每日论文速递 | LeCun新作:IWM图像世界模型
深度学习自然语言处理 分享整理:pp摘要:联合嵌入预测架构Joint-Embedding Predictive Architecture(JEPA)是一种很有前途的自监督方法,它通过利用世界模型进行学习。虽然以前仅限于预测输入中的缺失部分,但我们探索了如何将 JEPA 预测任务推广到更广泛的损坏数据集。我们引入了图像世界模型Image World Models (IWM),这是一种超越遮蔽图像建模
深度学习自然语言处理 分享
整理:pp
 摘要:联合嵌入预测架构Joint-Embedding Predictive Architecture(JEPA)是一种很有前途的自监督方法,它通过利用世界模型进行学习。虽然以前仅限于预测输入中的缺失部分,但我们探索了如何将 JEPA 预测任务推广到更广泛的损坏数据集。我们引入了图像世界模型Image World Models (IWM),这是一种超越遮蔽图像建模的方法,可学习预测潜在空间中全局光度变换的影响。我们研究了学习性能良好的图像世界模型的秘诀,并证明它依赖于三个关键方面:条件、预测难度和容量。此外,我们还证明,通过微调可以调整 IWM 学习到的预测性世界模型,以解决不同的任务;微调后的 IWM 世界模型与之前的自监督方法性能相当,甚至更胜一筹。最后,我们还展示了利用 IWM 学习可以控制所学表征的抽象程度,学习不变表征(如对比方法)或等变表征(如遮蔽图像建模)。
摘要:联合嵌入预测架构Joint-Embedding Predictive Architecture(JEPA)是一种很有前途的自监督方法,它通过利用世界模型进行学习。虽然以前仅限于预测输入中的缺失部分,但我们探索了如何将 JEPA 预测任务推广到更广泛的损坏数据集。我们引入了图像世界模型Image World Models (IWM),这是一种超越遮蔽图像建模的方法,可学习预测潜在空间中全局光度变换的影响。我们研究了学习性能良好的图像世界模型的秘诀,并证明它依赖于三个关键方面:条件、预测难度和容量。此外,我们还证明,通过微调可以调整 IWM 学习到的预测性世界模型,以解决不同的任务;微调后的 IWM 世界模型与之前的自监督方法性能相当,甚至更胜一筹。最后,我们还展示了利用 IWM 学习可以控制所学表征的抽象程度,学习不变表征(如对比方法)或等变表征(如遮蔽图像建模)。
https://arxiv.org/abs/2403.00504
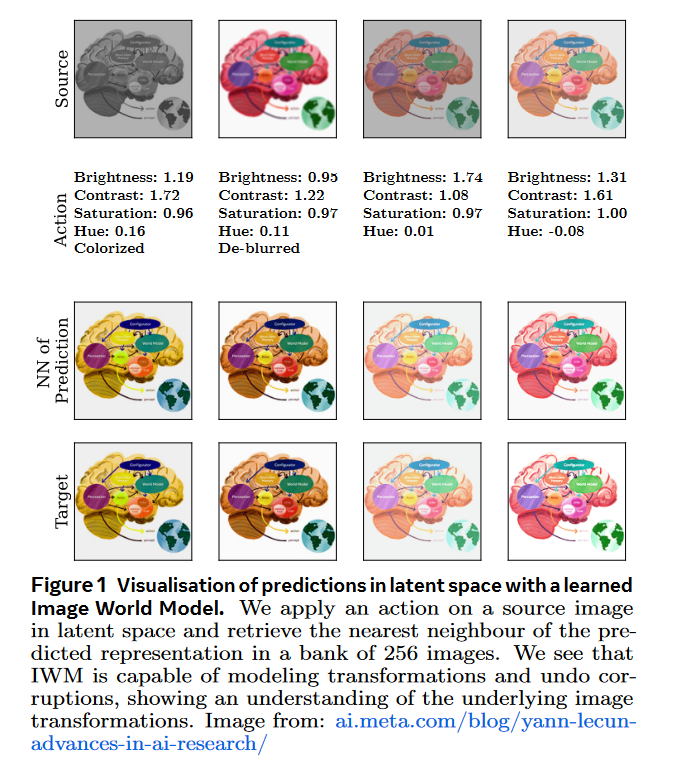
Q1: 这篇论文试图解决什么问题?
A:这篇论文探讨了在视觉表示学习中学习和利用世界模型的可能性。具体来说,它试图解决以下问题:
-
自监督学习方法的局限性:传统的自监督学习方法,如掩蔽图像建模(Masked Image Modeling)和对比学习方法,通常在预训练后丢弃了学到的世界模型,主要关注编码器网络的表示质量。作者提出,这种做法可能浪费了世界模型的潜力,因为在强化学习中,学到的世界模型通常会被用于下游任务,如规划。
-
世界模型在视觉表示学习中的应用:论文提出了一种名为Image World Models (IWM) 的方法,它基于Joint-Embedding Predictive Architecture (JEPA) 框架,旨在学习能够预测全局光度变换的潜在空间表示的模型。这种方法超越了掩蔽图像建模,允许模型学习更广泛的变换。
-
世界模型的泛化能力:作者探索了如何通过微调(finetuning)来适应不同的任务,例如图像分类和图像分割,从而证明学到的世界模型不仅能够用于预训练任务,还能够迁移到其他视觉任务。
-
表示的抽象层次控制:通过调整世界模型的容量,IWM能够控制学习到的表示的抽象层次。这允许模型学习到具有不同属性的表示,例如对比学习方法学习的更抽象的表示,或者掩蔽图像建模学习的更具体的表示。
-
多任务学习:论文还探讨了如何通过多任务微调来提高效率,即在多个任务上同时微调预测器,而不是单独为每个任务训练模型。
总的来说,这篇论文的目标是提出一种新的自监督学习方法,该方法能够学习强大的世界模型,并将其应用于多种下游任务,同时提供对表示抽象层次的控制。
Q2: 有哪些相关研究?
A:在这篇论文中,作者提到了多个与自监督学习、世界模型、以及视觉表示学习相关的研究领域。以下是一些关键的相关研究:
自监督学习:
掩蔽图像建模(Masked Image Modeling):如Bao et al. (2021) 和 He et al. (2021) 的工作,这些方法通过预测图像的掩蔽部分来学习表示。
对比学习方法:如Chen et al. (2020a, 2020b) 和 Caron et al. (2021),这些方法通过最大化不同增强视图之间的相似性来学习表示。
联合嵌入预测架构(Joint-Embedding Predictive Architecture, JEPA):如Assran et al. (2023) 和 Baevski et al. (2022),这些方法通过在潜在空间中预测变换后的表示来学习。
世界建模:
强化学习中的世界模型:如Ha and Schmidhuber (2018) 和 Hafner et al. (2019, 2023) 的工作,这些研究展示了在强化学习中世界模型的成功应用。
视觉表示学习中的世界建模:尽管在视觉表示学习中世界建模的概念尚未明确证明其优势,但有多种方法可以重新框架化,如Equivariant self-supervised learning methods (Devillers and Lefort, 2022; Park et al., 2022)。
生成模型:
生成对抗网络(GANs) 和 变分自编码器(VAEs):这些方法在表示学习中也有所应用,尽管它们的性能通常低于对比方法或MIM方法。
多任务学习和微调:
指令微调(Instruction Tuning):如Wei et al. (2022) 和 Zhang et al. (2023),这些方法通过给模型提供新的学习令牌来指示模型尝试解决的任务。
线性和有注意力的探测:
线性探测:如Chen et al. (2021),这种方法通过简单的线性层来评估学习到的表示。
有注意力的探测:如Chen et al. (2023),这种方法使用注意力机制来更复杂地评估表示。
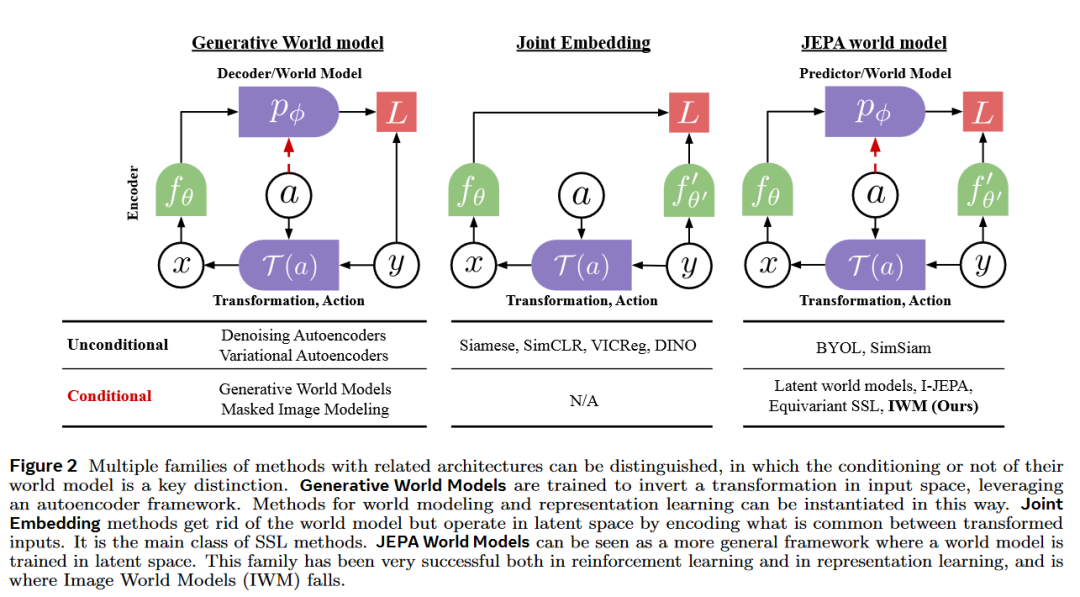
Q3: 论文如何解决这个问题?
A:论文通过提出Image World Models (IWM) 来解决在视觉表示学习中利用世界模型的问题。IWM是一种基于Joint-Embedding Predictive Architecture (JEPA) 的自监督学习方法,它通过以下关键步骤来实现:
-
扩展JEPA预测任务:IWM不仅限于预测输入的缺失部分,而是将预测任务推广到更广泛的图像变换,包括全局光度变换。
-
关键要素的学习:论文研究了学习有效的IWM所需的三个关键要素:条件化(conditioning)、预测难度(prediction difficulty)和容量(capacity)。
-
条件化:通过将变换参数(如掩蔽位置、光度变换参数)作为条件信息输入到预测器中,使得模型能够学习到变换的效果。
-
预测难度:通过使用复杂的数据增强(如颜色抖动、模糊、去色等),确保预测任务具有一定的挑战性,从而促使模型学习到有用的表示。
-
容量:通过增加预测器的深度和嵌入维度,提供足够的容量来处理复杂的变换。
-
微调适应性:展示了通过微调(finetuning)IWM学到的世界模型,可以适应多种下游任务。微调后的IWM在多种任务上的性能与之前自监督方法相当或更优。
-
表示的抽象层次控制:通过调整世界模型的容量,IWM能够控制学习到的表示的抽象层次。这允许模型学习到具有不同属性的表示,例如对比学习方法学习的更抽象的表示,或者掩蔽图像建模学习的更具体的表示。
-
多任务微调:受到指令微调(instruction tuning)的启发,论文展示了IWM的预测器可以在多个任务上同时进行微调,进一步提高效率。
-
可视化和评估:通过可视化预测结果和使用不同的评估协议(如线性评估、有注意力的探测),论文验证了IWM学习到的表示的质量和多样性。
通过这些方法,论文不仅提出了一种新的自监督学习方法,而且还展示了如何通过微调和多任务学习来充分利用学到的世界模型,以及如何通过调整模型的参数来控制表示的抽象层次。这些研究成果为视觉表示学习提供了新的视角,并为未来的研究提供了有价值的指导。
Q4: 论文做了哪些实验?
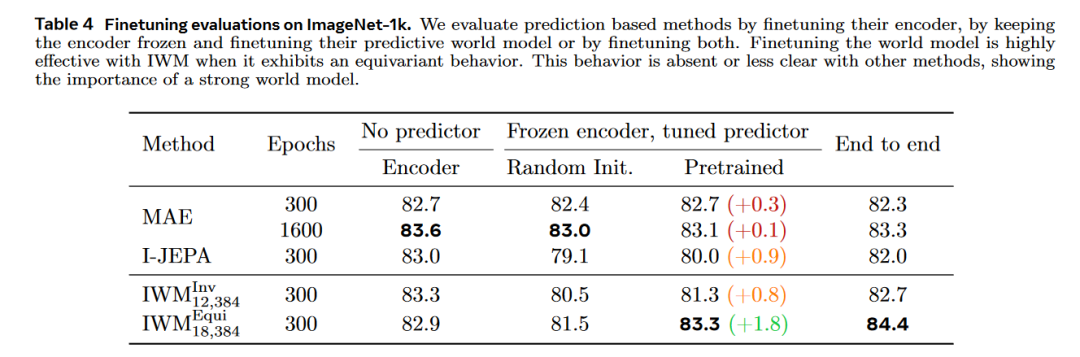
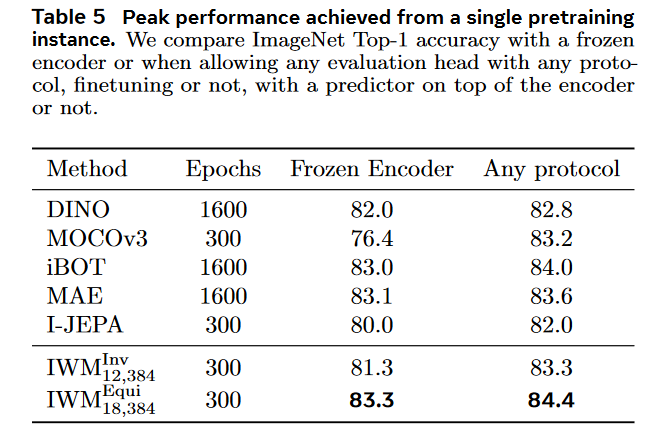
A:论文中进行了一系列实验来验证Image World Models (IWM) 的有效性和多功能性。以下是主要的实验内容:
世界模型质量评估:
使用Mean Reciprocal Rank (MRR) 作为主要指标,通过预测增强目标图像的表示并计算其与增强表示库中目标的最近邻距离来评估世界模型的质量。
关键要素的影响:
研究了条件化、预测难度和预测器容量对学习有效世界模型的影响。通过对比不同设置下的MRR值,展示了这些要素的重要性。
预测任务的影响:
通过不同的预测任务设置(如使用教师网络、空潜在表示、仅预测一个标记等)来研究它们对下游任务性能的影响。
微调协议的比较:
将预测器微调与编码器微调以及端到端微调进行比较,以评估不同微调策略在ImageNet分类任务上的性能。
多任务微调:
展示了如何通过多任务微调来提高效率,即在多个任务上同时微调预测器,而不是单独为每个任务训练模型。
线性和有注意力的探测性能:
使用线性和有注意力的探测协议来评估学习到的表示的质量,并与对比学习方法和掩蔽图像建模方法进行比较。
下游任务的性能:
在图像分类(ImageNet、iNaturalist18、SUN397、Places205)和图像分割(ADE20k)任务上评估IWM的性能。
表示空间的可视化:
通过可视化表示空间中的相似性矩阵,展示了不变性和等变模型在表示学习中的差异。
精确变换的应用:
通过在特定变换参数上进行网格搜索,展示了IWM在预测小变化方面的能力。
消融研究:
对于不同的数据增强策略、预测器架构和训练协议进行了消融研究,以验证它们对模型性能的影响。
Q5: 有什么可以进一步探索的点?
A:尽管论文提出了一种新的自监督学习方法并进行了广泛的实验验证,但仍有一些潜在的研究方向可以进一步探索:
更复杂的世界模型:探索是否可以构建更复杂的世界模型来处理更广泛的图像变换和属性,例如空间变换、时间序列数据或视频数据。
不同任务的微调策略:研究特定于任务的微调策略,以进一步提高IWM在特定应用(如目标检测、语义分割、视频理解)中的性能。
跨模态学习:将IWM应用于跨模态学习任务,例如图像和文本的联合表示学习,或者图像和声音的关联学习。
理论分析:深入分析IWM的理论基础,包括表示学习的理论保证、泛化能力和计算效率。
计算效率的优化:研究如何进一步优化IWM的训练和推理过程,以减少计算资源消耗,使其更适合资源受限的环境。
鲁棒性和泛化性研究:评估IWM在面对噪声数据、对抗性攻击和分布偏移时的鲁棒性。
多任务学习的扩展:探索如何将IWM应用于更复杂的多任务学习场景,例如同时学习多个视觉任务和非视觉任务。
可解释性和可视化:提高IWM的可解释性,通过可视化技术来理解模型是如何学习和应用世界模型的。
实时应用:研究如何将IWM应用于需要实时反馈的应用,例如自动驾驶或机器人导航。
开放世界学习:探索IWM在开放世界设置中的性能,其中模型需要处理在训练期间未见过的新类别或变换。
这些研究方向不仅可以推动自监督学习领域的发展,还可能为计算机视觉和其他人工智能应用带来新的突破。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题定义:论文探讨了在视觉表示学习中如何有效地学习和利用世界模型。作者指出,尽管在强化学习中世界模型已被证明是有益的,但在视觉表示学习中,这一概念尚未得到充分探索。
方法提出:作者提出了Image World Models (IWM),这是一种基于Joint-Embedding Predictive Architecture (JEPA) 的自监督学习方法。IWM通过预测图像的全局光度变换来学习潜在空间中的表示。
关键要素:论文强调了学习有效IWM的三个关键要素:条件化(预测器对变换的依赖)、预测难度(数据增强的复杂性)和预测器的容量。
实验验证:通过一系列实验,作者展示了IWM在不同任务(如图像分类和分割)上的性能,并与现有方法进行了比较。实验结果表明,IWM在微调后能够达到或超过现有自监督方法的性能。
表示的抽象层次:论文还探讨了如何通过调整世界模型的容量来控制学习到的表示的抽象层次,从而学习到具有不同属性的表示。
多任务微调:作者展示了IWM的预测器可以在多个任务上同时进行微调,提高了效率并保持了性能。
可视化和评估:通过可视化表示空间和使用不同的评估协议,论文验证了IWM学习到的表示的质量和多样性。
未来方向:论文提出了一些未来研究方向,包括构建更复杂的世界模型、探索特定于任务的微调策略、跨模态学习、理论分析、计算效率优化等。
总的来说,这篇论文提出了一种新的自监督学习方法,通过学习强大的世界模型来提高视觉表示学习的性能,并在多个方面进行了深入的实验验证和分析。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)