基于多视图轨迹视频的高一致性具身世界模型MTV-World: 赋能精准机器人操纵预测
同济大学&华东师范大学&美的集团联合研发的基于多视图轨迹视频的高一致性具身世界模型MTV-World,通过多视图轨迹视频控制与空间补偿机制,突破上述技术瓶颈,实现兼具运动精度与物理一致性的视觉运动预测,为复杂双臂机器人操纵任务提供可靠的模拟支撑。
摘要:具身世界模型作为物理世界的预测模拟器,能够基于当前观测与规划动作预测未来结果,在机器人政策学习的数据生成与安全评估中发挥核心作用。然而,现有模型普遍面临两大关键局限:一是难以将低层级动作(如关节位置)精准转化为机器人运动,导致预测帧中轨迹不稳定;二是运动预测的不精确进一步引发机器人与对象的交互偏差,与真实物理动力学规律存在不一致。
由同济大学&华东师范大学&美的集团联合研发的基于多视图轨迹视频的高一致性具身世界模型MTV-World《Towards High-Consistency Embodied World Model with Multi-View Trajectory Videos》:旨在通过多视图轨迹视频控制与空间补偿机制,突破上述技术瓶颈,实现兼具运动精度与物理一致性的视觉运动预测,为复杂双臂机器人操纵任务提供可靠的模拟支撑。
一、传统具身世界模型的核心技术瓶颈
当前具身世界模型在机器人操纵场景中仍存在难以忽视的短板,制约了其实际应用价值:
1. 低层级动作到运动的转化失准
现有模型多直接采用关节位置等低层级动作作为控制信号,但这类信号与机器人末端执行器的实际运动存在映射鸿沟,导致预测视频中机械臂轨迹不连贯、不真实,无法复现精准的操纵动作(如抓取、堆叠的精细运动)。
2. 空间信息损失引发交互不一致
将 3D 空间中的机器人动作投影到 2D 图像时,不可避免会丢失深度、方位等关键空间信息。单一视图的观测方式进一步放大了这种损失,使得模型难以准确建模机器人与对象的物理交互(如对象抓取后的位置跟随、堆叠时的接触对齐),导致预测结果与真实物理规律脱节。
3. 评估体系缺乏交互精准度度量
传统评估指标(如 FID、FVD)仅聚焦于生成视频的感知质量,无法量化机器人运动的执行精度与对象交互的准确性。现有评估方法难以系统性衡量具身世界模型的核心功能价值,阻碍了技术迭代与优化。
二、MTV-World 的核心技术设计:多维度保障高一致性预测
MTV-World 通过轨迹表示、对象建模、多视图架构与自动评估四大核心模块的协同设计,构建了从控制信号到预测结果的全链路一致性保障体系,其整体框架如图 1 所示。
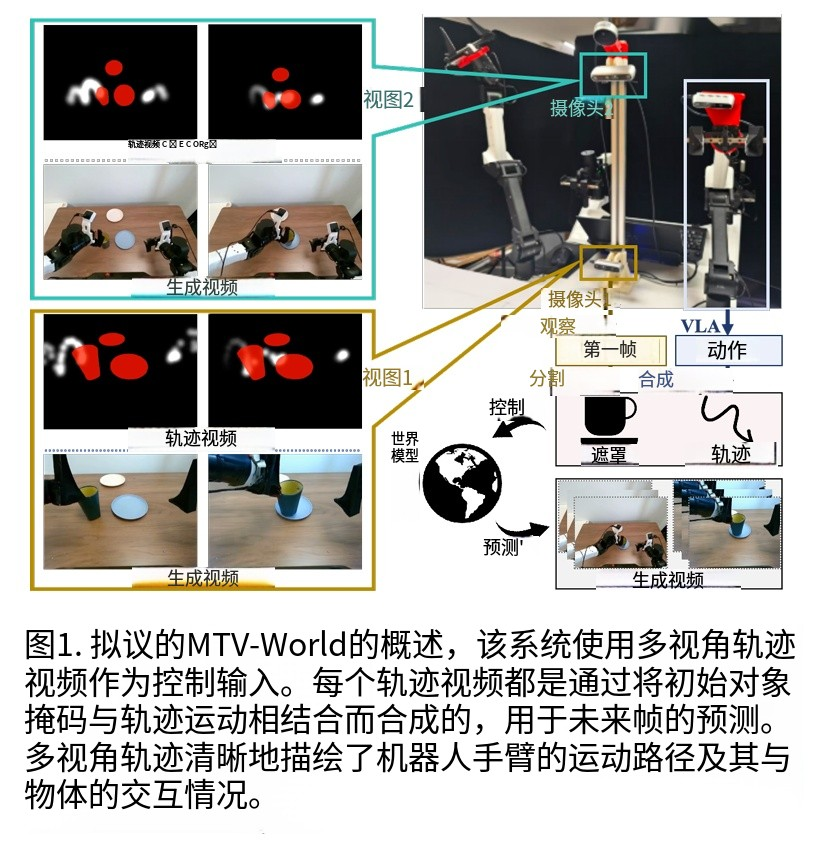
1. 轨迹表示:轨迹视频作为显式控制信号
为解决低层级动作转化失准问题,MTV-World 创新性地将控制信号转化为轨迹视频,核心流程包含三步:
-
首先通过机器人正运动学模型,将关节位置等原始动作序列映射为笛卡尔空间中的末端执行器位姿;
-
基于标定后的相机内参(焦距、主点)与外参(旋转矩阵、平移向量),将 3D 末端执行器位姿投影至 2D 图像像素坐标;
-
以发光点轨迹的形式渲染投影坐标,合成时序连续的轨迹视频,直观可视化运动演化过程,为模型提供显式的运动引导。
对于多视图场景,该流程针对每个相机视角独立执行,生成同步的多视图轨迹视频,为空间信息补偿奠定基础。
2. 对象表示:对象掩码作为前景先验
为精准建模机器人与操纵对象的交互关系,MTV-World 引入初始帧的对象掩码作为前景先验:
-
采用视觉语言模型(VLM)以视觉问答(VQA)方式生成图像中各对象的文本描述;
-
将文本描述输入参考视频对象分割(RVOS)模型,自动获取全视频序列的对象分割掩码;
-
提取初始帧的对象掩码作为前景先验,并将其复制到整个视频序列,为模型明确交互目标区域,强化机器人与对象的接触感知建模。
3. 模型架构:多视图融合保障空间一致性
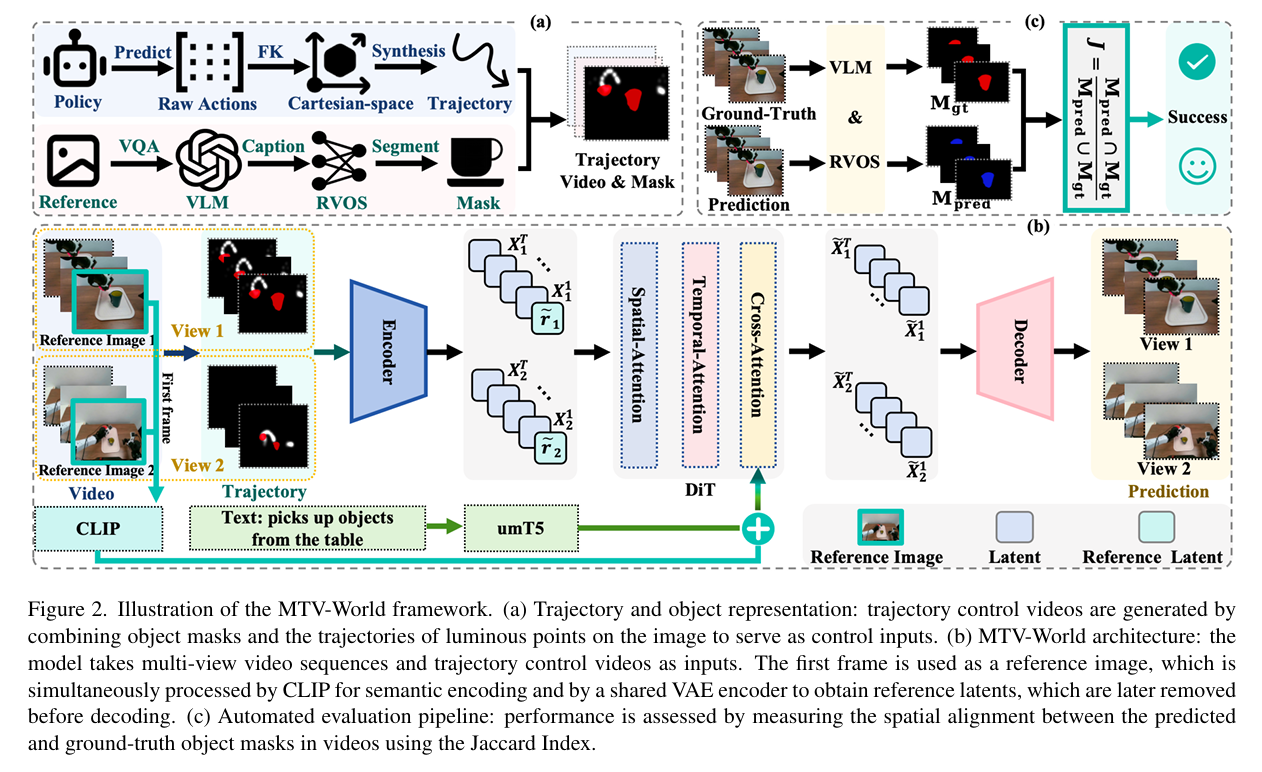
图 2:MTV-World 详细架构与自动评估流程
注:(a)轨迹与对象表示:轨迹视频融合对象掩码作为控制输入;(b)模型架构:多视图 latent 融合多模态先验,经 DiT 处理后解码生成预测视频;(c)自动评估:通过掩码匹配计算 Jaccard 指数,量化空间一致性)
MTV-World 的模型架构围绕多视图信息融合设计,确保运动与交互的跨视角一致性,具体如图 2(b)所示:
-
多模态编码:初始参考图像经 CLIP 编码器提取全局语义特征,文本指令经 umT5 编码器生成上下文令牌,两者拼接形成多模态场景先验,通过交叉注意力融入扩散 Transformer(DiT);
-
视图一致性约束:所有参考图像经共享 VAE 编码器编码后,通过轻量级适配器对齐维度,与对应视角的轨迹视频 latent 按时间维度拼接,形成多视图 latent 集合,为跨视角外观一致性提供约束;
-
扩散生成与解码:DiT 对多视图 latent 进行处理后,移除参考令牌并保留帧级输出,经 VAE 解码器还原为像素空间的多视图预测视频,确保语义对齐与视觉一致性。
4. 自动评估流水线:聚焦交互精准度量化
为解决传统评估指标的局限性,MTV-World 设计了面向运动精度与交互准确性的自动评估流水线(如图 2(c)所示):
-
采用与对象表示模块一致的 VLM+RVOS 流程,自动获取预测视频与真实视频的对象分割掩码;
-
将空间一致性量化为对象位置匹配问题,采用 Jaccard 指数(交并比)作为核心指标,计算帧级掩码匹配度后取平均,得到视频级一致性分数;
-
该流水线同时兼顾语义一致性与空间对齐性,通过对象掩码的精准匹配,直接反映机器人操纵与对象交互的准确性。
三、实验验证:MTV-World 的性能优势量化
基于自建双臂机器人操纵数据集(15 类任务、1492 段视频),MTV-World 通过基线对比、消融实验与可视化验证,充分证明了其技术优越性:
1. 数据集与实验设置
-
数据集涵盖 15 类双臂操纵任务(如堆叠积木、收集餐具、摇晃瓶子等),包含成功与失败案例(比例 8:2),支持标准训练(50% 数据)、有限数据训练(25% 数据)与零 - shot 泛化(未见过的视图、任务与对象)评估;
-
采用双相机拍摄配置(中间视角 View 1、顶部视角 View 2),获取近距离与全局场景观测;
-
评估指标包括感知质量(FID、FVD)与交互一致性(Jaccard 指数 J)。
2. 基线对比:全面超越现有模型
与采用 Policy2Vec latent 动作编码的 WorldEval 相比,MTV-World 在所有指标上均实现显著提升:
-
View 2 场景中,MTV-World(含对象掩码)的 Jaccard 指数达 42.0,远超 WorldEval 的 18.3;
-
感知质量同样优化明显,View 1 的 FID 降至 23.2、FVD 降至 39.1,体现了轨迹视频控制对运动建模的积极作用。
3. 消融实验:关键组件的有效性验证
通过系统性消融实验,明确各核心组件的技术价值:
-
多视图 vs 单视图:单视图模型在复杂 View 2 场景中 Jaccard 指数仅 44.3,低于多视图模型的 45.0,且多视图模型无需为不同视角单独训练,实现统一建模;
-
对象掩码:含对象掩码的模型在双视图中均取得更高 Jaccard 指数,证明前景先验对交互建模的增益;
-
零 - shot 能力:在未见过的视图、任务与对象场景中,MTV-World 仍保持 49.4(View 1)与 39.0(View 2)的 Jaccard 指数,展现出强劲的泛化能力;
-
数据效率:仅用 25% 训练数据的 MTV-World,性能接近 50% 数据训练的无掩码变体,验证了其数据高效性。
4. 可视化与动态性能分析
-
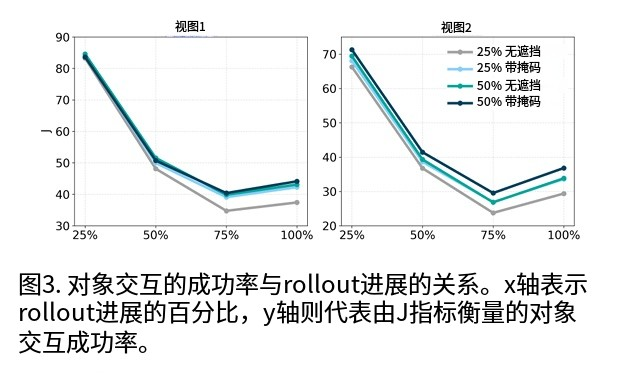
交互成功率演化:如图 3 所示,随着预测序列推进,Jaccard 指数逐渐下降(不确定性累积),在 75% 帧区间因对象遮挡出现明显下滑,但 MTV-World 仍能维持较高的交互一致性;
-
定性对比:如图 4 所示,在堆叠积木任务中,WorldEval 误将积木放置于目标旁,而 MTV-World 精准复现堆叠动作;在面包放置失败案例中,MTV-World 如实还原失败轨迹,与真实物理结果一致;
-
多视图轨迹可视化:如图 5 所示,双视图轨迹视频中的发光点形成连贯轨迹,清晰呈现机械臂抓取、摇晃、放置等动作,跨视角保持运动一致性。

四、结论与未来展望
MTV-World 通过多视图轨迹视频控制、对象掩码建模、跨视角融合架构与专用自动评估流水线的协同设计,有效解决了传统具身世界模型的运动精度与物理一致性问题。核心贡献可概括为:
-
一是提出轨迹视频作为显式控制信号,实现低层级动作到机器人运动的精准映射;
-
二是通过多视图框架弥补空间信息损失,强化物理交互一致性;
-
三是构建对象掩码引导的建模机制,明确机器人与对象的交互关系;
-
四是设计基于掩码匹配的自动评估流水线,实现交互精度的量化衡量。
未来研究可进一步拓展方向包括:优化长序列预测的不确定性抑制策略、融合更多模态信息(如深度图、力反馈)提升交互建模精度、拓展至更复杂的多机器人协作场景,持续提升模型的泛化能力与实用价值。
END

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)