更适配实时检测的任务场景,能持续提升模型性能。
2.7 训练设置与损失函数
DEIMv2 的训练策略沿用 DEIM [7] 框架 —— 该框架专为实现快速收敛与高性能设计。模型的整体优化目标是五项损失的加权和,包括匹配感知损失(Matchability-Aware Loss, MAL)[7]、细粒度定位损失(Fine-Grained Localization Loss, FGL)[17]、解耦蒸馏焦点损失(Decoupled Distillation Focal Loss, DDF)[17]、边界框 L1 损失(BBox Loss, L1)以及 GIoU 损失 [19]。
总损失函数定义如下:
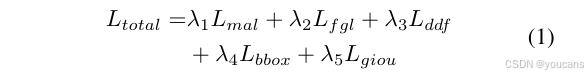
在所有实验中,各项损失的权重设置为:λ₁=1.0、λ₂=1.0、λ₃=1.5、λ₄=5、λ₅=2。
我们在表 2 中总结了 DEIMv2 的训练超参数,涵盖输入分辨率、学习率、训练轮次以及 Dense O2O 相关设置。实验中发现一个有趣现象:将 FGL 和 DDF 损失应用于超轻量级模型时,会导致性能下降。我们认为这一现象的原因在于,超轻量级模型容量有限且基准精度本身较低,使得自蒸馏机制的有效性大幅降低。因此,在训练 Pico、Femto 和 Atto 型号时,我们剔除了这两项损失(即局部损失)。
表2. DEIMv2 详细训练超参数。Back. 表示 Backbone。我们用 Local Loss 指代 D-FINE[17] 中的 Fine-Grained Localization (FGL) Loss 与 Decoupled Distillation Focal (DDF) Loss。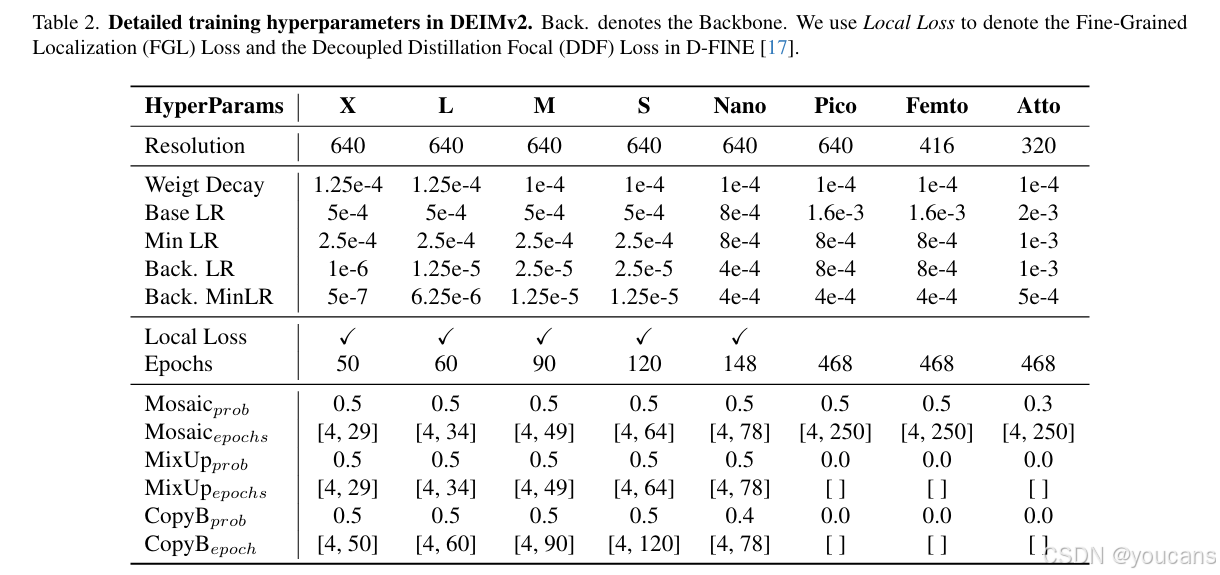
3. 实验
3.1 与当前最优实时目标检测器的对比
表 3 总结了 DEIMv2 在 S、M、L、X 四种型号下的性能表现,其相较于此前的当前最优(SOTA)检测器实现了显著提升。
例如,最大型号 DEIMv2-X 以约 5000 万参数和 151 GFLOPs(千兆次浮点运算)的计算量,实现了 57.8 的 COCO 平均精度(AP),超越了此前性能最佳的 DEIM-X—— 该模型需 6200 万参数和 202 GFLOPs,却仅能达到 56.5 AP。这一结果表明,DEIMv2 能够以更少的参数和更低的计算成本实现更优的检测精度。
在轻量级型号端,DEIMv2-S 创下了一项新里程碑:作为首个参数少于 1000 万的模型,它在 COCO 数据集上突破了 50 AP 的阈值,以仅 1100 万参数和 26 GFLOPs 的计算量实现了 50.9 AP。相较于此前的 DEIM-S(1000 万参数,49.0 AP),DEIMv2-S 在参数规模相近的情况下,检测精度有了明显提升。尽管基于 CNN 的骨干网络通常更适配硬件环境,但本文提出的基于 ViT 的骨干网络仍实现了轻量级设计,参数和计算量更少,具备更优的可扩展性和部署灵活性。值得注意的是,本文所提方法的延迟尚未经过优化;若采用 YOLOv12 [22] 中使用的 Flash Attention [2] 等技术,有望进一步加快推理速度。总体而言,计算量的降低凸显了基于 ViT 的骨干网络在经过合理优化后,实现低延迟性能的潜力。
有趣的是,在参数和计算量预算相近的条件下,将基于 DINOv3 的 DEIMv2 模型与其前代 DEIM 模型进行对比发现,DEIMv2 的精度提升主要来源于对中大型目标检测性能的改善,而对小型目标的检测性能则基本保持不变。
例如,DEIMv2-S 的中目标 AP(APₘ)达到 55.3、大目标 AP(APₗ)达到 70.3,显著超过 DEIM-S 的 52.6 APₘ和 65.7 APₗ,但两者的小目标 AP(APₛ)却几乎持平(31.4 vs. 30.4)。更大规模的模型也呈现出类似趋势:DEIMv2-X 的中目标 AP 从 DEIM-X 的 61.4 提升至 62.8,大目标 AP 从 74.2 提升至 75.9,但其小目标 AP(39.2)与 DEIM-M 的 38.8 仍十分接近。这些结果表明,DEIMv2 的核心优势在于增强对中大型目标的特征表示与检测能力,而小型目标检测仍是各尺度模型面临的共同挑战。
这一发现进一步证实,DINOv3 在捕捉强全局语义信息方面表现出色,但在表示细粒度细节(小型目标检测所需关键信息)方面能力有限。因此,探索如何更有效地将 DINOv3 特征融入实时检测器,成为未来研究的一个重要方向。
表3. 在 COCO [12] val2017 上与实时目标检测器的对比,按参数量排序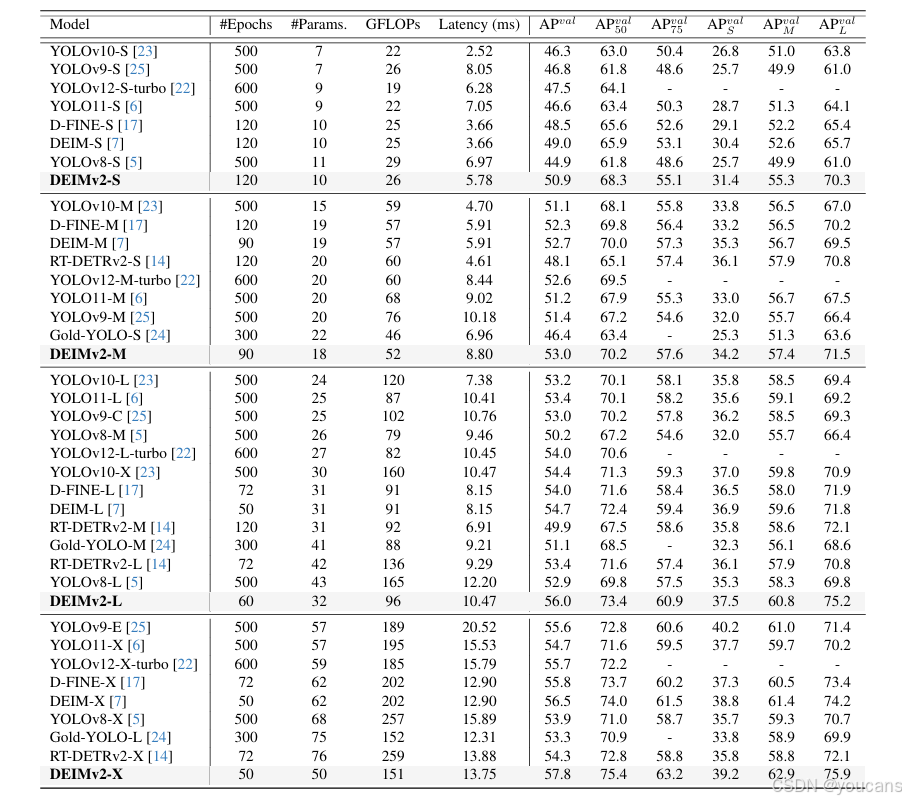
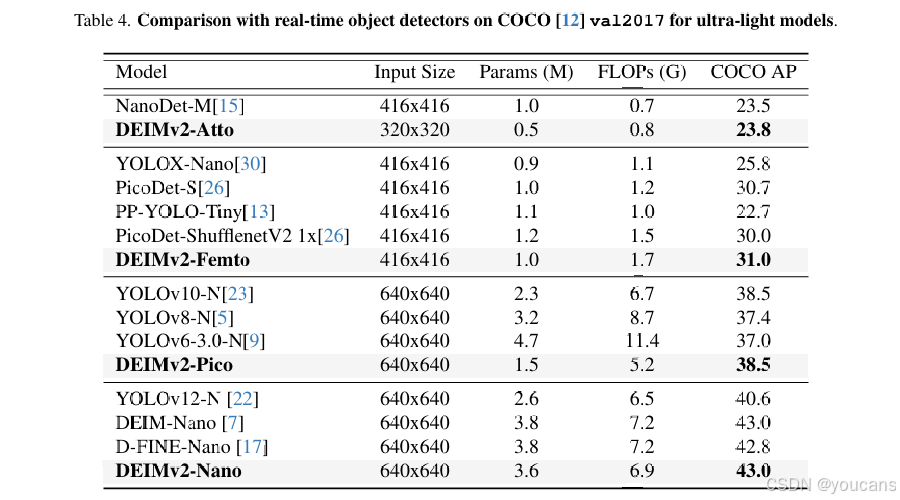
3.2 与主流超轻量级目标检测器的对比
DEIMv2 的超轻量级型号同样展现出强劲性能,具体数据总结于表 4。其中,DEIMv2-Atto 仅用 0.49M(百万)参数,就实现了与 NanoDet-M 相近的性能,且模型规模远小于后者。类似地,DEIMv2-Pico 的性能与 YOLOv10-N [23] 相当,但所需参数不足后者的一半。这些结果充分证明了 DEIMv2 在极紧凑模型规模下的有效性,同时也凸显了其在资源受限边缘设备上部署的适用性。
表4. 超轻量模型在 COCO [12] val2017 上与实时目标检测器的对比
4. 结论
在本研究中,我们提出了 DEIMv2—— 新一代实时目标检测器,它融合了 DINOv3 的强语义表示能力与轻量级空间调优适配器(STA)。
通过精心的设计与尺度扩展,DEIMv2 在全尺寸模型范围内均实现了当前最优(SOTA)性能。在高性能端,DEIMv2-X 以远少于以往大型检测器的参数,实现了 57.8 的 COCO 平均精度(AP);在轻量级端,DEIMv2-S 是同规模模型中首个突破 50 AP 的检测器;而超轻量级型号 DEIMv2-Pico 在匹配 YOLOv10-N 性能的同时,参数用量减少了 50% 以上。
这些结果共同表明,DEIMv2 不仅具备高效性,还拥有出色的可扩展性,其构建的统一框架推动了目标检测领域精度与效率权衡的边界。这种多场景适配能力使 DEIMv2 能够灵活部署于从资源受限的边缘设备到高性能检测系统的各类场景,为实时检测技术在实际应用中的更广泛落地奠定了基础。
5. 项目使用
项目地址: https://github.com/Intellindust-AI-Lab/DEIMv2
DEIMv2 是 DEIM 框架的演进版本,同时利用 DINOv3 的丰富特征。我们的方法设计了多种模型尺寸,从超轻量版本至 S、M、L 和 X,以适应广泛的场景需求。在这些变体中,DEIMv2 实现了最先进的性能,其中 S 尺寸模型在具有挑战性的 COCO 基准上显著突破 50 AP。
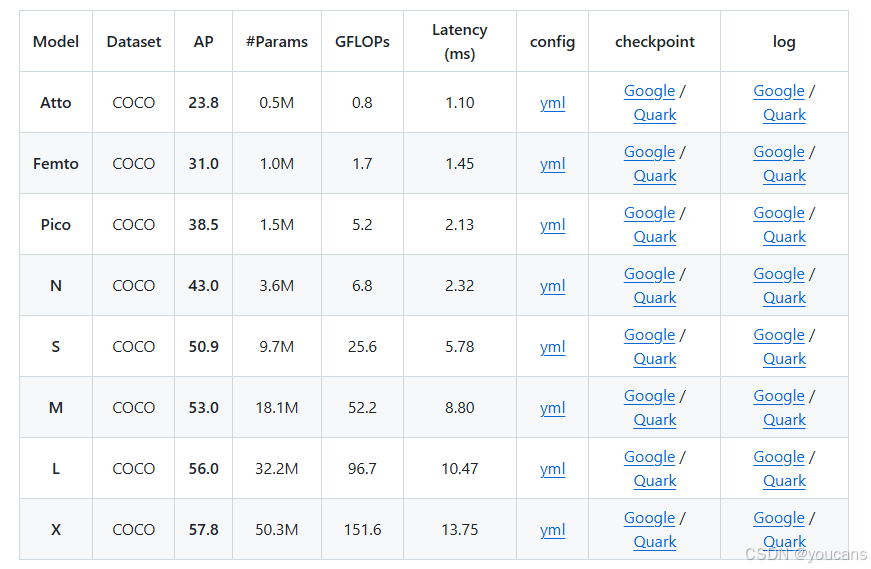
5.1 Model Zoo
5.2 快速开始
- 项目配置
conda create -n deimv2 python=3.11 -y
conda activate deimv2
pip install -r requirements.txt
- 数据准备:COCO2017 数据集
(1)从 OpenDataLab 或 COCO 下载 COCO2017。
(2)在 coco_detection.yml 中修改路径。
train_dataloader:
img_folder: /data/COCO2017/train2017/
ann_file: /data/COCO2017/annotations/instances_train2017.json
val_dataloader:
img_folder: /data/COCO2017/val2017/
ann_file: /data/COCO2017/annotations/instances_val2017.json
- 数据准备:自定义数据集
若要在自定义数据集上训练,需将其整理为 COCO 格式。请依照以下步骤准备数据集:
(1)将 remap_mscoco_category 设为 False:
该设置可防止类别 ID 被自动重映射以匹配 MSCOCO 类别。
remap_mscoco_category: False
(2)整理图像:
按照如下结构组织数据集目录:
dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
└── annotations/
├── instances_train.json
├── instances_val.json
└── ...
其中,images/train/:存放所有训练图像。images/val/:存放所有验证图像。annotations/:存放 COCO 格式的标注文件。
(3)将标注转换为COCO格式:
如果您的标注尚未采用COCO格式,需进行转换。可参考以下Python脚本,或使用已有工具:
import json
def convert_to_coco(input_annotations, output_annotations):
# Implement conversion logic here
pass
if __name__ == "__main__":
convert_to_coco('path/to/your_annotations.json', 'dataset/annotations/instances_train.json')
(4)更新配置文件:
修改 custom_detection.yml。
task: detection
evaluator:
type: CocoEvaluator
iou_types: ['bbox', ]
num_classes: 777 # your dataset classes
remap_mscoco_category: False
train_dataloader:
type: DataLoader
dataset:
type: CocoDetection
img_folder: /data/yourdataset/train
ann_file: /data/yourdataset/train/train.json
return_masks: False
transforms:
type: Compose
ops: ~
shuffle: True
num_workers: 4
drop_last: True
collate_fn:
type: BatchImageCollateFunction
val_dataloader:
type: DataLoader
dataset:
type: CocoDetection
img_folder: /data/yourdataset/val
ann_file: /data/yourdataset/val/ann.json
return_masks: False
transforms:
type: Compose
ops: ~
shuffle: False
num_workers: 4
drop_last: False
collate_fn:
type: BatchImageCollateFunction
- 骨干网络检查点(Backbone Checkpoints)
对于 DINOv3 S 与 S+,请依据 https://github.com/facebookresearch/dinov3 中的指引下载。
对于我们所蒸馏的 ViT-Tiny 与 ViT-Tiny+,可从 ViT-Tiny 与 ViT-Tiny+ 处下载。
随后将其置于 ./ckpts 目录,结构如下:
ckpts/
├── dinov3_vits16.pth
├── vitt_distill.pt
├── vittplus_distill.pt
└── ...
5.3 使用方法
- 训练
# for ViT-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --use-amp --seed=0
# for HGNetv2-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --use-amp --seed=0
- 测试
# for ViT-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --test-only -r model.pth
# for HGNetv2-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --test-only -r model.pth
- 微调
# for ViT-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --use-amp --seed=0 -t model.pth
# for HGNetv2-based variants
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --use-amp --seed=0 -t model.pth
6. 参考文献
[1] ChengCui,RuoyuGuo,YuningDu,DongliangHe,FuLi,ZewuWu,QiwenLiu,ShileiWen,JizhouHuang,XiaoguangHu, etal. Beyondself-supervision:Asimpleyeteffectivenetworkdistillationalternativetoimprovebackbones.arXiv,2021.3
[2] TriDao,DanFu,StefanoErmon,AtriRudra,andChristopherR´e. Flashattention: Fast andmemory-efficient exactattentionwithio-awareness. InNeurIPS,2022.5
[3] AlexeyDosovitskiy, LucasBeyer, AlexanderKolesnikov,DirkWeissenborn, Xiaohua Zhai, Thomas Unterthiner,MostafaDehghani,MatthiasMinderer,GeorgHeigold,SylvainGelly, etal. Animageisworth16x16words: Transformersforimagerecognitionatscale. InICLR,2020.3
[4] GolnazGhiasi,YinCui,AravindSrinivas,RuiQian,TsungYiLin,EkinDCubuk,QuocVLe,andBarretZoph.Simplecopy-pasteisastrongdataaugmentationmethodforinstancesegmentation. InCVPR,2021.4
[5] JocherGlenn.Yolov8.https://docs.ultralytics.com/models/yolov8/,2023.5,6
[6] JocherGlenn.Yolo11.https://docs.ultralytics.com/models/yolo11/,2024.1,5
[7] Shihua Huang, Zhichao Lu, Xiaodong Cun, Yongjun Yu,Xiao Zhou, and Xi Shen. Deim: Detr with improved matching for fast convergence. In CVPR, 2025. 2, 4, 5, 6
[8] Muhammad Hussain. Yolo-v1 to yolo-v8, the rise of yoloand its complementary nature toward digital manufacturingand industrial defect detection. 2023. 1
[9] Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, MengCheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, and Xiangxiang Chu. Yolov6 v3.0: A full-scale reloading. arXiv, 2023.6
[10] Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He.Exploring plain vision transformer backbones for object detection. In ECCV, 2022. 3
[11] Siyuan Liang, Hao Wu, Li Zhen, Qiaozhi Hua, Sahil Garg,Georges Kaddoum, MohammadMehediHassan,andKepingYu. Edge yolo: Real-time intelligent object detection system based on edge-cloud cooperation in autonomous vehicles. IEEE Transactions on Intelligent Transportation Systems, 2022. 1
[12] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C LawrenceZitnick. Microsoft coco: Common objects in context. InECCV, 2014. 1, 2, 5, 6
[13] XiangLong, Kaipeng Deng, GuanzhongWang, YangZhang,Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, ShuminHan, Errui Ding, and Shilei Wen. Pp-yolo: An effective andefficient implementation of object detector. arXiv, 2020. 6
[14] Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang,Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer.arXiv, 2024. 3, 5
[15] Rangi Lyu. Nanodet-plus. https://github.com/RangiLyu/nanodet/releases/tag/v1.0.0alpha-1, 2021. Version 1.0.0-alpha-1. 6
[16] Debapriya Maji, Soyeb Nagori, Manu Mathew, and DeepakPoddar. Yolo-6d-pose: Enhancing yolo for single-stagemonocular multi-object 6d pose estimation. In 3DV, 2024.1
[17] Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, XiaoyanSun, and Feng Wu. D-fine: Redefine regression task in detrsas fine-grained distribution refinement. In ICLR, 2024. 3, 4,5, 6
[18] Joseph Redmon, Santosh Divvala, Ross Girshick, and AliFarhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 1
[19] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, AmirSadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding boxregression. In CVPR, 2019. 4
[20] Noam Shazeer. Glu variants improve transformer. arXivpreprint arXiv:2002.05202, 2020. 2, 4
[21] Oriane Sim´eoni, Huy V Vo, Maximilian Seitzer, FedericoBaldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov,Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa,et al. Dinov3. arXiv, 2025. 2, 3
[22] Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12:Attention-centric real-time object detectors. In NeurIPS,2025. 1, 5, 6
[23] Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yolov10: Real-time end-toend object detection. In NeurIPS, 2024. 5, 6
[24] Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo,Chuanjian Liu, Yunhe Wang, and Kai Han. Gold-yolo: Efficient object detector via gather-and-distribute mechanism.In NeurIPS, 2023. 5
[25] Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao.Yolov9: Learning what you want to learn using programmable gradient information. arXiv, 2024. 5
[26] Guanghua Yu, Qinyao Chang, Wenyu Lv, Chang Xu, ChengCui, Wei Ji, Qingqing Dang, Kaipeng Deng, GuanzhongWang, Yuning Du, et al. Pp-picodet: A better real-time object detector on mobile devices. arXiv, 2021. 6
[27] Biao Zhang and Rico Sennrich. Root mean square layer normalization. In NeurIPS, 2019. 2, 4
[28] Hongyi Zhang. mixup: Beyond empirical risk minimization.In ICLR, 2017. 4
[29] Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei,Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen.Detrs beat yolos on real-time object detection. In CVPR,2024. 1
[30] Ge Zheng, Liu Songtao, Wang Feng, Li Zeming, and SunJian. Yolox: Exceeding yolo series in 2021. arXiv, 2021. 6
[31] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang,and Jifeng Dai. Deformable detr: Deformable transformersfor end-to-end object detection. In ICLR, 2021.
引用说明: Huang, S., Hou, Y., Liu, L., Yu, X., & Shen, X. (2025). Real-Time Object Detection Meets DINOv3. arXiv. [Online]. Available: https://arxiv.org/pdf/2509.20787
版权说明:
youcans@xidian 作品,转载必须标注原文链接:
【youcans论文精读】基于 DINOv3 的实时目标检测 (https://youcans.blog.csdn.net/article/details/153975745)
Crated:2025-10

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)