经典文献阅读之--BEVWorld(通过统一的BEV潜在空间实现多模态世界模型的自动驾驶)
世界模型建模了有关环境的知识,其可以通过给定的条件对未来进行合理的想象。:生成鬼探头、前方车辆遗撒等稀缺数据,并通过条件拓展不同天气、光照等环境下的数据。:自动驾驶模型的planning结果作为世界模型未来预测的条件,产出控车后的数据进行闭环测试。:对抗样本是自动驾驶模型的一个安全隐患,利用世界模型,采用同一场景变换condition的方式或者黑盒攻击方式,拿到模型失效的且逼真的样本,用于提升自动
0.简介
世界模型建模了有关环境的知识,其可以通过给定的条件对未来进行合理的想象。未来想象要求世界模型具有物理规律的理解能力以及零样本的探索能力,使得其在自动驾驶领域有着广泛的应用前景,比如:
长尾数据生成:生成鬼探头、前方车辆遗撒等稀缺数据,并通过条件拓展不同天气、光照等环境下的数据。
闭环仿真测试:自动驾驶模型的planning结果作为世界模型未来预测的条件,产出控车后的数据进行闭环测试。
对抗样本:对抗样本是自动驾驶模型的一个安全隐患,利用世界模型,采用同一场景变换condition的方式或者黑盒攻击方式,拿到模型失效的且逼真的样本,用于提升自动驾驶模型的安全性。
foundation model:世界模型通常采用自监督的训练模式,这种方式可以利用大量的无标注数据进行训练,从而可以作为感知决策模型的foundation model来提升自动驾驶模型的泛化能力。
本文《BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space》提出了一种创新方法,通过统一的鸟瞰图(Bird’s Eye View, BEV)潜在空间整合多模态传感器输入,进而构建世界模型。BEV的空间表达可以便捷地对齐多模态数据,提升多模态数据的生成一致性。同时,BEV表征可以自然地与端到端自动驾驶模型相结合,作为其辅助任务或预训练模型使用。代码即将在Github开源。
1. 主要贡献
潜在的BEV序列扩散网络旨在预测图像和点云的未来帧。借助多模态标记器,这项任务变得更容易,从而实现准确的未来BEV预测。具体而言,我们使用一种基于扩散的方法,结合时空Transformer,将序列中的噪声BEV潜在表示转换为基于动作条件的干净的未来BEV预测。
总结来说,本文的主要贡献如下:
- 我们引入了一种新颖的多模态标记器,将视觉语义和3D几何整合到统一的BEV表示中。通过创新性地应用基于渲染的方法从BEV中恢复多传感器数据,确保了BEV表示的质量。通过消融研究、可视化和下游任务实验验证了BEV表示的有效性。
- 我们设计了一个基于潜在扩散的世界模型,使未来多视角图像和点云的同步生成成为可能。在nuScenes和Carla数据集上的大量实验展示了多模态数据在未来预测性能上的领先表现。
2. 总体方法
在本节中,我们详细描述了BEVWorld的模型结构。整体架构如图1所示。给定一个多视角图像和Lidar观测序列 { o t − P , ⋯ , o t − 1 , o t , o t + 1 , ⋯ , o t + N } \{o_{t-P}, \cdots, o_{t-1}, o_t, o_{t+1}, \cdots, o_{t+N}\} {ot−P,⋯,ot−1,ot,ot+1,⋯,ot+N},其中 o t o_t ot 是当前观测,+/− 分别代表未来/过去的观测, P / N P/N P/N 是过去/未来观测的数量,我们的目标是在条件 { o t − P , ⋯ , o t − 1 , o t } \{o_{t-P}, \cdots, o_{t-1}, o_t\} {ot−P,⋯,ot−1,ot} 下预测 { o t + 1 , ⋯ , o t + N } \{o_{t+1}, \cdots, o_{t+N}\} {ot+1,⋯,ot+N}。鉴于在原始观测空间中学习世界模型的计算成本较高,我们提出了一种多模态标记器,将多视角图像和Lidar信息按帧压缩到统一的BEV空间中。编码器-解码器结构和自监督重建损失确保了几何和语义信息能够在BEV表示中得到良好的存储。这种设计为世界模型和其他下游任务提供了足够简洁的表示。我们的世界模型被设计为基于扩散的网络,以避免类似自回归方式中错误累积的问题。它以自车运动和 { x t − P , ⋯ , x t − 1 , x t } \{x_{t-P}, \cdots, x_{t-1}, x_t\} {xt−P,⋯,xt−1,xt}(即 { o t − P , ⋯ , o t − 1 , o t } \{o_{t-P}, \cdots, o_{t-1}, o_t\} {ot−P,⋯,ot−1,ot} 的BEV表示)作为条件来学习在训练过程中添加到 { x t + 1 , ⋯ , x t + N } \{x_{t+1}, \cdots, x_{t+N}\} {xt+1,⋯,xt+N} 的噪声 { ϵ t + 1 , ⋯ , ϵ t + N } \{\epsilon_{t+1}, \cdots, \epsilon_{t+N}\} {ϵt+1,⋯,ϵt+N}。在测试过程中,应用DDIM [32] 调度器从纯噪声中恢复未来的BEV token。接下来,我们使用多模态标记器的解码器来渲染未来的多视角图像和Lidar帧。
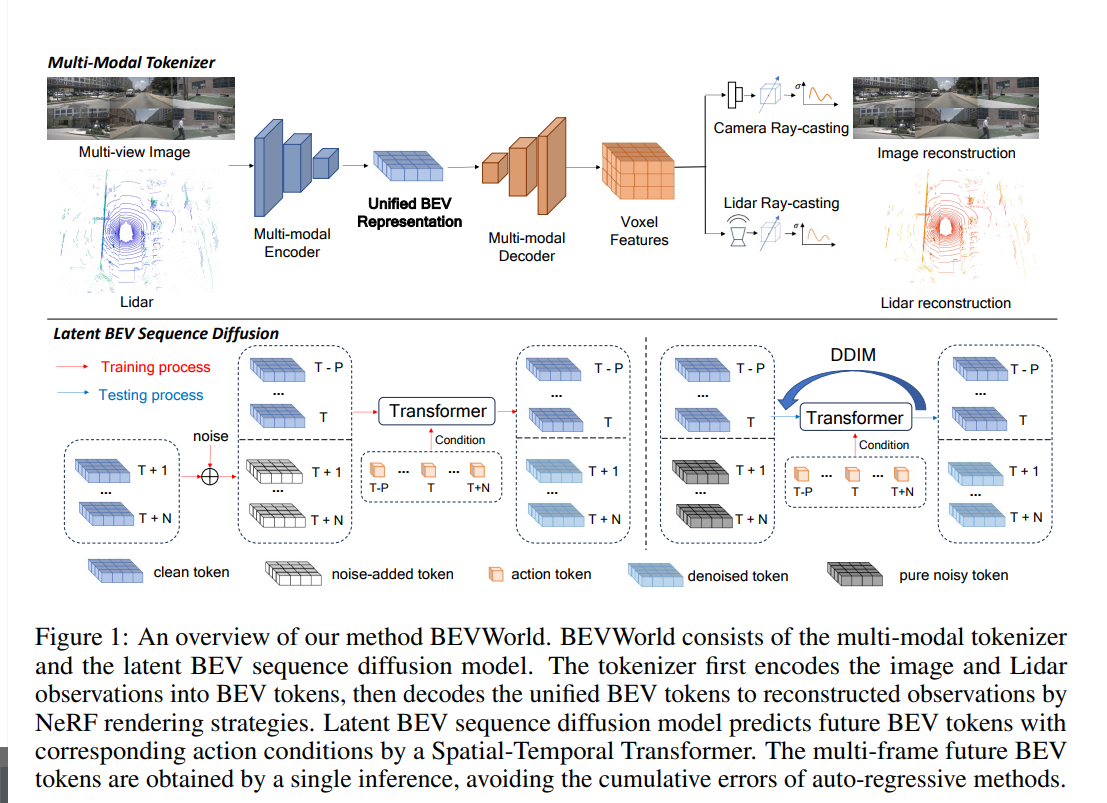
图1:我们的BEVWorld方法概览。BEVWorld由多模态标记器和潜在的BEV序列扩散模型组成。标记器首先将图像和Lidar观测编码为BEV token,然后通过NeRF渲染策略将统一的BEV token解码为重建的观测结果。潜在的BEV序列扩散模型通过时空Transformer,在相应的动作条件下预测未来的BEV token。多帧未来BEV token通过一次推理获得,避免了自回归方法的累积误差。
3. 多模态标记器
我们设计的多模态标记器包含三个部分:BEV编码器网络、BEV解码器网络和多模态渲染网络。BEV编码器网络的结构。如图2所示。为了使多模态网络尽可能地同质化,我们采用了Swin-Transformer [22] 网络作为图像主干网络来提取多图像特征。对于Lidar特征的提取,我们首先将点云在BEV空间中分割为柱体 [19],然后使用Swin-Transformer网络作为Lidar主干网络来提取Lidar BEV特征。我们通过基于可变形Transformer [46] 的方法将Lidar BEV特征与多视角图像特征融合。具体而言,我们在柱体的高度维度上采样 K( K = 4 K = 4 K=4)个点,并将这些点投影到图像上,以采样相应的图像特征。这些采样的图像特征作为值(values),而Lidar BEV特征作为查询(queries)在可变形注意力计算中使用。考虑到未来预测任务需要低维输入,我们进一步将融合后的BEV特征压缩为低维( C ′ = 4 C'= 4 C′=4)的BEV特征。对于BEV解码器,直接使用解码器来恢复图像和Lidar时存在模糊性问题,因为融合的BEV特征缺乏高度信息。为了解决这个问题,我们首先通过堆叠的上采样层和Swin块将BEV token转换为3D体素特征。然后,我们使用基于体素化的NeRF射线渲染来恢复多视角图像和Lidar点云。多模态渲染网络可以优雅地分为两个不同的部分,即图像重建网络和Lidar重建网络。对于图像重建网络,我们首先获得从相机中心 o o o 沿着方向 d d d 朝向像素中心射出的射线 r ( t ) = o + t d r(t) = o + td r(t)=o+td。然后,我们在射线上均匀采样一组点 { ( x i , y i , z i ) } i = 1 N r \{(x_i, y_i, z_i)\}_{i=1}^{N_r} {(xi,yi,zi)}i=1Nr,其中 N r ( N r = 150 ) N_r (N_r = 150) Nr(Nr=150) 是沿射线采样的点的总数。给定一个采样点 ( x i , y i , z i ) (x_i, y_i, z_i) (xi,yi,zi),根据其位置从体素特征中获取相应的特征 v i v_i vi。接着,将射线上所有采样特征聚合为像素级特征描述符(见公式1)。
v ( r ) = ∑ i = 1 N r w i v i , w i = α i ∏ j = 1 i − 1 ( 1 − α j ) , α i = σ ( MLP ( v i ) ) (1) \mathbf{v}(\mathbf{r}) = \sum_{i=1}^{N_r} w_i \mathbf{v}_i, \quad w_i = \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j), \quad \alpha_i = \sigma(\text{MLP}(\mathbf{v}_i)) \tag{1} v(r)=i=1∑Nrwivi,wi=αij=1∏i−1(1−αj),αi=σ(MLP(vi))(1)
我们遍历所有像素并获得图像的二维特征图 V ∈ R H f × W f × C f V \in \mathbb{R}^{H_f \times W_f \times C_f} V∈RHf×Wf×Cf。二维特征通过CNN解码器转换为RGB图像 I g ∈ R H × W × 3 I_g \in \mathbb{R}^{H \times W \times 3} Ig∈RH×W×3。为了提高生成图像的质量,我们添加了三种常见的损失:感知损失 [14]、GAN损失 [8] 和 L1 损失。我们的图像重建完整目标为:
L rgb = ∥ I g − I t ∥ 1 + λ perc ∥ ∑ j = 1 N ϕ ϕ j ( I g ) − ϕ j ( I t ) ∥ + λ gan L gan ( I g , I t ) (2) \mathcal{L}_{\text{rgb}} = \| \mathbf{I}_g - \mathbf{I}_t \|_1 + \lambda_{\text{perc}} \left\| \sum_{j=1}^{N_\phi} \phi^j(\mathbf{I}_g) - \phi^j(\mathbf{I}_t) \right\| + \lambda_{\text{gan}} \mathcal{L}_{\text{gan}}(\mathbf{I}_g, \mathbf{I}_t) \tag{2} Lrgb=∥Ig−It∥1+λperc j=1∑Nϕϕj(Ig)−ϕj(It) +λganLgan(Ig,It)(2)
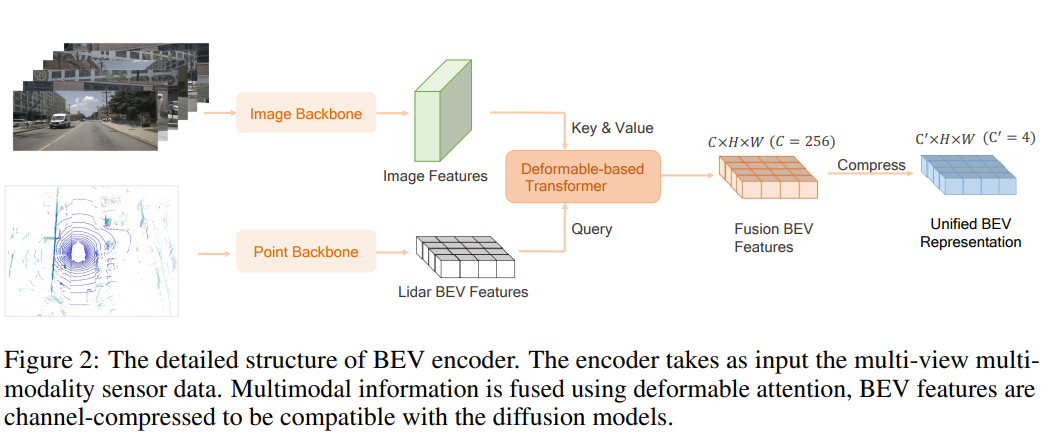
图2:BEV编码器的详细结构。编码器将多视角多模态传感器数据作为输入。多模态信息通过可变形注意力机制进行融合,BEV特征被压缩通道以与扩散模型兼容。
其中, I t I_t It 是 I g I_g Ig 的地面真实图像, ϕ j \phi^j ϕj 代表预训练VGG [31] 模型的第 j j j 层, L gan ( I g , I t ) \mathcal{L}_{\text{gan}}(I_g, I_t) Lgan(Ig,It) 的定义可以在文献 [8] 中找到。
对于Lidar重建网络,射线在球坐标系中由仰角 θ \theta θ 和方位角 ϕ \phi ϕ 定义。通过从Lidar中心射向当前帧的Lidar点来获得 θ \theta θ 和 ϕ \phi ϕ。我们以与图像重建相同的方式采样点并获取相应的特征。由于Lidar编码了深度信息,采样点的期望深度 D g ( r ) D_g(r) Dg(r) 被计算用于Lidar仿真。深度仿真过程和损失函数如公式3所示。
D g ( r ) = ∑ i = 1 N r w i t i , L Lidar = ∥ D g ( r ) − D t ( r ) ∥ 1 , (3) D_g(r) = \sum_{i=1}^{N_r} w_i t_i, \quad \mathcal{L}_{\text{Lidar}} = \| D_g(r) - D_t(r) \|_1, \tag{3} Dg(r)=i=1∑Nrwiti,LLidar=∥Dg(r)−Dt(r)∥1,(3)
其中, t i t_i ti 表示从Lidar中心采样点的深度, D t ( r ) D_t(r) Dt(r) 是通过Lidar观测计算的深度地面真实值。
-
点云的笛卡尔坐标可以通过以下公式计算:
( x , y , z ) = ( D g ( r ) sin θ cos ϕ , D g ( r ) sin θ sin ϕ , D g ( r ) cos θ ) (4) (x, y, z) = \left( D_g(r) \sin \theta \cos \phi, D_g(r) \sin \theta \sin \phi, D_g(r) \cos \theta \right) \tag{4} (x,y,z)=(Dg(r)sinθcosϕ,Dg(r)sinθsinϕ,Dg(r)cosθ)(4) -
总体来说,多模态标记器通过端到端训练,其总损失在公式5中:
L Total = L Lidar + L rgb (5) \mathcal{L}_{\text{Total}} = \mathcal{L}_{\text{Lidar}} + \mathcal{L}_{\text{rgb}} \tag {5} LTotal=LLidar+Lrgb(5)
…详情请参照古月居

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 7
7 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)