从“看懂”到“行动”: VLM 与 VLA
从“看懂”到“行动”: VLM 与 VLA
我们的目标是让机器(如自动驾驶汽车、机器人)能像人一样在物理世界中智能地行动。要实现这一目标,机器必须解决两个核心问题:
- 我看到了什么,当前情况是怎样的? (Perception & Reasoning)
- 基于当前情况,我下一步该怎么做? (Decision & Action)
VLM (视觉语言模型) 和 VLA (视觉语言动作模型) 正是分别解答这两个问题的关键技术。
第一层:VLM - 让机器拥有“带注释的眼睛”
VLM 的核心任务是将视觉信号(像素)与人类语言(语义)进行深度对齐,让机器不仅“看到”,更能“看懂”。
1. 起点:AI 如何“看”世界?—— 从像素到“词汇”
计算机看到的图片只是一堆像素矩阵(RGB值),它本身不包含任何意义。为了让 AI 理解,我们必须将这些原始信息转化成它能处理的“词汇”或“概念”,这个过程叫做嵌入 (Embedding)。
- 传统方法 (CNN): 卷积神经网络通过层层叠加的滤波器提取特征,比如从边缘、角点到物体的轮廓。但这是一种高度概括的、间接的理解方式。
- 现代核心技术 (Vision Transformer - ViT): Transformer是近年来 AI 领域的颠覆性技术。ViT 的做法更直接、更强大:
- 图像分块 (Image Patching): 将一张图片像切披萨一样,切成若干个固定大小的小方块(Patches)。
- “视觉词汇”化: 每个小方块被展平并线性映射成一个向量(一串数字),这个向量就成为了一个“视觉词汇 (Visual Token)”。
现在,一张完整的图片就变成了一系列“视觉词汇”组成的“句子”。
2. 核心机制:如何“理解”图像句子?—— 注意力机制 (Attention)
有了“视觉句子”,AI 如何理解其中哪些部分更重要?答案是注意力机制 (Attention Mechanism)。
- 工作原理: 注意力机制会计算句子中每个“词汇”与其他所有“词汇”之间的关联强度。当模型分析某个区域(某个 Patch)时,它会“特别关注”图像中与该区域最相关的其他部分。
- 举例: 当模型看到一个轮胎的 Patch 时,注意力机制会引导它高度关注车辆的其他部分(车灯、车窗),而不是背景里的树木或天空。这使得模型能够理解物体内部以及物体之间的结构关系,形成对场景的整体认知。
3. 终点:如何连接“看”与“说”?—— 多模态融合 (Multimodal Fusion)
VLM 的精髓在于,它不仅处理视觉,还同时处理语言。
- 语言的“词汇”化: 同样地,一个自然语言句子(如 “A cat is sitting on the mat”)也被分解成词汇 (Tokens),每个词汇也通过 Embedding 变成一个向量。
- 进入“共同思考空间”: 模型将“视觉词汇”和“语言词汇”投影到一个共享的高维向量空间(Shared Embedding Space)中。在这个空间里,模型通过海量数据训练,学会了将“看起来像猫的像素集合”所对应的视觉向量,与“cat”这个词的语言向量拉到极近的位置。
- VLM 的产出: 当你给 VLM 一张图,它内部已经将其转化为了富含上下文关系的视觉向量。此时你再提问(语言向量),模型就能在这个“共同思考空间”里进行检索、推理,并生成最匹配的答案(语言)。
VLM = (图像分块 + 语言分词) → 统一向量化 → 通过注意力机制理解各自上下文 → 在共享空间中对齐、融合 → 实现视觉问答、场景描述等深度理解任务。
第二层:VLA - 赋予机器“行动的灵魂”
VLA 的核心任务是在 VLM 理解世界的基础上,直接输出可执行的物理动作。
1. 范式革命:为何需要 VLA?—— 从“模块化”到“端到端”
传统自动驾驶系统像一个瀑布流,由多个独立模块串联而成:感知模块 → 预测模块 → 规划模块 → 控制模块
- 弊端:
- 信息损失: 每个模块只输出下一个模块需要的信息,大量原始的、丰富的细节(如行人微妙的身体姿态)在传递中丢失了。
- 错误累积: 感知模块的一个小错误,可能会在后续模块中被不断放大。
- 协同困难: 各个模块独立优化,难以实现全局最优。
VLA 采用的是端到端 (End-to-End) 架构:
- 工作原理: 它是一个单一的、庞大的神经网络。输入端是传感器原始数据(如摄像头图像),输出端直接就是车辆的驾驶指令(如方向盘转角、加速度)。
- 类比: 传统方法像一个严格按照菜谱分步做菜的新手;端到端模型则像一位经验丰富的大厨,他看一眼食材,就能凭借直觉和经验,行云流水地完成整道菜。
- 优势: VLM 提供的强大世界理解能力,使得这种“直觉”成为可能。模型可以直接从像素中,挖掘出与最终驾驶决策最相关的深层联系,避免了中间环节的信息损失和错误累积。
2. 核心技术:如何做出“高质量决策”?—— 概率式动作生成
现实世界充满不确定性。路口等待的行人,可能向前冲,也可能继续等待。因此,只预测一种“最优路径”是极其危险的。
- 问题: 如何生成既安全又覆盖多种可能性的动作?
- 前沿方案:扩散模型 (Diffusion Models)
- 起点 (加噪): 想象一下,我们有一组专家司机开出的“完美轨迹”。我们不断地往这些轨迹上添加随机“噪声”,直到它们变成完全无序的混乱状态。模型学习的是这个“从有序到无序”的逆过程。
- 终点 (去噪生成): 在真实决策时,模型从一堆完全随机的噪声点出发,在 VLM 对当前环境的理解(例如,“前方有行人,路况湿滑”)的引导 (Guidance) 下,一步步地将噪声去除,最终“雕刻”出一条或多条清晰、平滑、且符合当前路况的驾驶轨迹。
- 核心优势 (多模态预测): 由于去噪过程的随机性,每次运行,模型都可以生成一条略有不同但同样合理的轨迹。这使得 VLA 能够同时输出多种可能性(如“方案A:减速让行”、“方案B:轻微绕行”),并评估各自的概率,从而在不确定性中做出更鲁棒、更安全的决策。
VLA = VLM 的深度理解能力 + 端到端架构 + 概率式动作生成器 (如扩散模型)。它直接将“看懂了什么”转化为“具体怎么动”,并能同时考虑多种未来可能性。
- VLM 是“大脑皮层”: 负责高级认知、推理、理解和语言。它告诉你:“那是一个红灯,旁边有个推婴儿车的行人正在等待。”
- VLA 是“小脑+运动神经”: 负责将大脑的意图,转化为精确、协调的肌肉动作。它接收到大脑的指令后,立刻计算出需要踩下多深的刹车、保持多大的方向盘角度,才能平稳地在停车线前停下。
VLA 的终极形态,将是在内部构建一个可以模拟物理世界的“沙盒”,即世界模型。在做出实际动作前,AI 可以在这个脑内世界里“预演”不同决策的后果(“如果我加速会怎样?如果我变道会怎样?”),从而选择最优策略。这是实现通用人工智能 (AGI) 和完全自主机器人的关键一步。
VLA 从“理解”到“执行”的技术跨越
如果说 VLM 是让机器拥有了聪明的“眼睛和大脑”,那么 VLA 就是为这台机器装上了反应敏捷的“小脑和四肢”。VLA 的核心使命,是将 VLM 产生的丰富世界理解,转化为在物理世界中精准、合理、安全的动作序列。
下面,我们将从 “为何要用”、“如何构成”、“怎样行动” 和 “如何学习” 四个层面,彻底解构 VLA。
一、 VLA 的核心思想:端到端 (End-to-End) 的行动哲学
VLA 的出现,首先是一场思想上的革命,即从“模块化”转向“端到端”。
-
传统模块化系统 (The Assembly Line):
- 流程:
感知 → 预测 → 规划 → 控制。这就像一条汽车装配线,每个工位(模块)只负责自己的任务,然后将半成品交给下一个人。 - 弊端: 感知模块识别出车辆后,可能只传递“一辆车,位置X,速度Y”给预测模块,而这辆车是老旧的货车还是崭新的跑车、司机是否在左顾右盼等丰富的视觉细节,在传递过程中被大量丢失。这种信息损耗导致后续的决策是基于一个被“阉割”过的世界信息做出的。
- 流程:
-
VLA 端到端系统 (The Master Artisan):
- 流程:
传感器输入 → VLA 模型 → 驾驶指令。这更像一位经验丰富的工匠,他从观察一块木料(原始传感器数据)开始,脑海中就已经构思好了最终成品的样子,并直接动手(输出驾驶指令),整个过程一气呵成。 - 核心优势: VLA 能够学习到像素和最终动作之间那些难以用规则描述的隐性关联。比如,它能直接从“前方车辆刹车灯周围像素的微妙闪烁”直接关联到“我应该以何种平滑曲线减速”这一动作,而无需经过“识别刹车灯→判断减速意图→规划减速路径→执行刹车”的僵硬流程。
- 流程:
简而言之,端到端让决策过程更直接、信息保真度更高,从而实现更像“人类直觉”的驾驶行为。
VLA 的内部构造:一个“决策大脑”是如何运作的?
一个典型的 VLA 模型,虽然表面看是一个整体,但其内部依然有清晰的逻辑分工,我们可以将其理解为三大部件:
[输入感知] → [编码与推理核心] → [动作解码器]
-
输入感知层 (Sensory Input):
- 这是 VLA 的“感官”,负责接收最原始的世界数据。主要是来自多个摄像头的高清视频流,有时也会融合激光雷达 (LiDAR) 的点云数据、毫米波雷达信号等,力求 360 度无死角地感知环境。
-
编码与推理核心 (Encoder & Reasoning Core):
- 这是 VLA 的“大脑”,其核心通常就是一个强大的 VLM。
- 视觉编码器 (Vision Encoder): 利用 Vision Transformer (ViT) 将输入的视频流分解成时序的“视觉词汇”序列,并通过注意力机制理解画面中的物体、场景以及它们的动态变化。
- 多模态融合: 在这里,纯粹的视觉信息会与其他关键信息进行融合,形成更全面的“情境认知”。这些信息包括:
- 语言指令: 例如,用户通过语音说“在下一个路口左转”或“帮我找一个停车位”。
- 自身状态: 车辆当前的速度、加速度、方向盘角度等。
- 导航信息: 高精地图提供的道路结构、限速、交通规则等。
- 融合后的信息形成一个高维的“思想向量 (Thought Vector)”,它代表了 VLA 在这一瞬间对“我是谁、我在哪、周围发生了什么、我的目标是什么”的全部理解。
-
动作解码器 (Action Decoder):
- 这是 VLA 的“小脑和神经系统”,是整个架构的点睛之笔。它的任务是将抽象的“思想向量”翻译成具体、连续、可执行的物理动作。这是 VLA 最具挑战也最关键的部分。
解码“行动”:如何生成一连串驾驶指令?
动作解码器的主流技术,经历了从简单到复杂、从确定性到概率性的演进。
-
方法一 (早期探索): 直接回归 (Direct Regression)
- 做法: 将“思想向量”直接通过一个简单的全连接神经网络,输出一个确定的数值,如“方向盘转 15.3 度,油门踩 25%”。
- 缺点: 过于僵硬,无法应对现实世界的不确定性。它只能给出一个“它认为最优”的答案,如果判断失误,后果不堪设想。
-
方法二 (序列化生成): 自回归模型 (Autoregressive Model - “动作GPT”)
- 思想: 将复杂的驾驶行为分解成一连串的动作“词汇”,例如
[token_steer_5, token_accel_10, token_hold_0.5s, ...]。 - 做法: 像 GPT 生成文本一样,模型根据当前的“思想向量”和已经生成的动作,预测下一个最可能的动作词汇。
- 优点: 能够生成连贯、复杂的长时序动作序列。
- 缺点: 容易产生“一步错,步步错”的累积误差,且本质上还是在寻找一条单一的最优路径。
- 思想: 将复杂的驾驶行为分解成一连串的动作“词汇”,例如
-
方法三 (前沿主流): 扩散模型 (Diffusion Model - “概率式雕塑家”)
- 思想: 与其预测一个“唯一”的未来,不如生成一个“充满可能性的未来分布”,然后从中选择。
- 做法:
- 从混沌开始: 模型从一堆完全随机的动作点(代表无限的可能性和完全的不确定性)出发。
- 在理解中雕琢: 以 VLA 大脑产生的“思想向量”作为强力引导,模型开始一轮轮地“去噪”,逐步将随机点向“合理”和“安全”的轨迹上约束。就像一位雕塑家,看着模特的脸(环境理解),将一块粗糙的石头(随机噪声)雕刻成精美的人像(最终轨迹)。
- 输出多种未来: 由于去噪过程的内在随机性,每次运行都可以生成略有不同但都同样合理的轨迹方案。例如,面对前方慢车,它可以同时生成“方案A:保持安全距离跟车”和“方案B:打灯、加速、变道超车”两条轨迹,并附上各自的置信度。
- 核心优势: 这种多模态预测 (Multi-modal Prediction) 能力完美契合了现实驾驶的复杂性和不确定性,为决策提供了极大的安全冗余和灵活性。
训练 VLA:AI 如何从“新手”成长为“老司机”?
如此强大的模型,需要通过海量数据进行训练,主要方式有两种:
-
核心基础:模仿学习 (Imitation Learning)
- 也称为行为克隆 (Behavioral Cloning)。这是 VLA 最主要的训练方式。
- 流程: 收集数百万甚至上亿公里的人类专家驾驶数据,这些数据包含了在各种天气、路况和交通场景下的视频和对应的驾驶操作(方向盘、油门、刹车)。
- 目标: VLA 模型的目标就是,当输入和人类司机当时看到的画面相同时,其输出的驾驶指令要与人类司机的操作无限接近。本质上,就是让 AI 模仿成千上万个“老司机”的行为。
-
未来方向:强化学习 (Reinforcement Learning)
- 流程: 在高度逼真的模拟环境中,让 VLA “自由发挥”。通过设置奖励和惩罚机制(如:平稳驾驶得奖励、发生碰撞受惩罚、高效到达目的地得高奖励),让 AI 在不断的试错中,自我探索和学习,从而发现可能比人类更优的驾驶策略。
- 挑战: 模拟环境与现实世界的差距 (Sim-to-Real Gap) 以及安全验证是当前的主要难题。
VLA 并非单一技术,而是一个集大成的系统。它以端到端为核心哲学,采用 “编码-解码” 的内部架构,利用 VLM 的强大能力对世界进行深度理解和推理,最终通过 扩散模型 等先进的生成技术,将抽象的理解转化为具体的、概率性的、多模态的动作序列。而这一切,都建立在对海量人类专家数据进行 模仿学习 的基础之上。
端到端自动驾驶的核心概念
- 定义:端到端自动驾驶(End-to-End Autonomous Driving)是一种直接从传感器输入(如摄像头、激光雷达)生成控制指令(如转向、加速)的模型架构,取代传统的模块化方法(如分步实现感知、预测、规划)。其核心目标是实现输入到输出的端到端优化,提升系统的鲁棒性和效率。
- 发展背景:2024年,E2E+VLM(Vision-Language Model)双系统架构的成功,推动端到端成为智驾量产的核心算法。2025年,VLA(Vision-Language-Action)概念兴起,结合大语言模型(LLM)和视觉模型,成为技术迭代的新方向。
- 优势与挑战:
- 优势:减少模块间误差累积、提升实时性、适应复杂场景。
- 挑战:需融合多领域知识(如BEV感知、扩散模型、强化学习),模型可解释性低,安全验证难度高。
端到端技术流派分类
端到端自动驾驶根据架构设计分为两类主要流派:二段式端到端和一段式端到端,后者进一步细分为多个子领域。核心区别在于是否保留中间表示层:
-
二段式端到端:
- 核心思想:保留感知与规划的分离,但通过统一模型实现端到端训练。感知模块输出中间特征(如物体检测、场景表示),规划模块基于此生成控制指令。
- 代表算法:
- PLUTO:经典方法,用模型实现自车规划,强调感知特征到规划指令的端到端映射。
- CarPlanner(CVPR’25):优化规划模块的泛化能力,适用于动态环境。
- Plan-R1:最新工作,融合强化学习提升规划鲁棒性。
- 优缺点:易于集成现有感知模块,但规划模块依赖感知输出,可能引入误差。
-
一段式端到端:
- 核心思想:不保留中间表示,直接从输入生成控制指令,实现真正的端到端优化。分为四个子领域:
- 基于感知的一段式:
- 直接融合感知特征(如BEV表示)生成规划。
- 代表算法:UniAD(奠基工作,统一感知与规划)、VAD(地平线方案,优化实时性)、PARA-Drive(CVPR’24,引入多任务学习)。
- 基于世界模型的一段式:
- 利用世界模型预测环境动态(如障碍物运动、场景演化),增强规划可靠性。
- 代表算法:OccWorld(基于占据栅格的世界模型)、Drive-OccWorld(AAAI’25)、OccLLaMA(复旦团队,结合LLM)。
- 基于扩散模型的一段式:
- 采用扩散模型生成多模态轨迹,解决环境不确定性。
- 代表算法:DiffusionDrive(扩散模型生成多模轨迹)、Diffusion Planner(工业界应用)、DiffE2E(吉大工作,端到端优化)。
- 基于VLA的一段式:
- 结合视觉-语言-动作模型(VLA),利用大语言模型理解场景语义,生成控制指令。
- 代表算法:ORION(小米方案,VLA推理)、OpenDriveVLA(慕尼黑工大)、ReCogDrive(最新工作,增强场景理解)。
- 基于感知的一段式:
- 优缺点:端到端优化更彻底,但训练复杂度高,需大量数据。
- 核心思想:不保留中间表示,直接从输入生成控制指令,实现真正的端到端优化。分为四个子领域:
关键算法框架与技术细节
- UniAD(基于感知):统一感知与规划模块,使用Transformer架构处理BEV特征,输出直接控制指令。核心创新是多任务损失函数。
- DiffusionDrive(基于扩散模型):扩散模型生成多条候选轨迹,通过条件采样适应多模态场景(如路口变道),提升安全边界。
- ORION(基于VLA):集成视觉编码器、语言模型(LLaVA)和强化学习模块,实现语义场景理解(如交通规则)到动作生成。
- OccWorld(基于世界模型):构建3D占据栅格世界模型,预测长期环境变化,用于闭环仿真和规划。
核心背景知识
端到端自动驾驶依赖多领域技术,关键背景包括:
- Transformer与视觉模型:基础架构,用于处理时序数据;视觉Transformer(ViT)提取图像特征。
- BEV感知:鸟瞰图表示,支持3D检测、车道线识别、障碍物预测,是端到端输入的基石。
- 扩散模型:生成模型,用于多模轨迹输出(如Diffusion Planner),通过去噪过程处理不确定性。
- 强化学习:特别是RLHF(Reinforcement Learning from Human Feedback)和GRPO(Guidance-Regularized Policy Optimization),用于VLA模型的微调,提升决策安全性。
- 多模态大模型:如CLIP(图像-文本对齐)、LLaVA(视觉-语言模型),支撑VLA方向的场景理解。
技术趋势与应用
- 趋势:VLA成为主流方向,融合扩散模型(多模轨迹)和世界模型(环境预测),提升系统上限;工业界聚焦量产落地,如实时性优化、安全验证。
- 应用价值:掌握核心技术可应用于自动驾驶算法开发,包括感知-规划一体化设计、多模轨迹生成、语义场景理解等,推动L4级自动驾驶发展。
Orbis:解决长时域驾驶预测问题(弗莱堡大学)
- 核心问题:现有驾驶模型在长时预测(如转弯场景)中表现不佳,预测轨迹容易偏离实际。
- 技术方案:提出“连续自回归世界模型”,核心是流匹配(Flow Matching)方法。
- 通俗解释:模型像“时间旅行者”一样,基于当前驾驶状态(如车速、位置),连续预测未来多秒的场景(如6秒后的转弯路径)。它使用数学上的“流匹配”技术,让预测更平滑、更连续,避免了传统方法(如离散建模)的跳跃错误。
- 关键创新:
- 设计混合tokenizer:兼容离散和连续预测,公平比较不同方法。
- 发现连续建模优于离散建模:尤其在转弯等复杂场景,轨迹精度更高。
- 成果:在nuPlan数据集上,预测误差大幅降低(FVD降至132.25),转弯精度提升47%。
LaViPlan:解决语言-视觉-动作错位问题(ETRI团队)
- 核心问题:自动驾驶中,语言指令(如“左转”)、视觉输入(摄像头画面)和实际动作(车辆控制)常不匹配,导致路径规划错误。
- 技术方案:基于可验证奖励强化学习(RLVR) 的框架。
- 通俗解释:AI通过“奖励机制”学习:先用语言指令生成路径计划,然后用强化学习检查计划是否可行(如是否碰撞)。如果可行,给奖励;不可行,则调整。这就像教练教新手司机:先给指令,再根据实际驾驶结果反馈修正。
- 关键创新:
- 规划导向指标:确保语言指令转化为安全动作。
- 高效训练:比传统方法用更少数据,硬案例(如复杂路口)泛化能力更强。
- 成果:在ROAD数据集上,轨迹预测误差降低15-20%(如Easy场景降19.91%)。
世界模型场景生成:解决事故预测数据稀缺问题(澳门大学团队)
- 核心问题:真实事故数据少,难训练模型预测潜在风险。
- 技术方案:世界模型驱动的生成框架 + 增强动态图卷积网络。
- 通俗解释:用AI“造”虚拟事故场景(如模拟碰撞),丰富训练数据。核心是“世界模型”,它像游戏引擎一样生成逼真驾驶画面;再结合图网络分析车辆间关系(如谁可能追尾),预测事故。
- 关键创新:
- 领域知识引导:用视觉语言模型提取事故特征(如雨天打滑),确保生成场景真实。
- 自适应时间推理:处理瞬态事件(如突然刹车),提升鲁棒性。
- 成果:在DAD数据集上,事故预测精度达83.2%(提升7%),预警时间提前9.1%。
ReAL-AD:实现类人驾驶决策(上海科大&港中文)
- 核心问题:自动驾驶决策太机械,缺乏人类的分层思考(如先定战略再行动)。
- 技术方案:视觉语言模型(VLM)驱动的三层决策框架(战略-战术-操作)。
- 通俗解释:模仿人类驾驶思维:
- 战略层:决定大方向(如“避开拥堵区”)。
- 战术层:细化行动(如“变道超车”)。
- 操作层:执行控制(如方向盘角度)。
- 用视觉语言模型理解环境(如识别障碍物),将语言指令融入决策。
- 关键创新:
- 战略推理注入器:基于VLM生成高层策略。
- 战术推理整合器:将策略转为可执行计划。
- 分层轨迹解码器:逐步输出控制指令。
- 成果:在nuScenes数据集上,规划误差降33%,碰撞率降32%,安全分数提升至41.17。
- 通俗解释:模仿人类驾驶思维:
- 共同目标:提升自动驾驶的准确性、安全性和适应性。
- 技术趋势:
- 预测优化:Orbis和场景生成框架通过高级建模(流匹配、世界模型)解决长时预测和数据瓶颈。
- 人机对齐:LaViPlan和ReAL-AD强调语言与视觉融合,让AI决策更“人性化”。
- 高效训练:均采用生成式方法(如合成数据、强化学习)减少对真实数据的依赖。
- 通俗类比:这些技术让自动驾驶像“老司机”一样:预测未来路况(Orbis)、听懂指令并安全执行(LaViPlan)、模拟危险场景练手(场景生成)、分层思考决策(ReAL-AD)。
模块1:环境感知(核心方向)
- 2D/3D目标检测
- 涵盖Anchor-based/Free、单/双阶段检测、YOLO系列优化、小目标及误检消除技术。
- 多模态感知融合
- 数据级/特征级/目标级融合方案,侧重视觉-激光雷达-毫米波雷达跨模态协同。
- BEV(鸟瞰图)感知
- LSS方案、Cross Attention机制、轻量化BEV模型及预训练方法。
- Occupancy Networks
- 3D空间占据预测、开集识别、自监督Occupancy及NeRF结合方案。
- 专项感知任务
- 车道线检测(磨损/遮挡处理)、鱼眼相机泊车感知、目标跟踪(滤波关联/端到端模型)。
模块2:定位与建图
- 多传感器标定
- 相机-激光雷达-毫米波雷达离线/在线标定、时间同步技术。
- SLAM技术栈
- 视觉/LiDAR/毫米波SLAM、高精地图构建与定位方案。
- 在线高精地图
- 实时地图生成与更新关键技术。
模块3:决策与规划
- 轨迹预测
- 基于机器学习/强化学习的行人/车辆行为预测、多模态轨迹生成。
- 规划控制
- 行车/泊车/机器人运动规划算法(如优化控制、行为克隆)。
- 端到端自动驾驶
- 可解释性模型、模仿学习与大模型驱动方案。
模块4:模型部署与加速
- 计算优化
- TensorRT/NCNN部署、模型量化/剪裁、CUDA加速技术。
- 边缘计算
- 轻量化模型设计(如BEVFusion优化)。
模块5:前沿技术探索
- 大模型应用
- 通用大模型与垂直领域(自动驾驶)适配方案。
- NeRF/Gaussian Splatting
- 神经渲染技术在环境建模中的应用。
- V2X车路协同
- 多车协同感知与决策框架。
- 强化学习
- 自动驾驶场景下的策略优化。
- 数据集
- KITTI、Waymo、A2D2等30+开源数据集整合。
- 算法工具库
- 2D/3D检测标定工具、仿真环境(CARLA等)。
- 学习路径
- 覆盖感知/定位/预测/控制等方向的30+技术路线图。
- 论文与课程
- CVPR/ECCV等顶会论文解读;相机标定、Apollo系统等实战课程。
- 感知误检:多传感器冗余校验、时序滤波。
- BEV轻量化:知识蒸馏、模型剪枝。
- 部署瓶颈:TensorRT算子优化、INT8量化。
- 数据闭环:自动标注与仿真数据生成。
- 基础层:掌握传感器原理(相机/雷达)、经典算法(滤波/检测)。
- 核心层:深入BEV/Occupancy等工业级方案,强化多模态融合能力。
- 系统层:贯通感知-定位-规划全栈技术,熟悉端到端部署流程。
- 前沿层:跟踪大模型、NeRF、V2X等创新方向。
- VLA模型的核心概念:VLA模型是一种人工智能技术,旨在让机器人通过单一学习框架整合视觉感知(如摄像头图像)、自然语言理解(如人类指令)和具身控制(如机械臂动作)。这使机器人能在非结构化环境中(如家庭或工厂)执行复杂任务,例如抓取物体或导航,而无需依赖预设规则。
- 综述目的:研究人员理解如何从数据生成到真实机器人部署。解决具身智能(即机器人通过与物理世界交互学习)的挑战,例如在动态环境中实现安全自主操作。
- 关键背景:具身智能强调机器人通过感官输入(视觉、触觉)和动作反馈形成闭环学习,这是实现通用人工智能的关键。然而,开发VLA模型依赖于大规模、多模态数据(如视频、语言指令和动作序列),但真实数据收集成本高,因此仿真平台(如Habitat或Isaac Gym)成为重要补充,能高效生成合成数据。
VLA模型架构
- 基本架构范式:VLA模型采用端到端框架,将视觉输入(如图像)、语言输入(如指令)和机器人状态(如关节位置)编码后,融合生成控制命令(如末端执行器速度)。典型架构包括三个并行编码器:
- 视觉编码器:处理图像或视频帧,生成特征表示。常用技术包括基于Transformer的ViT(Vision Transformer)或基于CNN的ResNet,目的是提取空间和上下文信息(例如,CLIP或DINOv2模型用于对齐视觉和文本)。
- 语言编码器:处理自然语言指令(如“拿起杯子”),生成文本嵌入。流行模型包括LLaMA、T5或GPT系列,支持高级理解和零样本推理(即模型在未训练过的任务上也能工作)。
- 动作解码器:将融合后的特征转换为机器人动作。常见方法有基于扩散的策略(通过迭代去噪生成平滑动作序列)或自回归Transformer(逐步预测动作),输出是连续控制信号(如速度或扭矩)。
- 架构趋势:模型分类显示以下模式:
- 视觉编码器多使用CLIP或SigLIP增强的ViT,以提升视觉-文本对齐。
- 语言编码器以LLaMA家族为主,强调泛化能力。
- 动作解码器偏好基于扩散的Transformer(如Octo模型),因为它能处理复杂动作分布。
- 数据依赖:模型常训练在私有或公共数据集(如Open X-Embodiment),但挑战包括如何统一tokenization(分词)处理异质输入(如图像块和文本词),以及如何实现跨机器人泛化(即模型适应不同硬件)。
- 关键创新:如RT-2模型通过互联网规模数据预训练,实现零样本迁移;OpenVLA提供开源模块化设计,便于微调。
VLA训练数据集
- 数据集格式:数据集组织为多模态流,便于训练:
- 视觉流:存储RGB图像、视频、深度图或分割掩码,格式如JPEG或HDF5包。
- 语言流:包含自然语言指令(如任务描述),存储在JSON或文本文件中。
- 动作/控制流:包括动作标签(如“移动”指令)或连续控制向量(如关节位置),存储为NumPy数组。
- 数据集通常按“情节”(episode)组织,每个情节对应一个任务序列(如抓取-放置),确保模态同步。
- 主要数据集:关键公共数据集:
- Open X-Embodiment:整合22个机器人平台的500多个任务数据,支持跨实体泛化。
- DROID:利用人类标注和机器人视频,结合复杂操作场景。
- 其他示例:ALFRED(用于指令跟随)、Ego4D(以自我为中心的视觉流)、Kaiwu(多模态丰富,含触觉和音频)。
- 基准分析:数据集通过二维框架评估:
- 任务复杂性:量化任务难度,基于动作数量、技能多样性(如不同子任务数量)、顺序依赖程度(如任务步骤是否严格排序)和语言抽象水平(指令复杂度)。公式计算复杂性分数(归一化到1-5分),例如Kaiwu数据集得高分(高复杂性)。
- 模态丰富度:评估感官多样性,包括模态数量(如视觉、深度、语言)、信号质量、时间对齐精度和推理支持(如对象掩码)。分数归一化到2-5分,丰富数据集如TLA(含触觉)得高分。
- 关键发现:当前数据集大多集中在中等复杂性(如导航或简单操作),但缺乏高复杂性任务与丰富模态的结合(如长时间跨任务+多传感器),这限制了VLA模型的泛化能力。
仿真工具
- 作用与重要性:仿真平台(如AI2-THOR或NVIDIA Isaac Sim)高效生成大规模、标注丰富的数据,弥补真实数据不足。它们提供可编程环境(如不同光照、物体类型),支持模仿学习或强化学习。
- 平台分类:主要仿真器包括:
- 导航导向:如Habitat或AI2-THOR,支持RGB和深度模态,用于数据集如R2R。
- 操作导向:如PyBullet或MuJoCo,专注物理交互和接触反馈(如力/扭矩信号),用于DexGraspNet数据集。
- 大规模RL导向:如Isaac Gym或Gazebo,支持多机器人协调和GPU加速。
- 新兴平台:如Unity ML-Agents,强调高效数据生成和语言接口。
- 核心能力:仿真器支持自动标注(如对象姿态、语言指令),但面临挑战:物理准确性不足(如简化接触模型导致现实迁移问题)、视觉真实性 vs. 吞吐量权衡(高保真渲染降低速度),以及缺乏标准语言接地API(需自定义管道)。
应用与评估
- 应用领域:VLA模型分为六类:
- 操作与任务泛化:如抓取或装配,模型如RT-2实现跨任务零样本迁移。
- 自主移动:如导航,模型将语言指令转为运动计划。
- 人类辅助与交互:如协作任务或GUI自动化,强调安全性和响应性。
- 特定平台:针对硬件(如四足机器人)优化。
- 虚拟环境:用于游戏或模拟基准。
- 边缘部署:轻量级模型(如Pi-0)在低功耗设备运行。
- 模型评估:基准测试聚焦操作泛化能力。关键模型包括:
- RT-2:高成功率(≥90%)和零样本泛化,真实验证。
- Pi-0:轻量高效,中等泛化能力。
- 其他代表:如OpenVLA(开源匹配性能)、Octo(大规模扩散策略)、TLA(首个语言-触觉模型)。
- 评估指标:成功率(任务完成度)、零样本能力(未训练任务表现)、真实机器人验证。趋势显示:大型模型(如RT-2)强调预训练和规模,模块化系统(如CLIPort)提升特定任务稳健性。
挑战与未来方向
- 架构挑战:
- 分词与对齐:统一处理异质输入(如图像和文本)困难,导致跨模态注意力退化。未来需可学习分词器(如向量量化)。
- 模态融合:简单连接特征弱化视觉接地。方向包括动态融合块(基于任务重加权模态)。
- 跨实体泛化:模型难适应新机器人。解决方案如硬件特定适配器。
- 运动平滑性:动作轨迹不稳健。扩散策略(如Diffusion Policy)是趋势。
- 数据集挑战:任务多样性不足(缺长视距任务)、模态不平衡(如缺深度或触觉)、注释成本高、真实性 vs. 规模差距。未来需混合仿真-真实管道和自监督标注。
- 仿真挑战:物理不准确(如软体变形)、视觉-吞吐量权衡、语言接口非标准化。方向是改进接触模型和统一API。
- 未来方向:整体推动可扩展预训练(如分层架构)、模块化设计(插件式组件)、和多模态对齐策略,以加速真实部署。
- 总结:VLA模型通过整合感知、语言和动作,显著推进了机器人自主性,在任务泛化和真实部署上取得进展(如开源模型和数据集)。但核心挑战包括仿真到现实迁移、安全决策和大规模预训练。
- 最终建议:综述强调未来需协同发展数据集、仿真和架构(如可组合学习系统),以实现通用具身智能。
VLA(视觉-语言-动作)模型是理想汽车推出的端到端自动驾驶框架,旨在通过多模态输入(视觉和语言)直接输出驾驶动作。它代表了当前自动驾驶技术的演进:从传统模块化方法(分感知、预测、规划等阶段)发展到端到端范式,再升级到结合大型语言模型(LLM)的VLA范式。VLA的核心是融合视觉、语言和动作,实现更自然、高效的驾驶决策。
- 技术演进:从E2E(端到端)到VLM(视觉语言模型),再到VLA。VLA解决了传统方法的“语义鸿沟”问题,能够理解和执行自然语言指令。
- 应用场景:在理想i8车型上实现,支持语音指令(如“靠边停一下”“往前开50米”)和环境交互,提升驾驶直觉。
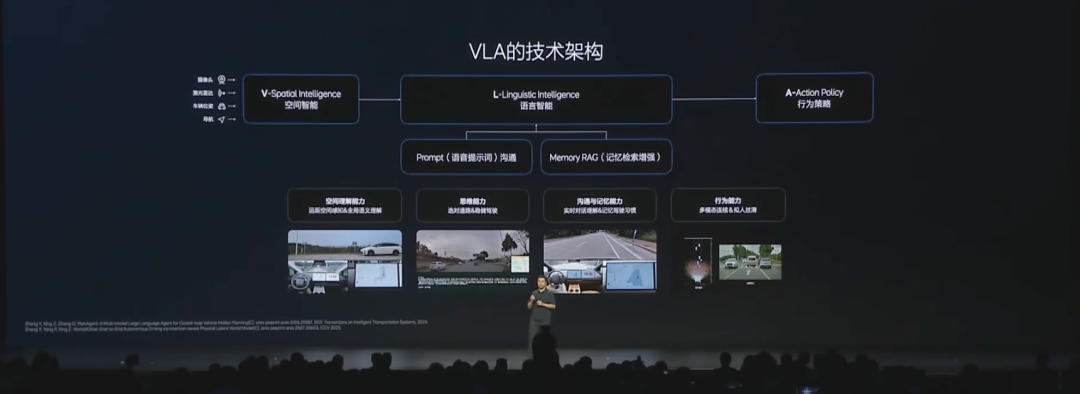
VLA的核心能力
VLA模型被设计为具备四个核心能力,这些能力源于多模态技术的整合:
- 空间理解能力:基于视觉输入(如摄像头数据)实时解析环境,包括动态目标(车辆、行人)、静态元素(道路、障碍物)和导航地图。这依赖于BEV(Bird’s Eye View,鸟瞰图)感知技术,将2D图像转换为3D空间表示,实现目标检测、车道线识别和占用网格(OCC)预测。

- 思维能力:利用语言模型(如LLM)的推理能力,实现“思维链”(Chain of Thought)机制。模型能逐步推理复杂路况,例如结合导航信息、动态目标和环境约束,生成决策序列(如“前方有行人→减速→变道”)。文档中展示了思维链的demo输出,整合了多源数据。

- 沟通与记忆能力:通过自然语言处理(NLP)理解用户指令(如“找到最近的星巴克”),并使用RAG(Retrieval-Augmented Generation,检索增强生成)技术实现记忆功能。RAG允许模型检索历史数据(如特定路段的速度偏好),增强决策的个性化和上下文感知。
- 行为能力:直接输出驾驶动作(如加速、转向),通过强化学习优化动作序列,确保安全性和效率。
关键技术栈解析
VLA模型依赖于多个跨领域技术,这些技术构成了端到端自动驾驶的基础:
-
多模态输入融合:
- 视觉Transformer:用于处理图像数据,将像素级信息转换为高维特征。扩展技术包括CLIP(对比语言-图像预训练)和LLaVA(大型视觉-语言对齐模型),实现图像与文本的语义对齐(例如,识别“星巴克”标志并关联到语言指令)。
- BEV感知:核心用于自动驾驶的3D环境建模。它将摄像头输入转换为鸟瞰图表示,支持任务如3D目标检测、车道线分割、轨迹预测和占用网格预测(OCC)。优势在于统一感知输出,简化后续规划。
-
推理与决策技术:
- 扩散模型(Diffusion Models):用于生成多模轨迹(即多种可能的未来路径),处理环境不确定性。例如,Diffusion Planner方法通过迭代去噪过程生成多条候选轨迹,选择最优路径。关键技术点包括去噪扩散概率模型(DDPM)和条件扩散。
- 强化学习(RL):用于优化动作输出。常用方法包括RLHF(人类反馈强化学习),通过人类偏好数据微调模型行为;GRPO(一种高效的RL算法)用于减少训练开销。
- 思维链(Chain of Thought):让模型模仿人类逐步推理,整合视觉、语言和地图输入,输出可解释的决策序列(如文档中的demo)。
-
记忆与检索技术:
- RAG(Retrieval-Augmented Generation):结合检索和生成,模型能从知识库中检索相关信息(如历史驾驶数据),用于实时决策。在VLA中,用于“设定特定路段的速度”等功能。
端到端自动驾驶的实现方法
VLA基于端到端范式,具体分为两类方法:
-
二段式端到端:分感知和规划两阶段。感知阶段输出环境表示(如BEV特征),规划阶段生成轨迹。代表性算法:
- PLUTO:经典方法,使用感知模块输出作为规划输入。
- CarPlanner(CVPR’25):结合语义地图和强化学习,提升规划鲁棒性。
- Plan-R1:最新工作,优化多目标决策。
-
一段式端到端:端到端直接输出动作,是VLA的基础。子方法包括:
- 基于感知的方法:如UniAD(统一感知-决策框架)和地平线VAD,直接将视觉特征映射到动作。
- 基于世界模型的方法:如Drive-OccWorld(AAAI’25)和OccLLaMA,构建环境动态模型(预测未来场景),用于仿真和决策。
- 基于扩散模型的方法:如DiffusionDrive、Diffusion Planner和DiffE2E,利用扩散生成多模轨迹,处理复杂路况。
- VLA方法:如小米ORION、OpenDriveVLA和ReCogDrive,整合视觉、语言和动作,实现自然语言交互和驾驶。
-
挑战:VLA需要高算力(推荐4090以上GPU),技术栈复杂(涉及BEV、扩散模型、RL等),且数据需求大(需多模态数据集)。难点包括模型可解释性、安全验证和实时性。
-
趋势:2024-2025年,业内重点在扩散模型和VLA的结合,以及强化学习微调(如RLHF大作业)。世界模型(用于场景生成和闭环仿真)也是热点,提升泛化能力。
-
通过融合视觉(V)、语言(L)和动作(A)实现端到端驾驶决策。
-
VLA架构受机器人和具身智能启发,将自动驾驶视为“四轮机器人”,通过多模态输入(视觉+语言)直接输出驾驶动作(规划与控制)。它解决了传统模块化方法(感知→预测→规划)的局限性,是端到端自动驾驶的演进。
-
技术定位:
- 起源:从无图NOA(基于高精地图的导航辅助驾驶)发展到端到端,再升级到VLA。端到端数据训练(1000万Clips)已边际收益递减,VLA通过语言模型引入高级推理能力。
- 核心优势:语言(L)赋予模型思维链(Chain of Thought, CoT)能力,使决策更接近人类直觉(如理解“靠边停车”指令)。VLA非短期方案,而是长期架构,预计延续至机器人技术成熟后才可能被替代。
-
潜力与适用性:
- 城区自动驾驶支持:专家(郎咸朋)确认VLA能支持城区复杂场景,因其泛化能力不依赖数据堆叠,而是通过强化学习形成“思维能力”,自主处理新场景(如未知路况)。
- 与传统架构对比:端到端仅依赖视觉(V)和动作(A),VLA增加语言(L)实现深度思考,是核心能力跃升(非锦上添花)。
-
VLA设计支持多硬件平台,重点优化推理帧率和算力效率。
-
芯片平台与帧率:
- Thor-U芯片:当前支持INT8/FP8精度,推理帧率达10Hz。未来通过FP4精度(算力翻倍)和架构优化,目标提升至20-30Hz。扩散模型轨迹生成的时延问题通过新方法(如DPIM、flow matching流匹配)解决,仅需2-3步去噪,时延约15毫秒。
- 双Orin平台:功能与模型表现与Thor平台无差异(同步优化)。部署帧率通过持续迭代改进,最终交付版本将优于当前测试版。
-
自研芯片决策:
- 理想暂不自研芯片,优先使用英伟达通用芯片(避免算子锁定)。待VLA架构稳定后,再评估自研可能性,当前注重模型通用性。
-
VLA整合多模态模型和强化学习,关键技术包括扩散模型、MoE架构和思维链。
-
模型架构:
- 3.2B MoE(Mixture of Experts)车端模型:
- 升级周期:预训练基座(空间理解、语言理解)每月更新;后训练(如新增Prompt或数据)按需快速迭代。
- 扩散模型优化:传统扩散模型轨迹生成时延高,VLA采用流匹配技术(2-3步生成多模轨迹),并行计算确保实时性。
- 语言(L)的核心作用:
- 必要性:语言能力是L4及以上无人驾驶的前提(如无地图场景需自然语言指令)。它增强思维链(CoT),使模型能推理复杂场景(例如,“前方慢车→评估超车风险→决策”)。
- 思维链实现:CoT以Token形式模拟人类推理过程(如整合动态目标、静态元素、导航地图)。超级对齐(RLHF)确保CoT符合人类价值观(采样多种逻辑,偏好筛选安全行为)。
- 3.2B MoE(Mixture of Experts)车端模型:
-
泛化机制:
- 不依赖数据输入,而是通过训练形成“下意识”泛化能力(类似人类经验学习)。例如,遇到突发障碍时优先安全刹停,无需反复训练。
-
VLA在实测中表现偏保守,专家解释为初版调试与价值观对齐。
-
驾驶行为调优:
- 保守场景(如不超车/低速行驶):当前版本优先合规与舒适(例如,虚线可借道但未超车)。未来通过强化学习支持个性化风格(激进/稳妥),根据用户偏好自适应调整。
- 动作缓慢问题:与帧率无关(如靠边停车/掉头),属工程信号控制问题(如挂挡逻辑),后续版本优化。
-
实用性与迭代:
- 短期目标:2024年底MPI(平均无干预里程)达400-500公里,2025年达千公里级。
- 长期愿景:VLA架构支持全场景自动驾驶(行车、泊车、AEB一体训练),通过仿真迭代加速(非人工测试)。
-
安全兜底:
- AEB(自动紧急制动):独立于VLA运行,直接基于感知结果做最后决策(帧率高,处理极端场景)。
- 时延应对:VLA决策时延通过硬件优化(如FP4)降低,但安全不依赖单一模块。
-
个性化驾驶:
- 风格切换:通过FaceID识别用户,在端侧用强化学习训练专属模型(车越开越“像”用户)。
- 差异化优势:VLA架构独家支持此功能(友商路线不同),形成产品体验壁垒。
-
模块整合:VLA推送时,行车、泊车、AEB已一体训练,共享多模态输入。
-
特斯拉参考:理想关注特斯拉FSD/Robotaxi进展,但更注重渐进式迭代(非激进无人化)。技术差异:VLA强调全场景能力积累,特斯拉侧重远程接管与数据采集。
-
技术趋势:VLA代表自动驾驶新范式——语言模型驱动决策,扩散模型优化轨迹,硬件协同提升实时性。其长期潜力在于泛化性、个性化及安全合规平衡。
-
挑战:初版行为保守需调优;帧率与算力持续优化中。
-
核心价值:VLA非工具升级,而是重构驾驶逻辑(从“规则编码”到“AI思考”),目标是实现L4级全场景自动驾驶。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)