DayDreamer:物理机器人学习的世界模型
22年6月来自伯克利分校的论文“DayDreamer: World Models for Physical Robot Learning”。
为了解决复杂环境中的任务,机器人需要从经验中学习。深度强化学习是机器人学习的常用方法,但需要大量的反复试验才能学习,这限制了它在物理世界中的部署。因此,机器人学习的许多进步都依赖于模拟器。另一方面,模拟器内部的学习无法捕捉现实世界的复杂性,容易出现模拟器不准确的情况,并且由此产生的行为无法适应世界的变化。Dreamer 算法最近通过在学习的世界模型中进行规划,从少量交互中学习,表现出巨大的潜力,在视频游戏中的表现优于纯强化学习。学习世界模型来预测潜在行动的结果,可以在想象中进行规划,从而减少在现实环境中所需的反复试验量。然而,Dreamer 是否能促进物理机器人更快地学习尚不清楚。
本文将 Dreamer 应用于 4 个机器人,让它们在线学习,并直接在现实世界中学习,而无需任何模拟器。 Dreamer 训练四足机器人在 1 小时内从头开始滚动、站立和行走,无需重置。然后推动机器人,发现 Dreamer 在 10 分钟内适应了干扰或快速翻身并重新站起来。在两个不同的机械臂上,Dreamer 学习直接从相机图像和稀疏奖励中拾取和放置多个物体,接近人类的表现。在轮式机器人上,Dreamer 学习仅从相机图像导航到目标位置,自动解决机器人方向的模糊性。在所有实验中使用相同的超参,Dreamer 能够在现实世界中进行在线学习,这建立了强大的基线。
本文利用 Dreamer 世界模型的最新进展,在最直接、最基本的问题设置中训练各种机器人:在现实世界中进行在线强化学习,无需模拟器或演示。如图所示:为了研究 Dreamer 对样本高效机器人学习的适用性,应用该算法在现实世界中从头开始学习 4 个机器人的机器人运动、操纵和导航任务,无需模拟器。这些任务评估了各种各样的挑战,包括连续和离散动作、密集和稀疏奖励、本体感受和摄像头输入,以及多种输入模态的传感器融合。在所有实验中使用相同的超参成功学习,Dreamer 为现实世界的机器人学习建立了强大的基础。

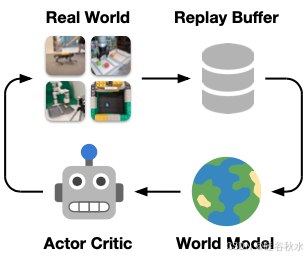
目标是直接在现实世界中突破机器人学习的极限,并提供一个强大的平台,以便未来的工作能够发挥世界模型对机器人学习的优势。如图所示:Dreamer 遵循一个简单的流水线,在没有模拟器的情况下在机器人硬件上进行在线学习。当前学习的策略,收集机器人的经验。此经验被添加到重放缓冲区。世界模型通过监督学习在重放的离策略(off-policy)序列上进行训练。A-C算法从世界模型潜空间中的想象展开中优化神经网络策略。并行化数据收集和神经网络学习,以便学习步可以在机器人移动时继续进行,并实现低延迟动作计算。
世界模型是一个深度神经网络,可以学习预测环境动态。由于感官输入可以是大型图像,因此预测的是未来的表示,而不是未来的输入。这减少了累积错误,并实现了大批量的大规模并行训练。因此,世界模型可以被认为是机器人自主学习的环境快速模拟器,从一张白纸开始,并在探索现实世界时不断改进其模型。世界模型基于递归状态空间模型 (RSSM;Hafner,2018)。
物理机器人通常配备多种不同模态的传感器,例如本体感受关节读数、力传感器以及 RGB 和深度相机图像等高维输入。编码器网络将所有传感输入 xt 融合到随机表示 zt 中。动力学模型学习使用其循环状态 ht 来预测随机表示序列。解码器重建传感输入,为学习表示提供丰富的信号,并允许人类检查模型预测,但在从潜变量展开中学习行为时不需要解码器。在实验中,机器人必须与现实世界互动来发现任务奖励,奖励网络会学习预测这些奖励。使用人工指定的奖励作为解码传感输入的函数也是可能的。通过随机反向传播联合优化世界模型的所有组件(Kingma & Welling,2013;Rezende,2014)。
虽然世界模型代表与任务无关的动态知识,但A-C算法会学习特定于当前任务的行为。从世界模型的潜空间中预测的展开中学习行为,无需解码观察结果。这使得在单个 GPU 典型 16K 批量大小进行大规模并行的行为学习,成为可能,类似于专门的现代模拟器(Makoviychuk,2021)。
如图所示神经网络训练。利用 Dreamer 算法(Hafner,2019;2020)在现实世界中实现机器人的快速学习。Dreamer 由两个神经网络组件组成。左图:世界模型遵循深度卡尔曼滤波器的结构,该滤波器根据从重放缓冲区中提取的子序列进行训练。编码器将所有传感模态融合成离散代码。解码器从代码中重建输入,提供丰富的学习信号并允许人工检查模型预测。循环状态空间模型 (RSSM) 经过训练可根据给定动作预测未来代码,而无需观察中间输入。右图:世界模型使用大批量从紧凑潜空间中的想象展开,实现大规模并行策略优化,而无需重建传感输入。Dreamer 根据想象的展开和学习的奖励函数,训练策略网络和价值网络。
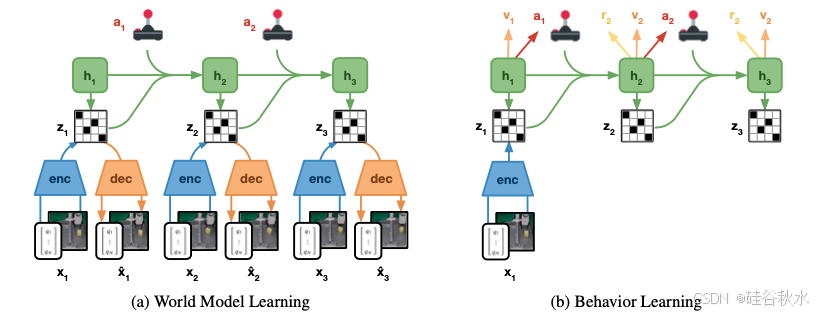
actor网络的作用,是学习每个潜模型状态 st 的一个成功动作分布,最大化未来预测任务奖励的总和。critic网络通过时间差异(TD)学习来学习预测未来任务奖励的总和(Sutton & Barto,2018)。
给定模型状态的预测轨迹,critic被训练来回归轨迹的回报。一个简单的选择是将回报计算为 N 个中间奖励的总和加上critic 自己对下一个状态的预测。
虽然critic网络被训练来回归 λ-回报,但actor网络被训练来最大化它们。不同的梯度估计器可用于计算用于优化actor的策略梯度,例如 Reinforce(Williams,1992)和重新参数化技巧(Kingma & Welling,2013;Rezende 等人,2014),它直接通过可微分动态网络反向传播回报梯度(Henaff,2019)。
按照 (Hafner 2020) 的做法,为连续控制任务选择重新参数化梯度,为离散动作任务选择强化梯度。除了最大化回报之外,actor还受到激励以保持高熵,防止为一个确定性策略崩溃,并在整个训练过程中保持一定程度的探索。
用 Adam 优化器 (Kingma & Ba, 2014) 优化A-C。为了计算 λ 回报,用常见的缓慢更新 critic 网络副本 (Mnih et al., 2015; Lillicrap et al., 2015)。A-C的梯度不会影响世界模型,因为这会导致模型预测不正确且过于乐观。与 (Hafner et al. 2020) 相比,没有训练频率超参,因为解耦学习器在数据收集的同时优化神经网络,没有速率限制。
以 DreamerV2(Hafner,2020)的官方实现为基础,该实现可处理多种传感模态。开发了一种异步actor和学习者设置,这在控制率较高的环境中必不可少,例如四足机器人,并且还可以加速较慢环境(例如机械臂)的学习。在所有实验中使用相同的超参,从而能够将其部署到不同的机器人具身中。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 28
28 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)