VLA 论文精读(三十四)Pure Vision Language Action (VLA) Models: A Comprehensive Survey
这篇文章是新出的一片 VLA 领域的综述,对现有 VLA 模型进行了分类并分析了整个 VLA 领域存在的局限性,同时给出了一些发展方向的预测。
这篇文章是新出的一片 VLA 领域的综述,对现有 VLA 模型进行了分类并分析了整个 VLA 领域存在的局限性,同时给出了一些发展方向的预测。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Pure Vision Language Action (VLA) Models: A Comprehensive Survey
- 原文链接: https://arxiv.org/abs/2509.19012
- 发表时间:2025年09月23日
- 发表平台:arxiv
- 预印版本号:[v1] Tue, 23 Sep 2025 13:53:52 UTC (1,792 KB)
- 作者团队:Dapeng Zhang, Jin Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, Qingguo Zhou
- 院校机构:
- Lanzhou University;
- Chinese Academy of Sciences, China;
- National University of Singapore;
- 项目链接: 【暂无】
- GitHub仓库: 【暂无】
Abstract
视觉语言动作 (VLA) 模型的出现标志着从传统基于策略的控制向广义机器人技术的范式转变,将视觉语言模型 (VLM) 从被动序列生成器重构为用于在复杂动态环境中进行操控和决策的主动智能体。本综述深入探讨了先进的 VLA 方法,旨在提供清晰的分类和系统全面的现有研究综述。面分析了不同场景下的 VLA 应用,并将 VLA 方法分为几种范式:基于自回归的方法、基于扩散的方法、基于强化的方法、混合方法和专用方法;同时详细探讨了它们的动机、核心策略、实现方式。还介绍了基础数据集、基准测试、仿真平台。基于当前的 VLA 研究现状,进一步提出了推进 VLA 模型和广义机器人技术研究的关键挑战和未来方向。通过综合最近三百多项研究的见解,描绘了这一快速发展的领域的轮廓,并强调了将影响可扩展、通用 VLA 方法发展的机遇和挑战。
1. Introductions
机器人技术长期以来一直是科学研究的热门领域。过去,机器人主要依靠 预编程指令 和 工程控制策略 来分解和执行任务。这些方法通常应用于简单、重复的任务,例如工厂装配线和物流分拣。近年来,人工智能的快速发展使得研究人员能够利用深度学习的特征提取和轨迹预测能力,涵盖图像、文本和点云等多种模态。通过整合感知、检测、跟踪和定位等技术,研究人员将机器人任务分解为多个阶段以满足执行需求,从而推动了具身智能和自动驾驶的发展。然而,大多数机器人仍然以孤立的智能体形式运行,为特定任务而设计,缺乏与人类和外部环境的有效交互。
为了突破上述限制,研究人员开始探索大语言模型 (LLM) 和视觉语言模型 (VLM) 的结合,以实现更精确、更灵活的机器人操控。 现代机器人操控方法通常利用视觉语言生成范式(例如,自回归模型或扩散模型),并结合大规模数据集和先进的微调策略,称之为 VLA 基础模型。它们显著提高了机器人操控的质量。对生成内容进行细粒度的动作控制,为用户提供了更大的灵活性,从而释放了 VLA 在任务执行方面的实际潜力。
尽管纯 VLA 方法前景光明,但对其的综述仍然稀缺。现有的综述要么侧重于 VLM 基础模型的分类,要么对机器人操作进行整体概述。首先,VLA 方法代表了机器人技术领域的一个新兴领域,尚无成熟的方法论体系或一致的分类法,因此很难系统地总结这些方法;其次,当前的综述要么根据基础模型的差异对 VLA 方法进行分类,要么对整个领域历史上的机器人应用进行全面分析,往往侧重于传统方法而忽略了新兴技术。虽然这些综述提供了宝贵的见解,但它们仅对机器人模型进行了粗略的考察,要么主要集中在基础模型上,导致纯 VLA 方法的文献存在重大空白。
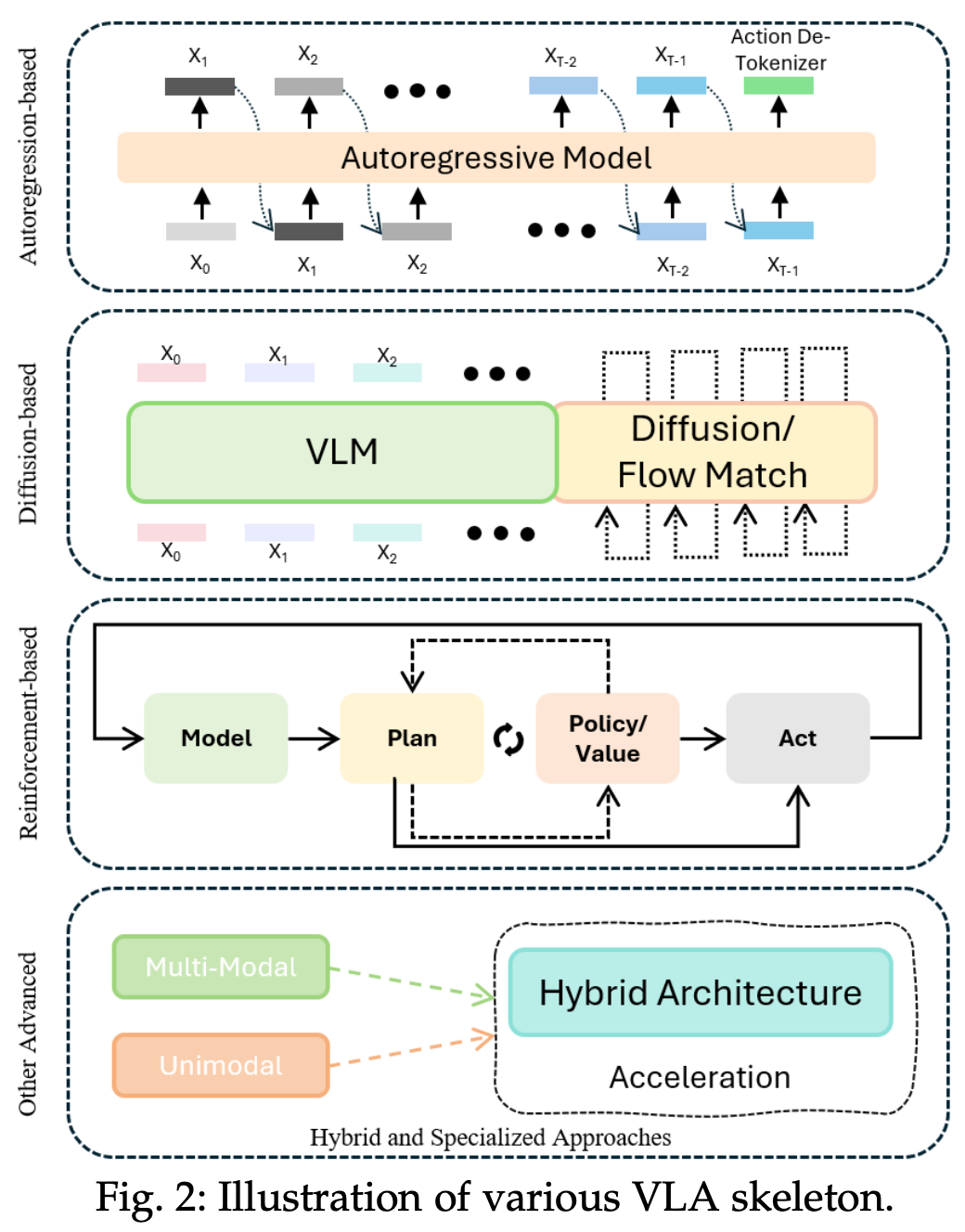
本文研究了 VLA 方法及其相关资源,并对现有方法进行了重点突出且全面的回顾,目标是提出一个清晰的分类体系,系统地总结 VLA 研究,并阐明这一快速发展领域的发展轨迹。在简要概述 LLM 和 VLM 之后,重点关注 VLA 模型的策略,突出先前研究的独特贡献和显著特征。作者将 VLA 方法分为四类:基于自回归的方法、基于扩散的方法、基于强化的方法、混合方法和专用方法,并对其动机、核心策略和机制进行了详细分析。如 Fig.2 展现了这些方法的 VLA 框架。考察了包括机械臂、四足机器人、类人机器人、轮式机器人(自动驾驶汽车)在内的应用领域,并对 VLA 在不同场景中的部署进行了全面的评估。鉴于 VLA 模型对数据集和仿真平台的高度依赖,简要概述了这些资源。最后,基于 VLA 的现状,总结了关键挑战,并概述了未来的研究方向:数据限制、推理速度、安全性,用以加速 VLA 模型和可泛化机器人技术的发展。
本综述的总体结构 Fig.1 所示。首先,第 2 节概述了 VLA 的研究背景。第 3 节介绍了机器人领域现有的 VLA 方法。第 4 节介绍了 VLA 方法所使用的数据集和基准测试。第 5 节和第 6 节讨论了仿真平台和机器人硬件。第 7 节进一步讨论了基于 VLA 的机器人方法面临的挑战和未来发展方向。最后对全文进行了总结,并展望了未来发展方向。
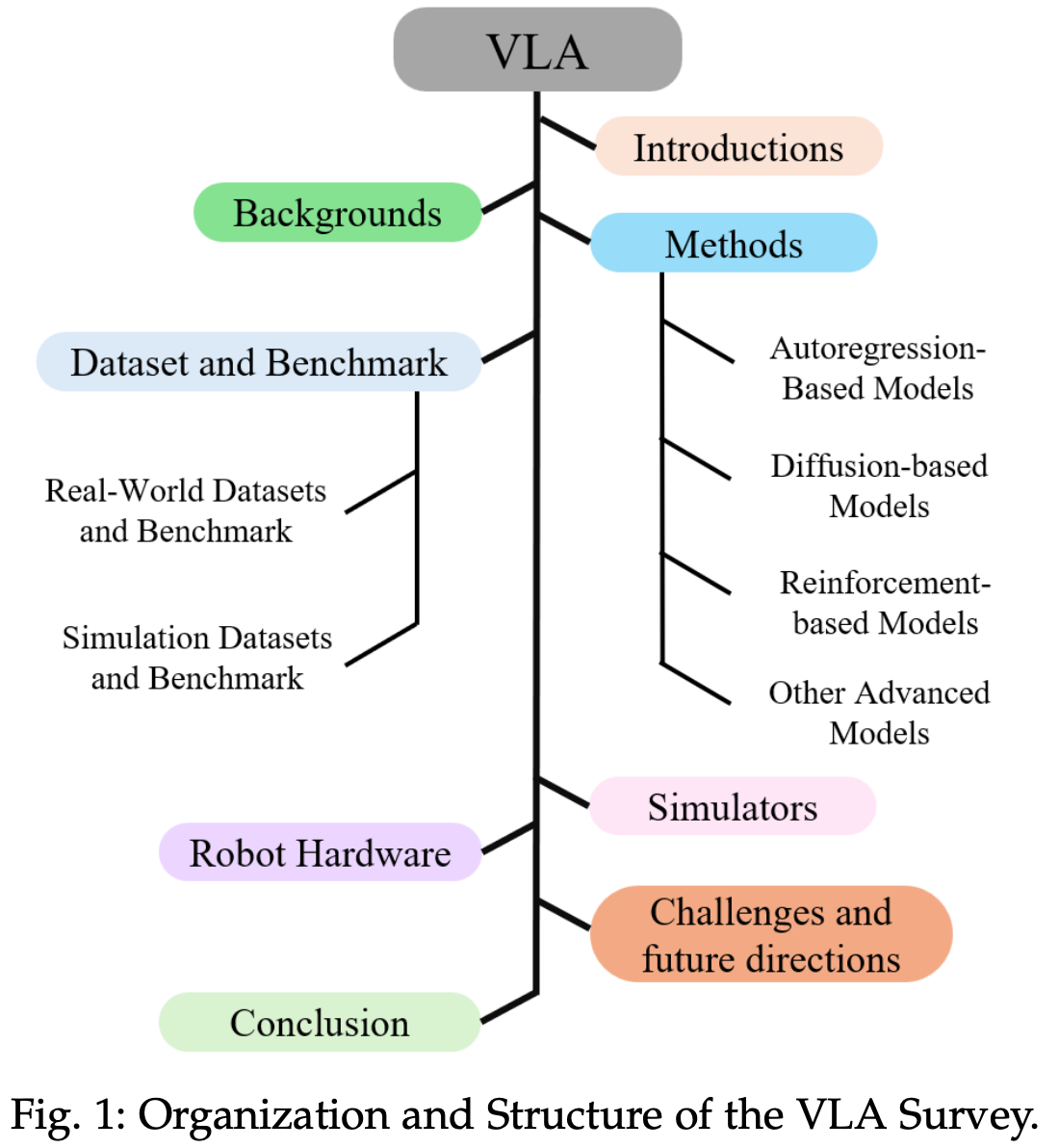
总而言之,作者的贡献如下:
- 提出了 结构清晰的纯 VLA 方法分类法,并根据其动作生成策略对方法进行分类。这有助于理解现有方法,并突出该领域的核心挑战;
- 强调了 每个类别和技术的特征和方法创新,为当前方法提供了清晰的视角;
- 全面概述了用于训练和评估 VLA 模型的相关资源(数据集、基准测试和仿真平台);
- 研究了 VLA 在机器人技术中的实际影响,指出了 现有技术的主要局限性,并提出了进一步探索的潜在途径。
2. Backgrounds
视觉语言动作 (VLA) 模型的出现,代表着通用具身智能的重大进步。传统的机器人系统通常依赖于孤立的感知管道、手工设计的控制策略或特定于任务的强化学习。尽管这些方法在受限环境(例如工厂车间或实验室)中表现有效,但它们在动态和非结构化环境中的泛化能力较差。现代机器人可以使用计算机视觉模型 “see”,通过大型语言模型 “understand” 语言,并通过控制器或学习到的策略 “act”;然而,将这些能力集成到一个连贯统一的系统中,仍然是一个挑战。VLA 模型通过提供一个统一的框架来应对这一挑战,该框架将语言建立在感知之上,并将其映射到可执行的操作。
2.1 Early: LLM/VLM fundamental Models
单模态建模的突破为多模态集成奠定了方法论和工程基础。在计算机视觉领域,卷积神经网络(例如 AlexNet、ResNet)建立了从局部卷积到深度残差学习的表征范式,而 Vision Transformer (ViT) 的出现则进一步推进了这一进程。ViT 将自注意力机制引入图像领域,显著提升了模型的可迁移性和泛化能力。在自然语言处理领域,Transformer 架构实现了大规模预训练和对齐技术,催生了 BERT 、GPT、T5 和 GPT-4 等模型,这些模型展现出强大的推理能力、指令遵循能力和情境学习能力。与此同时,强化学习推动了策略优化和序列决策的发展,从 DQN 和 PPO 发展到决策转换器,这凸显了通过序列建模实现统一的控制视角。
在此背景下,视觉语言模型 (VLM) 应运而生,成为单模态学习和具身智能之间的重要桥梁。早期方法(例如 ViLBERT、VisualBERT)使用双流或单流 Transformer 对图像和文本进行对齐和融合;而对比学习方法(例如 CLIP)则将大规模图像-文本对映射到共享嵌入空间,从而实现零样本和少样本识别与检索。近年来,针对指令调整、以对话为中心的多模态模型(例如 BLIP-2、Flamingo、LLaVA)显著增强了开放式跨模态理解、细粒度基础和多轮推理能力,为视觉语言动作 (VLA) 系统奠定了基础。
2.2 Present: Development of VLA Models
2.2.1 From LLM/VLM to VLA Models
沿着这一轨迹,研究自然而然地朝着 VLA 集成方向发展,它将视觉感知、语言理解、可执行控制统一在一个序列建模框架中。典型的设计是将图像和指令编码为前缀或 context tokens,将机器人状态和感知反馈注入为 state tokens,并自回归生成 action tokens 以生成控制序列,从而形成感知语言-动作闭环。与传统的感知规划控制流程相比,VLA 提供了端到端的跨模态对齐,并对目标、约束和意图进行了统一处理。继承了 VLM 的语义和指令泛化能力,而 显式的状态耦合和动作生成则赋予了其对环境干扰和长周期任务的鲁棒性。这种从单模态到多模态,再到多模态加可执行控制的进展,为不仅能够观察和理解,而且能够行动的系统建立了方法论基础。
2.2.2 The Supporting Role of Data and Simulation
机器人技术中 VLA 模型的开发在很大程度上依赖于高质量的数据集和能够捕捉真实场景复杂性的仿真模拟器。最近的机器人方法通常基于深度学习并由数据驱动;因此,数据集的收集和注释在推动该领域的进步方面发挥着至关重要的作用。一些数据集是在真实环境中收集的,这需要大量的人力和财力。为了应对这些挑战,研究人员还利用来自互联网的大规模人体操作视频作为泛化数据集,为 VLA 模型训练提供辅助监督。尽管做出了这些努力,数据收集仍然成本高昂,注释工作耗费大量人力,而且长尾极端情况往往未被充分重视。其他数据集是通过机器人模拟器生成的,这有助于收集大规模标记数据。模拟器提供多样化且可控的环境、灵活的传感器配置、逼真的运动模型以及交互式静态和动态场景,支持数据收集和模型评估。代表性数据集包括 Open X-Embodiment (OXE),它整合了来自 21 个机构的 22 个机器人数据集,涵盖 527 种技能和 160,266 个任务;以及 BridgeData,它涵盖了多个领域中 10 个环境中的 71 个任务。这些资源标准化了数据格式,从而促进了 VLA 研究的快速发展和可重复性。THOR、Habitat、MuJoCo、Isaac Gym 和 CARLA 等模拟器提供了可扩展的虚拟环境,能够生成多模态注释,包括动作轨迹、物体状态和自然语言指令。总的来说,这些数据集
和仿真平台缓解了现实世界机器人数据的稀缺性,并加速了 VLA 模型的训练和评估
2.3 Future: Towards General Embodied Intelligence
VLA 模型占据着视觉、语言和动作融合研究的前沿。它们建立在感知和推理基础模型的突破之上,强调人机交互和任务执行的能力,并将这些能力扩展到物理世界。通过整合视觉编码器的表征能力、大型语言模型的推理能力以及强化学习和控制框架的决策能力,VLA 模型在弥合“感知-理解-动作”鸿沟方面拥有巨大的潜力。VLA 面临着可扩展性、泛化、安全性和实际部署方面的挑战,但仍被广泛认为是具身人工智能的关键前沿领域。尽管 VLA 在视觉语言动作交互方面取得了显著成就,并受益于大规模语言模型的进步,但尚未在具身智能领域实现完全的通用性。通用具身智能认为,类人智能行为不仅依赖于认知处理,还依赖于身体、环境感知和反馈机制,从而实现与外部世界的交互。为了满足不同任务的需求,通用具身智能可以体现在各种类型的机器人中,包括家用类人机器人、配备灵巧机械手的装配机器人,以及具有特殊能力的仿生机器人。显然,通用具身智能有潜力使人工智能系统能够在各种环境中执行更广泛的任务。VLA 目前正在朝着通用具身智能的愿景发展,并有望实现这一愿景。
3. Vision Language Action Models
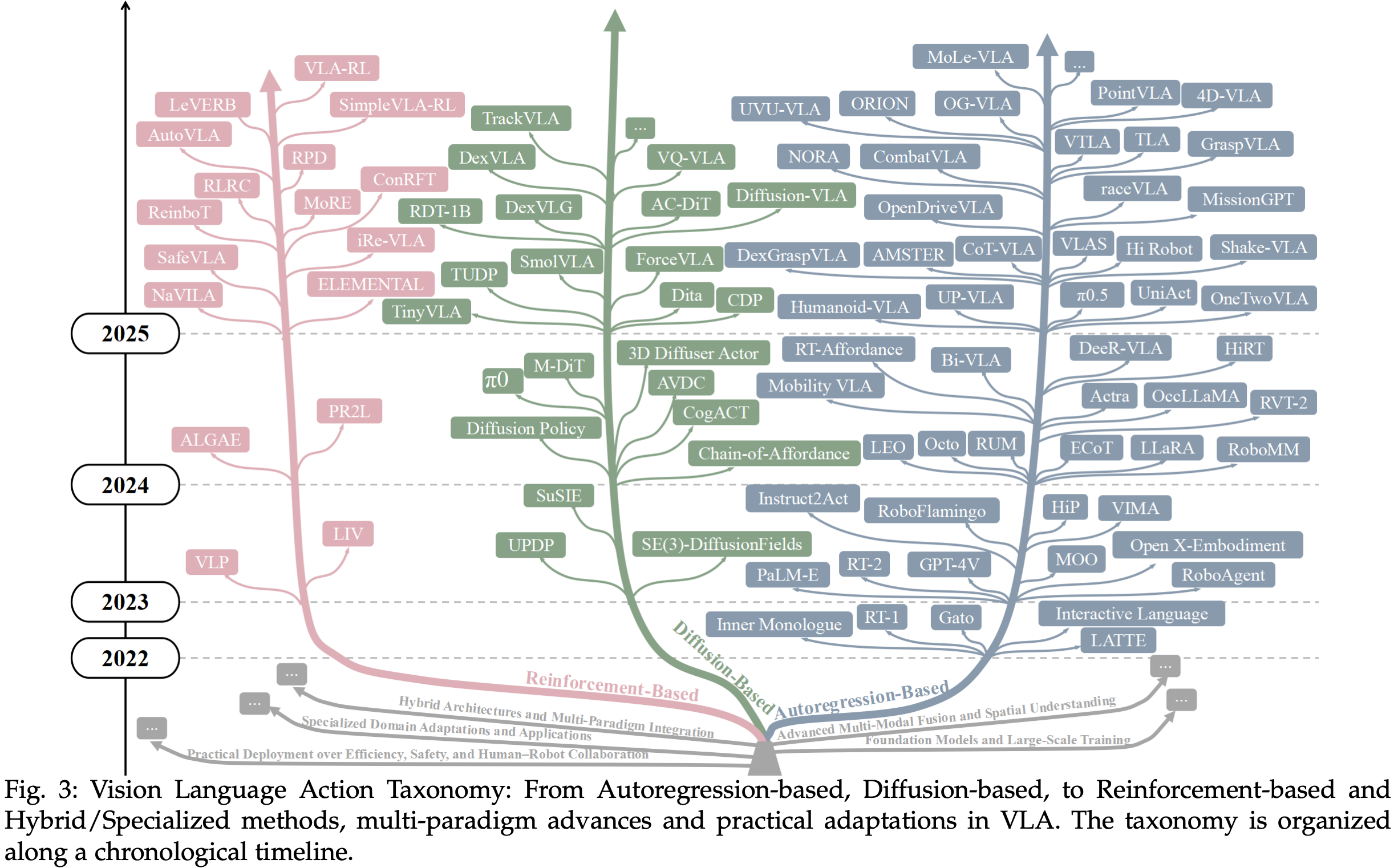
近年来,在多模态表征学习、生成模型、强化学习的推动下,VLA 模型经历了快速而系统的发展。为了追溯这一演变过程,本节回顾了 VLA 中的主要方法论范式,包括基于自回归的建模、基于扩散的方法、强化学习策略以及混合或专用设计。Fig.3 以树状图的形式展示了这些范式的进展,每个分支都突出了各自分类法中的代表性成果。该分类法按时间顺序排列,强调了方法论创新如何逐步扩展 VLA 模型的功能。
3.1 Autoregression-Based Models in Vision Language Action Research
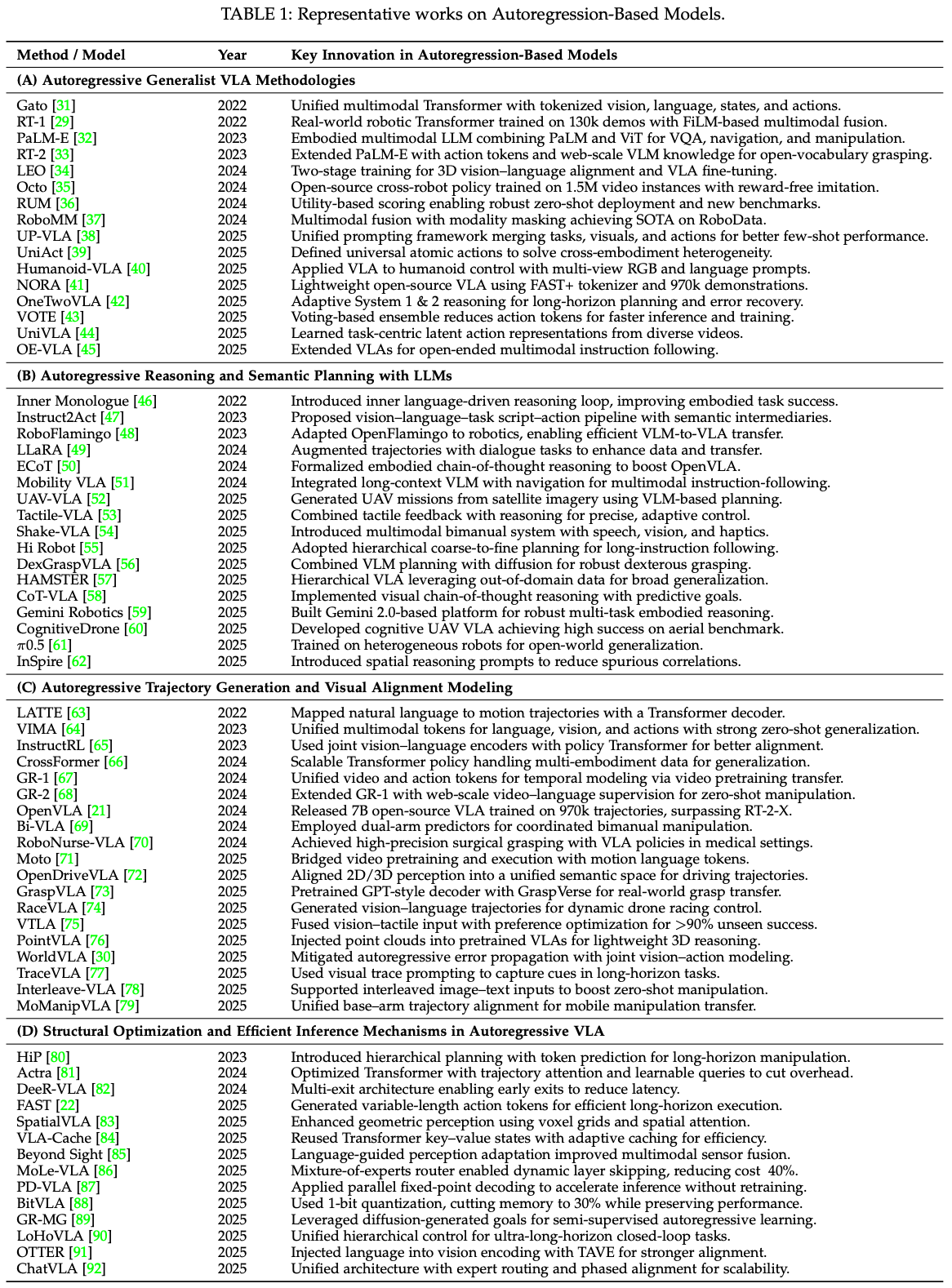
基于自回归的模型是 VLA 任务中序列生成的经典而有效的范式。通过将 动作序列视为时间依赖的过程,这些模型会根据先前的 上下文、感知输入、任务提示 逐步生成动作。随着 Transformer 架构的快速发展,最近的 VLA 系统已经证明了这种方法的可扩展性和鲁棒性。Table.1 总结了这些方向的代表性工作,共同凸显了基于自回归的建模范式在 VLA 研究中的多功能性和通用性。
3.1.1 Autoregressive Generalist VLA Methodologies
通用 VLA agents 的研究 将感知、任务指令、动作生成统一在自回归序列模型中。通过对多模态输入进行 tokenizing,这些模型能够跨异构任务逐步生成动作。
早期的研究,例如 Gato 将异构模态进行 tokenizing 用于联合训练。后续的扩展工作 RT-1/RT-2,利用了海量真实世界数据集和网络规模的预训练,而 PaLM-E 将预训练的语言知识融入到具身控制中,将自回归 Transformer 确立为实用的统一模型。
为了解决具体化碎片化问题,Octo、LEO 和 UniAct 等框架将视觉语言模态与通用动作抽象相结合,以实现跨平台兼容性,近期的工作侧重于推理集成和效率;当下,模型 将动作生成与语言推理和自适应提示相结合,以进行长期规划;NORA 和 RoboMM 等轻量级设计解决了部署限制问题。
总体而言,通用型 VLA 智能体的研究已从早期的统一 tokenization 发展到大规模现实世界训练和语义基础,并逐渐转向跨平台通用性、推理集成和以效率为导向的设计。这一发展反映了从概念验证演示到强调 可扩展性、语义推理、可部署性 的系统的转变。Table.1 (A) 总结了具有代表性的自回归通用智能体及其主要贡献。然而,安全性、可解释性以及与人类价值观的契合等问题仍未得到很大解决,为未来的研究留下了充足的空间。

3.1.2 Autoregressive Reasoning and Semantic Planning with LLMs
LLM 的集成使其 从被动输入解析器转变为 VLA 系统中的语义中介,
从而实现了对长周期和组合任务的推理驱动控制。本节回顾了基于 LLM 的推理从语义中介到分层规划器和平台级编排的演变。
为了将推理功能引入 VLA 模型,Inner Monologue 引入了自言自语式的推理,包括行动前规划和行动后反思。Prompt-to-Walk、RoboFlamingo 和 RoboMM 等扩展模型则在运动和操控任务中展示了语言表征。
后续方法通过反馈和分层规划增强了适应性。交互式语言实现了实时纠正,开放式可指导智能体利用了情景记忆,而 Hi Robot 则采用分层规划来执行长指令。MissionGPT、Mobility VLA 和 NORA 则强调轻量级部署和对话驱动的适应能力。
分层框架将语义规划与控制器相结合以实现灵巧的操作。InSpire 从远见到深思熟虑以及 CoT-VLA 强调运行时稳定性和思维链机制。
基于自回归的推理架构通常将输入拼凑到序列中,并利用这些 tokens 进行进一步推理。这些模型可以处理各种长度的输入,强大的上下文学习能力使其能够在统一的结构下处理不同的模态。无人机专用系统,例如认知无人机和 UAV-VLA 突出了空中导航和卫星信息规划。其他研究,包括OneTwoVLA,则解决了自适应推理,即动作切换和异构控制空间的抽象。
与上述方法相比,系统化和平台化的努力已开始巩固这些进展。Gemini Robotics 和 Agentic Robot 将 LLM 定位为具身化流程的中央协调器,而 π0.5 和 fast 则瞄准开放世界的可扩展性和高效的 tokenization。包括 VLA 模型-专家协作和 LLaRA 在内的支持性工作探索了协作机制和辅助任务,以改进 VLM 到 VLA 的迁移。基于 LLM 的 VLA 推理已从语义中介发展到交互式和分层规划、跨模态扩展和集成平台。
尽管基于 LLM 的 VLA 推理已从语义中介发展到交互式、分层式的
规划器、跨模态扩展和集成平台。然而,依旧存在一些长期挑战,包括幻觉控制、多模态对齐、推理稳定性、实时安全性。Table.1 (B) 总结了代表性研究及其贡献。

3.1.3 Autoregressive Trajectory Generation and Visual Alignment Modeling
自回归轨迹建模增强了感知动作映射,同时确保了视觉-语言语义的一致性。这些模型 基于多模态观测数据,解码运动轨迹或控制 token,为基于基础的指令遵循和动作执行提供了统一的机制。
早期研究如 LATTE,展示了将语言直接映射到轨迹的可行性,从而启发了多模态扩展。通过大规模预训练,VIMA 和 InstructRL 证明,语言、视觉、动作的联合 tokens 支持强大的跨任务泛化,尽管通常仅限于仿真。同时,MOO 和基于 GPT 的方法利用预训练的 VL 主干网络进行开放世界泛化和轻量级轨迹生成,这些研究表明语义先验可以减少对特定于机器人的预训练的依赖。
第二项工作探索了视频预测和世界建模。GR-1/2 将视频生成预训练迁移到机器人技术,而 CronusVLA 和 WorldVLA则改进了时间一致性。 TraceVLA 和 Uni-NaVid 进一步引入了长视界提示,共同实现了从短视界解码到预测环境建模的转变。
基于自回归的方法已被应用于从四足动物运动到双手操作的各种机器人实例,展现了 VLA 框架的灵活性。OpenVLA 等大规模研究进一步凸显了跨平台泛化和高效自适应性,而潜在运动 token 方法则指向了轻量级预训练策略。
除了控制之外,自回归轨迹生成技术还扩展到自动驾驶领域。最近的模型通过将视觉和语言与轨迹预测相结合来实现闭环控制,无需高清地图或激光雷达。类似的原理也已应用于移动操控和无人机规划,凸显了这些方法在机器人平台上的多功能性。
研究人员还将自回归框架扩展到细粒度感知和更丰富的模态。最近的模型强调通过强大的预训练流程行精确操作,将触觉-语言-动作整合实现了丰富的接触式交互。也有研究利用3D/4D感知将空间结构嵌入自回归解码,进一步拓宽了多模态领域。
基于自回归的轨迹生成技术已从直接的语言到轨迹映射发展成为一个涵盖 多模态预训练、视频驱动的世界建模、特定于具体化的架构、跨模态感知 的广泛生态系统Table.1 (C)。这些进展展示了自回归作为 VLA 统一机制的可扩展性和多功能性。尽管如此,在 长期稳定性、包含噪声的语义,以及在物理机器人上 高效部署 方面仍然存在挑战。未来的工作应优先考虑 预测模型和低级控制之间的稳健闭环集成,并探索自回归策略与高级推理模块(例如 LLM 规划器)之间的协同作用,从而更接近可靠的通用具体化智能。

3.1.4 Structural Optimization and Efficient Inference Mechanisms in Autoregressive VLA
在自回归 VLA 研究中,结构优化和高效推理对于实现可扩展部署和实时控制至关重要。除了准确性之外,核心挑战在于 如何减少计算冗余、缩短推理延迟,并在各种机器人设置中保持稳健性。
一个重要的方向是 分层模块化优化。早期工作,例如 HiP 表明,将任务分解为符号规划、视频预测、动作执行,能够利用自回归模型进行长时域推理。从高效的观察主干和动作分块,到轨迹感知的注意力机制和频率分离等研究进一步表明,模块化结构可以显著减少计算量,同时保持泛化能力。
另一项研究则强调 动态和自适应推理。DeeR-VLA 等框架能够根据任务复杂度提前终止解码; FAST 等高效的 token 设计则将长动作序列压缩为可变长度的 token。这些方法共同展示了自适应计算如何在准确率损失最小的情况下提高实时响应能力。
第三类强调 轻量级压缩和并行化。量化和跳层方法降低了计算精度,并动态地仅激活部分层子集,从而显著减少了计算量;并行解码和冗余减少策略无需重新训练即可加速推理,凸显了架构压缩如何补充自适应推理。压缩和并行化方法涵盖量化和跳层,这大大减少了计算量,以及并行解码和冗余减少策略,这加速了推理而无需重新训练。
还可以通过 传感器融合和时间复用来提高效率。体素化空间建模、自适应 key-value cache 和 感知自适应 等特定领域的优化,在提高鲁棒性的同时,减少了冗余计算。
一些研究将效率与多模态推理相结合。OTTER 将语言感知融入视觉编码,而 ChatVLA 则采用了分阶段耦合和混合专家路由;其他研究从基于扩散的目标生成、量化到超长视界的分层反馈,展示了架构改进如何平衡效率和可扩展性。
综上所述,自回归 VLA 模型的结构优化和高效推理已经从早期的分层分解策略发展到自适应计算、轻量级压缩、缓存、多模态感知集成 Table.1 (D)。这些方法解决了长序列依赖性和计算冗余问题,并在基准测试和实际部署中取得了显著的提升。未来的研究应致力于 硬件感知的协同优化、智能调度和强大的安全机制,以确保在通用具身智能方面取得可扩展且可靠的进展。

3.1.5 Discussion
Innovations
基于自回归的模型通过在可扩展的 Transformer 架构中统一多模态感知、语言推理、顺序动作生成,推动了 VLA 研究领域的重大创新,支持跨任务泛化的通用智能体,通过 LLM 集成实现语义规划,并将轨迹生成扩展到长视界和多模态,而诸如 token 压缩、并行解码和量化等结构优化则提高了实际部署的效率。
Limitations
自回归解码会引入误差累积和延迟;多模态对齐在噪声或不完整输入下可能变得脆弱;融入大型模型需要大量的计算资源和数据。此外,推理驱动的方法仍然面临着幻觉、稳定性和可解释性的挑战,而效率机制通常会在准确性或通用性之间做出权衡。解决这些问题需要推理和控制之间更紧密的耦合,在现实世界的不确定性下保持鲁棒性,并采用硬件感知的优化策略,以平衡可扩展性和实际部署。
3.2 Diffusion-based Models in Vision Language Action Research
扩散模型(包括流匹配、变分自编码器 VAE 等)已成为生成式人工智能的变革性范式,并在 VLA 框架中展现出实现具身智能的巨大潜力。本小节将回顾 VLA 系统中扩散模型的演变,重点关注三个关键维度。Table.2 总结了代表性研究成果。

3.2.1 Diffusion Generalist VLA Methodologies
将扩散模型集成到 VLA 系统中,将机器人动作生成从确定性回归转变为概率生成策略。通过将动作生成表述为条件去噪,基于扩散的方法可以自然地模拟不同的动作分布,从而能够从相同的观测中生成多个有效的轨迹。
一个关键的发展方向是 融入更丰富的表征结构。几何感知方法将 SE(3) 约束嵌入到扩散中超越欧氏空间,共同优化 3D 环境中的抓取和运动,从而确保物理上一致的动作。同时,将策略学习重新解释为视频生成,利用视频的丰富性进行长远规划和跨模态基础研究。
像 RDT-1B 展示了在双手操作中,通过时间和环境条件的轨迹级扩散来实现零样本泛化。时间相干性可以通过跨时间步长的统一速度场或历史条件以及高效缓存来实现,以实现实时推理。
这些进步标志着三个转变:从确定性到概率生成,从欧几里得表示到几何感知表示,以及从监督范式到自监督范式。这种对生成模型的重新定义使得多任务泛化、小样本自适应、自然语言接口成为可能。Table.2 (A) 总结了架构选择和训练策略。然而,在动态环境变化下,时间一致性仍然脆弱。

3.2.2 Diffusion-Based Multimodal Architectural Fusion
Transformer 与 VLA 系统的集成推动了单一框架内视觉、语言、动作的统一建模,超越了模块化流程,捕捉了具身智能中复杂的相互依赖关系。
将 Transformer 与扩散模型相结合,已被证明具有显著的革命性,因为 注意力机制可以自然地补充生成模型。诸如 Dita 和 Diffusion Transformer Policy 之类的大型框架表明, 将基于注意力机制的架构扩展到小型动作头之外,可以显著改善连续动作建模,并且归纳偏差中的自注意力机制与机器人行为的组合性完美契合。
核心挑战不在于架构的扩展,而在于 融合异构模态,同时保留其各自独特的属性。视觉、语言、本体感知在时间粒度、语义处理方面的需求各不相同,虽然为更丰富的情境创造了可能,但也存在削弱模态特定优势的风险。为了解决这个问题,诸如 M-DiT 之类的 token 空间对齐策略将不同的信号映射到统一的表示中,使条件扩散 Transformer 能够灵活地支持目标和观察的任意组合,这是迈向通用机器人技术的关键一步。
像 ForceVLA 这样的领域特定设计将 力感知 视为一流的模态,使用力感知混合专家将触觉反馈与视觉语言嵌入相结合,显著改善了接触丰富的操作。
最近的研究将 显式推理融入了扩散策略。Diffusion-VLA 引入了自生成推理模块用于生成符号表征;而 CogACT 则利用语义场景图统一了感知、推理和控制。
预训练模型 将图像编辑模型重新用于零样本操作和联合微调策略,例如 PERIA。通过 Chain-of-Affordance 进行的结构化分解和像 π0 这样的流程图方法在复杂环境中优于端到端方法。
综上所述,这些发展 Table.2 (B) 揭示了一个正在形成的领域,即 从单一的架构调整转向融合结构化推理、多感官输入和显性知识表征的认知启发式框架。这种转变标志着 机器学习正在超越纯粹数据驱动的端到端学习,转向更具解释性和泛化性的设计,尽管其进展仍然受到高计算需求和有限的数据集多样性的制约。

3.2.3 Application Optimization and Deployment in Diffusion-Based VLA
对于基于扩散的 VLA 系统而言,从实验室原型到实际部署的转变仍然是最艰巨的挑战之一。应对这一挑战需要在三个相互关联的方面取得进展:效率、适应性、稳健性。最近的研究表明,当下的进展取决于 优化策略、受认知启发的架构、部署机制,而 不是不加区分地扩大模型规模。
效率优化已成为核心议题。虽然扩散模型资源密集,但轻量级设计(例如 TinyVLA 和 SmolVLA)表明,经过参数高效调优的预训练主干网络(例如 LoRA)可以在不牺牲性能的情况下,将训练成本降低到单 GPU 规模,如 VQ-VLA 之类的补充策略,采用矢量量化动作分词器来缩小模拟与实际之间的差距,这说明了效率提升如何与鲁棒性相一致。这些研究反映了一种向“智能稀疏性”的范式转变,优先考虑每次计算的性能,而不是暴力扩展。
与此同时,任务适应性已成为先进 VLA 系统的一个决定性特征。在灵巧操作方面,诸如 DexVLG 之类的大规模精选数据集能够实现强大的零样本性能;而在移动操作方面,诸如 AC-DiT 之类的框架则通过从移动到身体的调节来统一感知和驱动。总体而言,趋势是在通用架构与深度领域专业化之间取得平衡,嵌入特定于任务的归纳偏差,同时保留广泛的多模态能力。
架构创新代表着下一个前沿领域。双系统 和 三系统 设计,例如 MinD 和 TriVLA 展示了如何在机器人技术中实现认知原理的运用。MinD 将用于规划的低频视频预测与用于反应控制的高频扩散策略相结合,而 TriVLA 则明确地将视觉语言推理、动态感知、策略学习分离为相互协调的模块。这些受认知启发的架构在交互频率(例如36Hz)下运行,不仅可以提升任务性能,还可以增强系统的可解释性和可维护性,这是工业部署的关键要求。
除了效率和设计之外,运行时鲁棒性 已成为现实世界应用的决定性因素。像 BYOVLA这样的轻量级干预策略,可以在推理时动态编辑不相关的视觉区域而无需进行微调,从而减轻了不可预测环境中的鲁棒性错误。同时,像 DreamVLA 这样的自反射架构引入了分层错误处理,并配备了推理增强模块、错误感知层和专家适配器。这些策略共同体现了向 “defensive AI” 的转变,强调弹性和可靠性,如同强调原始任务性能一样。
基于扩散的 VLA 系统扩张迅猛。在自动驾驶领域,Drive MoE 采用场景和技能专一化的专家组合,实现了最先进的闭环控制;而在人形机器人领域,DreamGen 利用视频世界模型,从单任务遥操作推广到数十种全新行为。EnerVerse 和 Vid Bot 扩展了这一范式,通过自回归视频扩散和可供性学习来预测具身未来,凸显了以视频为中心的世界模型在规划方面的潜力,这些进展表明了从 特定任务原型到多功能跨领域系统的转变。
对基础模型的研究进一步凸显了该领域的发展轨迹。FP3 引入了一个基于 60,000 条轨迹预训练的大规模 3D 策略模型,而 GR00T N1 将多模态 Transformer 架构集成到一个类人基础系统中。与自然语言处理中的大型语言模型一样,这些方法旨在 为机器人技术提供通用的先验知识,但它们也必须解决安全性、实时控制、物理可靠性等问题,这些挑战在基于文本的领域中并不那么突出。
泛化和微调策略对于推进基于扩散的 VLA 系统走向现实世界部署仍然至关重要。最近的研究突出了多个互补的方向:ObjectVLA 和 SwitchVLA 证明了开放世界对象操作和执行感知任务切换的可行性,强调了动态环境中的灵活性。与此同时,LangToMo 和 Evo 0 等方法引入了新颖的中间表示和几何感知插件模块,表明结构化感知先验可以显著增强跨任务的适应性。在优化方面,像 OFT 这样的系统性微调框架集成了 并行解码、动作分块 和 连续表示学习 等技术,将该领域从探索性的概念证明转向了工程学科。
总的来说,这些策略表明 实现稳健的泛化需要架构创新、高效的模型设计、自适应任务专业化、认知启发式架构以及稳健的运行时策略,如 Table.2 (C)所示。然而,挑战依然存在:安全关键场景的开发仍不充分。弥合这些差距对于从实验原型过渡到可靠的通用机器人系统至关重要。

扩散模型在 VLA 系统中的应用正朝着 更高效、更稳健 和 更通用的方向发展。从基础的动作生成建模到复杂的多模态融合和实际部署优化,一个全面的技术框架已经出现。尽管仍有一些问题需要解决,但 未来的发展趋势将继续致力于解决关键挑战,包括提升模型效率、提升泛化能力和优化实际部署性能。
3.2.4 Discussion
Innovations
基于扩散的模型从根本上将机器人控制重构为生成式建模问题。它们
支持概率动作生成、多模态架构融合以及受认知启发的部署策略,超越了确定性和模块化流程。这些方法改进了轨迹多样性、几何基础和推理集成。此外,TinyVLA 和 SmolVLA 等注重效率的设计使现实世界的部署越来越可行。
Limitations
然而,由于 动态环境中的时间相干性仍然脆弱,大规模扩散模型需要大量的计算资源和数据集,而且对抗性或不确定条件下的安全关键可靠性尚未得到充分探索。此外,虽然多模态融合丰富了表征,但它有可能削弱特定模态的优势,而领域专门化的适应性可能会降低可迁移性。应对这些挑战 需要更高效、更稳健的训练范式、更丰富的安全意识评估标准,以及基础规模建模与实际部署约束之间的更紧密结合。
3.3 Reinforcement-based Fine-Tune Models in Vision Language Action Research
3.3.1 Reinforcement-based Fine-Tune Strategies in VLA Research
基于强化学习的 VLA 方法将视觉语言基础模型与强化学习相结合,以增强感知、推理和决策能力。通过利用视觉和语言输入,这些方法能够在交互式动态环境中生成情境感知动作。它们已成为推动自动驾驶、机器人技术和更广泛的具身化人工智能系统发展的关键研究方向。最近的进展表明,基于强化学习的 VLA 方法可以融入人类反馈,适应新任务,并且优于纯监督学习范式。Table.3 总结了这些研究的进展。

早期方法利用大规模人类视频数据集或机器人操作数据集,通过 引入强化奖励策略来提升机器人的操作技能。这些方法旨在探究预训练 VLM 在强化学习中的可即时性,结果表明 即使是冻结的模型也能通过即时 embedding learning 支持高效的下游策略训练。VIP 推导出一个独立于动作的自监督目标条件价值函数,生成平滑的嵌入,并通过嵌入距离隐式地评估价值。
与其他强化微调方法类似,一些方法使用 语言和图像联合生成奖励 agent,并通过自监督对比训练获得跨模态状态语言表征。这些方法强调奖励感知表征的可迁移性,使其能够在稀疏奖励或复杂语言指令下的机器人学习中得到应用。
此外,一些方法主要通过 优化奖励函数或损失函数来改进策略学习。这些方法使用语言模型作为奖励函数设计的中介,通过人工演示和 VLM 语义映射来学习奖励 agent。这种方法简化了奖励工程,同时可以通过基于 RLHF 进一步优化泛化和可解释性。例如,Elemental 展示了在复杂操作任务中快速定制任务需求并从有限样本中高效学习的能力。SafeVLA 从安全角度探索了 VLA,解决了在开放环境中部署VLA的风险,提出了一种约束学习对齐机制,以防止高风险行为,同时保持任务性能。该方法将安全评论网络融入 VLA 架构中以估计风险水平,并采用 CPO 框架来最大化策略奖励,同时确保安全损失保持在低于预定阈值的水平。 SafeVLA 显著减少了多任务测试中的风险事件(包括操控、导航和处理),尤其是在模糊的自然语言指令增加策略不确定性的场景下,从而展现出卓越的安全性和稳定性。这项工作为在实际应用中部署 VLA 模型提供了重要的安全机制。
与前述机械臂 VLA 模型不同,研究人员还研究了用于四足机器人和人形机器人的 VLA 框架。这些机器人使用自然语言导航指令,重点关注轨迹预测、目标描述、避障及相关任务。例如,NaVILA 使用 single-stage RL 策略对 VLA 模型进行微调,以输出连续的控制命令,从而能够适应复杂地形并动态更改语言指令。相比之下,MoRE 将多个 low-rank 自适应模块作为不同的专家集成到一个密集 MLLM 中,形成一个稀疏激活的混合专家模型,随后使用强化学习目标将其训练为 Q-function。LeVERB 扩展了这一研究方向,提出了一个用于人形机器人全身控制 (WBC) 的分层 VLA 框架。与 NaVILA 类似,LeVERB 将视觉语言处理与动态级动作处理相结合,其中强化学习策略将潜在词汇转化为高频动态控制命令,从而实现复杂的全身任务执行。
离线强化学习已被证明能够有效地从混合质量数据集中构建稳健的策略模型。ReinboT 通过应用强化学习最大化累积奖励,预测能够捕捉操作任务细微差异的密集奖励,增强了对数据质量分布的理解,从而使机器人能够根据长期利益做出更稳健的决策。在线强化学习方法在 VLA 领域也得到了广泛的探索。例如,SimpleVLA-RL 仅使用单一轨迹和二元结果级别奖励 (0/1) 来训练 VLA 模型。该方法避免了对密集监督或大规模行为克隆数据集的依赖,但实现了与在环境中模拟基于规则的奖励信号的全轨迹监督微调 (SFT) 相当的性能。意识到仅使用离线或在线策略的局限性,ConRFT 引入了一种结合两者的混合策略。其离线策略将行为克隆与 Q-learning 相结合,从有限的演示中提取策略并稳定价值估计;而其在线策略则引入了一致性目标和人工干预机制,以稳步提升策略性能,确保整个训练过程中的安全探索和样本效率。
在自动驾驶领域,VLA 模型也利用强化学习来提升在未见过场景中的驾驶性能。AutoVLA 通过引入一个具备推理和行动能力的自回归生成模型来体现这一方向。它首先处理视觉输入和语言指令,然后应用推理微调来生成离散的、可行的动作,这些动作可以重构为连续的轨迹。该模型采用两个微调步骤:思维链推理 和 群体相关策略优化,实现了最先进的性能。
值得注意的是,与现有模型需要大量参数,从而导致计算和内存需求高昂不同,一些研究人员研究了 基于强化学习的 VLA 中的量化、剪枝和知识蒸馏等效率策略,这些策略通常与 PPO 等算法结合使用。例如,RPD 从 VLA 教师模型中提炼出学生模型以提高推理速度;而 RLRC 引入了一种新颖的压缩框架,该框架由结构化剪枝、基于 SFT 和强化学习的性能恢复以及量化组成。这些方法在保持原始 VLA 任务成功率的同时,减少了内存使用量,并提高了推理吞吐量。
3.3.2 Discussion
Innovations
基于强化学习的 VLA 策略微调利用视觉和语言信号生成密集且可迁移的奖励指标,并将离线行为克隆与在线强化学习相结合,从而稳定策略优化并增强泛化能力。以安全为中心的方法也代表了一项重要进步,它通过集成约束优化来减少开放世界部署中的高风险行为。此外,四足动物、人形机器人和自动驾驶任务的扩展,凸显了强化驱动的 VLA 在各种机器人实现中的多功能性。
Limitations
尽管取得了这些进展,基于强化学习的 VLA 工程的奖励通常仍然是间接的或嘈杂的,导致学习效果不佳;训练稳定性可能会受到监督微调和探索之间相互作用的阻碍;并且扩展到高维真实环境的计算成本高昂,需要大量的硬件和数据资源。此外,虽然已经提出了安全意识策略,但确保在模糊或对抗性指令下实现可靠的泛化仍然是一个悬而未决的挑战。解决这些问题需要更高效的奖励表示、稳健的样本高效训练范式,以及更丰富的评估基准,以兼顾安全性和推理能力。
3.4 Other Advanced Researches
虽然自回归、扩散和强化学习仍然是 VLA 模型设计的基础范式,但具体化任务日益增长的复杂性和多样性,促使人们开发出超越这些界限的方法。当前的研究进展可以分为五个关键方向:1. 融合多代范式的混合架构;2. 用于增强跨模态和空间理解的高级多模态融合;3. 应对特定任务挑战的专用领域自适应;4. 大规模统一感知-推理-控制的基础模型和大规模训练范式;以及 5. 强调效率、安全性和人机协作的实际部署策略。Table.4 总结了代表性工作。

3.4.1 Hybrid Architectures and Multi-Paradigm Integration
随着具身操作任务的多样性和复杂性不断增长,依赖单一生成范式(无论是自回归、扩散还是强化学习)往往显得力不从心。因此,混合架构应运而生,成为一种颇具前景的解决方案,它策略性地结合多种范式,以发挥其互补优势。这种方法的核心目标是 整合连续动作生成的流畅性和物理一致性、离散推理的精确性以及动态现实世界环境所需的适应性。如此一来,混合系统便为更强大、更通用的 VLA 模型奠定了基础。
一个代表性的例子是 HybridVLA,它将基于扩散的连续轨迹生成与自回归 token 级推理统一在一个 7B 参数框架中。该设计利用扩散过程来产生平滑且物理上连贯的运动,同时保留了自回归模型固有的上下文推理能力。受认知科学启发的双系统哲学也在最近的研究中得到了应用。Fast-in-Slow 通过将低延迟执行模块嵌入到速度较慢但认知更丰富的 VLM 主干中,实现了 Kahneman’s 双过程理论。这在保留高级推理能力的同时实现了实时响应。类似地,RationalVLA 通过可学习的潜在嵌入将视觉语言推理与低级操作策略相结合,使模型能够过滤掉不可行的命令并规划可执行的操作。
可扩展的混合设计也展现出巨大的潜力。基于 Transformer 的扩散策略表明,数十亿参数的架构可以有效地将扩散过程与注意力机制相结合,并通过捕捉更丰富的上下文依赖关系进行轨迹建模,超越了传统的 U-Net 设计。这一趋势预示着 下一代 VLA 系统将自回归 Transformer 嵌入到基于扩散的规划器中,从而实现更强的上下文感知能力以及更高质量的运动生成。
除了个别创新之外,Open Helix 等项目正在朝着混合 VLA 设计的系统化方向发展。通过大规模实证评估,OpenHelix 对集成策略中的替代推理-执行进行了基准测试,并提供了开源实现和设计指南。这一转变标志着该领域的成熟,促进了混合 VLA 开发的可重复性和标准化。Table.4 (A) 总结了这些工作的进展,其中概述了推动混合 VLA 架构的关键创新。

3.4.2 Advanced Multi-Modal Fusion and Spatial Understanding
在复杂环境中实现稳健的操作,需要的不仅仅是简单的跨模态对齐;它 需要能够捕捉细粒度语义和空间关系的结构化、任务感知的融合机制。最近的进展反映了一种决定性的转变,即从早期的 特征串联 转向 明确模拟几何、可供性和空间约束 的架构。这些进步正在推动 VLA 模型在非结构化、3D 感知的环境中实现更丰富的空间基础和更可靠的动作生成。
早期的研究,例如 CLIPort,通过将视觉处理分解为用于物体识别的 “what” 路径和用于动作定位的 “where” 路径。利用基于 CLIP 的表示,CLIPort 从成对的图像-语言输入中生成 pick-and-place heatmap,展示了结构化视觉推理在语言条件下操作中的优势。在此基础上,后续研究强调 3D 空间理解作为核心能力。VoxPoser 引入了由大型语言模型引导的可组合 3D value map,将指令解释分为基于体素化场景表示的目标理解和动作规划。这种模块化设计通过将语义解析与空间推理清晰地分离,增强了泛化能力。类似地,3D-VLA 将自回归语言建模与基于扩散的动作预测集成到一个生成式 3D 世界模型中,实现了感知、语言和动作模态的一致统一。
多视图感知的挑战已通过统一表征学习得到解决。RoboUniView 采用多视图 Transformer 模块融合时间和空间线索,与单视图基线相比,显著提升了对 3D 场景几何的理解。相比之下,BridgeVLA 将 3D 观测投影到多个 2D 视图中,并在统一的 2D heatmap 空间内预测动作,从而凸显了紧凑且基于空间的表征的效率。为了处理更苛刻的场景,出现了专门的空间推理方法。ReKep 通过关系关键点图建模时空依赖关系,在精度要求高的任务中表现出色。RoboPoint 预测突出显示可行交互区域的可供性图,为下游规划提供必要的感知先验。GeoManip 集成了符号几何约束,以指导动作生成,而无需针对特定任务进行再训练,从而实现了强大的非分布泛化能力。
综上所述,这些研究呈现出清晰的发展轨迹:从早期基于路径的二维融合,到统一空间基础、语义推理和动作生成的模块化三维感知架构。随着 VLA 系统越来越多地在不受约束的现实世界环境中运行,对几何和可供性进行明确推理的能力,仍将是实现稳健且可泛化操控的决定性因素。Table.4 (B)总结了这一进展。

3.4.3 Specialized Domain Adaptations and Applications
VLA 框架的多功能性使其能够扩展到具有独特感知、推理和控制挑战的特定具体领域。这些调整不仅验证了 VLA 的通用性,也揭示了特定领域成功所需的架构和算法修改。从安全关键型机器人到全数字化交互,这些创新展现了 VLA 流程对各种操作环境的适应性。
在自动驾驶等安全关键领域,CoVLA 提出了首个专为该领域量身定制的大规模 VLA 数据集,其中包含约 50,000 条涵盖不同城市场景的语言指令和驾驶轨迹视频配对。该研究展示了如何将视觉-语言推理与连续控制策略相结合,以实现导航和避险。
VLA 范式也已扩展到图形用户界面 (GUI) 交互,其中感知-动作循环在完全数字化的空间中运行。ShowUI 采用 vision–language–action 流水线来处理屏幕上的元素,并为点击、拖动和表单填写等操作生成控制序列。它在 GUI-Bench 上的出色表现凸显了 VLA 原理在非物理操作任务中的适用性。
类人机器人全身控制已成为另一个具有挑战性的领域。LeVERB 提出了一种分层架构,其中 视觉语言策略从运动演示中学习潜在动作词汇,而强化学习控制层则生成低级动态命令。这种双层设计弥合了语义与控制之间的鸿沟,实现了跨 150 多个任务的稳健模拟到现实迁移。同样,Helix 证明,单个统一的策略网络可以习得从物体操控到跨机器人协作等多种类人机器人行为,而无需针对特定任务进行再训练。
专门的改编也针对大规模机器人编排和移动操控。AutoRT 通过一个 observe–reason–execute 框架协调异构机器人队列,该框架将战略规划委托给 PaLM-E 和 RT-2 等 VLM;而 MoManipVLA 通过基于航点的轨迹生成和双层运动优化,将固定基座 VLA 模型迁移到移动操控设置。
其他领域特定创新则 融合了物理推理或特定任务的认知结构。基于物理的VLA 嵌入了用于估计稳定性和接触点的模块,从而改善了在复杂物理约束条件下的操作。CubeRobot 将双环 VisionCoT 和记忆流设计应用于魔方求解,在低复杂度和中等复杂度任务中实现了近乎完美的成功率,并在高难度场景中表现出色。
总体而言,这些领域驱动的调整体现了 VLA 架构的多功能性,以及定制感知-推理-控制流程以满足不同作战环境特定需求的重要性。它们也强化了 VLA 模型作为跨越物理、数字和混合环境的统一具身智能框架的潜力。Table.4 (C)总结了这些专门的调整,重点突出了使 VLA 系统能够在不同具身领域取得成功的架构和算法创新。

3.4.4 Foundation Models and Large-Scale Training
基础模型和大规模训练的兴起重塑了 VLA 研究的轨迹,使得能够跨任务、具体化和环境泛化的统一感知-推理-控制框架成为可能。通过利用海量多模态数据集和可扩展架构,该方向致力于构建具有广泛能力和高效适应能力的通用具体化智能体。大规模预训练正日益成为下一代 VLA 系统的支柱。近期的基础模型提供了机器人技术的系统性研究,涵盖视觉语言模型、策略模型以及用于操作、导航和规划的跨模态对齐技术,尤其侧重于 VLA 架构,将其划分为 感知对齐、策略生成 和 基于世界模型 的类别,同时确定了紧密集成的多模态界面的统一趋势。
大规模数据集对于实现基础规模的训练至关重要。DROID 贡献了超过 15 万条轨迹,涵盖 1000 多个物体和任务场景,并包含多模态标注,包括 RGB-D、语言、低维状态和环境标签。通用 General Flow 框架使用 3D 点轨迹作为可迁移的可供性表征,实现了从人类到机器人的跨领域技能迁移。ViSA-Flow 于从大规模人机交互视频中提取的语义动作流对生成模型进行预训练,只需对下游机器人学习进行少量调整。
为了提高效率和适应性,训练策略也得到了广泛的研究。Zhang 等人通过 2500 次推广实验分析了微调因素(包括动作空间、策略头设计和监督信号),为调整基础规模的 VLA 模型提供了实用指南;Chen 等人研究了将思路链推理融入具身策略学习,证明轻量级推理机制可以显著提升性能,推理速度比标准方法提高了 3 倍。
综上所述,这些努力表明,通用化具身智能体正朝着在海量多样化数据集上训练并具备模块化推理能力的方向发展。大规模预训练、高效自适应和可迁移可供性表征的结合,将基础级 VLA 模型定位为下一代机器人智能的支柱。Table.4 (D) 总结了该方向的代表性研究,重点突出了以数据为中心和算法方面的进步,这些进步推动了基础级 VLA 研究的发展。

3.4.5 Practical Deployment over Efficiency, Safety, and Human–Robot Collaboration
随着 VLA 模型从研究阶段过渡到实际应用,实际部署需要全面关注效率、稳健性和人机交互。实时推理、对对抗条件的适应能力以及无缝协作的工作流程,在动态、不可预测的环境中可靠运行至关重要。该方向将系统优化与安全性和适应性相结合,确保高容量模型在实践中保持有效性和可靠性。
面向效率的设计专注于 减少推理延迟、降低计算需求 以及 提高对资源受限平台的适应性。对于实时执行,RTC(Real-Time Chunking)在执行当前动作片段的同时预测即将发生的动作片段,从而实现连续的高频控制。EdgeVLA 消除了末端执行器预测中的自回归依赖关系,并结合了紧凑的语言模型,在性能损失最小的情况下实现了 6 倍的加速。同样,DeeR-VLA 采用动态提前退出机制,在达到置信度阈值后终止推理,从而降低了在线控制成本。
在适应过程中保持知识完整性已成为另一个优先事项。知识隔离的 VLA 模型解决了将专用模块集成到预训练 VLM 时出现的语义退化问题,并使用隔离策略来保持跨任务泛化能力。基于一致性的加速策略,例如 CEED VLA,应用一致性蒸馏和提前退出解码,实现了超过 4 倍的推理加速,同时通过混合标签监督减少了错误累积。轻量级多模态融合方法(例如 Robo Mamba)和跨领域适应方法(例如 ReVLA)进一步提高了可部署效率。
安全性和鲁棒性已成为部署准备的同等关键支柱。SAFE 利用 VLA 内部特征表示来检测跨多个任务的故障,并泛化到未见过的场景,从而实现主动干预。Cheng 等人通过物理漏洞评估程序 Physical Vulnerability Evaluation Procedures (PVEP) 进行的安全评估揭示了对抗补丁、基于排版的提示和分布偏移的漏洞,从而推动了对抗鲁棒感知控制流程的开发。Lu 等人以可解释性为重点的研究揭示了 VLA 隐藏层中对象、关系和动作的符号编码,为更透明的决策奠定了基础。自适应控制框架(例如 DyWA)通过联合建模几何、状态、物理和动作来进一步增强鲁棒性,以响应动态、部分可观察的条件。
人机协作研究探索了交互式学习循环,其中人类和 VLA 模型相互完善彼此的性能。Xiang 等人提出了协作框架,将有限的专家干预整合到 VLA 决策中,在丰富模型训练数据的同时,减少了操作员的工作量。Zhi 等人提出的闭环策略将 GPT-4V 感知与实时反馈控制相结合,以动态地适应环境变化。历史感知策略学习和以对象为中心的视觉提示方法(例如 CrayonRobo)增强了任务的扎实性和透明度。技能库 构建和 扎实掩码 方法则实现了可扩展、可重用的任务分解。相机空间策略设计(例如 cVLA)通过直接在二维图像坐标中预测轨迹路点,改进了从模拟到现实的迁移,使策略更加与具体化无关。Table.4 (E) 总结了实际部署的代表性方法,重点介绍了效率、安全性和人机协作方面的关键创新。

总而言之,VLA 系统的实际部署需要一种多方面的设计理念,同时兼顾 效率、安全性 和 协作适应 能力。实时推理优化、针对故障和对抗条件的鲁棒性以及人在环路改进策略的整合,为在现实环境中实现持久、可靠且交互式的机器人系统铺平了道路。
3.4.6 Discussion
Innovations
这些先进 VLA 突出了几项创新,这些创新共同扩展了 VLA 研究,使其超越了上一节的范围。混合架构 融合了推理和动作生成的互补范式,用于 3D 感知空间定位的高级多模态融合,以及将 VLA 原理扩展到自动驾驶、人形机器人控制和 GUI 交互等领域的领域适应。**基础模型 利用海量多模态数据集来构建日益通用的智能体,而面向部署的方法则强调效率、安全性和人机协作,以实现现实世界的适用性。
Limitations
然而,这些 混合系统仍然计算成本高昂,规模化难度大,多模态融合仍然难以应对嘈杂或不完整的现实世界输入。特定领域的适应性调整存在过度拟合狭窄场景的风险,而基础模型则需要大量的数据和资源投入。尽管部署工作前景光明,但在对抗性或动态条件下,其在鲁棒性、可解释性和可靠性方面仍然面临挑战。克服这些局限性需要更高效的训练策略、更广泛的评估标准,以及研究设计与实际部署之间更紧密的整合。
4. Datasets and Benchmarks
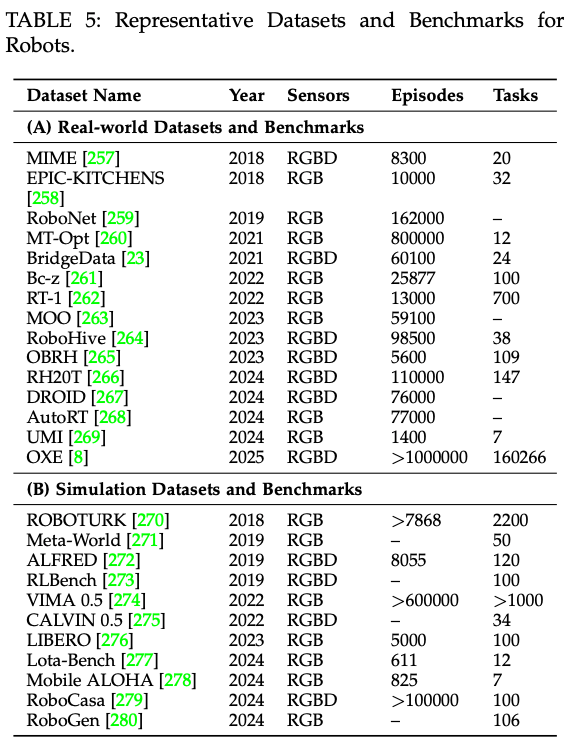
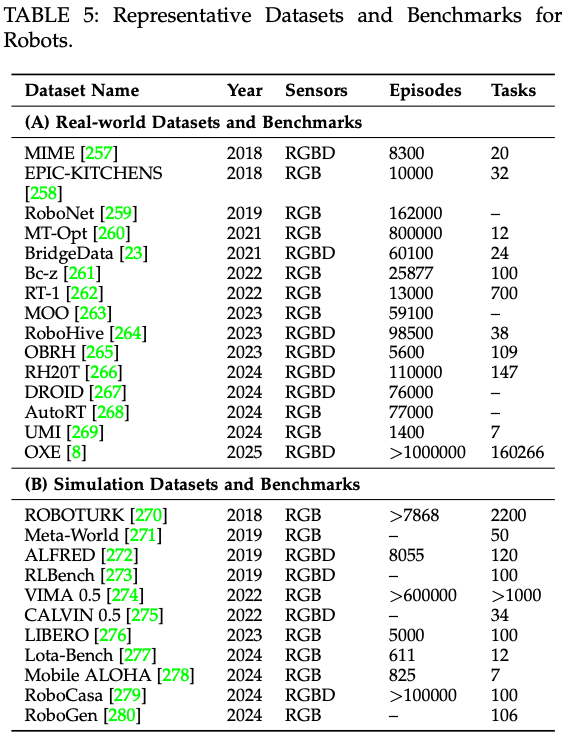
与其他模仿学习方法一样,VLA 模型依赖于高质量的带标签数据集。这些数据集要么从真实场景中收集,要么使用模拟环境生成,数据集样本如 Fig.4 所示。通常包含多模态观测数据(例如图像、激光雷达点云和惯性测量单元 (IMU) 读数),以及相应的真实标签和语言指令。为了便于系统理解,这里分析了现有的数据集和基准测试,并提出了一种根据数据集的复杂性、模态和任务多样性进行组织的分类法。该分类法提供了一个清晰的框架,用于评估不同数据集对 VLA 研究的适用性,并突出了现有资源中的潜在差距。代表性工作总结于Table.5。
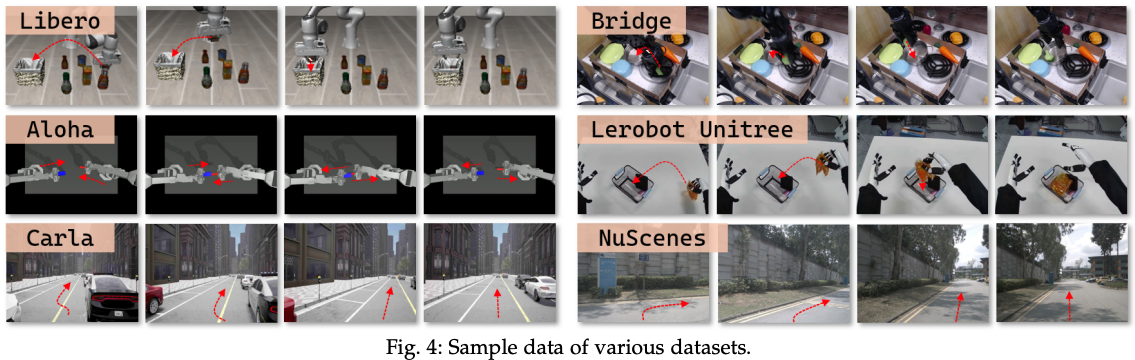
4.1 Real-World Datasets and Benchmarks
高质量的真实世界数据集是开发可靠的 VLA 算法的基础。近年来,已经收集了大量高质量且多样化的真实世界机器人数据集。研究人员使用不同的传感器模式,收集了各种任务和环境设置的数据集。
4.1.1 Real-World Datasets and Benchmarks for Embodied Robotics
现实世界具身机器人数据集是指从机器人获取的多模态数据集合,这些机器人通过感知和动作与其环境交互。具身机器人数据集专门用于捕捉视觉、听觉、本体感受和触觉输入与相应的运动动作、意图和环境情境之间的复杂交互。它们对于训练和评估具身人工智能中的模型至关重要,其目标是 使机器人能够通过动态环境中的闭环自适应行为执行任务。通过提供丰富的、时间上一致的观察和动作,这些数据集可作为开发和基准测试模仿学习、强化学习、视觉语言动作和机器人规划等算法的基础资源。
当前的具身机器人数据集面临着巨大的数据成本问题,因为现实世界的机器人数据收集工作并不广泛。收集现实世界的机器人数据集面临诸多挑战。它不仅需要硬件设备,还需要精确的操作。其中,MIME、RoboNet 和 MT-Opt 收集了涵盖一系列任务的大规模机器人演示数据集,从简单的物体推动到复杂的家用物品堆叠。与以往通常假设每个任务只有一个最优轨迹的数据集不同,这些数据集包含同一任务的多个演示,并使用测试轨迹之间的最小距离作为评估指标。这种方法极大地推动了操作和 VLA 任务的研究。BridgeData 提供了一个大规模、多领域机器人数据集,包含 10 个环境中的 71 个任务。实验表明,与单独使用目标领域数据相比,使用该数据集以及新领域中一小部分未见过的任务(例如 50 个任务)进行联合训练,可以将成功率提高一倍。因此,许多当代 VLA 方法都采用 BridgeData 进行模型训练。在具身人工智能领域,模型泛化通常受到收集多样化现实世界机器人数据困难的限制。RT-1 提供了一个广泛的现实世界机器人任务数据集,以提升任务性能和对新场景的泛化能力。同样,Bc-z 包含了以前未见过的、涉及同一场景中新物体组合的操作任务,支持可泛化的策略学习研究。一些数据集还为具身人工智能提供了全面的软件平台和生态系统,涵盖了诸如手部操作、运动、多任务处理、多智能体场景和基于肌肉的控制等环境。与早期研究相比,RoboHive 弥补了当前机器人学习能力与潜在增长之间的差距,支持包括强化学习、模仿学习和迁移学习在内的多种学习范式。RH20T 的独特之处在于,它提供了 147 个任务,涵盖 11 万个操作场景,包括多模态视觉、力、音频和动作数据。每个场景都配有人工演示和语言描述,这使得该数据集特别适合于一次性模仿学习以及基于先前训练场景向新任务的策略迁移。
为了推动更具泛化能力的操作策略的开发,机器人社区必须优先收集涵盖广泛任务和环境设置的大规模、多样化数据集。多个地区的多个机器人已经合作收集了多个数据集,使其成为迄今为止地理和环境多样性最丰富的具身机器人数据集之一。此外,Open X-Embodiment (OXE) 整合了 21 个机构合作收集的 22 个机器人数据集,涵盖 527 种技能和 160,266 项任务。OXE 提供标准化的数据格式,方便研究人员使用。这些数据集的概述如 Table.5 (A) 所示。
对于基准评估,研究人员通常使用成功率,一些研究还使用语言理解率来评估模型解释和执行语言指令的能力。此外,最近的 VLA 模型通常通过将训练好的策略迁移到之前未见过的环境中来评估,以衡量其鲁棒性和泛化性能。
4.1.2 Real-World Datasets and Benchmarks for Autonomous Driving
自动驾驶数据集不同于实体机器人数据集,已成为人工智能最具变革性的应用之一,高度依赖大规模数据集来训练和评估感知、规划和控制算法。高质量的数据集是开发稳健且可泛化的自动驾驶系统的基础,因为它们能够进行监督学习、基准测试以及对罕见或安全关键场景的模拟。在过去十年中,已经出现了许多数据集,它们提供了多模态传感器数据,包括摄像头图像、激光雷达点云、雷达信号和高清地图。这些数据集在地理覆盖范围、传感器配置、驾驶行为多样性和注释丰富度方面差异很大,因此它们可以作为研究和开发的补充资源。
然而,大多数公共数据集都是在开环环境中收集的,并且主要代表正常的驾驶行为,这限制了它们覆盖长尾极端情况的能力。为了弥补这一差距,最近的努力集中在生成合成数据、模拟闭环交互以及针对罕见或安全关键事件定制数据集。数据集设计的持续创新对于推进安全、可扩展和可推广的自动驾驶系统仍然至关重要。
为了进行评估,自动驾驶 VLA 模型通常依赖于 L2 距离等指标,该指标衡量与参考轨迹的偏差,以及完成率,该指标量化了成功完成的驾驶任务的比例。
4.2 Simulation Datasets and Benchmarks
为连续控制任务采集大规模真实世界数据面临着巨大的挑战,因为这些任务需要实时交互和来自人工注释者的持续反馈。此外,获取此类数据通常成本高昂且耗时,限制了其可扩展性。这为在大量问题实例上进行多样化人工监督提供了一种可扩展的机制。为了研究实体机器人或自动驾驶模型在大规模高质量数据中的表现,研究人员利用虚拟化引擎的模拟数据进行训练和评估。
4.2.1 Simulation Datasets and Benchmarks for Embodied Robotics
具身人工智能的模拟数据集通常包括合成场景、基于物理的交互、导航、对象操作、任务执行和代理环境动态的注释。这些数据集可用于对各种任务进行基准测试和训练,从视觉导航和语义探索到复杂的多步骤对象操作。每个数据集在真实感、任务多样性和控制保真度方面提供了不同的权衡。通过实现安全的实验和大规模数据收集,仿真数据集是开发稳健、可泛化的具身智能体的基础。随着该领域的成熟,设计更丰富、更逼真的模拟数据集,涵盖不同的具身、任务和环境,将继续推动其在现实世界的部署。
ROBOTURK 是一个高质量的六自由度操作状态和动作仿真数据集,通过使用移动设备进行远程操作收集。与依赖远程用户在虚拟引擎内演示动作的传统方法不同,ROBOTURK 利用策略学习来生成具有不同奖励的多步骤机器人任务。通过汇总大量演示,该数据集为训练和评估提供了精确可靠的数据。iGibson0.5 引入了一个用于训练和评估交互式导航解决方案的基准。这项工作不仅提供了一个新颖的实验模拟环境,还提出了一个专门的指标来评估导航路径上导航与物理交互之间的相互作用。该基准引入了交互式导航分数,它由两个子指标组成:路径效率和努力效率。路径效率定义为机器人成功路径的最短长度与实际路径长度之比,并由成功指标函数加权。努力效率捕捉导航过程中所需的额外运动学和动态努力,反映了物理交互的成本。VIMA 引入了一个新的基准 VIMA BENCH,建立了一个四级评估协议,以逐步评估更强的泛化能力,范围从随机物体放置到全新任务。类似地,CALVIN 和 LOTA-Bench 专注于使用多模态机器人传感器数据,在不同的操作环境中学习长视界、语言条件任务。这些基准特别适用于评估那些旨在通过在大规模交互数据集上训练并在新场景上测试来泛化到未知实体的方法。这些基准测试的性能通常以任务成功率来衡量。Table.5 (B)提供了这些仿真数据集的概述。
4.2.2 Simulation Datasets and Benchmarks for Autonomous Driving
闭环仿真在确保自动驾驶系统安全方面发挥着至关重要的作用,因为它能够生成现实世界中难以捕捉或危险的安全关键场景。虽然先前记录的驾驶日志为构建新场景提供了宝贵的资源,但闭环评估需要修改原始传感器数据,以反映更新的场景配置。例如,可能需要添加或删除参与者,并且现有参与者和自身车辆的轨迹可能与原始记录中的轨迹不同。UniSim 是一个神经传感器模拟器,可将单个记录的轨迹扩展为多传感器闭环仿真。它构建神经特征网格来重建静态背景和动态参与者,并将它们合成,以从新的视角模拟激光雷达和摄像头数据,允许添加、删除或重新定位参与者。为了更好地适应看不见的视点,UniSim 进一步采用了卷积网络来补充原始数据中不可见的区域。
与现实世界的自动驾驶数据集不同,闭环仿真基准测试需要针对交互式驾驶任务量身定制的评估指标。常用指标包括驾驶路线(衡量对规划轨迹的遵守情况)、违规评分(对交通违规行为的处罚)和完成评分(评估任务完成情况)。这些指标共同作用,可以更全面地评估 VLA 模型在现实的、安全关键型驾驶场景下的性能。
4.3 Discussion
Innovations
本文介绍了系统化的分类法、标准化的评估指标以及诸如 Open X-Embodiment (OXE) 等大规模协作成果。OXE 整合了来自多个机构的数据集,从而提高了可重复性和泛化能力。这些贡献使得任务覆盖范围更广、模态组合更丰富、跨领域策略迁移性能更佳,从而提升了具身化人工智能研究的可扩展性。
Limitations
然而,现实世界的数据集成本高昂,收集起来也极具挑战性,通常仅限于场景多样性有限的受控实验室环境;模拟数据集虽然可扩展且安全,但仍难以完全捕捉现实世界交互的复杂性、噪声和不可预测性。此外,成功率和轨迹偏差等基准指标可能不足以反映语言基础、长远推理或在非结构化环境中安全部署等细微能力。要解决这些限制,不仅需要扩展数据集的多样性和真实性,还需要设计更丰富的评估协议,以更好地捕捉现实世界自主性的需求。
5. Simulators
机器人模拟器已成为在多样化和交互式环境中开发和评估智能机器人系统不可或缺的工具。这些平台通常集成物理引擎、传感器模型(例如 RGB-D、IMU、LiDAR)和任务逻辑,以支持导航、操作和多模态指令跟踪等各种任务。最先进的模拟器提供可扩展、逼真且物理上合理的环境,用于使用强化学习、模仿学习或大型预训练模型来训练具身智能体。通过提供安全、可控和可重复的设置,具身模拟器加速了可泛化机器人智能的开发,同时显著降低了与现实世界实验相关的成本和风险。
THOR 是一款模拟器,具有近乎照片级逼真的 3D 室内场景,AI agent 可以在其中导航环境并与物体交互以完成任务。它支持多种研究领域,包括模仿学习、强化学习、操作规划、视觉问答、无监督表征学习、物体检测和语义分割。相比之下,一些模拟器基于虚拟化的真实空间而非人工设计的环境,包含数千座配备了实体代理的全尺寸建筑,这些实体 agent 受到现实的物理和空间约束。Habitat 和 Habitat 2.0 进一步扩展了这一范式,提供了可扩展的模拟平台,用于在具有交互式、物理支持的场景的复杂 3D 环境中训练实体代理。 ALFRED 引入了一个基准测试集,该基准测试集包含长视界、具有不可逆状态变化的组合任务,旨在弥合模拟基准测试集与实际应用之间的差距。ALFRED 同时包含高级目标和低级语言指令,这使得任务在序列长度、动作空间和语言多样性方面比现有的视觉和语言数据集更加复杂。
早期将物理和机器人任务相结合的仿真环境通常侧重于有限的场景,并且仅包含小规模、简化的场景。相比之下,iGibson 1.0 和 iGibson 2.0 是开源模拟平台,支持在大规模、逼真的环境中执行更多样化的家居任务。它们的场景是真实家居的复制品,物体的分布和布局与物理空间紧密结合,从而增强了生态效度并架起了桥梁。
MuJoCo 是一款广泛采用的开源物理引擎,旨在促进机器人技术及相关领域需要精确模拟的研究和开发。近年来,基于 GPU 的模拟引擎也越来越受欢迎,基于 Omniverse 平台构建的 NVIDIA Isaac Gym 能够在物理逼真的虚拟环境中大规模开发、模拟和测试 AI 驱动的机器人。Isaac Gym 在学术界和工业界都越来越受欢迎,因为它加速了新型机器人工具的开发并增强了现有系统。
自动驾驶领域也存在类似的挑战,大规模的真实世界数据收集和注释既昂贵又耗时。收集足够的数据来涵盖众多罕见的极端情况尤其困难。为了解决这个问题,研究人员开发了包含静态道路元素(例如交叉路口、交通信号灯和建筑物)和动态主体(例如车辆和行人)的模拟器。CARLA和 LGSVL 利用游戏引擎渲染逼真的驾驶场景,支持灵活的传感器配置,并生成适用于训练和评估驾驶策略的信号。这些平台通过提供可控、可重复且经济高效的测试环境,对于推进自动驾驶研究至关重要。
6. Robot Hardware
机器人的物理结构为其感知、运动、操控以及与环境交互奠定了基础。其核心组件通常包括传感器、执行器、动力系统和控制单元。传感器(例如摄像头、激光雷达、惯性测量单元和触觉阵列)提供有关外部环境和机器人内部状态的重要信息。执行器(包括电机、伺服系统或液压系统)将控制信号转换为物理动作,从而实现运动和物体操控等任务。控制单元通常基于嵌入式处理器或微控制器,作为计算核心,集成传感器输入并向执行器发出命令。动力系统通常以电池或外部能源的形式供电,以维持机器人的持续运行。硬件设计必须平衡性能、能效、重量和耐用性,以满足不同应用领域的特定任务要求,包括工业自动化、服务机器人和自动驾驶汽车。
7. Challenges and Future Directions
7.1 Challenges of Vision Language Action Models
本节总结了 VLA 模型发展面临的挑战和未来发展方向。尽管近年来取得了显著进展,VLA 模型的发展也逐渐暴露出关键瓶颈。最根本的问题在于,当前的 VLA 系统主要建立在大规模 LLM 或 VLM 的迁移之上。虽然这些模型在语义理解和跨模态对齐方面表现出色,但它们 缺乏与物理世界交互的直接训练和经验。因此,VLA 系统在实际环境中经常表现出“understanding the instruction but failing to execute the task” 的缺陷。这反映了一个根本性的矛盾:语义层面的泛化能力与物理世界中的具身能力之间的脱节。如何实现从非具身知识到具身智能的转化,并真正弥合语义推理与物理执行之间的差距,仍然是核心挑战。具体而言,这种矛盾体现在以下几个方面。
7.1.1 Scarcity of Robotic Data
机器人交互数据是决定 VLA 模型性能的关键资源;然而,现有数据集在规模和多样性方面仍然不足。在现实世界中,收集各种任务和环境的大规模演示数据受到硬件成本、实验效率和安全问题的制约。现有的开源数据集(例如 Open X-Embodiment)虽然具有先进的机器人学习能力,但主要 侧重于桌面操作和物体抓取。任务和环境多样性的缺乏严重限制了其在新情境和复杂任务中的泛化能力。RLBench 等仿真平台提供了一种经济高效的生成大规模轨迹的方法,但受到渲染保真度、物理引擎精度和任务建模的限制。即使采用了领域随机化或风格迁移等技术,模拟与现实之间的差距仍然存在,许多模型在模拟中表现良好,但在部署到实体机器人上时却失败了。因此,增强机器人数据的多样性和真实性仍然是缓解泛化缺陷的主要挑战。
7.1.2 Architectural Heterogeneity
大多数 VLA 模型尝试跨视觉、语言和动作进行端到端建模,但却表现出强烈的异构性。一方面,不同的工作采用不同的骨干网络:视觉编码器可能依赖于ViT、DINOv2 或 SigLIP;语言主干网络可能依赖于 PaLM、LLaMA 或 Qwen;而动作头则依赖于离散 token、连续控制向量,甚至基于扩散的生成。这种 架构多样性阻碍了跨模型的比较和重用,从而减缓了统一标准的出现。另一方面,感知、推理和控制通常内部松散耦合,导致特征空间碎片化,跨平台或任务域的可移植性较弱。一些模型擅长跨任务语言理解,但在与低级控制器交互时需要进行大量适配。这种架构异构性增加了集成复杂性,并显著限制了泛化和可扩展性。
7.1.3 Real-Time Inference Constraints and Cost
当前的 VLA 模型严重依赖于大规模带有自回归解码的 Transformer 架构,这严重限制了其在真实机器人上的推理速度和执行效率。由于每个动作 token 都依赖于前一个动作 token,因此延迟会累积,而诸如动态抓取或移动导航等高频任务则需要毫秒级的响应。此外,高维视觉输入和海量参数数量带来了高昂的计算和内存成本。许多最先进的 VLA 所需的 GPU 内存远远超出了典型嵌入式平台的容量。即使采用量化、压缩或边云协同推理,仍然难以在准确性、实时性和低成本之间取得平衡。推理约束和硬件瓶颈的结合使得 VLA 部署陷入了速度过慢和成本过高的困境。
7.1.4 Pseudo-Interaction in Human–Robot Interaction
基于先验知识或静态训练模式生成动作,而不是基于环境动态和因果推理进行真正的交互,当遇到不熟悉的设置或状态变化时,模型通常依赖于从数据中学习到的统计共现,而不是探测环境或利用传感器反馈来优化动作。这种因果推理的缺乏意味着 VLA 可能看似遵循指令,但却 无法在环境状态和动作结果之间建立真正的因果链。因此,机器人通常无法适应动态环境。这种伪交互凸显了 VLA 在因果建模和反馈利用方面的缺陷,并且仍然是实现具身智能的关键障碍。
7.1.5 Evaluation and Benchmarking Limitations
对 VLA 模型的评估也十分有限。当前的基准测试主要设定在实验室或高度结构化的模拟环境中,侧重于桌面操作或物体抓取。虽然此类任务衡量的是窄分布上的性能,但它们无法捕捉到开放世界场景下的泛化能力或鲁棒性。一旦部署到户外、工业或复杂的家居环境中,性能往往会急剧下降,暴露出评估结果与实际应用之间的差距。这种狭窄的评估范围阻碍了对 VLA 可行性的全面评估,并限制了不同模型之间的横向比较。缺乏统一、权威且多样化的基准测试,正成为现实世界进步的主要瓶颈。
虽然这五个方面凸显了数据、架构、交互和评估方面的关键缺陷,但它们并未穷尽 VLA 研究面临的挑战。长期问题是 VLA 系统能否真正实现可控性、可信度和安全性。换句话说,VLA 的未来不仅需要解决性能和泛化问题,还需要解决负责任地部署智能代理的更深层次问题。这种转变意味着研究人员必须超越模型优化,转向系统范式转变以应对长期挑战。
7.2 Opportunities of Vision Language Action Models
尽管面临严峻挑战,VLA 的未来也充满机遇。作为连接语言、感知和行动的关键桥梁,VLA 有潜力跨越语义与物理之间的鸿沟,成为具身智能的核心路径。克服当前的瓶颈,或许能够重塑机器人研究的范式,并使 VLA 走在现实世界部署的前沿。
7.2.1 World Modeling and Cross-Modal Unification
在目前的 VLA 系统中,语言、视觉和动作仍然松散耦合,使其局限于指令“生成”,而非整体的世界理解。实现真正的跨模态统一将使 VLA 能够在单个 token 流中对环境、推理和交互进行建模。这种统一的结构将使 VLA 演化为一个原型世界模型,使机器人能够完成从语义理解到物理执行的闭环。这不仅是技术进步,更标志着迈向通用人工智能的关键一步。
7.2.2 Breakthroughs in Causal Reasoning and Genuine Interaction
大多数现有的 VLA 依赖于静态数据分布和表层相关性,缺乏基于因果规律进行交互的能力。它们通过猜测先前的模式来模拟交互,而不是探索环境并通过反馈更新策略。如果未来的 VLA 能够结合因果建模和交互式推理,机器人将学会探索、验证和适应,从而实现与动态环境的真正对话。这样的突破将克服伪交互,标志着从数据驱动智能到深度交互智能的转变。
7.2.3 Virtual–Real Integration and Large-Scale Data Generation
数据稀缺固然是关键限制,但也蕴藏着巨大的机遇。如果能够 通过高保真模拟、合成数据生成和多机器人共享,将虚拟和现实数据生态系统整合起来,构建涵盖各种任务的数万亿条轨迹的数据集将成为可能。正如GPT利用互联网规模的语料库推动语言智能的飞跃一样,这样的数据生态系统可以推动具身泛化能力的飞跃,使VLA能够在开放世界场景中稳健运行。
7.2.4 Societal Embedding and Trustworthy Ecosystems
VLA 的最终价值不仅在于技术能力,更在于社会融合。随着 VLA 进入公共和家庭领域,安全性、可信度和道德一致性将决定其应用。建立标准化的风险评估、可解释性和问责框架,将使 VLA 从实验室产物转变为值得信赖的合作伙伴。一旦 VLA 融入社会,VLA 可以作为下一代人机交互界面,重塑医疗保健、工业、教育和服务等领域。这种社会融合标志着将前沿研究转化为现实世界变革的里程碑式机遇。
8. Conclusion
VLA 模型的最新进展已将其泛化能力扩展到机器人应用,包括具身化人工智能 (embodied AI)、自动驾驶和各种操控任务。本综述系统地概述了 VLA 方法的兴起,并考察了它们的动机、方法论和应用。它提供了统一的架构分类,并分析了 300 多篇文章及其支持材料。首先根据自回归模型、扩散模型、强化学习、混合结构和效率优化技术对 VLA 架构创新进行分类;随后,探索了用于 VLA 训练和评估的数据集、基准测试和模拟平台。在此全面综述的基础上,分析了当前方法的优势和局限性,并重点指出了未来研究的潜在方向。总的来说,这些见解为开发值得信赖、持续进化的 VLA 提供了综合的参考和前瞻性的路线图,从而能够推动机器人系统中通用人工智能的发展。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)