【论文蒸馏-世界模型】Understanding World or Predicting Future? A Comprehensive Survey of World Models
对世界模型总数的整理,主要以理解世界,预测未来以及应用三个方面对世界模型研究进行分类与总结
·
1. 背景
- 科学界长期以来一直渴望开发一个统一的模型,以复制其对世界的基本动态,从而实现通用人工智能。其主要强调两个主要功能:
- 构建内部表示以理解世界的机制 - 理解现在(概括与执行)
- 预测未来状态以模拟和指导决策 - 预测未来(下一个场景)
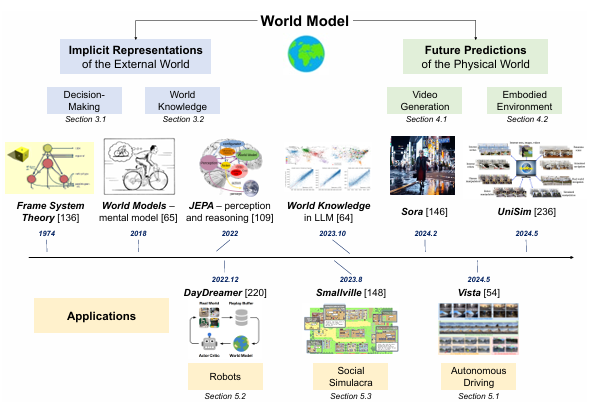
- 世界模型的潜在应用涵盖广泛的领域,每个领域对理解和预测能力都有不同的要求
- 自动驾驶 - 实时感知道路状况并准确预测其演变,特别注重即时环境觉察和复杂趋势预测
- 机器人 - 导航、目标检测和规划
- 虚拟社交系统模拟 - 预测更抽象的动态,如社交互动和人类决策
2. 历史发展
- 1971 “心理模型”,该原理提出人类将外部世界抽象为简单的元素及其相互关系以感知它。核心观点在于,对世界的描述通常涉及构建一个抽象的表示,而这个抽象的表示不需要详细的描述。
- 2018 引入人工智能领域
- 2022 Yann LeCun介绍联合嵌入预测架构 (JEPA, Joint Embedding Predictive Architecture)
- 核心是通过联合嵌入和预测来学习世界抽象表示,将输入数据映射到高维空间,并在高维空间中预测未来状态或缺失部分(如视频下一帧)。
- 自监督但并不用自回归方式,而是借助潜变量处理不确定性模拟未来。不是代替Transformer,而是补充其在物理世界的预测和规划上的不足。
- 结合双系统概念,反映快慢思维,对应是人的本能快速反应和长期性的计划。快 - 编码器迅速从输入数据提取高维特征;慢 - 层次化预测
- 2024 Sora - 输入现实世界的视觉数据,并输出预测未来世界演变的视频帧,并表现出卓越的物理建模能力
根据理解现在与预测未来两个方向,对世界模型的研究基本分为
- 外部世界的隐性表征 - 如何用潜变量来表征世界
- 外部世界的未来预测 - 最开始主要使用视觉,最近开始转向交互
- 世界模型的应用 - 自动驾驶、机器人技术和社会模拟
3. 外部世界的隐性表征
3.1 决策
-
基于模型强化学习
- 世界模型由 状态转换动态 和 奖励函数 组成,奖励一般自定义,所以学的主要是转换动态
- 学习任务可以转变为监督学习任务,标签从真实交互轨迹中得到,称为模拟数据
- 具体的策略方式还可以使用蒙特卡洛树(搜索树)来进行选择
-
以大语言模型为主干
- 因为LLM已经有了强大推理能力
- 具体的使用包括直接用其生成动作,以及模块化整合LLM两种
3.2 知识学习
-
全局物理世界知识
- 空间知识 - 位置、方向…
- 时间知识 - 顺序、持续时间…
- 物理常识 - 重力、运动…
-
局部物理世界知识
- 基于认知地图(对周围环境的一个表征)
-
人类社会知识
- 类似心智理论,解释个体如何推断周围其他人的心理状态
- 具体检测是通过评估模型在心智任务中的表现,评估其类人行为是否反映对社会规则和隐性知识的真正理解
4. 外部世界的未来预测
4.1 视频生成
-
Sora
- 利用强大的神经网络架构来处理多模态输入并生成视觉连贯的模拟
- 在成为世界模型上的局限性
- 因果推理: 交互受到限制,不能主动干预
- 物理上无法完全一致
-
发展方向
- 延长视频长度
- 在prompt中添加其他模态
- 增强交互
- 多样化环境(自然、自动驾驶、游戏)
4.2 作为具身环境的世界模型
- 室内 - 受控制的结构化场景
- 室外 - 规模更大,通常需要上下文察觉导航法
- 动态 - 提高模型在复杂、不可预测的现实世界情况下的适应性和泛化能力
5. 世界模型的应用
5.1 自动驾驶
- 世界模型被定义为以多模态数据作为输入,并以车辆感知数据的形式不断输出未来世界状态的模型
- 现代自动驾驶流程可以分为四个主要部分:感知、预测、规划和控制,感知和预测阶段也代表为车辆学习世界隐式表征的过程
5.2 机器人
- 师姐模型能够直接预测世界的未来状态,而不仅仅是抽象的表示,使机器人能够预测可能的环境变化并主动做出反应,使得机器人直接与现实世界环境交互并从中学习
5.3 社会拟像
- 一种反映现实世界社会计算系统的世界模型
6. 开放问题与发展方向
-
物理规律与反事实仿真
- diffusion等当前的视频生成模型实现视觉现实感,但是理解光学、流体动力学或磁学的任务中基本失败
- 考虑明确嵌入物理学的混合方法
- 考虑整合明确的模拟器,或者强调物理先验,可能做到能推广到未见反事实场景
-
增加社会维度
- 模拟物理元素还不足够,因为应该考虑人在社会中的互动
- 人类行为模式和认知过程的理论可以为代理工作流程的设计提供参考,从而增强LLM的人类行为模拟能力
-
利用具身智能对齐模拟与现实
- 自我强化循环,在与环境的交互中,既训练了具身智能的决策,又训练了世界模型对场景的建模
-
仿真高效性
- 自回归、大模型带来了高计算高延迟的开销
- 考虑小模型与其他架构的应用
-
伦理与安全性考量
- 数据隐私 - 提高其生命周期透明度
- 模拟不安全场景 - 保护其的使用
- 问责 - 传播不实信息带来的问题
-
构建评价基准
- 视频生成为核心的世界仿真
- 空间物理推理
- 具身决策

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)