刚刚,机器人觉醒的最后一块拼图找到了:世界模型
一朋友做wm和ail,确实认为vla行不通,但不是因为行不通所以做wm,我入行之前就知道vla行不通,因为基于ail的算法被证明其理论下界是高于bc的。三十年前可以认为这两个词更模糊宽泛不现实不专业,三十年后还觉得模糊不专业,只能说三十年没有进步了,毕竟梯度下降和适者生存一样宽泛,但是方向就在这里,进度也到了这里。AI世界模型的这个路必然是离不开视频,3d,2d等方向的研究的。我认为世界模型的作用
个人感觉现在弄世界模型是为时过早的,目前且不说世界模型,光真实视频,图像都仍有很多问题尚未解决。AI世界模型的这个路必然是离不开视频,3d,2d等方向的研究的
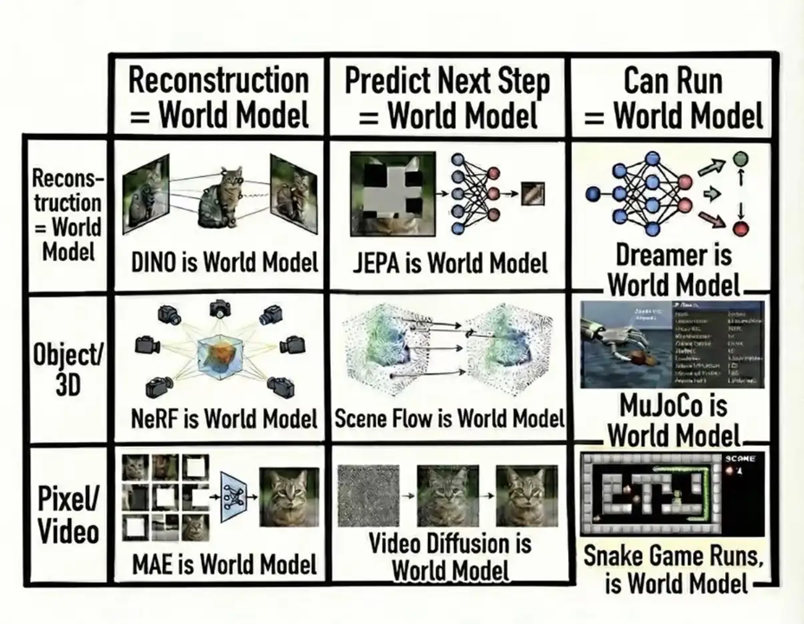
世界模型甚至都不是你说的正问题反问题的问题。目前所谓的世界模型,是降低精度数字孪生也就是CAE,用模型简化去模拟未来发生的状态。比如你把瓶子推桌子边,他会掉下去这种,对世界的模拟本来就是建立在有限元分析和傅里叶方程这类CAE方法上的。
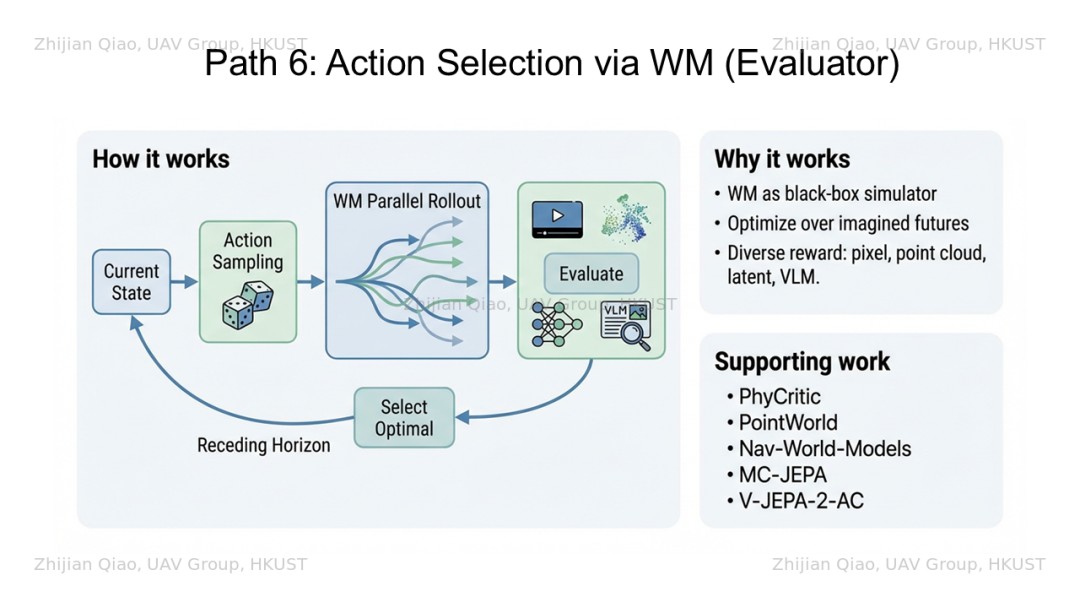
他的核心思想是通过大规模自回归建立动力学模型。单就这一个目的来说就足够重要且尚未解决。世界模型要的是大规模数据自监督的预训练,然后通过“泛化性”在你的正问题/反问题上微调来最终解决问题。现在的世界模型可以通过大规模训练,直接求解反问题。我想应该你理解的世界模型应该属于action conditional next frame pridiction。现在主流的世界模型在抛弃它。
世界模型要想真实,能够合理外推,就得靠CAE。但是这个算力需求可能大得离谱。想要算力需求低,就得唯像化,但这样做真实性就会存疑,很难再迭代回现实。
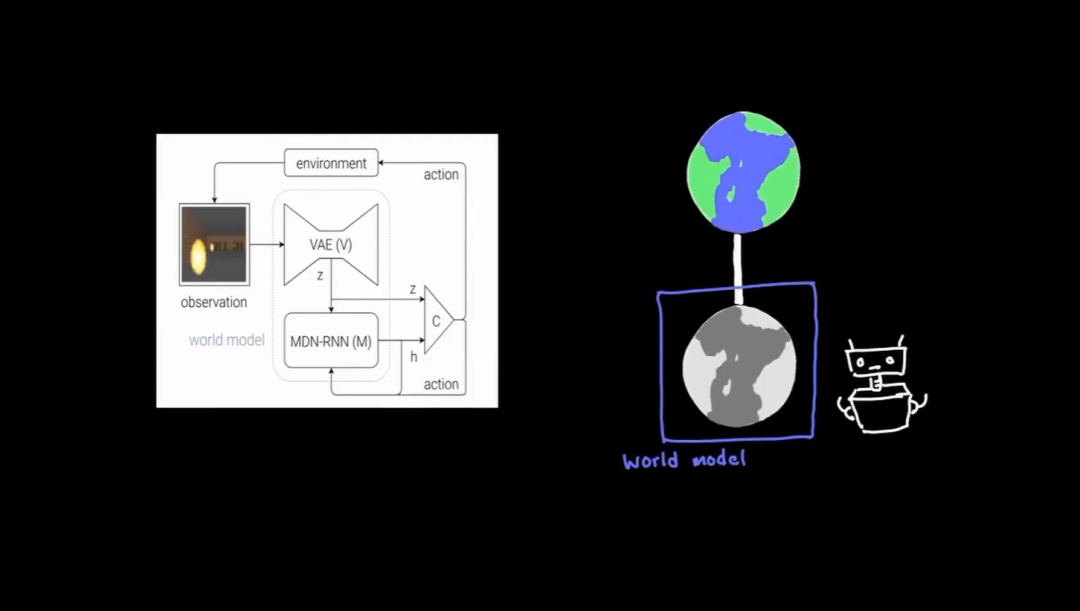
最好的世界模型就是世界自身,让大模型自己去与世界交互。具身智能可能更强调的是类人的感知和操作方式,以方便利用LLM从人类语言世界中提取压缩的知识。实际上,大模型与世界的交互并不一定要那么的类人,调用简单程序操控车子(类似fsd)也可以,甚至聊天也算是(相当于调用了输出token到语言的映射程序呗)
三十年前可以认为这两个词更模糊宽泛不现实不专业,三十年后还觉得模糊不专业,只能说三十年没有进步了,毕竟梯度下降和适者生存一样宽泛,但是方向就在这里,进度也到了这里
后面还是结合起来弄,毕竟有的符号定义起来可惜,但求解比较难,比如现在那些图像识别的。定义一个人容易,但从图像识别这个人还是比较难的。而且现在好像有神经语义学什么的,可能和这相关

严格来说我觉得可能文本就得是2维了(时间T还是要考虑进去),到Physics时间更是无法忽略,然后就需要更高规模的数据,也更没法scaling了。
一朋友做wm和ail,确实认为vla行不通,但不是因为行不通所以做wm,我入行之前就知道vla行不通,因为基于ail的算法被证明其理论下界是高于bc的。不过wm到底能不能行得通,我也不知道。至少有一点,相同的数据量,合理的训练方式ail是强过bc的
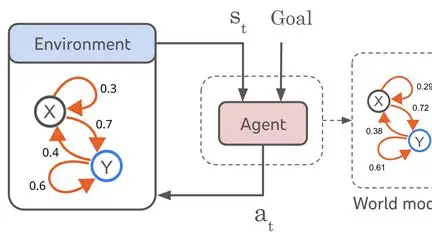
如果有足够的优质数据能训练出一个WM,或许VLA的训练效果也不差了。但是如果没有优质数据来训练高质量WM,指望用一个不太行的WM来做VLA的数据增广,或许效果也一般。
我认为世界模型的作用,是具身智能的前置,要先让模型在世界模型(模拟物理世界)中训练并抽象出基于物理世界的直觉推理能力。
人与大模型在学习成本和效率上有很大差距,人类大脑在一些方面(比如危险感知)有很强的直觉推理能力,并且在很多方面的学习具有很强的泛化能力。
多模态融合降维探索空间意义当然重大,纯视觉太局限了,尤其是缺少触觉模态来获得体积碰撞和物体性质的感知能力会造成很大的无意义探索空间
三十年前可以认为这两个词更模糊宽泛不现实不专业,三十年后还觉得模糊不专业,只能说三十年没有进步了,毕竟梯度下降和适者生存一样宽泛,但是方向就在这里,进度也到了这里。。。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)