MapReduce执行流程源码深度剖析(三)
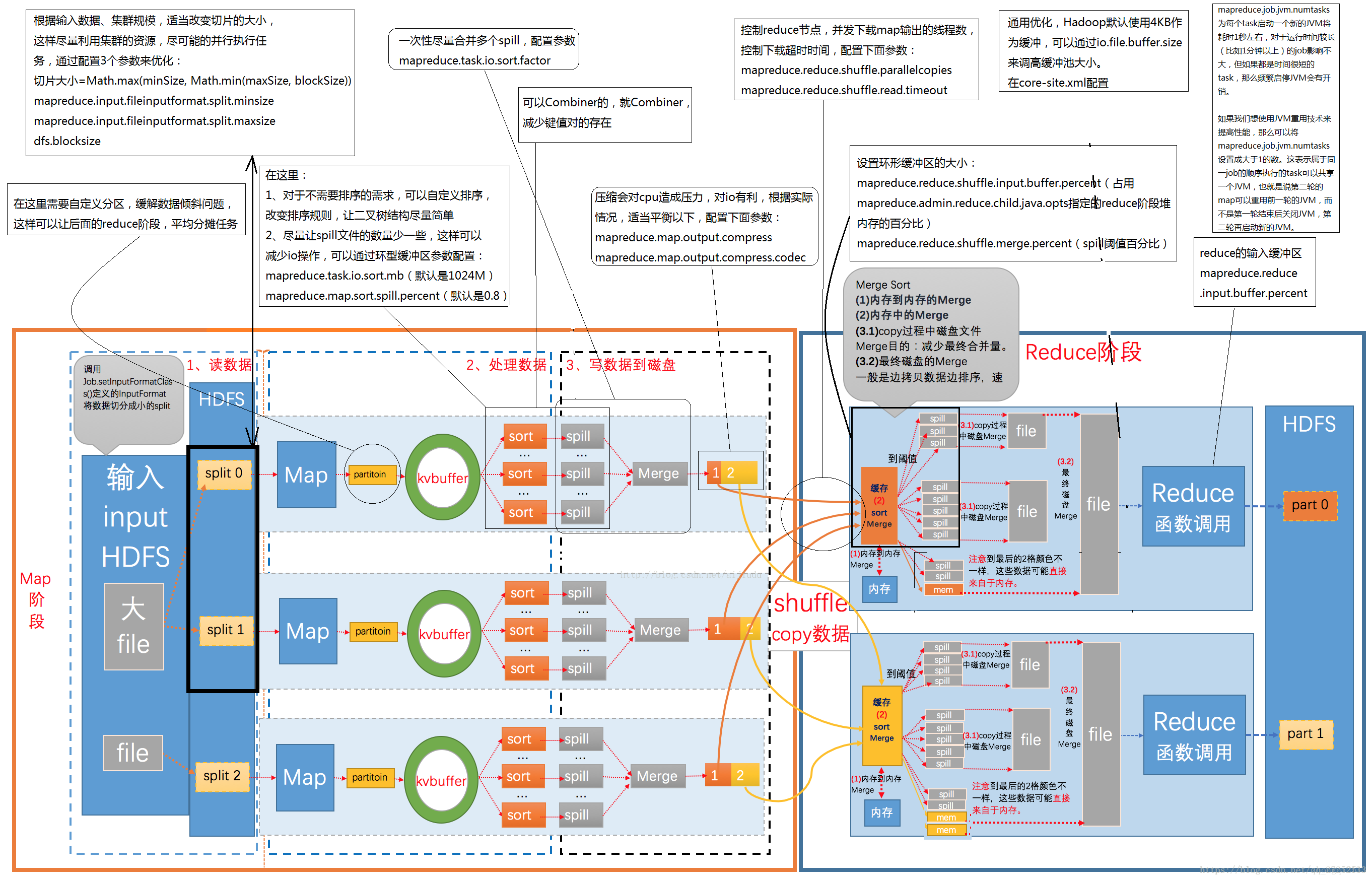
1.MapTask的工作原理1.1 runNewMapperprivate <INKEY,INVALUE,OUTKEY,OUTVALUE>void runNewMapper(final JobConf job,final TaskSplitIndex splitIndex,final TaskUmbilicalProtocol umbilical,TaskReporter
·
1. MapTask的工作原理
1.1 runNewMapper
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
/**
* TODO
* 每个MapTask都会有一个 TaskContext的上下文对象
* job.setXXX() 设置的各种组件,都放置在这个taskContext对象里面
*/
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
/**
* TODO make a maper
* 就是自己定义的mapper组件的实例对象
*/
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
//TODO 通过反射的形式来进行构建的
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
//TODO 构建一个输入组件, 默认是TextInputFormat.class
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
//TODO 先进行逻辑切片,每个逻辑切片,其实就是一个InputSplit对象
//TODO 每个 逻辑切片启动一个MapTask
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
/**
* TODO
* 正常来说,应该是由InputFormat来定义输入的格式
* 具体的输入工作由RecordReader来做, RecorReader 就是inputFormat的衍生组件 (组合设计模式)
* RecordReader 是由 InputFormat 来创建和关闭的!
*/
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input = new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
/**
* TODO RecordWriter 负责数据写出
*/
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
/**
* 如果没有 reducetask 那么就走 NewDirectOutputCollector
* 如果有 reducetask 那么就走 NewOutputCollector
*/
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
//TODO 默认走这里
// 如果没有reducer直接写出,这里准备了MapBuffer 也就是环形缓冲区
/**
* TODO
* context.write()
* output.collect()
*/
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
/**
* TODO MapContext 初始化 其实就是传播了很多的信息 来进行让其他的组件也能看到
* mapper.run(context) 中context 具备四个方法,其实就是调用了mapperContext的四个方法
*/
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE> mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
//装饰者设计模式.就是 把 mapContext 包装了一下
/**
* mapper.run(context) 中context 具备四个方法,其实也就是调用了 mapperContext的四个方法
* 其实就是调用了 mapContext的四个同名方法
*/
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
/**
* TODO 访问数据源,如果是文件,提前创建好读取该文件的输入流
* TODO 构建了逐行读取器
* input = LineRecordReader
* 这里又是采用了包装,我发现 设计中 用包装比较好,
* 最重要的事情,就是根据OutputFormat创建了一个RecordReader
* real = LineRecordReader
*/
input.initialize(split, mapperContext);
//TODO map开始执行,其实就是我们自己写的程序的Mapper实例对象
mapper.run
(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
/**
* TODO 执行合并 spill的操作
*
*/
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
1.2 mapper.run(mapperContext)
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
* mapper组件中 都有用一个 context
*/
public void run(Context context) throws IOException, InterruptedException {
//一般用来做初始化,默认实现什么都没做
setup(context);
try {
/**
* TODO nextkeyvalue() 取一个keyvalue 表示当前防范能取到值吗
* mapper组件中,都有一个叫做 context的参数 这个参数拥有最重要的四个方法:
* 1.context.nextKeyValue()
* 2.context.getCurrentKey()
* 3.context.getCurrentValue()
* 4.context.write()
*
* context 对象中 包含了真正去读取数据 和输出数据的对象实例
* 这里就是典型的装饰器设计模式的体现
*/
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
// 一般用来做收尾操作
cleanup(context);
}
}
}
1.3 map
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
1.4 真正执行write的是MapTask里面的NewOutputCollector的write方法
@Override
public void write(K key, V value) throws IOException, InterruptedException {
/**
* TODO 调用分区组件,给mapTask输出的key-value打上分区标记
*
*/
int partion = partitioner.getPartition(key, value, partitions);
/**
* collector.collect 写到了 mapOutputBuffer
*/
collector.collect(key, value, partion );
}
1.5 MapOutputBuffer(环形缓冲区)的collect方法
/**
* Serialize the key, value to intermediate storage.
* When this method returns, kvindex must refer to sufficient unused
* storage to store one METADATA.
*/
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
//key.getClass 在程序运行过程中 ,获取的实际的key的类型
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
/**
* TODO 接下来的动作就是完成,把数据写入到环形缓冲区
*/
bufferRemaining -= METASIZE;
/**
* TODO 在写之前,先判断,环形缓冲区股中的kvbuffer 区域是否已经装满
* 其实也就是说 100M大小的 80% 的数据区域是否已经装满
* bufferRemaining 专门用来统计能继续写入key-value的空间还剩多大
* 这个if (bufferRemaining <= 0) 中做的事情,就是在对那80%的数据溢写到磁盘
*
*/
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
/**
* 开始溢写
*/
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
/**
* 既然满足了溢写条件,那么写数据线程,就只能继续往剩下的20)的区域中写数据
* 但是需要重新溢写
*/
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}
1.6 我们来先来讲一讲环形缓冲区是怎么工作的
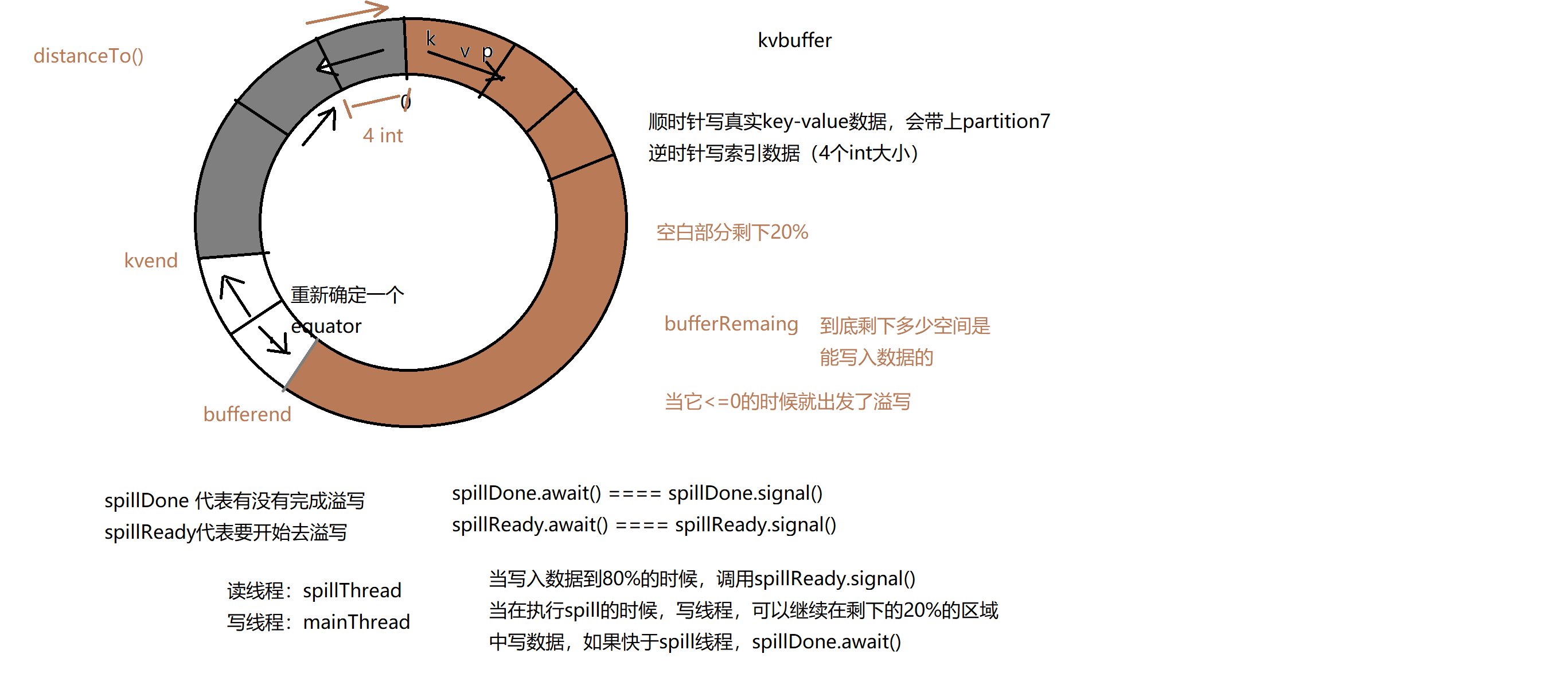
1.7 怎么溢写的
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
/**
* 开始溢写
*/
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
/**
* 既然满足了溢写条件,那么写数据线程,就只能继续往剩下的20)的区域中写数据
* 但是需要重新溢写
*/
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
1.7 startSpill
private void startSpill() {
assert !spillInProgress;
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
spillInProgress = true;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
spillReady.signal();
}
我们发现了spillReady.signal() 把溢写线程给唤醒了
1.8 SpillThread的run方法
/**
* 关于 SplillThread:
* 四个重要的组件:
* 1. SpillThread sortAndSpill() startSpill()
* 2. 可重入锁: ReentrantLock spillLock
* 3. 信号变量: Condition spillDone
* 4. 信号变量: Condition spillReady
*
* 再介绍两个重要的线程
* 1. 写数据线程
* 2. 一个spill线程
*
* 重要的工作机制
* 1. 当 kvbuffer写满百分之80的时候,应该被锁定
* 2. 写入数据线程,就应该重新确定 equ
*/
protected class SpillThread extends Thread {
@Override
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
/**
* TODO 让写入数据开始写数据
* 告诉写数据线程 spill线程 溢写完毕
*/
spillDone.signal();
/**
* TODO 一直在等待
* 刚开始 默认是 false
*/
while (!spillInProgress) {
// 只有 当 写线程的时候,spillReady.signal() 然后才会继续往下执行
spillReady.await();
}
try {
spillLock.unlock();
//TODO 现在已经卡在这里了
// 执行溢写
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
} //for结束
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
1.9 sortAndSpill
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
final int mstart = kvend / NMETA;
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
//TODO sorter = QuickSort
//TODO 对于将溢写数据,执行排序操作
/**
* 直接就在80% 的那个内存区域中,执行排序动作!
* 排序过程中,就是执行不同位置上的数据的位置交换
*
* 内存区域中的所有数据就有序了
* 1.先按照partiion 排序,相同分区的数据就在一起你了
* 2. 在每个分区中,然后按照key进行排序
*
* this: 就是数据缓冲区
*/
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
/**
* TODO 遍历每个分区,写出真实数据,同时记录索引
*/
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
/**
* TODO 这个writer就是写出流
*/
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
/**
* TODO 开始判断是否执行combiner
* combineCollector 这个
*/
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
/**
* TODO 如果没有设置 combiner 就直接输出
*/
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
/**
* TODO 执行combiner 操作
*/
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
}
}
1.10 执行合并 splill的操作
/**
* TODO 执行合并 spill的操作
*
*/
output.close(mapperContext);
1.11 close
@Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
/**
* TODO MapOutputBuffer 写出去
*/
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}
1.12 collector.flush();
public void flush() throws IOException, ClassNotFoundException,
InterruptedException {
LOG.info("Starting flush of map output");
if (kvbuffer == null) {
LOG.info("kvbuffer is null. Skipping flush.");
return;
}
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
/**
* 因为当所有的map方法执行完之后,有可能环形缓冲区汇总,还是有数据的,因为并没有触发溢写
* 这个地方执行溢写,就是为了把 缓冲区中的剩余数据写出去 都溢写出来
*/
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
assert !spillLock.isHeldByCurrentThread();
// shut down spill thread and wait for it to exit. Since the preceding
// ensures that it is finished with its work (and sortAndSpill did not
// throw), we elect to use an interrupt instead of setting a flag.
// Spilling simultaneously from this thread while the spill thread
// finishes its work might be both a useful way to extend this and also
// sufficient motivation for the latter approach.
try {
spillThread.interrupt();
spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
// release sort buffer before the merge
kvbuffer = null;
/**
* 所有的spill 文件执行合并操作
*/
mergeParts();
Path outputPath = mapOutputFile.getOutputFile();
fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen());
}
1.13 mergeParts
private void mergeParts() throws IOException, InterruptedException,
ClassNotFoundException {
// get the approximate size of the final output/index files
long finalOutFileSize = 0;
long finalIndexFileSize = 0;
//TODO numSpills 意思就是执行了多少次 溢写操作
final Path[] filename = new Path[numSpills];
final TaskAttemptID mapId = getTaskID();
for(int i = 0; i < numSpills; i++) {
filename[i] = mapOutputFile.getSpillFile(i);
finalOutFileSize += rfs.getFileStatus(filename[i]).getLen();
}
/**
* 如果你指一些了一次,那么就一个文件
*/
if (numSpills == 1) { //the spill is the final output
sameVolRename(filename[0],
mapOutputFile.getOutputFileForWriteInVolume(filename[0]));
if (indexCacheList.size() == 0) {
sameVolRename(mapOutputFile.getSpillIndexFile(0),
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]));
} else {
indexCacheList.get(0).writeToFile(
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job);
}
sortPhase.complete();
return;
}
// read in paged indices
for (int i = indexCacheList.size(); i < numSpills; ++i) {
Path indexFileName = mapOutputFile.getSpillIndexFile(i);
indexCacheList.add(new SpillRecord(indexFileName, job));
}
//make correction in the length to include the sequence file header
//lengths for each partition
finalOutFileSize += partitions * APPROX_HEADER_LENGTH;
finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH;
Path finalOutputFile =
mapOutputFile.getOutputFileForWrite(finalOutFileSize);
Path finalIndexFile =
mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize);
//The output stream for the final single output file
FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
/**
* 如果 没有溢写文件
* 之输出一个_success文件
*/
if (numSpills == 0) {
//create dummy files
IndexRecord rec = new IndexRecord();
SpillRecord sr = new SpillRecord(partitions);
try {
for (int i = 0; i < partitions; i++) {
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec, null);
writer.close();
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
sr.putIndex(rec, i);
}
sr.writeToFile(finalIndexFile, job);
} finally {
finalOut.close();
}
sortPhase.complete();
return;
}
{
sortPhase.addPhases(partitions); // Divide sort phase into sub-phases
IndexRecord rec = new IndexRecord();
final SpillRecord spillRec = new SpillRecord(partitions);
/**
* TODO 否则的话 就按照分区进行合并!
* 1. 把每个spill文件的对应问去的数据都弄过来来进行合并 (mergeSort 归并排序)
* 2. 为当前这个分区生成一条索引信息
* 3. 如果所有的分区都合并完了,所有的分区的索引,就都被管理在spillRec对象汇总
* 4. 再把这个spillRec 持久化到磁盘上
*
*/
for (int parts = 0; parts < partitions; parts++) {
//create the segments to be merged
List<Segment<K,V>> segmentList = new ArrayList<Segment<K, V>>(numSpills);
for(int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts);
//Segment 每一个溢写文件 每个文件的数据 就是一个 Segment
Segment<K,V> s = new Segment<K,V>(job, rfs, filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
if (LOG.isDebugEnabled()) {
LOG.debug("MapId=" + mapId + " Reducer=" + parts +
"Spill =" + i + "(" + indexRecord.startOffset + "," +
indexRecord.rawLength + ", " + indexRecord.partLength + ")");
}
}
int mergeFactor = job.getInt(JobContext.IO_SORT_FACTOR, 100);
// sort the segments only if there are intermediate merges
boolean sortSegments = segmentList.size() > mergeFactor;
//merge
@SuppressWarnings("unchecked")
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec,
segmentList, mergeFactor,
new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter, sortSegments,
null, spilledRecordsCounter, sortPhase.phase(),
TaskType.MAP);
//write merged output to disk
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
//close
writer.close();
sortPhase.startNextPhase();
/**
* TODO 上面所有的spill文件都已经合并成一个 数据文件了
* 同时也会给这个数据文件 生成一个索引文件
*/
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, parts);
}
/**
* 将文件写出去
*/
spillRec.writeToFile(finalIndexFile, job);
finalOut.close();
for(int i = 0; i < numSpills; i++) {
rfs.delete(filename[i],true);
}
}
}
2. ReduceTask的工作原理
2.1 ReduceTask的run方法
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
/**
* TODO copy + sort 就等于 shuffer
* 1. 先拉取数据
* 2. 然后使用归并排序的方式合并数据成一个文件
* 3. 执行reduce操作
*/
if (isMapOrReduce()) {
copyPhase = getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase = getProgress().addPhase("reduce");
}
// start thread that will handle communication with parent
TaskReporter reporter = startReporter(umbilical);
boolean useNewApi = job.getUseNewReducer();
/**
* TODO 这个地方的初始化,最重要,就是初始化了一个output
*/
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
// Initialize the codec
codec = initCodec();
RawKeyValueIterator rIter = null;
/**
* TODO reducer阶段负责拉取数据,和执行合并的事情,都是由ShuffleConsumerPlugin 这个组件来完成的
*/
ShuffleConsumerPlugin shuffleConsumerPlugin = null;
Class combinerClass = conf.getCombinerClass();
CombineOutputCollector combineCollector =
(null != combinerClass) ?
new CombineOutputCollector(reduceCombineOutputCounter, reporter, conf) : null;
Class<? extends ShuffleConsumerPlugin> clazz =
job.getClass(MRConfig.SHUFFLE_CONSUMER_PLUGIN, Shuffle.class, ShuffleConsumerPlugin.class);
shuffleConsumerPlugin = ReflectionUtils.newInstance(clazz, job);
LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin);
ShuffleConsumerPlugin.Context shuffleContext =
new ShuffleConsumerPlugin.Context(getTaskID(), job, FileSystem.getLocal(job), umbilical,
super.lDirAlloc, reporter, codec,
combinerClass, combineCollector,
spilledRecordsCounter, reduceCombineInputCounter,
shuffledMapsCounter,
reduceShuffleBytes, failedShuffleCounter,
mergedMapOutputsCounter,
taskStatus, copyPhase, sortPhase, this,
mapOutputFile, localMapFiles);
/**
* TODO 执行插件的初始化
* 创建了两个重要的对象
* 1. ShuffleSchedulerImpl
* 2. MergeManager
*/
shuffleConsumerPlugin.init(shuffleContext);
/**
* TODO 执行正儿八经的拉取数据和合并操作
*/
rIter = shuffleConsumerPlugin.run();
// free up the data structures
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
/**
* TODO 新API
*/
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
shuffleConsumerPlugin.close();
done(umbilical, reporter);
}
2.2 shuffleConsumerPlugin.init(shuffleContext);
public void init(ShuffleConsumerPlugin.Context context) {
this.context = context;
this.reduceId = context.getReduceId();
this.jobConf = context.getJobConf();
this.umbilical = context.getUmbilical();
this.reporter = context.getReporter();
this.metrics = new ShuffleClientMetrics(reduceId, jobConf);
this.copyPhase = context.getCopyPhase();
this.taskStatus = context.getStatus();
this.reduceTask = context.getReduceTask();
this.localMapFiles = context.getLocalMapFiles();
/**
* TODO ShuffleSchedulerImpl 负责拉取数据的
*/
scheduler = new ShuffleSchedulerImpl<K, V>(jobConf, taskStatus, reduceId,
this, copyPhase, context.getShuffledMapsCounter(),
context.getReduceShuffleBytes(), context.getFailedShuffleCounter());
/**
* TODO 负责执行合并的
*/
merger = createMergeManager(context);
}
2.3 shuffleConsumerPlugin.run();
/**
* TODO : EventFetcher 是一个总的管理对象!
* 会按照参数设置: 每个reduceTask会初始化5个Fetcher线程执行拉取数据操作
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public RawKeyValueIterator run() throws IOException, InterruptedException {
// Scale the maximum events we fetch per RPC call to mitigate OOM issues
// on the ApplicationMaster when a thundering herd of reducers fetch events
// TODO: This should not be necessary after HADOOP-8942
int eventsPerReducer = Math.max(MIN_EVENTS_TO_FETCH,
MAX_RPC_OUTSTANDING_EVENTS / jobConf.getNumReduceTasks());
int maxEventsToFetch = Math.min(MAX_EVENTS_TO_FETCH, eventsPerReducer);
// Start the map-completion events fetcher thread
final EventFetcher<K,V> eventFetcher =
new EventFetcher<K,V>(reduceId, umbilical, scheduler, this,
maxEventsToFetch);
eventFetcher.start();
// Start the map-output fetcher threads
boolean isLocal = localMapFiles != null;
final int numFetchers = isLocal ? 1 : jobConf.getInt(MRJobConfig.SHUFFLE_PARALLEL_COPIES, 5);
/**
* TODO 启动numFetchers的 拉取数据的线程
* 拉取所使用的的方式: HTTP协议
* 内部在工作的时候:
* 1. 每个mapTask(NodeManager) 在执行完毕的时候,就会向MRAppmatser汇报
* 执行汇报的时候:这个NodeManager 就会告诉 这个mapTask 执行完毕的结果存放在哪里,当前这个maptask执行节点的
* hostname:port
* 2. NodeManager 会向ResourceManager
* 3. MRAppMaster 启动 reduceTask 同时告诉这些reduceTask已经完成了的mapTask有哪些
* 所以这些reduceTask 就可以提前启动,然后去已经完成了的maptask节点去拉取数据,做提前合并
* 4. 每个reduceTask去mapTask拉取数据的时候,都会先扫描索引文件,确定自己的分区的数据范围
* 5. 通过HTTP的方式吧数据传输
*/
Fetcher<K,V>[] fetchers = new Fetcher[numFetchers];
if (isLocal) {
fetchers[0] = new LocalFetcher<K, V>(jobConf, reduceId, scheduler,
merger, reporter, metrics, this, reduceTask.getShuffleSecret(),
localMapFiles);
fetchers[0].start();
} else {
for (int i=0; i < numFetchers; ++i) {
/**
* TODO 启动fetcher线程
*/
fetchers[i] = new Fetcher<K,V>(jobConf, reduceId, scheduler, merger,
reporter, metrics, this,
reduceTask.getShuffleSecret());
fetchers[i].start();
}
}
// Wait for shuffle to complete successfully
/**
* 当fetcher把所有数据都取到之后,开始执行
*/
while (!scheduler.waitUntilDone(PROGRESS_FREQUENCY)) {
reporter.progress();
synchronized (this) {
if (throwable != null) {
throw new ShuffleError("error in shuffle in " + throwingThreadName,
throwable);
}
}
}
// Stop the event-fetcher thread
eventFetcher.shutDown();
// Stop the map-output fetcher threads
for (Fetcher<K,V> fetcher : fetchers) {
fetcher.shutDown();
}
// stop the scheduler
scheduler.close();
copyPhase.complete(); // copy is already complete
taskStatus.setPhase(TaskStatus.Phase.SORT);
reduceTask.statusUpdate(umbilical);
// Finish the on-going merges...
RawKeyValueIterator kvIter = null;
try {
/**
* TODO
*/
kvIter = merger.close();
} catch (Throwable e) {
throw new ShuffleError("Error while doing final merge " , e);
}
// Sanity check
synchronized (this) {
if (throwable != null) {
throw new ShuffleError("error in shuffle in " + throwingThreadName,
throwable);
}
}
return kvIter;
}
2.4 runNewReducer
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter,
RawComparator<INKEY> comparator,
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) throws IOException,InterruptedException,
ClassNotFoundException {
// wrap value iterator to report progress.
final RawKeyValueIterator rawIter = rIter;
rIter = new RawKeyValueIterator() {
public void close() throws IOException {
rawIter.close();
}
public DataInputBuffer getKey() throws IOException {
return rawIter.getKey();
}
public Progress getProgress() {
return rawIter.getProgress();
}
public DataInputBuffer getValue() throws IOException {
return rawIter.getValue();
}
public boolean next() throws IOException {
boolean ret = rawIter.next();
reporter.setProgress(rawIter.getProgress().getProgress());
return ret;
}
};
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(), reporter);
// make a reducer
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> trackedRW =
new NewTrackingRecordWriter<OUTKEY, OUTVALUE>(this, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW,
committer,
reporter, comparator, keyClass,
valueClass);
try {
/**
* TODO
* reducer 就是你在写MR程序的shihou,自己定义的Reducer 类的 一个实例对象
*/
reducer.run(reducerContext);
} finally {
trackedRW.close(reducerContext);
}
}
2.5 run
/**
* Advanced application writers can use the
* {@link #run(org.apache.hadoop.mapreduce.Reducer.Context)} method to
* control how the reduce task works.
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
/**
* TODO 三个重要的方法
* context.nextKey() : 负责帮你读取key相同的一组数据,从上一步骤拉取数据和合并成为的最终大磁盘文件汇总扫描得到的
* context.getCurrentKey(): 获取key,这个key 也会尽心个更改
* context.getValues(): 当前这个key所对应的一组value
*
*/
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
3. 总结

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)