20倍推理加速+10万亿token训练:Emu3.5开启多模态世界模型新纪元
北京智源研究院发布悟界·Emu3.5多模态世界大模型,通过原生多模态架构实现图文视频统一建模,推理速度提升20倍,性能媲美Gemini 2.5 Flash,为通用人工智能提供全新技术基座。## 行业现状:从"生成"到"理解"的范式转变2025年,多模态大模型已从单纯的内容生成迈向"世界理解"新阶段。据市场研究显示,72%的企业计划增加模型投入,其中动态物理世界建模和长时序推理成为核心需求。当
20倍推理加速+10万亿token训练:Emu3.5开启多模态世界模型新纪元
【免费下载链接】Emu3.5-Image  项目地址: https://ai.gitcode.com/BAAI/Emu3.5-Image
项目地址: https://ai.gitcode.com/BAAI/Emu3.5-Image
导语
北京智源研究院发布悟界·Emu3.5多模态世界大模型,通过原生多模态架构实现图文视频统一建模,推理速度提升20倍,性能媲美Gemini 2.5 Flash,为通用人工智能提供全新技术基座。
行业现状:从"生成"到"理解"的范式转变
2025年,多模态大模型已从单纯的内容生成迈向"世界理解"新阶段。据市场研究显示,72%的企业计划增加模型投入,其中动态物理世界建模和长时序推理成为核心需求。当前主流模型仍依赖模态适配器和扩散模型组合,存在生成逻辑断裂、时空一致性差等问题。例如,传统文生视频模型虽能生成逼真画面,却无法理解"苹果被拿走后桌面会变空"的基本物理规律。
在此背景下,智源研究院推出的Emu3.5通过原生多模态架构(Native Multimodal Architecture)直接预测视觉-语言序列的"下一个状态",首次实现无需任务特定头的端到端世界建模。

如上图所示,这是智源研究院举办“悟界·Emu系列技术交流会”现场,台上人员演讲介绍Emu3.5多模态世界大模型,台下参会者专注聆听、记录,展现人工智能技术发布的会议场景。这一发布会标志着我国在多模态大模型领域进入世界领先行列。
核心亮点:三大技术突破重构多模态能力
1. 统一世界建模范式
Emu3.5采用Decoder-only Transformer架构,将图像、文本、视频全部转化为离散token序列,通过单一"下一个状态预测"(Next-State Prediction)任务实现统一建模。与传统混合架构不同,其创新点在于:
- 无模态适配器:视觉与语言直接通过共享token空间交互
- 10万亿+多模态token训练:涵盖790年视频时长的时空数据,学习物理世界因果关系
- 动态场景一致性:支持第一视角虚拟世界探索,转身、移动时保持空间逻辑连贯
2. 20倍推理加速的DiDA技术
针对自回归模型生成效率低的痛点,Emu3.5提出离散扩散适配(Discrete Diffusion Adaptation, DiDA)技术,将传统token-by-token解码转化为双向并行预测,在保持生成质量的前提下实现20倍推理加速。实测显示,生成512x512图像仅需0.8秒,首次使开源模型达到闭源扩散模型的效率水平。
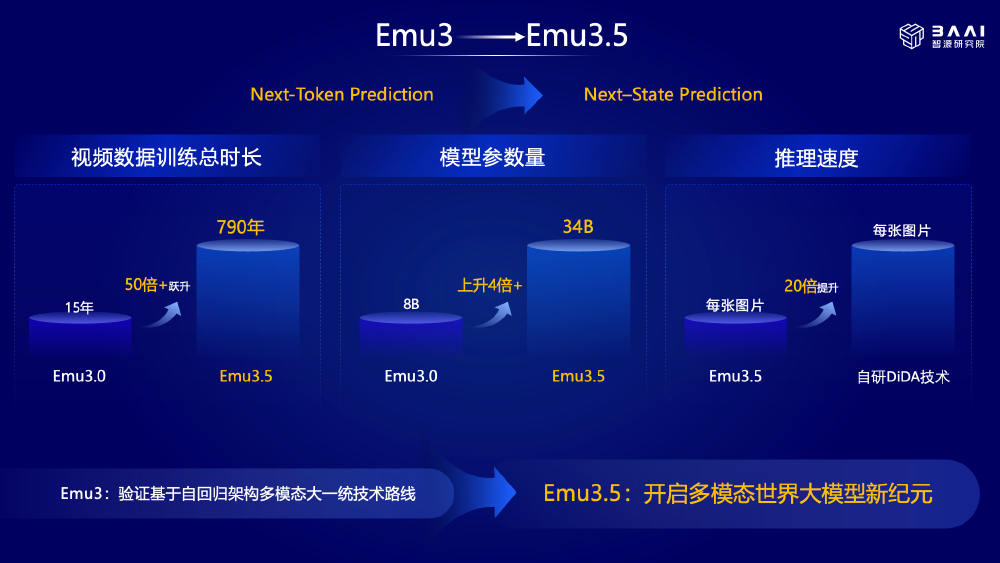
如上图所示,蓝色背景的对比图表展示Emu3到Emu3.5的关键升级,包括视频数据训练总时长(从15年增至790年,50倍+跃升)、模型参数量(从8B升至34B,4倍+)、推理速度(每张图片提升20倍,自研DiDA技术),底部文字表明Emu3.5开启多模态世界大模型新纪元。这一对比清晰展示了Emu3.5的跨越式发展。
3. 泛化交互能力:从虚拟到现实的桥梁
通过340亿参数和10万亿多模态token训练,Emu3.5展现出三类核心应用能力:
- 高精度图像编辑:支持像素级文本擦除、跨场景物体替换,保持物体光影与场景一致性
- 多模态指导生成:输入"如何做芹菜饺子",自动生成带步骤说明的图文教程
- 具身操作规划:理解"叠衣服"指令后,可拆解为机器人可执行的12步动作序列
行业影响:开源基座加速AGI探索
Emu3.5的开源发布(模型权重已在Hugging Face开放)将深刻影响三大领域:
开发者生态
提供首个支持动态物理推理的开源基座,降低机器人导航、虚拟世界构建等研究门槛。开发者可通过以下命令快速体验:
git clone https://gitcode.com/BAAI/Emu3.5
cd Emu3.5 && pip install -r requirements.txt
python inference.py --cfg configs/config.py
企业应用
零售、制造等行业可基于其开发智能客服(自动生成产品安装教程)、工业质检(动态缺陷检测)等场景化解决方案。据智源研究院测试,在交错生成任务(如图文故事创作)中,Emu3.5准确率比现有开源模型高出37%;在图像编辑任务上,与Gemini 2.5 Flash的性能差距缩小至5%以内。
AGI研究
其"观察-预测-行动"闭环能力,为具身智能(Embodied AI)提供可复用的技术框架。Emu3.5能够根据指令,生成在虚拟环境中连续移动的视觉序列,并保持场景的几何、语义和外观一致性。

如上图所示,图片展示了智源研究院(BAAI)发布的Emu3.5的标题页,明确标注其为"Native Multimodal Models are World Learners"(原生多模态模型即世界学习模型),并包含Emu3.5团队、BAAI标识及官方网址。这一标题页凸显了Emu3.5的核心理念和技术定位。
结论与前瞻
Emu3.5通过原生多模态架构和世界状态预测范式,重新定义了多模态大模型的技术边界。其核心价值不仅在于性能提升,更在于提供了从"感知"到"认知"的可扩展路径。随着开源生态的完善,我们或将看到:
- 2026年出现基于Emu3.5的消费级虚拟助手,能理解用户家庭环境并提供个性化服务
- 制造业数字孪生系统成本降低60%,实现物理世界与虚拟空间的实时双向映射
- 自动驾驶场景预测和元宇宙动态内容生成等领域实现更大突破
Emu3.5的开源策略正产生深远影响。通过Gitcode平台(https://gitcode.com/BAAI/Emu3.5),全球开发者可获取完整的模型权重与训练代码,这种开放模式已催生超过200个创新应用。未来,随着训练数据规模扩大和DiDA技术迭代,多模态世界模型有望在更多领域实现革命性突破。
如果您对Emu3.5感兴趣,请点赞收藏本文,并关注我们获取更多大模型最新资讯!
【免费下载链接】Emu3.5-Image 项目地址: https://ai.gitcode.com/BAAI/Emu3.5-Image

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)