VLA 论文精读(三十六)VLA-0: Building State-of-the-Art VLAs with Zero Modification
这篇论文是 Nvidia 发表的一篇 VLA 领域的论文,提出了一个名为 VLA-0 架构,该架构采用了一种极其简单但被忽视的策略:将动作直接表示为文本 。它不需要对底层的 VLM 进行任何修改,将机器人的连续动作转换为数值字符串,然后像生成普通文本一样,训练 VLM 直接输出这些动作字符串。但想要实现这一效果还需要 Masked Action Augmentation、Ensemble Prediction 等关键组件。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:VLA-0: Building State-of-the-Art VLAs with Zero Modification
- 原文链接: https://arxiv.org/abs/2510.13054
- 发表时间:2025年10月15日
- 发表平台:arxiv
- 预印版本号:[v1] Wed, 15 Oct 2025 00:31:10 UTC (502 KB)
- 作者团队:Ankit Goyal, Hugo Hadfield, Xuning Yang, Valts Blukis, Fabio Ramos
- 院校机构:
- Nvidia
- 项目链接: https://vla0.github.io/
- GitHub仓库: https://github.com/NVlabs/vla0
Abstract
视觉-语言-动作模型 (VLA) 在实现通用机器人操控方面前景广阔。然而,构建它们的最佳方法仍是一个悬而未决的问题。目前的方法通常会增加复杂性,例如用动作 tokens 修改视觉-语言模型 (VLM) 的现有词表,或引入特殊的动作头。奇怪的是,将动作直接表示为文本这种最简单的策略在很大程度上仍未被探索。本研究引入了 VLA-0 来探究这一想法。作者发现 VLA-0 不仅有效且功能强大。如果设计得当,VLA-0 的表现甚至优于更复杂的模型。在 LIBERO(一种流行的 VLA 评估基准)上,VLA-0 的表现优于所有基于相同机器人数据训练的现有方法,包括 π 0.5 \pi_{0.5} π0.5-KI、OpenVLA-OFT 和 SmolVLA。此外,无需进行大规模机器人专用训练,它的表现就优于在大规模机器人数据上训练的方法,例如 p i 0.5 pi_{0.5} pi0.5-KI、 π 0 \pi_{0} π0、GR00T N1 和 MolmoAct。这些发现也适用于现实世界,VLA-0 的表现优于 SmolVLA(一个在大规模真实数据上预训练的 VLA 模型)。本文总结了作者意想不到的发现,并阐述了解锁这种简单而强大的 VLA 设计高性能所需的具体技术。可视化结果、代码和训练好的模型可在 https://vla0.github.io/ 上找到。

1. Introduction
继大型语言模型 (LLM) 在文本处理和视觉语言模型 (VLM) 在处理视觉和文本输入方面的成功之后,下一步自然是探索视觉-语言-动作模型 (VLA),即不仅能理解视觉和文本信息,还能预测机器人动作的系统。VLA 通常是通过修改基础 VLM 来预测动作而构建的。然而,目前尚不清楚什么是 “correct” 的方法来做到这一点,如果有的话。最近的研究采用了各种方法,作者大致将其分为三类,如 Fig.2 所示:(1) Discrete Token VLAs,(2) Generative Action Head VLAs,以及 (3) Custom Architecture VLA。
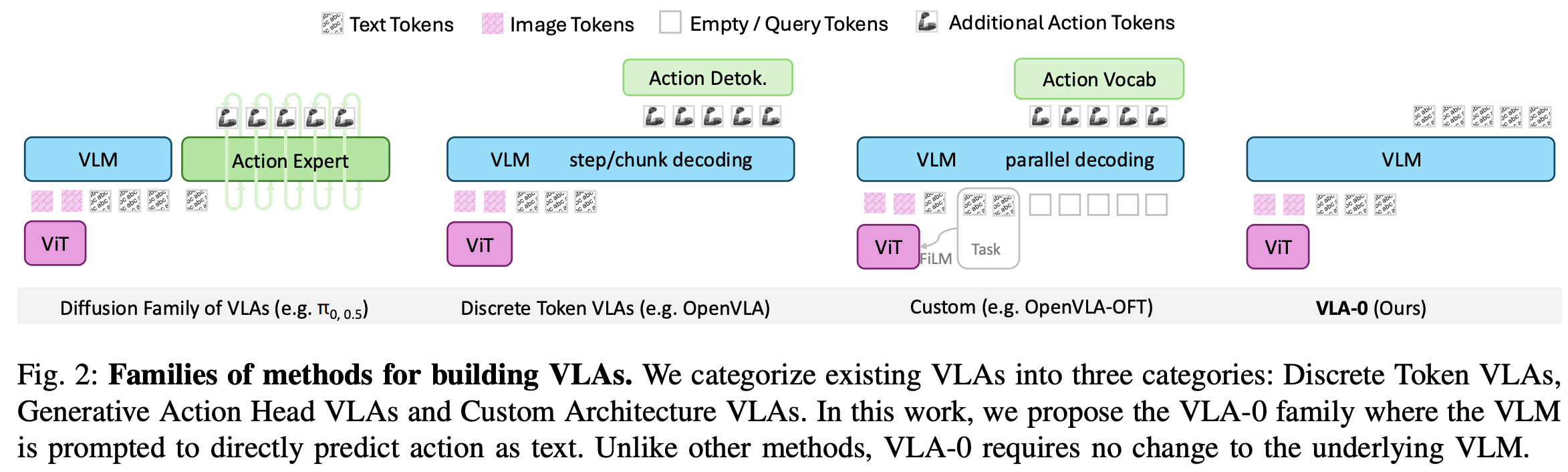
Discrete Token VLAs
这是 RT-2 和 OpenVLA 等模型推广的初始策略之一。机器人动作原本是连续的,被离散化到不同的 bin 中;然后,每个 bin 从 VLM 词表中分配一个 token,使用全新定义或不常用的 token;然后,用与训练基础 VLM 相同的交叉熵损失来训练模型预测这些动作 tokens。虽然这种方法很简单,但它有两个主要局限性:
- 它限制了动作空间的分辨率:因为细粒度控制可能需要数千个 bin,这与共享文本词域相冲突;
- 它通过重新利用 VLM 的词表来适应动作:损害了 VLM 预训练的语言理解能力。
鉴于这些局限性,需要使用其他方法或自定义训练流程。
尽管这些方法取得了成功,但仍需思考是否存在更简单的替代方案。一种无需更改 VLM 词表或引入任何新架构组件的方案。当前是否已经排除了将动作预测为文本的可能性?为什么不将动作(例如坐标、关节角度)表示为数字字符串,并使用 VLM 原生的文本生成功能生成它们呢?这种方法无需添加新的 token、无需修改词表、也无需更改架构。它能够保持 VLM 的完整性,同时在动作空间中提供任意分辨率。鉴于人们为优化各种 VLA 设计的训练方案付出了巨大的努力,有人可能会问:如果专注于最简单的架构会怎样?
为了使此设计达到最佳性能,需要精心设计训练和测试方案。例如,作者发现在训练过程中,对动作文本进行随机 mask 可以提高性能。同样,在测试过程中,集成先前的预测也很有帮助。总而言之,本文的贡献如下:
- 证明了简单的 VLA 设计无需改变 VLM 架构即可实现与流行替代方案类似的 SOTA 结果;
- 设计了训练和测试方案,通过简单的 VLA 设计实现 SOTA 性能;
2. Related Work
工作建立在视觉语言动作模型和更广泛的机器人学习领域的最新进展的基础上。
Vision-Language-Action Models
近期,将预训练的视觉语言模型 (VLM) 用于机器人控制的范式获得了显著的关注。一种主流方法是将连续动作表示为离散的 token。RT-2 和 OpenVLA 等颇具影响力的模型采用了这种策略,将动作空间离散化为有限数量的 bin,并将每个 bin 映射到 VLM 词表中的 token。虽然这种方法可以直接将动作生成集成到语言建模目标中,但它 会在动作解析度和词量之间引入权衡,并且可能会破坏重新利用的 token 的语义。
另一类著名的方法通过引入辅助动作头来避免改变 VLM 的词汇。 π 0 \pi_{0} π0 和 SmolVLA 等模型对 VLM 进行微调使其输出潜在 embedding,然后由单独的生成模型,例如 Diffusion Policy 或 Flow Matching,将其解码为连续动作。虽然这保留了 VLM 的原始词汇并允许执行高保真动作,但它增加了模型的复杂性,有时会导致 VLM 的语言基础能力下降。
第三类涉及更实质性的架构修改,例如 OpenVLA-OFT 中的专门动作头或 π \pi π-FAST 中通过离散余弦变换进行的自定义动作标记化,这些通常需要复杂的训练流程。
作者提出的方法 VLA-0 探索了一种概念上更简单的替代方案:将动作直接表示为文本。通过将数值动作(例如,末端执行器坐标)表示为字符串,无需任何架构修改即可利用 VLM 的原生文本生成功能。与本文方法最接近的方法是 LLARVA,它学习将动作预测为文本。然而,LLARVA 采用两阶段流程,首先生成二维轨迹规划,然后再预测最终动作。相比之下,作者的工作表明,直接的端到端动作字符串生成可以实现最佳性能,此处的关键在于精心设计的训练和推理方案,包括动作 token mask 和预测集成,这是 LLARVA 中尚未探索的关键组件。
另一项与之接近的研究是 HAMSTER,它提出了一个分层的 VLA。HAMSTER 的第一阶段使用 VLM 预测文本中的二维动作轨迹。作者的设计与之类似,但将完整的机器人动作(例如关节姿势或末端执行器增量)预测为文本。
Robot Learning Policies
从演示中学习机器人策略是一个成熟的领域,其历史早于近年来 VLA 的兴起。与 VLA 不同,这些方法通常基于领域内数据从头开始训练策略,而无需利用已老化的大型预训练视觉和语言模型。一个典型的例子是 Diffusion Policy,它使用条件扩散过程对动作空间进行建模,并在各种操作任务中表现出色。
另一项研究重点是通过将显式 3D 表示纳入策略架构来提高样本效率和空间推理能力。RVT、RVT-2、ManiFlow 和 Act3D 等模型利用 3D 场景信息来学习更鲁棒、更泛化的策略。
与这些方法相比,VLA-0 与 VLA 范式保持一致,直接构建于 VLM 强大的预训练表示之上。本文的研究结果表明,通过合理利用 VLM,简单方法在仅使用领域内动作数据的基准任务上的表现可以超越扩散策略等专门方法。
3. Method
A. Background
Vision-Language Models
视觉语言模型 (VLM) 是一类神经网络,旨在处理和推理来自视觉和文本模态的信息。通常,它们由一个预训练的视觉编码器(例如,Vision Transformer)和一个处理文本信息的大型语言模型 (LLM) 组成。视觉特征被投影到 LLM 的嵌入空间中,使模型能够同时对图像和文本提示进行条件反射,从而生成连贯的文本输出。
在本研究中,基于一个公开可用的、SOTA 的 VLM 构建系统。具体来说,采用了拥有 3B 参数的 Qwen-VL-2.5 模型,但也适用于任何其他 VLM。选择 Qwen-VL-2.5-3B 有几个原因。就其模型规模而言,Qwen-VL-2.5-3B 展现出了极具竞争力的性能。作为一个相对较小的 VLM,它计算效率高,有助于加快训练和推理速度。此外,其开放权重的特性也提升了可访问性和可重复性。
Method: VLA-0
作者推出 VLA-0,一种用于构建视觉语言-动作模型的简单设计。与其他方案不同,VLA-0 保留了底层 VLM 的完整性:它不会引入新的 token、更改现有词表或添加任何新的神经网络层。尽管 VLA-0 很简单,并且与先前文献的预期相反,但它的性能与更复杂的方案一样出色。然而,实现这一性能依赖于一个精心设计的方案。该方案的三个关键组成部分是 action decoding 动作解码、ensemble prediction 集成预测 和 masked action augmentation 掩码动作增强。
Input
VLA-0 继承了底层 VLM 的输入结构,该结构由 System Prompt 系统提示、Images 图像和 Task Instruction 任务指令组成。系统提示指定了 VLM 的高级目标。在微调过程中,使用以下提示,其中 H、D 和 B 是根据数据选择的。
System Prompt
Analyze the input image and predict robot actions for the next H timesteps. Each action has D dimensions. Output a single sequence of H ×D integers (0 - B each), epresenting the H timesteps sequentially. Provide only space-separated numbers. Nothing else.
与底层 VLM 类似,VLA-0 可以将一张或多张图像作为输入。在仿真实验中,使用第三人称和腕部摄像头图像作为输入;在真机实验中,使用左右摄像头图像,如 Fig.3 所示。

作者还尝试了另一种图像输入设计,即不再将图像作为单独的实体提供,而是将它们拼贴成一张合成图像。在实验中发现这两种设计表现出相似的性能 Table.2。最后,输入包含任务指令,例如:“put the banana on the plate.”。
Action Decoding
VLA-0 将动作输出为文本。为了简化此任务,要求 VLM 将动作输出为整数。具体来说,首先将原始的连续动作值归一化到一个固定的整数范围(例如 [0,1000]);然后,VLM 负责为每个动作维度生成一个整数。该范围的最大值可以根据数据集和所需的动作分辨率进行调整。值得注意的是,与基于离散 tokens 的 VLA 不同,这种方法允许任意解析,而无需改变模型的词表。
Ensemble Prediction
VLA-0 采用了 Action-Chunking Transformer (ACT) 引入的预测集成技术,该技术也被其他最先进的 VLA(例如 OpenVLA-OFT)所采用。在每个推理步骤中,VLM 都会预测一系列包含 n n n 个未来动作的序列。对于当前时间步 t t t,该动作有 n n n 个可用的预测:一个是在当前步骤 t t t 做出的预测,另一个是在步骤 t − 1 t-1 t−1 做出的预测(作为其预测序列中的第二个动作),依此类推,直到步骤 t − n + 1 t-n+1 t−n+1 做出的预测。在作者的设计中,会对这 n n n 个预测取平均值,以生成时间步 t t t 的最终、更稳定的动作。
Masked Action Augmentation
方案的另一个组成部分是引入的训练增强技术,称之为“Masked Action Augmentation”。VLM 以自回归的方式生成文本,这意味着每个生成的 token 都以之前生成的 token 为条件。在训练过程中,会随机屏蔽目标动作字符串中的字符。这个过程迫使 VLM 根据视觉观察和指令来推理动作,而不是仅仅依赖于自动完成它已经开始生成的数字序列。
Training Details
通过对基础 VLM 进行全面微调来训练 VLA-0。该模型使用词表上的标准交叉熵损失来训练,以生成目标动作字符串。们使用 Adam 优化器,以 192 的 batch_size 和 5e-6 的 learning_rate 训练模型 64 个 epoch。在 8 块 A100 GPU 上训练大约需要 32 小时。
4. Experiments
A. Steup
在真实世界和仿真环境中评估模型。
Real-World
在真实世界评估中,使用 SO-100 机器人和 LeRobot 框架。针对四项不同的操作任务训练和测试策略:调整积木方向、推动苹果、拾取和放置香蕉以及拾取和放置纸杯蛋糕。对于每项任务,收集 100 个演示进行训练。然后,在不同的物体初始条件下评估学习到的策略,以测试其稳健性。
Simulation
使用 LIBERO 基准,这是一个广泛用于比较 VLA 模型的基准。LIBERO 包含四个套件:Spatial、Object、Goal 和 Long。每个套件旨在评估系统在特定维度上的能力。每个套件包含 10 个任务,每个任务在 50 个回合中测试。性能报告为每个套件的成功率和总体平均值。
B. Baselines
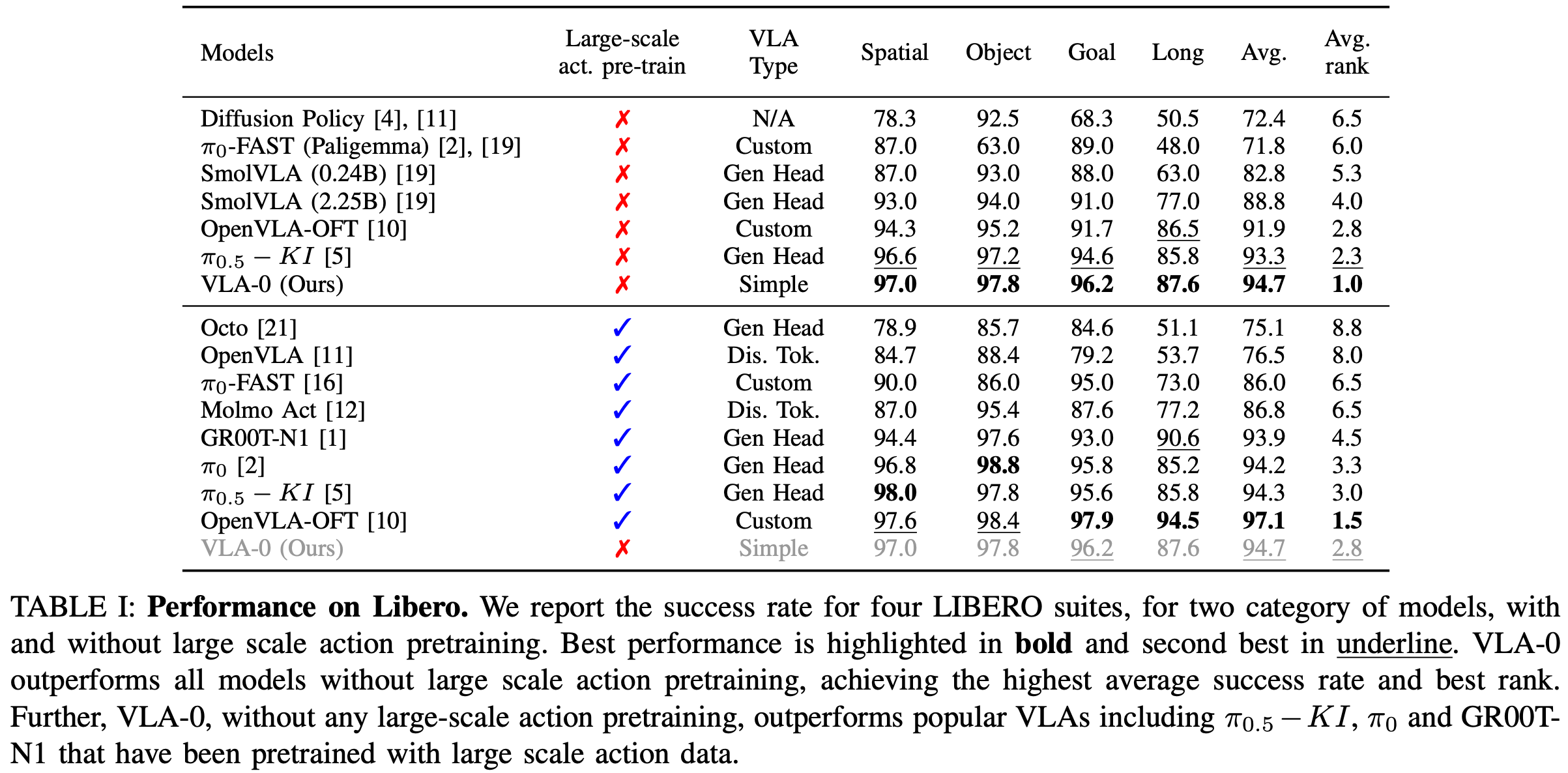
将 VLA-0 与几个基线模型进行了比较,包括扩散策略和各种最先进的视觉语言动作 (VLA) 模型。基线模型来自之前概述的三个类别 Fig.2:基于离散 tokens 的系列模型包括 OpenVLA 和 MolmoAct;基于动作的生成系列模型包括 Octo、 π 0 \pi_{0} π0、GR00T-N1、 π 0.5 \pi_{0.5} π0.5-KI 和 SmolVLA;自定义架构系列模型包括 π 0 \pi_{0} π0-FAST 和 OpenVLA-OFT。 π 0.5 \pi_{0.5} π0.5-KI 指的是 Dries 等人在 π 0.5 \pi_{0.5} π0.5 基础上进行的研究,以展示 VLA 中知识隔离的有效性。这些 VLA 模型的一个关键区别是它们使用了大规模动作预训练。为了确保公平比较,主要分析的是像 VLA-0 这样未经预训练的模型。然而,为了完整性,也在 Table.1中报告了预训练模型的性能。
C. Simulation Results
Table.1 总结了各种基线模型和 VLA-0 在 LIBERO 上的性能。发现 VLA-0 的性能优于所有现有的 VLA 模型,这些模型与作者的方法一样,没有使用大规模机器人数据进行预训练。这些模型包括 π 0.5 \pi_{0.5} π0.5-KI、OpenVLA-OFT、 π 0 \pi_{0} π0-Fast 和 SmolVLA。VLA-0 在所有 LIBERO 套件上的性能均优于这些基线模型,平均比第二好的方法高出 1.4 个百分点。这一结果非常令人惊讶,与现有文献的预期背道而驰。它表明,在不对底层 VLM 进行任何更改的情况下,可以构建出性能卓越的 VLA 模型。
更令人惊讶的是,VLA-0 与那些在大规模机器人数据上进行预训练的模型相比,其表现如何。尽管没有进行大规模动作预训练,VLA-0 的表现却超越了许多知名的预训练模型,包括 π 0.5 \pi_{0.5} π0.5-KI、π0、π0-FAST、Octo、OpenVLA、GROOT N1.5 和 MolmoAct。总体而言,它获得了第二好的平均排名 2.8,仅次于定制的 VLA 模型 OpenVLA-OFT(平均排名 1.5)。这表明,提出的简单策略能够有效地对抗使用大规模训练数据进行预训练的最佳模型。
D. Real-World Evaluation
为了在物理硬件上验证方法,使用 LeRobot 框架在现实世界中评估了 VLA-0。将其与 SmolVLA 进行了比较。SmolVLA 是一个强大的基线,专门在大规模 SO-100 数据集上训练,并已被证明在该平台上优于 π 0 \pi_{0} π0 和 ACT 等流行方法。
为了进行推理,使用配备 5090 GPU 的台式机。系统会为每个时间步长流式传输操作,从而实现 4 Hz 的推理速度。此性能是使用标准 PyTorch 实现实现的。作者认为,通过模型蒸馏或量化等技术可以显著提升这一速度,这留待后续研究。为了简单起见不会实际集成操作,但需要同时运行 8 个模型实例。
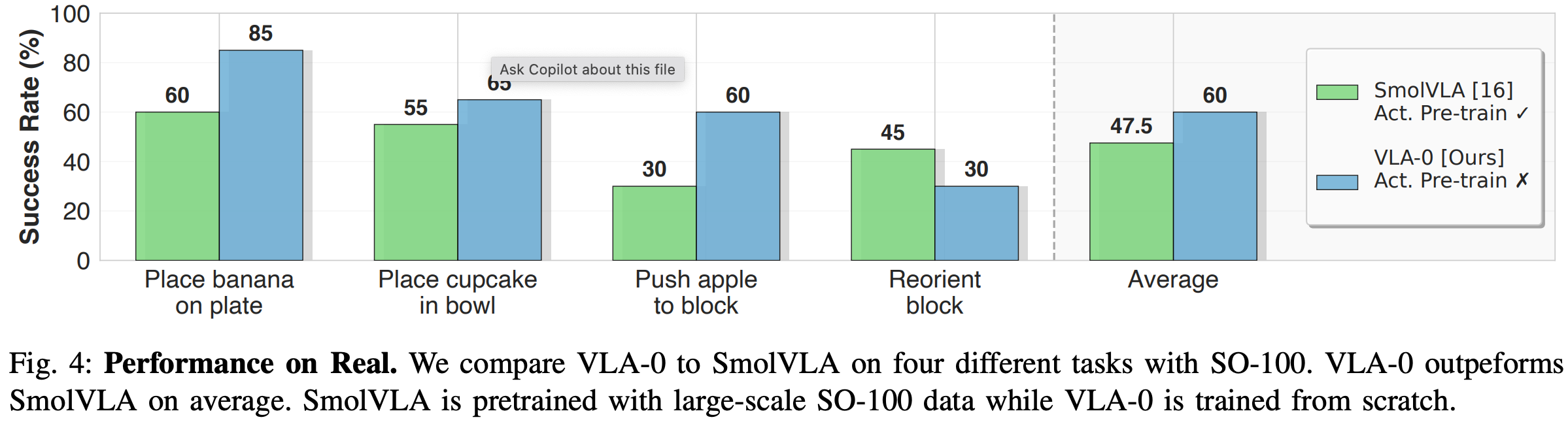
Fig.4 总结了四项实际任务的成功率。结果表明,尽管 VLA-0 未在大规模 SO100 数据集上进行预训练,但它的表现仍比 SmolVLA 高出 12.5 个百分点。这表明我们的方法的有效性已从模拟转化为现实。
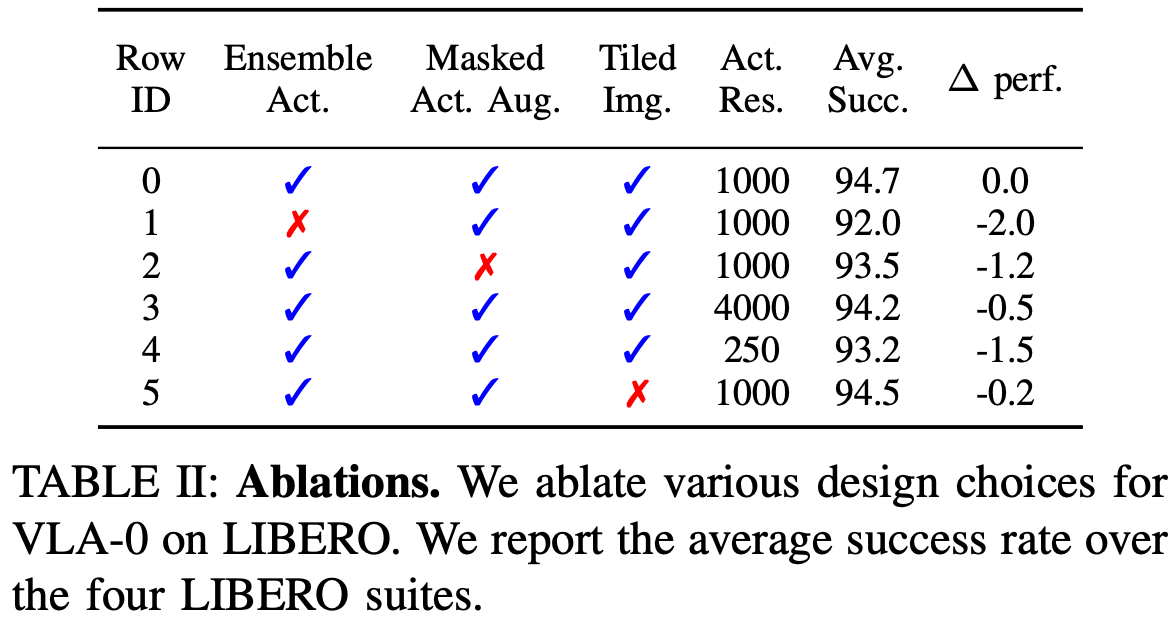
E. Ablations
作者对 LIBERO 基准进行了一系列消融研究,以分析 VLA-0 中关键设计组件的影响。Table.2 总结了这些结果。
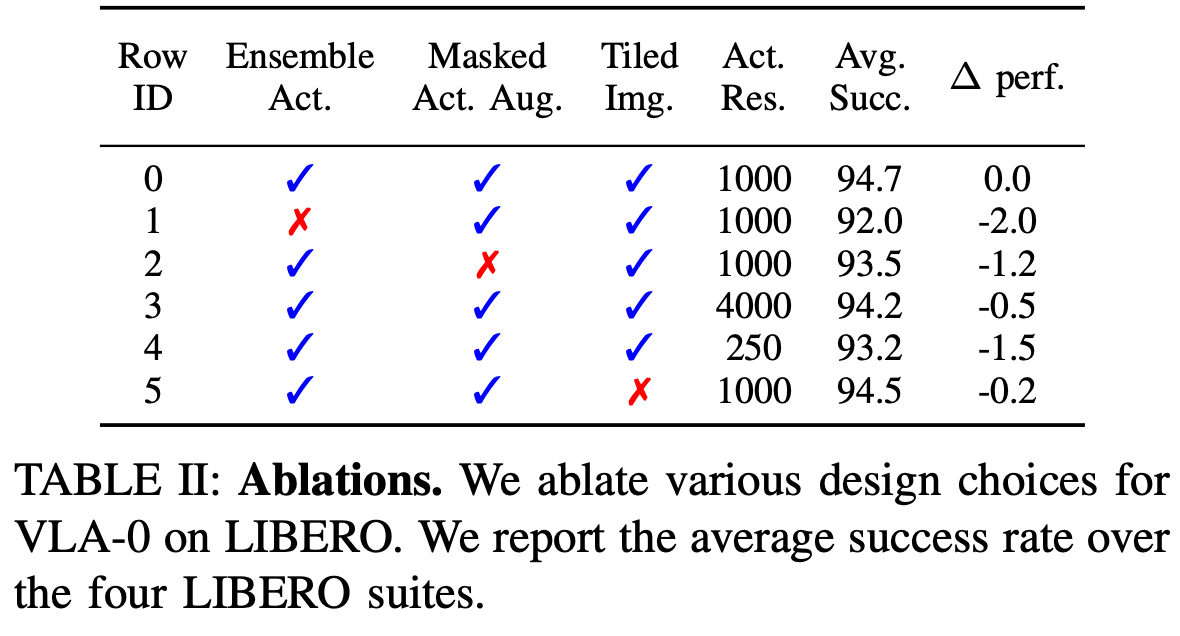
- Action Ensembling:禁用动作集成(比较第 0 行和第 1 行)揭示了其显著的影响。这项技术是一个关键组成部分,将整体成功率提高了 2 个百分点;
- Masked Action Augmentation:提出的 mask 动作增强方案提供了适度但持续的益处。移除此增强(比较第 0 行和第 2 行)会使成功率降低 1.2 个百分点;
- Action Resolution:动作分辨率的选择是一个重要的超参数。对于 LIBERO 基准测试,发现分辨率 1000 就足够了。将分辨率降低到 250 会降低性能,成功率会降低 1.5 个百分点,而分辨率提高到 4000 则不会带来额外的性能提升;
- Image Tiling:当向 VLM 提供多幅图像观测值时,可以将它们拼贴成一张合成图像,也可以将它们作为单独的输入。发现,这种做法对性能没有明显的影响;
5. Conclusions and Limitations
本研究提出了一种简单的 VLA 设计方案,该方案在不改变 VLM 的 tokenization 或引入新的架构组件的情况下,保留了基础 VLM 的完整性。作者证明了,只要方法得当,这种方法的表现优于更复杂的策略。考虑到文献中的主流趋势,这一结果令人惊讶。
尽管这些发现很有前景,但我们的工作也存在一些局限性,这为未来的研究指明了方向。一个值得探索的关键领域是 VLA-0 在使用大规模动作数据训练时的表现;另一个值得研究的领域是使用量化和蒸馏等优化技术来提升 VLA-0 的推理速度。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 22
22 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)