下一代“认知”移动机器人MxM(多世界x多层次)世界模型的架构原理
摘要: "多世界×多层次"世界模型是一种用于认知移动机器人的新型建模方法。"多世界"指从几何、对象、语义、规则、意图、反事实等不同视角同时建模环境,每个世界解决特定问题;"多层次"指在不同时间尺度(毫秒级安全控制到小时级学习)分层决策。该模型强调工程实现性:各模块需明确输入/输出、可单独测试、通过接口协作。构建步骤包括定义各世界最小输出、
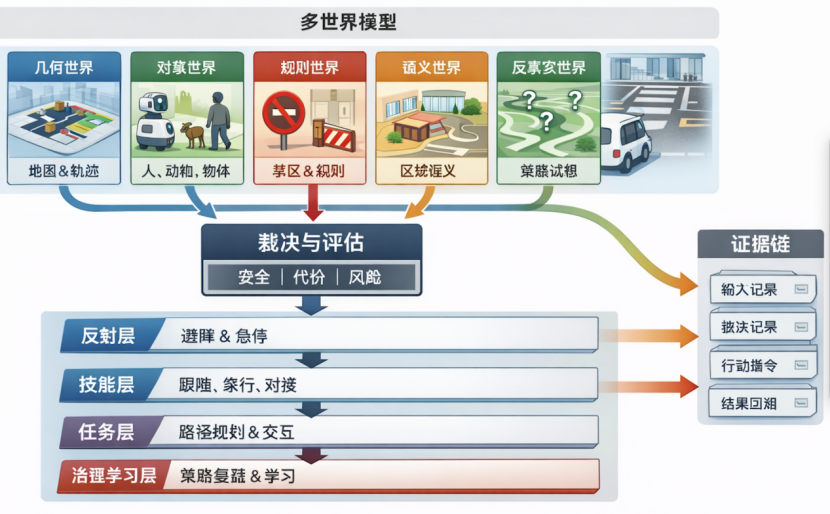
1. “多世界 × 多层次”世界模型到底指什么
多世界(Multi-World)
同一个环境,用多种可计算的视角同时建模。它们各自解决不同问题,输出不同类型的结论。
常见几类“世界”:
1. 几何世界
地图、占据栅格、点云、可通行区域、动态障碍轨迹。
2. 对象世界
把环境分成“可交互对象”:人、宠物、自行车、门、电梯、桌椅、台阶、充电桩等。每个对象有状态(开/关、移动/静止、可用/不可用)。
3. 语义世界
区域与场景含义:人行道/马路、候车区、办公区、厨房、安静区、危险边缘等。语义不直接等于几何边界,但会影响策略。
4. 规则/约束世界
“允许/禁止/必须”类约束:速度上限、礼让规则、隐私限制、不可进入区域、任务流程约束等。
5. 意图/社会世界
对他人意图的估计:对向行人要通过还是停下、对方是否注意到机器人、是否要让路、是否在和机器人互动。
6. 反事实/预测世界
“如果我走左边/右边/停一下/请求协助,会发生什么”。用于选择策略。
关键点:多世界不是为了“更复杂”,而是为了把不同性质的问题分开建模、分别验证。
多层次(Multi-Layer)
同一个机器人在不同时间尺度做决策:
• 毫秒级:安全与稳定(急停、制动、避碰)
• 秒级:局部动作(绕行、跟随、会车、通过门口)
• 分钟级:任务步骤(去某处、取放、交接、充电)
• 小时/天级:学习与治理(规则更新、性能评估、复盘)
关键点:层次不是“分层软件架构”那么简单,而是“不同时间尺度的机制”。
2. 机器人落地要求:世界模型必须“可运行、可验证、可替换”
在工程实践中,你不是去追求一个“统一的大模型解释一切”,而是构造一组机制模块:
• 每个模块都有明确输入/输出
• 每个模块能被单独测试(仿真/回放/单元测试)
• 模块间通过清晰接口协作
• 关键决策能给出“依据”(证据)
所以,M×M世界模型不是一张概念图,而是一个可工程实现的机制集合。
3. 怎么构建:先把“世界”做对,再把“层”做稳,最后解决冲突
第一步:定义每个世界的最小可用输出(MVP)
不要一上来追求大而全。每个世界先做到“能产出稳定信号”。
• 几何世界:
• 输出:可通行代价地图 + 动态障碍轨迹 + 不确定度
• 对象世界:
• 输出:对象列表(类别/位置/速度/尺寸/状态)+ 跟踪ID
• 语义世界:
• 输出:区域标签 + 语义代价(例如“尽量绕开人群密集区”)
• 规则世界:
• 输出:约束集合(速度上限、禁入区、交互规则)+ 优先级
• 意图世界:
• 输出:对关键对象的意图分布(通过/停留/转向)+ 置信度
• 反事实世界:
• 输出:候选策略集 + 每个策略的风险/代价/成功概率
注意:这些输出都要带上最基本的三件事:
时间戳、来源、置信度(或不确定度)。
第二步:用“层间契约”组织多层次
多层次最常见的问题是:上层计划不可行,下层只会报错或硬扛。
建议用契约化接口:
• 上层给下层:
• 目标(去哪)
• 约束(不能做什么)
• 预算(最大风险/最大时间/最大能耗)
• 下层给上层:
• 可行性(可/不可/不确定)
• 失败原因(被规则限制/感知不确定/几何不可通行)
• 建议(换路线/等待/请求协助)
这样做的好处:每一层可以独立优化,也能明确责任边界。
第三步:解决多世界冲突,靠“裁决机制”,不是靠平均融合
多世界输出经常冲突,例如:
• 几何世界说能走,但规则世界说这里禁止进入
• 对象世界识别为“可移动物体”,语义世界却认为这里是“危险边缘”
• 意图世界认为对方会停下,但几何世界发现对方速度很快且不稳定
解决方法是建立一个裁决器(Arbiter):
• 输入:各世界输出 + 置信度 + 优先级
• 输出:统一的“可行动集合”与“代价/风险评估”
• 原则:
1. 安全约束优先于效率
2. 确定性约束优先于不确定预测
3. 不确定度高时选择可回退策略(慢走/停下/拉开距离)
这一步是“认知机器人”能可靠运行的关键。
4. 反事实层:让机器人具备“先评估再行动”的基本能力
反事实世界不要求很复杂,但要实用:
• 生成少量候选(例如 3–7 个):绕左、绕右、等待、后退、请求协助、换目标点……
• 为每个候选计算三类指标:
• 风险(碰撞概率、规则违背概率)
• 代价(时间、能耗、路径长度)
• 可解释理由(触发了哪些规则/证据)
你会发现:只要反事实评估是“可回放”的,系统可调试性会明显提高。
5. “具身”的落点:世界模型必须和动作空间绑定
世界模型不是为了好看,是为了驱动动作。每个世界都要能回答:
• 我现在能做哪些动作?(动作集合)
• 每个动作的结果大概是什么?(短期预测)
• 哪些动作违反约束?(可行性过滤)
• 需要什么证据才允许动作?(证据门槛)
工程上可以把动作分成两层:
• 原子动作:转向、减速、停止、跟随、进门、按电梯按钮等
• 复合技能:穿越拥挤区域、会车礼让、靠站对接、跟随某人到指定地点等
对象世界和规则世界对“动作可行性”的贡献非常大,这就是“具身机械主义”的现实含义:模型必须对行动负责。
6. 最后一步:把“证据链”做成系统的一等公民
要让系统可治理、可复盘,需要把每次决策的依据记录下来。最少记录:
• 当时各世界给了什么输出(或其摘要/哈希引用)
• 裁决器如何选择(规则触发、阈值、优先级)
• 最终动作与控制命令
• 结果与偏差(是否达到预期、是否触发安全事件)
这不是“日志多写点”,而是把系统做成可审计的机制。你会在调参、排错、迭代时极度受益。
7. 一个入门级的构建顺序
1. 几何世界 + 反射层:先保证不会撞
2. 规则世界加入:保证不会违规(速度/禁入/隐私等)
3. 对象世界加入:开始“可交互”,不只是避障
4. 语义世界加入:策略更稳健(不同区域不同偏好)
5. 反事实世界加入:关键节点做策略评估与解释
6. 意图世界加入:在人群环境下更自然
7. 证据链 + 复盘工具完善:进入可治理迭代
8. 总结成一句话
构建下一代认知移动机器人的“多世界×多层次”世界模型,本质是:
用多个可验证的世界视角分别建模,用层间契约组织不同时间尺度的决策,用裁决器处理冲突,用反事实评估做策略选择,并用证据链保证可复盘与可治理。
如果你希望我再“落一层”,我可以直接给一份工程模板:
• 每个世界的输入/输出数据结构(字段级)
• 裁决器的优先级与阈值框架
• 层间契约接口定义(类似 API 规范)
• 证据链事件格式(用于回放与评估)

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)