(简)RAG-Gym:强化学习训练推理链
RAGGym框架的提出是为了优化RAG在multi-hop question answer中的表现。主要使用的方法是将查询和回答视为查询代理的过程,然后通过基于马尔科夫链的奖励机制,通过微调等方法优化这个步骤。
文章对本人目前的一些工作关系不是很大,所以笔记记得简单一点(虽然还是花了很久去读)
一、概述
RAGGym框架的提出是为了优化RAG在multi-hop question answer中的表现。主要使用的方法是将查询和回答视为查询代理的过程,然后通过基于马尔科夫链的奖励机制,通过微调等方法优化这个步骤。
二、相关知识
RAG-Gym models knowledge-intensive QA as a nested Markov Decision Process (MDP),所以需要先知道马尔科夫链的强化学习方法。
简单地说,将所有的信息、查询原文视作一张有向图。一个马尔科夫链就是对图中的Node的轨迹。这个轨迹其实上就是对于QA一类的数据集的思维链。在本模型中,这样的链条有很多,所以叫做嵌套的马尔科夫链。具体是怎么嵌套的呢?下文会提到。在这个过程中,马尔科夫链的 “无记忆性” 体现为智能体在每一步选择动作时,只依赖于当前的状态(即当前的问题和已有的搜索历史),而不考虑之前是如何到达这个状态的。这样可以简化模型的复杂度,使智能体能够专注于根据当前信息做出最优决策,以逐步找到问题的答案并获得最大奖励。
三、RAG-Gym框架
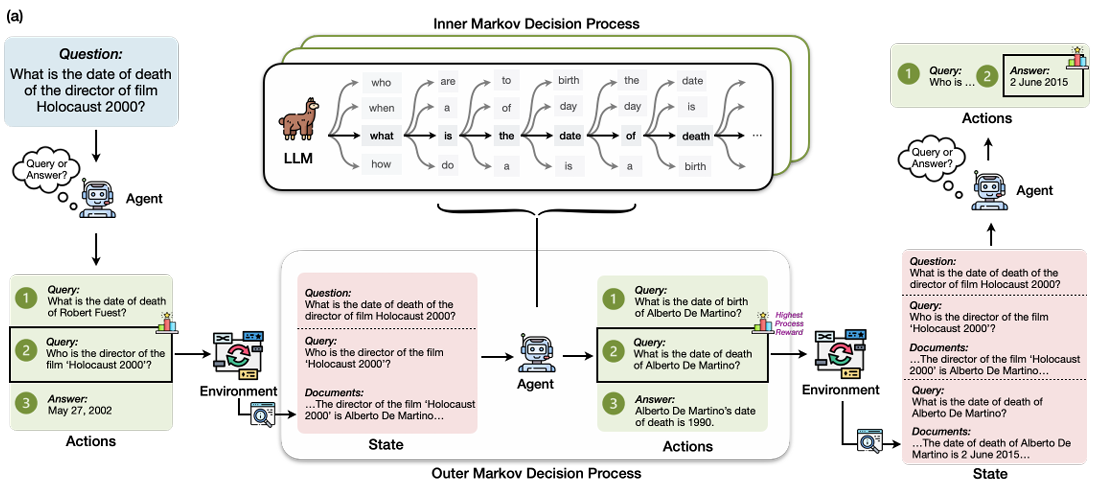
我们看上图,先说一个训练成熟的RAG-Gym模型的推理过程:
输入“三体的作者的第一任编辑是谁?”,agent根据策略、结合动作历史,会正确地选择出首个动作。动作包含生成查询、查询到结果。那么第一步的动作历史是空集,agent根据策略生成的第一个动作是:生成查询“三体的作者是谁?”。好,接下来就进入下一个action,这次我们的agent选择去环境中查询并返回答案,那么第一个周期到此结束。模型判断一下,发现这并非是正确结果。那么接下来周期继续,直到模型觉得自己产生了正确结果。
那么怎么训练出来呢?
作者采用LLM辅助的方法构建了排名的数据集。首先让模型先按照查询-返回-查询-返回---的形式进行问题的回答,然后抽样,对推理过程进行排名。这样构建的数据集来训练模型。具体步骤:
生成多路径推理轨迹
- 使用 LLM(如 GPT-4)模拟智能体的搜索 - 推理过程,对同一问题生成多条不同的 “查询 - 文档” 轨迹(例如:
- 轨迹 1:查询 “三体作者”→查询 “作者编辑”→生成答案
- 轨迹 2:直接查询 “三体作者的编辑”→生成答案
- 轨迹 3:错误轨迹,如查询无关内容)。
- 步骤 2:轨迹排名与奖励标注
- 让 LLM 对不同轨迹的 “合理性” 进行排名(例如:轨迹 1 比轨迹 2 更符合分步推理逻辑,轨迹 3 无效),或直接标注每条轨迹中每个状态 - 动作对的奖励分数(如:合理查询 + 0.5,无关查询 - 0.3)。
后续介绍了训练方法,以及示例,我这里省略掉了。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)