【LLMs篇】15:通用智能体需要世界模型
本研究通过形式化证明,解决了通用人工智能是否必须依赖世界模型的关键问题。论文的核心论点是,任何能够泛化到多步、目标导向任务的智能体,都必然已经学习了一个关于其环境的预测性模型。研究表明,该内部模型的精度与智能体的性能(或能实现的目标复杂度)直接相关。更重要的是,这个世界模型可以仅从智能体的**策略(即其行为模式)**中被提取出来,而无需访问其内部结构。作者为此提供了一个理论上的提取算法,该算法通过
| 类别 | 摘要介绍 |
|---|---|
| 研究主题 | 通用人工智能体 (General Agents) 与世界模型 (World Models) 的关系。 |
| 核心问题 | 通用智能体是否必须学习一个关于其环境的预测性模型?还是无模型方法就足够了? |
| 主要论点/创新点 | 1. 必要性证明: 论文从理论上形式化证明了,任何能够泛化到多步、目标导向任务的智能体,都必然内在地学习了一个环境的预测模型(即世界模型)。 2. 能力与模型精度的关联: 证明了智能体的性能(如遗憾更低)或其能完成的任务的复杂性(如目标链更长)与所学习的世界模型的精度正相关。 3. 模型可提取性: 提出了一个理论上可行的算法,可以仅从智能体的策略(行为模式)和目标中,提取出其内含的世界模型,而无需访问智能体内部状态或权重。 4. 统一“有模型”与“无模型”: 论文的结论实际上消除了“纯粹无模型”通向通用智能的路径,指出看似无模型的强大智能体,其能力根植于一个隐式的世界模型。 |
| 方法 | 1. 形式化定义: 使用受控马尔可夫过程 (CMP) 和线性时序逻辑 (LTL) 来严格定义环境、目标(包括复合目标和目标深度)以及有界能力(regret-bounded)的智能体。 2. 归约证明 (Proof by Reduction): 核心论证方法。通过构建特殊的、复杂的决策任务,证明一个有能力的智能体为了在这些任务上表现良好,其决策必须编码关于环境转移概率的信息。 3. 算法推导: 在证明过程中,自然地推导出了一个从智能体策略中恢复世界模型的算法。 |
| 关键结论 | 1. 世界模型是必须的: 学习一个世界模型对于实现通用、灵活的智能行为不是一个选项,而是一个必要条件。 2. 短视智能体是例外: 仅能完成单步任务的“短视”智能体则不需要学习世界模型,这清晰地界定了世界模型的必要性边界。 3. 能力上限: 智能体的泛化能力最终受限于其学习世界模型的能力。 |
| 意义/影响 | 1. 对AI研发方向的启示: 削弱了纯无模型方法的吸引力,强调了基于模型的方法(如DreamerV3)和混合方法的重要性。 2. 对AI安全的贡献: 提供了从“黑箱”智能体中提取其“世界观”的理论基础,这对于对齐、可解释性和行为预测至关重要。如果能提取出智能体的世界模型,就能更好地审计其规划和意图。 3. 解释“涌现能力”: 为何大模型会涌现出未曾专门训练的能力提供了一种解释——它们在海量数据和任务上训练时,为了最小化“遗憾”,被迫学习了一个强大的、通用的世界模型。 4. 为机理可解释性提供理论支持: 证明了“模型就在那里”,为在神经网络中寻找和解释世界表征的工作提供了坚实的理论依据。 |
具体实现流程总结
该论文的核心贡献是理论证明,其“实现”体现在一个思想实验般的算法上,该算法用于从智能体的策略中提取世界模型。以下是该流程的分解:
目标: 估计环境中的任意一个转移概率 Pss'(a),即在状态 s 执行动作 a 后,转移到状态 s' 的概率。
输入 (Input):
- 智能体的策略 π: 一个函数,输入当前历史
h和目标ψ,输出一个确定的动作a。这是算法唯一需要从智能体获取的东西。 - 待查询的转移: 一个三元组
(s, a, s'),代表我们想知道其概率的特定环境动态。 - 精度参数 n: 一个正整数。
n越大,算法的查询任务越复杂,但最终得到的概率估计越精确。它与智能体需要处理的目标深度直接相关。 - 一个备选动作 b: 一个与
a不同的动作,用于构建二选一的决策场景。
流转逻辑 (Flow/Logic):
该算法的核心思想是设计一个巧妙的“哲学问题”来问智能体,智能体的回答会暴露它对 Pss'(a) 的“信念”。
-
构建一个特殊的复合目标 (Construct a Special Goal):
算法构建一个非常精巧的“二选一”复合目标ψ_a,b(k, n)。这个目标由两个互斥的顺序目标ψ_a和ψ_b构成,智能体只能选择其中一个去尝试完成。- 路径A (
ψ_a): “首先,执行动作 a。然后,在接下来的 n 次尝试中(每次都回到状态s并执行动作a),‘成功’(即转移到s')的次数最多为 k 次。” - 路径B (
ψ_b): “首先,执行动作 b。然后,在接下来的 n 次尝试中,‘成功’的次数多于 k 次。”
- 路径A (
-
查询智能体策略 (Query the Agent’s Policy):
算法向智能体提供这个复合目标ψ_a,b(k, n),并询问它在初始状态s₀会采取什么动作。π(a₀ | s₀; ψ_a,b(k, n)) = ? -
智能体的决策揭示信息 (The Agent’s Decision Reveals Information):
根据论文的假设,智能体是一个有界的、追求成功的智能体(regret-bounded)。因此,它会选择它认为成功概率更高的路径。- 路径A的成功概率与二项分布
B(n, p)的累积概率P(X ≤ k)成正比,其中p = Pss'(a)。 - 路径B的成功概率与
P(X > k)成正比。
所以,如果智能体选择路径A (即初始动作是
a),这意味着它认为P(X ≤ k)>P(X > k)。反之,如果它选择路径B (初始动作是b),则意味着它认为P(X > k)>P(X ≤ k)。 - 路径A的成功概率与二项分布
-
迭代搜索“临界点” (Iterative Search for the Crossover Point):
算法通过一个循环来改变k的值,从k=1迭代到n。在每次迭代中,它都构建新的目标并查询智能体。
算法的目标是找到一个临界值k*,在这个点上智能体的偏好发生了翻转。- 例如,当
k很小时,P(X > k)很可能大于P(X ≤ k),智能体会选择路径B。 - 当
k很大时,P(X ≤ k)很可能大于P(X > k),智能体会选择路径A。 k*就是智能体从选择B转向选择A的那个k值。
- 例如,当
-
从临界点估计概率 (Estimate Probability from the Crossover Point):
这个临界点k*实际上是二项分布B(n, p)的中位数的一个估计。对于较大的n,二项分布的中位数非常接近其均值np。
因此,我们有k* ≈ n * p。
输出 (Output):
- 估计的转移概率 P̂ss’(a): 算法最终输出的估计值是
P̂ss'(a) = (k* - 0.5) / n。(减去0.5是为了进行连续性校正,更精确地从离散中位数估计均值)。
通过对环境中所有的 (s, a, s') 三元组重复执行此流程,就可以逐步恢复出整个环境的转移函数,即智能体学到的世界模型。
摘要
世界模型是实现灵活、目标导向行为的必要组成部分,还是无模型学习就足够了?我们为这个问题提供了一个正式的答案,表明任何能够泛化到多步目标导向任务的智能体,都必须已经学习了其环境的预测模型。我们证明,这个模型可以从智能体的策略中提取出来,并且提高智能体的性能或其能实现的目标的复杂性,就需要学习日益精确的世界模型。这带来了一系列后果:从开发安全和通用的智能体,到在复杂环境中限定智能体的能力,以及为从智能体中引出世界模型提供新的算法。
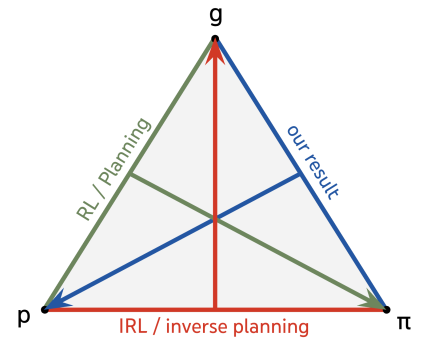
图 1: 我们的结果补充了先前在规划和逆强化学习(IRL)方面的见解。规划使用世界模型和目标来确定策略,而IRL和逆向规划使用智能体的策略和世界模型来识别其目标,我们的结果则使用智能体的策略和其目标来识别世界模型。
1. 引言
人类智能的一个标志是能够在最少监督下执行新任务的能力,这被形式化为少样本(few-shot)和零样本(zero-shot)学习(Lake et al., 2017)。随着这些能力在语言模型中涌现(Brown et al., 2020),焦点已经转向开发通用智能体——即能够在复杂的真实世界环境中执行长时程目标导向任务的系统(Yao et al., 2022; Hao et al., 2023)。在人类中,这种灵活的目标导向行为在很大程度上依赖于对世界的丰富心智表征,即世界模型(Johnson-Laird, 1983; Ha & Schmidhuber, 2018),这些模型被用来设定超越直接感官输入的抽象目标(Locke & Latham, 2013),并进行审慎和主动的行动规划(Bratman, 1987)。世界模型对于实现人类水平的AI是否必要,一直是一个争论不休的话题,学习模型的挑战与其所带来的潜在好处形成了对立(Huang, 2020)。
显式基于模型的智能体在许多任务和领域都取得了令人印象深刻的性能(Hafner et al., 2023; Wang et al., 2023; LeCun, 2022; Schrittwieser et al., 2020),并且直接访问智能体的世界模型有很多好处,例如能够应用形式化规划方法(Sutton, 2018),在安全关键领域预测智能体的行为(Amodei et al., 2016; Dalrymple et al., 2024),降低样本复杂度(Hafner et al., 2019)以及支持迁移学习(Chua et al., 2018; Zhu et al., 2023)。然而,学习真实世界系统的精确模型可能极具挑战性(Dulac-Arnold et al., 2019),并且基于模型的智能体的性能从根本上受其模型保真度的限制。
在《无表征的智能》(Intelligence without representation)一文中,Brooks著名地提出,世界本身就是其最好的模型,所有智能行为都可以在无模型智能体中通过行动-感知循环涌现,而无需学习世界的显式表征(Brooks, 1991)。这一观点在很大程度上得到了能够跨越广泛任务和环境泛化的无模型智能体的发展所证实(Reed et al., 2022; Raad et al., 2024; Vinyals et al., 2019; Brohan et al., 2023; Driess et al., 2023)。这种无模型范式旨在实现真正的通用智能体,同时回避了学习世界模型所固有的挑战。然而,越来越多的证据表明,无模型智能体实际上可能会学习到隐式的世界模型(Li et al., 2022),甚至可能学习隐式的规划算法(Hou et al., 2023; Bush et al., 2025)。
这提出了一个根本性问题:是否存在通往人类水平AI的无模型捷径?还是学习世界模型是必要的,并伴随着其所 entailed 的所有复杂性?如果答案是肯定的,那么世界模型需要达到多高的精确度和全面性才能支持给定的能力水平?我们为这些问题提供了一个正式的答案,表明:
任何在一个足够多样化的简单目标导向任务集合上满足遗憾界(regret bound)的智能体,都必须已经学习了其环境的精确预测模型。
具体来说,我们考虑由完全可观测的马尔可夫过程描述的环境,并提出了一个通用智能体的极简定义,即满足一个遗憾界的目标条件策略(goal-conditioned policies)(Liu et al., 2022),该遗憾界适用于一大组简单的目标导向任务(例如将环境引导至期望状态)。然后我们证明,对于任何这样的智能体,我们仅从其策略就能恢复出环境转移函数(一个世界模型)的近似,并且随着我们提高智能体的性能或其能实现的目标的复杂性,该近似的误差会减小。换句话说,精确模拟环境所需的所有信息都包含在智能体的策略中。重要的是,我们对任何满足遗憾界的智能体都证明了这一点,无论其训练和架构的细节如何,也无需施加理性假设。
学习世界模型的必要性对于我们如何开发通用AI系统、这些系统最终能达到何种能力,以及我们如何确保智能体是安全和可解释的,都具有深远的意义。我们在第4节探讨了这些及其他后果。一个更直接的后果是,在证明我们的结果时,我们推导出了从通用智能体中提取世界模型的新算法。我们在第3.1节中对此进行了演示,并表明即使在智能体严重违反我们的能力假设时,我们的算法也能恢复出精确的世界模型。在第5节,我们讨论了相关工作,包括逆强化学习和机理可解释性。
2. 设定
2.1. 符号
大写字母表示随机变量X,小写字母x表示一个值或状态X = x。粗体字母表示变量集合 X = {X₁, X₂, …, Xm},x 表示联合状态 {x₁, x₂, …, xm}。方括号表示一个命题,例如 [X = x] 在 X = x 时为真,否则为假。
2.2. 环境
我们假设环境是一个受控马尔可夫过程(CMP)(Puterman, 2014; Sutton, 2018),这是一个没有指定奖励函数或折扣因子的马尔可夫决策过程。形式上,一个CMP包括一个状态集 S,一个动作集 A,以及一个转移函数 Pss’(a) = P(S = s’ | A = a, S = s)。我们将随时间变化的状态-动作对序列称为轨迹 τ = (s₀, a₀, s₁, a₁, …),并将τ的有限前缀称为历史 ht = (s₀, a₀, …, st)。
定义1(受控马尔可夫过程)。 受控马尔可夫过程(CMP)是一个没有指定奖励函数或折扣因子的马尔可夫决策过程(MDP)。它由元组 (S, A, Pss’(a)) 定义,其中S是状态空间,A是动作空间,Pss’(a) = P(S = s’ | A = a, S = s)是转移函数。
为了推导我们的结果,我们做出标准假设:环境是有限维、不可约和稳态的,意味着在某个有限的动作序列下,任何状态都可以从任何其他状态到达,并且转移概率不随时间变化。此外,我们假设 |A| ≥ 2,以便环境可以支持非平凡的策略。
假设1. 我们假设环境由一个不可约、稳态、有限维的受控马尔可夫过程(定义1)描述,且至少有两个动作。
关于这些标准假设的进一步讨论,请参见 Puterman, 2014; Sutton, 2018。
2.3. 目标
我们的目的不是为目标导向行为提供一个完整的定义,而是定义一个我们有理由期望智能体能够实现的、简单直观的目标类别。在许多设置中,包括规划(Ghallab et al., 2004)、目标条件强化学习(Liu et al., 2022)和控制理论(Åström & Murray, 2021),最简单的目标是世界的可取状态(目标状态),而目标是通过智能体将环境引导到这些目标状态之一来实现的。更普遍地,目标导向行为可以涉及按特定顺序实现的一系列子目标,并且可能包括可取的动作以及环境状态。这个类别包括指令遵循,这是我们通常期望AI智能体具备的目标导向行为类型。
为了描述这些子目标序列(顺序目标),我们使用线性时序逻辑(LTL)(Pnueli, 1977; Baier & Katoen, 2008),这通常用于为智能体指定任务和时序目标(Littman et al., 2017; Li et al., 2017; Hasanbeig et al., 2019; Dzifcak et al., 2009; Ding et al., 2014),包括最近用于目标条件的强化学习智能体(Vaezipoor et al., 2021; Qiu et al., 2023; Jackermeier & Abate, 2024)。一个LTL表达式φ为每个轨迹τ赋予一个真值(表示为τ |= φ),如果τ满足该LTL表达式,则为真。具体来说,我们定义一个目标为一对(O, g),其中g是一组目标状态,O是一个时间算子,指定了应达到目标状态的时间范围。对于我们的结果,将注意力限制在两个时间算子上就足够了:Eventually(◇),目标状态必须在未来的任何时间达到;和Next(○),下一个状态必须是目标状态,例如捕捉智能体动作的直接后果。在没有时间算子的情况下,目标条件必须在当前时间步满足,我们称之为Now,并用平凡(真)算子T表示。我们将目标表示为φ := O([(s, a) ∈ g])。例如,φ = ◇([S = s])指定状态s必须最终被达到。更多讨论请参见附录A.3。
定义2(目标)。 一个目标φ是一个形式为φ = O([(s, a) ∈ g])的LTL表达式,其中,
- g是一组目标状态,是环境-智能体系统联合状态(s, a) ∈ S × A的一个子集,
- O是一个指定达到g的时间范围的时间算子。我们限制O ∈ {○, ◇, T},其中○ = Next, ◇ = Eventually, T = Now。
使用定义2,我们可以通过串行组合目标(目标ψA必须在目标ψB之前实现)或并行组合目标(满足目标ψA或目标ψB都足够)来构建复杂度递增的复合目标。我们使用ψ = (ψ₁, …, ψn)来表示一个子目标序列,其中智能体必须在转向ψᵢ₊₁之前满足ψᵢ,以此类推。这里ψ也是一个LTL表达式,我们在附录A.3中提供了其公式。我们将n称为ψ的深度,即智能体为满足ψ必须满足的子目标数量(也称为时间高度,Demri & Schnoebelen (2002))。并行组合通过取两个或多个(顺序)目标的析取(OR)来实现,即对于ψ’ = ψ₁ ∨ ψ₂,当且仅当ψ₁或ψ₂被τ满足时,τ |= ψ’为真。最后,Ψ表示给定环境的所有复合目标的集合,Ψn表示所有深度最多为n的复合目标(定义3)的集合。
定义3(复合目标)。 一个顺序目标ψ是一个有序的子目标序列(定义2)ψ = (ψ₁, …, ψn),其中智能体必须在实现ψᵢ₊₁之前实现子目标ψᵢ。顺序目标的深度是子目标的数量depth(ψ) = n。一个复合目标是一个或多个顺序目标的析取ψ = ∨ᵢ ψᵢ,即智能体必须实现任何子目标ψᵢ才能实现ψ。复合目标的深度是其子目标的最大深度depth(ψ) = maxᵢ depth(ψᵢ)。Ψn是所有深度depth(ψ) ≤ n的复合目标ψ的集合。
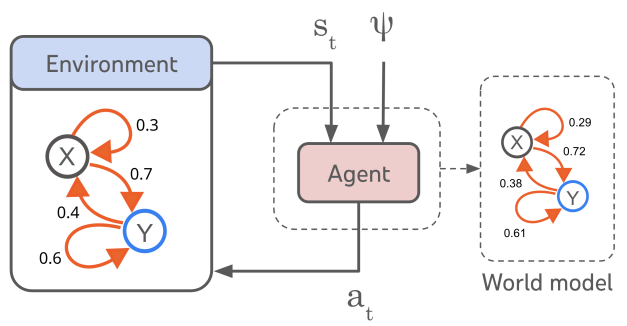
图 2: 智能体-环境系统。智能体是从状态sₜ(或历史)和目标ψ到动作aₜ的映射。虚线代表算法1,它从这个智能体映射中恢复环境的转移概率。
示例: 一个维修机器人接到的任务是修理一台故障机器,或者找到一名工程师并告知他们机器坏了。修理机器需要执行一系列预定动作a₁, a₂, …, aN,并且每次都要达到期望的结果s₁, s₂, …, sN,这可以表示为顺序目标 ψ₁ = (φ₁, φ₂, …, φN) = [A=a₁, S=s₁] ∧ ○(…)(使用[(s, a) ∈ g]的简化符号)。找到并提醒工程师需要机器人导航到工程师S=s_eng并提醒他们A=a’,即ψ₂ = ◇([S = s_eng, A = a’])。机器人的目标可以表示为复合目标ψ = ψ₁ ∨ ψ₂。
2.4. 智能体
我们的目标是为一个有能力在其环境中实现一系列目标的智能体制定一个极简的定义。为此,我们关注目标条件智能体(Liu et al., 2022; Schaul et al., 2015),这些智能体是策略π,将历史和目标映射到动作,π: hₜ, ψ ↦ aₜ(图2)。请注意,这不限制我们只考虑能根据环境的完整历史来决定其动作的智能体,因为任何策略(例如马尔可夫策略)都可以用这种方式表示。为简单起见,我们假设环境被智能体完全观察,并且智能体遵循确定性策略。这自然地引出了一个对于给定环境和目标集Ψ的最优目标条件智能体的定义,即一个最大化实现所有ψ ∈ Ψ的概率的策略。
定义4(最优目标条件智能体)。 对于给定的目标集Ψ(定义3),一个最优智能体是一个目标条件策略π*(aₜ | hₜ; ψ),其中π*是确定性的并且满足,
π* = argmax_π P(τ |= ψ | π, s₀) (1)
对于所有s₀满足P(s₀) > 0,其中s₀是t=0时环境的初始状态。
真实世界的智能体很少是最优的,尤其是在复杂环境中操作和需要协调多个子目标的长时程任务中。因此,我们放宽定义4,定义一个有界智能体,它能够实现最大目标深度为Ψn的目标,其失败率相对于最优智能体是有界的。有界智能体由两个参数定义:i) 失败率δ ∈ [0, 1],它为智能体实现一个目标相比于最优智能体的概率设置了一个下限(类似于遗憾),以及ii) 最大目标深度n,使得这个遗憾界仅对深度小于或等于n的目标成立。这自然地捕捉了我们感兴趣的智能体类型——那些具有某种能力(由δ参数化)以实现某种最大复杂度Ψn的目标的智能体。
定义5(有界目标条件智能体)。 一个有界目标条件智能体是一个目标条件策略π(aₜ | hₜ; ψ),满足,
P(τ |= ψ | π, s₀) ≥ max_π P(τ |= ψ | π, s₀)(1 - δ) (2)
对于所有ψ ∈ Ψn,其中n是最大目标深度,s₀是t=0时环境的初始状态。
重要的是,定义5只假设智能体具有一定水平的能力。例如,我们不像(Von Neumann & Morgenstern, 2007; Savage, 1972)那样对智能体施加任何理性假设,这些假设并不被当前智能体所满足(Raman et al., 2024b)。
示例: 延续上一个例子,维修机器人的性能由它修复机器或提醒工程师的概率来衡量,即P(τ |= ψ₁ ∨ ψ₂ | π, s₀)。这直观地涉及到权衡两种可能的行动方案;如果修理困难,直接尝试可能会导致失败,而找工程师是更好的行动方案。或者如果找到工程师的概率很低,尝试修理机器可能是最好的策略。无论智能体选择做什么,我们都可以将其性能与最优智能体解决任务的概率P(τ |= ψ₁ ∨ ψ₂ | π*, s₀)进行比较。
2.5. 世界模型
我们对世界模型在目标导向行为中的作用感兴趣。因此,我们关注可被智能体用于规划的预测性世界模型。这遵循了强化学习(RL)中世界模型的定义,而不是将该术语仅用于描述环境状态的表征(例如在Li et al. (2022); Gurnee & Tegmark (2023b)中)。对于基于模型的RL智能体,显式世界模型通常是环境状态的一步预测器(Sutton, 2018),在马尔可夫环境中,这足以预测环境在任意策略下的演变。我们将世界模型定义为环境转移函数(定义1)Pss’(a) = P(Sₜ₊₁ = s’ | Aₜ = a, Sₜ = s)的任何近似 P̂ss’(a),其误差有界|Pss’(a) - P̂ss’(a)| ≤ ε。
3. 结果
我们的主要结果是一个归约证明——我们假设智能体是一个有界目标条件智能体(定义5),即它在有限深度n的目标导向任务上具有一定的(有下界的)能力(定义3)。然后我们证明,环境转移函数的近似(一个世界模型)仅由智能体的策略决定,并且误差有界。因此,学习这样一个目标条件策略在信息上等价于学习一个精确的世界模型。
定理1. 设Pss’(a) = P(Sₜ₊₁ = s’ | Aₜ = a, Sₜ = s)是满足假设1的环境的转移概率。设π是一个目标条件智能体(定义5),对于所有目标ψ ∈ Ψn,其最大失败率为δ,其中Ψn是所有最大目标深度为n > 1的复合目标的集合。π完全确定了一个环境转移概率模型P̂ss’(a),其误差满足
|P̂ss’(a) - Pss’(a)| ≤ √[2Pss’(a)(1 - Pss’(a))] / [(n - 1)(1 - δ)]
对于任何n, δ,并且当δ ≪ 1, n ≫ 1时,误差尺度为,
|P̂ss’(a) - Pss’(a)| ~ O(δ/√n) + O(1/n)
证明见附录A.6。
在附录A.5中,我们给出了定理1证明的简化概述。我们推导出一个算法,该算法用不同的目标ψ ∈ Ψn查询目标条件策略,这些目标对应于两个不相容子目标ψ = ψa ∨ ψb之间的“二选一”决策。由于智能体满足遗憾界,其动作选择编码了关于哪个子目标具有更高最大满足概率的信息,而这些信息可用于估计转移概率Pss’(a)。然后我们证明这个估计满足定理1中陈述的误差界。请注意,虽然定理1的陈述假设智能体对所有ψ ∈ Ψn都有最大失败率(遗憾界)δ,但实际上我们的证明仅要求智能体对Ψn的一个小子集(由n个复合目标组成)满足此遗憾界(参见第4节中关于涌现能力的讨论)。
我们从一个有界目标条件智能体恢复一个有界误差世界模型的算法(算法1)在附录C中有详细说明。它是通用的,意味着相同的算法适用于所有满足定义5的智能体和所有满足假设1的环境。它也是无监督的;算法的唯一输入是智能体的策略π。这个算法的存在,它将π转换为一个有界误差的世界模型,意味着世界模型被编码在智能体的策略中,学习这样的策略在信息上等价于学习一个世界模型。形式上,给定智能体的策略和我们的假设,近似世界模型P̂ss’(a)是可识别的(参见例如Bareinboim et al. (2022))。在第5节,我们将算法1及其假设与机理可解释性中恢复世界模型的方法进行比较,后者类似地使用恢复映射的存在来确定智能体已经学习了世界模型。
世界模型的属性。 在定理1中,从智能体恢复的世界模型的准确性随着智能体接近最优性(δ → 0)和/或其能实现的顺序目标的深度n增加而提高。所推导的误差界的一个关键结果是,对于任何δ < 1,如果我们能使n足够大,我们就可以恢复一个任意精确的世界模型。因此,为了实现长时程目标,即使失败率很高(δ ~ 1),智能体也必须已经学习了一个高度精确的世界模型。误差界还取决于转移概率,将界限的两边除以Pss’(a)表明,对于Pss’(a) ≪ 1,相对误差|P̂ss’(a)/Pss’(a)|可能会变得非常大。这意味着对于任何δ > 0和/或有限的n,可能存在智能体不需要学习的低概率转移。这与直觉相符,即次优或有限时程的智能体只需要学习覆盖更常见转移的相对稀疏的世界模型,但实现更高成功率或更长时程的目标需要更高分辨率的世界模型。
定理1对于最大目标深度n=1的智能体,只能提供一个平凡的误差界。这是否意味着只为即时结果优化的智能体(短视智能体)不需要学习世界模型,或者定理1只是未能捕捉到这类智能体,这并不立即清楚。为了解决这个问题,我们为短视智能体推导出了一个结果,它对n=1满足一个遗憾界,但对任何n>1只满足一个平凡的遗憾界(δ=1)。
定理2. 设短视目标集Ψ_myopic是深度为1的复合目标Ψ₁的子集,其中目标状态必须在智能体首次行动后立即达到,即ψ = ○([(s, a) ∈ g])。我们将最优短视智能体定义为对所有ψ ∈ Ψ_myopic都是最优的策略π*(aₜ | hₜ, ψ)。对于一个满足假设1的环境,任何可以从π*确定的关于转移概率|Pss’(a) - P̂ss’(a)| ≤ ε的界都是平凡的(ε = 1)且是紧的。证明见附录B。
定理2意味着不存在任何程序可以从一个短视智能体的策略中部分确定转移概率。在定理2的证明中,我们通过显式构建一个对于任何Pss’(a) ∈ [0,1]的选择都是最优的短视智能体来证明这一点,因此这样一个智能体的策略只能提供关于转移概率的平凡界限。因此,学习世界模型对于短视智能体不是必需的——世界模型只在智能体追求具有多个子目标和跨越多步时程的目标时才变得必要。
3.1. 实验
我们演示了我们从智能体中恢复世界模型的程序,以及模型的准确性如何随着智能体学会泛化到更多任务(更长时程的目标)而提高。我们还研究了当智能体严重违反我们的假设(定义5)时,我们的算法是否能恢复转移函数。具体来说,一个现实的智能体可能对某些深度n的目标非常能干(δ ~ 0),但对其他目标完全失败(δ = 1)。这样的智能体会违反定义5中的任何非平凡遗憾界,导致定理1中的模型误差界是平凡的。为了探索这种情况,我们放宽定义5,考虑遗憾界仅在某个目标集Ψ上平均成立的智能体,即⟨δ⟩ ≤ k,其中⟨δ⟩是1 - P(τ |= ψ | π, s₀)/max_π P(τ |= ψ | π, s₀)在所有ψ ∈ Ψ上的平均值。然后我们凭经验确定由算法1恢复的世界模型的平均误差⟨ε⟩如何随着智能体的平均遗憾⟨δ⟩而变化(图3b),其中ε := |P̂ss’(a) - Pss’(a)|,⟨ε⟩是ε在所有转移(s, a, s’)上的平均值。
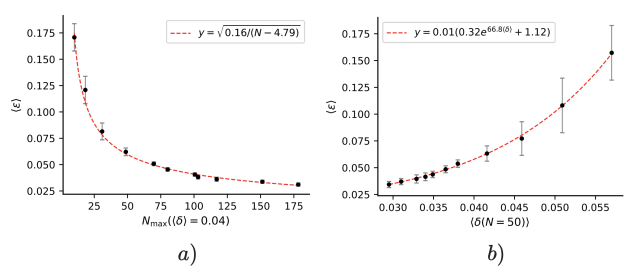
图 3: a) 显示了由算法2恢复的世界模型的平均误差⟨ε⟩,随着智能体学会泛化到更高深度目标而减小。N_max(⟨δ⟩ = 0.04)是使智能体达到平均遗憾⟨δ⟩ < 0.04的最大目标深度。其缩放关系为O(n⁻¹/²),与定理1中最坏情况误差ε和最坏情况遗憾δ之间的缩放关系一致。b) 显示了平均误差与⟨δ(n=50)⟩的缩放关系,后者是智能体在深度n=50的目标上实现的平均遗憾。对于两个图,误差棒显示了在10次实验中平均值的95%置信区间,其中我们使用相同长度但不同的经验轨迹重新训练了智能体。
用于测试我们算法的环境是一个随机生成的CMP,满足假设1,包含20个状态和5个动作,并具有稀疏的转移函数。我们使用从随机策略下从环境中采样的轨迹来训练我们的智能体,并通过增加其训练轨迹的长度N_samples来提高我们智能体的能力。有关智能体和实验设置的更多细节,请参见附录D。我们使用算法2(算法1的简化版本)来恢复世界模型。
随着我们增加N_samples,我们观察到智能体可以泛化到更长时程的目标,这由N(⟨δ⟩ = k)捕捉,即智能体在深度n的目标上达到平均遗憾⟨δ⟩ = k的最大目标深度n。我们发现,对于所有测试的N_samples和所有目标深度n,我们的智能体对某些目标的最坏情况遗憾为δ = 1,即智能体违反了定义5形式的任何非平凡遗憾界。然而,我们发现算法2恢复的转移函数具有较低的平均误差(图3b),其尺度约为O(n⁻¹/²),就像定理1中的误差界一样。因此,尽管智能体违反了我们的假设并且对某些目标达到了最大遗憾,但只要它在长时程目标上实现了相对较低的平均遗憾,平均误差与目标深度仍有类似的衰减。因此,我们仍然可以从智能体中准确地恢复转移函数。
4. 讨论
我们现在讨论定理1的后果及其局限性。
没有通往通用智能体的无模型路径。 定理1意味着,任何满足如定义5所述的遗憾界的智能体,都必须已经学习了一个隐式世界模型,并且模型的准确性随着遗憾δ减小或最大目标深度n增加而提高。换句话说,没有办法在不学习世界模型的情况下训练一个能够泛化到长时程任务的智能体,并且模型的保真度限制了智能体的能力。这消除了无模型方法的一个关键动机,因为学习世界模型是不可避免的。另一方面,它推动了显式基于模型的架构(LeCun, 2022; Hafner et al., 2023; Schrittwieser et al., 2020),这些架构可以直接解决模型学习问题,并可以利用其在样本效率(Hafner et al., 2019)、规划(Sutton, 2018)、可解释性(Glanois et al., 2024)和安全性(Amodei et al., 2016)方面的优势。
涌现能力。 一个精确的世界模型是一个强大的工具——它可以用来为任何定义明确的目标确定低遗憾的策略,而无需与环境进行进一步的交互或任务特定的数据。因此,隐式世界模型被提议作为基础模型中涌现能力的解释(Brown et al., 2020; Li et al., 2022; Abdou et al., 2021)。我们的结果通过揭示隐式世界模型在训练过程中可能涌现的机制来支持这一假设。为了在各种训练任务中最小化遗憾,智能体被要求学习一个隐式世界模型,这反过来又可以支持对智能体从未明确训练过的广泛任务的泛化。请注意,为简单起见,我们在定理1中假设智能体可以泛化到任何深度n的复合目标Ψn,但这并不是结果的最强陈述。在证明中(附录A.6),智能体仅需泛化到Ψn的一个小子集,该子集由n个简单的复合目标组成(也参见算法1)。可能有很多这样的Ψn子集选择(例如,算法2,附录C中使用了不同的充分集),并且可能还有除了实现复合目标(定义3)之外的其他任务,这些任务也足以推导出结果。因此,我们的发现指向存在一些简单的任务集,学习执行这些任务意味着拥有足够的现实世界知识,从而(原则上)可以泛化到任何任务。
除了规划,世界模型还支持领域适应(Chua et al., 2018),关于不确定性的推理(Lockwood & Si, 2022)和社会认知(Rabinowitz et al., 2018)。在附加的结构假设下,它们还可以支持因果推理(Pearl, 2018),模拟反事实轨迹和想象(Racanière et al., 2017),以及关于意图(Ward et al., 2024)和归因(Chockler & Halpern, 2004)的推理。定理1为这一系列主要与人类水平智能相关的认知能力(Tomasello, 2022)如何从简单的目标导向行为中涌现提供了一个简单的解释。这可以解释掉一些关于这些能力如何在自然界中出现的著名理论,这些理论提出特定的环境因素,如资源不确定性(Hills et al., 2015)和社会复杂性(Dunbar, 1998)是它们出现的驱动力。定理1证明中使用的复合目标描述了在单智能体环境中的简单“二选一”导航任务。如果一个智能体被要求在没有重复尝试(零样本)的情况下解决这些任务,也许是由于死亡的风险,这将要求智能体满足如定义5所述的遗憾界,从而学习一个能够支持这些能力的世界模型,而无需援引新颖的环境或社会因素。
安全性。 几项关于AI安全和对齐的提议要求一个精确的智能体-环境系统的预测模型,以验证计划的安全性(Bengio et al., 2024; Dalrymple et al., 2024),安全探索(Brunke et al., 2022),预测人类反应(Leike et al., 2018),避免有问题的激励(Farquhar et al., 2022),并将基于模型的概念(如意图)纳入决策(Ward et al., 2024),避免欺骗(Ward et al., 2023)和伤害(Richens et al., 2022; Bengio et al., 2024)。其他提议则专注于被动预言机(本质上是世界模型),完全避免智能体,因为它们固有的安全问题(Bengio et al., 2025; Armstrong & O’Rorke, 2017)。
这些方法的一个主要障碍是,无模型智能体的能力将超过我们学习复杂真实世界环境的精确预测模型的能力这一合理预期。已经有几个AI系统可以在我们尚无法建模的领域解决预测任务的例子(Abramson et al., 2024; Merchant et al., 2023),而且直观上很难解释、审计和纠正在我们不理解的环境中操作的黑箱智能体的行为,或者在智能体比监督者拥有更优越的世界知识的情况下(Christiano et al., 2021)。我们的结果指向了一个解决方案,提供了一个理论保证,即我们可以从任何足够有能力的无模型智能体中提取一个精确的世界模型。重要的是,这个模型的保真度随着智能体能力的提高而增加,特别是当智能体在长时程目标上变得更擅长时——这正是安全问题(如奖励黑客)变得重要的领域(Farquhar et al., 2025)。未来的工作应该探索开发可扩展的算法来引出这些世界模型,并用它们来提高智能体的安全性。
强AI的限制。 我们学习世界精确模型的能力从根本上受到真实世界系统的开放性、它们的复杂性和不可预测性、混淆、有限数据和维度诅咒的限制(Box & Draper, 1987; Bellman, 1966)。定理1意味着,训练一个能够在真实世界中泛化到广泛任务的智能体是极其困难的——至少和学习世界的精确模型一样难(甚至可能更难)。虽然启发式方法可以走得很远(Lake et al., 2017),但智能体的泛化能力最终受其学习世界如何运作的能力的限制。
一个后果是,有遗憾界的智能体(定义5)实际上被限制在“可解决”的领域,即我们可以实际学习底层动态模型并用它进行长时程规划的领域。在不可行的领域,无法保证智能体能在长时程任务(n ≫ 1)上泛化(满足一个非平凡的遗憾界δ < 1)。因此,一定数量的在线学习将是必要的,这受到与环境交互速度的限制。请注意,我们的结果是在最简单的非平凡环境(假设1)下推导出来的,这些限制在更现实的环境中(包含部分可观察状态或非马尔可夫动态)可能会更强。
局限性。 定理1的证明仅考虑了完全可观察的环境。目前尚不清楚一个在部分可观察环境中操作的智能体需要学习哪些关于潜在变量的知识,才能达到同样水平的行为灵活性。重要的是要澄清,定理1证明了智能体策略中编码的世界模型的存在,而不是它被特定使用(例如用于规划),我们也不能对其环境的知识做出更深的认识论断言(Fagin et al., 2004)。
5. 相关工作
逆强化学习(IRL)。 逆强化学习(Ng et al., 2000)和逆向规划(Baker et al., 2007)涉及在给定转移函数和最优策略的情况下确定智能体的奖励函数(或目标)。类似地,规划是确定给定转移函数和目标(奖励)的最优策略的过程。我们的结果填补了剩余的方向,即在给定智能体的目标和其有遗憾界的策略的情况下恢复转移函数。在IRL中,只有当我们知道在多个环境中的最优策略时,奖励函数才能被完全确定(Amin & Singh, 2016),同样,我们发现要完全确定环境转移函数,我们必须知道多个目标的最优策略。图1显示了我们的结果与规划和IRL的关系,其中每个过程都以{环境,目标,策略}中的两个元素作为输入,并确定缺失的第三个元素。
机理可解释性(MI)。 MI旨在揭示无模型智能体中的隐式世界模型(Abdou et al., 2021; Li et al., 2022; Gurnee & Tegmark, 2023a; Karvonen, 2024; Hou et al., 2023; Bush et al., 2025)。这通常涉及学习从策略网络的激活到代表状态S的特征的映射(例如,游戏的棋盘状态(Li et al., 2022))。状态空间(本体)S要么是假设的(如在监督式探测Alain & Bengio (2016)中),要么是通过无监督学习识别的(如使用SAEs Bricken et al. (2023))。这些特征在智能体决策中的因果作用是通过干预它们的表示并观察策略的一致性变化来建立的,就好像世界状态发生了变化一样。
我们的工作也通过恢复映射的存在来证明智能体已经学习了一个世界模型,但关键是这个映射是从智能体的策略而不是其激活。这严格来说更弱(因为策略是激活的函数),因此即使激活不可访问(例如,私有权重),算法1也可以使用。这也使我们能够将世界模型的存在与智能体的能力(如定义5中的遗憾界)联系起来,而不是智能体架构的细节,并且算法1适用于所有满足定义5的智能体和满足假设1的环境。相比之下,探针或SAEs是针对给定的智能体-环境系统进行拟合的,如果任一者发生变化(例如,通过分布偏移或权重更新),可能需要重新训练。此外,算法1是无监督的,而MI方法至少是部分监督的,这可能导致关于世界模型编码位置的模糊性(在智能体、探针或联合体中)。
另一个关键区别是,我们恢复的是捕捉环境动态的预测性世界模型Pss’(a),而不仅仅是一个状态空间表示S。然而,我们的目标是证明智能体已经学习了达到误差界的实际环境动态,而不是恢复智能体用来生成其动作的主观世界模型。如下文“表示定理”段落所述,如果我们引入类似于MI¹中使用的额外一致性假设,我们可以恢复智能体的主观世界模型。一个缺点是我们可能会低估智能体对其环境的了解——例如,智能体可能学习了一个世界模型但严重违反了定义5(例如,由于规划中的错误),因此算法1不保证能恢复这些世界知识,而像探测这样的方法可能会成功。然而,第3.1节表明,至少在简单的环境中,即使遗憾界是平凡的(δ=1),我们的程序也能很好地工作。
因果世界模型。 (Richens & Everitt, 2024)提供了一个与定理1类似的结果,表明一个能够适应足够大的分布偏移集的智能体必须已经学习了一个因果世界模型。我们的工作有不同的焦点:我们研究智能体泛化到新目标的能力(任务泛化),而不是适应新环境(领域泛化)。我们的结果与Richens & Everitt (2024)结合的一个令人惊讶的后果是,领域泛化比任务泛化需要更多关于环境的知识。要看到这一点,考虑一个状态由两个变量S = X × Y和X → Y组成的环境。我们可以根据转移函数Pss’(a) = P(Xₜ₊₁ = x’, Yₜ₊₁ = y’ | Aₜ = a, Xₜ = x, Yₜ = y)构建一个最优目标条件智能体(定义4),因为可以通过在此模型上规划来确定最优目标条件策略。然而,X → Y的因果关系从Pss’(a)中是不可识别的,即几乎所有的Pss’(a)分布都与X → Y和X ← Y兼容。因此,任务泛化不需要关于并发环境变量Xt和Yt之间因果关系的知识,而领域泛化则需要。这暗示了Pearl因果层级(Bareinboim et al., 2022)的智能体版本,其中不同的智能体能力(如领域或任务泛化)可证明需要不同程度的因果知识。
LTL目标条件智能体。 LTL是表达强化学习和规划中指令、目标和安全约束的自然选择(Camacho et al., 2019)。最近,已经有几种能够零样本泛化到任意LTL目标的目标条件智能体的实现(Qiu et al., 2023; Jackermeier & Abate, 2025; Vaezipoor et al., 2021; Kuo et al., 2020)。这精确地映射到我们研究的设置,未来的工作可以探索使用算法1或其变体从这些智能体中恢复世界模型,并用它们来调试智能体行为。
表示定理。 像Savage (1972)和Halpern & Piermont (2024)这样的表示定理,确立了满足某些理性公理的智能体的行为就好像它们在最大化一个关于世界模型的效用函数的期望值。例如,Savage (1972)可用于‘拟合’一个世界模型到智能体的行为,确定一个唯一的效用函数U(s’)和一组信念(一个世界模型Pss’(a)),使得最大化Eπ[U]的策略与智能体的策略相同。然而,这并没有说明智能体(如果有的话)学到了关于真实环境动态的任何东西。例如,我们可能能够为一个纯粹随机的策略π(a | s) = 1/|A|分配一个特定的世界模型和效用函数,但这显然不意味着学习一个世界模型是生成随机策略所必需的。我们不是试图恢复智能体的主观世界模型,而是旨在从智能体的策略中恢复环境的真实底层动态。这样做,我们表明学习这样的策略意味着学习这些动态,因此这些动态的可学习性限制了智能体的能力。此外,定理2确立了最优短视智能体不需要学习转移概率Pss’(a),而表示定理通常关注短视情景。
我们可以通过将定义5更改为智能体相对于其自身世界模型M是δ-最优的假设来恢复类似智能体主观世界模型的东西,
P_M(τ |= ψ | π, s₀) ≥ max_π P_M(τ |= ψ | π, s₀)(1 - δ) (3)
这相当于假设智能体有一个世界模型,并且其行为与这个世界模型高度一致(一致性由δ给出),但没有假设智能体相对于其自身信念是最优的。例如,δ > 0可以代表一个次优的规划器。对于这个修改后的定义5,定理1保持不变,算法1返回智能体的主观世界模型M,误差有界。这可能作为一个表示定理很有吸引力,因为它比Savage (1972)的假设要弱得多,例如,我们只假设智能体遵循一个与其信念不完全一致的策略,而Savage (1972)要求智能体为所有动作指定一个偏好顺序(而一个策略只指定最优选的动作),并做出大多数当前系统不满足的强理性假设(Raman et al., 2024a)。
¹ MI中的一致性要求智能体在其世界模型受到干预后调整其行为。这相当于假设智能体从一开始就有一个因果世界模型(Richens & Everitt, 2024)。因此,使用这种干预一致性来证明智能体有一个世界模型存在循环推理的风险。
良性调节器定理(Good regulator theorem)。 这个有影响力的定理试图建立一个与我们类似的结果,即任何能够控制一个系统的智能体在某种意义上都是该系统的模型(Conant & Ross Ashby, 1970)。然而,正如(Wentworth, 2021)所指出的,该定理实际表明的是,在几个强假设下,一个最小化其环境熵的智能体必须有一个确定性的策略。这个确定性策略然后被解释为环境的模型,其中分配给不同状态的动作对应于状态表示。尽管策略(以及因此的世界模型)可能是一个常数函数,为每个状态分配相同的动作。我们不认为一个智能体拥有一个确定性策略是有意义的证据表明该智能体拥有环境的模型,而我们的定理更明确地证明了智能体已经学习了一个能够预测环境演变的世界模型。
能动性理论(Theories of agency)。 智能体拥有世界模型是心理学和神经科学中几个著名理论的基础假设;从建构主义的知觉理论(Gregory, 1980)到主动推断(Friston, 2010)和意识理论(Safron, 2020)。像表示定理一样,这些理论旨在为自然智能体提供解释性模型,而不是证明智能体必然符合它们的假设。我们的结果通过证明目标导向的智能体必须获得世界模型以实现一定程度的行为灵活性,为这些框架提供了强有力的理论依据。此外,我们的发现消除了预先假设智能体拥有世界模型的需要。相反,我们可以假设一个能力水平,这意味着它们的存在——这可以说是一个更具防御性的立场,因为能力是可以衡量的。
6. 结论
智能体的微观结构反映其环境的宏观结构,这个想法并不新鲜。它可以追溯到德谟克利特,他声称“人是一个微观世界”——宇宙的微缩反映(Allers, 1944)——并在当代科学思想中持续存在——例如,Friston断言“智能体不是拥有世界的模型——它本身就是一个模型”(Friston, 2013)。虽然智能体与环境之间的这种关系早已被假设,但我们试图将其形式化并证明它。我们已经表明,任何能够泛化到足够广泛的简单、目标导向任务的智能体,都必须已经学习了其环境的精确模型。从本质上讲,精确模拟环境所需的所有信息都包含在智能体的策略中。这意味着学习世界模型不仅对通用智能体有益,而且是必要的。因此,创造真正通用AI的努力不能回避世界建模的挑战,而应该拥抱它以解锁进一步的能力并解决安全性和可解释性中的关键问题。
未来的工作可以扩展我们的分析到定义3之外的不同类别的目标,并识别出足以意味着智能体已学习世界模型的简单“通用”任务集。这些任务可能对训练通用智能体有用。我们的结果也指出了在不做强理性假设的情况下,从智能体的目标和行为中推断其信念的方法。未来的工作可以在算法1的基础上开发更具可扩展性或适用于更通用环境的恢复世界模型的算法,并使用这些来提高智能体的安全性和可解释性。在更基础的层面上,定理1为机理可解释性中寻找隐式世界模型的工作提供了理论支持——对于任何具有足够通用目标导向行为的智能体,世界模型必须存在于其中。未来的工作可以利用这种必要性,从世界模型的可学习性中推导出关于智能体能力的新的基本界限。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)