运动规划实战案例 | 基于ROS的机器人智能任务调度仿真平台
目录
1 任务调度问题
在任务调度过程中,其核心问题即为任务的合理分配问题,任务分配即按照一定的优化目标将所有任务合理均衡地分配给机器人,并根据所制定的任务分配方案,消耗最小化代价完成所有任务,优化任务分配策略旨在提升机器人的整体工作效能。单机器人的任务调度包含三个方面:
- 机器人的出发和待处理任务位置提前获知;
- 机器人必须不重复地途径所有指派的任务点;
- 机器人应以最小代价经过所有任务点
因此,单机器人的任务调度可以描述为:某个机器人要完成辖区内所有任务,从起点出发,遍历所有任务点后回到出发地,求解该机器人应如何选择行进顺序,使总代价最小,多机器人的场景也可以此拓展。
进一步,形式化地,有一由 m m m个任务点形成的完全无向带权图 G ( M , A ) G(M,A) G(M,A),其中节点 M = { 1 , 2 , ⋯ , m } M=\left\{ 1,2,\cdots ,m \right\} M={1,2,⋯,m},边 A = { ( i , j ) ∣ i , j ∈ M } A=\left\{ \left( i,j \right) |i,j\in M \right\} A={(i,j)∣i,j∈M},则任务调度问题的拓扑结构为
D = [ 0 d 12 ⋯ d 1 m d 21 0 ⋯ d 2 m ⋮ ⋮ ⋱ ⋮ d m 1 d m 2 ⋯ 0 ] \boldsymbol{D}=\left[ \begin{matrix} 0& d_{12}& \cdots& d_{1m}\\ d_{21}& 0& \cdots& d_{2m}\\ \vdots& \vdots& \ddots& \vdots\\ d_{m1}& d_{m2}& \cdots& 0\\\end{matrix} \right] D= 0d21⋮dm1d120⋮dm2⋯⋯⋱⋯d1md2m⋮0
其中矩阵 D \boldsymbol{D} D是对称阵。优化目标是求解一个节点序列
ℓ = { i 1 , i 2 , ⋯ i m + 1 } \ell =\left\{ i_1,i_2,\cdots i_{m+1} \right\} ℓ={i1,i2,⋯im+1}
使代价
ℓ = a r g min i ∈ ℓ ∑ l = 1 n + 1 d i l \ell =\underset{i\in \ell}{\mathrm{arg}\min}\sum_{l=1}^{n+1}{d_{i_l}} ℓ=i∈ℓargminl=1∑n+1dil
最小,其中要求机器人回到出发位置,即节点序列首尾相连 i 1 = i m + 1 i_1=i_{m+1} i1=im+1
2 旅行商问题求解器
旅行商问题(traveling salesman problem,TSP)是组合优化中的一个NP-hard问题,其日标是寻找一条最优路径使旅行商能够以最小的总距离或总成本访遍所有城市,被广泛应用于物流配送、电子通信、项目调度、城市规划等领域,具有重要的应用和研究价值。

目前求解TSP问题的常用算法主要包括精确算法和(元)启发式算法。以贪心算法、分支定界法、动态规划法为代表的精确算法求解问题的时间复杂度随问题规模的增加呈指数级增长,只适用于求解小规模算例,元启发式算法作为传统人工智能算法,通常具有较低的时间复杂度,并能够在合理的时间范围内找到接近最优解的求解方案,更适用于解决大规模现实问题,尤其是遗传算法(genetic algorthm,GA)、模拟退火算法(simulated annealing algorithm,SA)、蚁群算法(ant colony optimization,ACO)等元启发式算法
这里介绍贪心算法的原理。贪心算法求解旅行商问题采用逐步构建路径的启发式策略,其核心是在每一步选择当前局部最优的决策以期望获得全局近似最优解。具体而言,算法从随机城市 c 1 c_1 c1出发,初始化路径 P = [ c 1 ] P=[c₁] P=[c1]和未访问城市集合 U U U,包含其余n-1个城市;在每一步迭代中,从当前末端城市 c k c_k ck出发,选择距离最近的未访问城市 c k + 1 c_{k+1} ck+1,即满足
c k + 1 = arg min j ∈ U d ( c k , j ) c_{k+1} = \argmin_{j∈U} d(c_k, j) ck+1=j∈Uargmind(ck,j)
其中 d ( c k , j ) d(c_k, j) d(ck,j)表示城市间距离,随后将 c k + 1 c_{k+1} ck+1加入路径并从未访问集合中移除。重复此过程直至 U U U为空,最终闭合回路,将起始城市 c 1 c₁ c1添加至路径末端,形成完整哈密顿回路,总路径长度
L = ∑ i = 1 n − 1 d ( c i , c i + 1 ) + d ( c n , c 1 ) L = \sum_{i=1}^{n-1} d(c_i, c_{i+1}) + d(c_n, c_1) L=i=1∑n−1d(ci,ci+1)+d(cn,c1)
贪心算法的时间复杂度为 O ( n 2 ) O(n²) O(n2),易于实现,适用于简单TSP实例的快速求解。然而,由于算法仅关注即时最优,缺乏全局规划,可能陷入局部最优陷阱,导致最终路径长度显著偏离真正最优解,例如早期选择的短边可能迫使后续引入长边而劣化整体性能。为提升解质量,常采用多随机起点贪心策略以生成多样路径并择优,或作为更复杂元启发式算法的初始化步骤。尽管存在局限,贪心算法仍为TSP提供了基础且实用的近似求解框架。核心代码如下所示
bool GreedySTSPSolver::solve(const TSPProblem::Matrixd& weight_matrix, Solution& solution)
{
if (weight_matrix.rows() == 0 || weight_matrix.cols() == 0)
{
std::cout << "Error: Please initialize the weighted matrix.\n";
return false;
}
// prepare for solution
solution.reset();
const int dimension = weight_matrix.rows();
int curr_index = 0;
std::vector<bool> visited(dimension, false);
visited[curr_index] = true;
solution.best_route.push_back(curr_index);
for (int i = 1; i < dimension; ++i)
{
// find the nearest non-visited node
int nearest_index = -1;
int min_dist = std::numeric_limits<int>::max();
for (int j = 0; j < dimension; ++j)
{
if (!visited[j] && weight_matrix.getValue(curr_index, j) < min_dist)
{
min_dist = weight_matrix.getValue(curr_index, j);
nearest_index = j;
}
}
solution.best_route.push_back(nearest_index);
visited[nearest_index] = true;
curr_index = nearest_index;
}
}
3 机器人智能任务调度平台
3.1 整体框架
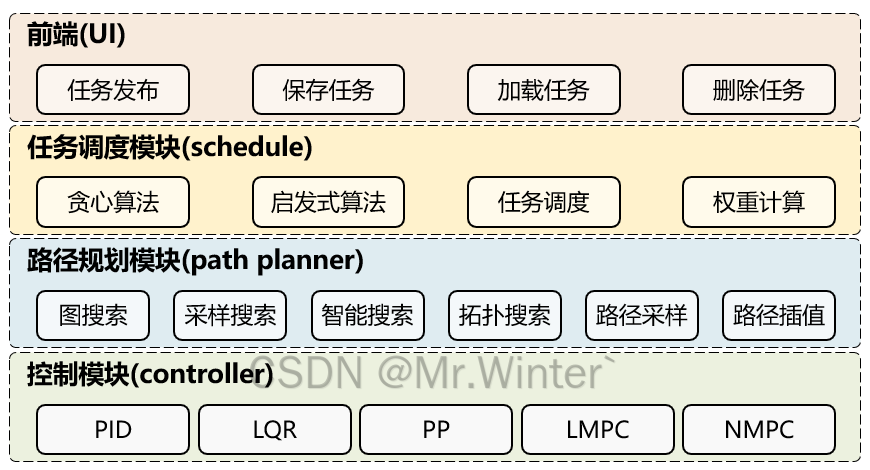
本文设计的基于ROS的机器人智能任务调度仿真平台,轻量化地实现了调度、规划、控制等多种功能,同时框架保证了功能的高度可拓展和可定制。首先,基于rviz插件设计了一个前端窗口,可以在其中进行任务的发布、保存、加载等常规功能。接着,在move_base框架基础上增加了一个任务调度模块。我提供了一个通用的tsp求解器,集成了贪心算法、遗传算法、粒子群算法等常用选项。在明确要执行的任务后,机器人会自主规划一条从当前位置到任务点的最短路径。最后是控制算法,用于驱动机器人点到点间的跟踪运动。
3.2 平台操作演示
3.2.1 发布任务
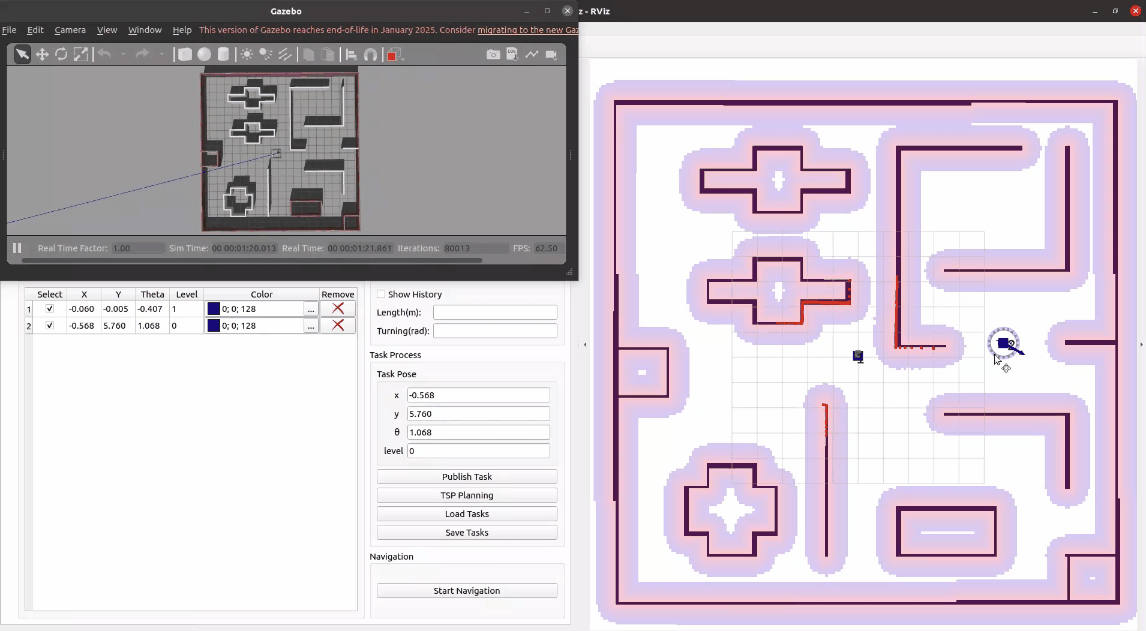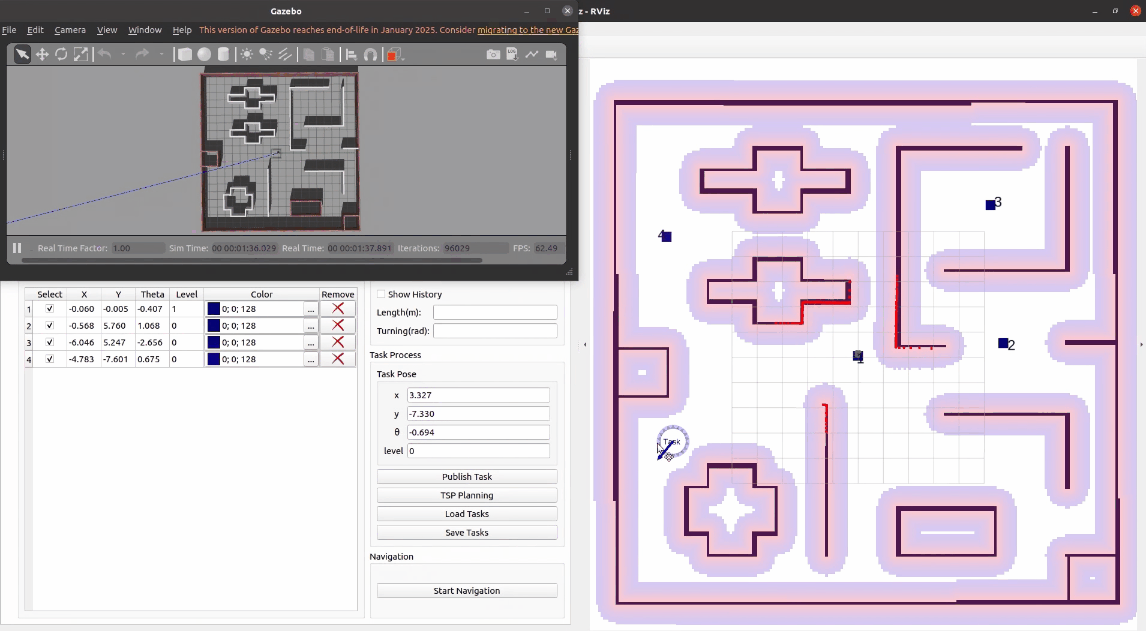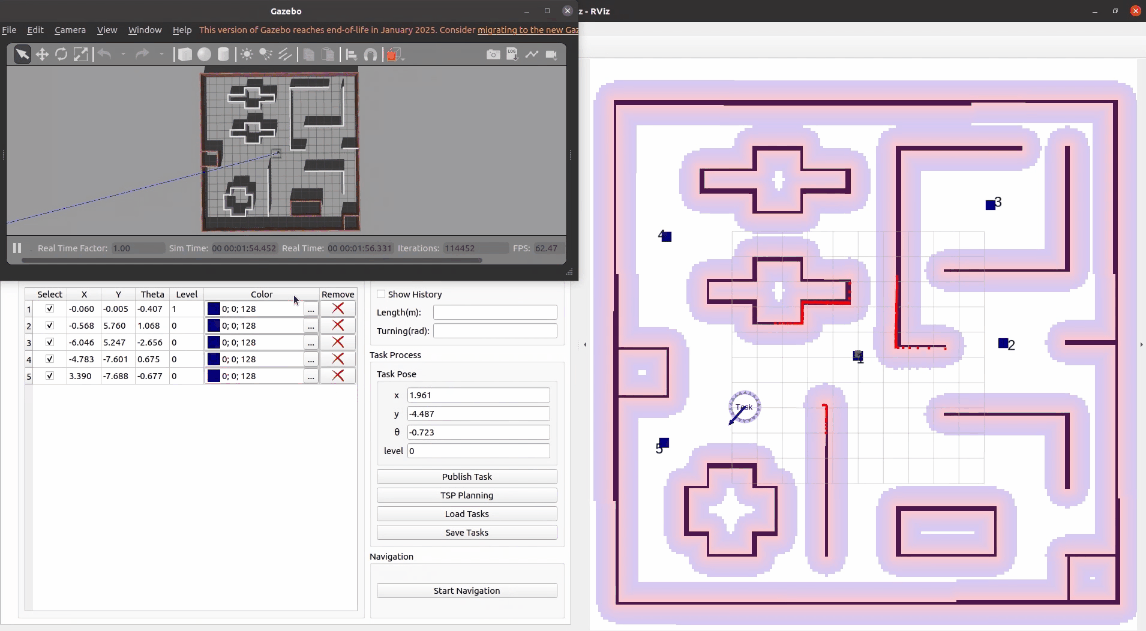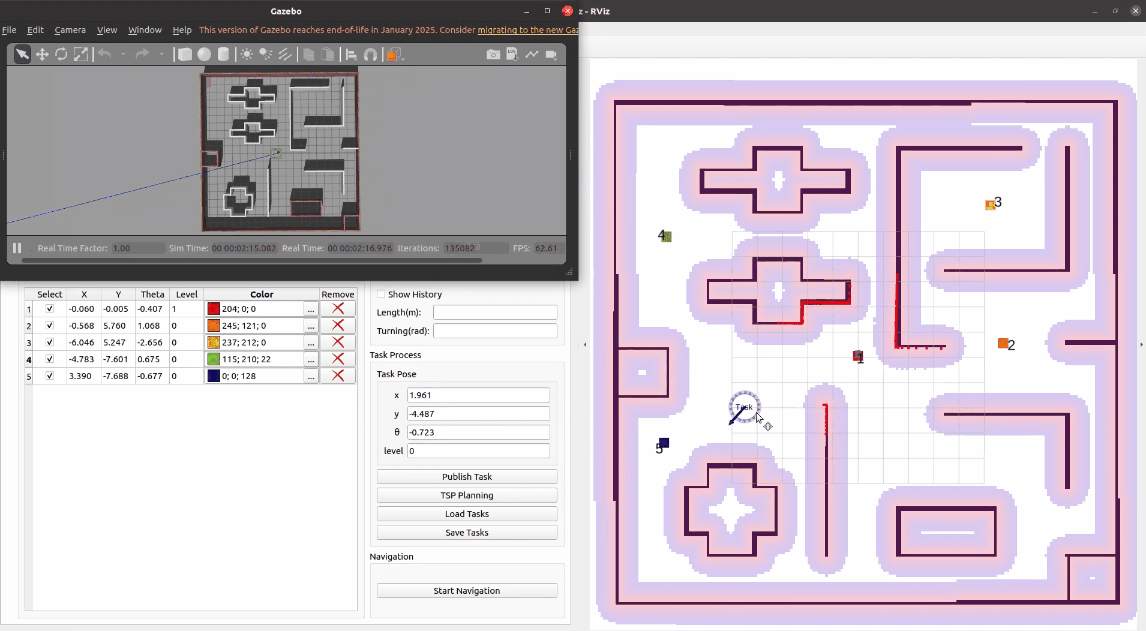
项目启动后,可以看到左下角就是任务调度平台的前端界面,我们可以通过拖动task交互按钮来确认任务坐标,也可以在编辑框内直接输入精确的任务位姿和优先级。接着,点击发布任务,左侧任务列表新增这个任务的具体信息,右侧地图上也对应发布了这个任务点。
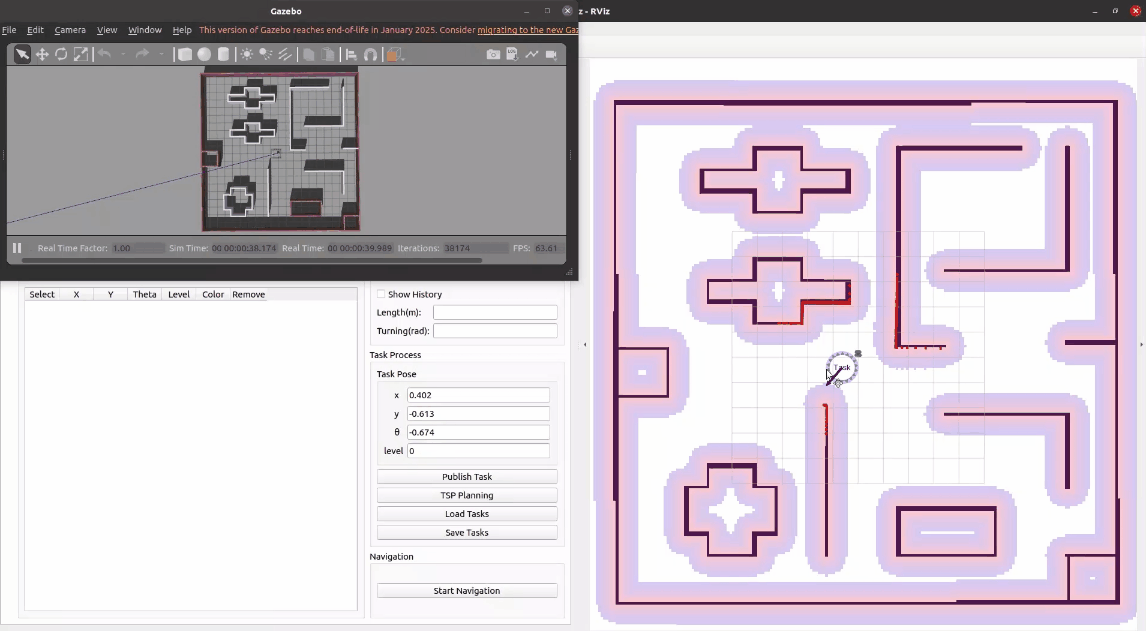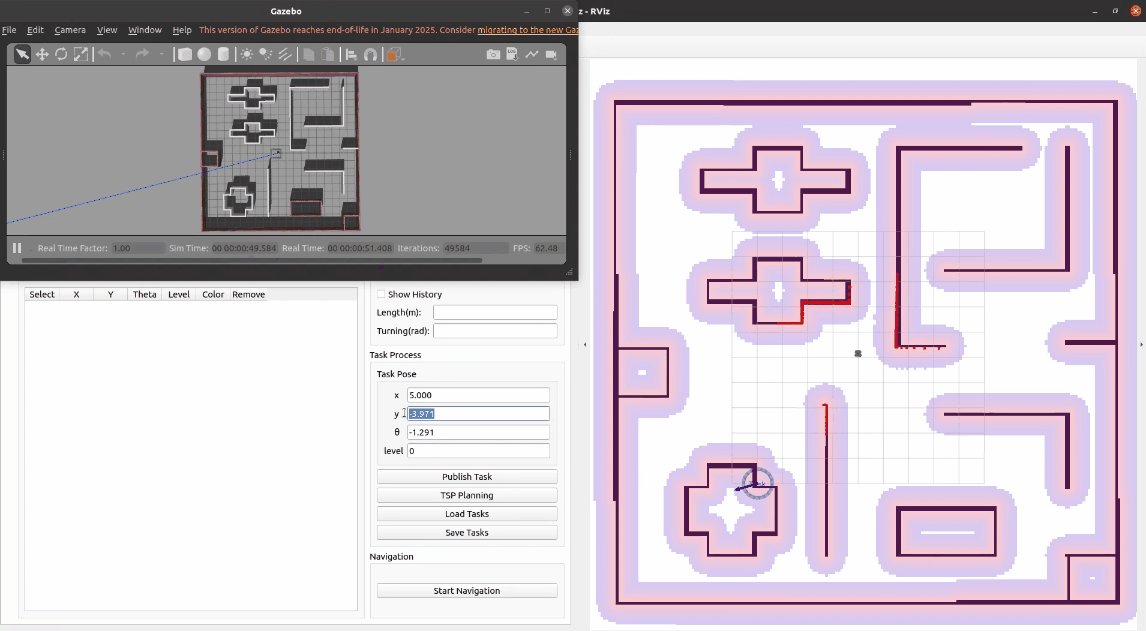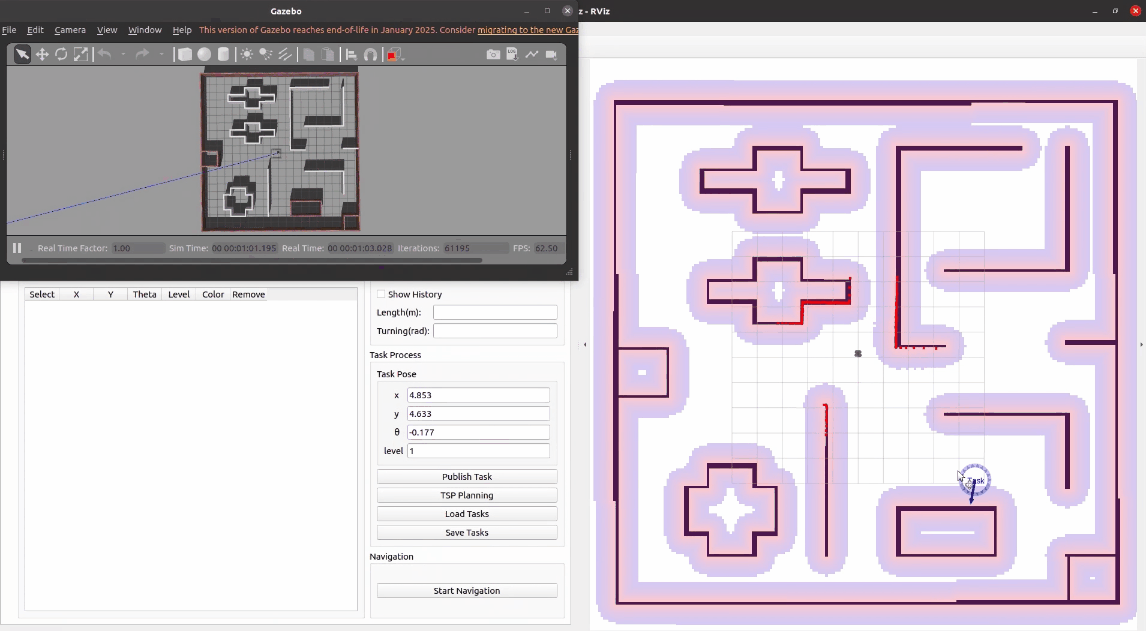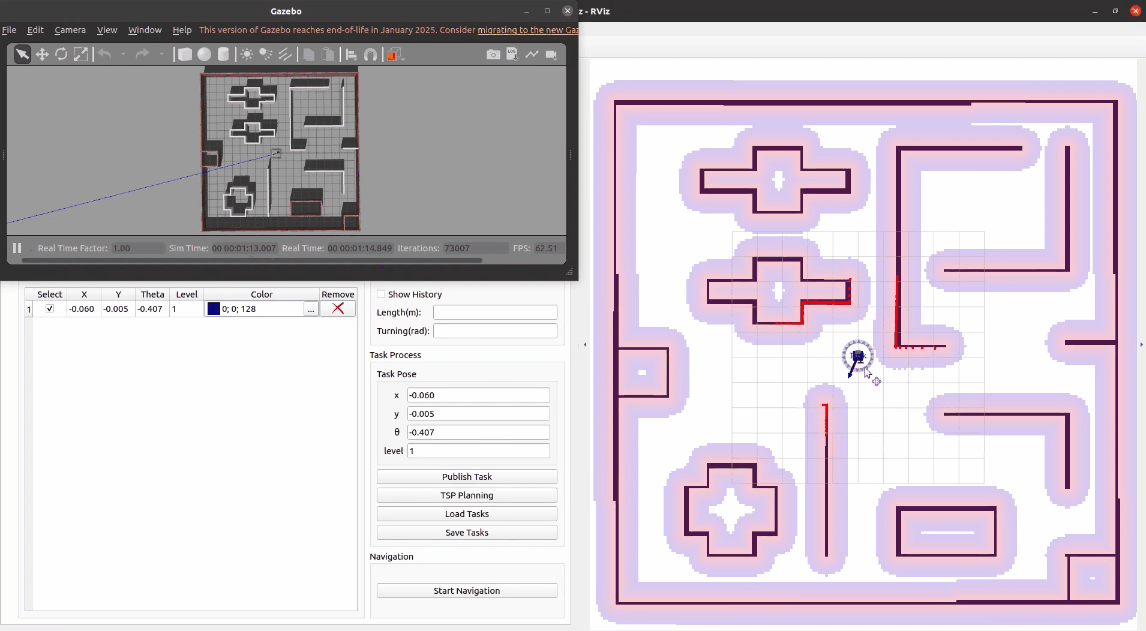
按照同样的方法可以再发布几个任务。如果不需要某个任务,可以点击表格中的删除按钮进行删除。我们也可以为任务设置不同的颜色用来区分
3.2.2 保存任务
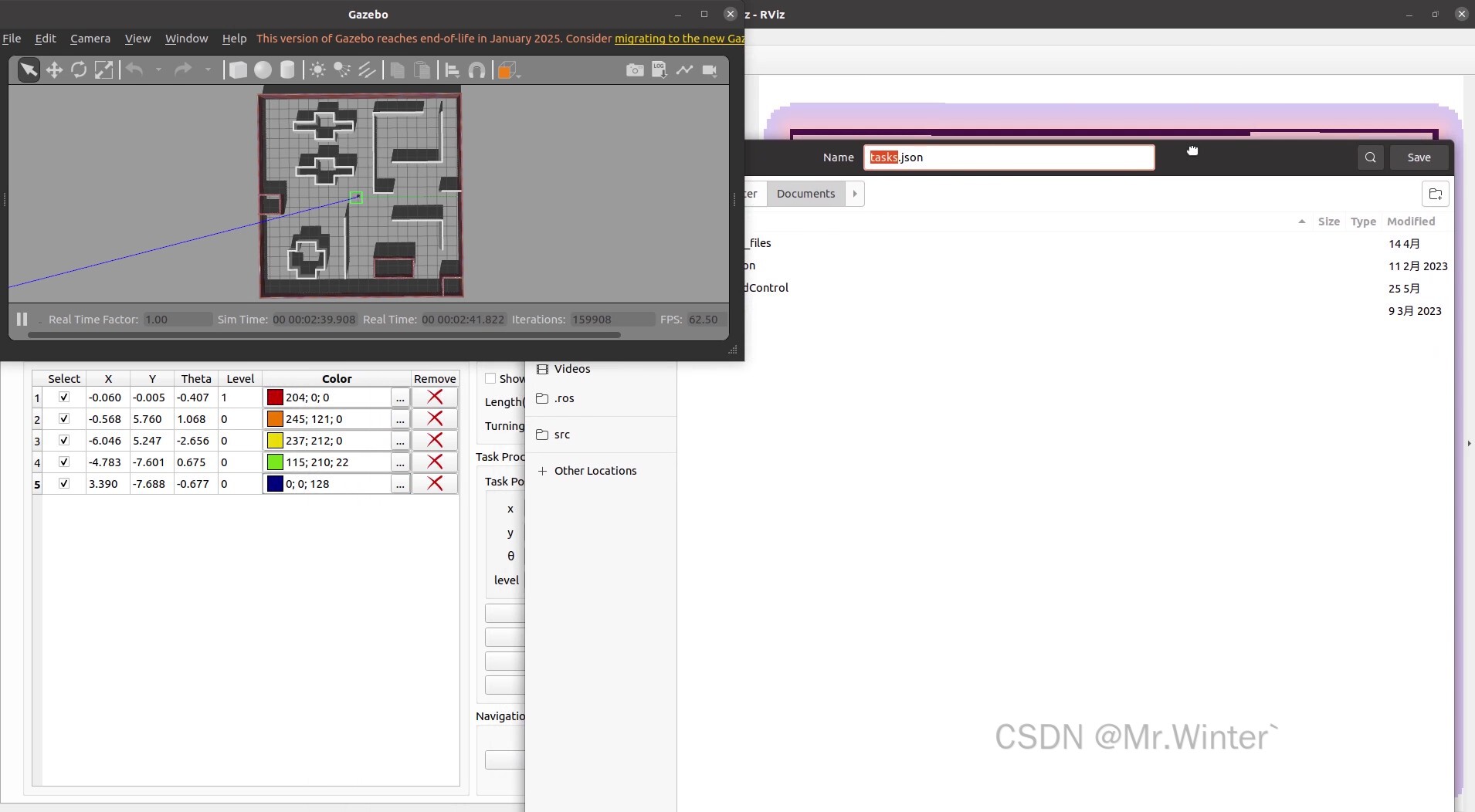
这一切设置完成后,可以点击保存任务,把这组配置保存下来,这样下次进行相同任务时无需重复设置
3.2.3 加载任务
刷新界面,这次重新加载刚才设置好的任务点即可还原工况
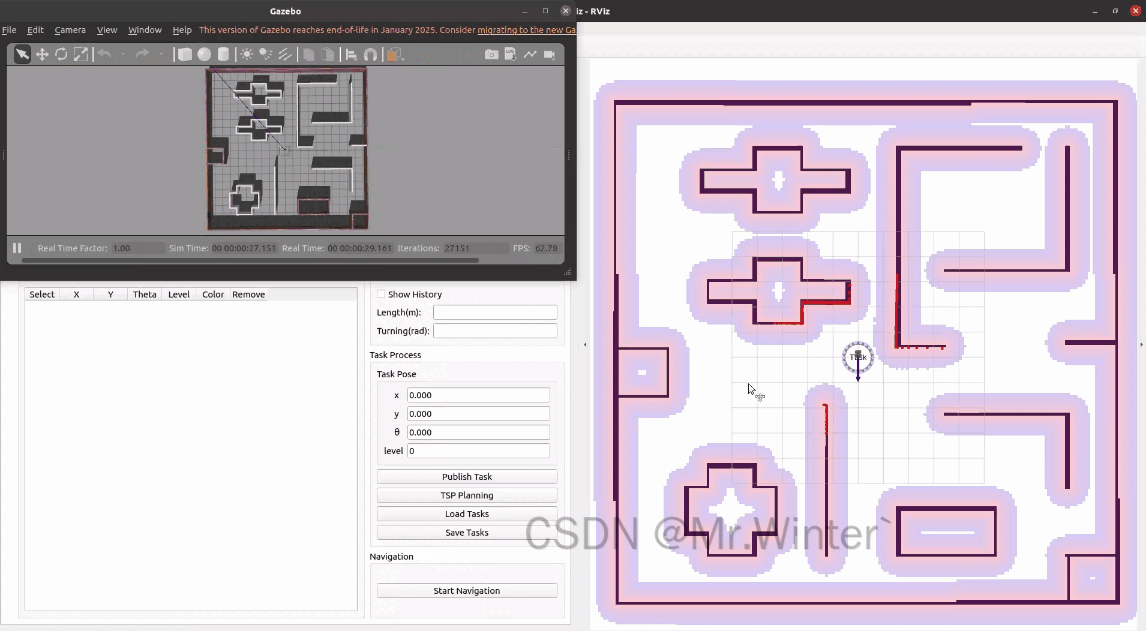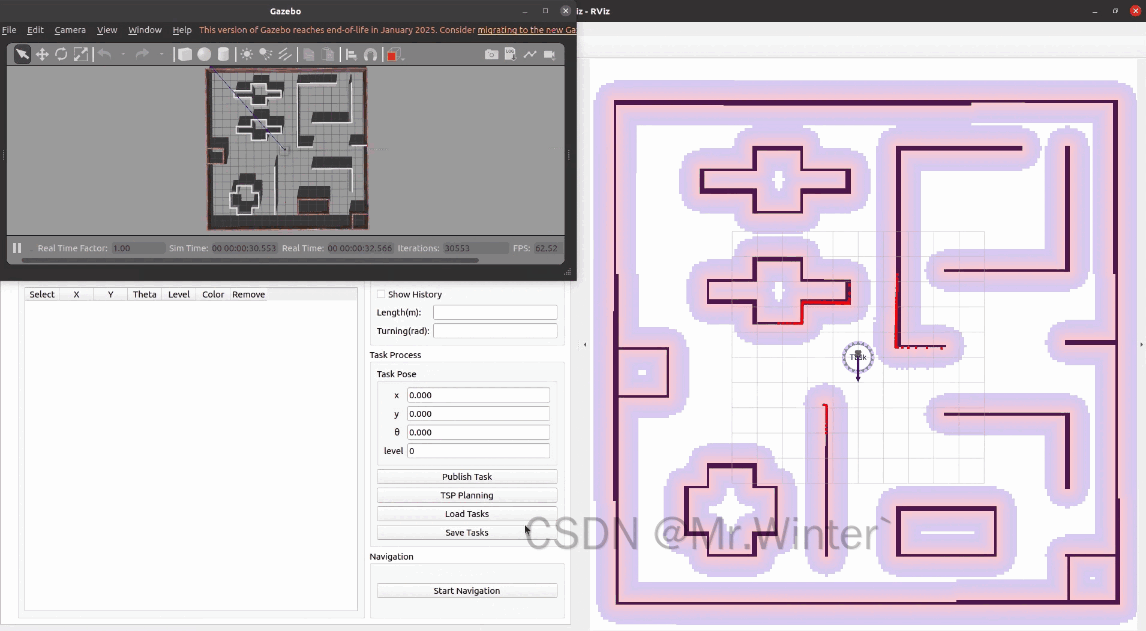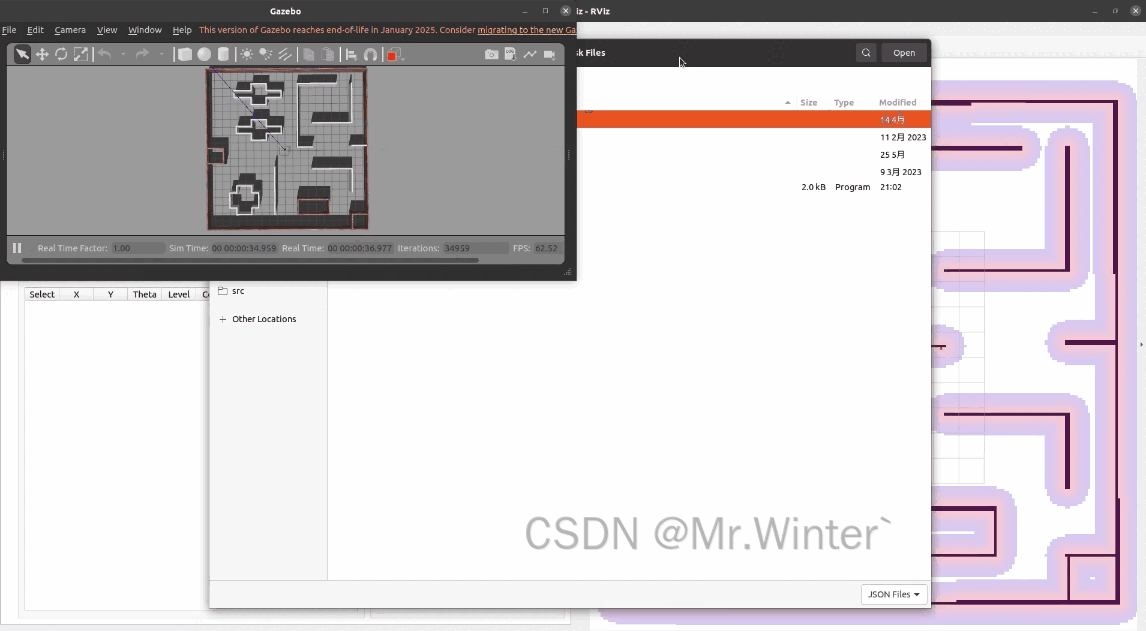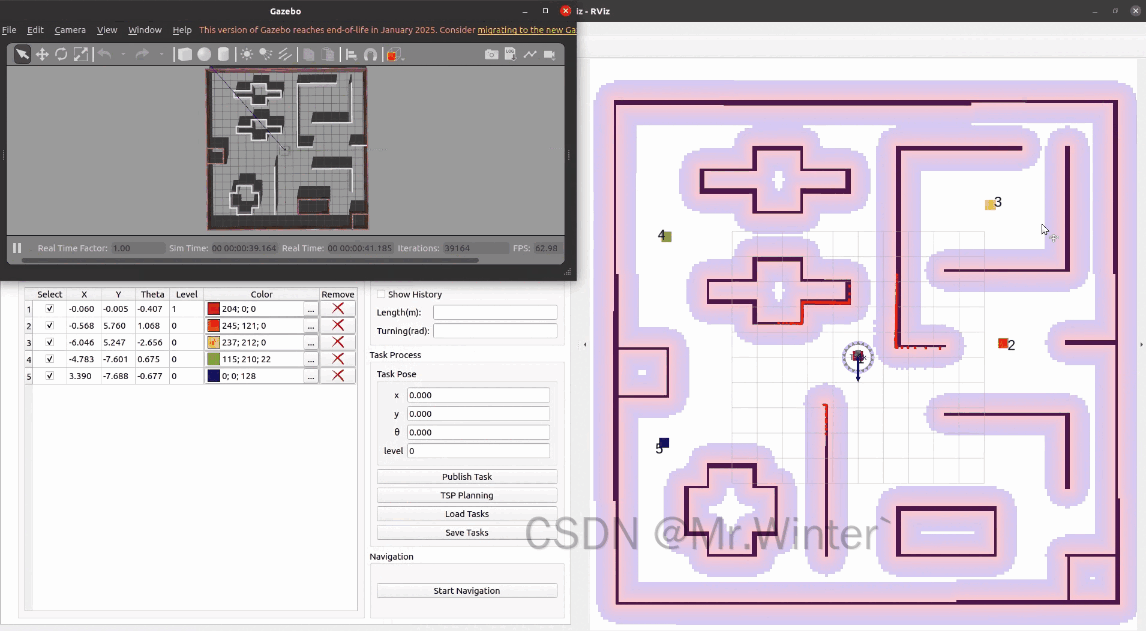
3.2.4 任务调度
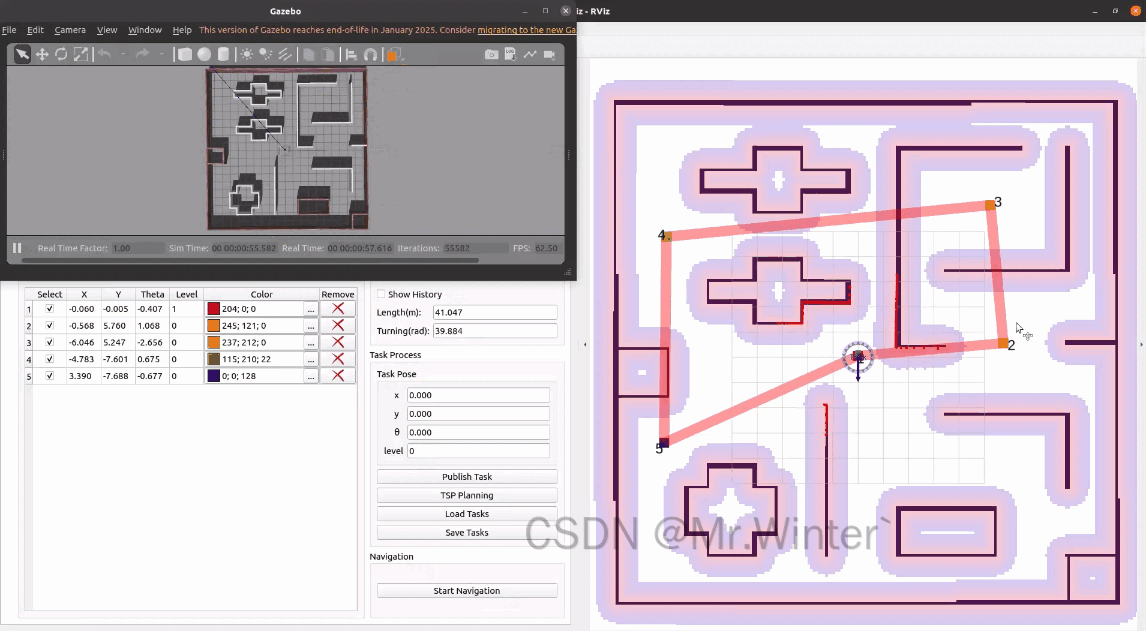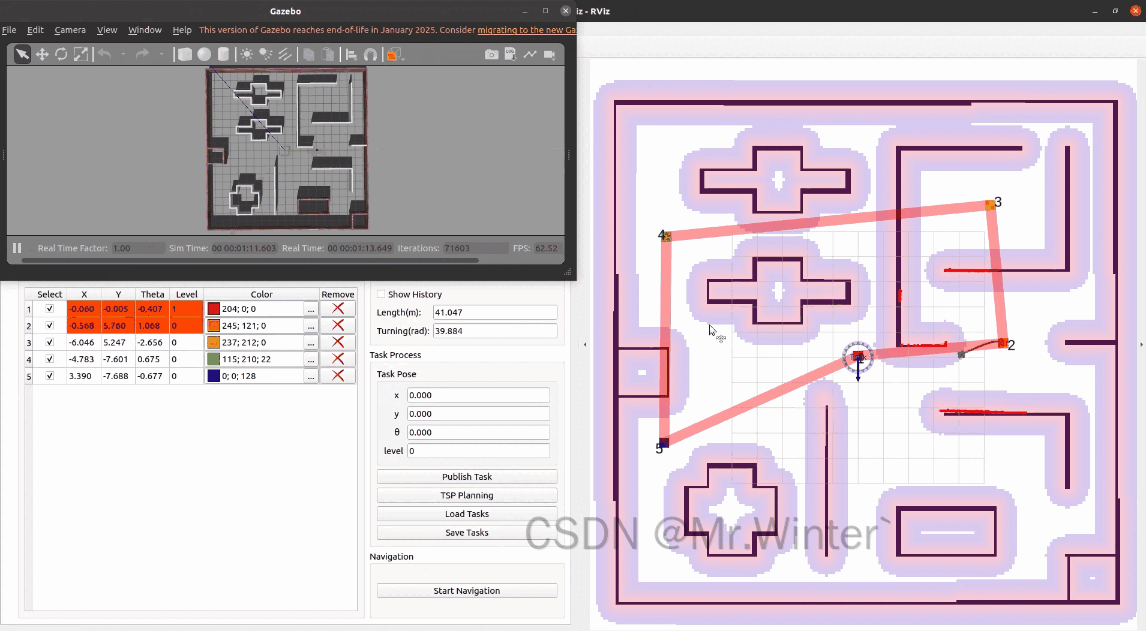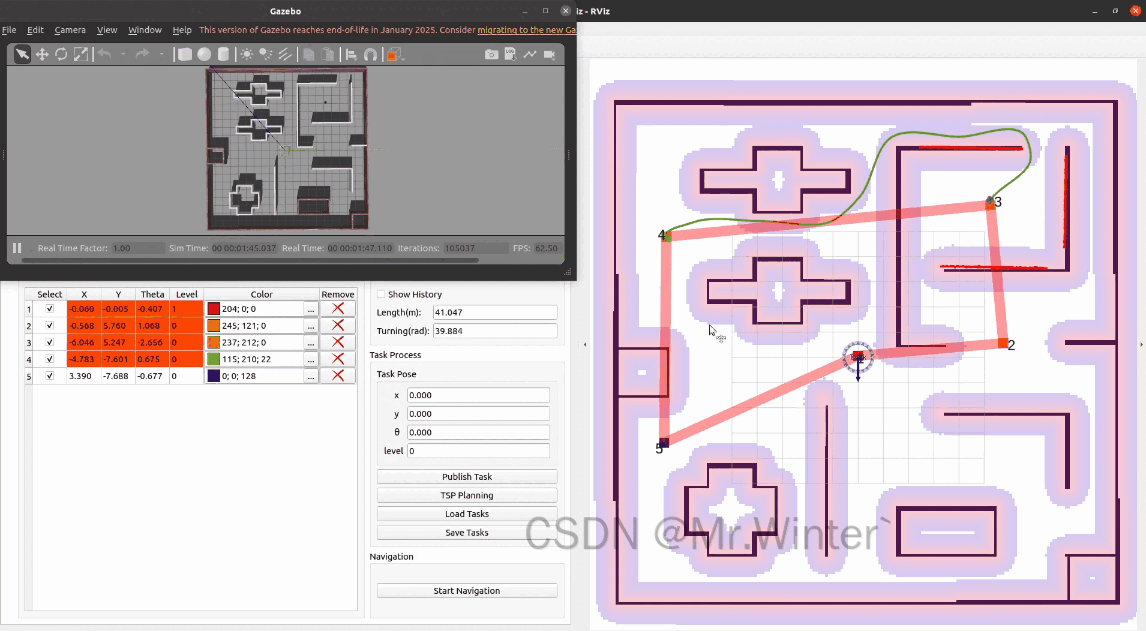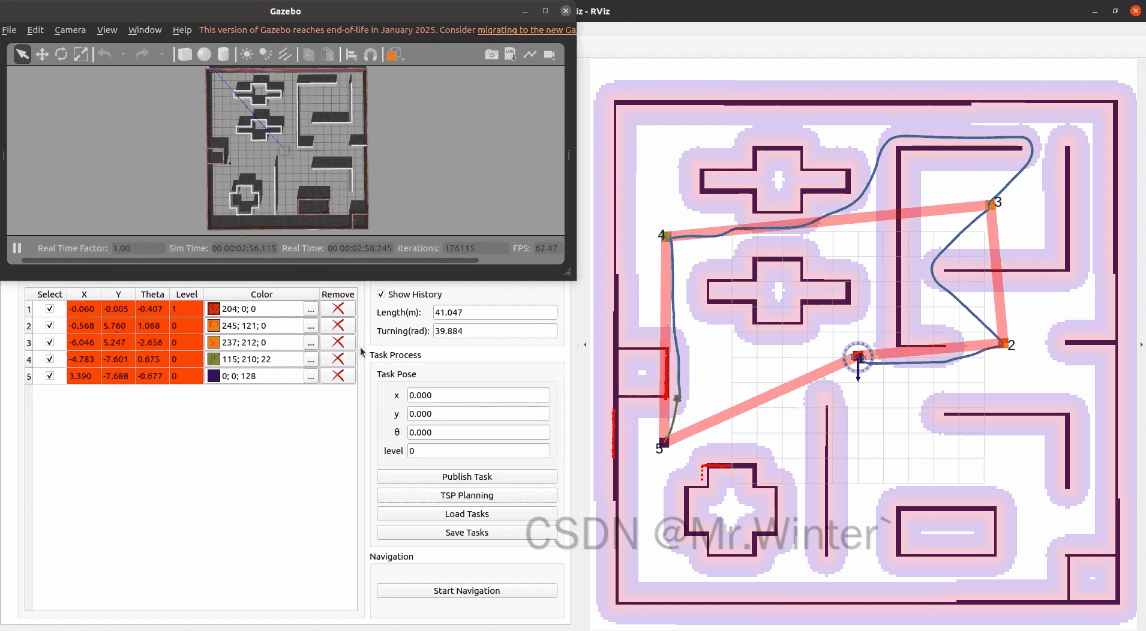
点击TSP Planning即可规划最优的任务顺序
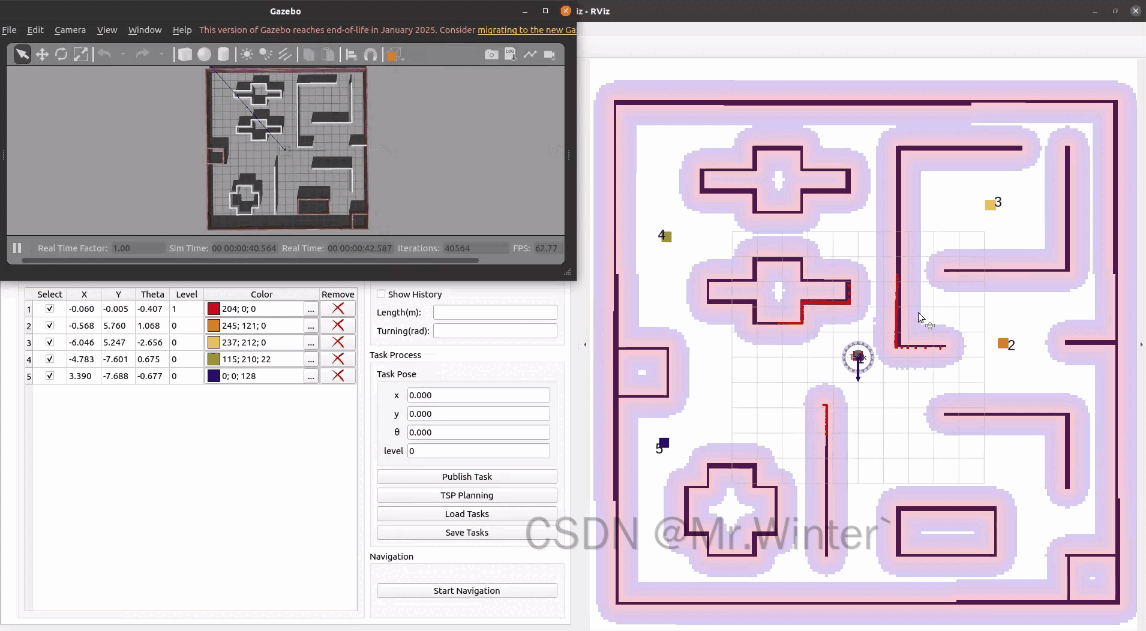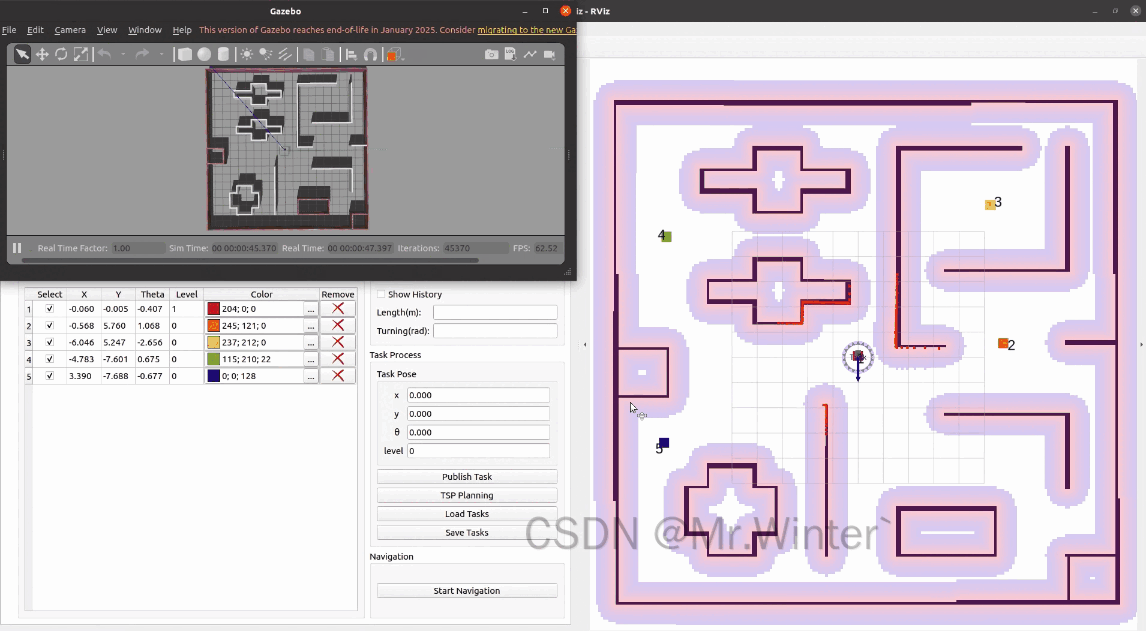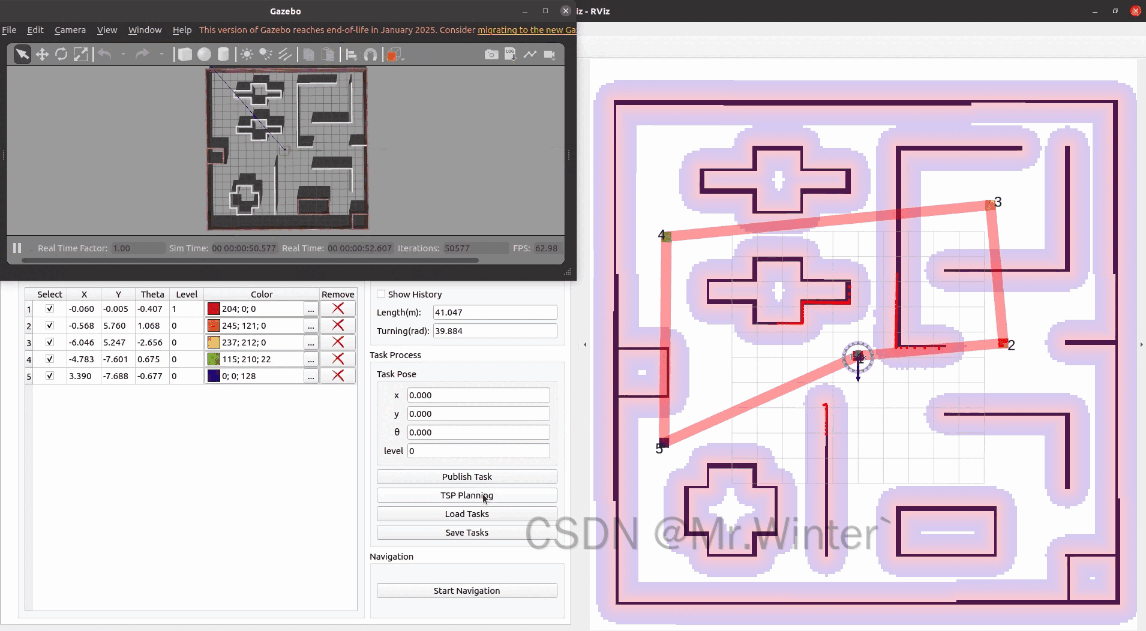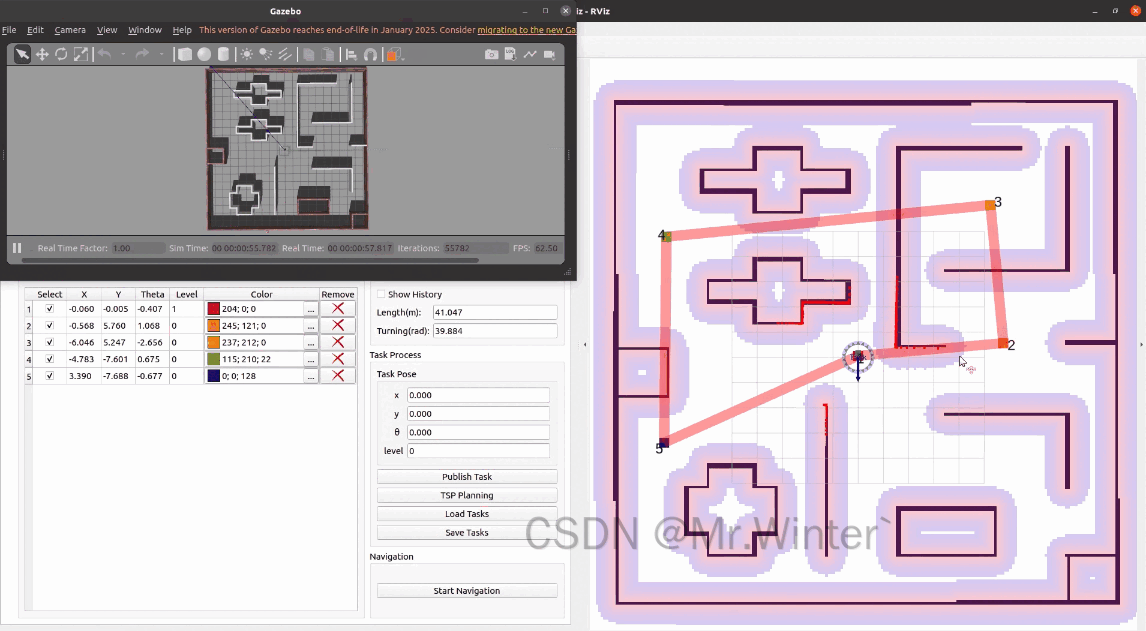
3.2.5 多点巡检
点击Start Navigation,机器人就会按照规划的顺序依次访问这些任务点。点击show history可以显示机器人的历史路径。
完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏:

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 85
85 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)