《VLA 系列》OpenVLA-OFT | 并行解码 | 连续动作 |VLA动作解码方法对比
OpenVLA-OFT:高效并行解码的连续动作生成方案 传统OpenVLA采用自回归解码和离散动作表示,存在效率低、精度差等问题。OpenVLA-OFT通过三大改进优化性能: 并行解码:将自回归改为单次前向传播生成动作分块,显著提升推理效率; 连续动作表示:直接输出连续动作向量,避免离散化带来的精度损失; L1回归目标:替换交叉熵损失,提升训练收敛速度和动作精度。 对比其他方法(如扩散建模和流匹配
原始OpenVLA的训练方案是:自回归解码 + 离散动作 + 下一个token预测,这是为了适配VLM预训练范式的妥协性设计,导致了效率低、精度差、无法适配高频控制的问题。
OpenVLA-OFT 核心改进点设计:
- 解码方式:从自回归 → 并行解码(突破效率瓶颈,让动作分块落地)
- 动作表示:从离散 → 连续动作(提升精度,兼容并行解码)
- 学习目标:从下一个token预测 → L1回归(兼顾训练收敛速度与推理效率)
论文地址:Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
开源地址:https://github.com/moojink/openvla-oft
本文不单分析OpenVLA-OFT,还分析了动作解码方式对比(自回归 vs 并行)、动作表示形式对比(离散 vs 连续),以及自回归、扩散建模、流匹配的VLA动作解码方法对比。
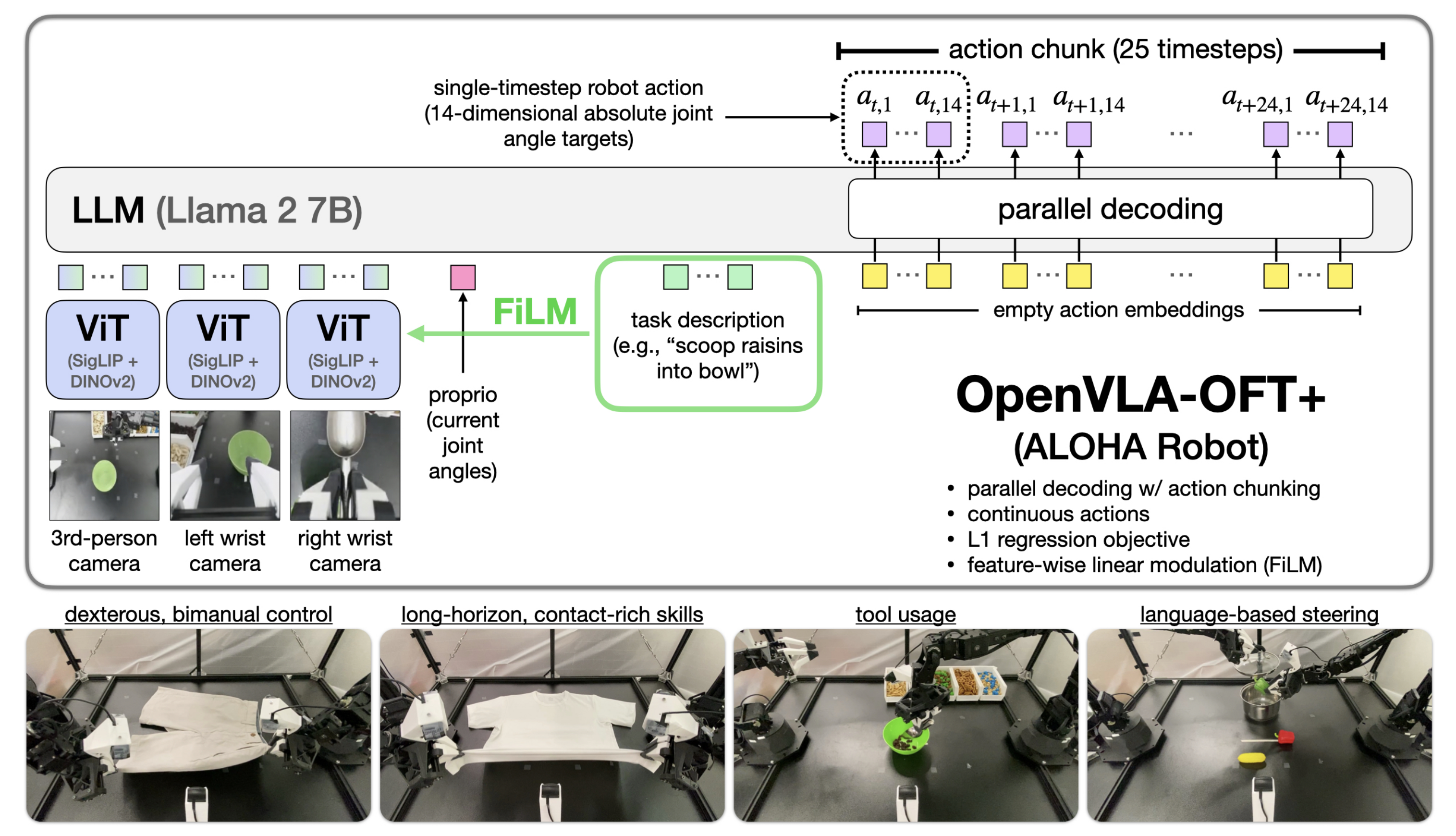
1、模型架构
如下图所示,展示了OpenVLA-OFT 的核心流程:
-
多模态输入采集
3路相机视觉信号(第三人称全局+双腕相机)、14维机械臂关节本体状态、自然语言任务指令 -
视觉编码与FiLM语言编码
- 多视角图像经ViT(SigLIP+DINOv2)提取视觉特征
- 语言嵌入生成参数γ/β,通过FiLM仿射变换,将语言信息融合进视觉特征
-
多模态特征融合
调制后视觉特征、本体状态、语言特征投影至统一嵌入空间,拼接为多模态序列,输入LLM主干
-
LLM双向注意力建模
基于Llama 2 7B主干,替换自回归因果注意力为双向注意力,完成多模态信息的语义与时序依赖建模 -
并行解码+动作分块输出
输入空动作嵌入,单次前向传播 并行生成25步14维连续动作分块,以L1回归为学习目标保证动作精度 -
机械臂实时控制执行
动作序列驱动ALOHA双机械臂,完成灵巧双臂操作、长程接触任务、工具使用、语言引导控制等落地场景
OpenVLA 与 OpenVLA-OFT的对比分析:
| 优化组件 | 对应流程环节 | 解决的核心痛点 |
|---|---|---|
| 并行解码+动作分块 | 解码输出层 | 自回归解码延迟高、无法适配高频控制 |
| 连续动作+L1回归目标 | 解码输出层 | 离散动作精度不足、动作细节丢失 |
| 多模态输入融合 | 特征处理层 | 原始模型仅支持单相机输入、无法适配双臂多视角场景 |
原始OpenVLA的训练方案是:自回归解码 + 离散动作 + 下一个token预测,这是为了适配VLM预训练范式的妥协性设计,导致了效率低、精度差、无法适配高频控制的问题。
而OFT方案通过重新选择两大核心设计维度:
- 解码方式:从自回归 → 并行解码(突破效率瓶颈,让动作分块落地)
- 动作表示:从离散 → 连续动作(提升精度,兼容并行解码)
- 学习目标:从下一个token预测 → L1回归(兼顾训练收敛速度与推理效率)
原本仅能在低频单臂机器人上运行的 OpenVLA,经过 OFT + 方案优化后,成功适配了 25Hz 高频控制的双机械臂 ALOHA 平台。
2、VLA动作解码方法对比:OpenVLA、OpenVLA-OFT、扩散建模、流匹配
这四种方法代表了VLA动作解码的不同技术路线,核心差异体现在解码机制、学习目标、训练/推理效率、性能特点上。下面从核心维度展开对比:
1. 核心机制与解码逻辑
| 方法 | 核心机制 | 解码方式 | 关键特点 |
|---|---|---|---|
| OpenVLA(原始) | 自回归生成 + 离散动作令牌 | 逐帧生成动作,每个动作严格依赖前一动作的输出(因果注意力) | 与VLM预训练范式天然兼容,但效率极低,无法适配高频控制 |
| OpenVLA-OFT | 并行解码 + 动作分块 + 连续动作 | 单次前向传播生成整个动作分块(如25步),无迭代步骤,采用双向注意力 | 直接预测连续动作值,完全抛弃自回归和迭代生成,是效率优先的方案 |
| 扩散建模 | 正向噪声注入 + 反向去噪迭代 | 自回归或并行生成,但推理需多次前向传播(如50步去噪) | 学习预测动作上的噪声,通过反向去噪逐步生成动作,表达性强但效率低 |
| 流匹配 | 学习从简单分布到目标分布的流映射 |
可并行生成,推理仅需1步或少量前向传播(如1-10步) | 学习“流函数”,直接映射简单分布(如高斯)到目标动作分布,是扩散的改进版 |
2. 学习目标与训练特点
| 方法 | 学习目标 | 训练复杂度 | 收敛速度 | 对演示噪声的鲁棒性 |
|---|---|---|---|---|
| OpenVLA(原始) | 下一个token预测(交叉熵损失):预测离散动作令牌的下一个值 | 低,仅需适配VLM的语言建模目标 | 中,依赖预训练权重 | 弱,离散化会放大噪声影响 |
| OpenVLA-OFT | L1回归:最小化预测动作与真实动作的L1距离 | 极低,仅修改输出层和注意力掩码 | 极快,数小时内收敛 | 中等,可平滑噪声但难以捕捉多模态分布 |
| 扩散建模 | 噪声预测:学习从噪声动作恢复真实动作 | 高,需设计噪声调度、去噪步骤,训练不稳定 | 慢,需数天训练,易过拟合 | 强,能捕捉多模态动作分布,处理演示噪声能力强 |
| 流匹配 | 流函数学习:最小化流函数与目标分布的差异 | 中,比扩散简单但比L1复杂 | 中,比扩散快,训练更稳定 | 强,可捕捉多模态分布,鲁棒性接近扩散 |
3、动作解码方式对比(自回归 vs 并行)
动作解码方式对比(自回归 vs 并行),如下图所示:
1. 自回归解码(Autoregressive Decoding)
- 机制:LLM逐一生成动作,每个动作的生成严格依赖前一个动作的输出(单向因果注意力),形成“动作1→动作2→…→动作N”的链式生成过程。
- 特点:
- 优点:能充分利用动作序列的时序依赖关系,理论上表达性更强。
- 缺点:推理效率极低——生成K步动作需要K次前向传播,延迟随动作步数线性增加,完全无法适配机器人25-50Hz的高频控制需求;同时,动作分块会进一步放大延迟,导致性能优势无法落地。
- 原始OpenVLA的选择:自回归解码是原始方案的核心,也是其效率瓶颈的根源。
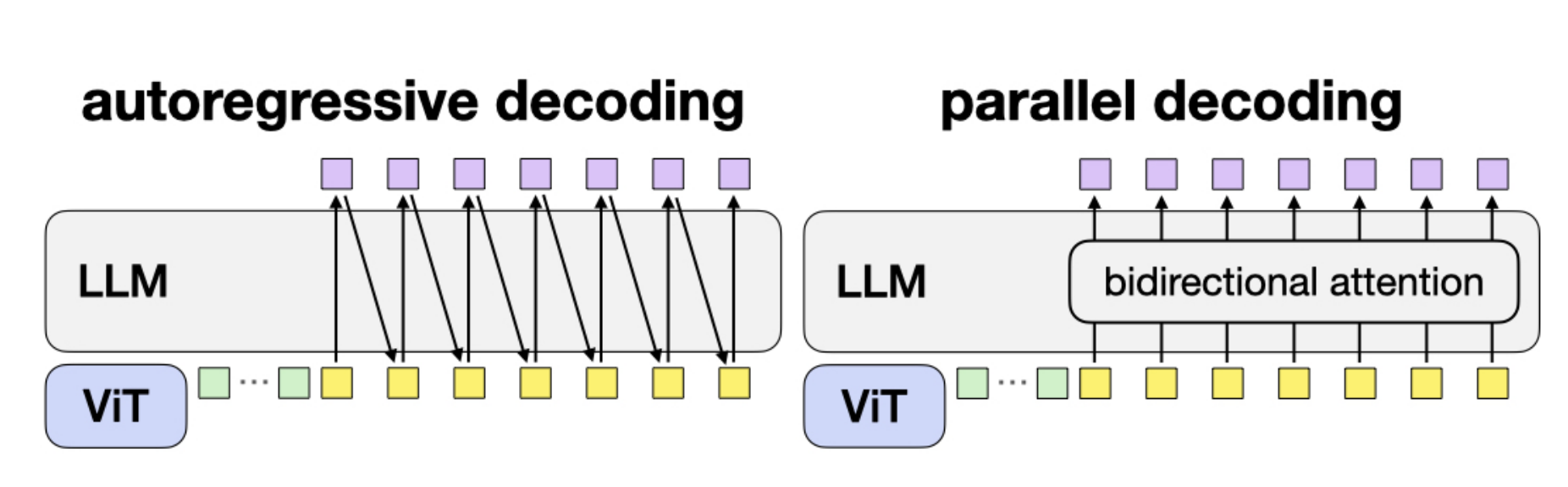
2. 并行解码(Parallel Decoding)
- 机制:移除因果注意力掩码,采用双向注意力,LLM通过单次前向传播,一次性生成所有动作(输入空动作嵌入,无需依赖前序动作)。
- 特点:
- 优点:
吞吐量呈线性提升(生成K步动作仅需1次前向传播),延迟几乎不随动作步数增加,适配动作分块技术,让性能优势落地;同时提升了模型对多模态输入的兼容性。 - 缺点:理论上表达性略弱于自回归(无法利用前序动作的时序信息),但后续实验证明,这种损失可被效率和分块带来的性能增益完全覆盖。
- 优点:
- OFT方案的选择:并行解码是OFT突破效率瓶颈的核心组件。
4、动作表示形式对比(离散 vs 连续)
动作表示形式对比(离散 vs 连续),如下图所示:
1. 离散动作(Discrete Action)
- 机制:将连续的机器人动作(如关节角、末端位姿)离散化为固定数量的令牌(如256-bin),通过下一个token预测(交叉熵损失)训练,输出为离散令牌序列(如
128 132 14 ...)。 - 特点:
- 优点:与预训练VLM的语言建模范式天然兼容,无需修改核心架构。
- 缺点:离散化过程会牺牲精细动作细节,导致动作精度下降;且与自回归解码深度绑定,进一步限制了效率。
- 原始OpenVLA的选择:离散动作+下一个token预测是原始方案的基线,也是其动作精度不足的原因。
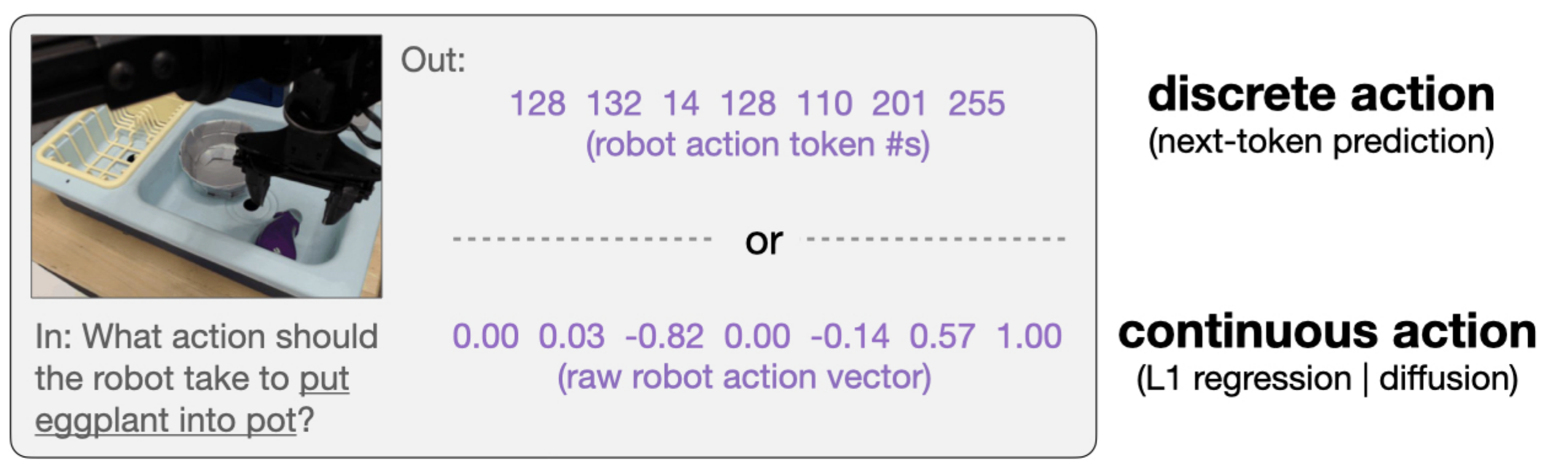
2. 连续动作(Continuous Action)
- 机制:用MLP动作头替代离散嵌入层,直接输出归一化的连续动作向量(如
0.00 0.03 -0.82 ...),通过L1回归或扩散建模训练。 - 特点:
- 优点:保留了动作的精细特征,提升预测精度;与并行解码完全兼容,推理无额外步骤(L1回归),效率更高。
- 缺点:需要修改模型输出层,且扩散建模会增加训练/推理成本(L1回归则无此问题)。
- OFT方案的选择:连续动作+L1回归是OFT兼顾精度与效率的关键选择。
5、OpenVLA-OFT 与 流匹配 深入分析
OpenVLA-OFT和流匹配在表面上确实高度相似:都支持并行解码、都能一次性预测一整个动作分块(多个连续动作)、都能摆脱自回归解码的延迟瓶颈。
但两者的底层生成逻辑、学习目标、推理本质、能力边界完全是两条技术路线,核心差异可以用一句话先概括:
OpenVLA-OFT是「一步算出确定的最优动作」的确定性回归模型;流匹配是「一步生成合理动作分布样本」的生成式概率模型。
5.1、根上的区别:底层生成逻辑完全不同
这是所有差异的源头,哪怕两者都是“一次出多个动作”,但“怎么出的”本质完全不一样:
1. OpenVLA-OFT的并行解码:直接算“标准答案”
OFT的核心是L1回归任务,它的逻辑和你做数学题直接写最终答案一模一样:
- 模型学习的是「视觉+语言指令+机器人本体状态」到「专家演示的动作序列」的直接映射;
- 推理时,一次LLM前向传播,直接输出它认为的唯一、确定的最优动作分块(比如25步关节角),没有任何中间过程、没有概率分布的概念,就是“输入→输出”的一步到位。
2. 流匹配的并行解码:先学“所有合理答案的规律”,再生成一个样本
流匹配的核心是生成式分布建模,它的逻辑和你“从一堆优秀范文里学写作规律,再自己写一篇合格的作文”一模一样:
- 模型学习的不是某一个固定的专家动作,而是所有能完成任务的合理动作的概率分布(比如“舀葡萄干可以从左边下勺,也可以从右边下勺,都是合理的”);
- 它学的是「从简单的高斯噪声分布,到真实动作分布的连续映射流」,哪怕是1步并行推理,本质也是通过学的“流函数”,把一个随机噪声,映射到动作分布里的一个合理样本。
5.2、训练、推理、效率完全不同
根上的逻辑差异,直接导致了两者在VLA微调、机器人部署时的实际表现差异:
1. 训练目标与难度天差地别
| 维度 | OpenVLA-OFT | 流匹配 |
|---|---|---|
| 核心训练目标 | L1回归损失:最小化「模型预测动作」和「专家演示动作」的绝对值差,目标就是无限贴近专家的标准答案 | 流匹配损失:最小化「模型预测的向量场」和「真实最优传输向量场」的差异,目标是学好动作的整体分布规律 |
| 训练复杂度 | 极低:只需要专家演示的动作序列,不需要额外处理,和普通大模型微调逻辑一致,代码极简 | 极高:需要给每个样本加时间步、加噪声、设计向量场,要处理微分方程的拟合,训练逻辑复杂,调参难度大 |
| 收敛速度 | 极快:论文里几十到15万步就能收敛,单卡几小时就能跑完 | 慢:需要几十万步才能收敛,哪怕用多卡也要数天,且训练稳定性不如OFT |
| 小数据集友好度 | 极强:哪怕只有20条演示(比如论文里的叠短裤任务),也能稳定拟合,不容易过拟合 | 极弱:需要大量演示数据才能学好分布,小数据集下分布学不准,很容易过拟合,生成的动作完全不合理 |
2. 推理效率:哪怕都是1步,延迟和吞吐量也不一样
你可能会问:都是一次前向传播出结果,效率还能有区别?
答案是:有,而且差距很大,核心是流匹配有额外的计算开销:
- OpenVLA-OFT的推理:纯纯的1次LLM前向传播,没有任何额外计算。输入视觉+语言+空动作嵌入,一次前向直接输出动作,计算量就是LLM本身的一次前向,没有任何多余开销。
论文里的实测:7.5B参数的OFT+,在A100上吞吐量77.9Hz,延迟0.0128秒,完美适配25Hz的ALOHA机器人。 - 流匹配的推理:哪怕是1步“快速推理”,本质也是「1次前向传播+微分方程求解」。模型的输出不是动作本身,而是“流场的向量”,需要通过欧拉法/龙格-库塔法解常微分方程(ODE),才能得到最终的动作。哪怕是1步求解,也有额外的计算开销,输出头设计也比OFT的MLP头复杂。
论文里的实测:3.3B参数、用JAX极致优化的流匹配模型π0,吞吐量才勉强超过7.5B的OFT+,同参数量下,OFT的效率是流匹配的2-3倍。
6、模型效果
如下图所示,在四项 ALOHA 操控任务中,对从零训练的策略(ACT、Diffusion Policy)与微调后的 VLA(RDT-1B、π₀、OpenVLA-OFT+)进行对比。

分享完成~

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)