从扩散模型到流匹配:π_RL如何突破视觉-语言-动作模型的强化学习困境
本文探讨了OpenAI的o1模型通过强化推理阶段提升逻辑能力的技术路径,分析了蒙特卡洛树搜索(MCTS)和强化学习(RL)等关键技术。重点讨论了微软rStar项目如何在小语言模型场景中应用纯推理优化策略,通过MCTS实现高效搜索而避免依赖大规模标注数据。文章详细解析了将人类思维模式转化为五种算法动作的实践方法,展示了如何构建自然语言推理的搜索树结构。研究揭示了流匹配与传统RL的兼容性问题,以及π_
0. 引言
在深度学习领域,OpenAI的o1模型开启了一个全新的范式——将更多算力投入到推理阶段以提升模型的逻辑推理能力。这一理念并非凭空而来,而是建立在多年来对蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)、扩散模型(Diffusion Models)以及强化学习(Reinforcement Learning, RL)等技术的深入研究之上。本文将深入探讨这些技术的演进路径,重点分析为何流匹配(Flow Matching)与传统强化学习存在天然的不融洽性,以及最新的π_RL框架如何巧妙地解决这一根本性难题。
从技术框架来看,o1的实现可能遵循"预训练-后训练-推理优化"的三阶段路径。其中,推理优化阶段是区别于传统语言模型的关键创新点。这一阶段主要有两个作用:第一,直接对推理过程进行优化,例如通过过程奖励模型(Process Reward Model, PRM)结合搜索方法,或采用MCTS进行自我博弈式的路径探索;第二,用于在后训练过程中筛选高质量数据。这种设计哲学体现了一个核心原则——尽量减少人工标注,充分利用已有模型的能力自动化生产训练数据,再通过监督微调或强化学习等后训练方法提升模型性能。
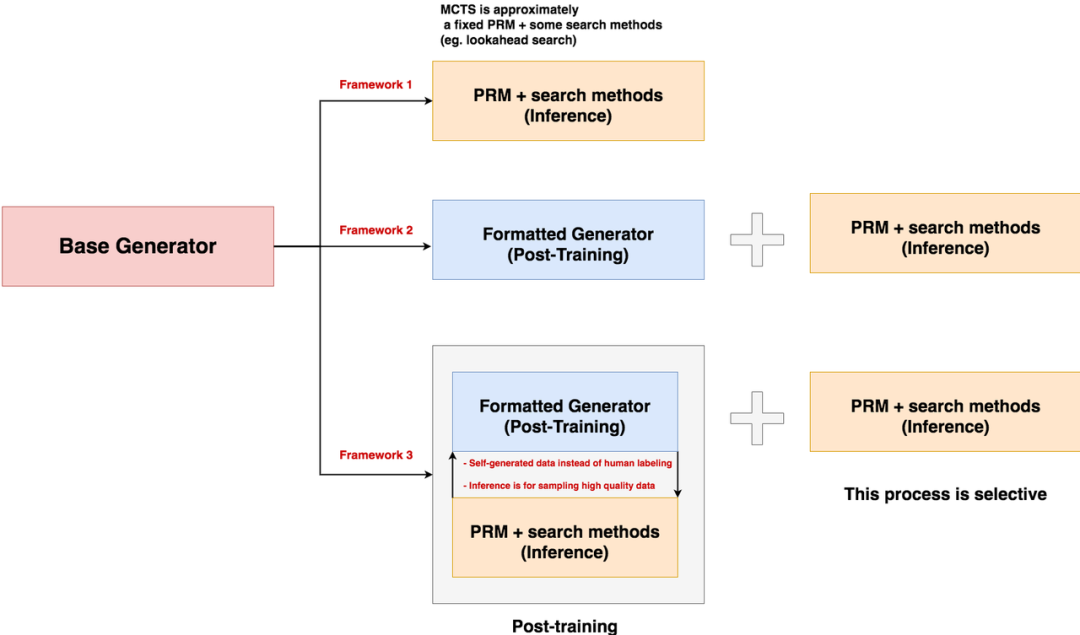
理解这一框架对于把握当前AI技术的发展脉络至关重要。MCTS和推理优化可以被视为整个系统中的一块关键"积木"——当你理解了这块积木的目的和实现方法后,就可以根据需要灵活地将其组装到系统的任何环节。无论o1最终采用的是纯推理优化路线,还是后训练与推理优化相结合的路线,掌握这些基础技术都是必要的。接下来,我们将从微软开源的rStar项目入手,详细剖析MCTS在自然语言推理任务中的具体应用。
1. MCTS在自然语言推理中的应用——以rStar为例
1.1 为什么选择rStar作为切入点
蒙特卡洛树搜索最初在围棋AI AlphaGo中大放异彩,但如何将其应用于自然语言处理领域一直是研究者关注的焦点。微软开源的rStar项目提供了一个极佳的案例,它完全走纯推理优化路线,不依赖大规模后训练,因此更便于我们理解MCTS作为独立模块的工作机制。
rStar选择这一路线有充分的理由。首先,它针对的是小语言模型(Small Language Model, SLM)场景。对于小模型而言,其预训练阶段获得的能力有限,难以通过自产自销的方式生产高质量训练数据,这使得后训练方法的效果大打折扣。其次,训练一个高质量的过程奖励模型(PRM)需要大量人工标注的中间步骤数据,这在资源受限的情况下是不现实的。因此,rStar选择了一条"用算力换标注"的道路——通过MCTS在推理时进行大量搜索,找到高质量的推理路径。
更重要的是,rStar的代码完全开源,这为我们深入理解MCTS的每一个细节提供了可能。尽管其论文写得相对精简,省略了许多实现细节,但通过源码分析,我们可以完整地重现整个推理过程。这种从源码出发的学习方式,相比单纯阅读论文或想象实现方案,能够让我们获得更扎实的理解。
1.2 构造搜索树:从人类思维到算法实现
在深入MCTS的技术细节之前,让我们先从一个简单问题出发,思考人类是如何解决问题的。考虑这样一个问题:"停车场原有3辆车,又来了2辆车,现在停车场有多少辆车?"面对这个问题,我们可能采用多种思考方式。
第一种方式是步步推理(Action A1)。我们将问题分解为多个步骤:第一步,确定停车场原有车辆数量为3辆;第二步,确定新来车辆数量为2辆;第三步,将两个数字相加得到5辆;第四步,给出最终答案。这种方式的特点是每一步都有明确的中间结果,最后一步以"答案是"开头。
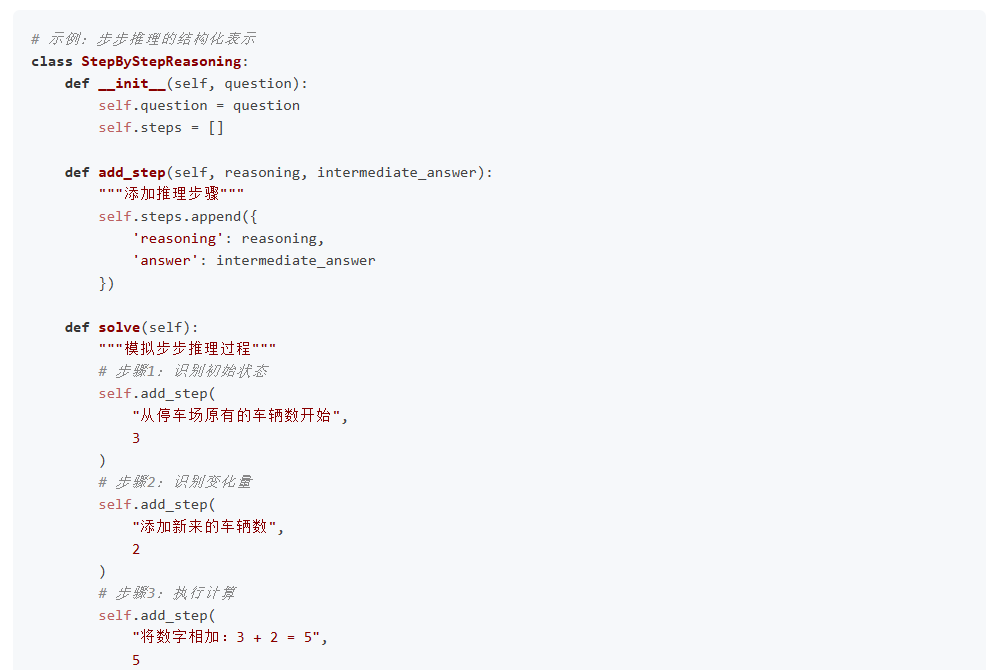

第二种方式是一步到位(Action A2)。对于简单问题,我们可能不会进行详细的步骤分解,而是直接给出答案:"原来有3辆,来了2辆,3加2等于5,答案是5。"这种方式省略了中间的细节推理过程。
第三种方式是子问题分解(Action A3)。我们可以将原问题拆解为一系列子问题:子问题1.1询问停车场原有多少辆车,答案是3辆;子问题1.2询问新来多少辆车,答案是2辆;子问题1.3整合前两个答案,得出最终结果5辆。这种方式更适合处理复杂问题,通过逐步缩小问题规模来降低求解难度。
除此之外,还有两种辅助性的思考方式。第四种是重新回答子问题(Action A4),当我们对某个子问题的答案不确定时,可以用不同的方法重新求解。第五种是问题改写(Action A5),即将冗长的问题描述精炼为关键信息,例如提取条件1、条件2等核心要素。
在rStar的实现中,这五种思考方式被转化为具体的prompt模板,用于指导模型执行不同的推理动作。下面展示了如何将这些思考方式组合成一棵搜索树。搜索树的根节点是用户的原始问题,从根节点出发,模型可以选择采用A1到A5中的任意一种或多种方式进行探索。方形节点表示终止节点,例如A2节点一步到位给出答案后即终止。虚线表示可选探索,实线表示必须探索。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)