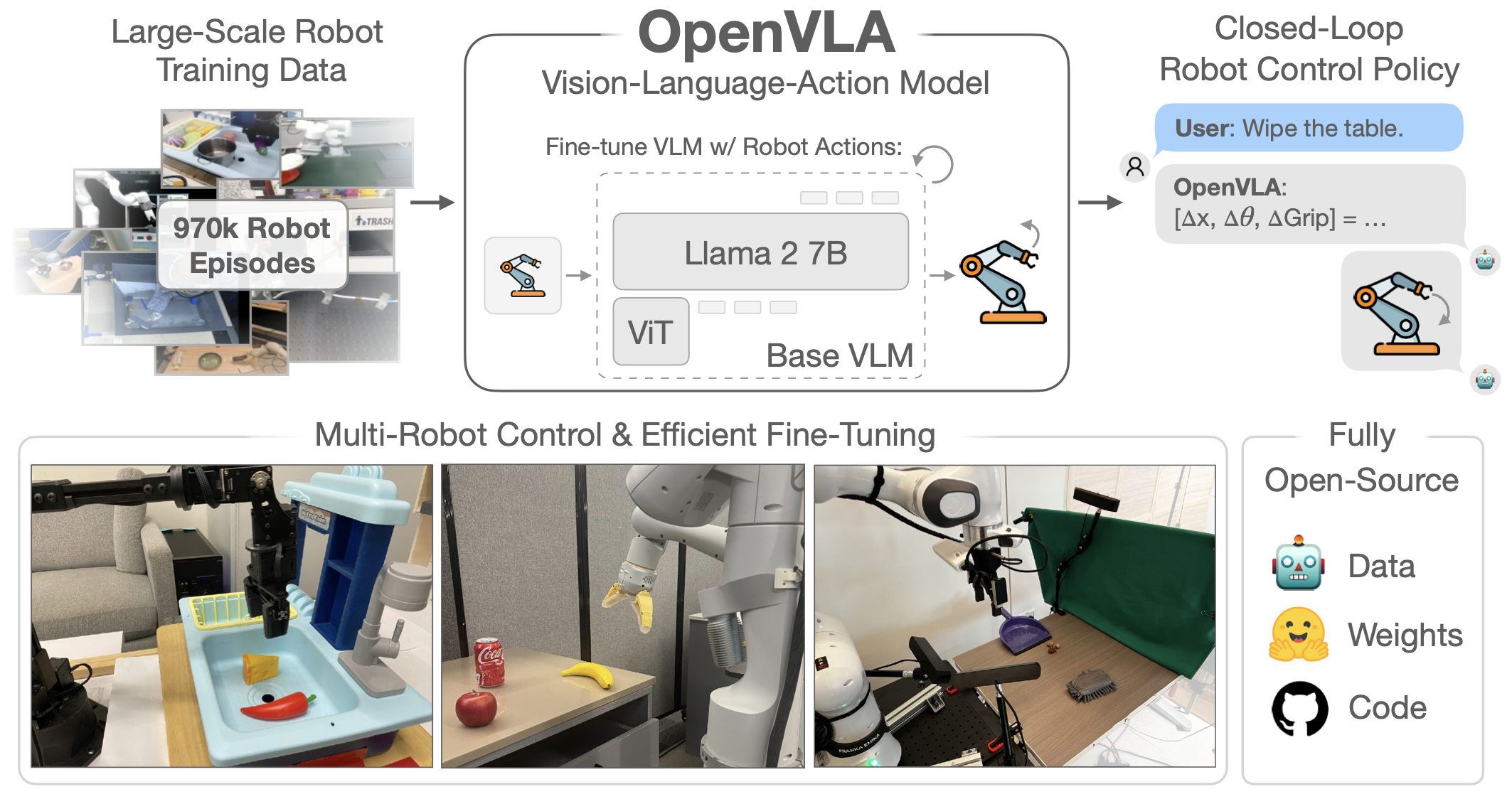
OpenVLA:开源视觉-语言-动作模型的突破性进展
OpenVLA的提出标志着机器人学向“开源基础模型”时代迈进了关键一步。性能突破:以70亿参数超越550亿参数的闭源模型,证明高效架构设计的价值。泛化能力:通过多样化数据和融合视觉编码器,实现跨机器人、跨场景的零样本控制。可访问性:LoRA微调与量化技术使模型能在消费级硬件上部署,降低应用门槛。开源生态:完整工具链推动社区协作,加速通用机器人政策的研究与应用。未来,随着更多研究者参与优化,Open
论文名称:OpenVLA: An Open-Source Vision-Language-Action Model
论文地址:https://arxiv.org/pdf/2406.09246
在机器人学领域,通用型操纵政策的发展一直面临着泛化能力有限、模型封闭性强以及适配新任务成本高昂等核心挑战。2024年,由斯坦福大学、加州大学伯克利分校、丰田研究院等机构联合研发的OpenVLA(Open-Source Vision-Language-Action Model)为解决这些问题提供了全新思路。作为首个开源的70亿参数视觉-语言-动作模型,OpenVLA在97万条真实机器人演示数据上训练而成,不仅刷新了通用机器人操纵政策的性能基准,更通过高效微调技术和全开源生态,为机器人学研究与应用开辟了新路径。
研究背景:通用机器人政策的困境与突破方向
传统机器人政策的局限性主要体现在三个方面:
- 泛化能力薄弱:即使在单一技能或语言指令上训练的政策,也难以应对场景干扰物、新型物体或未见过的任务指令。例如,在“拾取杯子”任务中表现优异的模型,可能因背景中出现其他物品而失效。
- 模型封闭性:现有视觉-语言-动作模型(VLAs)多为闭源,如RT-2-X(550亿参数),其架构细节、训练流程和数据混合方式不对外公开,阻碍了社区进一步研究与改进。
- 适配成本高昂:现有模型缺乏针对新机器人、环境或任务的高效微调方案,通常需要大规模计算资源,难以在消费级硬件上部署。
OpenVLA的提出正是基于对这些痛点的突破。研究团队发现,结合互联网规模的视觉-语言数据与多样化机器人演示数据预训练的模型,能够通过微调快速适配新任务,而非从零开始训练。这种思路借鉴了自然语言处理中“基础模型+微调”的范式,将其迁移到机器人控制领域。
OpenVLA的核心架构:融合视觉、语言与动作的统一框架
OpenVLA的架构设计围绕“复用现有基础模型能力”与“高效生成机器人动作”两大目标展开,核心组件包括视觉编码器、投影层和语言模型 backbone。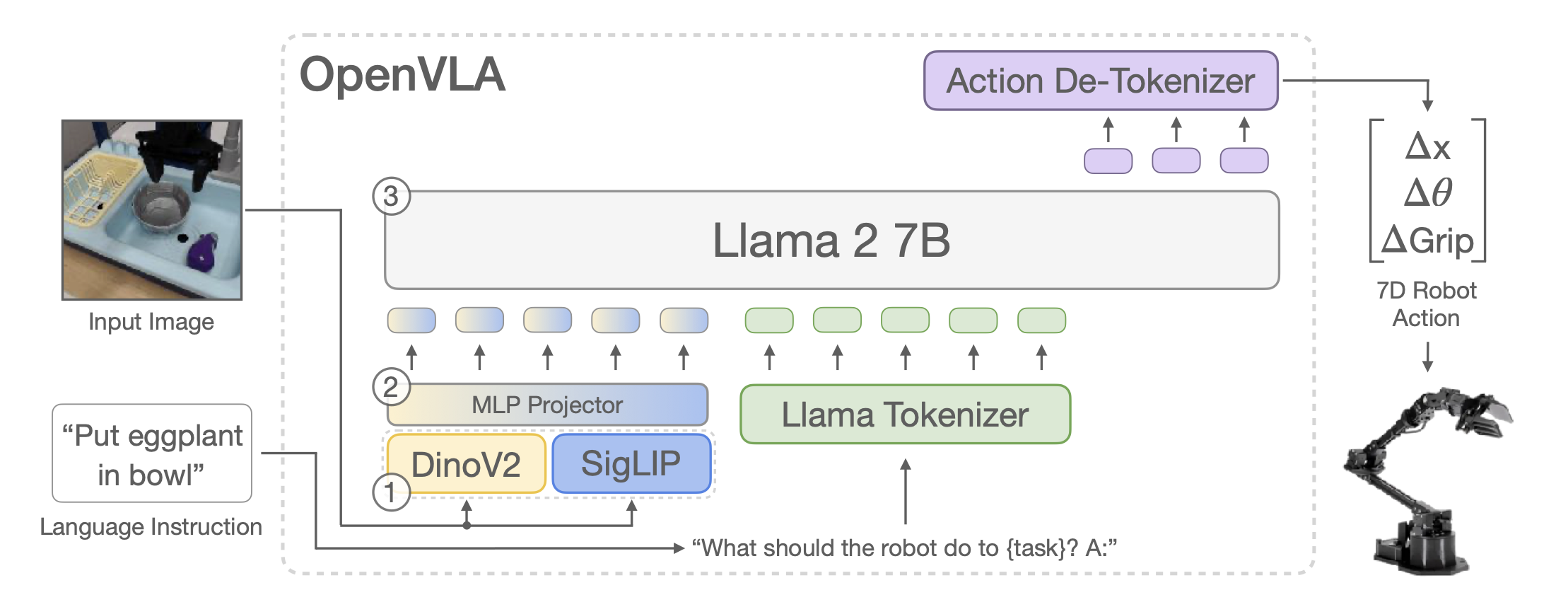
1. 视觉编码器:融合语义与空间特征
OpenVLA采用双视觉编码器融合策略,结合了:
- SigLIP:擅长捕捉高层语义信息,基于互联网图像-文本对训练,能理解物体类别、场景上下文等抽象概念。
- DINOv2:无监督训练的视觉Transformer,专注于细粒度空间特征,如物体位置、姿态和局部结构,对机器人精确操作至关重要。
两者的特征通过通道级联方式融合,既保留了语义理解能力,又增强了空间推理精度。这种设计在多物体场景中表现尤为突出,例如在“将茄子放入碗中”任务中,模型能同时识别“茄子”的类别(SigLIP)和其在桌面上的具体位置(DINOv2)。
2. 投影层:连接视觉与语言空间
视觉编码器输出的特征通过一个两层MLP投影层,被映射到语言模型的输入嵌入空间。这一步骤解决了视觉特征与语言模型语义空间的适配问题,确保图像信息能被语言模型有效理解。
3. 语言模型Backbone:Llama 2 7B
OpenVLA以Llama 2 7B大语言模型为基础,通过微调使其具备生成机器人动作的能力。为实现这一点,研究团队将连续的7维机器人动作(位置Δx、Δy、Δz,姿态Δθ, gripper控制等)离散化为256个 bins,每个bin对应Llama词汇表中被替换的低频 token。训练时,模型以“下一个token预测”为目标,直接生成离散动作序列,再通过解令牌器(Action De-Tokenizer)转换为连续控制信号。
这种设计的优势在于:
- 复用Llama 2的强大语言理解能力,支持自然语言指令直接驱动机器人。
- 借助成熟的Transformer训练基础设施(如FlashAttention、FSDP),实现大规模高效训练。
训练数据与流程:多样化与精细化的结合
OpenVLA的训练数据与流程设计直接影响其泛化能力,核心包括数据来源、筛选策略和训练细节。
1. 数据来源:Open X-Embodiment数据集
模型在Open X-Embodiment数据集的97万条轨迹上训练,该数据集整合了70多个机器人数据集,涵盖多种机器人形态(如WidowX机械臂、Google移动机器人)、任务类型(抓取、放置、清洁等)和场景(厨房、桌面等)。与RT-2-X使用的35万条数据相比,OpenVLA的数据量几乎翻倍,且通过以下策略优化:
- 筛选规则:仅保留包含第三人称相机和单臂末端执行器控制的数据,确保输入输出空间的一致性。
- 平衡混合:参考Octo模型的权重策略,对多样性高的数据集(如BridgeData V2)赋予更高权重,对重复度高的数据集降权,避免模型偏向特定任务。
- 异常处理:移除包含全零动作的轨迹(如演示数据中初始时刻的无效动作),防止模型学习“冻结”行为。
2. 训练细节
- 离散化策略:将每个动作维度按训练数据的1%-99%分位数均匀离散为256个bin,忽略极端异常值,提高离散精度。
- 训练目标:仅对动作token计算交叉熵损失,视觉与语言输入作为条件不参与损失计算。
- 超参数:学习率2e-5(与VLM预训练一致),训练27个epoch,远多于常规LLM的1-2个epoch,确保模型充分学习机器人控制模式。
实验结果:性能与泛化能力的全面突破
OpenVLA在多维度实验中展现出显著优势,涵盖零样本性能、微调效果、计算效率等方面。
1. 零样本跨机器人控制:超越闭源模型
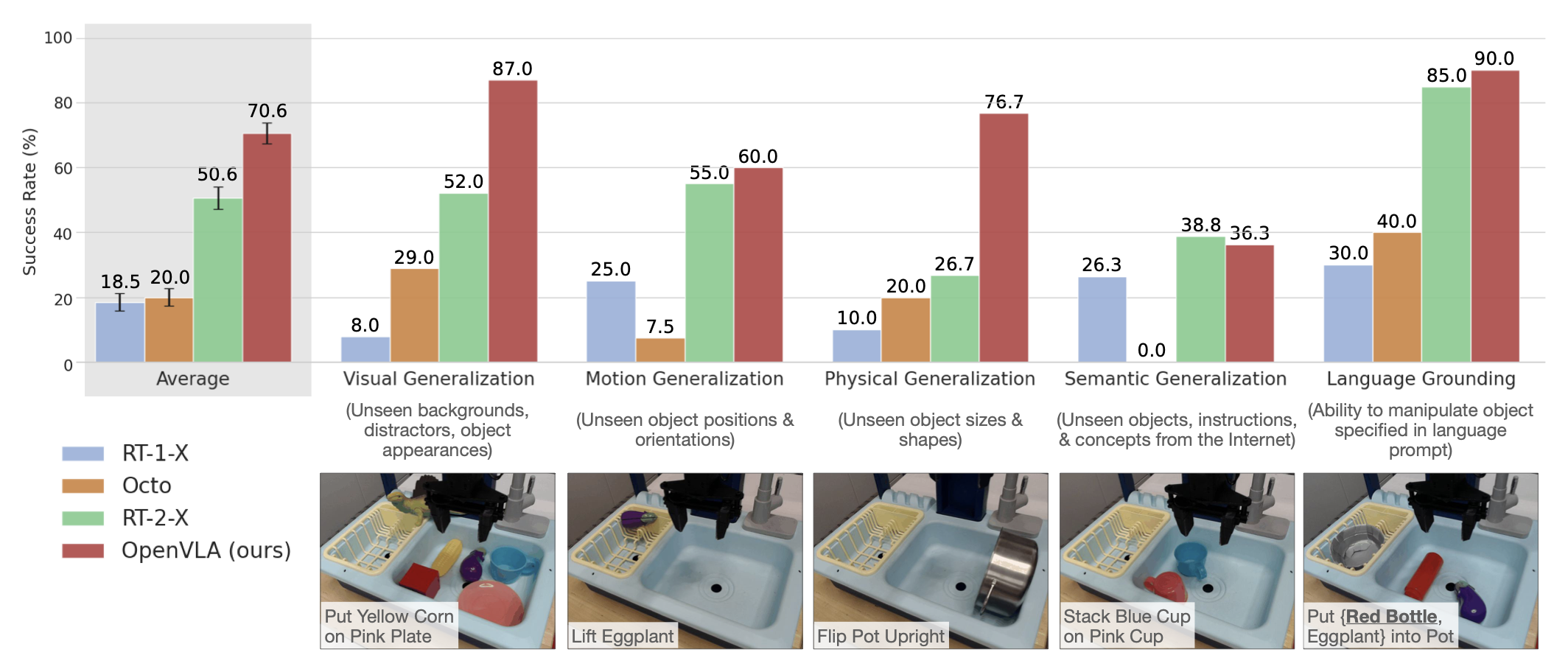
在WidowX机械臂和Google移动机器人上的29项任务中,OpenVLA以70亿参数实现了对550亿参数RT-2-X的超越:
- 绝对成功率提升16.5%:在视觉泛化(如 unseen 背景、干扰物)、物理泛化(如新型物体尺寸)等任务中表现尤为突出。例如,在“将胡萝卜放在盘子上”任务中,OpenVLA成功率达80%,
而RT-2-X为50%。 - 语言接地能力:在多物体场景中,能准确响应指令(如“拿起茄子而非红瓶子”),成功率比Octo高30%以上。
唯一的差距体现在语义泛化任务(如操作完全未见过的物体),RT-2-X因联合训练互联网数据而略占优势,但OpenVLA通过更大规模的机器人数据缩小了这一差距。
2. 微调适配新任务:高效且鲁棒
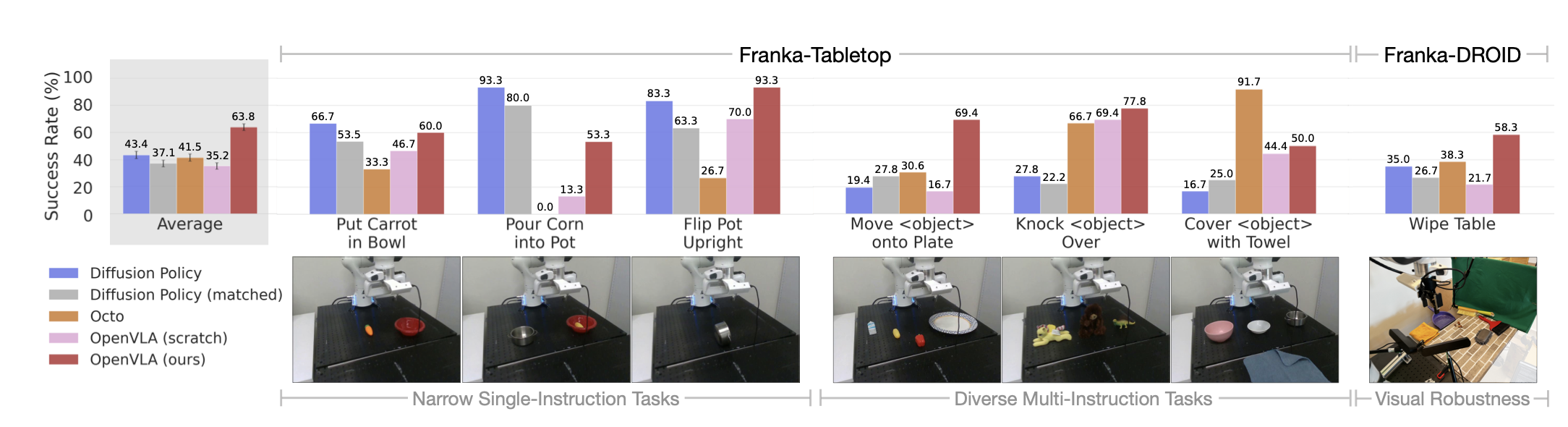
在Franka机械臂的7项新任务(如“擦桌子”“将玉米倒入锅中”)中,OpenVLA微调后表现如下:
- 超越从头训练方法:比Diffusion Policy(当前最优模仿学习方法)在多任务场景中提升20.4%,尤其在需要语言接地的任务(如“移动指定物体到盘子”)中优势明显。
- 数据效率:仅需10-150条演示数据即可实现高成功率,例如“翻转锅”任务在10条数据下成功率达100%。
3. 参数高效微调:消费级GPU可部署
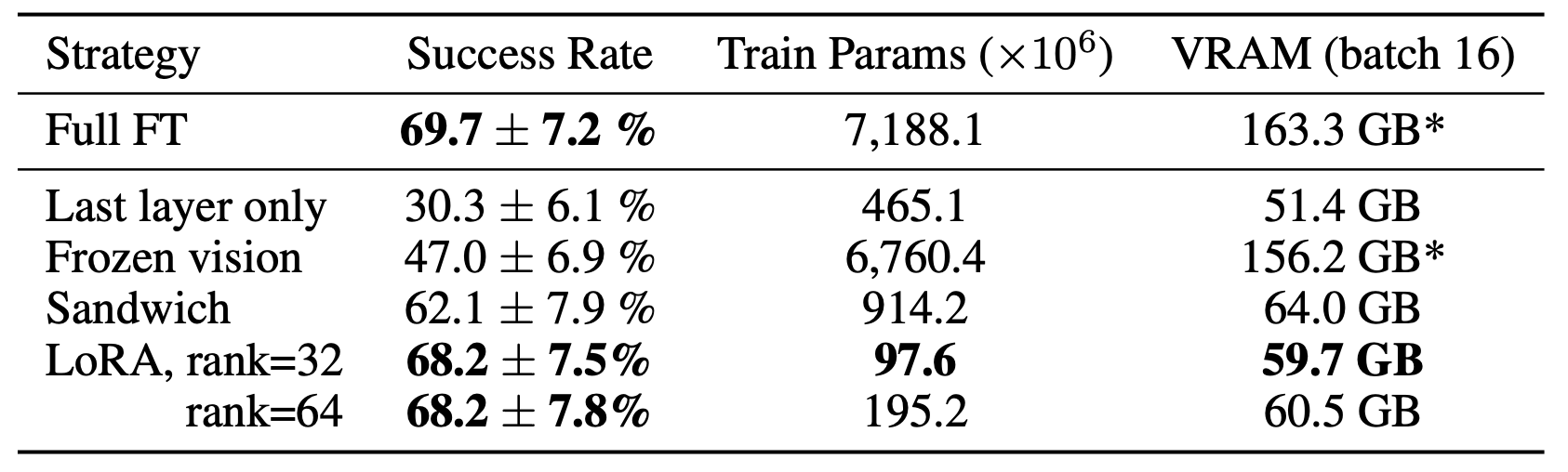
研究团队探索了多种微调策略,发现LoRA(Low-Rank Adaptation) 效果最优:
- 性能:微调1.4%的参数即可匹配全量微调效果,在“移动物体到盘子”任务中成功率达68.2%。
- 计算成本:单A100 GPU仅需10-15小时,显存占用从全量微调的163.3GB降至59.7GB,支持消费级GPU(如RTX 4090)部署。
4. 量化推理:内存高效且性能无损

通过模型量化技术,OpenVLA在推理阶段进一步优化:
- 4位量化:显存占用从16.8GB(bfloat16)降至7.0GB,成功率保持71.9%(与bfloat16基本一致)。
- 速度:在RTX 4090上可达6Hz,满足多数机器人实时控制需求。
开源生态与局限性
1. 全开源资源
OpenVLA开源了完整的工具链,包括:
- 模型权重(HuggingFace可下载)。
- 训练代码(支持多节点GPU集群,集成AMP、FlashAttention等技术)。
- 微调笔记本和远程推理服务器,方便研究者快速适配新机器人。
这一生态填补了开源通用机器人政策的空白,类比于Llama 2对NLP领域的推动,为社区提供了可扩展的基础。
2. 局限性与未来方向
尽管表现优异,OpenVLA仍存在改进空间:
- 输入模态单一:仅支持单张图像输入,未来可扩展至多相机、 proprioceptive(本体感受)数据。
- 推理速度:当前6Hz的控制频率难以满足高动态任务(如双臂操作),需探索动作分块(action chunking)或投机解码(speculative decoding)技术。
- 可靠性:部分任务成功率仍低于90%,需进一步优化数据质量和模型架构。
- 设计空间探索:基础VLM大小、联合训练(机器人数据+互联网数据)的影响等问题尚未深入研究。
总结与影响
OpenVLA的提出标志着机器人学向“开源基础模型”时代迈进了关键一步。其核心贡献包括:
- 性能突破:以70亿参数超越550亿参数的闭源模型,证明高效架构设计的价值。
- 泛化能力:通过多样化数据和融合视觉编码器,实现跨机器人、跨场景的零样本控制。
- 可访问性:LoRA微调与量化技术使模型能在消费级硬件上部署,降低应用门槛。
- 开源生态:完整工具链推动社区协作,加速通用机器人政策的研究与应用。
未来,随着更多研究者参与优化,OpenVLA有望成为机器人操纵领域的基准模型,推动家庭服务、工业自动化等场景中通用机器人的普及。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)