统一的视觉-语言-动作模型
摘要: 本文提出UniVLA,一种统一的自回归模型,将视觉、语言和动作表示为离散标记进行联合建模,支持多模态任务学习。不同于传统视觉-语言-动作(VLA)模型依赖独立编码器,UniVLA通过统一框架实现跨模态深度集成,并利用视频数据捕捉时间动态。实验表明,该模型在CALVIN、LIBERO等基准上达到最先进性能,且通过世界建模增强长期任务表现。UniVLA还展示了在自动驾驶等领域的扩展潜力,为通用
Yuqi Wang 1∗{ }^{1 *}1∗ Xinghang Li2\mathbf{L i}^{2}Li2 Wenxuan Wang 1,2{ }^{1,2}1,2 Junbo Zhang 3{ }^{3}3 Yingyan Li1\mathbf{L i}^{1}Li1
Yuntao Chen 4{ }^{4}4 Xinlong Wang 2⊠{ }^{2 \boxtimes}2⊠ Zhaoxiang Zhang 1⊠{ }^{1 \boxtimes}1⊠
1{ }^{1}1 CASIA 2{ }^{2}2 BAAI 3{ }^{3}3 THU 4{ }^{4}4 HKISI
项目页面: https://robertwyq.github.io/univla.github.io
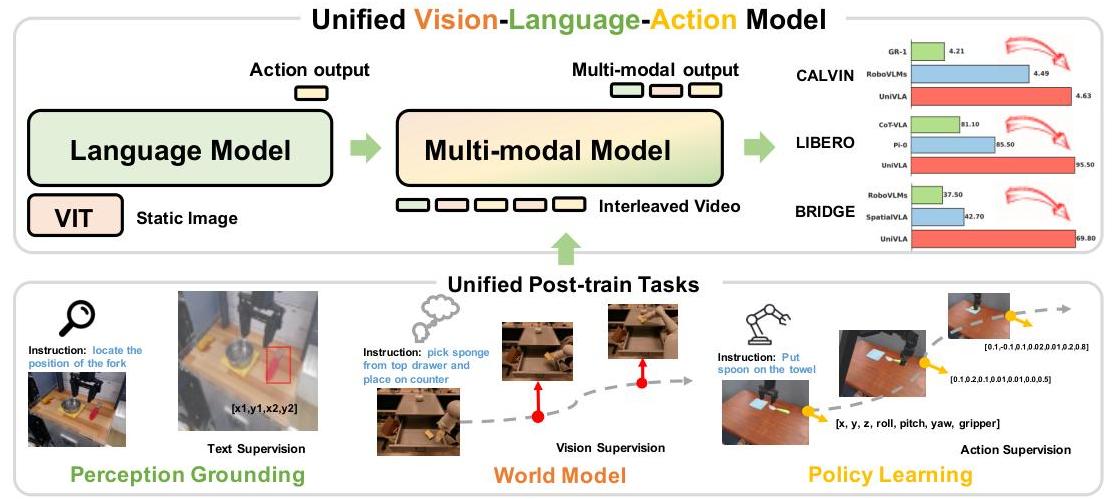
图 1:我们提出了 UniVLA,一个统一的视觉-语言-动作模型。与以往通常依赖额外视觉编码器来提取图像特征并仅生成动作输出的 VLA 方法不同,UniVLA 在统一的自回归框架中将视觉、语言和动作表示为离散标记。这种统一建模范式支持多模态输出,并能支持广泛的任务——例如文本监督的感知基础、视觉监督的世界建模以及动作监督的策略学习——在单一架构内实现。基于统一标记的设计进一步使 UniVLA 能够有效利用大规模多模态数据(尤其是视频),实现可扩展且通用的学习。UniVLA 在 CALVIN、LIBERO 和 SimplerEnv-Bridge 上取得了新的最先进成果,显著超越了现有方法。
摘要
视觉-语言-动作模型(VLAs)因其在推动机器人操作方面的潜力而受到广泛关注。然而,以前的方法主要依赖于视觉-语言模型(VLMs)的一般理解能力来生成动作信号,常常忽略了视觉观察中嵌入的丰富时间结构和因果关系。在本文中,我们提出了 UniVLA,一种统一且原生的多模态 VLA 模型,该模型以离散标记序列的形式自回归地建模视觉、语言和动作信号。这一形式使得灵活的多模态任务学习成为可能,特别是从大规模视频数据中进行学习。通过在后期训练中结合世界建模,UniVLA 能够从视频中捕捉因果动态,从而促进有效的下游策略学习——尤其是在长期任务上。我们的方法在多个广泛使用的模拟基准测试中设立了新的最先进结果,包括 CALVIN、LIBERO 和 Simplenv-Bridge,显著超越了先前方法。
*在北京人工智能研究院实习期间完成的工作。${ }^{\boxtimes}$ 通讯作者
例如,UniVLA 在 LIBERO 基准测试中实现了 95.5% 的平均成功率,超过了 $\pi_{0}$-FAST 的 85.5%。我们进一步展示了其在真实世界 ALOHA 操作和自动驾驶中的广泛应用。
1 引言
开发能够在物理世界中感知、推理和行动的智能体长期以来一直是人工智能的核心目标。最近的视觉-语言-动作(VLA)模型 [8, 56, 42, 6],基于强大的视觉-语言模型(VLMs)[57, 38, 3, 66, 30] 的泛化能力,在广泛的机器人操作任务中表现出色,并且越来越多地被应用于需要更广泛具身智能的通用人形机器人 [5, 20]。然而,大多数现有的 VLA 方法 [42, 6] 遵循以语言为中心的范式:首先将视觉观察投影到语义空间,然后根据这些表示推导出动作策略。这种晚期融合策略虽然有助于语义理解和泛化,但限制了深度耦合的跨模态表示的形成,并阻碍了感知-动作循环中时间结构和因果依赖性的学习。这引出了一个核心问题:能否在一个统一的表示空间中联合建模视觉、语言和动作,以促进更紧密的跨模态集成和更有效的策略学习?
尽管理论上很吸引人,统一建模面临着两个关键挑战。首先,视觉、语言和动作本质上是异构模态:视觉由高维、连续的空间信号组成;语言传达抽象、离散的语义;而动作涉及具有因果依赖性的时间有序序列。其次,感知到动作的管道本质上是动态和因果的,然而现有的 VLA 模型 [8, 42, 6] 通常采用静态、以语言为中心的范式,仅仅学习从静态图像到动作的映射。这些模型未能捕捉现实世界交互的动态特性,从而限制了它们利用视频中的丰富时间信息进行训练的能力。
为了解决上述挑战,我们引入了 UniVLA,这是一种用于统一视觉-语言-动作学习的新框架。如图 1 所示,我们提出了一种支持多模态和多任务学习的统一框架。在模态层面,视觉、语言和动作信号都被转换为离散标记,并使用共享词汇表进行建模。这种统一的标记表示允许跨模态的联合学习,促进更深层次的跨模态理解和集成。在统一框架的基础上,我们采用了一种基于自回归马尔可夫链的序列建模方法,其中观察和动作是交错的。这种结构自然地融入了因果依赖性,使模型能够对时间动态进行推理,而不是将感知和动作视为孤立的任务。通过在训练过程中整合世界模型范式,我们利用大规模机器人视频进行自我监督学习,使模型能够以时间一致且因果基础的方式捕捉环境动态。值得注意的是,我们发现带有世界模型的后期训练显著增强了策略学习,特别是在长期任务和分布外任务上。
在包括 CALVIN [54]、LIBERO [49] 和 SimplerEnv [48] 在内的多个模拟基准上的实验表明,我们的模型在性能上有明显提升。我们的模型在后期训练中结合了世界模型学习,使其能够有效地从大规模视频中捕捉视觉动态。这一策略显著提高了下游策略学习的数据效率和训练效率,并允许快速适应新的机器人任务。除了策略学习,我们还展示了模型的多模态输出能力,包括空间推理和视觉预测,突显了其多功能性。此外,我们将我们的方法扩展到自动驾驶场景,以展示其更广泛的应用性。这些结果强调了我们提出的统一 VLA 模型作为通用具身智能的一种替代和有前途的方向的潜力。
我们的贡献总结如下:
- 我们提出了 UniVLA,这是第一个将视觉、语言和动作作为离散标记在共享词汇表中进行编码的统一视觉-语言-动作 (VLA) 模型,通过自回归序列学习对其进行联合建模。这种方法提供了一种新颖的架构替代方案,超越了现有的 VLA 范式,促进了更紧密的跨模态建模,并支持基于视频的大规模训练。
-
- 我们的统一序列建模框架支持广泛的多模态任务。通过研究各种后训练策略,我们证明世界模型可以从视频数据中有效学习时间动态,显著提高性能,并改善下游策略学习中的数据和训练效率——特别是在长视野和分布外场景中。
-
- 我们的模型在几个模拟基准(CALVIN、LIBERO 和 SimplerEnv-Bridge)上达到了最先进的性能,并介绍了一个支持大规模视频训练的开源 VLA 方法。我们进一步探索了它在各种模态中的能力,包括空间推理和视频预测,并展示了其向驾驶场景的有效迁移,突显了其在通用具身智能中的潜力。
2 相关工作
2.1 视觉-语言-动作模型
最近的视觉-语言-动作 (VLA) 模型在多样化的机器人和任务中表现出了强大的任务性能 [8,64,22,42,76,12,6,78,50,41,37][8,64,22,42,76,12,6,78,50,41,37][8,64,22,42,76,12,6,78,50,41,37]。这些模型利用预训练的视觉-语言模型 (VLMs) 来增强理解和泛化能力,并在大规模机器人数据集上进一步微调以实现低级控制。目前,VLA 模型可以根据其输出空间分为两种范式:纯动作预测和视觉引导的动作预测。
纯动作预测。最近的研究已经将视觉-语言模型 (VLMs) 扩展到包含动作模态,从而能够直接从视觉和语言输入生成离散动作。一个突出的例子是 RT-2[8],它通过互联网规模和机器人数据进行学习,以自回归方式生成离散动作,展示了强大的泛化能力和语义基础。在此基础上,RT-H[2] 引入了分层动作以促进任务间的数据共享。OpenVLA[42] 使用一个参数为 7B 的开源模型扩展了这一范式,该模型在跨越多样化数据集的 970k 个实际演示中进行了训练。为了增强空间推理能力,SpatialVLA[59] 将空间表示集成到动作建模过程中。除了架构扩展,新的动作建模技术也不断涌现。π0\pi_{0}π0 [6] 结合流匹配以提高动作学习效率,而 FAST [58] 则引入了一种统一的频域公式以离散化动作。
视觉引导的动作预测。这些研究利用视觉预训练的力量,通常基于策略即视频的公式,通过预测未来的视觉信号并随后将其解码为动作。SuSIE [7] 预测未来的关键帧并通过逆动力学导出动作。UniPi [24] 根据文本指令生成视频,并从帧中提取动作。GR 系列 [70, 12, 44] 利用视频预训练进行通用策略学习。PAD [31] 使用扩散模型同时学习未来图像和动作。LAPA [73] 提出使用 VQ-VAE 从无动作的互联网规模视频中学习图像间的潜在动作。Track2Act [4] 从多样化的网络视频中提取点轨迹,以指导交互计划的学习。
这两种方法各有优劣。第一种专注于动作预测,与视觉-语言模型(VLMs)集成良好,但缺乏空间理解和视觉预测能力。第二种结合视觉生成,需要分离生成模型和动作预测模型,限制了VLMs的全部潜力。我们的工作统一了这些方法,将视频生成预训练与VLMs的优势结合起来,提出了一种具有巨大未来潜力的本地多模态模型。
2.2 机器人领域的世界模型
世界模型 [32, 33, 43] 因其捕捉和推理物理世界动态的能力而广受关注。它们已成为一系列领域的重要支柱,包括交互式视频生成 [10, 11]、自动驾驶 [35, 69, 67, 26] 和机器人学 [24, 71, 72]。机器人学的最新进展越来越关注通用可控视频生成,以模拟真实且多样的机器人-环境互动。Visual Foresight [25] 利用带有模型预测控制的动作条件视频预测,使机器人能够通过预测未来的视觉观察来规划操作任务。UniSim [72] 构建了一个“通用模拟器”,在多样化的视觉数据集上进行训练,能够可视化高层次指令(例如,“打开抽屉”)和新场景中低层次控制的效果。RoboDreamer [80] 通过分解视频生成来学习一个组合式世界模型,促进新型动作序列的合成。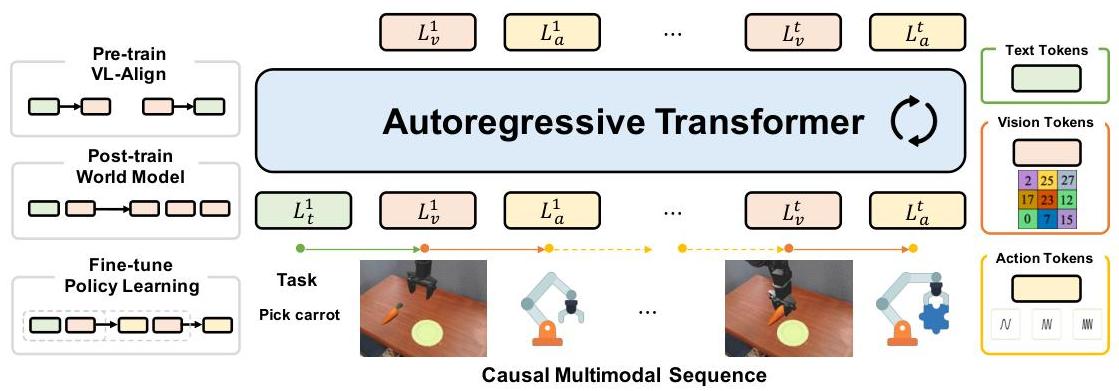
图 2:UniVLA 框架概览。我们的模型将来自不同模态的信息统一成一个离散交错序列,并使用自回归 Transformer 进行建模。为了实现统一建模,图像使用矢量量化(VQ)编码器进行离散化,而动作则通过离散余弦变换(DCT)编码转换到频域并离散化。这种因果多模态序列自然保留了现实任务所需的时间动态和因果关系。该模型建立在预训练的视觉-语言模型之上,并遵循两阶段训练策略:(1) 一个后期训练阶段,在无需动作的大规模数据集上采用世界模型训练;(2) 一个微调阶段,将动作交错进序列,实现下游任务的策略学习。
新型动作序列。DREMA [1] 通过将高斯点绘与物理模拟相结合来复制场景动态和结构。VLP [23] 通过结合文本到视频生成与视觉-语言模型作为启发式评估器,实现长视野视觉规划。DayDreamer [71] 将 Dreamer [34] 扩展到真实世界的机器人平台,而 UVA [45] 提出一个联合视频-动作潜空间以分离视频和动作生成,在策略推理中实现高精度和高效。AdaWorld [27] 以自监督的方式从视频中提取潜动作,并构建一个基于这些潜动作的自回归世界模型。
3 统一的视觉-语言-动作模型
在本节中,我们介绍了 UniVLA 的设计,如图 2 所示。不同于之前依赖 ViT [21] 进行图像编码的 VLA 模型 [42, 6],我们的方法采用了一种无编码器架构,将所有模态转换为离散标记并通过自回归方式进行学习。整体设计简单却有效,展现出强大的可扩展性。
我们的 统一范式 有两个关键方面:首先,它 统一了多种模态的学习,将各种模态标记整合到一个共享的表示空间中,并使用 transformer 进行自回归学习;其次,它 统一了跨任务的序列建模,通过模态的自然交错,促进诸如视频生成、视觉基础和动作学习等任务的无缝结合。在接下来的部分中,我们将从 统一多模态模型 和 统一多模态序列建模 两个角度介绍该方法。
3.1 统一多模态模型
如图 2 所示,我们的方法通过将每种模态转换为离散标记并将它们连接成单个多模态序列 L 来统一语言、视觉和动作模态。具体来说,Lt, Lv 和 La 分别表示语言、视觉和动作的离散标记序列,都来自共享的词汇表。上标表示时间步,标记在模态之间交错排列以保持时间对齐。
例如,在机器人操作任务中,文本指令仅在开始时提供,随后是一系列自然交错的视觉观察和动作。语言和视觉标记器采用与 Emu3 [68] 相同的设计;视觉观察使用 VQ 标记器 [77] 进行离散化,而动作则使用 FAST [58] 编码。为了清晰划分模态边界,我们使用特殊标记—boi(图像开始)、eoi(图像结束)、boa(动作开始)和 eoa(动作结束)—分别封装图像和动作标记。
动作建模 我们遵循 FAST [58] 并应用离散余弦变换 (DCT) 将连续动作序列转换为离散动作标记。具体而言,给定一个时间窗口内的动作序列,我们在特定时间步定义 LaL_{a}La 为动作标记序列 [T1,…,Tn]\left[T_{1}, \ldots, T_{n}\right][T1,…,Tn]。原始动作序列 A1:H={a1,a2,…,aH}A_{1: H}=\left\{a_{1}, a_{2}, \ldots, a_{H}\right\}A1:H={a1,a2,…,aH} 跨越大小为 HHH 的窗口,其中每个动作 ata_{t}at 是一个 ddd-维向量。FAST 动作标记器将 A1:HA_{1: H}A1:H 编码为离散标记序列 [T1,…,Tn]\left[T_{1}, \ldots, T_{n}\right][T1,…,Tn],其中 nnn 个标记取自大小为 ∣V∣|V|∣V∣ 的词汇表。类似于自然语言处理,动作序列的标记长度可以变化,导致变长 (nnn) 的离散表示。
训练目标 由于所有模态信号都被转换为离散标记,训练目标简化为标准的下一个标记预测任务,使用交叉熵损失。为了适应不同的任务格式,我们在损失计算中选择性地包含特定标记,确保在各种任务中的兼容性和灵活性。
3.2 统一多模态序列建模
如图 2 所示,我们的多模态序列表示自然地捕捉到了任务执行中固有的时间动态和因果结构。具身规划问题可以表述为马尔可夫决策过程 (MDP),这是一个部分随机环境中决策的通用数学框架。例如,在拾取胡萝卜的任务中,指令和当前观察决定了动作;这个动作改变了环境,导致新的观察进而指导下一步动作。基于这种交错的马尔可夫公式,我们在共享的序列建模框架中统一了各种任务,并在下面呈现任务特定的建模策略。
世界模型 (后训练) 在 MDP 框架中,世界模型旨在通过建模转移函数 P(st+1∣st,at)P\left(\mathbf{s}_{t+1} \mid \mathbf{s}_{t}, \mathbf{a}_{t}\right)P(st+1∣st,at) 来学习环境动态。所学到的世界模型使代理能够在不直接与环境互动的情况下模拟未来轨迹、规划行动并推理后果。具体来说,在机器人任务背景下,我们将语言指令视为一种普遍形式的动作。给定当前观察 Lv1L_{v}^{1}Lv1 和指令 Lt1L_{t}^{1}Lt1,世界模型需要预测未来的视觉内容。在这种设置下,我们仅使用视觉标记的损失作为监督信号,使模型能够根据给定的指令和观察状态生成视觉预测。序列 SvS_{v}Sv 的公式如下:
Sv={Lt1,Lv1,Lv2,…,Lvt} S_{v}=\left\{L_{t}^{1}, L_{v}^{1}, L_{v}^{2}, \ldots, L_{v}^{t}\right\} Sv={Lt1,Lv1,Lv2,…,Lvt}
策略学习 (微调) 策略学习使代理能够根据当前观察和先前状态确定最佳动作,从而有效指导任务执行。在此设置中,我们使用仅从动作标记计算的损失函数。表示随时间互动的序列 SaS_{a}Sa 公式如下:
Sa={Lt1,Lv1,La1,Lv2,La2,…,Lvt,Lat} S_{a}=\left\{L_{t}^{1}, L_{v}^{1}, L_{a}^{1}, L_{v}^{2}, L_{a}^{2}, \ldots, L_{v}^{t}, L_{a}^{t}\right\} Sa={Lt1,Lv1,La1,Lv2,La2,…,Lvt,Lat}
如图 2 所示,在这种交错格式中,我们为机器人任务采用了两阶段训练范式。模型初始化为一个视觉-语言 (VL) 对齐的检查点,赋予其基本的视觉-语言能力。后训练阶段利用世界模型目标捕捉视频动态,将世界建模视为一个通用的视觉学习任务。在学习到的世界模型基础上,微调阶段专注于动作学习以优化特定任务的行为。我们观察到,加入世界模型显著提高了策略学习的效率和效果。
4 实验
4.1 数据集
CALVIN. CALVIN [54] 是一个专门设计用于评估长视野、语言条件下的机器人操作的模拟基准。它包括四个模拟环境(A、B、C 和 D),每个环境都包含通过人类远程操作收集的演示轨迹。该基准包含 34 个不同的操作任务,共有 1,000 个独特的语言指令。性能衡量指标是在一个序列中成功完成的子任务的平均数量。标准评估协议包括 ABC→DA B C \rightarrow DABC→D 和 ABCD→DA B C D \rightarrow DABCD→D 设置,这些设置测试模型在未见过的环境和长视野任务组合中的泛化能力。
LIBERO. LIBERO 基准 [49] 是一个综合套件,用于终身机器人操作,包含四个任务套件,每个套件有 10 个任务和 50 个人类演示。这些套件旨在评估不同的泛化能力:LIBERO-Spatial 通过固定对象改变布局测试空间推理;LIBERO-Object 在固定场景中通过变化对象评估对象级别泛化;LIBERO-Goal 通过变化任务目标测试目标条件行为;LIBERO-Long (LIBERO-10) 包含长视野、组合任务,涉及多样对象、布局和目标,挑战时间和组合推理。
SimplerEnv. SimplerEnv [48] 是一个模拟基准,旨在评估在真实世界视频数据上训练的模型的可迁移性和泛化能力。它涵盖了 WidowX 和 Google Robot 平台上的多样化操作设置,包括光照条件、物体纹理、颜色分布和相机视角的变化。
4.2 实现细节
该模型采用完全自回归的 Transformer 架构,参数为 85 亿,与 Emu3 [68] 相同。图像使用基于 VQ 的图像编码器进行标记化,空间压缩因子为 8 。对于动作编码,我们使用相邻帧之间的相对差异。首先应用 1st 和 99th 百分位数归一化,然后使用 FAST 标记器 [58],其词汇量为 1024,并替换语言标记器最后 1024 个标记 ID。
后训练阶段。在后训练阶段,我们利用大规模的机器人中心视频数据集,研究不同后训练策略对下游策略学习的影响。模型使用 Emu3 第一阶段的预训练权重进行初始化 [68]。我们整理了总共 622 K 个视频来自现有机器人数据集(详细信息见附录),并确定世界模型是最有效的后训练方法。在训练过程中,仅在视觉标记上施加监督。模型训练了 30 K 步,批大小为 64 。
微调阶段。在微调阶段,模型使用后训练阶段的权重进行初始化,并使用双帧交错的视觉-动作序列进行训练,动作块大小为 10。应用余弦退火学习率调度,起始值为 8×10−58 \times 10^{-5}8×10−5,损失仅在动作标记上计算。对于 CALVIN 基准测试,使用第三人称 (200×200)(200 \times 200)(200×200) 和手腕视角 (80×80)(80 \times 80)(80×80) 摄像机的 RGB 观察。训练在 A100 GPU 上进行,批大小为 192,共训练 8 k 步。对于 LIBERO 基准测试,使用第三人称和手腕视角的 RGB 图像(均为 200×200200 \times 200200×200)训练一个统一模型,批大小为 192,共训练 8 k 步。一个模型在四个任务套件上进行评估。对于 SimplerEnv 基准测试,使用单视图 RGB 观察,输入调整为 256×256256 \times 256256×256。训练在 Bridge-WidowX 设置上进行,批大小为 128,共训练 20k 步,动作块大小为 5。
关于后训练策略、真实机器人微调程序和自动驾驶实验的更多实现细节见附录。
4.3 主要结果
在本节中,我们在三个模拟基准上评估我们的方法:CALVIN(长视野任务)、LIBERO(多样泛化)和 SimplerEnv(真实到模拟操作)。我们的方法在所有设置上均达到最先进的性能。
CALVIN 模拟评估。表 1 展示了 CALVIN 基准的实验结果。我们的方法在 ABC→D\mathrm{ABC} \rightarrow \mathrm{D}ABC→D 和 ABCD→D\mathrm{ABCD} \rightarrow \mathrm{D}ABCD→D 任务上均取得最高性能,显著优于先前方法,展示了其在多任务学习和长视野规划方面的强大能力。
LIBERO 模拟评估。按照 [75] 的做法,我们报告了每个任务套件(空间、对象、目标、长视野)在 500 次试验中的平均成功率。如表 2 所示,UniVLA 在所有 LIBERO 基准套件中表现最佳,尤其在长视野任务上取得了显著提升——将之前的最先进水平从 69.0%69.0 \%69.0% 提升至 94.0%94.0 \%94.0%。与 π0\pi_{0}π0 [58] 相比,我们的方法在长视野任务上表现更优。
表 1:在 CALVIN 基准上进行的长视野机器人操作评估。
| 方法 | 任务 | 连续完成的任务数 | 平均长度 ↑\uparrow↑ | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| MCIL [52] | ABCD →\rightarrow→ D | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| RT-1 [9] | ABCD →\rightarrow→ D | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| Robo-Flamingo [47] | ABCD →\rightarrow→ D | 0.964 | 0.896 | 0.824 | 0.740 | 0.660 | 4.09 |
| GR-1 [70] | ABCD →\rightarrow→ D | 0.949 | 0.896 | 0.844 | 0.789 | 0.731 | 4.21 |
| UP-VLA [74] | ABCD →\rightarrow→ D | 0.962 | 0.921 | 0.879 | 0.842 | 0.812 | 4.42 |
| RoboVLMs [46] | ABCD →\rightarrow→ D | 0.967 | 0.930 | 0.899 | 0.865 | 0.826 | 4.49 |
| UniVLA | ABCD →\rightarrow→ D | 0.985 | 0.961 | 0.931 | 0.899 | 0.851 | 4.63 |
| MCIL [52] | ABC →\rightarrow→ D | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| Robo-Flamingo [47] | ABC →\rightarrow→ D | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.47 |
| SuSIE [7] | ABC →\rightarrow→ D | 0.870 | 0.690 | 0.490 | 0.380 | 0.260 | 2.69 |
| GR-1 [70] | ABC →\rightarrow→ D | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 |
| UP-VLA [74] | ABC →\rightarrow→ D | 0.928 | 0.865 | 0.815 | 0.769 | 0.699 | 4.08 |
| RoboVLMs [46] | ABC →\rightarrow→ D | 0.980 | 0.936 | 0.854 | 0.778 | 0.704 | 4.25 |
| Seer-Large [63] | ABC →\rightarrow→ D | 0.963 | 0.916 | 0.861 | 0.803 | 0.740 | 4.28 |
| UniVLA | ABC →\rightarrow→ D | 0.989 | 0.948 | 0.890 | 0.828 | 0.751 | 4.41 |
表 2:不同方法在 LIBERO 基准上的比较。
| 方法 | SPATIAL | OBJECT | GOAL | LONG | 平均 |
|---|---|---|---|---|---|
| DP* [17] | 78.3%78.3 \%78.3% | 92.5%92.5 \%92.5% | 68.3%68.3 \%68.3% | 50.5%50.5 \%50.5% | 72.4%72.4 \%72.4% |
| Octo [62] | 78.9%78.9 \%78.9% | 85.7%85.7 \%85.7% | 84.6%84.6 \%84.6% | 51.1%51.1 \%51.1% | 75.1%75.1 \%75.1% |
| OpenVLA [42] | 84.9%84.9 \%84.9% | 88.4%88.4 \%88.4% | 79.2%79.2 \%79.2% | 53.7%53.7 \%53.7% | 76.5%76.5 \%76.5% |
| SpatialVLA [59] | 88.2%88.2 \%88.2% | 89.9%89.9 \%89.9% | 78.6%78.6 \%78.6% | 55.5%55.5 \%55.5% | 78.1%78.1 \%78.1% |
| CoT-VLA [75] | 87.5%87.5 \%87.5% | 91.6%91.6 \%91.6% | 87.6%87.6 \%87.6% | 69.0%69.0 \%69.0% | 81.1%81.1 \%81.1% |
| π0\pi_{0}π0-FAST [58] | 96.4%\mathbf{9 6 . 4 \%}96.4% | 96.8%96.8 \%96.8% | 88.6%88.6 \%88.6% | 60.2%60.2 \%60.2% | 85.5%85.5 \%85.5% |
| UniVLA | 95.4%95.4 \%95.4% | 98.8%\mathbf{9 8 . 8 \%}98.8% | 93.6%\mathbf{9 3 . 6 \%}93.6% | 94.0%\mathbf{9 4 . 0 \%}94.0% | 95.5%\mathbf{9 5 . 5 \%}95.5% |
SimplerEnv 模拟评估。表 3 总结了 Bridge-WidowX 设置上各种操作策略的表现。我们的方法相比之前的方法有了显著改进,将平均成功率从 42.7%42.7 \%42.7% 提高到 69.8%69.8 \%69.8%。特别是在之前困难的任务上,如堆叠积木、放置胡萝卜和放置勺子,表现有显著提升。
表 3:在 SimplerEnv-WidowX 上的各种操作任务评估。
| 模型 | 放置勺子在毛巾上 | 放置胡萝卜在盘子上 | 堆叠绿色积木在黄色积木上 | 放置茄子在黄色篮子里 | 总体 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 抓取 | 成功 | 抓取 | 成功 | 抓取 | 成功 | 抓取 | 成功 | 成功 | |
| RT-1-X [5] | 16.7%16.7 \%16.7% | 0.0%0.0 \%0.0% | 20.8%20.8 \%20.8% | 4.2%4.2 \%4.2% | 8.3%8.3 \%8.3% | 0.0%0.0 \%0.0% | 0.0%0.0 \%0.0% | 0.0%0.0 \%0.0% | 1.1%1.1 \%1.1% |
| Octo-Base [56] | 34.7%34.7 \%34.7% | 12.5%12.5 \%12.5% | 52.8%52.8 \%52.8% | 8.3%8.3 \%8.3% | 31.9%31.9 \%31.9% | 0.0%0.0 \%0.0% | 66.7%66.7 \%66.7% | 43.1%43.1 \%43.1% | 16.0%16.0 \%16.0% |
| Octo-Small [56] | 77.8%77.8 \%77.8% | 47.2%47.2 \%47.2% | 27.8%27.8 \%27.8% | 9.7%9.7 \%9.7% | 40.3%40.3 \%40.3% | 4.2%4.2 \%4.2% | 87.5%87.5 \%87.5% | 56.9%56.9 \%56.9% | 29.5%29.5 \%29.5% |
| OpenVLA [42] | 4.1%4.1 \%4.1% | 0.0%0.0 \%0.0% | 33.3%33.3 \%33.3% | 0.0%0.0 \%0.0% | 12.5%12.5 \%12.5% | 0.0%0.0 \%0.0% | 8.3%8.3 \%8.3% | 4.1%4.1 \%4.1% | 1.0%1.0 \%1.0% |
| RoboVLMs [46] | 70.8%70.8 \%70.8% | 45.8%45.8 \%45.8% | 33.3%33.3 \%33.3% | 20.8%20.8 \%20.8% | 54.2%54.2 \%54.2% | 4.2%4.2 \%4.2% | 91.7%91.7 \%91.7% | 79.279.279.2 | 37.5%37.5 \%37.5% |
| SpatialVLA [59] | 20.8%20.8 \%20.8% | 16.7%16.7 \%16.7% | 29.2%29.2 \%29.2% | 25.0%25.0 \%25.0% | 62.5%62.5 \%62.5% | 29.2%29.2 \%29.2% | 100%100 \%100% | 100%\mathbf{1 0 0 \%}100% | 42.7%42.7 \%42.7% |
| UniVLA | 83.3%\mathbf{8 3 . 3 \%}83.3% | 83.3%\mathbf{8 3 . 3 \%}83.3% | 74.0%\mathbf{7 4 . 0 \%}74.0% | 66.7%\mathbf{6 6 . 7 \%}66.7% | 95.8%\mathbf{9 5 . 8 \%}95.8% | 33.3%\mathbf{3 3 . 3 \%}33.3% | 100.0%\mathbf{1 0 0 . 0 \%}100.0% | 95.8%95.8 \%95.8% | 69.8%\mathbf{6 9 . 8 \%}69.8% |
4.4 深度分析
在本节中,我们在统一框架内进行深入分析,这可能为未来 VLA 模型的设计提供关键见解。我们首先分析了后期训练如何在性能(表 4)和训练效率(表 5)方面提升下游策略学习,突出了世界模型作为机器人一般后期训练策略的潜力。然后,我们研究了即使没有后期训练阶段,纳入视觉预测损失(表 6a)和历史上下文(表 6b)仍然对策略学习有积极贡献。
世界模型后期训练的有效性。表 4 探究了不同后期训练策略对各种模拟基准下游策略学习的影响。结果显示,由于任务之间动作空间的不一致性,仅动作学习表现出较低的可迁移性,导致性能下降。相比之下,大多数后期训练方法显著提升了策略学习,突出了视觉学习在可迁移性中的关键作用。其中,世界模型后期训练方法产生了最大的收益,提升了泛化能力和长视野规划能力。与文本到图像(T2I)训练的对比强调了在视频数据中建模时间动态的重要性,而与仅视频训练的对比则突出了文本指导在状态转换中的重要作用。值得注意的是,这种世界模型训练不需要动作标注,从而能够从大规模视频数据中进行可扩展的学习,为未来的 VLA 研究提供了有希望的方向。
数据和训练效率。表 5 显示,后期训练显著提高了下游策略学习的效率。在 CALVIN 基准(表 5a)上,我们的方法仅使用 10% 的微调数据就达到了更高的成功率,超过了之前的 GR-1 [70] 和 RoboVLMs [46] 等方法。此外,表 5b 强调了训练效率的提高,因为该模型在较少的微调迭代次数下迅速收敛。Simpler-Env 的结果进一步证明了基于世界模型的后期训练在不同机器人设置中策略适应的有效性。虽然在潜动作方法 [73, 16, 27] 中也观察到类似的效果,但我们的世界模型提供了一种更简单的范式,无需潜动作,从而实现更好的可迁移性。
表 5:后期训练促成了数据高效和训练高效的下游策略学习。
(a) 数据效率比较。
| 方法 | 数据 | CALVIN |
|---|---|---|
| RT-1 [9] | 10%10 \%10% | 0.34 |
| MT-R3M [55] | 10%10 \%10% | 0.61 |
| HULC [53] | 10%10 \%10% | 1.11 |
| GR-1 [70] | 10%10 \%10% | 2.00 |
| RoboVLMS [46] | 10%10 \%10% | 2.52 |
| UniVLA (w/o post-train) | 10%10 \%10% | 0.15 |
| UniVLA | 10%10 \%10% | 3.19\mathbf{3 . 1 9}3.19 |
(b) 训练效率比较。
| 快速收敛(CALVIN) | |||
|---|---|---|---|
| 训练迭代次数 | 2 k | 4 k | 8 k |
| w/o post-train | 0.37 | 0.82 | 1.46 |
| w/ post-train | 4.21 | 4.56 | 4.61 |
| 快速适应(SimplerEnv-Bridge) | |||
| 方法 | 批量大小 | 迭代次数 | 成功率 |
| RoboVLMs [46] | 128 | 50k | 37.5 |
| UniVLA | 128 | 12k | 64.6 |
表 6:策略学习中视觉预测和历史上下文的消融研究。
(a) 视觉预测的效果。
| 后期训练 | 视觉预测 | CALVIN | LIBERO |
|---|---|---|---|
| ✓\checkmark✓ | 4.61 | 94.2 | |
| ✓\checkmark✓ | 4.42 | 88.7 | |
| 1.46 | 48.5 |
(b) 历史上下文的效果。
| 观察 | 平均长度 ↑\uparrow↑ | |
|---|---|---|
| 历史窗口 | 当前 + 历史 | |
| 0 | 1+01+01+0 | 4.26 |
| 10 | 1+11+11+1 | 4.61 |
| 10 | 1+21+21+2 | 4.43 |
| 20 | 1+21+21+2 | 4.47 |
视觉预测的有效性。虽然后期训练被证明是有效的,但模型在不依赖它的情况下表现出强性能同样至关重要。如表 6a 所示,我们的研究结果表明,即使没有后期训练,通过视觉损失监督进行微调——利用模型的自回归性质——自然地将世界模型学习整合到策略学习过程中。这种方法显著提高了模型的性能。
历史背景的有效性。历史背景——包括过去的观察和动作——为机器人规划提供了宝贵的指导。在本节中,我们调查了在微调阶段适当的历史窗口长度。如表 6b 所示,我们在 CALVIN 基准上进行的消融研究考察了不同历史窗口长度的影响。纳入历史窗口显著提高了性能(从 4.26 提升到 4.61)。然而,超过一定长度后延长窗口的效果逐渐减弱,这表明最近的观察携带最多的预测价值,与顺序规划中的马尔可夫性质一致。
图 3:UniVLA 的多模态能力。顶部:在 LIBERO 基准中执行长视野任务的动作输出。底部:视觉预测和空间定位显示了模型对时空的理解。红框标记当前观察;绿框表示预测的目标检测。
4.5 多模态能力
如图 3 所示,我们定性地展示了模型在统一框架中交错多种模态——动作、语言和视觉——的能力。这种设计使具身控制的策略学习、通过语言输出的空间推理以及通过视觉输出的未来状态预测成为可能,突出了模型对通用多模态理解的能力。
4.6 更广泛的应用
端到端的自动驾驶学习。为进一步探索我们的方法的潜力,我们在 NAVSIM 基准上进行了初步的迁移,通过在模型上进行微调来进行自动驾驶。值得注意的是,我们的方法是一个纯粹的自回归、基于标记的框架,将驾驶任务建模为离散多模态标记上的因果序列预测。尽管仅使用前视摄像头输入——不依赖 BEV 表示或多传感器融合——我们的模型在 NAVSIM 测试集上实现了强大的性能。值得注意的是,当前的性能并不是在驾驶视频上预训练的,而是仅在下游策略基准上进行微调的。这些结果突出了我们的方法在更广泛的现实世界应用中的强大潜力。
表 7:UniVLA 在 NAVSIM 上的端到端自动驾驶的更广泛应用。MC:多摄像头。L:激光雷达。FC:前摄像头。
| 方法 | 模型 | 输入 | NC ↑\uparrow↑ | DAC ↑\uparrow↑ | EP ↑\uparrow↑ | TTC ↑\uparrow↑ | C ↑\uparrow↑ | PDMS ↑\uparrow↑ |
|---|---|---|---|---|---|---|---|---|
| 人类 | - | - | 100.0 | 100.0 | 87.5 | 100.0 | 99.9 | 94.8 |
| Ego Status MLP | - | 自车状态 | 93.0 | 77.3 | 62.8 | 83.6 | 100.0 | 65.6 |
| VADv2 [15] | 基于 BEV | MC | 97.9 | 91.7 | 77.6 | 92.9 | 100.0 | 83.0 |
| UniAD [36] | 基于 BEV | MC | 97.8 | 91.9 | 78.8 | 92.9 | 100.0 | 83.4 |
| Transfuser [18] | 基于 BEV | MC&L | 97.7 | 92.8 | 79.2 | 92.8 | 100.0 | 84.0 |
| UniVLA | 自回归 | FC | 96.9 | 91.1 | 76.8 | 91.7 | 96.7 | 81.7 |
5 结论
在本文中,我们提出了 UniVLA,一个统一的视觉-语言-动作建模框架,通过共享标记空间桥接异质模态并通过自回归建模。所提出的统一设计促进了更深层的跨模态集成,并内在支持灵活的多模态任务。通过利用从视频中捕捉动态和因果关系的世界模型进行训练,我们观察到在下游策略学习方面的显著改进,无论是在性能还是效率方面。广泛的模拟实验进一步证明了模型的强大泛化能力、高效的策略学习以及在不同领域的广泛应用。这些发现突出了我们的方法作为视觉-语言-动作建模新范式的巨大潜力。
局限性与未来工作。由于计算资源有限,我们对后期训练可扩展性的研究仍处于早期阶段。尽管如此,初步结果令人鼓舞,表明有潜力扩展到更大的视频数据集。此外,尽管统一的多模态框架在跨模态学习方面表现出强大的能力,但仍需进一步研究以充分将其与强化学习范式整合,从而使策略学习更加稳健和自适应。
参考文献
[1] Leonardo Barcellona, Andrii Zadaianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Compositional world models empowering robot imitation learning with imagination. arXiv preprint arXiv:2412.14957, 2024. 4
[2] Suneel Belkhale, Tianli Ding, Ted Xiao, Pierre Sermanet, Quon Vuong, Jonathan Tompson, Yevgen Chebotar, Debidatta Dwibedi, and Dorsa Sadigh. Rt-h: Action hierarchies using language. arXiv preprint arXiv:2403.01823, 2024. 3
[3] Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024. 2
[4] Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables diverse zero-shot robot manipulation. In European Conference on Computer Vision, 2024. 3
[5] Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025. 2
[6] Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0\pi_{0}π0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024. 2, 3, 4
[7] Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Walke, Chelsea Finn, Aviral Kumar, and Sergey Levine. Zero-shot robotic manipulation with pretrained image-editing diffusion models. arXiv preprint arXiv:2310.10639, 2023. 3, 7
[8] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-languageaction models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023. 2, 3, 7
[9] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022. 7, 8, 16
[10] Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024. 3
[11] Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. Gamegen-x: Interactive open-world game video generation. arXiv preprint arXiv:2411.00769, 2024. 3
[12] Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2024. 3
[13] Lawrence Yunliang Chen, Simeon Adebola, and Ken Goldberg. Berkeley UR5 demonstration dataset. https://sites.google.com/view/berkeley-ur5/home. 16
[14] Lili Chen, Shikhar Bahl, and Deepak Pathak. Playfusion: Skill acquisition via diffusion from language-annotated play. In Conference on Robot Learning, pages 2012-2029. PMLR, 2023. 16
[15] Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243, 2024. 9
[16] Yi Chen, Yuying Ge, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for robot manipulation. arXiv preprint arXiv:2412.04445, 2024. 8
[17] Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023. 7
[18] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence, 45(11):12878-12895, 2022. 9
[19] Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven nonreactive autonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems, 37:28706-28719, 2024. 18
[20] Pengxiang Ding, Jianfei Ma, Xinyang Tong, Binghong Zou, Xinxin Luo, Yiguo Fan, Ting Wang, Hongchao Lu, Panzhong Mo, Jinxin Liu, et al. Humanoid-vla: Towards universal humanoid control with visual integration. arXiv preprint arXiv:2502.14795, 2025. 2
[21] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. 4
[22] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. In International Conference on Machine Learning, pages 84698488. PMLR, 2023. 3
[23] Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B Tenenbaum, et al. Video language planning. ICLR, 2024. 4
[24] Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. Advances in neural information processing systems, 36:9156-9172, 2023. 3
[25] Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In 2017 IEEE international conference on robotics and automation (ICRA), pages 2786-2793. IEEE, 2017. 3
[26] Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. arXiv preprint arXiv:2405.17398, 2024. 3
[27] Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions. arXiv preprint arXiv:2503.18938, 2025. 4, 8
[28] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. In Proceedings of the IEEE international conference on computer vision, pages 58425850, 2017. 16
[29] Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqing Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023. 16
[30] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 2
[31] Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 3
[32] David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018. 3
[33] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019. 3
[34] Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555-2565. PMLR, 2019. 4
[35] Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023. 3
[36] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853-17862, 2023. 9
[37] Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. \pi_ {0.5}\{0.5\}{0.5} : a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025. 3
[38] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024. 2
[39] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on robot learning, pages 651-673. PMLR, 2018. 16
[40] Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024. 16
[41] Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645, 2025. 3
[42] Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024. 2, 3, 4, 7, 16
[43] Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1-62, 2022. 3
[44] Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, and Tao Kong. Gr-mg: Leveraging partially-annotated data via multi-modal goal-conditioned policy. IEEE Robotics and Automation Letters, 2025. 3
[45] Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model. arXiv preprint arXiv:2503.00200, 2025. 4
[46] Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. Towards generalist robot policies: What matters in building vision-language-action models. arXiv preprint arXiv:2412.14058, 2024. 7, 8, 16
[47] Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, et al. Vision-language foundation models as effective robot imitators. In ICLR,2024.7I C L R, 2024.7ICLR,2024.7
[48] Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024. 2, 6
[49] Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36:44776-44791, 2023. 2, 6, 16
[50] Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025. 3
[51] Jianlan Luo, Charles Xu, Fangchen Liu, Liam Tan, Zipeng Lin, Jeffrey Wu, Pieter Abbeel, and Sergey Levine. Fmb: a functional manipulation benchmark for generalizable robotic learning. The International Journal of Robotics Research, page 02783649241276017, 2023. 16
[52] Corey Lynch and Pierre Sermanet. Language conditioned imitation learning over unstructured data. arXiv preprint arXiv:2005.07648, 2020. 7
[53] Oier Mees, Lukas Hermann, and Wolfram Burgard. What matters in language conditioned robotic imitation learning over unstructured data. IEEE Robotics and Automation Letters, 7(4):11205-11212, 2022. 8
[54] Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters, 7(3):7327-7334, 2022. 2, 5, 16
[55] Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation. arXiv preprint arXiv:2203.12601, 2022. 8
[56] Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. In Proceedings of Robotics: Science and Systems, Delft, Netherlands, 2024. 2,7
[57] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023. 2
[58] Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747, 2025. 3, 4, 5, 6, 7
[59] Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830, 2025. 3, 7
[60] Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. Latent plans for task-agnostic offline reinforcement learning. In Conference on Robot Learning, pages 1838-1849. PMLR, 2023. 16
[61] Rutav Shah, Roberto Martín-Martín, and Yuke Zhu. Mutex: Learning unified policies from multimodal task specifications. arXiv preprint arXiv:2309.14320, 2023. 16
[62] Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213, 2024. 7
[63] Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. arXiv preprint arXiv:2412.15109, 2024. 7
[64] Quan Vuong, Sergey Levine, Homer Rich Walke, Karl Pertsch, Anikait Singh, Ria Doshi, Charles Xu, Jianlan Luo, Liam Tan, Dhruv Shah, et al. Open x-embodiment: Robotic learning datasets and rt-x models. In Towards Generalist Robots: Learning Paradigms for Scalable Skill Acquisition@ CoRL2023, 2023. 3
[65] Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe HansenEstruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning, pages 1723-1736. PMLR, 2023. 16
[66] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 2
[67] Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-drive world models for autonomous driving. In European Conference on Computer Vision, pages 55-72. Springer, 2024. 3
[68] Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024. 4, 6
[69] Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14749-14759, 2024. 3
[70] Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. In The Twelfth International Conference on Learning Representations, 2024. 3, 7, 8
[71] Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In Conference on robot learning, pages 2226-2240. PMLR, 2023. 3, 4
[72] Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. arXiv preprint arXiv:2310.06114, 1(2):6,2023.31(2): 6,2023.31(2):6,2023.3
[73] Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos. ICLR,2025.3,8I C L R, 2025.3,8ICLR,2025.3,8
[74] Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent. arXiv preprint arXiv:2501.18867, 2025. 7
[75] Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. arXiv preprint arXiv:2503.22020, 2025. 6, 7
[76] Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model. In International Conference on Machine Learning, pages 61229-61245. PMLR, 2024. 3
[77] Chuanxia Zheng, Tung-Long Vuong, Jianfei Cai, and Dinh Phung. Movq: Modulating quantized vectors for high-fidelity image generation. Advances in Neural Information Processing Systems, 35:23412−23425,2022.435: 23412-23425,2022.435:23412−23425,2022.4
[78] Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345, 2024. 3
[79] Gaoyue Zhou, Victoria Dean, Mohan Kumar Srirama, Aravind Rajeswaran, Jyothish Pari, Kyle Hatch, Aryan Jain, Tianhe Yu, Pieter Abbeel, Lerrel Pinto, et al. Train offline, test online: A real robot learning benchmark. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9197-9203. IEEE, 2023. 16
[80] Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robodreamer: Learning compositional world models for robot imagination. arXiv preprint arXiv:2404.12377, 2024. 3
[81] Yifeng Zhu, Abhishek Joshi, Peter Stone, and Yuke Zhu. Viola: Imitation learning for visionbased manipulation with object proposal priors. In Conference on Robot Learning, pages 1199-1210. PMLR, 2023. 16
附录
A 实现细节
后期训练阶段 我们首先选择了几个高质量的机器人数据集用于后期训练,如表 8 所示。为了考虑不同数据集中数据收集频率的差异,我们应用了特定数据集的帧采样间隔,以确保关键帧之间的时间间隔大约为一秒。我们进一步过滤掉包含少于六帧的视频序列,以及那些缺乏相应文本指令的视频。由于 Kuka [39] 数据集中的视频数量众多,我们随机保留了 100k 个视频,以防止其在整体训练数据中占据主导地位。
表 8:后期训练数据集。
| 数据集 | 来源 | 数据类型 | 原始视频数 | 使用视频数 | 间隔 |
|---|---|---|---|---|---|
| RT-1 [9] | 真实 | 文本、视频、动作 | 87212 | 84084 | 3 |
| BridgeV2 [65] | 真实 | 文本、视频、动作 | 60064 | 28083 | 5 |
| DROID [40] | 真实 | 文本、视频、动作 | 275997 | 145641 | 15 |
| Kuka [39] | 真实 | 文本、视频、动作 | 580392 | 100000 | 3 |
| TOTO [79] | 真实 | 文本、视频、动作 | 902 | 899 | 20 |
| Taco Play [60] | 真实 | 文本、视频、动作 | 3242 | 3242 | 5 |
| FMB [51] | 真实 | 文本、视频、动作 | 8611 | 7876 | 5 |
| Berkeley autolab ur5 [13] | 真实 | 文本、视频、动作 | 896 | 896 | 5 |
| VIOLA [81] | 真实 | 文本、视频、动作 | 135 | 135 | 15 |
| Cmu Play Fusion [14] | 真实 | 文本、视频、动作 | 576 | 576 | 10 |
| Utaustin Mutex [61] | 真实 | 文本、视频、动作 | 1500 | 1500 | 10 |
| CALVIN [54] | 模拟 | 文本、视频、动作 | 22966 | 22966 | 5 |
| LIBERO [49] | 模拟 | 文本、视频、动作 | 3386 | 3386 | 10 |
| ManiSkill2 [29] | 模拟 | 文本、视频、动作 | 30213 | 193273 | 10 |
| SSV2 [28] | 真实 | 文本、视频 | 220847 | 220847 | 1 |
对于表 4 中的实验,为了确保对不同后训练策略进行公平比较,所有模型都在相同的数据集上进行训练(不包括不含动作注释的 SSV2 [28]),只有后训练策略有所不同。对于动作预测任务,我们将输入组织为 (T,I,A)(T, I, A)(T,I,A),其中 TTT 表示文本指令,III 表示图像观察,AAA 表示动作序列。在训练过程中,仅在动作标记 AAA 上进行监督损失计算。对于文本到图像任务,输入组织为 (T,I)(T, I)(T,I),其中 TTT 表示输入文本,III 表示目标图像。在训练过程中,损失仅在与 III 对应的视觉标记上计算。对于视频预测任务,输入组织为 (I1,…,It)\left(I_{1}, \ldots, I_{t}\right)(I1,…,It),其中 III 表示视频帧。在训练过程中,损失计算在视觉标记上。对于世界模型任务,输入组织为 (T,I1,…,It)\left(T, I_{1}, \ldots, I_{t}\right)(T,I1,…,It),其中 TTT 表示输入文本,III 表示视频帧。在训练过程中,损失计算在视觉标记上。
在训练过程中,将观测调整为 256×256256 \times 256256×256 大小,使用六帧作为输入,最大序列长度设置为 6400 。我们在 32 个 A100 GPU (40 GB)(40 \mathrm{~GB})(40 GB) 上进行了 50k 步的全参数训练,耗时约 4-5 天。
模拟微调 训练设置在主文中已描述。我们采用全参数训练,在评估时,我们按照 OpenVLA [42] 和 RoboVLMs [46] 在各种基准上的测试协议进行评估。默认情况下,我们的模型使用视频格式序列进行训练;然而,它也支持使用图像格式序列进行微调。在评估视觉预测效果的消融研究中,当未应用后训练时,视觉标记权重设置为 0.5,而动作标记权重设置为 1.0,以保持两种模态之间的平衡。
真实机器人微调 为了进行真实世界的评估,我们在 ALOHA 平台上进行了实验,使用从三个视角(cam high、wrist left 和 wrist right)捕获的图像。真实机器人通过末端执行器(EE)姿态进行控制。所有输入图像都被调整为 128×128128 \times 128128×128 的分辨率。模型输出一个 14 维的动作向量。动作块大小设置为 20 。
每个任务训练 8k 步,批处理大小为 256 。学习率设置为 5×10−55 \times 10^{-5}5×10−5,其他所有设置均与上述一致。我们还利用了世界模型预训练,使用收集的真实 aloha 数据集(表 9)进行基于视频的后训练。有趣的是,即使转移到真实的机器人执行,这种后训练也能提供显著的好处。
B 真实机器人实验

图 4:AgileX Cobot Magic 双臂机器人的真实世界设置。该系统配备了三个 RGB 相机进行视觉观察:一个安装在左腕部,一个安装在右腕部,还有一个位于高角度视图的位置。
B. 1 ALOHA 实验设置
本文使用的机器人平台是 AgileX Cobot Magic V2.0,这是一个双臂机器人。如图 4 所示,该机器人配备了两个手臂和三个相机视角,使其能够执行多种操作任务。例如,图 5 展示了一系列从真实场景中收集的操作任务实例。
图 5:真实世界任务示例。这些任务包括擦拭白板、整理餐具、制作汉堡包和插入连接器等多样化任务。
现实世界任务收集 表 9 提供了从物理机器人收集的真实世界数据摘要,记录的实际频率为 30 Hz 。总共包含了 8 个任务,每个任务平均收集了约 500 条轨迹。在预处理期间,过滤掉了每条轨迹开始和结束时的静态帧。
表 9:真实世界任务轨迹。
| 折叠衣服 | 清理桌子 | 存储眼镜 | 食物包装 | 倒水 | 清洁黑板 | 插入插头 | 制作汉堡包 |
|---|---|---|---|---|---|---|---|
| 528 | 500 | 500 | 500 | 496 | 500 | 500 | 640 |
数据处理 为了减少冗余并提高训练效率,我们根据记录的动作关节值变化阈值选择关键帧。对于每个选定的序列,动作块通过减去第一帧的关节值进行归一化。
C 自动驾驶实验
NAVSIM 设置 NAVSIM 数据集 [19],从 OpenScene 重新采样以强调挑战性场景,目前是自动驾驶领域最成熟的端到端评估基准之一。数据集分为两部分:Navtrain 和 Navtest,分别包含 1,192 个用于训练和验证的场景,以及 136 个用于测试的场景。
在模型训练中,输入图像被调整为 512×288512 \times 288512×288 的分辨率。我们遵循标准的训练设置,使用当前图像帧和自车状态来预测接下来 8 帧的轨迹。动作和自车状态都使用快速标记器进行编码。
参考论文:https://arxiv.org/pdf/2506.19850

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)