VLA 论文精读(三十三)A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
这篇论文是一篇比较新的(2025年07月02日发表) VLA 领域综述,原文一共 70 页内容,主要是从 Action Tokenization 角度出发进行了一次全面的总结,可以直接将其当作一个字典,其中的表格整理的非常清晰直观。
这篇论文是一篇比较新的(2025年07月02日发表) VLA 领域综述,原文一共 70 页内容,主要是从 Action Tokenization 角度出发进行了一次全面的总结,可以直接将其当作一个字典,其中的表格整理的非常清晰直观。
【Note】:因为这篇文章的定位是综述,里面出现了大量模型,但原文中对模型的方法与性能描述堆在了一段,这里为了我自己阅读方便会将其拆分出来,因此在排班上会存在一定差异。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
- 原文链接: https://arxiv.org/abs/2507.01925
- 发表时间:2025年07月02日
- 发表平台:arxiv
- 预印版本号:[v1] Wed, 2 Jul 2025 17:34:52 UTC (16,319 KB)
- 作者团队:Yifan Zhong, Fengshuo Bai, Shaofei Cai, Xuchuan Huang, Zhang Chen, Xiaowei Zhang, Yuanfei Wang, Shaoyang Guo, Tianrui Guan, Ka Nam Lui, Zhiquan Qi, Yitao Liang, Yuanpei Chen, Yaodong Yang
- 院校机构:
- Peking University;
- PKU-PsiBot Joint Lab;
- 项目链接: 【暂无】
- GitHub仓库: 【暂无】
Abstract
视觉语言基础模型在多模态理解、推理和生成方面的显著进步,激发了人们将此类智能扩展到物理世界的日益增长的努力,并推动了 VLA 的蓬勃发展。尽管方法看似多样,但当前 VLA 模型可以统一在一个框架下:视觉语言输入由一系列 VLA 模块处理,生成一系列 action tokens,这些 tokens 逐步编码更扎实、更可操作的信息,最终生成可执行的动作。进一步确定,区分 VLA 模型的主要设计选择在于 action token 的表述方式,action token 可以分为语言描述、代码、可供性、轨迹、目标状态、潜在表征、原始动作、推理。然而,目前仍然缺乏对动作 token 的全面理解,这严重阻碍了 VLA 的有效开发,并模糊了未来的发展方向。因此,本综述旨在通过动作 tokenizer 的视角对现有的 VLA 研究进行分类和解读,提炼每种 token 类型的优势和局限性,并找出需要改进的领域。通过系统的回顾和分析,对 VLA 模型的更广泛发展进行了综合展望,重点介绍了尚未得到充分探索但前景光明的方向,并为未来的研究提供了指导,希望使该领域更接近通用智能。
Executive Summary
- VLA Unified Framework and Action Token Taxonomy:当前的 VLA 模型可以统一在一个框架下。视觉和语言输入由一系列 VLA 模块处理,生成一系列动作 token,这些 tokens 逐步编码更扎实、更可操作的信息,最终生成可执行的操作。作为该框架的核心,动作 token 可以分为语言描述、代码、可供性、轨迹、目标状态、潜在表征、原始动作、推理。VLA 中的动作 token 是 LLM 中语言 token 的广义对应物;
- Action Token Trends:VLA 模型的未来并非取决于单一主导动作 token,而在于它们的战略整合。语言动作由于表达能力有限,不太可能成为主流,但语言规划对于任务分解仍然至关重要;Code 是一种强大的替代方案,其潜力将通过构建整合感知和动作原语的综合函数库来释放,以解决复杂的长期任务;语义指导的可供性与定义精确操作路径的轨迹之间正在形成关键的协同作用,这种组合得到了世界模型的有力支持,世界模型可以预测视觉目标状态,为两种 token 类型的生成奠定基础;潜在表征前景广阔,但面临训练挑战,原始动作代表了端到端学习的理想状态,但仍然受到数据可用性的限制;推理作为一种元 token,可以增强所有其他 token,并从纯粹基于语言的推理发展到基于动作 token 的推理,并具有多模态反馈和自适应测试时间计算;
- Emerging Action Token Types:动作 token 类型由模型的基础能力决定。更强大的模型和新的模态(例如,音频、触觉)将催生新的 token 类型和子类型;
- VLA Architecture Trends:有效的 VLA 模型可能采用分层架构,顶层使用语言描述和代码进行长远规划和逻辑控制。短期内,预计较低层将紧密整合目标状态的视频预测、轨迹的流建模以及可供性的 3D 交互预测,以形成中间运动表征,并最终映射到原始动作;长期来看,较低层将发展为完全端到端的方法,直接从子任务级输入预测原始动作。推理功能始终会根据需要集成到整个 VLA 模型中;
- From Imitation to Reinforcement Learning:通过融入强化学习,VLA 模型可以克服模仿学习的局限性,实现更接近人类的试错和自主探索能力。然而,现实世界的部署需要更高效的强化学习算法来解决高重置成本和低交互效率的问题。此外,VLM 可以自动生成密集奖励函数,从而加速模型训练和部署;
- From VLA Models to VLA Agents:应该有意识地从 VLA 模型发展到 VLA agents,后者是一种主动系统,能够通过更广泛的认知架构(包括记忆、探索、规划、反思)来增强感知-行动能力。这一转变也意味着从当前的线性处理架构过渡到更复杂、双向和图结构的拓扑结构;
- The Triad of Progress: Model, Data, and Hardware:具身人工智能旨在处理物理世界的非结构化、开放性,这一目标 需要模型、数据和硬件之间的协同作用。尽管如此,机器人平台和稀缺的高质量具身数据在很大程度上限制了该领域的进展,迫使大多数研究只能在复杂现实世界简化后的实验室环境中进行,因此该领域仍处于起步阶段。要实现强大的通用智能,需要模型、数据、硬件共同演进,齐头并进,而非孤立发展;
- Safety and Alignment:当前的 VLA 研究主要侧重于模型能力。未来的工作必须更加 注重确保安全性和人体协调性;
1. Introduction
近年来 AI 在通用智能方面取得了显著进展。这一进步的核心是基础模型的出现,大型神经网络在互联网规模的数据上进行训练,通过捕捉训练语料库中蕴含的多样化知识和模式,获得了广泛且可迁移的能力。一个突出的例子是大型语言模型 (LLM),例如 GPT-4 和 DeepSeek-R1,在自然语言理解、推理、生成方面表现出色,构成了许多基于文本的应用程序的支柱。与此同时,视觉基础模型 (VFM),例如 CLIP、DINO、SAM,在广泛的视觉任务中展现出强大的泛化能力;以 GPT-4o、Gemini 2.5 Pro、Qwen2.5-VL 为代表的 VLM 整合了视觉和文本模态,实现了多模态处理和生成。这些模型编码了海量的世界知识,在复杂任务上表现出色,并能泛化到新的场景,使其具有高度的通用性和跨领域的广泛应用。
然而,尽管这些模型功能强大却仍然局限于数字世界,限制了其对现实世界任务的影响。为了突破这一局限,研究人员开始探索如何利用基础模型的感知和认知能力来增强任务执行,从而将其智能扩展到物理世界。这方面的研究催生了视觉-语言-动作 (VLA) 模型,作者将其正式定义为 基于视觉和语言输入生成动作的模型,并且至少基于一个大规模视觉或语言基础模型构建。例如,SayCan、PaLM-E、Code as Policies 利用 LLM 和 VLM 的语言和代码生成能力,生成以自然语言或可执行代码表达的高级动作计划,然后由低级控制器解释和执行。其他研究则侧重于从基础模型中提取可操作的知识,例如生成与任务相关对象的 可供性 或 预测场景级轨迹 以指导下游控制;另一项研究则通过专门的预训练有目的地构建具身动作序列的潜在表征,并调整 VLM 来预测这些表征,这些表征随后由策略控制器进行解码和执行;还有一些研究试图将视觉和语言领域观察到的 Scaling Laws 扩展到具身场景,收集大规模具身数据集,并在视觉-语言基础模型之上端到端地训练通用智能体。这些多样化的方法使得 VLA 模型在机器人操作 manipulation、导航 navigation 和自动驾驶 autonomous driving 等领域迅速普及,并在多任务学习 multitask learning、长周期任务完成 long-horizon task completion 和强泛化 strong generalization 方面展现出良好的性能。通过利用基础模型智能,它们为解决具身人工智能中长期存在的挑战(例如数据稀缺和跨具身迁移能力差)提供了新的方向,并为能够在开放世界物理环境中通过开放词汇指令解决开放式任务的智能体铺平了道路。
VLA 模型的快速发展以及日益多样化,迫切需要进行及时且系统的综述以指导和指导未来的研究。看似迥异的架构之间潜在的共性进一步凸显了这一需求。现有的 VLA 模型通常可以抽象成一个统一的框架:视觉和语言输入通过一系列 VLA 模块进行迭代处理,生成一系列动作 token,这些 token 逐渐编码出信息量越来越大且可操作的指导,最终生成可执行的动作。作者将 VLA 模块定义为 VLA 模型中支持端到端梯度流的最大可微子网络,或不可微功能单元(例如运动规划)。如果多个神经组件连接并联合优化,则它们被视为同一模块的各个部分。按照 VLM 中语言和图像 token 的命名约定,将 VLA 模块的输出称为 action tokens。此外,还将 VLA 模块中语义上有意义的中间表征视为 action tokens(例如通过专用预训练和目标图像构建的潜在表征)。Fig.1 展示了几个代表性 VLA 中 VLA 模块和 action tokens 的实例,重点展示了如何使用作者提出的框架统一地查看、解释、理解它们。从这个角度来看 VLA 模型的主要区别在于动作 token 的构成和组织方式。这些 token 可以分为八种类型:语言描述 language description、代码 code、可供性 affordance、轨迹 trajectory、目标状态 goal state、潜在表征 latent representation、原始动作 raw action 、推理 reasoning。
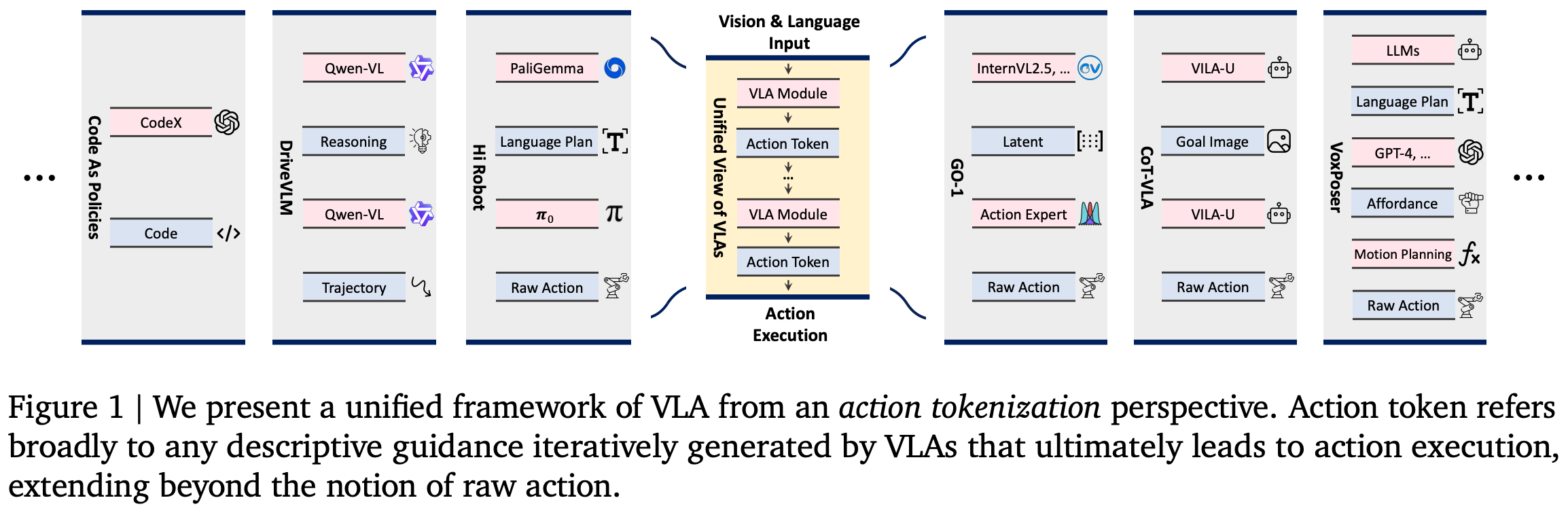
Fig.2 使用单个具身任务可视化了它们的常见形式。动作 token 的设计几乎影响了 VLA 模型的方方面面,包括基础模型的选择、数据需求、训练、推理效率、可解释性、可扩展性、跨任务和环境的适用性。因此,action tokenization 是 VLA 模型设计的核心,需要深入理解。

尽管 action tokenization 至关重要,但目前研究界仍缺乏对其系统深入的理解。本综述旨在填补这一空白,从 action tokenization 的角度对 VLA 研究进行结构化的概述。首先,回顾视觉和语言基础模型的演变,考察它们的设计选择、扩展策略、能力;然后,讨论向具身人工智能的过渡,特别是 VLA 模型,并将 VLA 确立为下一个研究前沿(第 2 节);在此基础上介绍 VLA 的研究概况,概述动作 token,包括它们的分类、定义、比较以及 VLA 模型中的组织模式(第 3 节);后续章节将深入探讨每个主要的动作 token 类别,分析它们的动机、代表性方法、属性、优势、局限性和未来研究方向(第 4 至 11 节);总结可扩展的数据源,为未来的研究提供参考和支持(第 12 节);最后,基于调研的现状和新兴趋势,概述未来推进 VLA 领域的研究方向(第 13 节);
作者希望他们的综述能为下一代具身化人工智能系统的开发提供宝贵的见解和切实可行的指导。
2. The Evolution of Language and Vision Foundation Models
本节首先回顾语言基础模型(LFM,第 2.1 节)、视觉基础模型(VFM,第 2.2 节)、视觉语言模型(VLM,第 2.3 节)的主要发展,阐明它们在能力、技术创新、方法论方面的进展。随后,讨论该领域向具身人工智能(embodied AI)的进展,分析该领域显著更高的复杂性,并将具身 VLA 确立为下一个前沿领域。
2.1. Language Foundation Models
语言基础模型的出现很大程度上可以追溯到 Transformer 架构的引入,该架构利用多头自注意力和交叉注意力机制进行可扩展的序列建模,并采用 encoder-decoder 结构实现高效的序列到序列生成。
BERT:在大规模未标注语料库上,以自监督的方式预训练双向 Transformer 编码器,使用掩码语言建模和下一句预测目标,使模型能够学习丰富的、上下文感知的表征,从而显著提升下游任务的性能。通用句子编码器类似地采用 Transformer 编码器来学习可迁移的句子级编码;T5:保留了 encoder-decoder 结构,将所有自然语言处理任务重新组织为统一的文本到文本格式,并在大规模C4数据集上进行预训练。其预训练编码器被广泛用于为开放词汇输入生成高质量的语言编码;
相比之下,GPT 模型将所有 NLP 任务都表述为下一个词法单元的预测,这促使人们使用仅包含 decoder 的 Transformer 架构,也称为因果 Transformer 或自回归 Transformer。
GPT-3:通过将模型规模扩展至 1750 亿个参数,并在互联网规模的语料库上进行预训练,展现了令人印象深刻的语言理解和生成能力,表现出了一些新兴行为,例如情境学习 in-context learning,即模型可以仅基于推理时提供的少量示例执行任务。
这表明 模型架构、训练目标、数据源的可扩展性使学习能够有效地大规模应用,从而产生性能优于特定任务系统的通用模型。这种范式转变与 Bitter Lesson 的核心洞见相一致,标志着大型语言模型 (LLM) 时代的开始。
为了指导 LLM 有效扩增,已提出了 Scaling Laws 来表征模型大小、数据量、计算需求、预训练损失之间的可预测关系。这些结论为大规模训练期间的模型设计和资源分配的实际决策提供了参考。InstructGPT 通过在指令遵循数据集上应用监督微调 (SFT),然后进行基于人类反馈的强化学习 (RLHF),进一步提高了LLM与人类意图的一致性。此后,对齐技术 alignment techniques 得到了广泛的研究,以确保大型AI模型的行为符合安全考虑、人类偏好和价值观。
这些技术进步促成了高性能商用 LLM 的开发。
GPT-4和Claude:在开放式对话、代码生成、思路推理方面表现出色;Gemini 2.0 Flash和Gemini 2.0 Pro:被编排成名为AlphaEvolve的进化编码代理,共同推动了包括矩阵乘法在内的开放科学问题取得显著突破。
然而,由于其闭源性质和基于 API 的访问受限,这些模型难以检查、微调或集成到更广泛的研发工作流程中。为了解决这些局限性,许多开源的 LLM 模型已经发布。Llama、Gemma、Mistral:模型大小从 2B 到 70B 参数不等,以满足不同的需求。基于这些模型构建的参数高效微调 Parameter-Efficient Fine-Tuning (PEFT) 技术,例如 LoRA,能够使用更少的可训练参数和更低的计算成本实现针对特定任务的自适应,从而使微调在资源受限的环境中变得可行。
为了在不增加计算量的情况下进一步扩展模型容量,混合专家 Mixture-of-Experts (MoE) 架构已被引入到 LLM 中,例如 Switch Transformer 和 Mixtral。MoE 模型仅针对每个输入激活专家子网络的一个子集,从而显著提高模型的有效容量,并保持高效的推理能力。
为了解决 Transformer 架构的二次时间复杂度,一些替代方案被提出,例如 Mamba。Mamba 用选择性状态空间更新取代了自注意力机制,从而实现了线性时间序列建模,在长上下文中保持了强大的性能。
另一项研究通过扩展测试时计算来提升推理能力。例如,OpenAI o1 和 DeepSeek-R1 在推理过程中动态分配计算资源,以提升复杂推理任务的性能。尤其是 DeepSeek-R1,它通过基于 GRPO 的大规模强化学习获得了这种能力。
最后,在优化用于训练和部署 LLM 方面取得了重大进展。一系列并行策略,包括数据并行 data parallelism、模型并行 model parallelism、流水线并行 pipeline parallelism、张量并行 tensor parallelism,被积极用于在分布式计算环境中扩展训练;推理加速技术,例如模型量化 model quantization、权重剪枝 weight pruning 、推测解码 speculative decoding 等也得到了开发,以减少部署期间的延迟和计算开销。
这些进步使 LLM 在知识、对话、代码、推理方面拥有强大的能力,同时还能通过成熟的基础设施实现高效的训练、部署和微调。它们不仅提升了 LLM 的可用性,还支持视觉和多模态系统的开发,构成了具身化 VLA 模型的关键构建模块。
2.2. Vision Foundation Models
继 Transformer 在语言领域的成功之后,计算机视觉界开始用 Vision Transformer (ViT) 取代卷积神经网络,将其作为视觉模型的默认骨干网络,以便在使用大规模数据集训练时获得更佳性能。这种架构上的转变自然地将图像视为 visual tokens,表征格式允许视觉输入与文本输入进行类似或联合处理,从而促进后续多模态模型中的跨模态对齐和融合。LLM 训练的可扩展性也启发了研究人员探索视觉学习中可扩展的学习目标,以便在无需人工标注的互联网规模视觉数据上训练通用模型。
CLIP:利用自然语言监督进行图像表征学习,使用 contrastive loss 对 4 亿个图像-文本对进行训练。这使得CLIP能够学习鲁棒且可泛化的图像表征,并展现出令人印象深刻的零样本迁移能力;SigLIP:在CLIP的基础上进行了改进,用 sigmoid loss 取代了原有的 Softmax 运算,从而提升了训练效率和性能。
由于 CLIP 和 SigLIP 都与文本监督联合训练,它们都被广泛应用于图像编码器,尤其是在需要多模态理解的场景中。然而,依赖文本监督也构成了它们的局限性。由于文本描述通常层次较高且抽象,CLIP 和 SigLIP 编码后的图像特征可能缺乏复杂的像素级信息,这对于需要详细视觉理解的任务来说是不利的。
DINO:以自监督的方式直接从精选的图像数据集中学习,获得丰富的通用视觉特征,这些特征有助于语义分割和深度估计等细粒度的下游任务。重要的是,其编码特征可以匹配不同物体(例如飞机机翼和鸟类)之间的相似区域,展现出深入的语义理解和世界知识;
Darcet 等人提出了一种简单而有效的改进方法,改进了这些基于 ViT 的模型,即在原始 [CLS] token 和 patch tokens 的基础上添加可学习的 register token ,以消除特征图中原本存在的伪影,并提高密集预测任务的性能。基于这些开创性的图像编码工作,后续研究开发了针对特定下游视觉任务的基础模型。
Depth Anything:有效地利用了从大规模未标注数据中自生成的伪标签,实现了稳健的单目深度估计 (Monocular Depth Estimation, MDE);Depth Anything V2:则利用了来自合成数据的真实标签来增强细粒度细节的保存;Segment Anything:是可提示图像分割的基础模型,其后继模型SAM 2将此功能扩展到视频领域,这些模型可以根据点 points、边界框 bounding boxes,、蒙版 masks 以及文本等形式的提示生成有效的分割 mask;Cutie:较早的视频对象分割 (Video Object Segmentation, VOS) 模型,并在各种视觉条件下都表现出了稳健性;SAMURAI:通过结合运动建模和运动感知内存选择,提升了SAM 2的视觉对象跟踪 (Visual Object Tracking, VOT) 性能,从而能够更有效地处理快速运动、遮挡和拥挤场景;CoTracker:通过引入一个用于长视频序列中密集点跟踪的 Transformer 架构,对SAMURAI的研究进行了补充;
在开放词汇检测和词根定位领域,一系列模型逐步推进了区域级视觉语言理解。
GLIP:通过将CLIP式对齐扩展至区域级别,将检测和短语词根定位统一在一个预训练框架内;Grounding DINO:在此基础上构建了DETR式架构和对比式区域-文本对齐,在开放词汇词根定位任务上取得了优异的性能;Grounding DINO 1.5:扩展了模型规模和训练数据,提升了泛化能力,并创下了新的 SOTA 成果;Grounded SAM:进一步将Grounding DINO与SAM相结合,实现了零样本语言驱动的分割;Grounded SAM 2:将其扩展到词根定位,并可追踪视频中的任何内容;
对于高保真图像和视频生成,扩散模型 diffusion models 已成为主流方法。早期模型,如 GLIDE、DALL·E 2 和 Imagen,展示了文本引导图像合成的强大功能,而稳定扩散则实现了高效的开放域生成,并得到了广泛的应用。
ControlNet:引入了空间调节,以支持对结构和布局的细粒度控制;VideoCrafter和PVDM等:将扩散扩展到时间域,用于文本到视频的合成;Sora:通过采用流匹配 flow-matching 进一步推进了这一技术,并学习物理先验知识来生成具有强时间相干性的长时高分辨率视频;Veo 3:展示了全模态生成功能,包括同步音频和动作,突破了逼真视频合成的界限。这些先进的图像和视频生成模型也被称为世界模型,因为它们编码了大量的物理常识和世界知识;
其他世界模型,例如 Genie 和 Genie 2 能够模拟基于动作序列的未来视觉动态,从而能够准确、连贯地展现环境随时间的变化。还有研究则侧重于开发与操作相关的感知任务的基础模型。
Foundation Pose:是一个统一的视觉基础模型,用于对新物体进行鲁棒且可泛化的6D姿态估计和跟踪,且不受CAD模型可用性的限制;HaMeR:利用大规模数据和高容量Transformer架构,能够从单目输入中准确可靠地恢复手部网格,从而促进从人体视频中提取手部姿态,并支持灵巧的操作任务;
2.3. Vision-Language Model
视觉和语言基础模型的进步自然而然地推动了多模态理解、推理、生成的研究,从而导致 VLM 的兴起。
BLIP:引入了一种基于 ViT 和BERT的多模态编码器-解码器 (Mixture of Encoder-Decoder, MED) 混合架构,用于统一的视觉-语言理解和生成,以及一种数据引导策略,该策略可以合成字幕并将嘈杂的网络数据过滤为高质量的图文对;BLIP-2:提出了一个Q-Former连接器和一个两阶段训练策略,以有效地将冻结的预训练图像编码器与冻结的 LLM 对齐,从而以适度的可训练参数实现了强大的视觉-语言性能,更好地利用现成的单模态基础模型;
研究人员还探索了不同的架构范式。
Flamingo:采用感知器重采样器和门控交叉注意力层进行跨模态对齐。它还以一种与交错的视觉和文本序列固有兼容的方式处理输入,从而实现了强大的少样本学习能力;LLaVA:代表了 VLM 架构发展的一个里程碑,它通过线性投影将 CLIP 视觉编码器简单地连接到Vicuna LLM,并使用GPT-4合成的视觉指令调整数据进行训练;LLaVA-1.5:在LLaVA的基础上进行了改进,采用了更强大的视觉编码器,用 MLP 取代了线性投影,并在更大的数据集上进行训练;
Qwen-VL 系列代表了另一项杰出的研究成果。
Qwen-VL:通过位置感知交叉注意力适配器将Qwen 7B LLM与 ViT 相结合。其专门设计的图像和边界框输入输出接口,结合三阶段训练策略,实现了交错式图文理解和视觉基础能力;Qwen2-VL:利用 2D RoPE 和 M-RoPE 增强了时空编码,以支持不同分辨率和宽高比的图像和视频。它在字幕制作、视觉问答 (VQA) 和视频理解等视觉语言任务上展现出强大的多语言能力和极具竞争力的性能;Qwen2.5-VL:将动态分辨率扩展到时域,并将M-RoPE时间 ID 与绝对时间对齐,从而实现了更精细的时间理解。它在视觉编码器中加入了窗口注意力机制,以提高推理效率。结合广泛的高质量数据管理,可提供增强的视觉识别、精确的对象定位、强大的文档解析和长视频理解功能;
Karamcheti 等人探索了围绕图像预处理、架构、优化的关键 VLM 设计决策,并得出结论:单阶段训练、融合 DINOv2 和 SigLIP 视觉主干模型、基础 LLM 以及与纯语言数据协同训练是有效的策略,以此为依据他们开发了 Prismatic VLM。
Prismatic VLM:在各个基准测试中的表现始终优于LLaVA-1.5,并在之后的OpenVLA中得到应用;PaliGemma:是一个基于SigLIP、So400m、Gemma 2B构建的 3B VLM,其重点是可迁移性,随后被用作 π 0 \pi_{0} π0 系列 VLA 模型的主干模型;
目前处于领先地位的是两个专有模型:GPT-4o 和 Gemini 2.5 Pro。两者在通用视觉语言基准测试中均表现出色,并在实际应用中得到广泛采用。GPT-4o 以其对图像生成的原生支持而著称,而 Gemini 2.5 Pro 则因其强大的推理能力而备受认可,这凸显了现代 VLM 的快速发展和实用性。
2.4. Embodied VLA Models as the Next Frontier
基础模型的快速发展正日益激发人们的想象力,并推动着人们对通用人工智能 (AGI) 的追求。由于当前的基础模型主要在数字领域运行,代表着数字人工智能 (Digital AI),研究人员自然而然地将注意力转向具身人工智能,其目标是开发 能够在物理世界中遵循人类指令的通用智能体。然而,具身人工智能比数字人工智能有着更大胆的目标,原因如下。
- 从根本上说,具身人工智能必须解决的问题引入了数字人工智能所缺乏的 全新形式的开放性和挑战。尽管棘手的数字案例可能涉及分 OOD 或对抗性输入,但物理世界本质上是非结构化的,即使是常规环境也可能极具挑战性。流畅的人类对话、无意的干预、倒下的椅子、杂乱的房间、遮挡都是常见的例子。一个类似且可能更为常见的问题是自动驾驶,本文也将其视为具身人工智能的一部分。虽然自动驾驶已经非常困难,但物理世界中的通用具身智能必须处理更多数量级的情况,从而带来更大数量级的挑战和困难。这对模型和数据都提出了巨大的要求,以支持强大的具身人工智能;
- 一个关键的共识是,具身人工智能也涉及对 机器人硬件的要求,而数字人工智能则不具备。为了实现通用的具身智能,硬件平台必须具备执行一般任务所需的灵活性和鲁棒性,而这一水平目前还远远没有达到。代表性的差距包括:灵巧手和机械臂远未达到人类水平的灵活性、对夹持器的严重依赖、具身的多样性和孤立性,以及 缺乏灵敏的、全覆盖的触觉传感器。由于硬件的完善无法在短时间内实现,因此合理的预期是 模型、数据和硬件将协同发展,最终实现通用智能;
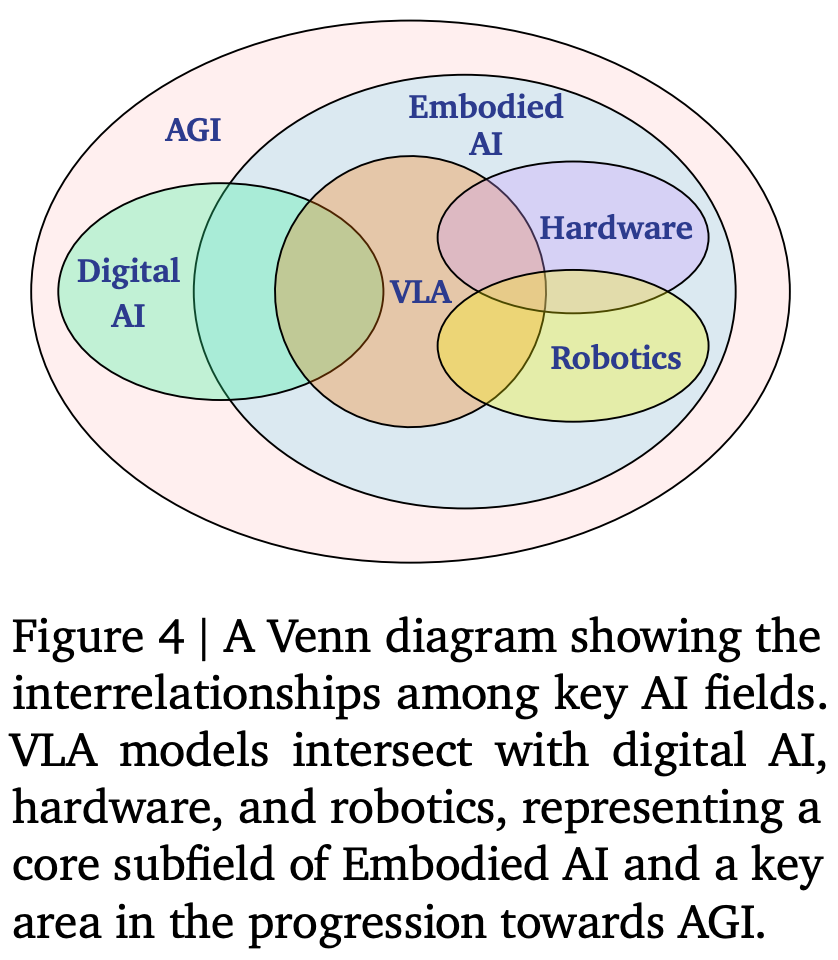
鉴于具身人工智能需要通用的视觉和语言能力,一种自然的策略是在基础模型的上构建并赋予其行动能力。这一方向催生了具身超逻辑行为模型 (VLA),如今已成为研究的核心课题。VLA 处于数字人工智能、机器人技术和硬件的交叉领域,是具身人工智能的核心子领域,也是实现通用人工智能 (AGI) 的关键领域 Fig.4。
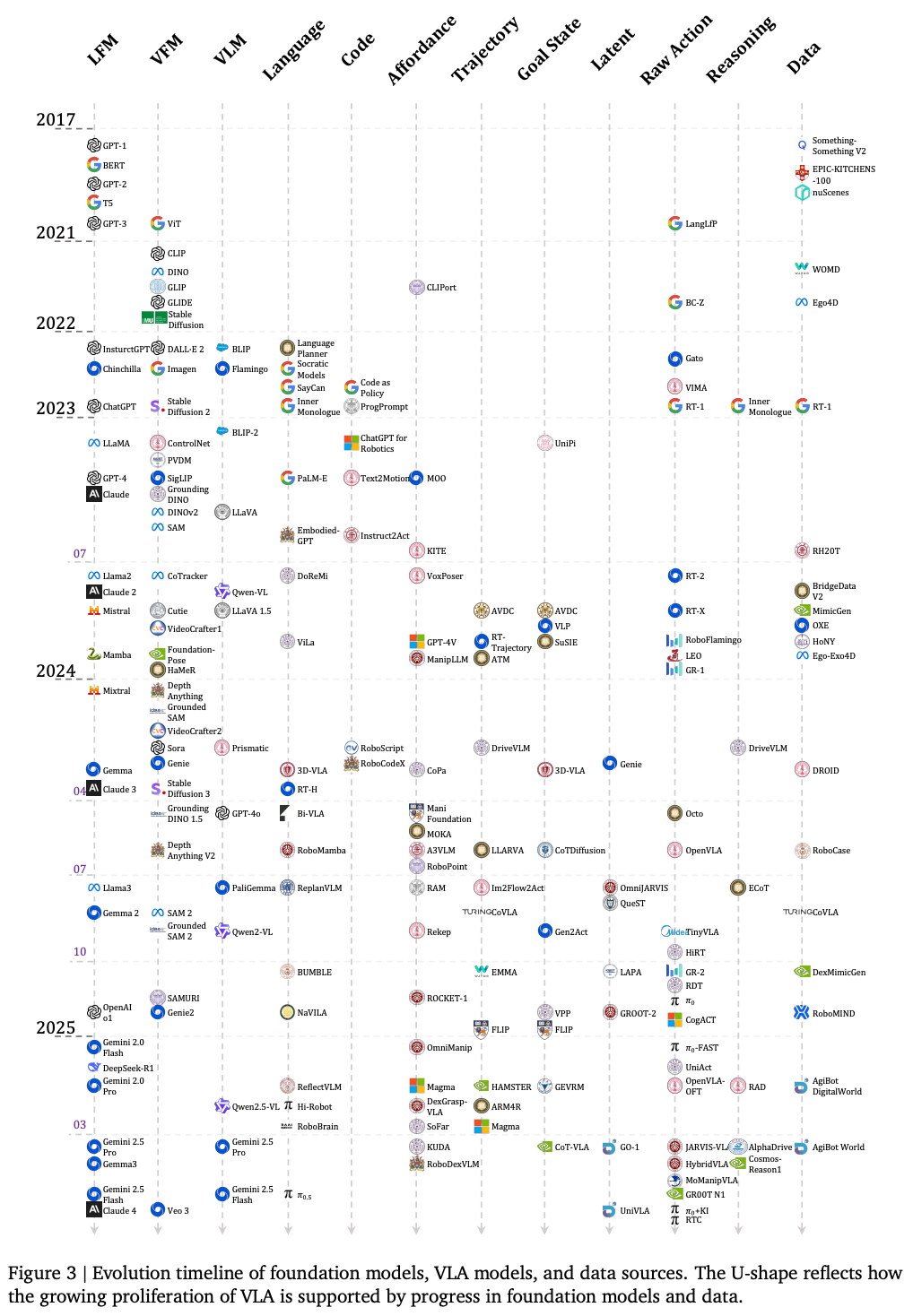
迄今为止,数百篇 VLA 论文体现出这是一个快速发展的领域 Fig.3,已经表现出早期但有限的智能化和泛化迹象。本综述从 action tokenization 的角度系统地回顾和分析了这些论文,目的是勾勒出研究前景。尽管最近取得了一些进展,但大多数评估仍然局限于简化的实验室环境,主要是基于抓手的操作。因此远未达到日常环境中对通用具身智能体的要求。该领域尚处于起步阶段,仍需取得实质性进展,在可预见的未来,具身 VLA 模型的持续发展仍将是下一个研究前沿。
3. Overview of Action Tokens
VLA 模型的研究侧重于利用基础模型处理视觉和语言输入以生成动作输出。在设计 VLA 架构和制定训练策略时,VLA 模块和动作 token 的概念自然而然地出现。为了将原始感知映射到动作,VLA 模型必须有效地理解场景和指令,将指令融入场景,规划当前子任务以及预测后续动作,并生成可执行动作。具体化任务的复杂性和普遍性进一步要求这些能力的切换、重复、递归。为了促进与任务相关的信息流和细化,VLA 将这些能力委托给不同的模块实现,管理它们各自的生成行为,并在逻辑上将这些模块及其生成关联起来以得出最终动作。因此,这些模块的生成格式和训练策略的设计是 VLA 的核心。
将 VLA 中的最大可微子网络和不可微功能单元称为 “VLA modules”,并将其代称为 “action tokens”。此外,VLA 模块中语义上有意义的中间代也被视为 “action token”。“action token”这一名称不仅表明这些代封装了与动作相关的信息,也符合 LLM 中 “language token”的命名约定。事实上,VLA 中的动作 token 是 LLM 中语言 token 的广义对应物。Fig.1 突出显示了几个代表性示例。
Hi Robot:使用经过微调的PaliGemma模型来预测自然语言中的下一个子任务,然后使用 VLA 模型(其训练方式类似于 π 0 \pi_{0} π0)生成低级机器人命令。经过微调的PaliGemma和自定义的 π 0 \pi_{0} π0 构成 VLA 模块,而中间语言规划和生成的原始动作则用作动作 token;VoxPoser:首先使用 LLM 将语言指令分解为子任务,然后使用 LLM 和 VLM 基于当前场景生成用于解决每个子任务的可供性图,最后调用运动规划模块将可供性图转换为原始动作。LLM、VLM 和运动规划算法都充当 VLA 模块,而语言规划、可供性图、原始动作则代表相应的动作 token;
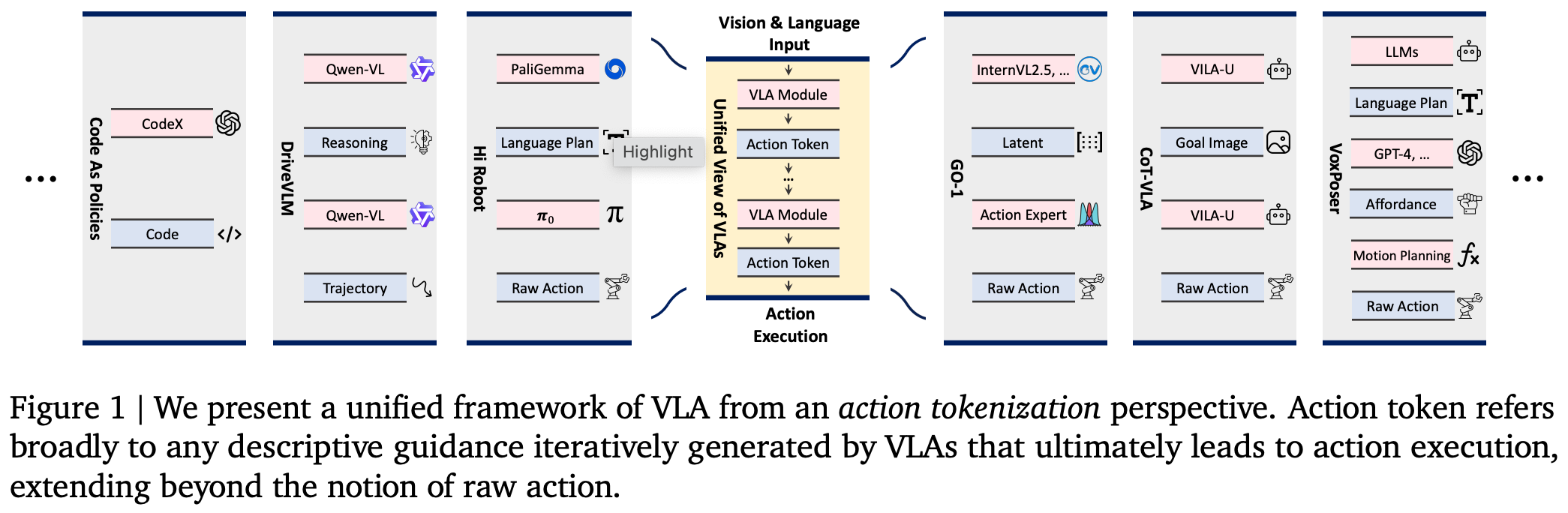
由于 VLA 利用基础模型来开发 VLA 模块和动作 token,这些底层模型固有的多样性导致了各种动作 token 格式。现有的 VLA 研究主要研究了八种主要类型的动作 token:语言描述、代码、可供性、轨迹、目标状态、潜在表征、原始动作、推理。Fig.2 中以 “prepare tea” 这一说明性任务为例,可视化了这些动作 token 的常见格式。该可视化图表明,对于给定的语言指令和观察结果,每种类型的动作 token 都以不同的方式编码与任务相关的指导。这些动作 token 的正式定义如下所示。
- Language description(Section 4):描述预期动作序列的自然语言表达,范围从高级抽象的语言计划到低级具体的语言动作;
- Code(Section 5):构成完整机器人程序或指定低级原子操作的可执行代码片段或伪代码;
- Affordance(Section 6):一种空间基础表示,可捕捉对象的任务特定和交互相关属性,通常表示为关键点、边界框、分割蒙版或阿福舞蹈图;
- Trajectory(Section 7):按时间顺序排列的空间状态序列,用于捕捉物体、末端执行器或场景的动态演变;
- Goal state(Section 8):预测的未来观察结果(例如图像、点云或视频片段),以视觉方式呈现预期动作序列的预期结果,作为规划和执行的中间目标;
- Latent representation(Section 9):经过专门预训练的潜在向量序列,对时间间隔内的动作相关信息进行编码,通常从大规模数据集中提取;
- Raw action(Section 10):一个或多个可由机器人直接执行的低级控制命令;
- Reasoning(Section 11):明确描述导致特定动作 token 的决策过程的自然语言表达;
以下章节将系统地介绍按每种动作 token 类型分类的 VLA 模型。对于每个类别,讨论其采用的动机、回顾相关文献、分析其优势和局限性、预测未来的研究方向。每个章节还包含一个表格,总结所调查的研究成果,并考察与相应动作 token 相关的多个维度上的异同,其中 “previous module” 和 “next module” 列分别指动作 token 前后 VLA 模块的设计策略,这些策略通常反映了在 token 生成和转换方式方面的关键创新和深思熟虑的设计选择,从而实现有效的 VLA 模型。Table.1 总结了每种动作 token 最显著的优势、局限性和值得注意的实证结果,以便于跨类别进行比较、理解和洞察。
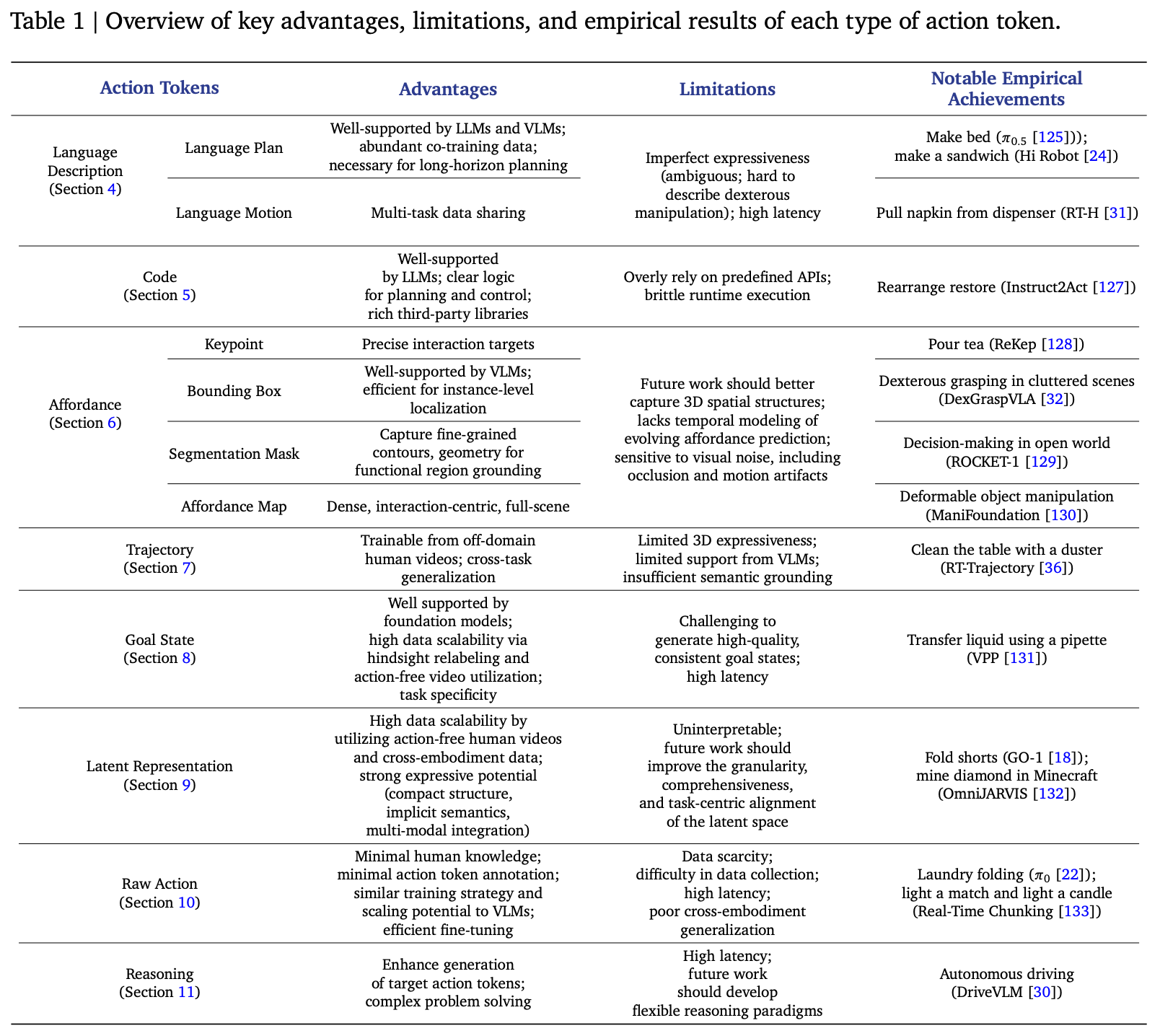
4. Language Description as Action Tokens
LLM 和 VLM 的进步自然而然地推动了 VLA 模型中语言描述作为动作 token 的使用,从而能够直接发挥其在语言理解、生成、推理、规划方面的优势。通过自然语言表示动作与人类概念化和沟通方式高度契合,尤其是在执行复杂且长期的任务时。人类并非直接执行原始动作,而是倾向于将高级指令分解为中间的、语义上有意义的子步骤,并在必要时进一步分解为精确的动作命令。这种任务的层级结构使人们能够灵活地根据不同的情境和控制级别调整计划。受此启发,VLA 模型中这些基于语言的 token 也设计了不同的抽象级别,大致分为两类。
- upper end:语言计划 language plans 通常用一个短语描述整个子任务或高级目标。例如,“language motions” 和 “place the cup on the table” 等示例传达了机器人应该完成的任务,它们充当可分配给技能或策略的语义锚点;
- finer level:语言动作 language motions 则使用诸如 “move the arm forward” 和 “close gripper” 等表达来指定更接近运动控制的低级物理动作,这些表达详细描述了特定动作的执行。这种抽象范围提供了一个概念框架,使 VLA 模型能够在不同粒度级别组织、解释和执行具体任务,并有可能支持更类似人类的分层规划。受这些优势的推动,越来越多的研究探索将语言描述作为动作 token 融入 VLA,从而产生了多种用于任务分解、动作排序和执行管理的策略。
Table.2中列出了这些策略;
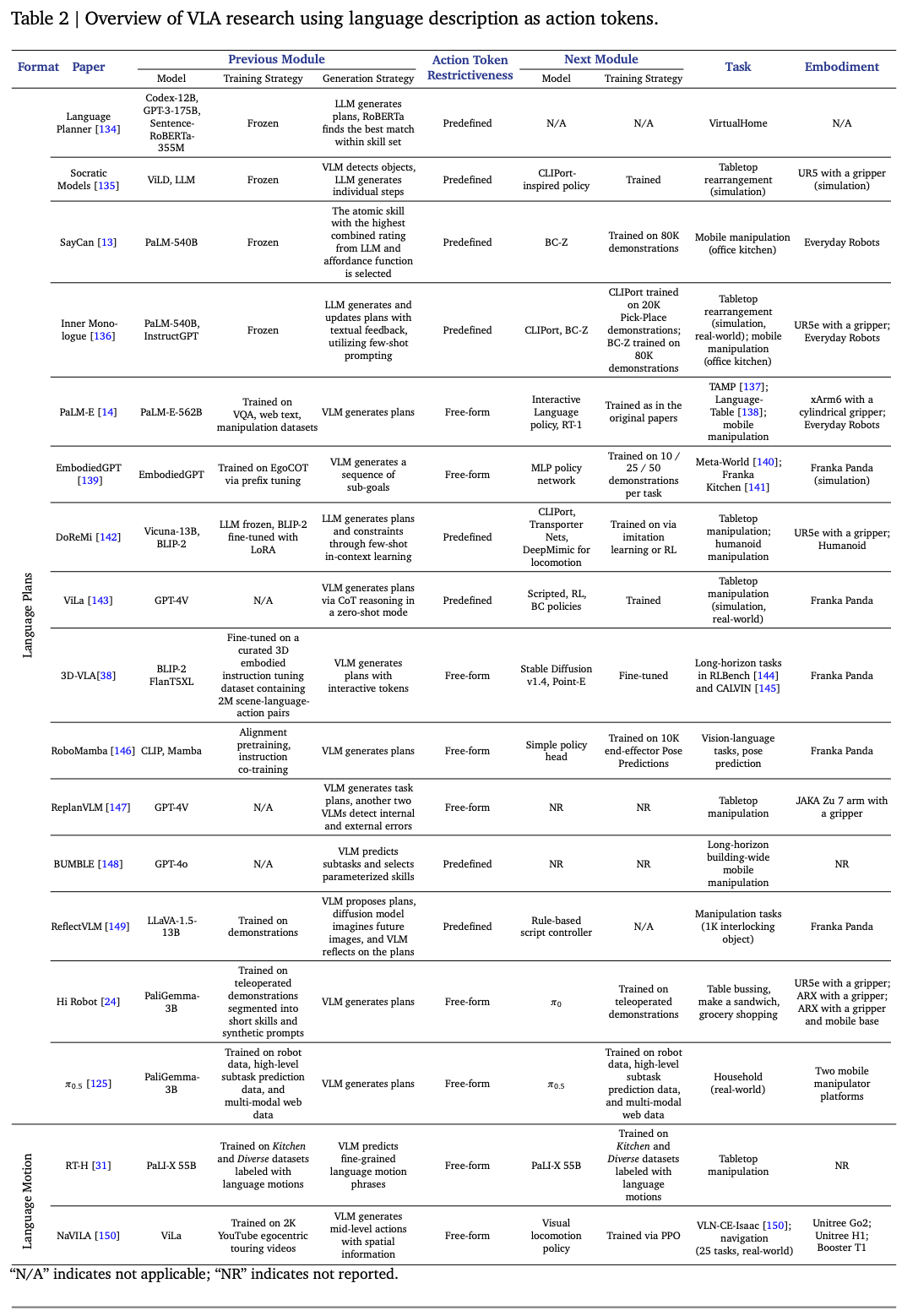
4.1. Progress and Key Papers
早期的研究,例如 Language Planner、Socratic Models、SayCan,表明 LLM 可以直接将高级自然语言指令分解为具有语义意义的子目标,而无需针对特定任务进行训练。这开启了无需领域特定工程即可进行规划的可能性。然而,LLM 规划器面临一个根本性的限制:缺乏感知基础。由于无法直接获取视觉、空间或感官输入,因此很难将抽象的规划与环境的实际状态相结合,也无法有效地适应意料之外的物理环境。为了解决这个问题,这些研究引入了显式的落地机制。
Socratic Models:将 LLM 与 VLM 配对,后者可以检测相关对象并提供视觉上下文,从而弥合抽象计划与物理现实之间的差距;SayCan:使用可供性函数重新加权 LLM 生成的计划,该函数可以估计每个行动计划在给定环境下的可行性;Inner Monologue:通过引入反馈回路进一步扩展了这一机制,系统不断向 LLM 发出信号,例如成功检测、场景描述或人工反馈,从而实现反思性、多轮推理和计划的动态调整;DoReMi:提出了一个双角色框架,其中 LLM 既生成高级计划,也生成显式的执行约束。这些约束由基于 VLM 的检测器在运行时监控,确保系统能够对动态突发事件做出反应;
然而外部模块难以灵活地提供与任务相关的信息,不能与 LLM 联合推理,且通常不足以处理复杂环境中的细粒度任务。为了应对这些挑战,后续研究转向了更自然的落地方法,即通过 VLM 将视觉输入直接融入规划过程。
PaLM-E:是一个大规模的具身化多模态语言模型,它将视觉、语言和机器人状态信息编码为单一多模态输入,从而实现统一。这种设计实现了感知的深度整合,使模型能够直接生成以感官输入为条件的规划;EmbodiedGPT:采用了由预训练组件和冻结组件组成的轻量级 VLM 架构,并使用参数高效的策略在自行构建的EgoCOT数据集上进行训练,降低了训练成本并增强可访问性;ViLa:使用GPT-4V作为规划器,表明基础模型的进步可以直接转化为 VLA 模型的改进,而无需额外的任务特定训练;3D-VLA和RoboMamba:通过将 3D 场景理解、空间布局和视觉可供性预测纳入规划循环,扩展了这一范式;
后续研究超越了基础理论,通过引入 记忆和反射机制,解决了长期复杂的任务。
BUMBLE和ReflectVLM:整合了这些机制,使系统能够处理相互依赖的子任务,并在多样化和复杂的环境中进行规划。这些类似智能体的能力标志着从孤立规划向更集成、更具适应性的行为的转变;
先前的论文将生成的语言规划限制在预定义技能集或脚本控制器的范围内,这限制了它们在处理复杂指令和开放式场景时的灵活性。为了克服这些限制并使其能够处理自由形式的提示,研究越来越侧重于 集成更稳健、更可泛化的低级策略。其中值得注意的是 Hi Robot 和 π 0.5 \pi_{0.5} π0.5 就是这种转变的典型例子。
Hi Robot 提出了一个分层框架,其中 高级 VLM 解释复杂的提示和动态用户反馈,生成由低级通用控制策略执行的自由形式语言命令。高级和低级组件的通用性使系统能够跨不同平台处理多阶段任务和情境校正。其后继模型 π 0.5 \pi_{0.5} π0.5 将规划器和控制器统一为一个 VLA 模型,该模型首先预测高级语义子任务,然后根据这些子任务生成连续的低级动作。通过对网络规模的异构数据进行训练,它可以执行长视界、开放世界的任务,例如清洁未见过的厨房,并具有出色的泛化能力。
虽然上述研究主要关注子任务层面的语言规划,但另一研究方向则将语言动作视为低级动作的细粒度语言学描述。该方向的代表性工作是 RT-H,它在视觉语言输入和动作输出之间引入了一个 语言动作的中间层,以促进跨不同高级任务的多任务数据共享。
RT-H:采用了一种分层架构,其中 VLM 首先根据指令(例如 “pick coke can”)预测当前的语言动作(例如 “move arm forward”),然后根据指令和预测的语言动作生成低级动作。这种方法提高了性能并实现了更有效的干预;NaVILA:将此思想应用于导航任务,它首先用自然语言生成中级空间命令,例如 “move forward 75 cm”,然后由视觉运动策略执行这些命令;
这些研究共同表明,通过明确描述空间和时间上的微动作,细粒度的语言动作可以为低级控制器提供精确且可解释的指导。其关键优势在于 能够在语言动作层面实现不同任务之间更好的数据共享,从而提高语言动作的合成、泛化能力和数据效率。此外,细粒度的语言动作也更便于人类根据当前场景进行纠正。
4.2. Advantages of Language Descriptions
- 使用语言描述作为动作 token 的主要优势在于它们可以与大型基础模型无缝集成。LLM 和 VLM 都拥有强大的开箱即用的理解、推理、规划能力,这使得零样本规划成为可能,并显著减少了针对特定任务进行训练的需求。它们还可以直接受益于情境学习、记忆、解码策略、搜索技术的持续进步。即使需要进行微调,语言描述与模型原生输出空间之间的一致性也能使整个过程比其他形式的动作 token 更高效、更少干扰,因为其他形式的动作 token 通常会受到更严重的模态不匹配的影响;
- 语言描述受益于丰富的协同训练数据。
PaLM-E和 π 0.5 \pi_{0.5} π0.5 的实证结果表明,基于此类数据进行协同训练可以将丰富的世界知识迁移到 VLA 模型中,从而提升泛化能力 - 语言描述尤其适合长期规划。如果 VLA 模型要执行复杂且时间较长的任务,语言描述几乎是必不可少的;
- 语言描述的可解释性有助于人类的监督和干预,从而增强安全性、透明度和可控性。
Hi Robot和YAY Robot等系统,体现了基于语言的规划如何实现人机交互校正和动态反馈的无缝集成。此外,通过在线人机交互收集的校正数据,可以用于随着时间的推移迭代地改进模型性能;
4.3. Discussion and Future Directions
使用语言描述作为动作 token 的一个局限性在于 其表达能力的不完善。虽然自然语言灵活且易于解释,但它本质上 具有歧义性,通常不足以指定细粒度的控制行为,尤其是在接触丰富或可变形的操作任务中,因为精确的空间和时间细节至关重要。这些问题可能导致系统组件之间的沟通不畅和任务基础不充分,这两者都会阻碍整体性能。
另一个限制因素是 延迟。生成高质量的语言描述通常依赖于大规模模型,而这可能会导致推理延迟,并限制其在动态或实时场景中的适用性。潜在的补救措施包括采用推理加速技术以及开发异步规划和执行框架。
抛开这些局限性,一个有前景的研究方向是主要利用语言描述进行高级规划,将复杂任务分解为更简单的子问题,然后利用 VLA 模型更有效地解决这些子问题,这些模型可以利用其他动作 token 格式,例如可供性(第 6 节)、轨迹(第 7 节)或目标状态(第 8 节)。这些表征为低级执行提供了更高的精度和效率,从而实现更可靠、更可扩展的具身智能。
5. Code as Action Tokens
VLA 模型面临的一个关键挑战在于 规划和控制复杂、长期操控任务,这些任务需要结构化推理和对动态环境的适应性。传统的动作表示,例如离散信号或直接语言命令,通常缺乏这种复杂性所需的表达能力。基于 Code 的 action token 应运而生,成为一种强大的替代方案。这些表示由可执行的代码片段或伪代码组成,其中包含条件语句和循环等控制结构。这种格式允许通过机器人控制 API 直接执行,使模型能够生成具有明确逻辑的模块化行为。它有效地支持分层规划和反应式控制。
代码相比其他动作格式具有显著优势。它提供清晰的逻辑结构,并可以利用丰富的第三方库,在高级指令和低级机器人原语之间建立了透明且可验证的桥梁。LLM 的最新进展使得 从自然语言和视觉输入中合成与任务相关的代码成为可能。这一范式促使越来越多的研究探索将代码作为机器人技术的结构化和可解释的动作表示。Table.3总结了使用基于 Code 的动作 token 的代表性 VLA 模型。
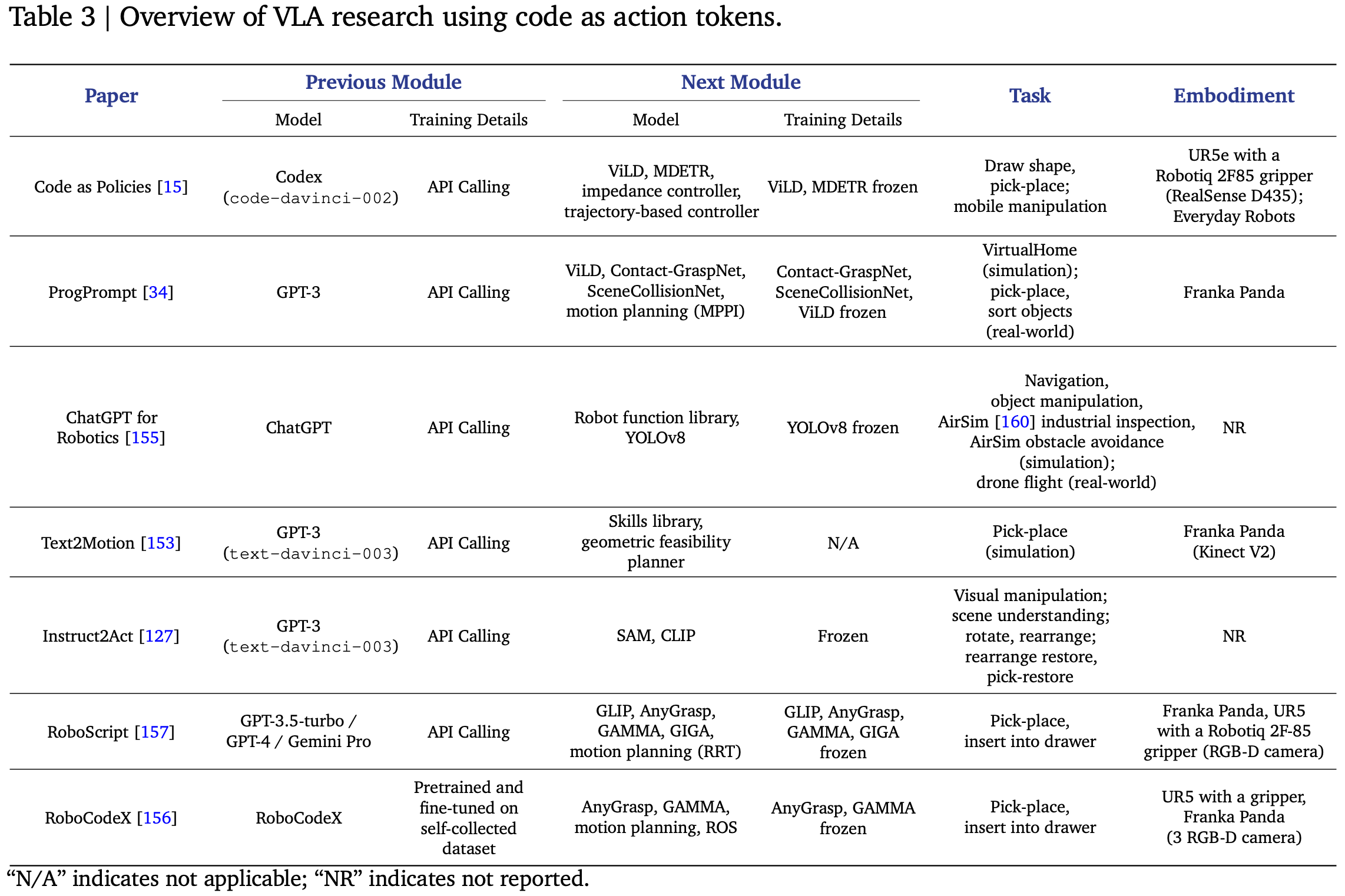
5.1. Evolution of Code-Based Action
两项基础研究开创了在 VLA 研究中使用基于代码的动作表示的先河:Code as Policy 和 ProgPrompt。
Code as Policy:利用GPT-3或Codex等 LLM 将语言指令映射到 Python 代码片段。生成的代码处理感知输入,参数化低级机器人 API,并在机器人平台上执行任务。其关键功能是能够与 NumPy 等第三方库自然集成,以执行复杂的空间推理。同时,该系统还能通过 从感知模块引导,有效地泛化到新对象。这种模块化特性使其策略代码能够通过新的指令和 API 适应新的行为;ProgPrompt:使用 有限状态机 (FSM) 框架扩展了代码生成过程,在提示中使用程序化结构来指导 LLM,它集成了导入声明来指定机器人功能、自然语言注释来构建高级推理,以及断言来验证执行状态。FSM 框架负责协调整体任务执行,它定义了明确的子任务转换,并使用了反应式触发机制,使系统能够适应动态的环境变化;
最近的研究通过整合常识推理和改进生成代码在物理世界中的落地性,扩展了基于代码的动作 token。机器人领域的 ChatGPT 探索了多种提示策略,如自由形式对话、代码提示、XML 标签、闭环推理,以更好地解析人类意图。为了生成更有效、更扎实的代码,强调了提示中描述性 API 名称和清晰的任务规范的重要性。至关重要的是,生成的代码要经过人在环的验证过程,在此过程中对其质量和安全性的反馈将用于迭代改进,然后再最终部署到机器人上。为了解决 “Code as Policies” 中的感知限制,有两项具有代表性的工作:
Instruct2Act:使用专门的多模态基础模型增强了编码 LLM,以实现精确的对象分割和开放词汇分类。通过卸载感知和语义理解,Instruct2Act有效地将高级语言指令落地为精确、可执行的策略代码;RoboCodeX:进一步推进了多模态集成,专注于融合来自不同来源的信息,例如各种场景数据集、各种对象数据集和程序性任务描述。引入了一种新颖的思维树框架,通过结合视觉、语言和物理线索来合成行为。该模型的推理能力通过在专门构建的多模态数据集上进行微调得到增强,从而实现更准确、更通用的机器人动作;
基于代码的动作 token 对于高级规划和任务泛化也非常有效,如处理长周期任务。
Text2Motion:利用GPT-3生成定义任务成功的有效目标状态,从而为规划提供明确的终止标准。为了实现这一目标,该框架采用了混合规划器,将射击搜索规划与贪婪搜索规划相结合以提高效率,并实现可靠的回退;RoboScript:引入了统一的代码生成流水线,该流水线标准化输入并集成了各种感知和运动规划工具。这种设计显著增强了代码的灵活性和跨各种机器人的适应性,解决了此类生成规划的实际部署问题;Chain-of-Modality:(非 VLA 模型)引入了一种新颖的提示策略,引导 VLM 推理多模态人体演示(例如,肌肉或音频信号),以生成机器人可执行的代码,进一步拓展泛化的边界;
5.2. Brittleness and Challenges
尽管基于代码的动作 token 具有诸多优势,但它们也面临着一些重大的实际限制,其表达能力本质上 受限于预定义感知和控制 API 库的功能。当机器人遇到高度动态、模糊或先前未观察到的环境时,预先设定的 API 可能不足以准确捕捉或表达所需的新行为。系统 在复杂的开放世界环境中的适应性和探索能力受到限制,如果 API 没有提供诸如 “slippery surfaces” 或 “fragile objects” 等环境特征的抽象,即使是编写完美的代码,也难以生成此类场景所需的细致动作。
这种对僵化符号表示的依赖也会导致执行的脆弱性。机器人策略不仅容易受到 LLM 内部生成错误的影响(例如,生成逻辑不一致或低效的代码);而且当现实世界的环境状态违反 API 预设的前提条件时容易失效。这是符号基础问题的核心体现,代码中的抽象符号无法可靠地映射到复杂的现实世界感知,例如,一段控制机械臂进行抓取的代码可能假设物体表面始终是干燥且平坦的,如果实际物体是湿的或形状不规则的,那么这段代码虽然语法正确但可能会导致抓取失败、物体损坏,甚至硬件损坏。这种固有的脆弱性直接转化为巨大的安全风险,因为看似无害的代码命令可能在不可预见的情况下引发严重事故。
5.3. Future Directions
未来工作的一个有前景的方向是开发全面的 API 函数库,以充分释放基于代码的动作 token 的潜力。这样的框架应该集成丰富的模块化功能,包括多模态感知 API(例如,物体检测和跟踪)、推理模块(例如,空间关系分析)以及强大的动作原语。通过提供结构化且可靠的接口,该框架将使 VLM 能够充当高级协调器,生成可执行代码来组合这些原语,以解决现实世界中复杂且长期的任务。
未来的第二个方向是 将形式化验证融入整个代码生命周期以增强稳健性。这包括验证 API 库的一致性和安全性,以及开发动态验证 LLM 生成代码的方法。逻辑推理和约束满足可以指导安全的代码生成,而静态分析和模型检查则可以在部署前捕获错误或证明其安全性;最后,运行时监控可以确保 API 的先决条件得到满足,并在发生异常时触发安全关闭或恢复。
另一个前沿领域是 利用代码的可解释性来实现有效的人机协作。与黑盒模型不同,代码的透明性使人类能够理解并干预机器人的逻辑。这支持两种关键范式:交互式调试(可实时追踪和修复故障)和协作式改进(人类以迭代方式指导程序改进)。这种“人在环”系统对于开发不仅功能强大,而且值得信赖且可控的机器人代理至关重要。
6. Affordance as Action Tokens
在 VLA 范式中,可供性 affordance 是结构化且基于空间的动作 token,连接着视觉感知和物理交互。近期研究表明,可供性表征利用 VL 基础模型的空间推理能力识别可操作区域,并基于多模态输入评估物理可行性。通过抽象出特定于具体化的控制机制,可供性增强了跨平台泛化能力,允许在各种机器人系统上执行相同的高级指令,明确地编码了与任务相关的交互信息,例如抓取点或可操作表面,这使得它们在现实世界中 以对象为中心的操作中尤为有效。
可供性可以以多种形式表达,每种形式都能提供关于机器人如何与其环境中的物体交互的独特见解。近期研究主要探索关键点 keypoints、边界框 bounding box、分割蒙版 segmentation masks 、可供性图 affordance maps。Table.4 中总结了这些成果。对于像厨房清洁这样接触频繁的任务,表示形式的选择至关重要。
- Keypoints:提供精确的目标,非常适合精确定位碗的边缘,以便抓取或按下洗碗机的小按钮;
- Bounding Box:提供更简单、粗略的定位,足以用于一般的物体选择;
- Segmentation Masks:捕捉物体的精确轮廓,对于需要细粒度交互的操作更友好,例如擦拭碗的不规则内部;
- Affordance Maps:提供了对交互可能性的密集、场景级理解,同时突出显示所有可抓取或可擦除区域,从而实现跨多个物体的更复杂的空间推理。
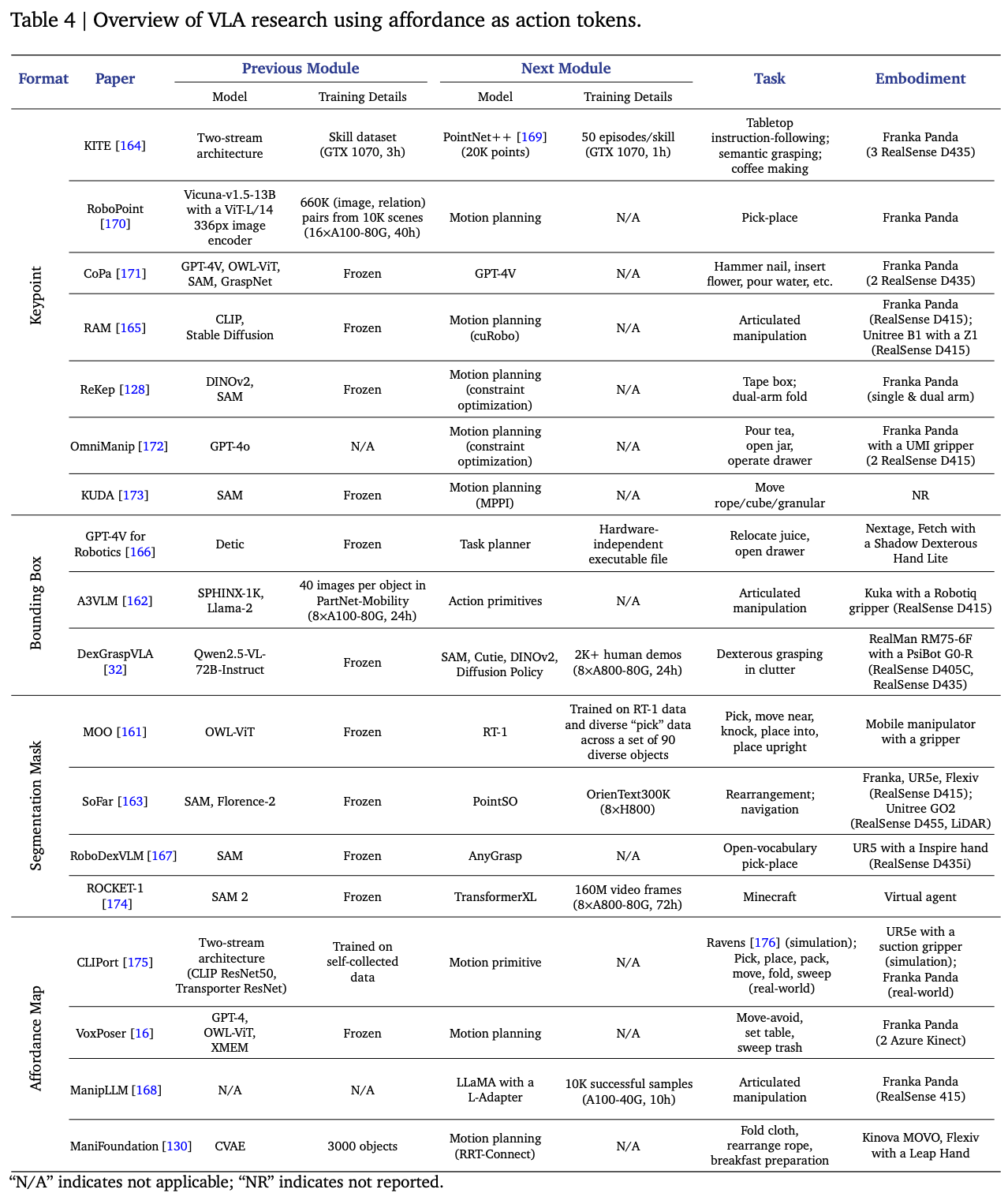
可供性表征的选择需要在交互精度、计算复杂度和任务需求之间进行根本性的权衡。
6.1. Keypoints: Precise Interaction Anchors
关键点为交互目标(例如对象手柄或接触边缘)提供了紧凑而精确的表示。通常定义为 k = [ x , d ] \mathbf{k=[x,d]} k=[x,d],其中 x , d ∈ R 3 \mathbf{x,d}\in\mathbb{R}^{3} x,d∈R3, x \mathbf{x} x 表示空间接触位置; d \mathbf{d} d 表示交互方向。得益于 VLM 的精确空间定位能力,一些早期的 VLA 模型已采用关键点将视觉语言感知与控制级执行直接关联。
KITE:通过预测与语义对象部分对应的任务相关关键点,将语言指令定位到视觉场景中。这些关键点随后被用于条件技能以执行低级动作;RoboPoint:在此基础上构建了一个合成数据集,用于对 VLM 进行指令调优,使其能够进行空间推理,从而使模型能够识别满足关系约束的点,然后通过运动规划来执行这些点;CoPa: 通过将来自可变学习模型 (VLM) 的常识先验纳入由粗到细的接地流程,进一步增强了空间接地。该流程首先识别合理的交互区域,然后将其细化为可操作的空间约束,用于后续的运动规划;KUDA:引入了两级闭环控制机制,以促进基于模型的鲁棒规划,使用可变学习模型 (VLM) 生成包含关键点及其对应目标位置的任务规范。然后,这些规范被公式化为成本函数,用于指导两级控制器的优化。该系统采用了基于检索的提示库,增强了少样本适配和系统鲁棒性;
关键点也已被纳入包含任务语义、关系约束和跨领域知识的结构化框架中。
RAM:通过从各种域外数据集构建可供性记忆来解决域内数据收集的成本问题,使用 VFM 进行语言条件下的相关演示检索,通过概率提升将二维关键点转换为三维,从而实现在新环境中的零样本操作;ReKep:将操作形式化为对跟踪关键点的约束优化问题,其中任务目标被编码为 Python 函数,这些函数在机器人和物体之间施加几何和关系成本。分层求解器规划 SE(3) 子目标并通过滚动视界控制优化动作,支持具有高时空复杂度的双手和人在环交互;OmniManip:引入了一种以对象为中心的规范化过程,将对象映射到功能空间。在这个结构化空间中,关键点充当推理原语,VLM 可基于此预测空间约束和交互目标。为了缓解幻觉和执行漂移,它集成了一个自校正循环,用于渲染结果并重新采样交互点,同时由一个双层控制器负责高级规划和细粒度的姿态跟踪;
一个新兴方向是 将静态关键点扩展为时间序列,从而有效地将其转换为基于轨迹的动作 token。这种演进使系统不仅能够表示行动的位置,还能表示行动如何随时间展开。
Magma和VidBot:能够根据任务指令和视觉观察预测关键点位置序列,从而捕捉细粒度的时间动态,以实现以对象为中心的操作。通过对基于时间的关键点进行建模,这些系统支持更长远的推理,并实现时间一致的动作规划。
这种时间扩展增强了表达能力和规划能力,在空间可供性和轨迹级表示之间架起了一座天然的桥梁。
6.2. Bounding Boxes: Coarse Grounding
边界框为视觉场景中的实例级定位提供了一种粗略但高效的表示。二维边界框通常定义为 B = { ( x t l , y t l ) , ( x b r , y b r ) } \mathcal{B}=\{(x_{tl},y_{tl}),(x_{br},y_{br})\} B={(xtl,ytl),(xbr,ybr)},标记图像平面的左上角和右下角。在三维空间中,边界框通常由八个空间角点 { ( x i , y i , z i ) ∣ i ∈ ( 1 , … , 8 ) } \{(x_{i},y_{i},z_{i})|i\in(1,\dots,8)\} {(xi,yi,zi)∣i∈(1,…,8)} 表示,用于编码物体在场景中的物理范围。虽然这些表示缺乏细粒度的几何细节,但它们提供了鲁棒性和计算简单性。强大的开放词汇检测器(例如 Grounding DINO、Detic 和 OWL-ViT)和视觉语言模型(例如 Qwen2.5-VL)的出现,通过基于自由形式语言查询将对象有效地定位到边界框中,在视觉理解和物理操作之间建立了牢固的联系。
一些 VLA 模型利用 边界框将语言指令锚定到以对象为中心的视觉输入中。
DexGraspVLA:通过定位目标对象的领域不变边界框来锚定领域变化的指称表达式,然后将其转换为分割掩码。这些掩码使用Cutie进行时间跟踪,从而在整个抓取过程中实现时间一致的视觉锚定。
该流程体现了近期研究中的一个更广泛的趋势:使用边界框作为模块化接口,将指称语言与空间局部化的对象表征连接起来。边界框作为一种高效的感知抽象,简化了从语言到可操作视觉输入的映射,从而能够在开放词汇环境中进行任务规范,而无需密集监督。
除了通过语言指令进行物体定位之外,边界框还可以支持交互推理和后续动作生成。Wake 等人使用 GPT-4V 处理人类演示视频,整合手部和物体边界框,通过空间接近度检测抓取和释放事件。
这些时空线索是提取可供性相关信息(包括抓取策略和路径点轨迹)的基础,这些信息随后被转换为机器人可执行代码。
A3VLM:使用由 3D 边界框、运动轴和语义标签组成的结构化三元组来建模物体关节。为了预测该三元组,它引入了一个物体级关节标注数据集,并使用投影层对Llama-2-7B模型进行了微调,这种与机器人无关的表示可以通过简单的动作原语直接转化为低级机器人动作,从而实现跨平台的泛化和显著的操控性能。
6.3. Segmentation Masks: Pixel-Level Regions
分割 mask 提供高分辨率的空间表征,能够捕捉细粒度的物体轮廓和部件级几何形状,从而能够精确地确定功能区域,例如可擦拭表面或可抓取区域。mask 的正式定义为二元矩阵 M ∈ { 0 , 1 } H × W \mathbf{M}\in\{0,1\}^{H\times W} M∈{0,1}H×W,提供的像素级细节超越了边界框等较粗的抽象。随着 SAM 和 Florence-2 等基础模型的出现,语言条件分割的质量和泛化能力得到了显著提升。最近的 VLA 模型利用这些能力从文本指令中提取可供性对齐的物体区域。
MOO:利用OWL-ViT提取物体表征,并将其与文本指令融合,为开放世界操控任务中的策略学习提供信息;SoFar:使用 SAM 分割物体蒙版,然后使用它们构建以物体为中心的点云和方向感知的场景图。这些表征引导PointSO预测功能方向(例如,“handle facing up”)并支持结构化空间推理。RoboDexVLM:采用由粗到细的细化流程来获取高质量掩码,这些掩码可用于通过AnyGrasp预测末端执行器的抓取姿势。
总之,这些方法表明,分割掩码提供了结构化的、任务对齐的表征,能够在接触丰富的操作任务中连接感知和控制。近期的一个方向探索了将分割掩码用作时间锚定的交互界面。
ROCKET-1:引入了一个分层系统,该系统利用通过SAM 2提取和跟踪的跨时间分割序列作为持久的视觉提示。这些时间锚定的掩码支持动态环境中的高级推理和连贯的动作选择,从而能够在没有固定任务模板的情况下实现鲁棒的对象操作。
6.4. Affordance Maps: Dense Spatial Fields
可供性图将场景表示为空间场,为每个区域分配特定动作的分级适用性分数,以反映先前的交互意识。通常被表示为 A ∈ R H × W \mathbf{A}\in\mathbb{R}^{H\times W} A∈RH×W,其中 H H H 和 W W W 表示空间分辨率。这些图对物体几何形状、表面拓扑结构和特定任务的先验进行编码,从而实现密集且以指令为条件的交互推理。
CLIPort:采用双流网络融合语义和空间特征进行可供性预测,指导精确的拾取-放置动作;IGANet:学习生成以语言输入为条件的像素级可供性分布,使同一物体能够在不同的指令下做出不同的动作;VoxPoser:扩展了这一概念,它促使 LLM 以代码形式合成可供性和约束规范,然后通过 VLM 感知空间形成 3D 值图。这些图无需重新训练即可实现针对不同任务和对象的零样本轨迹合成;
除了空间基础之外,可供性图还 支持对物理接触和操作动力学进行推理。
ManipLLM:将可供性图纳入多模态思维链框架,利用它们编码区域级先验信息,指导操作感知姿态的生成。这些可供性图指示了哪些动作最有可能引发有意义的物体运动,从而提高了复杂场景中的精度和稳定性;ManiFoundation:进一步扩展了这一工作思路,将操作视为接触合成,利用力和运动热图来表示以接触为中心的可供性。这些可供性图编码了接触应发生的位置、施加的力以及预期的运动轨迹,从而能够对刚性和可变形物体进行鲁棒的接触预测。随着任务复杂性的增加,这种结构化的可供性先验信息为将低级控制应用于物理现实交互领域提供了一种可扩展的解决方案。
6.5. Discussion and Future Directions
尽管基于可供性的动作 token 具有诸多优势,但它们仍面临一些限制,影响了其在现实世界操控中的有效性。
- 大多数 VLA 模型 依赖二维图像表征,这不足以捕捉精确控制所需的三维几何形状和空间关系。尽管
A3VLM和SoFar等模型融合了部分三维信息,但它们在涉及复杂物体形状和遮挡的任务,以及动态(例如,将组件插入移动的组件中)或精细(例如,细粒度的零件组装)操控中常见的场景中仍然显得力不从心; - 可供性 token 通常编码 静态物体属性,例如 ““graspable handle” 或 “closeable door”,而没有对这些可供性如何随时间演变进行建模。这些限制削弱了它们在需要对变化的可供性状态进行持续推理的、接触密集型任务中的有效性;
- 可供性表征容易受到 遮挡和运动模糊等视觉干扰 的影响,关键点在遮挡下会显著降低精度,而分割 masks 在视觉挑战场景中会失去准确性,从而影响操作性能。
为了应对这些挑战,作者确定了三个有前景的研究方向。
- Learning True 3D Affordances:超越二维或投影三维,直接在原生三维表征中学习可供性。通过将策略建立在神经辐射场、三维高斯溅射或显式网格等结构上,模型可以对物体的几何形状、自由空间和遮挡形成整体理解。这种方法将为目前难以实现的复杂任务提供强大的推理能力,例如将零件插入隐藏的空腔或在杂乱的环境中操纵非刚性物体;
- Modeling Temporal Affordance Dynamics:未来的模型应该学会预测动作如何随时间改变物体的可供性。例如,模型应该推断执行 “lift lid” 的动作会将可供性状态从 “openable” 转换为 “pourable”。这种时间推理对于实现长期规划以及成功完成接触丰富的连续任务至关重要;
- Enhancing Policy Robustness and Uncertainty-Awareness:现实世界的部署需要策略能够抵御视觉模糊性,并意识到自身的局限性,模型应该使用高级数据增强等技术进行训练,以提高对视觉干扰的鲁棒性。策略应该通过输出概率可供性来量化自身的不确定性;
7. Trajectory as Action Tokens
扩展 VLA 模型的核心挑战之一在于 机器人数据有限,尤其是带有动作标签的数据。为了解决这一限制,近期有研究提出利用 域外视频数据,然而这些数据通常缺乏明确的动作注释。此类研究使用轨迹作为动作表征的代理,因为它们易于从视频中提取,并且能够在整个操作过程中封装丰富的可操作信息。Table.5 中总结了基于轨迹的代表性方法。与其他研究提出的潜在表征(第 9 节)相比,轨迹是一种相对明确的动作表征,易于人类解释和理解,从而有助于训练和调试。VLA 研究的另一个主要挑战是任务泛化。例如,以基于语言的动作 token 为条件的策略通常难以在具有相似低级运动模式的语义不同任务中推广零样本训练,例如从 “wiping a table” 推广到 “sliding a block on a desk”。相比之下,轨迹条件策略在这些任务中表现出更强的泛化能力,RT-Trajectory 就证明了这一点。
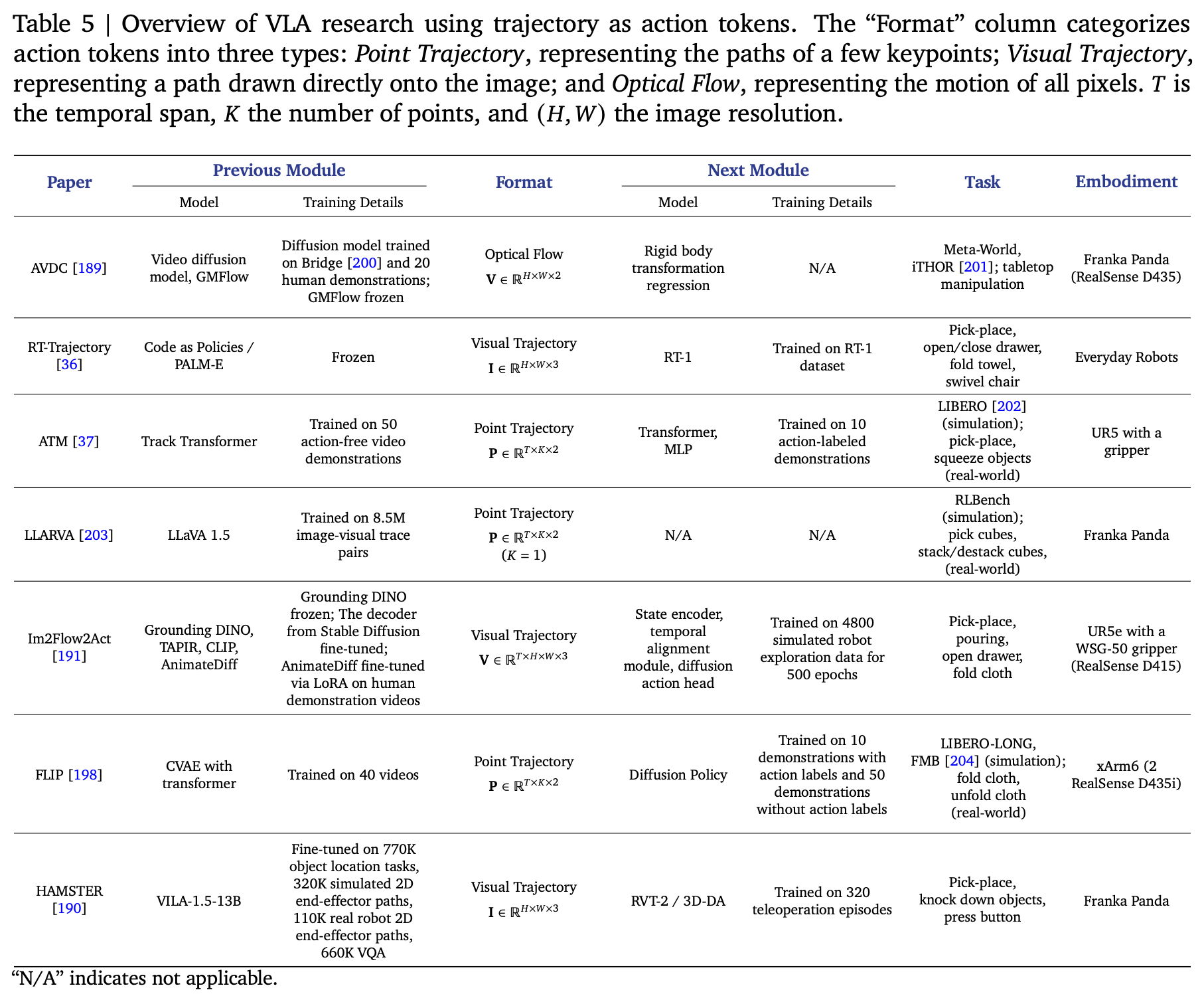
7.1. Overview of Trajectories
基于轨迹的动作 token 可以分为三种不同的形式:点轨迹、视觉轨迹、光流。每种形式都以不同的抽象程度和信息密度来表示运动。
- Point Trajectory:是最直接的方法,将动作编码为离散点序列,表示为 P ∈ R T × K × 2 \mathbf{P}\in\mathbb{R}^{T\times K\times 2} P∈RT×K×2。该方法对 K K K 个关键点在时间跨度 T T T 内的路径进行建模,从而提供有针对性且数值精确的引导。在自动驾驶中,模型可以预测鸟瞰 (BEV) 空间中的未来车辆路径点。对于机器人操控任务,它们可以生成图像平面内末端执行器或物体的二维坐标路径。
- Visual Trajectory:直接将路径渲染到像素空间中。输出的不仅仅是一串坐标列表,而是一幅新的图像或视频,其中以视觉方式描绘了预期的运动。这可以通过将点序列叠加到观察帧上来实现,记为 I ∈ R H × W × 3 \mathbf{I}\in\mathbb{R}^{H\times W\times3} I∈RH×W×3,或者通过生成视频流来实现,该视频流随时间变化呈现为可见的曲线,例如 I ∈ R T × H × W × 3 \mathbf{I}\in\mathbb{R}^{T\times H\times W\times 3} I∈RT×H×W×3。这种形式具有很强的可解释性,因为它在视觉语境中展现了动作。
- Optical Flow:提供了最稠密的表示,其形式为运动场 V ∈ R H × W × 2 \mathbf{V}\in\mathbb{R}^{H\times W\times2} V∈RH×W×2。该场描述帧间每个像素的运动,捕捉整个场景的整体动态,而非单一路径。通过将场景的集体运动视为动作信号,该方法可以隐式地建模复杂的多对象交互。
7.2. Progress and Key Papers
数据稀缺长期以来一直是机器人技术的瓶颈,基于轨迹的动作 token 提供了一种解决方案,从丰富的域外视频中学习。
AVDC:使用基于人类或机器人演示视频训练的扩散模型来预测未来帧,并使用预训练模型生成光流,利用深度信息指导下游控制。然而这种方法计算成本高昂,且容易产生幻觉;ATM:通过预测任意点的轨迹来缓解这些问题,并且只需要少量域内动作 token 数据即可进行低级策略训练;Im2Flow2Act:不需要现实世界的机器人数据。它学习从人类演示视频中生成视频轨迹,并使用模拟数据训练轨迹条件策略;Im2Flow2Act:专注于对象流而非任意点流,以此来弥合表现差异;FLIP:集成了一个基于视频构建的世界模型,包括动态、动作和价值模块。它执行基于模型的规划,并根据流和视频规划预测动作。与ATM相比FLIP采样了更密集的流点并获得了更好的性能,证明了密集流在低级控制中的有效性;
基于轨迹的动作 token 在跨任务以及视觉和语义变化方面表现出强大的泛化能力,即使任务在语义上截然不同,轨迹空间中共享的运动模式也能实现跨任务泛化。
RT-Trajectory:通过粗略的二维或 2.5 维末端执行器运动轨迹对任务进行编码,并以此为条件设置端到端策略(即RT-1)。在未见任务上,RT-Trajectory的表现优于RT-1、RT-2和RT-1-Goal(以目标图像为条件的RT-1);HAMSTER:采用分层架构,使用 VLM 合成二维轨迹,并设置以三维观测为条件的低级策略。这种结构有利于在大规模异域数据集(如RoboPoint)上进行微调,从而提高其视觉和语义泛化能力;
另一个方向侧重于基于以轨迹为中心的数据对大型模型进行预训练。
LLARVA:通过指令调整构建了统一的机器人 LLM,融合了控制模式、任务和本体感受等结构化信息。它以文本形式输出二维轨迹和机器人动作,展现出跨控制模式的更高灵活性。尽管利用了Open X-Embodiment(OXE) 中的 850 万个视觉-动作对,但其规模仍然小于传统的 LLM/VLM 数据集;ARM4R:引入了一种三阶段训练范式:在EPIC-KITCHENS-100上进行预训练,在 1-2K 个机器人演示上进行微调,以及预测本体感受状态。其四维轨迹表示使其性能优于LLARVA和ATM;Magma:是 UI 导航和机器人操作的基础模型,它在具有 Set-of-Mark 和 Trace-of-Mark 的异构数据集上进行训练,赋予其时空推理能力,超越了仅在机器人数据上训练的 VLA 模型(如OpenVLA);
7.3. Trajectory-Related Data
各种类型的数据都可用于训练基于轨迹的 VLA,例如互联网规模的视觉语言数据集、人类视频和现有的机器人数据。网络规模的视觉语言对可以将广泛的常识融入策略中。一些方法利用 VLM 直接输出关键点序列,这需要在协同训练阶段使用视觉语言数据集(例如物体定位任务)来保持 VLM 的泛化能力。人类和机器人演示进一步提供了具体的可操作知识。轨迹标签可以直接从现有视频中提取,无需人工注释。一种选择是使用点跟踪工具,例如 CoTracker、TAPIR,或 RAFT 使用的光流方法。另一项工作,例如 RT-Trajectory,使用末端执行器状态从机器人演示中提取 2.5 维轨迹。无论哪种方式,所有现有的演示数据集,无论是人类、模拟还是真实机器人,都可以轻松利用。在自动驾驶领域,也可以使用类似 CoVLA 中的流程自动生成轨迹和字幕,该流程将基于卡尔曼滤波器的轨迹预测与基于规则和 VLM 驱动的字幕相结合。
7.4. Discussion and Future Directions
尽管基于轨迹的动作 token 具有诸多优势,但它们仍面临一些关键挑战。作者确定了三个主要领域:3D 空间理解、计算效率、任务适用性。大多数工作使用 2D 轨迹,但 2D 轨迹缺乏明确的 3D 信息。这可能会引入歧义,并限制其在非平面任务中的适用性。深度数据是关键的补充:AVDC、RT-Trajectory 和 HAM STER 都结合了深度信息来缓解这一问题,并提供更丰富的 3D 理解。然而,一个更根本的挑战是,点轨迹通常仅编码位置。它们忽略了关键的方向信息,使其不适用于复杂的灵巧操作任务。未来的工作可以探索将完整的 3D 空间信息集成到轨迹表示中。
另一个重大挑战是计算效率。许多方法采用生成模型来预测轨迹或视频,但这些模型的训练和推理计算成本高昂。其他方法利用可变长度模型 (VLM) 来预测轨迹,但 VLM 通常以较低频率输出航点,不足以实现平滑控制。一种解决方案是使用传统的规划方法将这些稀疏输出细化为高频控制信号。为了避免在每个时间步重新规划,其他方法会预测一次完整轨迹,并使用时间对齐模块进行实时执行。开发轻量级且富有表现力的轨迹生成模型仍然是一个关键的研究方向。
最后,轨迹的适用性取决于任务和环境。轨迹擅长于由精确运动路径定义的任务,例如擦拭表面或导航。然而,在无法预先规划完整路径的部分观察环境中,轨迹的效率较低。此外,对于涉及复杂交互逻辑的任务,轨迹缺乏丰富的语义,并且本身无法捕捉诸如施加力或理解物体可供性之类的概念。一个有希望的未来方向是创建混合动作 token,将轨迹 token 与语义概念(例如 “grasp”、“increase force”)相结合,使机器人能够处理更广泛、更复杂的任务。
8. Goal State as Action Tokens
当人类处理操作任务时,人类的大脑并非只是将原始感知直接转化为行动,相反会经常进行心理模拟,在执行任何步骤之前预想期望的结果。例如,如果被要求 “clean up the table”,人们首先会概念化一个整洁有序的桌子,然后逆向思考以确定必要的操作。受这种强大的人类认知策略的启发,越来越多的 VLA 模型研究提出利用预测目标状态(任务预期结果的视觉表示)作为中间动作 token。这些研究,包括 3D-VLA、FLIP 和 VPP 等最新进展,旨在通过将“要做什么”以视觉丰富且可解释的形式呈现,来弥合高级指令和低级操作之间的差距。
通常,使用目标状态作为动作 token 的模型采用分层架构。高级模型(通常是像 DiT 或 CVAE 这样的生成模型)负责根据当前观察和语言教学条件合成目标状态。然后,生成的目标状态会调节低级模型(例如扩散策略或MLP),后者将其转换为最终的动作序列。这种设置有效地将目标状态确立为一个关键的心理模拟步骤,位于理解指令和合成动作之间。根据时间维度,目标状态大致可分为两类:单帧图像和多帧视频,Table.6 列出了本节讨论的主要方法。
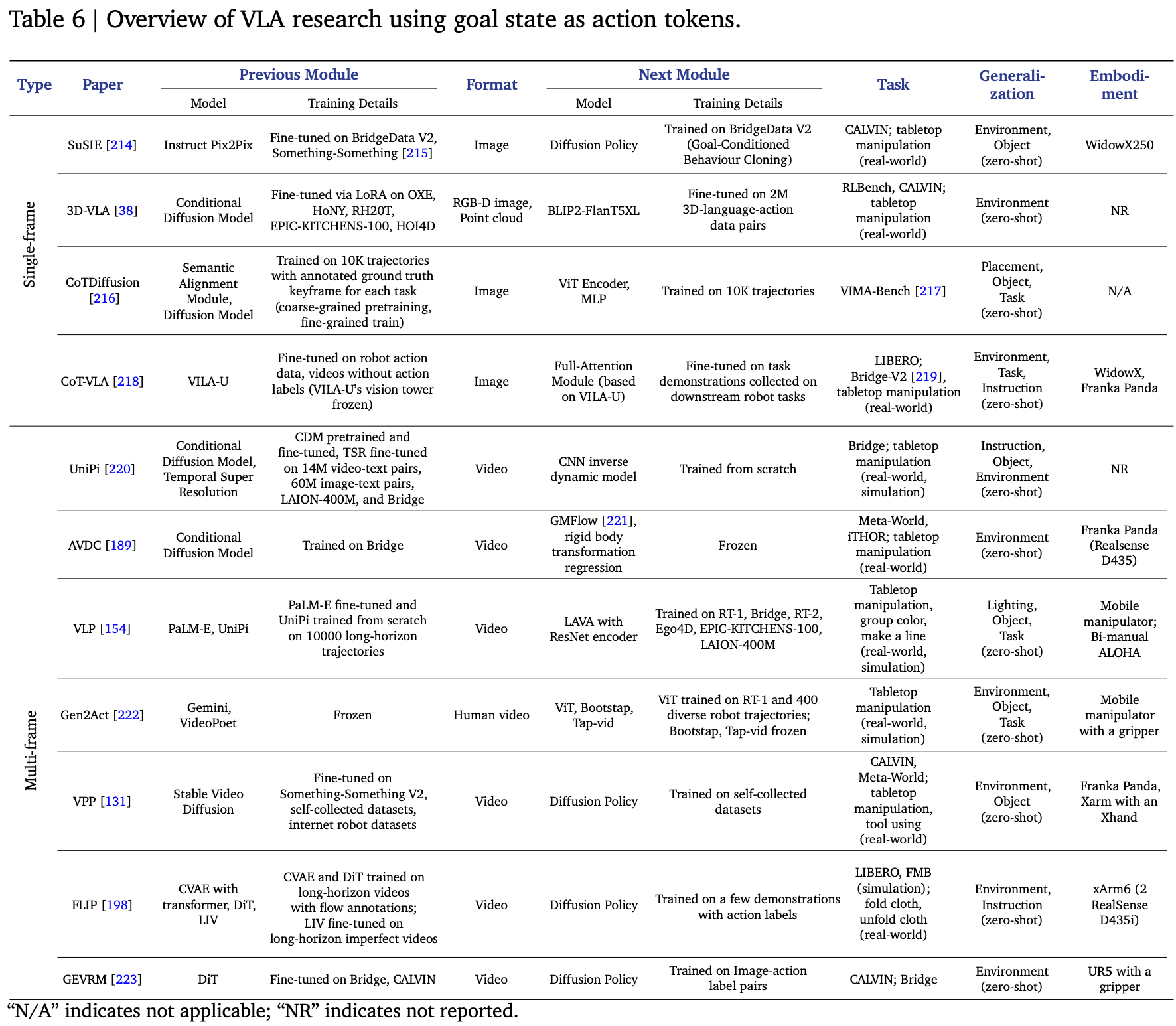
8.1. Single-Frame Image as Goal State
单帧目标状态通常采用二维 RGB 图像、2.5 维 RGB-D 图像或三维点云的形式来描绘整个目标场景,正如近期研究所示,这具有许多关键优势。
LangLf P:展示了如何利用目标图像的方法通过事后重标记轻松实现数据可扩展性。该技术提取未分段的机器人游戏数据流,自动采样短窗口,并将每个窗口的最终帧视为目标图像。此过程自动生成带有目标图像注释的大规模机器人动作数据集,完全无需手动标记;
基于目标图像在数据扩展和低级控制方面的实用性,后续研究集成了高级目标图像生成,以创建完整的分层 VLA 模型。
SuSIE:首先利用一个简单的图像生成模型进行视觉语义推理,然后再采用低级策略来确定精确的运动驱动;
高级扩散模型根据语言指令生成目标图像,低级DDPM将这些图像解码为所需的动作序列。
CoTDiffusion:通过集成语义对齐模块进一步扩展了SuSIE的分层扩散架构,使扩散模型能够评估自身的任务完成进度。
使用目标图像的另一个显著优势是,它们能够利用无动作视频来训练高级目标图像生成器。
CoT-VLA:利用无动作人类视频来训练其目标图像生成器。与上述基于扩散的架构不同,CoT-VLA中的两个阶段都是自回归 VLM,高级模型使用因果注意力来合成目标图像,而低级模型使用非因果注意力来生成相应的动作序列;3D-VLA:以及类似的研究将单帧目标状态扩展至 RGB-D 图像和点云。通过利用深度和 3D 几何结构丰富视觉编码,这些方法能够对任务目标提供更精准、更丰富的感知描述;
8.2. Multi-Frame Video as Goal State
与单帧目标状态相比,多帧目标状态(如短视频)提供了更丰富的时间背景。通过捕捉场景的演变,这一额外的时间维度提供了至关重要的 “how-to-do” 提示,显著减少了执行的模糊性,并提供了更细粒度的运动信息。该领域的研究通过各种创新利用了多帧目标状态:
- Generating from Large-Scale Data:一种方法侧重于从海量数据集生成未来视频内容,为行动提供指导;
UniPi:率先使用互联网规模的数据生成文本条件视频,然后使用逆动力学模型 (MLP) 根据这些预测的视频序列计算动作;
- Extracting Implicit Action Cues from Videos:其他研究则专注于直接从生成的目标视频中提取显式或隐式的动作相关信息;
AVDC:使模型能够利用视频中的密集对应关系,而无需依赖任何动作标签。它通过使用扩散模型来合成未来的视频帧,然后从这些帧中提取密集的像素级光流,从而指导底层策略。该方法有效地将视觉运动转化为可操作的指导;
- Enhancing Generalization and Robustness:为了提升模型的泛化能力和鲁棒性,多帧目标状态也被探索。鉴于特定于具体化的策略会限制更广泛的泛化;
Gen2Act和FLIP:通过生成人类执行的目标视频(而非机器人特定的视频)来增强跨具体化的泛化能力,从而减少了对机器人特定微调的依赖;GEVRM:引入了一种辅助状态对齐损失,专门用于提高对外部扰动的鲁棒性;
- Strategies for Complex Long-Horizon Tasks:对于复杂的长期任务,研究人员通常采用两种主要方法;
Gen2Act:直接利用 LLM 将长期任务分解为较短的子任务,然后对每个较短的子任务运行相同的模型。第二种方法涉及使用多个候选目标视频来改进规划;VLP:使用单独的 VLM 生成并评分多个候选目标视频,使用类似波束搜索的算法为子任务选择最优的长期策略;FLIP:采用语言图像评估模型 (LIV) 来评估候选的人类执行目标视频(由DiT网络根据关键点轨迹合成),然后使用类似波束搜索的算法选择最佳的长期策略。这些方法展示了基于多帧目标的复杂规划能力;
8.3. Advantages of Goal State
目标状态具有多项关键优势,能够显著提升其作为行动令牌的有效性。
- data scalability:目标状态提供了卓越的数据可扩展性,通过事后目标重新标记实现。允许通过从原始机器人轨迹中提取单帧和多帧目标状态来自主生成大量训练数据集,从根本上绕过动作注释瓶颈;
- broader training data sources and enhanced generalization capabilities:使用目标状态可以解锁更广泛的训练数据源并增强泛化能力,生成器可以利用大规模无动作视频数据来学习现实世界的动态,从而提高整体泛化能力;基于人类执行的目标状态(例如
Gen2Act)进行训练,尤其能够提升它们的跨具体化泛化能力,增强跨不同机器人平台的知识迁移; - task specificity:目标状态还能增强任务的针对性,通过编码高度精确的空间和视觉信息充当清晰的动作 token,减少复杂任务中的歧义,为底层策略提供精确的视觉指令以实现细粒度的动作执行。
- robust interpretability:此类模型还拥有强大的可解释性 ;它们的白盒训练和推理过程使人类的理解、调试和干预更加可行;
- straightforward evaluation:目标状态易于直接评估 ,现成的语言图像评估模型,例如
FLIP中改编的模型,可以通过检查目标状态与语言指令的一致性来轻松评估目标状态的质量;
8.4. Limitations and Future Directions
尽管目标状态具有显著的优势,但它本身也存在一些局限性。
- Generating high-quality and consistent goal states remains challenging,:生成高质量且一致的目标状态仍然具有挑战性,通常表现为过度规范或完全不准确。
- 过度规范:当生成的目标状态包含不必要或过于精确的细节时,就会出现过度规范的情况。这会导致低级策略关注琐碎的细节,过度限制其灵活性,甚至如果这些细节并不重要,则会使任务更难完成,从而削弱策略对环境或任务执行中细微变化的泛化能力。为了缓解这个问题,
VPP通过使用其高级扩散模型仅执行单个去噪步骤来合成目标视频,仅传达粗略的动作,并省略一些细粒度的细节,从而部分缓解了过度规范的情况; - 完全不准确:生成的目标状态从根本上是不正确的、与期望结果不一致、物理上不可信,或者由于动态建模不足而表现出时间和空间上的不一致性。这种错误的目标直接提供了误导性的指导,不可避免地导致低级策略尝试错误的行动从而导致任务失败;
- 过度规范:当生成的目标状态包含不必要或过于精确的细节时,就会出现过度规范的情况。这会导致低级策略关注琐碎的细节,过度限制其灵活性,甚至如果这些细节并不重要,则会使任务更难完成,从而削弱策略对环境或任务执行中细微变化的泛化能力。为了缓解这个问题,
- generating future images or videos inherently introduces high inference latency:由于计算开销巨大,生成未来图像或视频本身就会导致较高的推理延迟。
AVDC:需要大约 10 秒才能合成一段 8 帧的目标视频。低层策略需要以这些计算密集型的目标状态为条件来生成动作序列,这进一步加剧了这种显著的延迟;Gen2Act仅能达到 3 Hz 的推理速度,这使得实时机器人控制变得困难;VPP:虽然通过在生成目标状态时仅执行一个去噪步骤来缓解部分延迟,但控制频率仍然只能达到 7-10 Hz;
将目标状态作为动作 token,代表了 VLA 模型开发中的一个良好方向,它提供了卓越的数据可扩展性、丰富的视觉引导和强大的可解释性。图像和视频生成的快速发展(以扩散模型和大规模视频生成模型为例)为这一范式提供了日益坚实的基础,因为更高质量、时间一致性更高的视觉内容将更好地利用这种方法的目标指定性,为具身智能体提供精准而丰富的视觉引导。谷歌最近发布的 Veo 3 视频生成模型在图像质量和物理约束遵循性方面都表现出色。除了提升生成质量之外,还有几个关键的研究方向值得探索:提高计算效率以实现实时机器人控制;增强对环境变化的鲁棒性,以便在实际场景中部署;以及开发更高效的长期任务规划方法,因为当前的方法要么严重依赖基于LLM的任务分解(受子任务分割质量的限制),要么采用计算成本高昂的类似波束搜索的策略来评估候选目标。解决这些限制对于在VLA模型中将目标状态确立为高效且广泛适用的动作 token 至关重要。
9. Latent Representation as Action Tokens
由于大规模、特定于具体化且带有动作 token 的数据集的可用性有限,具身人工智能面临着一项根本性的挑战。为了克服这一数据瓶颈,研究人员转向了更具可扩展性的数据源,例如网络规模的人类活动视频(例如 Ego4D)和异构的跨具身机器人数据集。尽管这些数据源丰富,但它们通常缺乏明确的动作注释或存在显著的具身化差距,因此难以直接利用。一种有前景的方法是从这些数据中提取统一的、与具体化无关的潜在动作表征,这些表征编码了高级语义行为(例如抓取或左转),并有效地模拟现实世界的动态以支持机器人学习。这一想法及其扩展和变体已在一系列使用潜在表征作为动作token 的 VLA 模型中得到探索。通常这些方法是通过三级流水线实现的,如 Fig.5 所示。
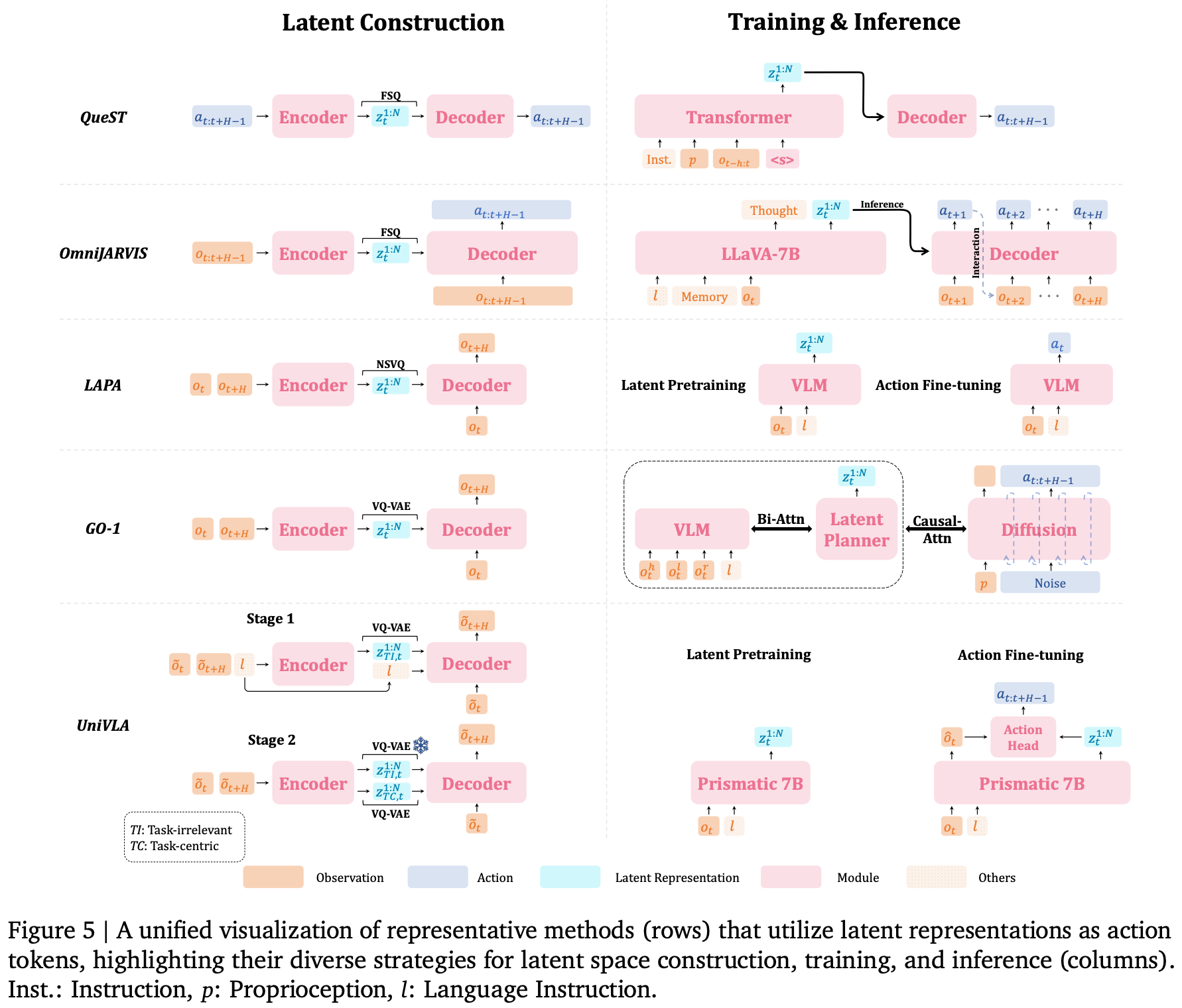
- Latent Construction:初始期间以无监督的方式从大型数据集构建潜在动作空间,为后续阶段提供伪标签;
- Latent Pretraining:潜在预训练阶段,VLM 会根据当前的观察和指令进行调整,预测合适的潜在动作;
- Action Fine-tuning:最终的动作微调阶段训练 VLA,将预测的高级潜在动作转换为目标实施例的低级可执行命令。根据这些潜在动作所代表的含义,这些方法大致可分为基于视觉、基于动作或基于目标;
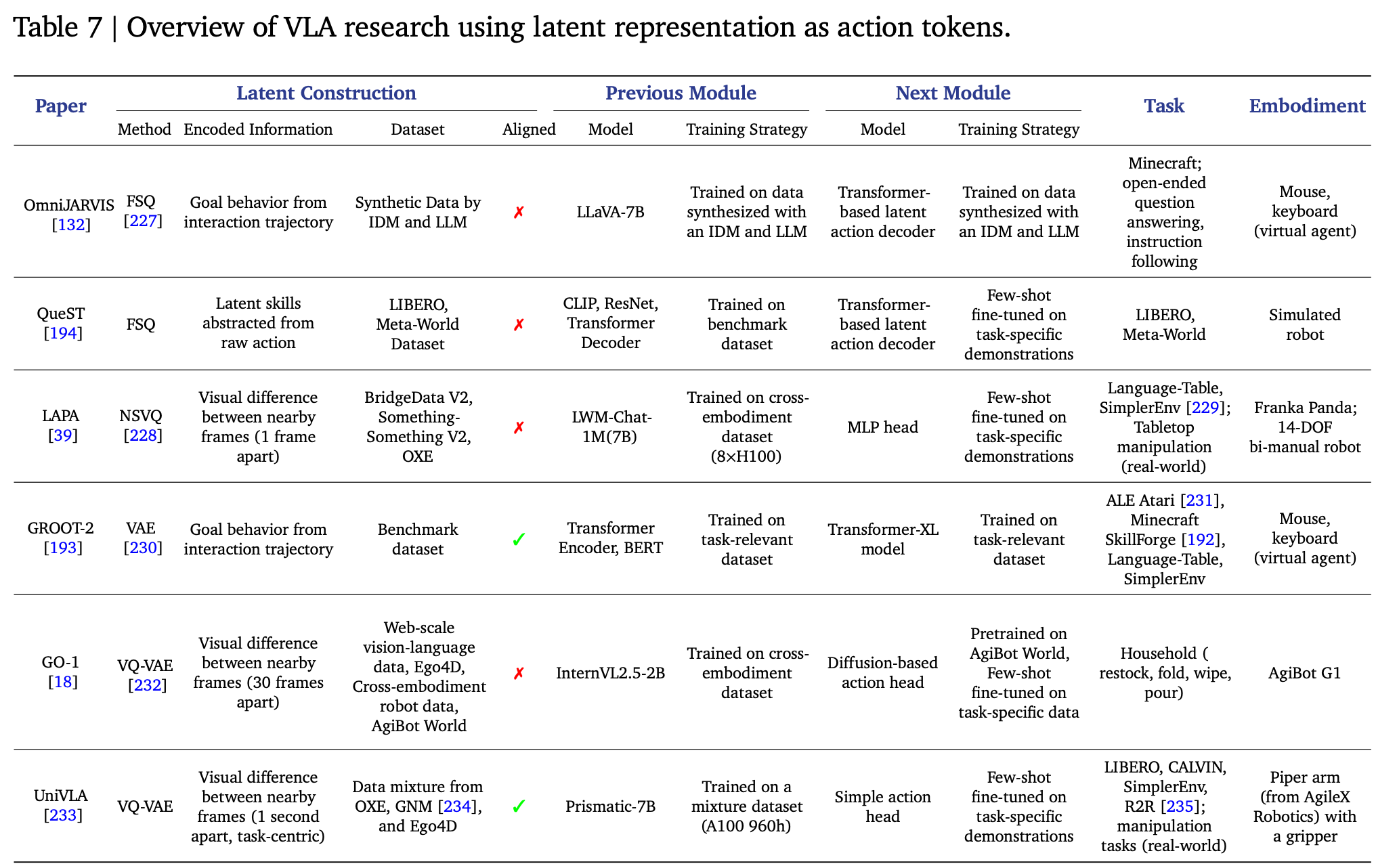
Table.7 全面概述了本节讨论的代表性方法。
9.1. Vision-Based Latent Representation
基于视觉的潜在构建主要利用 VQ-VAE 类架构来建模视觉状态转换,通过从先前的观察中重建未来的目标观察来进行学习,并以 VQ-VAE 码本中的一系列潜在代码 z 1 : N z^{1:N} z1:N 为条件。该框架固有的信息瓶颈迫使这些代码提炼状态之间的视觉转换,其中包含有关底层动作的信息。
Genie:使用网络游戏视频进行训练,以生成一个完全由潜在动作控制的世界模型。这些学习到的动作表现出卓越的语义一致性,不仅能够在不同游戏中实现连贯的控制,而且在推广到现实世界的机器人场景时也能实现;LAPA:将这种方法应用于机器人操控,方法是将学习到的离散潜在动作进行 tokenize,并使用 VLM 进行潜在动作预测。该策略展现出卓越的跨具体化学习能力,当代理的具体化在预训练和微调阶段之间切换时,其在基于真实动作标签的预训练上的表现优于预训练;GO-1:使用类似 π 0 \pi_{0} π0 的架构进一步完善了此方法,该架构通过因果、逐层调节将 VLM、潜在规划器和基于扩散的动作头集成到共享主干网络中。这种统一的架构可以预测潜在动作并为下游任务生成细粒度的高频运动。
现实世界的实验通过展示相比没有它的基线的性能提升来验证潜在规划器的有效性。然而,基于视觉的方法的一个关键挑战是,由此产生的潜在空间可能会无意中捕捉到与任务无关的视觉变化,例如背景杂乱或相机抖动。
UniVLA:缓解了这个问题,首先通过DINOv2将原始像素转换为块级语义特征,然后采用两阶段训练方案,使用语言指令将潜在空间明确地分解为以任务为中心和与任务无关的动作 token。消融结果表明,UniVLA构建的潜在空间比使用Genie方法生成的潜在空间效率高出 6.4%;
9.2. Action-Based Latent Representation
与基于视觉的方法不同,另一项研究采用了基于动作的潜在表征,它通过直接编码和重构固定长度 H H H 的动作块来学习潜在技能空间。例如,QueST 将 FSQ 应用于来自多任务操作数据集的这些动作块,学习了与任务无关的动作基元词汇(例如,reaching、grasping 或 lifting)。实验证实了这种方法的价值:可视化结果显示,语义相似的行为会聚集在一起,并且学习到的技能能够有效地通过少量样本迁移到新任务。虽然这种方法有效,但它在预训练阶段依赖于带有动作 token 的数据,限制了其可扩展性和跨具体化泛化能力。
9.3. Goal-Based Latent Representation
与建模短期视觉转换或动作基元的方法不同,基于目标的表示将整个任务的轨迹编码为表示总体目标的潜在向量。这种范式已被证明在虚拟开放世界环境中尤其有效,例如《Minecraft》。
GROOT和GROOT-2:采用 VAE 将整个任务的观测序列编码为连续的潜在向量序列。随后,以这些潜在向量为条件的解码器根据观测结果因果地重建相应的动作序列。然而,正如GROOT-2中所讨论的,这种潜在空间容易出现两种失效模式,机械地模仿低级轨迹和后验崩溃,从而导致偏离预期的目标信息。为了更好地将潜在空间与任务相关目标对齐并解决这些问题,GROOT-2引入了弱监督,通过 MLE 目标鼓励编码的潜在目标与编码的语言指令匹配。尽管有这些改进,这些方法仍然缺乏推理和长期规划能力;OmniJARVIS:采用 VLM 来联合建模离散的潜在目标以及涵盖观察、指令、记忆和思考的视觉和语言 token。这种方法既能确保强大的推理能力,又能确保高效的决策能力,其成功案例包括它能够回答与 Minecraft 相关的问题,并成功执行复杂的长期任务(例如开采钻石),而这些任务在以前是无法实现的;
9.4. Advantages of Latent Representation
利用潜在表征作为动作 token,在可扩展性、训练效率、表达能力方面具有诸多关键优势。首先,基于视觉的潜在表征使模型能够扩展到无动作、互联网规模的真人视频和跨具身机器人数据集,从而促进对物理动力学的体感不可知理解,从而增强泛化能力,并允许高效的下游针对具身的微调。这种可扩展性与训练效率的显著提升相得益彰。通过将高级运动语义编码为紧凑序列,潜在空间为视觉语言模型 (VLM) 提供了一个比原始动作更简单的预训练目标。
UniVLA:仅使用 4.45% 的训练时间就实现了与OpenVLA相当的性能;
最后,潜在表征具有强大的表达潜力,因为它们能够学习更紧凑、更高效的结构,隐式编码难以通过显式格式指定的任务相关语义,并支持非视觉和非语言模态(例如触觉反馈和音频)的整合,而这些模态通常是基于语言和视觉的动作 token(例如语言计划或关键点)无法实现的。
9.5. Limitations and Future Directions
尽管潜在表示具有上述优势,但它也存在一个关键限制,即其固有的可解释性和可控性不足,这使得人类无法像 RT-H 等方法那样干预或纠正策略错误,从而增加了解释和调试的难度。因此,潜在表示可能不适用于需要严格安全性或可靠性保证的场景。
鉴于潜在表征本身的不可解释性,其构建的属性和质量变得至关重要。因此,未来的研究应集中在三个关键方向上。
- granularity:首先是实现适当的粒度,潜在空间必须足够细粒度,以表示灵巧任务所需的细微变化,同时又要足够抽象,以避免不必要的复杂性和死记硬背。当前基于视觉的方法通常存在粒度不足和重建保真度低的问题,这限制了它们在细粒度操作等高度灵巧任务中的有效性;
- comprehensiveness:其次是全面性,潜在空间必须涵盖给定任务领域所需的全部行为,因为当智能体遇到其学习范围之外的情况时,不完整的行为词汇将不可避免地导致策略失败;
- alignment:第三个关键点是确保与人类意图高度一致。正如
UniVLA和GROOT-2的讨论中所强调的,从视觉和动作数据中衍生的潜在空间可能会无意中编码与给定指令无关的信息;
因此,开发稳健的方法来区分以任务为中心的信号与这些噪声至关重要。专注于这三个方面:提升表征粒度、全面性、与人类意图的一致性,对于提升利用潜在表征作为动作 token 的方法的能力和可靠性至关重要。
10. Raw Action as Action Tokens
前几节讨论了各种形式的动作 token,它们编码了可操作的指导。这些 token 通常作为 VLA 模块的中间输出,最终映射到原始动作。每种形式的动作 token 都表现出独特的特性,使其适用于特定领域。然而,选择合适的 token 表示并非易事。在这种情况下,一个直接且直观的替代方案是将 VLA 模型构建为从视觉和语言输入到原始动作的直接映射。
这一策略的背后,是基础模型的成功。这些模型在大规模、多样化、任务无关的数据集上进行训练,能够以零样本或少量样本的方式在下游任务中取得优异的性能,展现出泛化能力和可扩展性。类似地,典型的方法是收集包含自然语言注释的大规模真实机器人数据集,并端到端地训练 VLA 模型,使其能够直接预测原始动作。其总体目标是,随着数据集规模和多样性的增长,以及基础模型能力的提升,最终的 VLA 模型能够学习通用的机器人策略。鉴于这种训练范式与基础模型的相似性,基础模型社区开发的许多技术和最佳实践都可以被继承并应用于此场景。
本节回顾了该方向的进展,Table.8 总结了代表性工作。
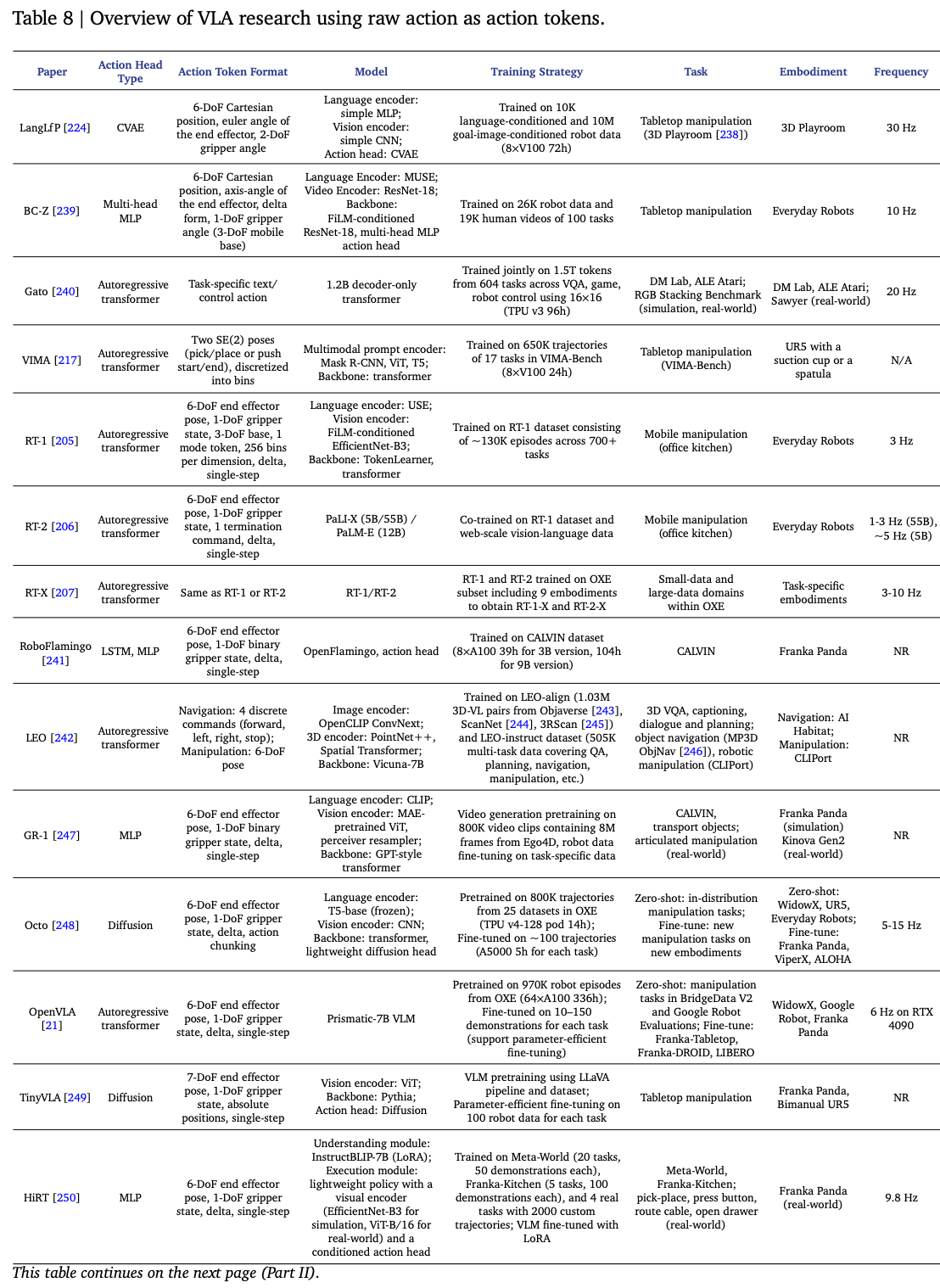
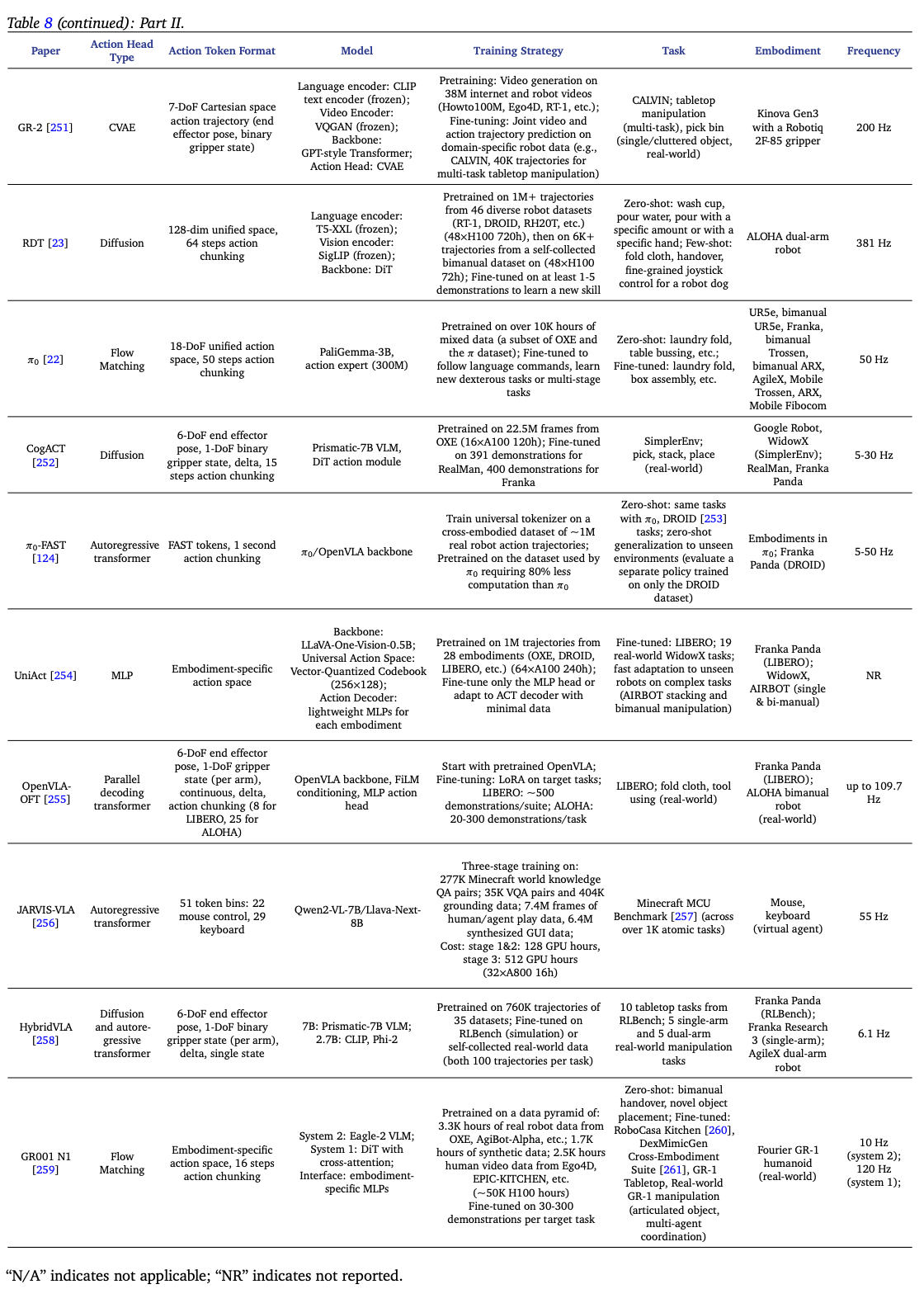
10.1. Vision-Language Feature Fusion
在早期阶段,最常见的方法是融合视觉和语言模块,以获得用于下游任务的多模态特征。然后,这些融合的表征通过简单的层映射到原始动作。
LangLf P:代表了最早的 VLA 模型之一,使用 MLP 和 CNN 对输入进行编码,并使用CVAE解码器生成动作序列。为了扩展数据量,LangLf P将 10M 个目标-图像条件化的状态-动作对与 10K 个人类标记的语言条件化样本相结合;BC Z:是首批收集大型数据集(26K 个机器人数据和 19K 个人类视频)以研究数据扩展如何促进可泛化的策略训练的研究之一,利用了ResNet和多语言句子编码器,但通过使用多阶段FiLM条件化改进了融合过程,该模型基于语言输入动态地调节视觉特征。这种方法允许更细粒度的指令基础,并使用更简单的 MLP 解码动作;
10.2. Transformer-Based Generalists
基于 LLM 中 Scaling Laws 的规律,后续研究更进一步构建了更大的数据集,涵盖了更多样化的任务领域,并采用了自回归 Transformer 主干模型,旨在培养通才型模型。
VIMA:使用Mask R-CNN和ViT从视觉观察中提取对象 token,然后将其与语言 token 连接起来,并由预训练的T5模型处理,以生成多模态提示 token。这些 token 被用作交叉注意层的输入,用于解码机器人动作;Gato:在 596 个控制任务(总计 1.5T 个 token)和 8 个 VL 数据集上成功训练了一个大型仅解码器 Transformer 模型(1.2B 参数)。Gato模型能够执行跨不同领域的各种任务,例如 Atari 游戏、机器人操作、VQA 和聊天任务。通过统一视觉、语言和动作 token,Gato证明了单个自回归模型可以充当多模态、多任务和多体现的通才策略;LEO:通过合并额外的 3D 数据集来增强模型的 3D 推理能力,将通才模型提升到 3D 空间。这一改进增强了 LEO 在体现推理和规划任务中的表现;JARVIS-VLA:基于预训练 VLM 模型(Qwen2-VL或LLaVA-NeXT)进行微调的 Minecraft VLA 模型。以往的 VLA 模型通常直接应用模仿学习来对大规模数据集上的 VLM 进行微调,以进行动作预测;JARVIS-VLA则采用了三阶段微调策略:(1)纯文本世界知识微调,(2)多模态视觉语言对齐和空间基础,(3)指令遵循模仿学习;
10.3. Autoregressive Robot VLA
RT-1:引入了当时最大的机器人操作数据集,其中包含 700 多个任务的 13 万个演示,并训练了一个基于 Transformer 的真实机器人模型。它利用FiLM调节的EfficientNet,允许语言调节视觉特征。Transformer 解码器随后自回归生成原始动作。RT-1在可见任务上表现出色,并能很好地泛化至未可见任务,且对干扰项和不同背景表现出良好的鲁棒性。结合模拟数据,其性能进一步提升。此外,结合来自不同机器人平台(Everyday Robots和Kuka)的数据,可以实现跨不同实例的泛化;RT-2:通过更精简的端到端设计进一步推进了这一目标,该设计最大限度地提高了基础模型的知识迁移。它将网络规模的预训练 VLM(PaLI-X和PaLM-E)微调为端到端 VLA(RT-2-PaLI-X和RT-2-PaLM-E),后者可直接输出原始动作。原始机器人动作被离散化到动作箱中,从而能够以与 VLM 相同的方式进行自回归推理。重要的是,这种方法无需修改基础模型的原始架构。通过利用基础 VLM 作为骨干模型,并结合视觉语言数据和机器人动作数据进行协同训练,RT-2展现出增强的推理和泛化能力。它在测试时推理中展现出超越其训练数据的新兴能力。此外,具有思维链推理能力的RT-2可以解释和响应复杂命令,凸显了使用 VLM 作为 VLA 模型骨干模型的显著优势。RT-2模型虽然影响巨大,但其训练代码和模型尚未公开发布;OXE:引入了一个统一的数据集,该数据集包含从 22 个不同机器人收集的超过 100 万条轨迹,增强了数据集的规模和多样性,从而提升策略泛化能力。在该数据集上重新训练RT-1/2的实证结果表明,跨实例训练可以显著提升性能,并且模型容量在数据丰富的环境中起着至关重要的作用;RoboFlamingo:建立在开源 VLMOpenFlamingo的基础上,专注于单步视觉语言理解。它通过显式策略头对序列历史进行建模,并通过在语言条件下的操作数据集上进行模仿学习进行轻度微调。虽然RoboFlamingo专注于经济高效的开源解决方案,但它仅在模拟基准CALVIN中进行过评估;OpenVLA:一个广受认可的基于 Transformer 的开源 VLA 模型,已被众多后续研究采用为 backbone。构建了一个包含 97 万条异构机器人轨迹的高质量 OXE 子集,以先进的Prismatic-7B模型为基础,并提供了一个结构良好、随时可用的代码库。OpenVLA在预训练后展现出强大的零样本泛化能力,并表明在跨具体化数据集上进行联合训练可以实现高效的机器人专用微调,每个机器人只需 10 到 150 条轨迹即可优化性能。这种先进行联合预训练,然后进行轻量级自适应的范式已获得显著发展。此外,OpenVLA还通过量化探索了参数高效的微调和内存高效的推理。通过开源其模型和数据集,OpenVLA催化了社区规模的开发,并引发了一系列后续研究;MoManipVLA:提出了一个双层优化框架,使基于静态的OpenVLA能够适应移动操作任务。它利用OpenVLA生成夹持器的三维位置、姿态和状态 ( Δ x , Δ θ , Δ G ) (\Delta x,\Delta\theta,\Delta G) (Δx,Δθ,ΔG),并使用下游搜索算法求解机械手和基座之间的协调运动。这种过渡只需极少的微调(200 次模拟演示和 50 次真实场景),凸显了 VLA 在不同具体实现中的泛化能力;OpenVLA-OFT:对微调方案进行了全面的实证分析,并提出将并行解码、动作分块和连续动作表示集成到微调过程中,提高了训练和推理速度、提升任务成功率并确定最佳微调策略;TinyVLA:旨在开发一个更高效的预训练和推理模型。它首先预训练一个可变学习模型 (VLM) 来初始化策略主干,然后冻结预训练的组件并应用参数高效的微调方法 LoRA。基于扩散的动作解码器头通过线性投影层附加到预训练的可变学习模型 (VLM);HiRT:进一步引入了一个分层机器人变换器框架,以提高执行频率和性能,减少了模型规模过大导致的推理延迟并更好地处理动态任务。在此设计中InstructBLIP以较低的频率将 VL 输入编码为潜在表示,然后轻量级策略头通过调节该潜在表示以及实时观测数据,异步生成低级动作;
10.4. Video Pretraining and Robot Data Fine-Tuning
另一项研究探索了大规模视频生成预训练,以捕捉世界动态并促进机器人学习。
GR-1:采用 GPT 风格的 Transformer 模型,该模型在视频预训练期间学习预测未来帧,随后在机器人数据集上进行微调以融入动作生成。在CALVIN模拟基准和真实机器人上的实验结果证明了基于视频的预训练的有效性;GR-2:通过在更大的数据集(3800 万个文本-视频对,而 GR-1 只有 80 万个片段)上进行预训练,扩展了这种方法,并用CVAE替换了 MLP 动作头。该模型学习从视频中捕捉重要的世界动态和语义信息,这些信息对于下游的策略学习至关重要。GR-2的视频生成能力有效地充当了动作生成的规划器,生成的视频与现实世界的部署紧密相关;
10.5. Diffusion-Based Action Chunking
尽管基于 Transformer 的自回归模型取得了显著进展,但仍存在一些局限性。首先,离散自回归 tokenization 难以表示连续或多模态动作,而这些动作对于灵巧任务尤为重要;此外,标准的自回归生成过程每次只生成一个动作,限制了动作推理频率。为了解决这些问题,出现了一类新的 VLA 模型,作为纯 GPT 式架构的替代方案:使用基于扩散的动作头和动作分块。扩散策略已展现出对多模态动作分布建模的卓越能力,而动作分块则允许模型同时输出连续动作。这种方法提高了时间一致性,减少了复合误差,并显著提高了控制频率。
Octo:引入了一种基于 Transformer 的策略,该策略带有一个扩散头 (diffusion head),并在 OXE 的 25 个数据集子集上进行训练。该模型使用 CNN 和 ViT 处理图像,而语言则由冻结的 T5 模型处理。Transformer 的逐块注意力结构允许在微调过程中添加或删除输入和输出,从而能够适应跨具体化的动作和观察空间。这种设计增强了输入源和微调的灵活性;pi0:将流匹配与动作分块相结合以改进策略。 π 0 \pi_{0} π0 的 VLM 主干模型从PaliGemma初始化。该模型在OXE Magic Soup和 π \pi π 数据集的混合数据集上进行预训练,涵盖了广泛的场景、矫正行为和恢复策略。在训练后阶段, π 0 \pi_{0} π0 会基于较小的、针对特定任务的数据集进行微调,以适应特定的下游任务。结果表明,全面的预训练能够实现强大的零样本泛化能力,同时只需极少的微调数据即可在复杂的多阶段任务(例如折叠衣物、构建盒子和包装鸡蛋)中实现高性能。此外, π 0 \pi_{0} π0 支持高达 50 Hz 的控制频率,比RT-2的 5 Hz 提升了几个数量级;RDT:将基于扩散的 VLA 模型进一步扩展到双手操作,展现出令人印象深刻的少样本学习能力,采用冻结的SigLIP和T5-XXL进行图像和语言编码,并将 DiT 头扩展到 1B 个参数。RDT只需 1-5 次演示即可掌握新技能,这标志着其在复杂机器人任务中朝着高数据效率学习迈出了重要一步;CogACT:为OpenVLA添加了基于扩散的动作头,并引入了一种集成策略,通过聚合分块序列来缓解块间模式偏移;HybridVLA:将自回归和扩散策略集成到一个统一的 VLA 模型中;
10.6. Heterogeneous Datasets and Unified Action Space
GR00T N1:引入数据金字塔,以增强训练机器人基础模型的数据多样性和数量。该金字塔包含大规模网络和真人视频数据、中规模合成模拟数据和小规模真实世界数据。它利用整个金字塔,从真人视频和通过DexMimicGen生成的合成演示中提取潜在动作,并结合真实世界数据进行训练。使用分层架构,其中高级模型是一个慢速(10 Hz)自回归 VLM(Eagle-2,13.4 亿个参数),负责根据视觉和语言输入进行高级情境推理和规划。低级模型是一个快速(120 Hz)扩散变换器(0.86 亿个参数),专用于实时电机控制,生成平滑且响应迅速的动作,这两个模型紧密集成,并进行端到端联合训练。为了更好地利用跨实施数据集;UniAct:学习了一个兼容不同实施的通用动作空间,用矢量量化代码表示,其中每个代码都编码了不同机器人之间共享的通用原子行为;
10.7. Recent Advancements
尽管基于扩散的动作头在动作分块方面取得了进展,但推理延迟问题仍然存在,因为模型需要时间来生成下一个动作块。如果机器人在下一个动作块仍在推断过程中时继续执行前一个动作块,新的动作块将基于过时的观察结果,缺乏实时环境反馈。此外,在扩散过程中,块边界可能存在多种合理的动作模式,模式转换可能导致块之间不连续,从而导致运动不平稳或超出分布范围。实时分块 Real-Time Chunking 表明,简单的基于平均的平滑策略实际上会降低性能,产生的轨迹比单个块的轨迹更差。相反,它将块融合定义为通过流匹配进行推理时修复,并引入软掩码来改善跨块连续性。在推理过程中,模型在执行当前动作块的同时生成下一个动作块,冻结保证执行的动作并修复剩余步骤。软掩蔽确保在生成过程中仍考虑块的其余部分,从而进一步提高跨块的连续性。
pi0-FAST:是 π 0 \pi_{0} π0 的扩展,它表明由于高频下连续 token 之间存在强相关性,简单的分箱 tokenize 方法会产生较差的结果。为了解决这个问题,它应用了离散余弦变换 (DCT) 来编码动作块。基于 DCT 的表示法在跨任务时提供了显著的 token 压缩率(高达 13.2 倍),同时产生了更平滑的动作轨迹——这两者对于高精度操作都至关重要;
先前研究的另一个局限性是,仅靠 VLM 预训练无法产生与机器人任务完全一致的表征,而单纯的带动作监督的微调可能会降低先前学习的知识。
pi0.5:提出在离散化动作和通用视觉语言数据上对 VLM 主干进行预训练,以开发鲁棒且可迁移的表征。动作专家则使用连续动作的流匹配进行单独训练。为了保留主干的预训练知识,来自动作专家的梯度被阻止回流,从而有效地隔离了其表征。在推理过程中,轻量级动作专家生成连续动作,而冻结的主干则贡献来自不同预训练数据的广泛视觉语言理解;
10.8. Conclusions and Discussions
总而言之,原始动作是最直接、最可执行的动作表示形式,因此自然而然地成为 VLA 模型的选择。这种方法通常只需要极少的人类先验知识和较少的结构约束,有利于端到端学习。由于现实世界的数据是以原始动作格式收集的,因此它也需要极少的动作 token 注释。正如 LLM 开发中观察到的“惨痛教训”所强调的,规模化的力量远胜于人工工程,随着基础模型的不断增强和数据集的不断扩大,基于原始动作的端到端 VLA 模型很可能也会随之发展。
事实上,使用原始动作 token 的 VLA 模型的演变反映了基础模型时代的更广泛趋势——数据和模型规模的扩大、基础模型架构的改进,以及从纯粹的预训练策略过渡到后训练策略。近期的一些研究,例如 π 0 \pi_{0} π0、RDT 和 GR00T N1,表明全面的预训练能够实现强大的零样本泛化能力和高效的特定任务微调能力。这一进展反映了 LLM 的发展轨迹。
然而,原始动作数据缺乏语言数据那样的互联网规模可访问性。其收集成本高昂,通常需要远程操作和真实的机器人交互,这限制了其可扩展性。此外,原始动作无法直接跨具体实例进行推广,并且在下游任务中进行微调或后训练可能会导致预先训练好的视觉语言知识的灾难性遗忘。此外,对于长期控制任务而言,直接生成没有中间表示的原始控制命令不太实用,因为所需的上下文长度、计算成本和推理延迟可能会变得过高。在保留基础模型知识的同时应对这些挑战仍然是未来研究的关键方向。
11. Reasoning as Action Tokens
诸如机器人操控和自动驾驶等具身任务通常要求人工智能代理具备复杂的认知能力。它们固有的复杂性源于对长远推理、对空间、语义和常识的深度理解,以及在动态环境中有效运作的能力的需求。即使是先进的基础模型在这些领域也面临着巨大的挑战。虽然单个VLA模型有望解决各种各样的具身任务,但仅仅增加模型参数通常不足以应对现实世界场景的固有复杂性,尤其是那些需要强大的逻辑和具身推理的场景。因此,为VLA配备增强的推理能力成为一种有前景的解决方案。Table.9 总结了明确使用推理作为动作 token 的代表性作品。
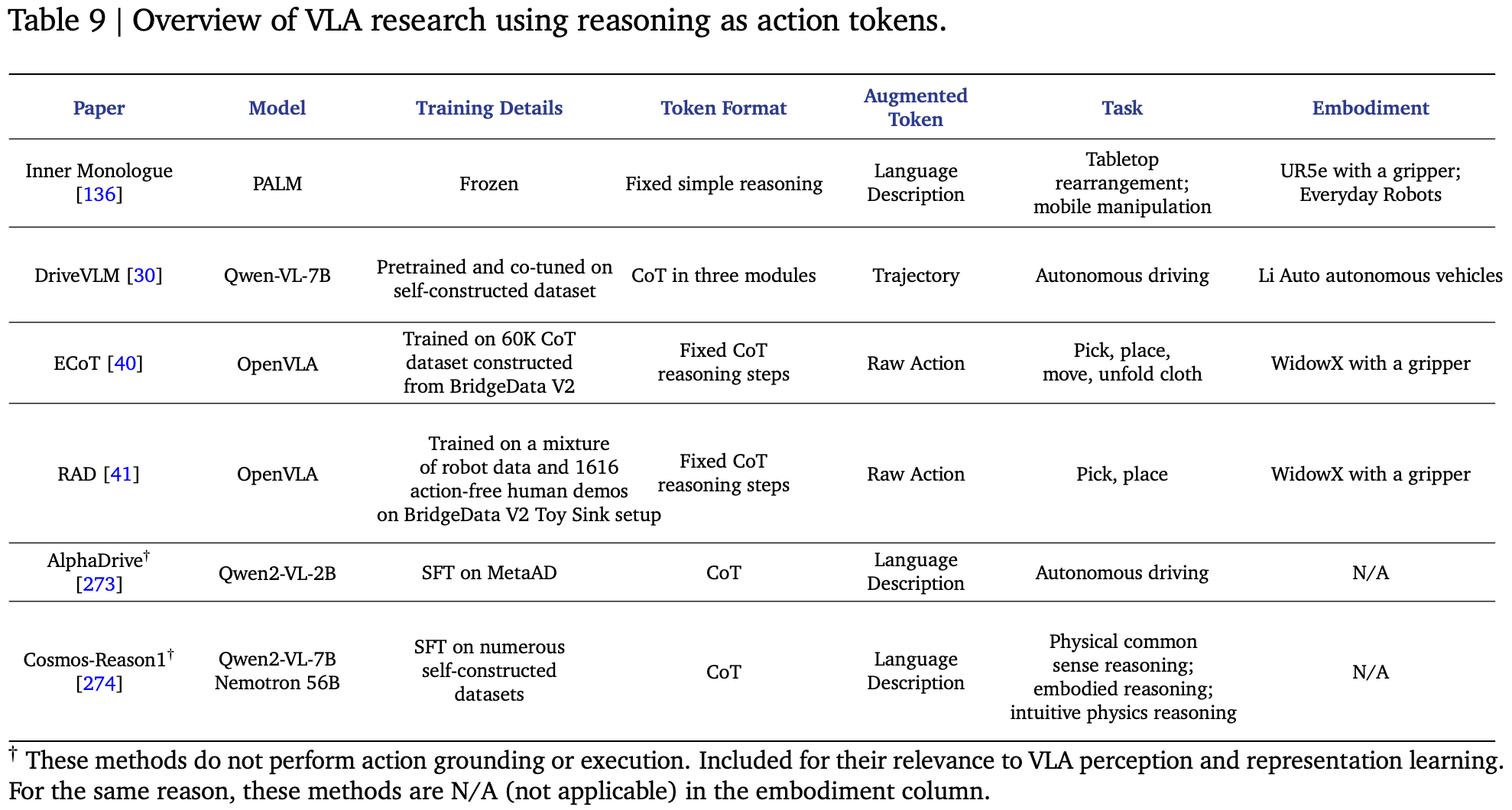
在 VLA 的语境中,推理是指一种审慎的思考过程,它以自然语言的形式明确地外化,并用于增强目标动作 token 的生成。与其他直接表示物理动作或强调对象交互的动作 token 不同,这些推理 token 充当中介角色,促进后续可执行动作 token 的生成。这一概念使模型能够 “think step-by-step”,并将其内部决策过程外化。例如,RAD 使用推理来生成由语言计划指导的原始动作,而 DriveVLM 在生成车辆运动轨迹之前处理推理。
11.1. Evolution of Reasoning in VLA Models
将内部推理过程外化的核心思想源于思维链 (CoT) 提示。CoT 最初是为 LLM 开发的,用于在最终输出之前清晰地表达中间步骤(例如,通过提示“逐步思考”)。CoT 现已超越纯文本领域。它扩展到视觉和多模态情境,为推理如何在 VLA 模型中发挥作用奠定了基础。例如,在视觉任务中,CoT 已被用于在计算最终动作之前生成视觉中间步骤,例如目标物体的边界框。
具身推理领域的早期先驱研究通常利用 LLM,并添加额外的模块来解释视觉场景。一个值得注意的例子是 “Inner Monologue”,使用 LLM 接受人类指令、场景描述(由 MDETR 生成)和动作反馈(来自杠杆感知模型)。这种设置允许递归地进行多步骤语言规划,直到任务成功完成。
然而,该领域发展迅速。如今,集成推理的 VLA 模型的主流方法是利用 VLM。VLM 拥有固有且精通的多模态先验知识,通过减少对众多附加模块的需求来简化模型架构。它们固有的处理语言和视觉模态的能力显著增强了复杂具身任务的推理过程。为了使这些 VLM 适应具身任务所必需的特定推理模式,通常采用微调或再训练模型等方法,例如具身推理测试 (ECoT) 和 RAD就证明了这一点。
11.2. Key Implementations and Applications
ECoT是将推理应用于具身任务的典型案例。
OpenVLA:基于Prismatic VLM构建,并专门使用推理数据进行训练。该领域的一个重大挑战是获取高质量、大规模的推理数据集。虽然人工标注可以产生高质量的数据集,但在大规模情况下并不实用。ECoT引入了一种自动化数据合成流程,将推理构建成一个固定的序列,从任务分解到抓取器位置再到物体框预测;RAD:采用了类似的框架,但大幅扩展了数据收集范围。它不仅可以根据机器人轨迹自动合成推理数据,还可以从易于获取的无动作真人视频中合成推理数据。真人视频的合成过程与机器人数据的合成过程相似,用HaMeR(一种用于手部关键点和姿势跟踪的方法)取代了运动基元提取。这项创新促进了机器人数据和真人视频的协同训练,拓宽了可用数据的范围;Cosmos-Reason1:通过强化学习(具体来说,GRPO)和监督微调 (SFT) 对物理常识、具身推理和直觉物理学进行训练,使其能够适应具身应用;
除了机器人操控之外,自动驾驶因其高度复杂、动态、交互的环境以及对增强安全性的迫切需求,为推理提供了另一个关键的应用领域。
DriveVLM:将认知推理应用于其三个关键模块:场景描述、场景分析和分层规划。场景描述模块识别驾驶环境中的关键物体。然后,场景分析模块评估其特征及其对自身车辆的潜在影响。最后,分层规划模块制定分步计划,从语言动作到决策描述,最终到路径点。这项艰巨的任务需要对各种物体和场景进行复杂的推理和常识性理解,因此使用 VLM 进行推理尤为合适;AlphaDrive:先进行 SFT 预热训练,然后进行基于GRPO的强化学习探索,就是专为自动驾驶环境下的推理而开发的 VLM 的例子;
11.3. Advantages of Reasoning as Action Tokens
将推理集成为动作 token 可以为 VLA 模型带来几个引人注目的优势:
- Bridging the Instruction-Action Gap and Enhanced Generalization:推理通过引入中间思维步骤,显著缩小了高级指令和低级可执行操作之间的差距。这使得 VLM 能够利用其先验知识来处理涉及各种场景和物体的任务,从而增强其在复杂的长视域任务中的泛化能力和性能。例如,ECoT [40] 在“将可食用物体放入碗中”等复杂的操作任务中表现出显著的性能提升。这项任务需要复杂的推理,包括识别碗、检查所有现有物体以及根据常识选择可食用的物体。
ECoT还表现出对未知物体和场景的增强泛化能力,展现了推理的强大力量; - Improved Interpretability and Human-in-theLoop Capabilities:通过将代理的思维过程外化,推理增强了模型的可解释性。人类可以清晰地审查代理的决策,追踪推理链中的错误点,甚至在检测到错误时进行实时干预。这种透明性也促进了人机交互,允许灵活地处理不确定的人类输入以用于后续操作,例如,Inner Monologue 允许人类实时选择对象;
- Enabling Cross-Embodiment Capability:虽然不同的实施方案可能具有不同的架构和动作令牌格式,但完成任务的高级计划通常保持一致。推理可以提取这些抽象计划,将主要挑战转移到将它们投射到最终执行中。VLM 丰富的先验知识,结合在
OXE等跨实施方案数据集上的训练或微调,可以促进跨各种实施方案的推理。ECoT验证了其跨实施方案能力,表明经过微调的模型可以在新的实施方案中有效地执行ECoT推理;
11.4. Limitations and Future Directions
尽管推理具有诸多优势,但在具体任务中运用推理仍然面临一些限制:
- Increased Inference Time and Reduced Execution Speed:推理通常需要模型生成冗长的思考过程或多个推理步骤,导致推理时间过长且执行速度缓慢。这对于具身化人工智能中常见的实时高频任务而言是一个关键制约因素。虽然像 ECoT 的异步执行这样的解决方案可以将推理速度提高约 40%,但进一步的加速技术至关重要;
- Fixed Reasoning Steps and Data Challenges:在当前的实现中,推理步骤通常需要手动修复。虽然这为某些任务提供了稳定性,但它会限制模型的泛化能力,并阻碍探索潜在的更优推理路径。此外,构建高质量、大规模的推理数据集仍然成本高昂且具有挑战性;
从其优点和局限性来看,推理特别适合于复杂、长期、需要分解为多个子任务的演绎任务,尤其是那些由于当前推理速度限制而执行频率相对较低的任务。
展望未来,该领域的未来工作有望取得令人兴奋的进步:
- Improved Inference Speed and Foundation Model Capabilities:预计基础模型的推理速度和固有推理能力将得到提升;
- Better Data Collection Methods:开发更高效、更可扩展的方法来收集高质量的推理数据至关重要;
- Advanced Test-Time Compute:利用测试时计算(即推理过程中的额外计算)有望提升推理模型的性能、泛化能力和鲁棒性。
AlphaDrive和Cosmos-Reason1中探索的技术只是早期的例子; - Novel Reasoning Paradigm Design:人们迫切期待着对 VLA 推理模块范式设计的深入理解。这可能包括多模态推理,并最终推广到更广泛的、甚至所有具身化任务和机器人具身化;
12. Scalable Data Sources
VLA 模型的开发关键依赖于学习基于多模态观察的动作 token,这些 token 可组合以支持技能排序,并可执行以用于具体化的策略控制。有效地学习此类表征需要能够共同提供视觉语言基础、细粒度动作监督和与具体化相符的感觉运动控制的数据。然而,各个数据源通常提供的监督信号强度互补。为了解决这个问题,现代 VLA 框架采用了分层的多源数据范式,将网络数据和真人视频集成用于视觉语言基础,将合成和模拟数据用于技能组合,将现实世界的具体化数据用于具体化控制基础。随着这三类数据源数量的减少和具体化程度的提高,它们构成了“数据金字塔”的底层、中层、顶层。这种多层监督结构使得跨不同任务、具体化和控制模态的动作 token 学习能够实现可扩展且可迁移。Table.10 展示了可扩展数据源的代表性作品
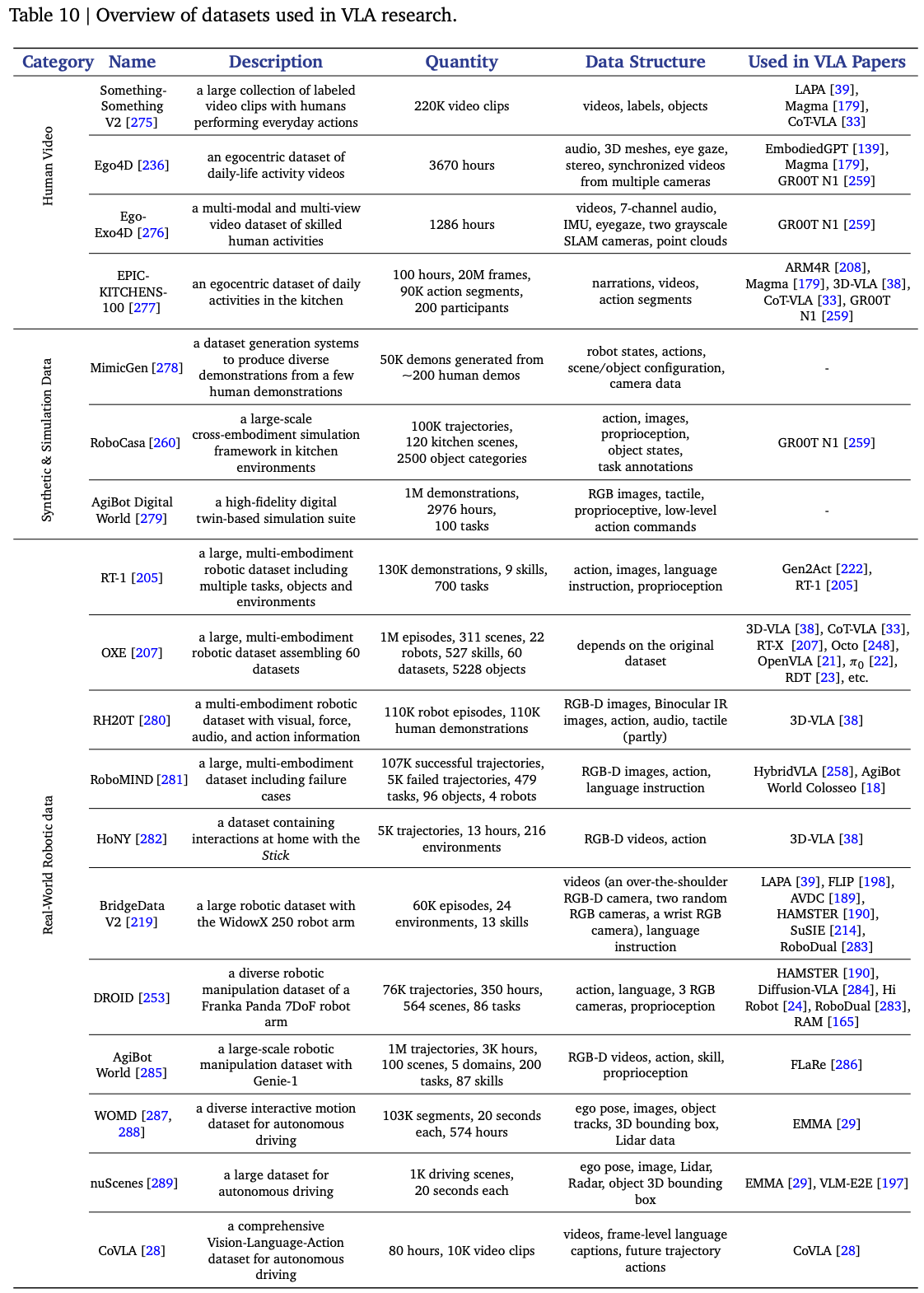
12.1. Bottom Layer: Web Data and Human Videos
底层由大规模网络数据和人类视频数据集组成,用于支持视觉语言基础 visual-linguistic grounding、世界建模 world modeling、时间预测 temporal prediction。由于网络数据主要由 VL 对组成,且主要用于增强基础模型能力,因此在讨论中主要关注人类视频。代表性的人类视频数据集包括 Ego4D、EPIC-KITCHENS-100 和 Something-Something V2。虽然这些数据集不包含可直接用于策略学习的动作标签,但它们捕捉了多样化的人机交互、复杂的操作技巧和丰富的物理常识,这些都是宝贵的世界知识来源。它们的规模和多样性使得时间视觉编码器能够进行预训练,并有助于动作 token 表征的学习。最近的 VLA 模型利用这些数据集提取轨迹、推断潜在状态转换 [39] 并生成潜在动作。由此产生的预训练模块提供了基于时间、语义结构化且部分具身化的先验知识,从而增强了跨任务和具身化的下游策略学习。
除了显式感知内容外,这些视频还隐式编码了视觉观察与物理动作之间的映射。这种隐式结构使模型能够获取基于观测状态和估计动作的粗略可供性先验和潜在动态。自我中心视角通过近似机器人视角来缩小体现差距,尤其是在操作和导航任务中。近期研究进一步利用弱监督从大规模视频中提取可操作的表征。帧级字幕和时间对齐提供了间接监督信号,用于生成基于轨迹和目标状态的动作 token。
Magma:引入了 token 集和 token 迹抽象,以在视频流中锚定动作基础;Ego-Exo4D:利用第三人称视角增强自我中心数据,以实现 3D 运动基础,从而促进体现迁移。这些方法使 VLA 模型能够在开放世界环境中构建时间基础和语言条件的策略先验;
12.2. Middle Layer: Synthetic and Simulation Data
为了在真人视频与高昂的现实世界数据收集成本之间搭建起一座关键的桥梁,VLA 研究广泛利用了模拟和合成数据。这种范式提供了可扩展的结构化、以任务为中心的数据访问途径,这些数据对于学习构图技巧和稳健的控制策略至关重要。两种互补的方法是该方法的核心。
- Synthetic Dataset Generation:第一种方法是离线合成数据生成。它采用
MimicGen、DexMimicGen和RoboCasa等程序化生成流程,以编程方式从有限的专家演示中增强或合成大规模数据集。Mimic Gen:建立了一种范例,将程序化的变化(例如空间变换和场景重构)应用于现有轨迹,以增强数据多样性;RoboCasa:扩展了此过程,为各种操作任务生成超过 10 万条轨迹;DexMimicGen:则通过结合运动学重定向和接触动力学随机化,将其扩展到复杂的双手操作。这些方法以低成本大大丰富了数据集的数量和多样性,正如GR00T N1所证明的那样,它利用这些数据来训练复杂的双手装配任务的策略;
- Interactive Simulation Platforms:作为合成数据集的补充,第二种方法涉及交互式模拟平台,例如
robosuite、Habitat、Isaac Gym、Isaac Lab等。这些模拟器中的数据生成遵循几个关键范式。首先,它涉及远程操作,其中人类操作员使用VR控制器、键盘或其他界面来控制模拟机器人并执行任务。第二种方法涉及算法求解器,例如经典的运动规划器,它可以为具有清晰解决路径的任务生成成功的轨迹。第三,通常通过强化学习训练的学习策略可以自主收集大量数据。除了生成机器人轨迹之外,这些平台还使训练环境本身多样化。程序化内容生成系统地随机化环境因素,包括物体、纹理和光照条件。AgiBot Digital World平台将逼真的3D资产与高保真物理模拟相结合,促进了对罕见、易出错和复杂的交互场景的探索;
这些环境使代理能够通过与基于物理的世界直接交互进行学习,从而促进大规模强化学习和模仿学习。模拟对于高风险或安全关键场景尤其有价值,例如工具误用或复杂的接触动态,这些场景对于具有恢复能力的稳健策略至关重要。然而,解决模拟与现实之间持续存在的差距仍然至关重要,视觉保真度和物理建模方面的差异需要在现实环境中进一步微调。
12.3. Top Layer: Real-World Robot Data
真实世界机器人数据包含训练 VLA 模型最关键的资源,为学习基于物理且可执行的策略提供直接监督。与模拟或人类视频不同,真实机器人数据集能够捕捉物理环境中固有的复杂动态、感知噪声和不可预测的变化。这种高保真信息对于弥合模拟与现实之间的差距以及灌输关键的具现化特性(例如运动学约束和接触动力学)至关重要。因此,真实世界数据对于训练策略生成低级动作至关重要,而低级动作需要精确的物理真实感才能成功执行。
VLA 研究的主要目标是开发能够跨多种机器人平台运行的通用智能体。这推动了大规模、多体现数据集的收集,这些数据集汇集了来自各种机器人形态和环境的经验。
OXE:从涵盖 22 个机器人的多个数据集中收集了超过 100 万个操作场景,从而促进了具有显著跨体现迁移能力的策略学习;RoboMIND:独特地整合了负向数据,提供了 5000 条带有因果注释的失败轨迹,从而通过对比或纠正机制实现更稳健的策略学习;RH20T:进一步提供了多模态信息,包括力-扭矩和音频数据,以支持推理物理接触和环境声音的策略;
与多体现数据集的广泛覆盖范围相比,单体现数据集和特定任务数据集为掌握复杂的专业技能提供了互补数据。这些数据集对于学习细粒度操作和长期任务至关重要。
RT-1:代表了最早也是最著名的收集大规模单体现数据集的努力之一;DROID:引入了一个统一的机器人平台,并将其部署到全球多个机构,研究人员可以共同收集涵盖广泛任务、物体、场景、视点和交互位置的大规模数据集。这种统一而多样的数据有助于训练可泛化的 VLA 模型;AgiBot World:提供了Genie-1机器人在 5 个不同领域的 100 万次实验;BridgeData V2:包含 6 万个复杂的厨房长程任务演示,为学习多步骤操作中的因果依赖关系提供监督;HoNY:专注于在非结构化的“野外”家庭环境中采集数据,这带来了诸如物体杂乱和光照变化等挑战;nuScenes和Waymo Open Dataset-Motion:集成了丰富的传感器组件(例如激光雷达、雷达)来训练安全关键型驾驶策略,通常使用轨迹 token 作为主要动作表示;
尽管现实世界机器人数据不可或缺,但由于成本高昂、操作复杂以及远程操作或便携式动作捕捉设备速度缓慢,获取现实世界机器人数据仍然是一个重大瓶颈。这种可扩展性挑战从根本上塑造了大多数先进 VLA 模型的数据策略。一种普遍有效的范式是利用丰富的模拟数据或网络爬取数据进行大规模预训练,以学习可泛化的视觉、语言和语义表征。随后,在规模较小、高质量的现实世界数据集上对模型进行微调,使这些通用表征适应特定的物理实现和任务需求。这种分层方法在广泛的世界知识需求与可靠现实世界执行所需的精确物理基础之间实现了战略性平衡,有效地缓解了数据稀缺问题,同时最大限度地提高了性能。
13. General Discussions and Future Directions
前述章节表明,一系列颇具影响力的论文已对各类行动符号进行了探索。这些研究揭示了不同行动符号的表达能力,有效利用了基础模型的优势,并开发了可扩展的数据策略,最终形成了展现出良好实证表现的VLA模型。显然,每种行动符号都有其自身的优势和局限性,且仍处于探索的早期阶段,未来发展潜力巨大。目前,没有任何一种类型表现出绝对的主导地位或明显的劣势,研究界也尚未形成一个主导的行动符号范式,因此难以给出明确的建议。在第13.1节中对行动符号的未来趋势和 VLA 模型的发展进行评估。在第13.2至13.6节中进一步提出一系列一般性观察和思考,指出 VLA研究中尚未充分探索的领域,以指导和指导未来的研究方向。
13.1. Trends of Action Tokens and VLA Models
根据 Table.1 中每个 token 的优缺点总结,观察到不同的动作 token 展现出互补的优势,并且最适合 VLA 模型中的不同层级。这表明 VLA 的未来并非取决于单一的主导 token 类型,而在于它们的战略组合,从而推动层级架构的发展。语言规划和代码在长期规划和逻辑控制方面具有独特的优势,这些能力难以用其他动作 token 类型替代,使其成为顶层的理想选择。对于源自这些高级规划的子任务,3D 可供性、轨迹建模和目标视频预测的组合可以提供精确且可解释的运动表征,使其非常适合中间层。相比之下,语言动作和基于 API 的代码表达能力相对较弱,通常可以被前三者取代。最后,可以训练一个策略模块,将这些基于视觉的表征映射到原始动作中。
虽然潜在表征拥有巨大的潜力,但由于当前的训练挑战,尤其是在实现适当的粒度、语义全面性和以任务为中心的一致性方面,作者并未将其纳入其所提出的架构中。这些限制不易克服,并且可能会损害实际应用中的可靠性。因此,目前更倾向于使用更明确形式的动作 token,这些 token 通常更易于训练和检查,并且具有更高的可解释性和控制性。尽管如此,潜在表征的未来发展及其随着该领域发展而最终融入其中保持乐观。
端到端的低级策略将子任务直接映射到原始动作,提供了基本的可扩展性,尽管它仍然受到数据可用性的限制。短期内,上述分层设计有助于数据收集,从而实现数据飞轮效应;从长远来看,它可以实现完全端到端的控制器学习,绕过中间 token,直接从子任务预测原始动作。
在 VLA 模型中,推理以一个至关重要的动作 token 为特征。虽然推理已被纳入当前的 VLA 模型,但它通常还处于初级阶段,仅适用于相对简单的任务。如第 2.4 节所述,VLA 模型中的动作 token 的作用类似于 LLM 中的语言 token。因此,自然地会设想 VLA 模型中的推理过程并非基于语言 token,而是基于动作 token。这反映了人类解决复杂任务的方式,不仅通过语言规划和反思,还通过运用物理世界基础和想象力。此外,基于动作 token的推理应被设计为能够自适应地利用测试时间计算,并根据任务复杂性调整其长度,就像基于语言的推理中常见的做法一样。这种推理应根据需要集成到整个 VLA 层次结构中,以增强所有其他动作 token 的生成,从而为实现更通用、更接近人类的智能提供一条充满希望的道路。
以上分析从动作 tokenization 的角度,展现了作者对 VLA 模型未来发展的看法。从根本上说,当前动作 token 的存在源于基础模型生成和解释它们的能力。随着基础模型的不断发展以及新模态(例如,音频、触觉)的日益普及,预计会出现新的动作 token 类型和子类型,这将进一步扩展 VLA 模型的表现力和有效性。持续研究并深思熟虑地整合所有动作 token,对于充分利用它们之间的互补优势,并迈向更强大、更通用的具身智能至关重要。
13.2. From VLA Models to VLA Agents
下一步自然是自觉地从 VLA 模型向 VLA 代理演进,通过以代理为中心的范式补充核心功能。虽然当前的 VLA 模型主要侧重于学习从视觉语言输入到动作输出的有效映射,但构建更通用、更强大的具身智能可能需要具有全面集成功能的代理级系统。大多数现有的 VLA 模型缺乏整合历史记录的机制。即使有,这种上下文通常也仅限于少数帧或简单的基于语言的规划。这对于现实世界中的长期任务来说是远远不够的,尤其是那些涉及进度跟踪、子任务依赖关系或在线探索的任务。应对这些挑战需要强大且结构化的记忆、规划和反思机制,这些组件已在更广泛的代理研究界得到广泛研究,并且可以有效地集成到 VLA 中。RoboOS 等初步努力代表了朝着这个方向迈出的早期一步,尽管目前的设计仍然相对简单。此外,通过整合世界模型的进步,VLA 代理的规划和在线探索能力也可以得到显著增强。
虽然现有研究通常可以在交错 VLA 模块和动作令牌组成的链式框架中描述,但未来的代理系统不应局限于线性架构。相反,代理应该自适应地调用和管理模块和生成的动作令牌,以充分处理信息并生成有效的输出。
最后,向 VLA agent的演进,以及在现实世界环境中部署具身代理的更广阔愿景,也要求学界更加关注多代理系统和人机共存,这两者对于未来机器人融入人类日常生活都至关重要。
13.3. From Imitation Learning to Reinforcement Learning
第三个观察集中在 VLA 模型的训练范式上。目前,绝大多数 VLA 模型都是使用模仿学习进行训练,这存在一些局限性。这些局限性包括:
- 受人类演示者能力限制,存在固有的上限;
- 缺乏目标导向的执行机制;
- 难以实现一致且近乎完美的性能;
- 人类演示通常不够理想,并且可能由于疲劳、注意力不集中、个人特质以及数据收集设备的技术限制(例如传感器的精度和延迟)等因素而缺乏灵活性;
模仿学习的这些局限性自然引发了反思:人类的大部分学习并非仅仅源于观察或指导,而是 从根本上依赖于实践中的反复试验和自主探索。这为未来的研究提供了一个充满希望的方向:应用强化学习 (RL) 来优化 VLA 模型。通过使模型能够直接从目标反馈中学习并自主探索环境,这种方法可以产生更稳健、更灵巧且成功率更高的行为。因此,强化学习为 VLA 模型提供了一条通往更接近人类学习过程和能力的途径。
虽然强化学习在 VLA 模型中的应用前景光明,但将其直接应用于现实世界仍面临重大挑战。在现实世界中部署 VLA 模型通常会产生高昂的重置成本,每次试验后都需要投入大量时间和资源来重置环境。此外,现实世界环境的交互效率低下,意味着模型需要大量的交互才能有效学习,这通常是不切实际的。安全问题也不容忽视,因为强化学习训练期间的探索性操作可能会对机器人或其周围环境造成损坏。这些挑战凸显了开发更高效的强化学习算法的迫切需求,这些算法可以使 VLA 模型能够以最少的交互在真实机器上运行。这可能涉及诸如情境强化学习之类的技术,它利用大型预训练模型,通过适应新的情境,在有限的数据下学习新任务。
未来研究的另一个关键领域是利用现有的可变学习模型 (VLM) 实现密集奖励函数的自动化设计。为复杂的机器人任务设计有效的奖励函数极其困难,通常需要大量的人工投入和领域专业知识。可变学习模型 (VLM) 凭借其对视觉和文本信息的出色理解,有望解读高级任务描述,并自动生成细粒度、密集的奖励信号,引导强化学习 (RL) 智能体成功完成任务。这种方法可以显著减轻奖励工程的负担,加速强化学习驱动的可变学习算法 (VLA) 模型在各种实际应用中的开发和部署。
13.4. From Restrictive Hardware to Full Dexterity and Modalities
当前 VLA 模型的另一个关键限制在于其底层硬件配置。虽然在日常生活中,大多数复杂且精细的操作任务都是通过人手完成的,但现有的 VLA 研究绝大多数仅仅依赖于简单的抓手,这严重限制了操作空间和灵活性。为了构建更强大的 VLA 模型,未来的研究必须将灵巧手作为核心组件。
此外,现有研究主要集中于三种常见感知模式:视觉、语言、动作。然而,这样的传感器配置不足以开发真正通用的智能体。更广泛的感知模式,包括 触觉、听觉、嗅觉,甚至味觉,对于使智能体能够处理更广泛的现实世界任务,并具备通用智能所需的鲁棒性和适应性至关重要。
13.5. From Capability-Centric to Safety-Aware
VLA 模型还必须更加重视安全性考虑。具身智能不仅继承了数字人工智能系统中存在的许多一致性和安全挑战,而且还因其与现实世界的交互而引入了额外的风险,例如对硬件的物理损坏,甚至对人类的潜在伤害。这些高风险的后果要求在算法设计中将安全性视为首要考虑因素。然而,这在当前的研究中仍然是一个尚未充分探索的领域,需要更系统的研究和积极开发安全感知方法。
13.6. From Data Scarcity to Data Scalability
深度学习的历史反复证明,数据是驱动强大模型发展的“化石燃料”。然而,当前机器人数据收集方面的努力已明确表明,短期内,在几个关键维度上,数据可用性仍将不足。
- 机器人数据的总量极其有限。与得益于海量且不断扩展的互联网规模语料库的语言和视觉数据相比,机器人数据必须通过劳动密集型流程手动收集。尽管社区做出了巨大努力,但可用的机器人数据量仍然比视觉语言数据量低几个数量级,并且短期内不太可能达到相当的水平。据估计
OXE数据集中的 token 总数仅为大规模语言模型语料库的二十万分之一,这进一步凸显了机器人数据的稀缺性; - 机器人数据缺乏足够的模态覆盖。大多数现有数据集仅限于视觉、语言和动作,而其他重要的感官模态,例如触觉、听觉、嗅觉和味觉,则在很大程度上尚未得到体现。由于硬件限制,这些空白在短期内难以填补;
- 机器人的形态多种多样,且彼此之间通常互不兼容。尽管在不同平台上收集了大量数据,但这些数据集分散在不同的形态中,不易共享或重用,这进一步减少了可用数据量;
- 机器人数据质量通常不足,尤其是在涉及灵巧操作的场景中。现有的灵巧手数据采集设备在精度、响应速度和可靠性方面尚不够先进。因此,获取用于复杂任务的高质量数据仍然十分困难。对于具有力反馈的高自由度灵巧手来说,这一挑战更加突出;
由于这些限制,VLA 模型最终可能需要比数字 AI 系统大得多的数据量,因此在数据可用性方面面临着巨大的瓶颈。未来的研究应从两个关键方向应对这些挑战。一方面,应更好地利用模拟和互联网规模的资源来提供可扩展的监督。另一方面,开发更通用、更可靠、多模态且适用于野外环境的数据收集系统至关重要,这些系统能够在现实环境中有效运行。这些努力对于支持 VLA 模型的持续发展和可扩展性至关重要。
14. Conclusion
本综述将 VLA 模型定位为通往具身人工智能的核心路径,并从动作 tokenization的角度对现有研究进行了全面回顾。对于每一类动作token,系统地考察了具有代表性的 VLA 模型,分析了它们的优势和局限性,并重点指出了未来研究的潜在方向;进一步总结了可扩展数据源方面的主要成果,旨在为正在进行的研究提供参考和支持。最后,基于 VLA 的当前发展状况,概述了未来趋势和尚未探索的领域,以帮助指导下一阶段的进展。随着视觉和语言基础模型的持续蓬勃发展,VLA 的研究势头强劲,前景广阔。希望本综述能够阐明该领域的发展历程,规划其发展轨迹,并为其发展做出有意义的贡献,最终更接近人们对通用人工智能的追求。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 40
40 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)