攻克“世界模型”最后难题!清华陈建宇×斯坦福Chelsea团队推出Ctrl-World让机器人学会“想象式”训练
现有的世界模型(在虚拟环境中预测未来的模型)虽然提供了一种可行的替代方案,但它们大多无法支持与现代机器人策略进行复杂的多步交互,存在着视角单一、控制精度不足和长期交互不稳定等问题。该模型的核心思路是:改造一个预训练的视频生成模型,使其能够理解并精确模拟机器人高频动作所带来的多视角视觉变化,从而创建一个可交互的、高保真的机器人虚拟测试环境。该模型通过在虚拟的“想象空间”中模拟机器人的动作结果,不仅能
一、导读
当前,通用的机器人已经能完成多种操作任务,但如何高效地评估和改进它们在面对陌生物体和指令时的能力,是一个巨大的挑战。传统的评估方法需要大量真实机器人反复试验,而改进则依赖专家收集和标注新的数据,这些过程都非常耗时且昂贵。现有的世界模型(在虚拟环境中预测未来的模型)虽然提供了一种可行的替代方案,但它们大多无法支持与现代机器人策略进行复杂的多步交互,存在着视角单一、控制精度不足和长期交互不稳定等问题。
为了解决这些难题,本文提出了一个名为 Ctrl-World 的可控多视角生成式世界模型。该模型通过在虚拟的“想象空间”中模拟机器人的动作结果,不仅能准确地评估机器人策略的优劣,还能通过生成成功的虚拟经验来指导机器人学习,最终将机器人策略的成功率提升了44.7%。
二、论文基本信息

论文标题: CTRL-WORLD: A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION (一个用于机器人操控的可控生成式世界模型)
作者姓名与单位: Yanjiang Guo (斯坦福大学, 清华大学), Lucy Xiaoyang Shi (斯坦福大学), Jianyu Chen (清华大学), Chelsea Finn (斯坦福大学)
论文链接: https://arxiv.org/abs/2510.10125v2
三、主要贡献与创新
- 提出了一个可控的多视角世界模型,首次实现了与通用机器人策略在虚拟空间中的闭环交互。
- 设计了姿态条件的记忆检索机制,显著提升了模型生成视频在长时间范围内的时序一致性。
- 通过帧级动作条件注入,实现了对生成视频的精细化控制,确保了动作与画面的因果关系。
- 验证了在虚拟世界模型中评估和改进机器人策略的可行性,为机器人学习提供了新范式。
四、研究方法与原理
该模型的核心思路是:改造一个预训练的视频生成模型,使其能够理解并精确模拟机器人高频动作所带来的多视角视觉变化,从而创建一个可交互的、高保真的机器人虚拟测试环境。
【模型结构图】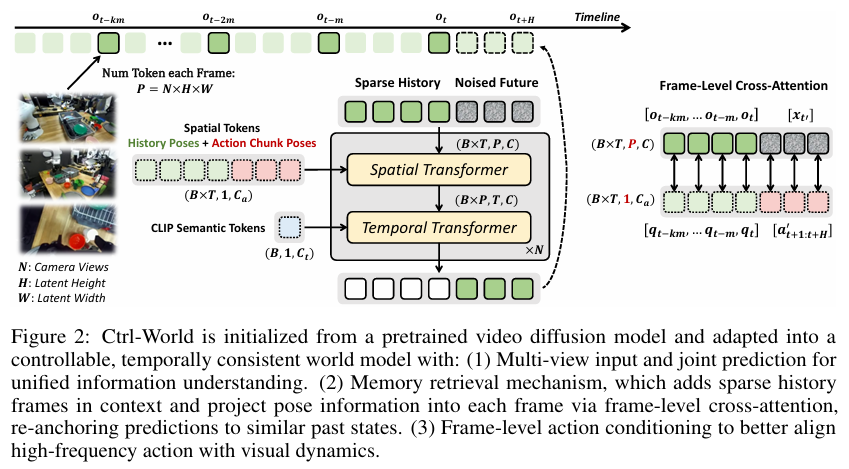
Ctrl-World 模型基于一个预训练的视频扩散模型(Stable Video Diffusion)进行改造,并引入了三个关键设计以实现与机器人策略的交互:
-
多视角联合预测 (Multi-View Joint Predictions)
现代先进的机器人策略通常需要同时输入来自不同位置的多个摄像头画面(如第三人称视角和机器人手腕视角)来全面感知环境。为了适配这一点,Ctrl-World 将多个视角的图像在token维度上拼接起来,作为一个整体输入到模型中,并联合预测所有视角在未来的画面。这种设计不仅满足了策略的输入需求,还通过整合多视角信息,显著减少了因单一视角信息不全而产生的幻觉(例如物体凭空出现在机械臂上),提升了生成画面的空间一致性。 -
姿态条件的记忆检索机制 (Pose-conditioned Memory Retrieval Mechanism)
长时间的视频生成任务中,微小的预测误差会不断累积,导致最终画面变得模糊或不合逻辑。为了解决这个问题,模型在预测未来时,会从历史画面中稀疏地采样 k k k 帧(例如每隔 m m m 帧采样一次)作为记忆上下文。更关键的是,模型会将这些历史画面的机器人手臂姿态信息 q t − k m , … , q t q_{t-km}, \dots, q_t qt−km,…,qt 通过帧级交叉注意力机制(frame-wise cross-attention)融入到每一帧的视觉特征中。这使得模型能够根据当前姿态,从记忆中找到相似姿态的历史画面并获取相关信息,从而稳定长时程预测,保持画面的时序连贯性。 -
帧级动作条件 (Frame-level Action Conditioning)
为了让模型能被机器人的动作精确控制,Ctrl-World 将策略输出的未来动作序列 a t + 1 : t + H a_{t+1:t+H} at+1:t+H 也作为模型的输入条件。这些动作指令被转换成笛卡尔空间下的手臂姿态序列 [ a t + 1 : t + H ′ ] [a'_{t+1:t+H}] [at+1:t+H′]。与处理历史姿态类似,模型同样采用帧级交叉注意力机制,让每一帧未来的视觉特征都能关注到其对应的动作姿态。这样一来,生成的视频动态变化就能与输入的高频动作信号紧密对齐,确保了模型的可控性。
最终,模型通过一个扩散损失函数(diffusion loss)进行微调。其目标是让模型在给定历史画面、语言指令和未来动作序列 c c c 的条件下,能够从一个加了噪声的未来画面 x t ′ x_{t'} xt′ 中,准确地预测出原始的清晰画面 x 0 x_0 x0。训练目标函数如下:
L = E x 0 , ϵ , t ′ ∥ x ^ 0 ( x t ′ , t ′ , c ) − x 0 ∥ 2 \mathcal{L} = \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}, t'} \|\hat{\mathbf{x}}_0(\mathbf{x}_{t'}, t', c) - \mathbf{x}_0\|^2 L=Ex0,ϵ,t′∥x^0(xt′,t′,c)−x0∥2
其中, x ^ 0 \hat{\mathbf{x}}_0 x^0 是模型的预测结果, x 0 \mathbf{x}_0 x0 是真实的未来多视角画面序列 o t + 1 : t + H o_{t+1:t+H} ot+1:t+H。
五、实验设计与结果分析
-
实验设置
实验基于 DROID 平台和数据集,该数据集包含了由一个Panda机械臂在564个真实场景中收集的 95,599 条多样化的操作轨迹,其中既有成功也有失败的案例,为训练一个能模拟多种可能性的世界模型提供了丰富数据。模型需要联合预测3个分辨率为192x320的摄像头画面。
评测真实世界模型生成质量的指标包括:- 基于计算的指标:PSNR (峰值信噪比) 和 SSIM (结构相似性),越高代表画面越接近真实。
- 基于模型的指标:LPIPS (学习感知图像块相似度),越低代表感知上越相似;FID (弗雷歇初始距离) 和 FVD (弗雷歇视频距离),越低代表生成视频的分布与真实视频越接近。
-
世界模型质量分析 (World Model Quality Analysis)
对比实验:实验将 Ctrl-World 与两种先进的动作条件世界模型 WPE 和 IRASim 进行了比较。为了公平对比,研究人员首先训练了一个只使用单一第三人称视角的 Ctrl-World 版本。结果显示,即便是单视角版本,Ctrl-World 在各项指标上已优于其他模型。而完整的 Ctrl-World (ours) 模型通过多视角联合预测,在所有指标上都取得了最佳性能,尤其在FVD指标上优势显著,证明其生成的视频质量更高、更连贯。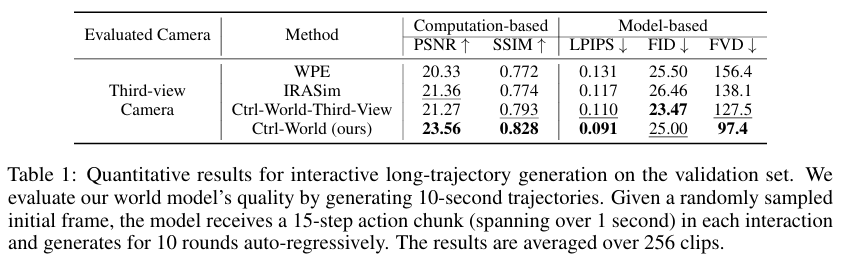
可视化对比:如下图所示,依赖单视角预测的 IRASim 模型在执行任务时出现了幻觉,例如,它未能模拟出移动绿色毛巾的动作,也无法抓取红碗。相比之下,Ctrl-World 通过联合预测第三人称和手腕视角,能够精准地模拟机器人与物体的交互,其生成的结果与真实情况高度一致。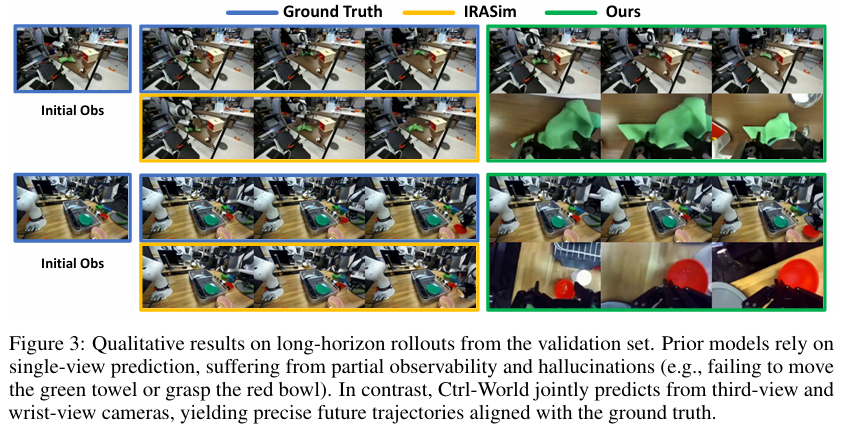
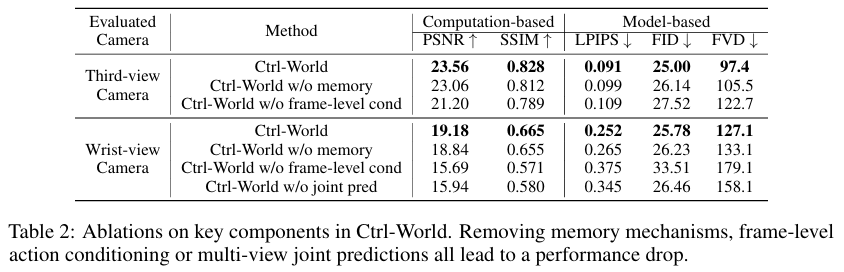
消融实验:为了验证模型各组件的有效性,研究人员分别移除了记忆机制 (w/o memory)、帧级动作条件 (w/o frame-level cond) 和多视角联合预测 (w/o joint pred)。结果显示,缺少任何一个组件都会导致模型性能在所有指标上出现下降,这证明了这三个设计对于提升生成质量和可控性都至关重要。
-
世界模型用于策略评估 (World Model for Policy Evaluation)
实验评估了三个公开的机器人策略( π 0 \pi^0 π0, π 0 \pi^0 π0-FAST, π 0.5 \pi^{0.5} π0.5)在真实世界和 Ctrl-World 中的表现。结果显示,一个策略在世界模型中的指令遵循度与它在真实世界中的表现高度相关(线性回归 y = 0.87 x − 0.04 y = 0.87x - 0.04 y=0.87x−0.04)。这意味着 Ctrl-World 能够作为一个可靠的评估工具,来预测不同策略在真实部署前的高层任务规划能力。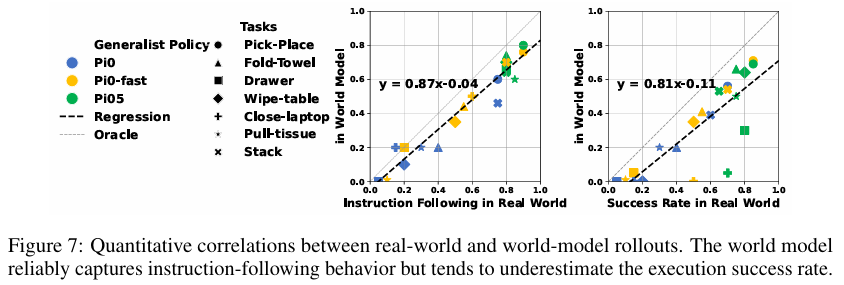
如下图所示, π 0.5 \pi^{0.5} π0.5 策略在真实世界和世界模型中执行“折叠毛巾”、“擦桌子”、“关闭笔记本电脑”等任务时,其行为路径和最终结果非常相似,证明了Ctrl-World模拟的保真度。

-
世界模型用于策略改进 (World Model for Policy Improvement)
研究人员利用 Ctrl-World 来生成成功的轨迹数据,用于微调基础策略 π 0.5 \pi^{0.5} π0.5,以提升其在新指令和新物体上的表现。他们通过改写指令或随机重置机械臂初始位置来探索多样的成功路径,然后筛选出成功的轨迹。如下图所示,针对“空间理解”、“形状理解”、“毛巾折叠方向”和“新物体”等四类泛化任务,微调后的策略成功率平均从 38.7% 大幅提升至 83.4%,总提升幅度为 44.7%。这证明了利用世界模型生成合成数据进行策略改进的巨大潜力。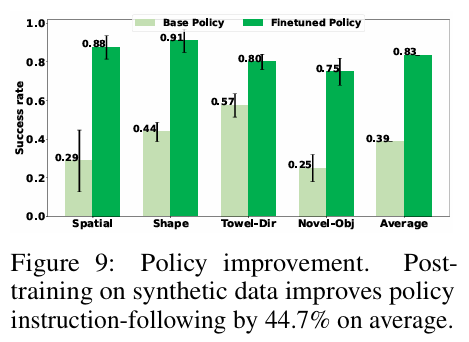
六、论文结论与评价
本文的核心结论是,一个设计精良的世界模型不仅可以作为机器人策略的高保真“虚拟试验场”,用于低成本、高效率地评估其能力,还能成为一个强大的“教练”,通过在想象中探索并生成成功的范例,来指导和改进现有策略,尤其是在它们不熟悉的任务上。实验证明,Ctrl-World在预测策略行为方面与真实世界表现出很强的一致性,并且利用它生成的合成数据能将一个预训练策略的成功率提高44.7%。
这项研究的价值在于,它为机器人学习开辟了一条摆脱对大规模真实世界数据和昂贵硬件迭代依赖的道路。未来的机器人或许可以在大部分时间里通过“想象”来学习和试错,只在必要时才与真实世界交互,这将极大地加速通用机器人的研发进程。
尽管如此,该方法也存在一些局限性。首先,Ctrl-World在模拟精细物理动态(如碰撞、物体滑动和复杂接触)方面仍有不足,这导致它在评估底层执行成功率方面不如指令遵循度评估那么准确。其次,模型的表现受限于初始观测的质量,如果起始场景过于复杂或罕见,生成质量可能会下降。最后,其模拟能力的上限仍然受限于训练数据的多样性,无法完全覆盖真实世界中所有的失效模式。
为了进一步提升,未来的研究可以探索将世界模型与策略进行迭代式共同优化:即用世界模型改进策略,再用改进后的策略在真实世界中收集更高质量的数据来反哺世界模型,形成一个良性循环。此外,将更强大的视频生成模型作为骨干,以及集成自动化的奖励模型来代替人工判断,也是非常有前景的方向。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)