强化学习训练方法:超参设置技巧-Polaris的强化学习训练配方
4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦Polaris的成功的秘籍就是:训练数据及超参数设置都要围绕待训练的模型来进行设置。
来源1:Polaris的强化学习训练配方:4B小模型700步RL训练,数学推理逼近235B
4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦
Polaris的成功的秘籍就是:训练数据及超参数设置都要围绕待训练的模型来进行设置。
总结:
- 提出对数据难度的分析与调整方法,确保训练数据难度分布适中且略偏难题,采用“镜像J型”分布。
- 引入基于生成结果多样性的采样温度初始化和逐步调增,有效提升训练多样性和探索能力。
- 在推理阶段支持“训练短生成长”的CoT技术,通过推理长度外推减少训练资源需求。
- 多阶段训练设计提升探索效率,讨论了训练初期响应长度缩短风险及更保守的训练策略建议。
1.1 训练数据构造
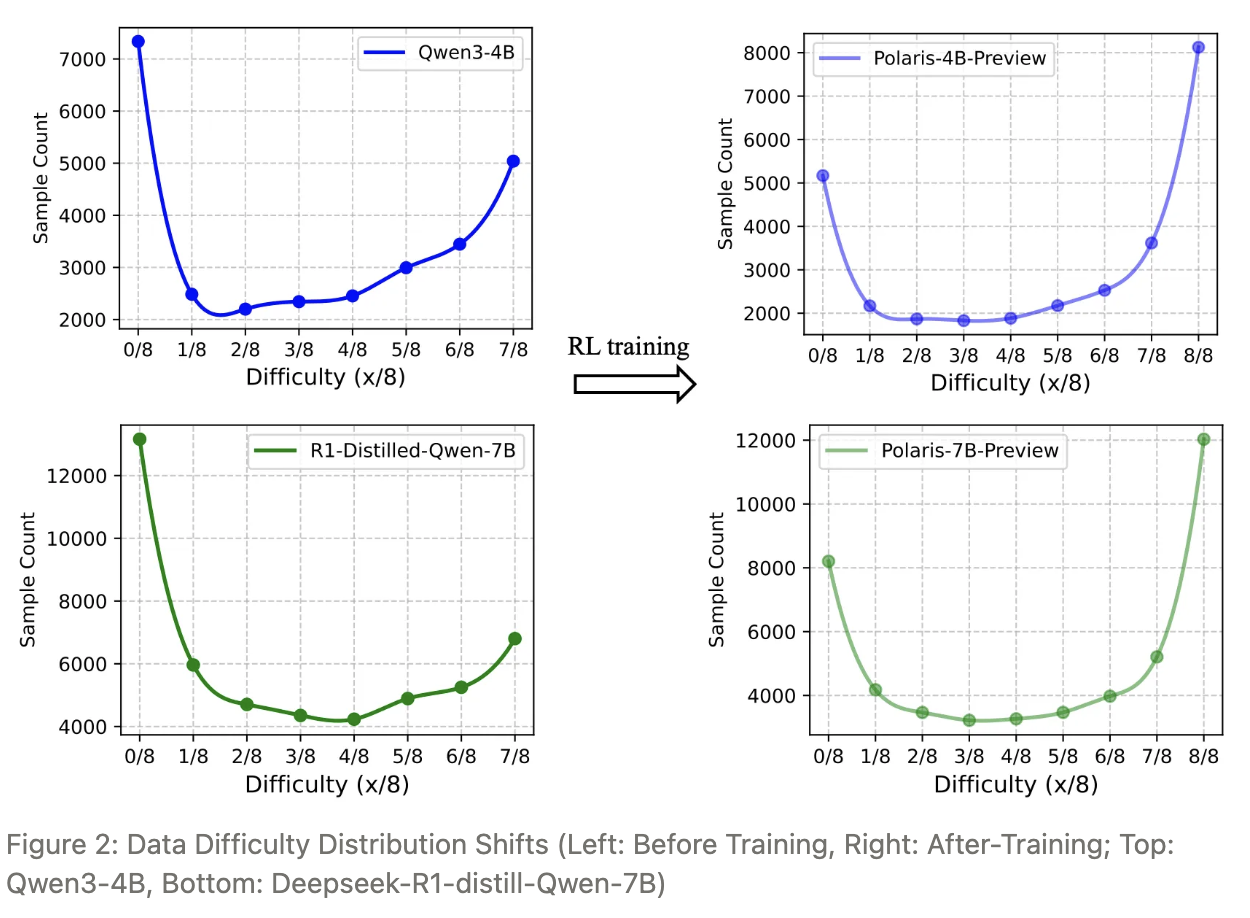
Polaris团队发现,对于同一份数据,不同能力的基模型展现出的难度分布呈现出镜像化的特征。
对于DeepScaleR-40K训练集中的每个样本,研究人员使用R1-Distill-Qwen-1.5B/7B两个模型回答分别推理了8次,再统计其中正确次数,以此衡量每个样本的难度水平。
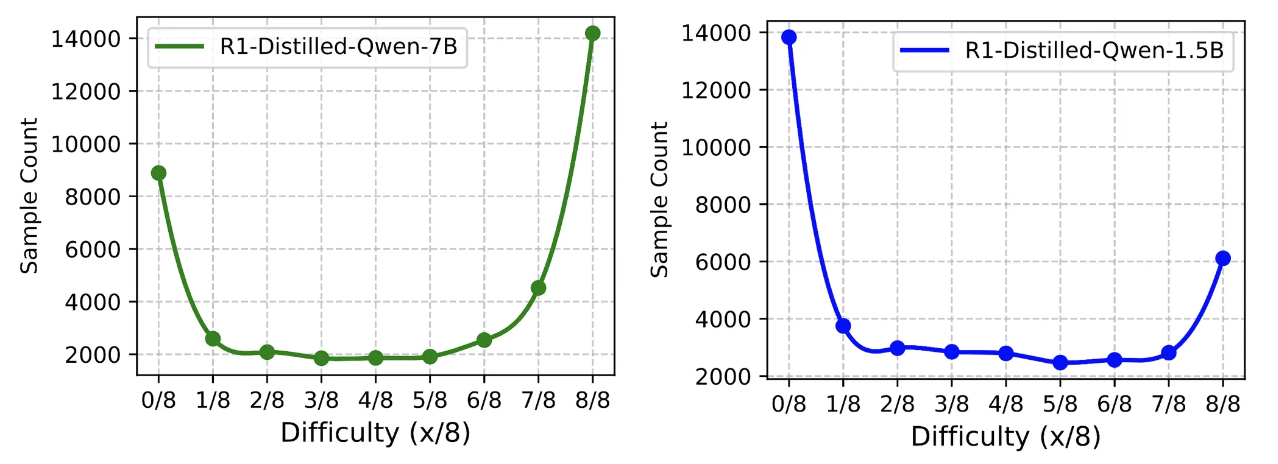
实验结果显示,大多数样本位于两端(8/8正确解答或0/8正确解答),意味着该数据集虽然对1.5B模型具有挑战性,却不足以有效训练7B模型。
1.1.1 依赖难度均衡分布
完整数据集(40K 样本): 数据呈原始 J 形分布,绝大多数为“简单样本”(8/8 解法全部正确)。
剔除满分样本(26K 样本): 移除所有 8/8 全对的样本后,分布被“翻转”为镜像 J 形。
激进过滤(19K 样本): 进一步筛掉通过率 >4/8 的所有题目,仅保留最难的问题,最终得到近似均匀或右偏的分布。
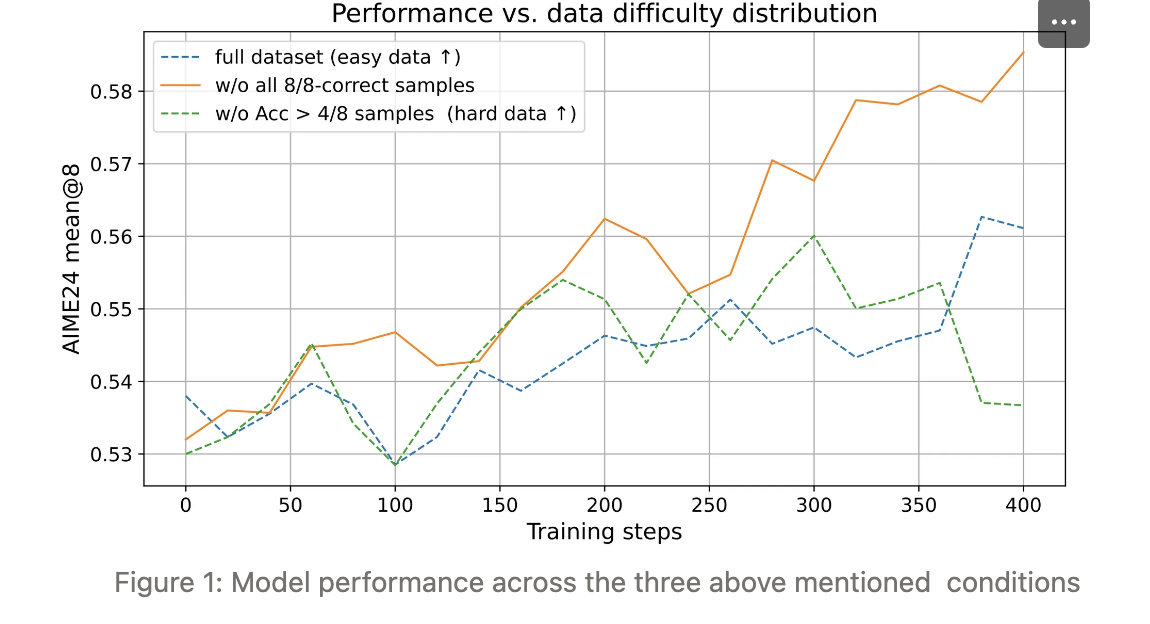
- 最优的 RL 训练必须依赖难度均衡的分布——既能提供足够的挑战性以驱动学习,又避免题目过易或过难造成的阻碍。过度偏向简单题或难题的分布都会使得无法产生优势的样本在每个batch中占有过大的比例
POLARIS 数据策划策略(中文精炼版)
受前述实验启发,POLARIS 方案通过「镜像 J 形难度分布」来精选高质量公开数据集,主要来源包括:
- DeepScaleR-40K:约 4 万道数学竞赛题(AIME、AMC 等)。
- AReaL-boba-106k:10 万余道涵盖数论、几何、组合的多元难题。
三阶段工程流程
- 离线难度评估
用当前待训模型为每道题生成 8 条 rollout,以通过率作为对该模型而言的“动态难度”指标。- 目标过滤
为构建镜像 J 形分布,剔除所有 8 次全对的“过易”样本。- 数据集组装与再校准
DeepSeek-R1-Distill-Qwen-7B:在 DeepScaleR 与 AReaL 上过滤后得 53K(26K + 27K)。
Qwen3-4B:在上述 53K 上再做一轮过滤,保留 30K 难度匹配样本。通过这种“模型专属”的难度校准,POLARIS 确保任何模型在训练全程都能持续获得恰到好处的挑战。
1.1.2 数据动态更新策略
Polaris对开源数据DeepScale-40K和AReaL-boba-106k进行了筛选,剔除所有8/8正确的样本,最终形成了53K的初始化数据集。
尽管已经得到了一个好的初始化数据,但它并不是训练数据的“最终版本”。
在强化学习训练过程中,随着模型对训练样本的“掌握率”提高,难题也会变成简单题。
为此,研究团队在训练中引入了数据动态更新策略。训练过程中,每个样本的通过率会随着reward计算而实时更新。在每个训练阶段结束时,准确率过高的样本将被删除。
训练期动态掉易机制
随着 RL 训练推进,模型能力增强,原本困难的题目逐渐变易。因此,我们在训练过程中实时重新评估难度并剔除新生成的易题。下图展示了训练期内数据难度分布的动态迁移(示意图略)。
我们观察到:
训练过程中,样本难度分布会自然从「镜像 J 形」(Ⴑ)逐渐演变为普通 J 形。这一变化印证了我们以 Ⴑ 形作为起点的合理性——它允许模型在能力提升后平滑过渡到最终的 J 形。
由于数据难度实时变化,始终使用初始数据集显然次优。为维持理想分布,我们引入动态难度更新机制:
- 在 rollout 规模 n=8 的训练中,每完成一次奖励计算,立刻用最新结果刷新该样本的准确率(初始难度由离线过滤结果给出)。
- 每个训练阶段结束时,删除所有准确率 >0.9 的样本,从而把分布拉回初始 Ⴑ 形,防止继续滑向 J 形。
通过持续剔除已掌握样本,模型始终面对恰到好处的挑战,避免学习信号因「过度简单」而衰减。
1.2 基于多样性的 Rollout 采样(中文要点)
在 GRPO 训练中,“多样性” 是产生有效正负轨迹对比的核心。高多样性能让一次 rollout 里同时出现正确与错误答案,从而放大学习信号;也能帮助模型探索更广的推理路径,防止过早陷入局部模式。
关键超参数:top-p、top-k 和 temperature。
开源项目通常把 top-p=1.0、top-k=-1 固定到最大,只调温度。
1.2.1 采样温度动态调整而不是不变
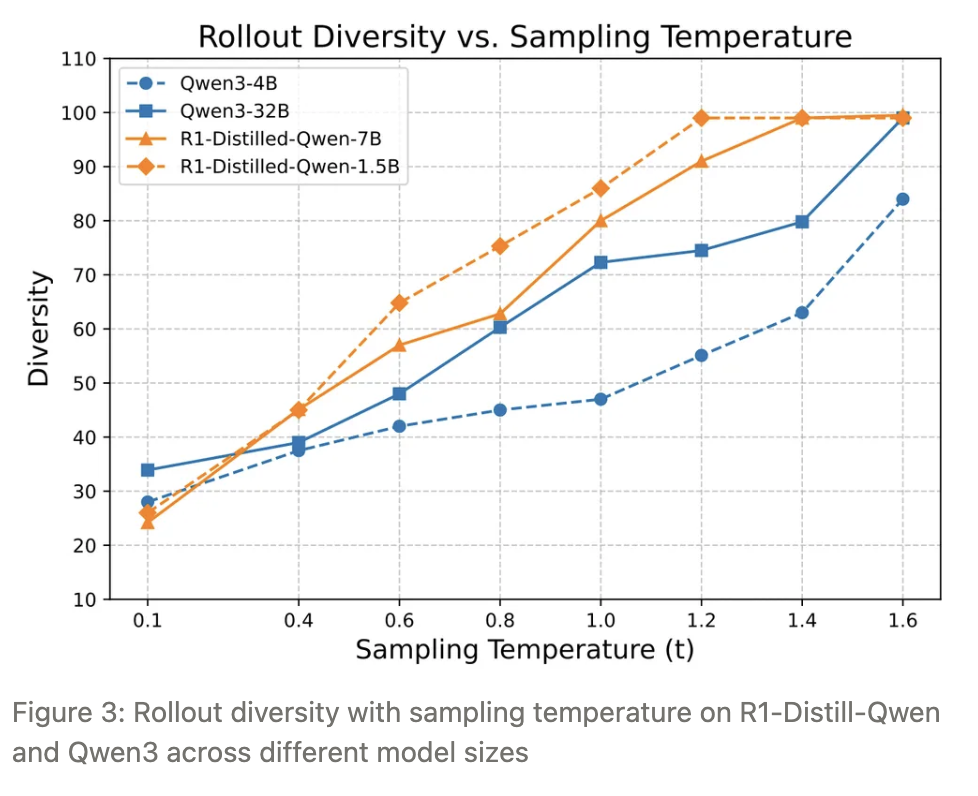
使用distinct N-gram(N=4)指标衡量推理轨迹的词汇多样性:
越接近1表示产出多样性越高;越接近0则表示重复度高,多样性低。

- 温度越高 → 多样性越高(用 4-gram distinct 度量,越接近 1 越多样)。
- 不同基模型在同一温度下的多样性差异明显;如 Qwen3 天生分布更集中,需要更高温度才能匹配他人。
因此,建议按基模型的实际多样性动态调整温度,而不是死跟官方默认值(0.6 或 1.0)。
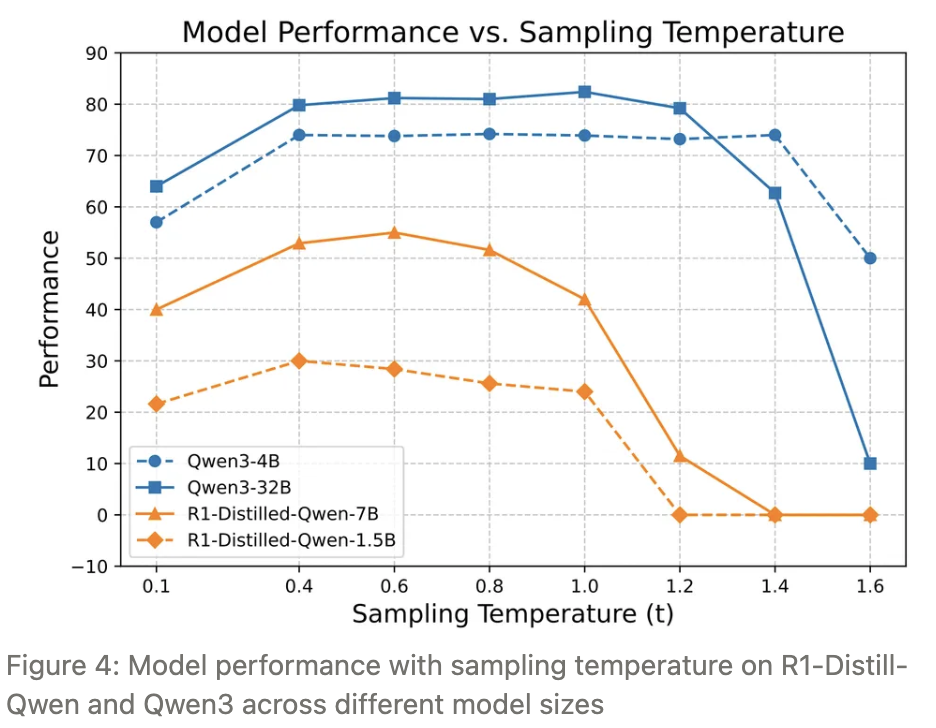
1.2.2 采样温度vs性能曲线虽都是先升后降,不同模型需单独校准适宜温度区间
性能 vs. 采样温度:在追求轨迹多样性的同时,也必须保证模型性能。
- 实验显示,当温度从 0 逐步升高时,所有受测模型的平均准确率均呈现「先升后降」的倒 U 形曲线。
- 此外,不同模型在「峰值区间」的宽度差异显著,说明并不存在放之四海而皆准的温度设置。
因此,要想在多样性与稳定性之间取得最佳平衡,必须为每个模型单独做温度校准。
1.2.3 在可控探索区间选择初始化温度,显著优于传统 0.6/1.0 设置
温度区间定义(Temperature Zone)
根据实验结果,我们将采样温度划分为三个经验区间:
- 稳健生成区间(RGZ)
在此区间内,模型性能既最优又稳定,无明显波动。日常推理/解码建议直接选用 RGZ 内的温度。- 可控探索区间(CEZ)
温度落在 CEZ 时,性能相比 RGZ 略降,但降幅在可接受范围;同时 rollout 多样性显著提升,适合用作 RL 训练采样。- 性能崩塌区间(PCZ)
超过 CEZ 后进入 PCZ,模型开始输出大量噪声 token,性能急剧下降,无论训练还是解码都不适用。
以 Qwen3-4B 在 AIME24 为例:
- RGZ:0.6–1.4(性能最高且平稳)
- CEZ:1.4–1.55(性能略降、多样性上升)
- PCZ:≥1.55(性能崩塌)
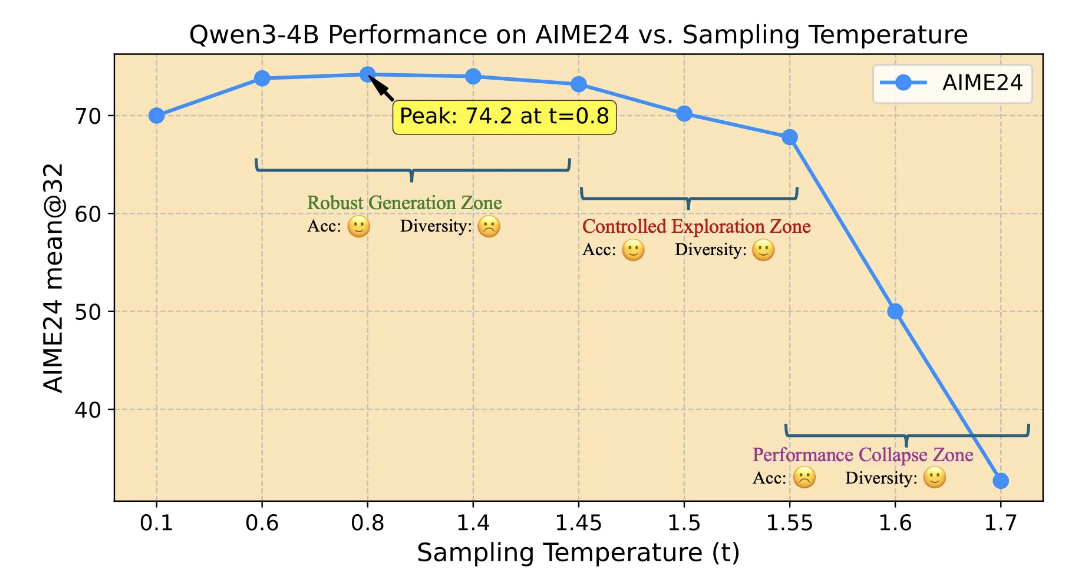
探测实验表明:
默认的 0.6/1.0 过于确定,导致多样性不足,RL 性能受限。
在 CEZ 起始点初始化温度 既能保持可接受的性能,又能最大化轨迹多样性。
实验对比证实,采用 CEZ 温度启动 RL 训练,显著优于传统 0.6/1.0 设置。
| 模型 | 建议初始温度(CEZ 起始) |
|---|---|
| Qwen3-4B | 1.4 |
| Deepseek-R1-Distill-Qwen-7B | 0.7 |
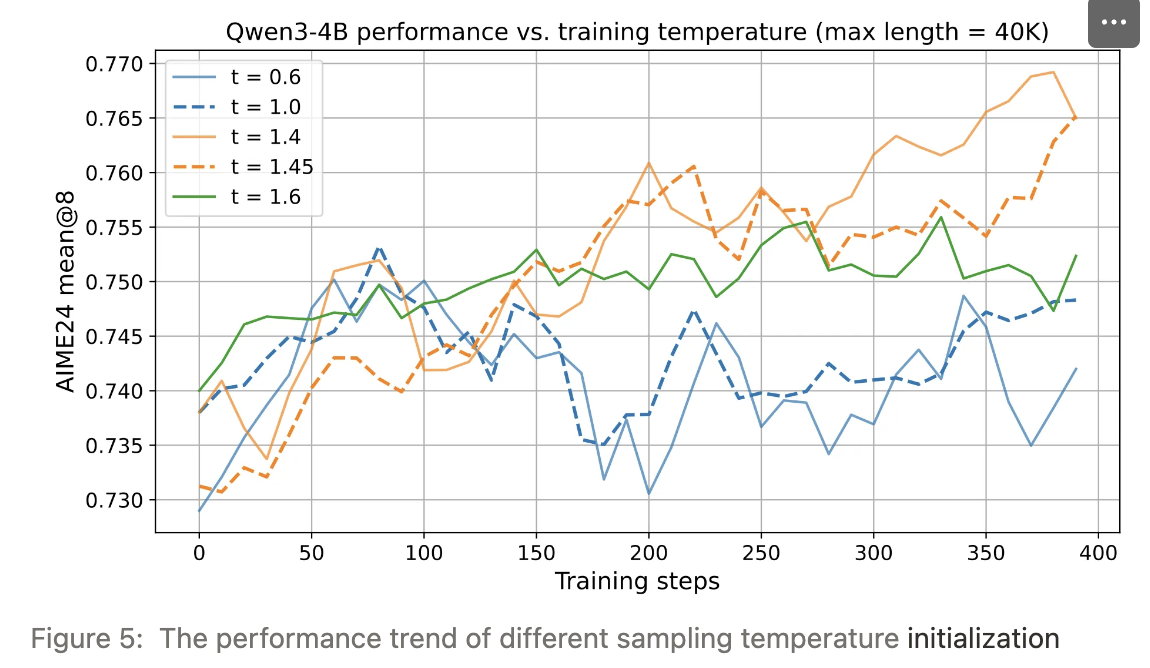
1.2.4 训练阶段动态温度重置
随着 RL 训练推进,模型的 RGZ(稳健生成区间) 与 CEZ(可控探索区间) 会整体右移:
强化学习不断抬高“高质量模式”的概率,模型熵降低、探索空间收窄,表现为各轨迹 N-gram 趋于收敛。
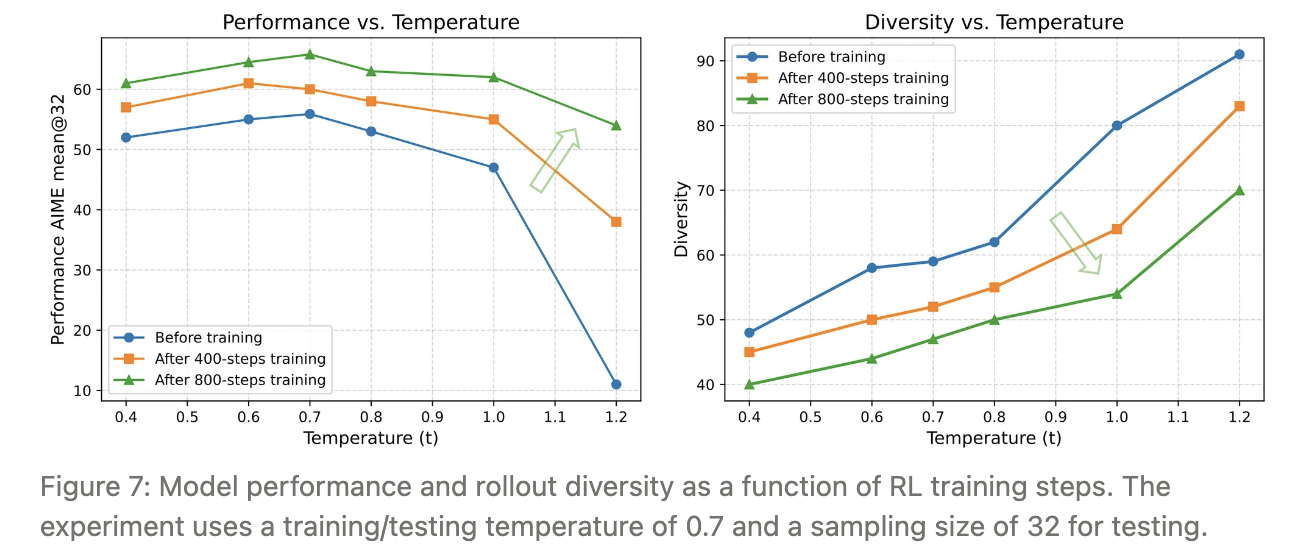
图 7 显示:整体性能提升的同时,模型对高温采样的鲁棒性显著增强——在更高温度下性能衰减更小。
📌 若全程固定温度,后期轨迹多样性会不足,从而限制性能进一步提升。
1.2.5 动态温度重置规则
因此,我们提出 “动态温度重置”:
- 初始阶段:在 CEZ 起始点(如 Qwen3-4B 的 1.4)采样,兼顾性能与多样性。
- 随着模型收敛,逐步 上调 采样温度,持续把温度“推回”新的 CEZ 起始点或更高,强制扩大探索空间。
实际做法:定期监测多样性指标(distinct-4),当发现多样性连续下降时,按固定步长或自适应策略升温,直到再次落入 CEZ 为止。
通过这一策略,整个训练周期内始终维持充足的轨迹多样性,避免“过早收敛”导致的性能天花板。
阶段结束后升温规则
每次训练阶段结束时,我们会:
用多个候选温度做快速探测,找出仍能恢复上一阶段 diversity score 的最低温度;
以该温度作为下一阶段的采样温度。
- 升温步长由上一阶段 熵减幅度 ΔH 决定:
ΔH 较小 → 步长 +0.05
ΔH 显著 → 步长 >0.05(视探测结果而定)下表给出 Polaris 在各阶段的实际采样温度:
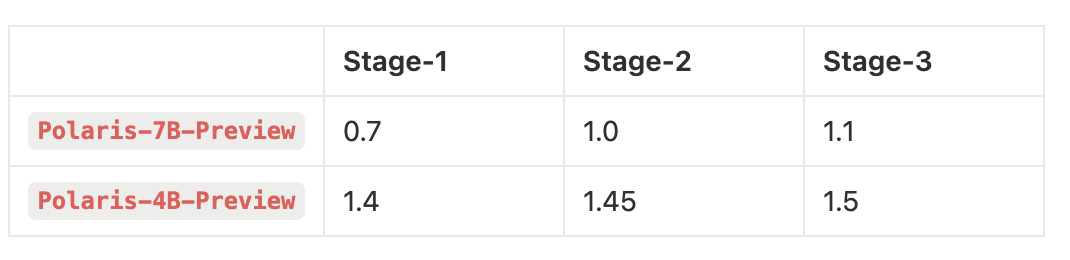
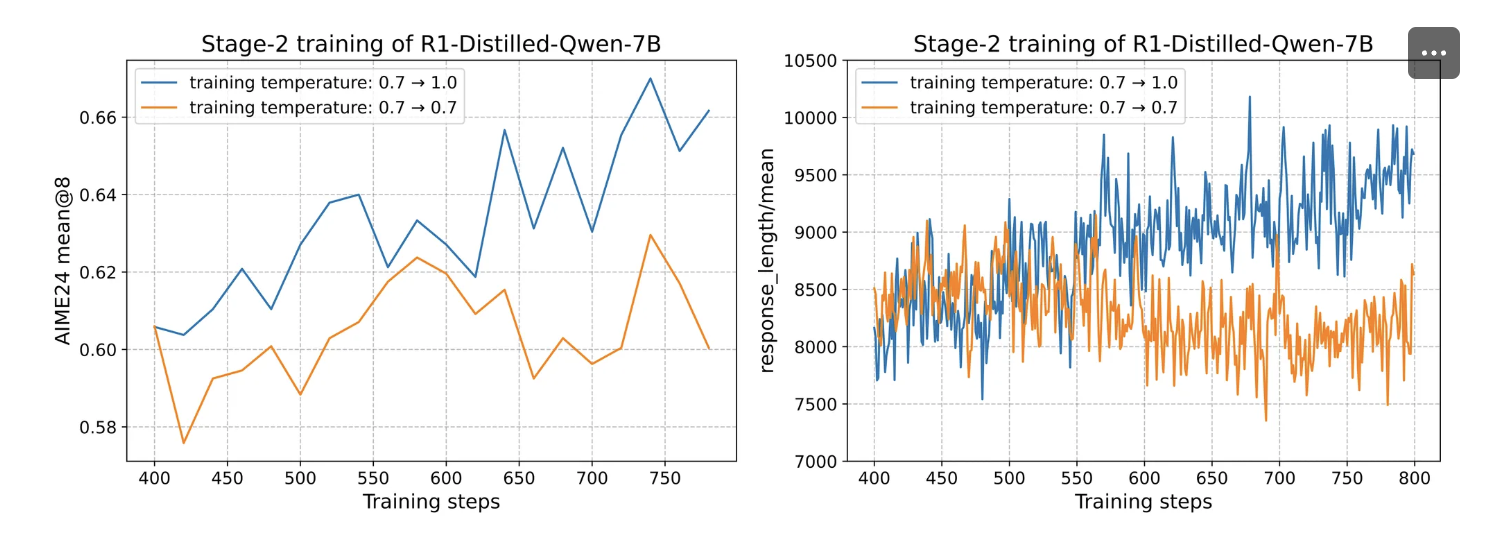
为验证“逐级升温”的有效性,我们设置了一条全程固定温度的对照基线。实验结果显示:
多阶段升温策略不仅带来更优的 RL 训练曲线(准确率、奖励均更高),
还显著拉长了模型的思维链长度(平均响应 token 数 ↑ ≈ 18–25%),
表明持续升温确实拓宽了模型的“思考深度”空间。
因此,动态升温在保持多样性的同时,进一步挖掘了模型的推理潜力,优于固定温度方案。
1.3 推理阶段“长度外推”策略
1.3.1 放弃“训练阶段继续堆长度”,转为 “短训练、长推理”(train-short, test-long)方案
长上下文训练不足的现实瓶颈
- 以 Qwen3-4B 为例:预训练长度 32 K,RL 阶段把上限提到 52 K,但 clip_ratio < 10 %(极少样本真用满长度)。
- 在线 RL 的 rollout 中,短样本必须等长样本解码完毕,导致 GPU 空转;继续盲目抬长度,训练效率极低。
因此,我们放弃“训练阶段继续堆长度”,转为 “短训练、长推理”(train-short, test-long)方案:
- RL 训练长度固定 32 K 以内(保证 90 % 样本不截断)。
推理阶段启用 长度外推:
- 采用 RoPE scaling(θ 基频放大 + 线性/NTK-by-parts)将有效窗口扩展到 64 K~128 K。
- 引入动态 sliding-window attention:超出训练长度的 token 以 4 K~8 K 滑窗复用 KV-cache,显存可控。
验证效果:在 MATH-500 与 AIME24 的 4 K~12 K 长链思考题上,外推后 pass@1 ↑ 3.6 %,而训练成本保持原水平。
通过“短训长推”,我们在有限预算内让 4 B 模型也能完成超长推理,实现训练效率与推理深度的双赢。
1.3.2 遵循 “短训长推” 原则,我们在推理阶段引入长度外推
超预训练长度推理性能急剧下降
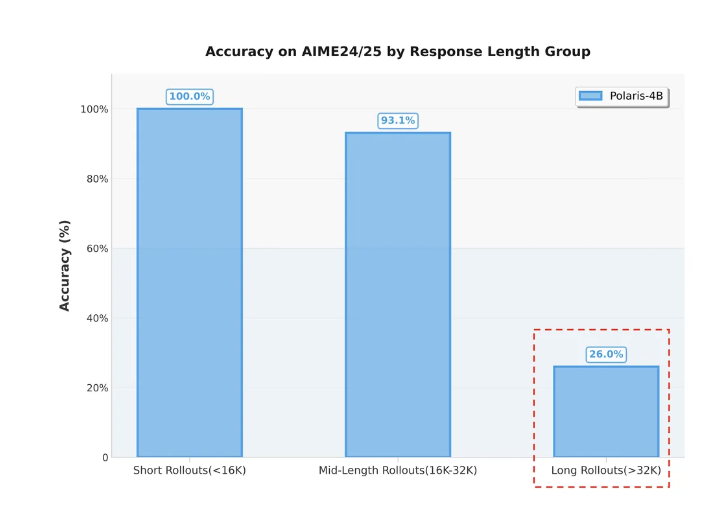
为量化 Polaris-4B-Preview 的有效思维链(CoT)长度,我们选取 AIME24/25 共 60 题,每题 32 条 rollout(共 1920 条),按输出长度分组:
- 组别 长度区间 准确率
- 短 < 16 K 高
- 中 16 K–32 K 高
- 长 > 32 K 仅 26 %(蓝色柱)
结果验证:受限于长上下文 RL 训练效率,模型在 超出原预训练长度 32 K 后显著失效,即使 RL 上限设为 52 K。
免训练长度外推(Training-free Length Extrapolation)
遵循 “短训长推” 原则,我们在推理阶段引入长度外推:
- 方法:对 RoPE 采用 Yarn,缩放因子 1.5。
Yarn 默认建议同步调低 attention temperature;我们发现此举对检索任务有益,却会 损害长推理质量,故保持原温度。- 效果:
32 K 推理准确率由 26 % → 50 %+(无需重训)。收益集中在难题;易题提升有限。
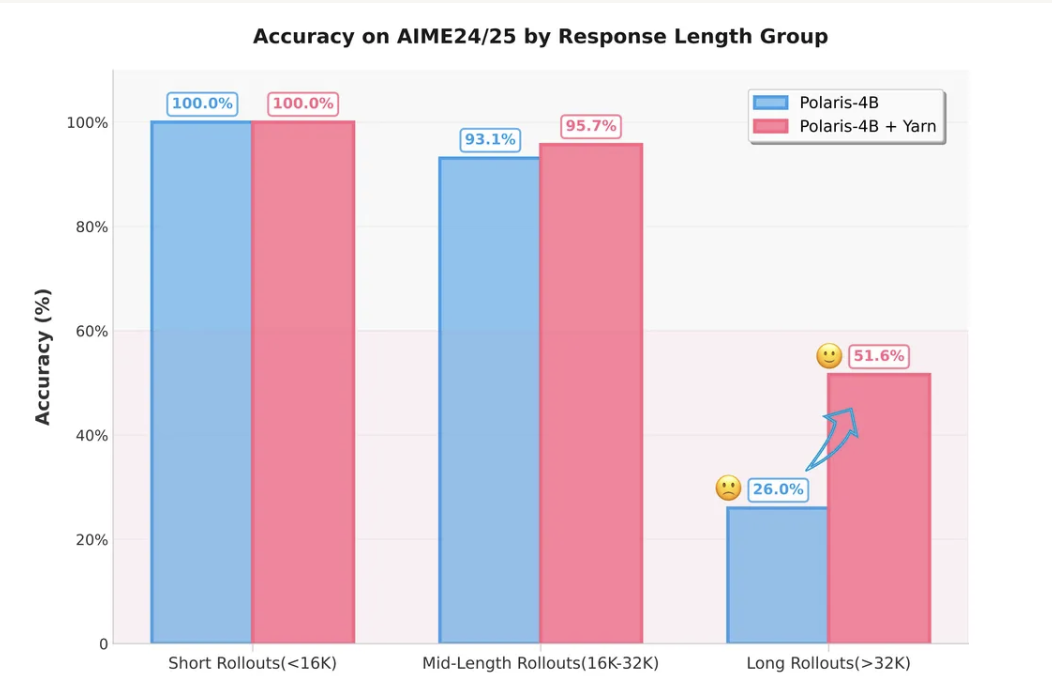
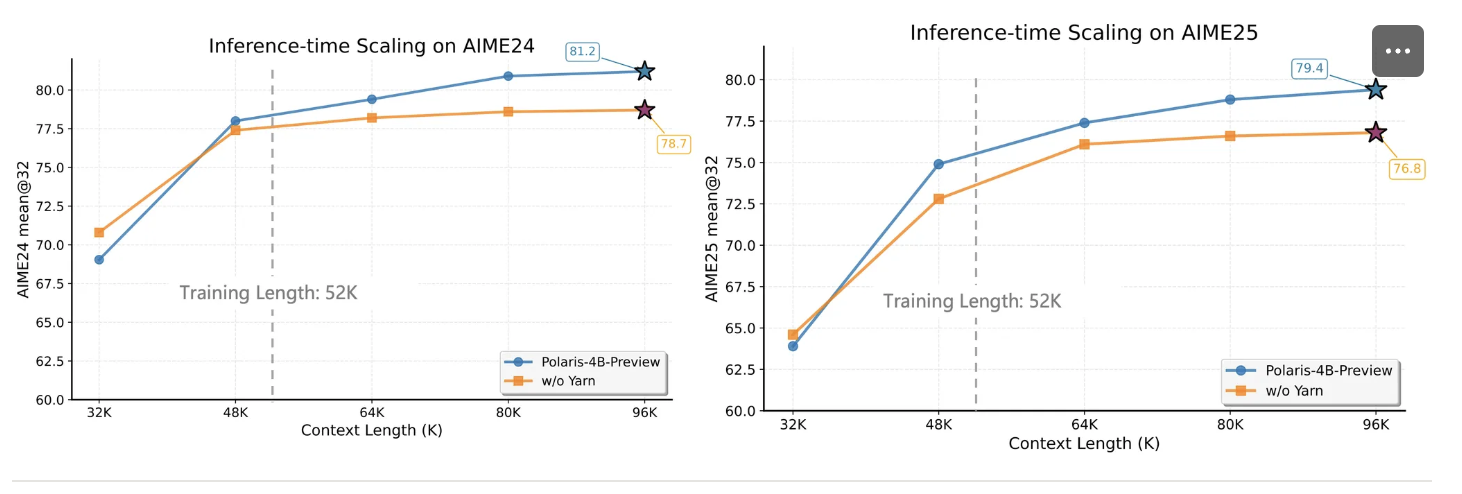
AIME24/25 推理时长度扩展曲线:
蓝线:Polaris-4B-Preview + Yarn
橙线:无 Yarn 基线
- 当上下文 > 48 K 时,Yarn 版本显著优于 Qwen3-4B 基线;
- 长度延伸至 96 K 时,性能继续提升,而无 Yarn 版本在 64 K 后即 停滞。
结论:推理阶段应用 Yarn 等外推技术,可绕过实际 RL 训练长度瓶颈,解锁更长上下文的推理潜力。
1.4 提升rollout的样本效率
探索效率(Exploration Efficiency)
长链思考(long-CoT)训练能否成功,关键在于稀疏奖励前沿的高效探索。
POLARIS 采用多阶段训练,并辅以两项轻量级技术,分别在响应级与样本级缓解奖励稀疏。
多阶段训练
- 核心操作: 在训练的早期阶段,使用较短的上下文窗口(即生成较短的回复)。当模型在当前长度下的性能收敛后,再进入下一个阶段,并增加上下文窗口的长度。
- 目的: 这种渐进式增加长度的方法,可以显著提升整体的训练效率。
一句话总结:
POLARIS ==通过「直接长训 + 离线缓存救援 + 批次内替换」,==在低成本 rollout 下持续提供高质量正负对比,显著提升了长 CoT RL 的探索效率与收敛速度。
1.4.1 多阶段训练是否必须「先短后长」?
结论:并非所有模型都适用「先短后长」。
资源允许时,直接启用官方推荐的最大解码长度更安全。
对 token 效率低的模型(如 Qwen3-4B),强行先短后长会造成灾难性遗忘。
| 模型 | 24 K → 40 K | 直接 40 K |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 有效 | 同样有效 |
| Qwen3-4B | 性能不可逆下跌(clip_ratio < 15 %) | 稳步提升 |
1.4.2 Rollout Rescue 机制(离线缓存)
- 问题:rollout=8 时,难题易出现 0/8 零奖励批次。
- 方案:
每题维护一个离线“sink”缓存:当 0/8 且历史上曾出现正确 rollout 时,把正确响应存入 sink(覆盖旧值)。
后续再遇 0/8,随机把 sink 中的正确响应替换到当前 batch 里。- 收益:显著减少零奖励样本,无需重采样或额外 rollout,收敛更快。
1.4.3 Intra-Batch Informative Substitution(批次内替换)
- 问题:GRPO 中全对/全错样本无法提供梯度。
- 方案:
在 batch 内找出带有正负样本的“有效”题目(梯度非零)。
直接复制这些题目去覆盖批次内零梯度样本,保持 batch 规模不变。- 特点:
仅用索引操作,零额外开销。
与 DAPO 的动态采样效果近似,但实现极简,无需改动数据管线。
1.5 吸收 DAPO 与 GRPO+ 的关键设计
在 Polaris 训练中,我们直接采纳了 DAPO 与 GRPO+ 的三条已被验证的“去冗余”策略:
| 技术点 | 来源 | 用途 | 在 Polaris 中的效果 |
|---|---|---|---|
| 去掉熵损失 | GRPO+ | 防止熵爆炸导致训练崩溃 | 训练曲线更平滑,省去手调 β 熵系数 |
| 去掉 KL 损失 | DAPO | 让策略不被 SFT 参考模型束缚 | 省掉 reference 对数概率计算,训练提速约 8 % |
| 提高 Clip 上限 | DAPO | 允许更大的策略步长以强化探索 | 熵值更稳定,最终 AIME24 pass@1 ↑ 1.3 % |
一句话总结:
“零熵、零 KL、高 Clip” 已经成为 Polaris 长 CoT RL 训练的默认配方,兼顾稳定性、速度与性能。
1.6 奖励函数
我们沿用 DeepScaleR 的奖励设计,仅用结果奖励(ORM),完全舍弃过程奖励(PRM),以根本避免 reward hacking。具体规则:
- +1 —— 答案通过 LaTeX/SymPy 自动检查且格式合规(须包含 … )。
- 0 —— 其余情况(答案错误、格式不符或缺少指定标签)。
1.7 evaluate
推理阶段设置建议
- 温度
由于 RL 训练后模型的 Robust Generation Zone 右移,建议把 Qwen3 官方推荐的 0.6 提升到 1.4;但不要高于训练时的温度,否则性能反而下降。- 长度
使用 > 64 K 的响应上限,避免截断导致性能低于原版 Qwen3;- 其余超参数保持默认。
sampling_params = SamplingParams(
temperature=1.4,
top_p=1.0,
top_k=20,
max_tokens=90000
)

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)