基于物理模拟器和世界模型的具身智能学习:深度解析与未来展望
本文系统探讨了世界模型(World Models)在人工智能发展中的关键作用及其在智能机器人分级体系中的应用。世界模型作为实现通用人工智能(AGI)的核心技术,通过内部模拟、因果推理和预测能力使机器能够像人类一样理解和预测复杂环境。文章梳理了世界模型的历史发展轨迹,从早期探索到现代突破,并分析了当前多模态融合、大规模预训练等研究趋势。同时,提出了一套从IR-L0到IR-L4的五级智能机器人分类标准
1. 引言:什么是世界模型
1.1 研究背景与动机
在人工智能的发展历程中,一个核心问题始终困扰着研究者:如何让机器像人类一样理解和预测这个复杂多变的世界?世界模型(World Models)作为解决这一问题的关键技术,正在成为实现通用人工智能(AGI)的重要基石。
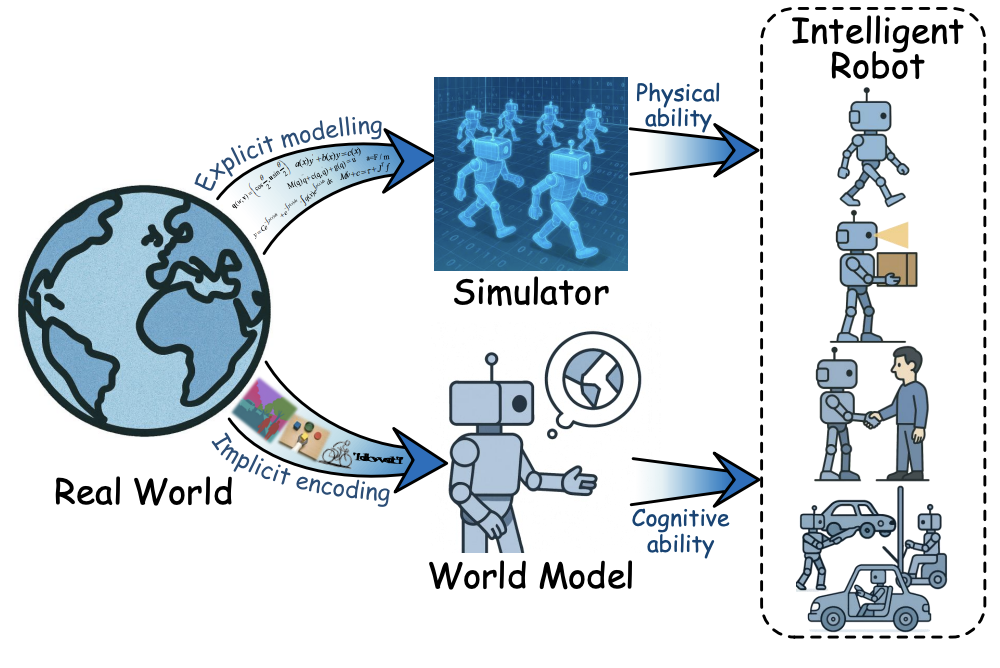
随着深度学习的快速发展,我们见证了AI在感知和决策方面的巨大进步。然而,现有的大多数AI系统仍然是反应式的——它们只能对当前输入做出响应,缺乏对未来的预测能力。这种局限性在复杂动态环境中尤为明显,比如自动驾驶、机器人操作等具身智能任务。
具身智能(Embodied Intelligence)的核心挑战在于智能体需要在物理世界中与环境进行实时交互。这要求系统不仅要理解当前状态,还要能够预测行动的后果,并在不确定性下做出最优决策。传统的端到端学习方法虽然在某些任务上表现出色,但往往缺乏对环境动态的深层理解,难以泛化到新的情况。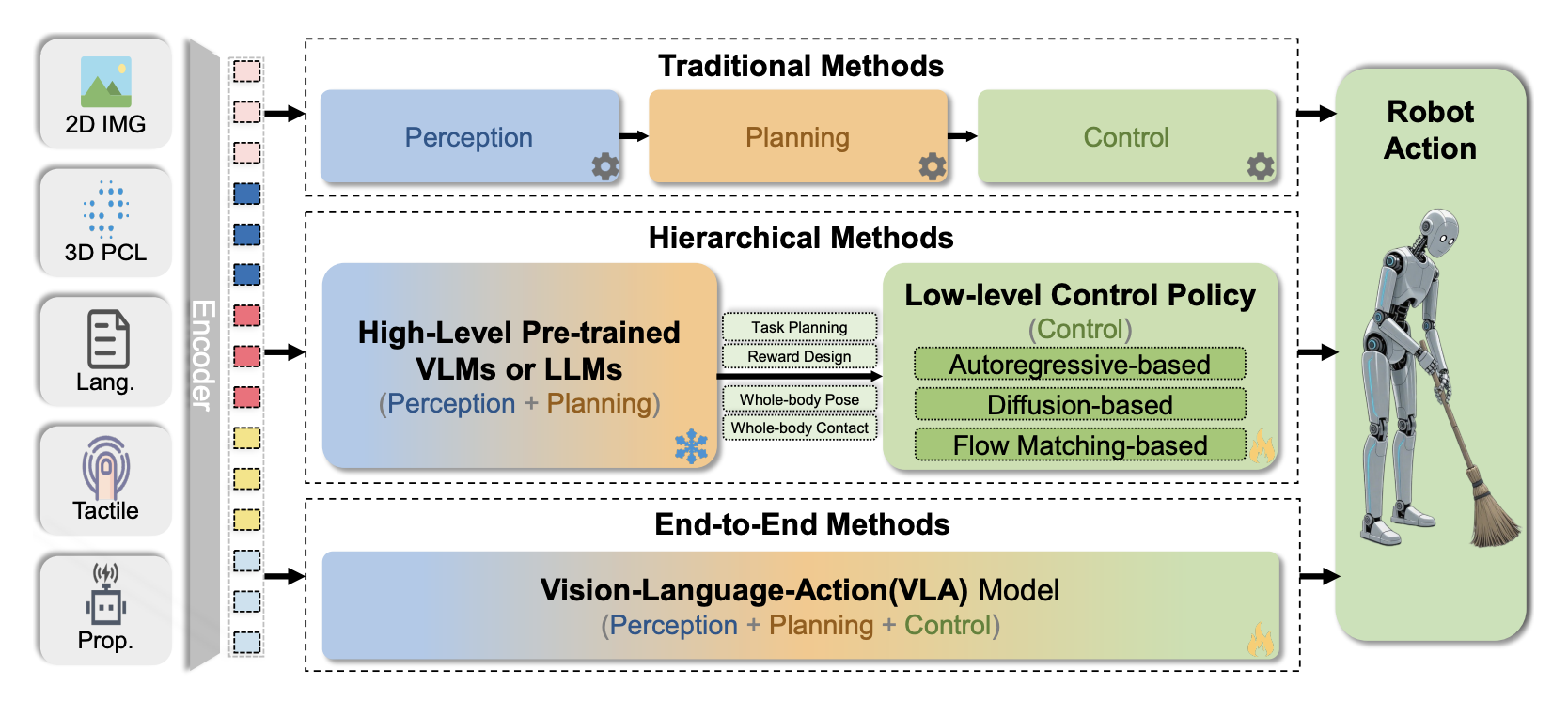
1.2 世界模型的核心概念
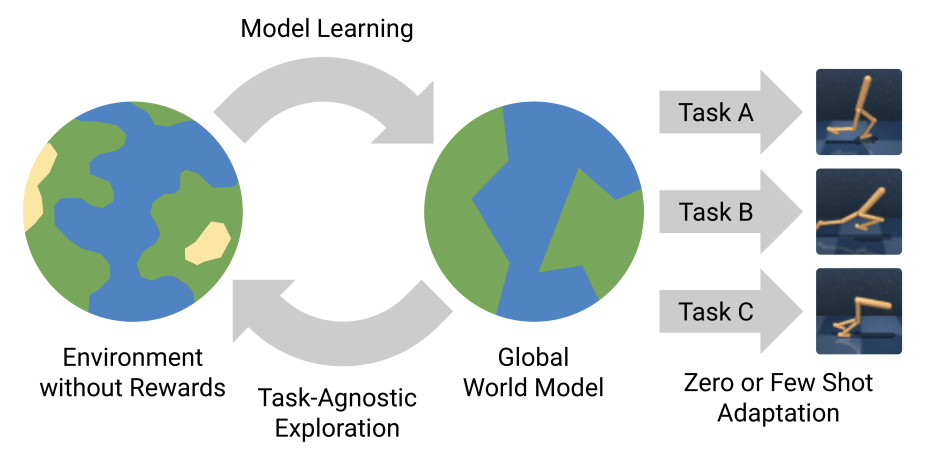
世界模型可以理解为智能体内部携带的环境表示,就像一个"计算雪球",包含了对外部世界动态、物理规律和因果关系的深层理解。与传统的反应式AI系统不同,拥有世界模型的智能体能够在执行动作之前,在内部"想象"和评估可能的结果,从而做出更加明智的决策。
图3:世界模型的工作流程图
从认知科学的角度来看,世界模型体现了人类思维的核心特征:
- 内部模拟:在执行动作前进行心理预演
- 因果推理:理解行动与结果之间的因果关系
- 预测能力:基于当前状态预测未来可能的状态
- 规划能力:通过模拟不同行动序列来制定计划
1.3 历史发展轨迹
世界模型的发展可以追溯到人工智能的早期研究。让我们回顾这一技术的重要里程碑: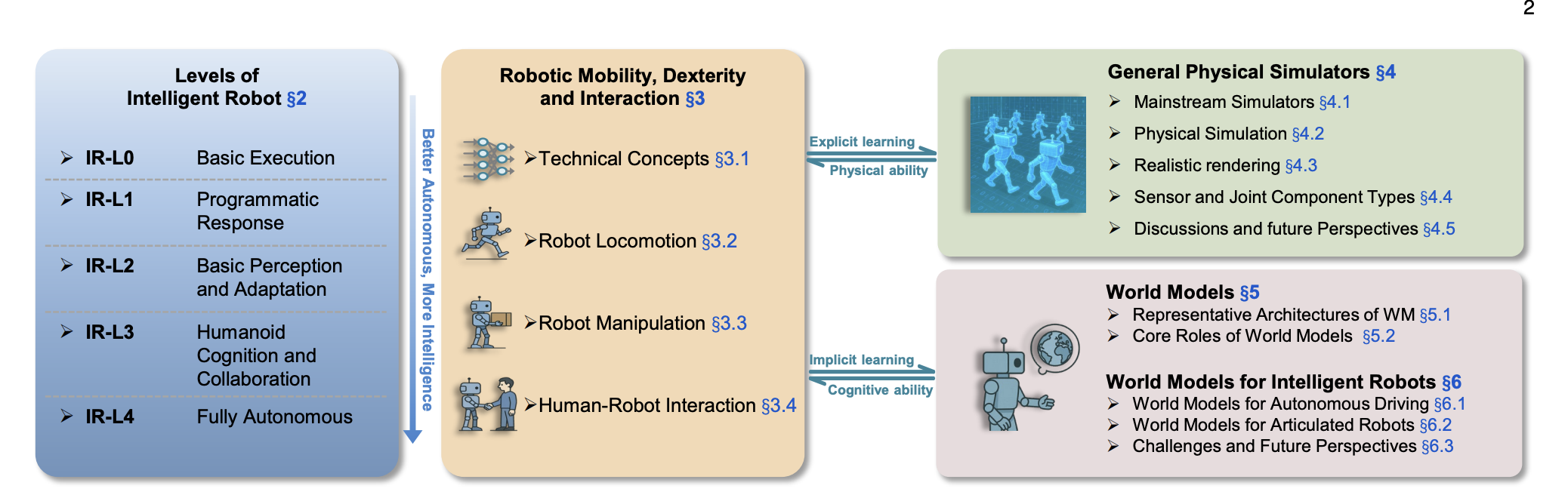
早期探索阶段(1950s-1990s)
- 1950s:冯·诺依曼提出自复制自动机概念,首次讨论机器的内部世界模型
- 1980s:认知科学家开始研究人类的心理模型(Mental Models)
- 1990s:早期的基于模型的强化学习方法开始出现
理论奠基阶段(2000s-2010s)
- 2007:Sutton和Barto在《强化学习:导论》中系统阐述了基于模型的学习
- 2012:深度学习革命开始,为世界模型提供了强大的表示学习能力
- 2015:Watter等人提出了基于变分自编码器的世界模型
现代突破阶段(2018-至今)
- 2018:Ha和Schmidhuber发表经典论文《World Models》,正式提出现代世界模型概念
- 2019-2021:Dreamer系列模型的发布,展示了世界模型在强化学习中的强大能力
- 2022-2024:大规模视频生成模型(如Sora)的出现,为世界模型带来了新的突破
- 2024-至今:多模态世界模型和统一架构成为研究热点
2018年,Ha和Schmidhuber首次系统性地提出了世界模型的概念,他们展示了如何通过学习环境的压缩生成模型来模拟体验,使智能体能够在没有直接与现实世界交互的情况下进行强化学习。这一突破性工作为后续的研究奠定了坚实基础。
随着视频生成模型的快速发展,特别是2024年以来Sora、Kling等模型的出现,世界模型的能力得到了显著提升。这些模型在高保真度视频合成和物理世界建模方面表现出色,证明了世界模型作为"物理世界引擎"的巨大潜力。正如OpenAI在Sora的技术报告中所强调的,视频生成模型有望成为理解和模拟物理世界的强大工具。
1.4 当前研究趋势
当前世界模型的研究呈现出以下几个重要趋势:
多模态融合
现代世界模型不再局限于单一模态,而是整合视觉、语言、听觉等多种感知输入,构建更加全面的环境理解。
大规模预训练
借鉴大语言模型的成功经验,研究者开始探索在大规模数据上预训练通用世界模型,然后针对特定任务进行微调。
物理约束建模
显式地将物理定律和约束嵌入到模型中,提高预测的物理合理性和泛化能力。
实时部署优化
为了在实际应用中部署,研究者致力于提高模型的计算效率和实时性能。
2. 智能机器人等级分类体系
2.1 分级标准概述
随着具身智能技术的不断发展,建立一个统一的智能机器人分级标准变得至关重要。本研究提出了一个从IR-L0到IR-L4的五级分级标准,用于评估机器人的自主性、任务处理能力、环境适应性和社会认知能力。
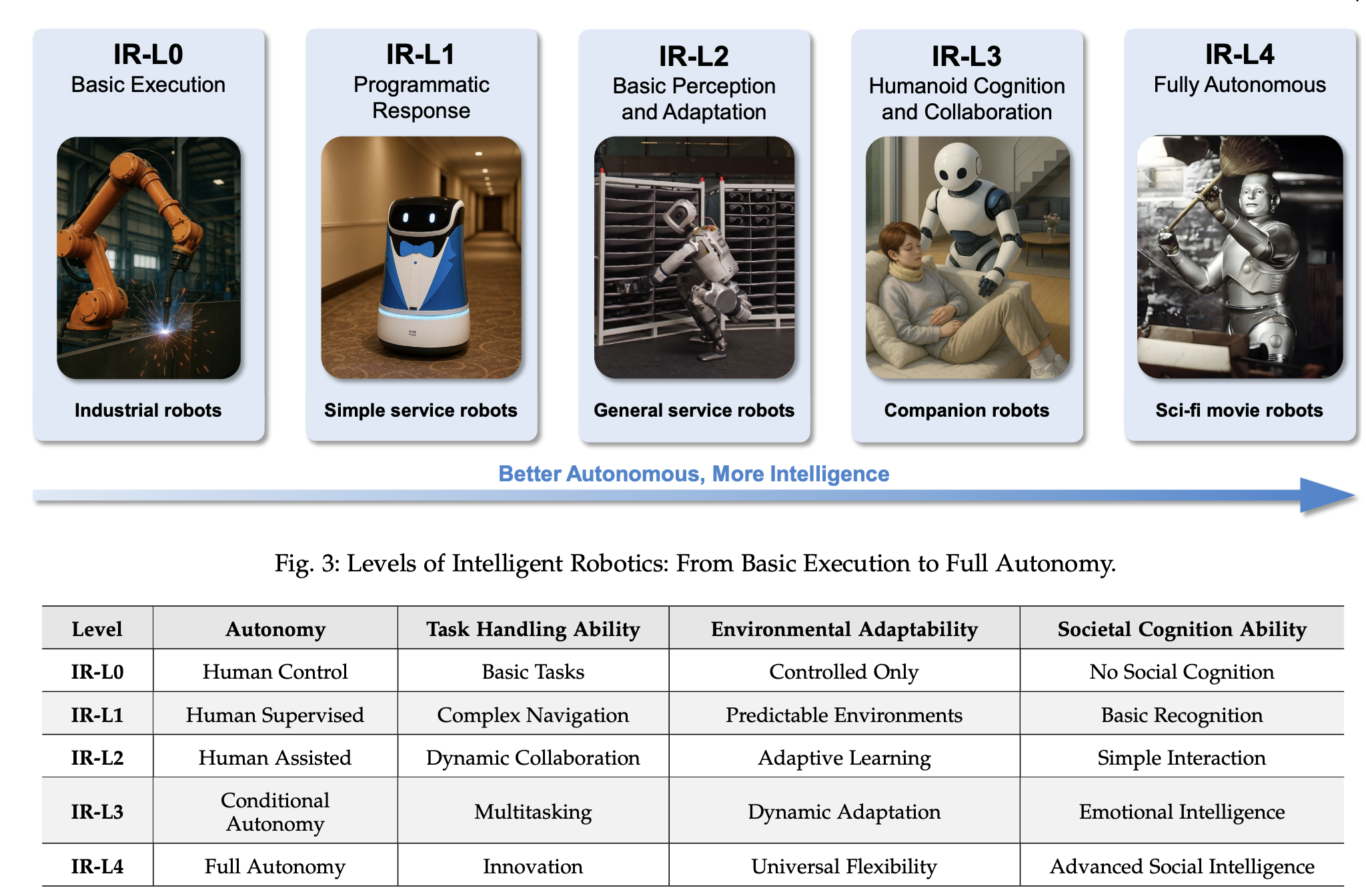
2.2 详细分级介绍
2.2.1 IR-L0:基础执行级别(Foundation Execution Level)
核心特征:
- 完全非智能、程序驱动的属性
- 专注于执行高度重复、机械化、确定性的任务
- 完全依赖预定义的程序指令或实时遥操作
- 缺乏环境感知、状态反馈或自主决策能力
技术要求:
IR-L0技术架构
- 硬件:高精度伺服电机和刚性机械结构
- 控制系统:基于PLC或MCU的运动控制器
- 感知能力:极其有限,通常涉及限位开关、编码器等
- 控制算法:主要基于预定义脚本、动作序列或遥操作
- 人机交互:非常有限,或者仅限于简单的按钮/遥操作
典型应用:
- 工业焊接机器人
- 固定路径的物料搬运
- 简单的装配线作业
技术局限性:
- 无法处理环境变化
- 缺乏学习能力
- 需要精确的环境设置
2.2.2 IR-L1:程序化响应级别(Programmed Response Level)
核心特征:
- 具有有限的基于规则的反应能力
- 能够执行预定义的任务序列
- 利用基本传感器触发特定的行为模式
- 只能在规则明确的封闭任务环境中表现出操作稳定性
技术要求:
- 传感器:集成基本传感器(红外、超声波、压力)
- 处理能力:适度增强的处理器能力
- 感知能力:能够检测障碍物、边界和简单的人类运动
- 控制算法:基于规则引擎和有限状态机(FSM),辅以基本的SLAM或随机游走算法
典型应用:
- 扫地机器人(如Roomba)
- 简单的接待机器人
- 基础的安保巡逻机器人
2.2.3 IR-L2:基础感知与适应性级别(Basic Perception and Adaptation Level)
核心特征:
- 引入了初步的环境意识和自主能力
- 能够在动态环境中执行任务
- 支持语音命令执行和路径规划
- 具备基本的对象识别能力
技术架构:
IR-L2技术架构
关键技术突破:
- 多模态感知:整合摄像头、激光雷达、麦克风阵列
- 环境理解:基本的对象识别和环境建图能力
- 自然交互:语音识别和合成,能够理解和执行基本命令
- 适应性行为:基于环境变化调整行为策略
典型应用场景:
- 服务机器人(送餐、导航引导)
- 智能家居助手
- 教育机器人
2.2.4 IR-L3:人形认知与协作级别(Humanoid Cognition and Collaboration Level)
核心特征:
- 在复杂动态环境中表现出自主决策能力
- 支持复杂的多模态人机交互
- 能够推断用户意图并相应地调整行为
- 在既定的伦理约束内运行
技术要求:
- 高性能计算:GPU加速的深度学习推理
- 多模态传感器:深度摄像头、肌电图传感器、力感测阵列
- AI架构:基于深度学习的感知和语言理解(CNN、Transformer)
- 学习能力:强化学习用于适应性策略优化
- 伦理系统:嵌入伦理治理系统,防止不安全或不符合规定的行为
典型应用:
- 老年护理机器人
- 医疗辅助机器人
- 高级家庭服务机器人
2.2.5 IR-L4:完全自主级别(Full Autonomy Level)
核心特征:
- 完全的自主性,能够在任何环境中独立运行
- 具备自我进化的伦理推理能力
- 高级认知能力、移情能力和长期适应性学习能力
- 支持复杂的社交互动和多智能体协作
技术架构愿景:
IR-L4技术架构愿景
技术要求(未来愿景):
- 仿生结构:高度仿生结构,具有全身多自由度关节
- 计算平台:分布式高性能计算平台
- 感知系统:全方位、多尺度、多模态传感系统
- AI架构:集成通用人工智能(AGI)框架
- 学习能力:元学习、生成人工智能和具身智能
- 伦理系统:动态伦理决策系统,能够在伦理困境中做出道德选择
预期应用:
- 通用家庭伙伴机器人
- 复杂工业协作机器人
- 科研助手机器人
- 社会服务机器人
2.3 分级标准的应用价值
这个分级标准不仅为技术发展提供了清晰的路线图,还为以下方面提供了指导:
监管和安全评估
- 为不同级别的机器人制定相应的安全标准
- 建立分级认证体系
- 指导责任分配和法律框架
产业发展规划
- 帮助企业明确技术发展目标
- 指导投资决策和资源配置
- 促进产业链协同发展
伦理部署指导
- 为不同级别机器人的伦理使用提供框架
- 指导人机交互设计
- 促进社会接受度
3. 物理模拟器:虚拟世界的基石
3.1 物理模拟器概述
物理模拟器是机器人研究和开发的基础工具,它们提供了高保真的虚拟环境,使研究人员能够在安全、高效的条件下训练和验证机器人行为。随着具身智能技术的发展,物理模拟器的重要性日益凸显。

3.2 主流物理模拟器详细分析
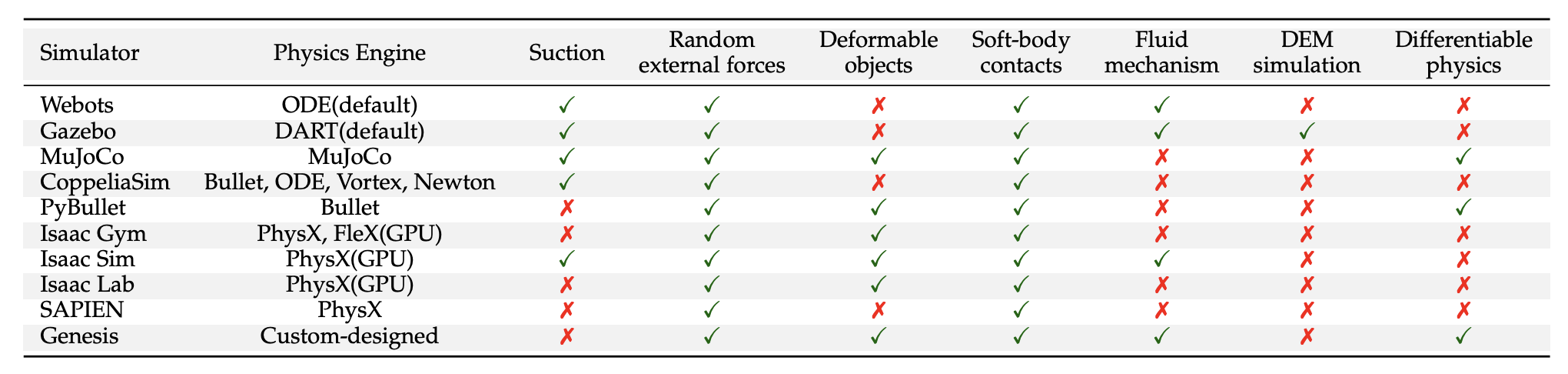
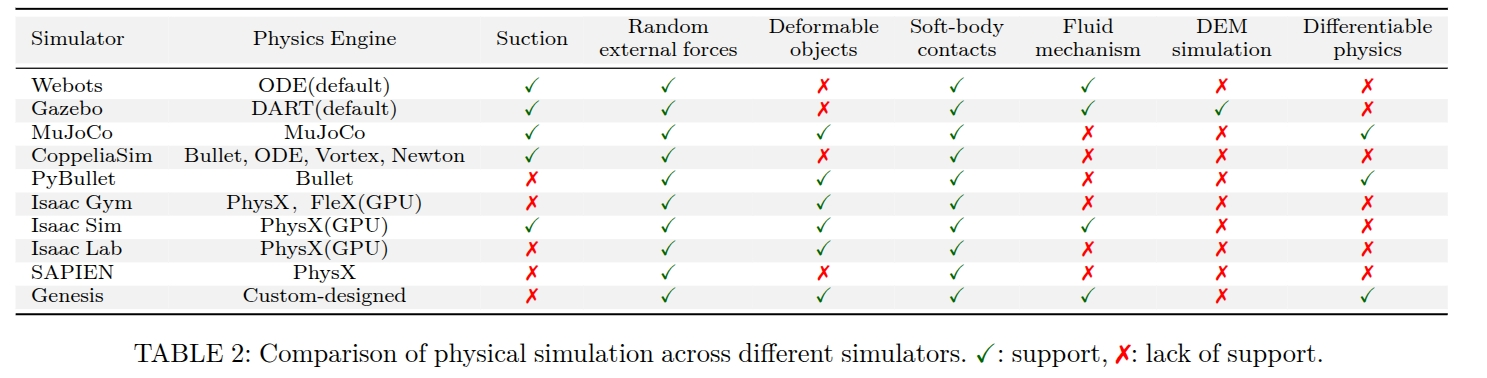
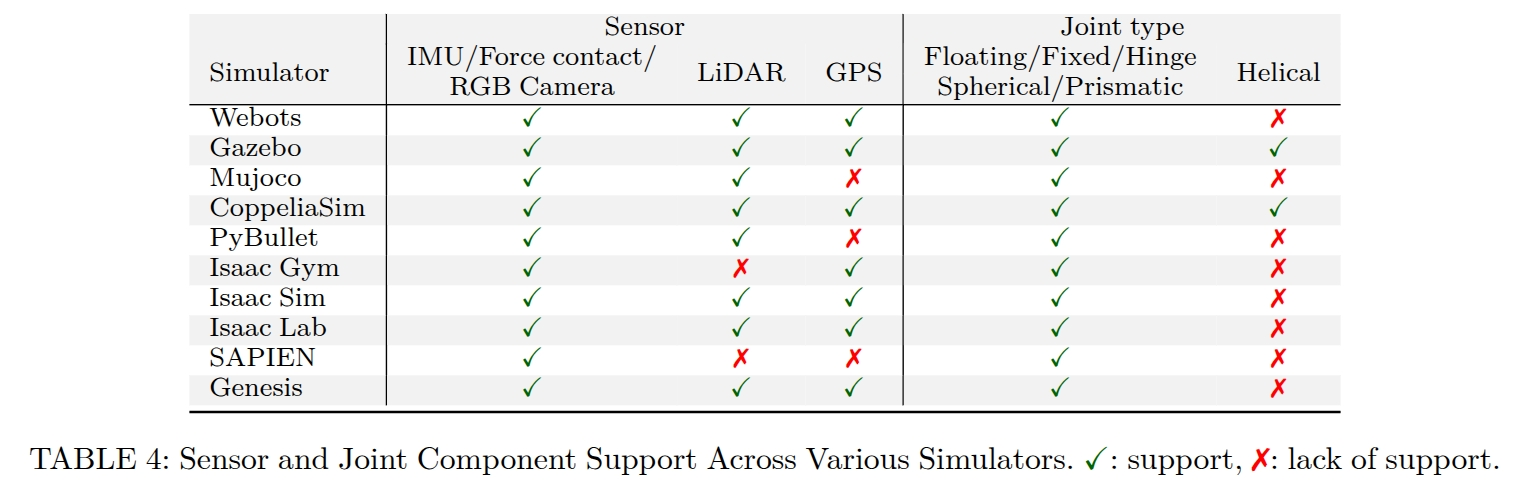
3.2.1 传统通用模拟器
Webots:教育与工业的桥梁
Webots由Cyberbotics Ltd.于1998年推出,经过多年发展,已成为机器人教育和研究的重要平台。
技术特点:
- 渲染引擎:基于OpenGL的WREN引擎,支持PBR
- 物理引擎:内置ODE物理引擎
- 编程接口:支持Python、C++、Java、MATLAB
- 机器人模型:丰富的预建机器人库
- 传感器支持:完整的传感器仿真
应用优势:
- 易于学习和使用
- 强大的可视化界面
- 完善的文档和教程
- 活跃的社区支持
局限性:
- 不支持可变形体
- 缺乏流体动力学
- 并行计算能力有限
Gazebo:ROS生态的核心
Gazebo是开源机器人仿真平台,与ROS深度集成,是机器人研究的重要工具。
技术特点:
- 模块化设计:插件架构,高度可扩展
- 物理引擎:支持ODE、Bullet、DART等多种引擎
- 传感器模拟:完整的传感器生态系统
- 分布式仿真:支持多机分布式计算
应用优势:
- 与ROS无缝集成
- 强大的插件系统
- 丰富的传感器模型
- 支持多机器人仿真
挑战与限制:
- 学习曲线较陡
- 性能优化复杂
- 大规模仿真限制
3.2.2 高性能专业模拟器
MuJoCo:精准物理建模的典范
MuJoCo专注于多关节系统的接触丰富动力学建模,是强化学习研究的首选平台。
技术优势:
- 高精度物理:基于广义坐标的优化算法
- 接触建模:精确的接触和摩擦模拟
- 计算效率:高度优化的求解器
- 生物力学:支持腱驱动和肌肉模型
应用领域:
- 强化学习研究
- 人形机器人控制
- 生物力学分析
- 运动控制算法开发
3.2.3 GPU加速新一代模拟器
Isaac Gym:并行仿真的革命
NVIDIA Isaac Gym开创了GPU大规模并行物理仿真的新时代。
技术突破:
- 大规模并行:单GPU上数千个环境同时仿真
- GPU加速:完全在GPU上运行的物理引擎
- 强化学习优化:专为RL训练优化的接口
- 高吞吐量:百万级样本/秒的训练速度
4. 世界模型的理论基础
4.1 人类认知中的内在世界表示
人类认知系统的一个显著特征是能够构建和维护对外部世界的内在表示。当我们闭上眼睛想象一个场景时,大脑会激活与实际感知相同的神经网络区域,这表明人类拥有强大的内在世界模型。这种能力使我们能够进行心理模拟、预测未来事件,并基于假设情景进行推理。
认知科学研究表明,人类的世界模型具有以下关键特征:层次化表示(从低层感知特征到高层抽象概念)、时空连贯性(保持对象和事件在时间和空间上的一致性)、因果推理能力(理解行动与结果之间的因果关系)、以及泛化能力(将已学知识应用到新情境中)。
4.2 从感知到预测:世界模型的工作机制
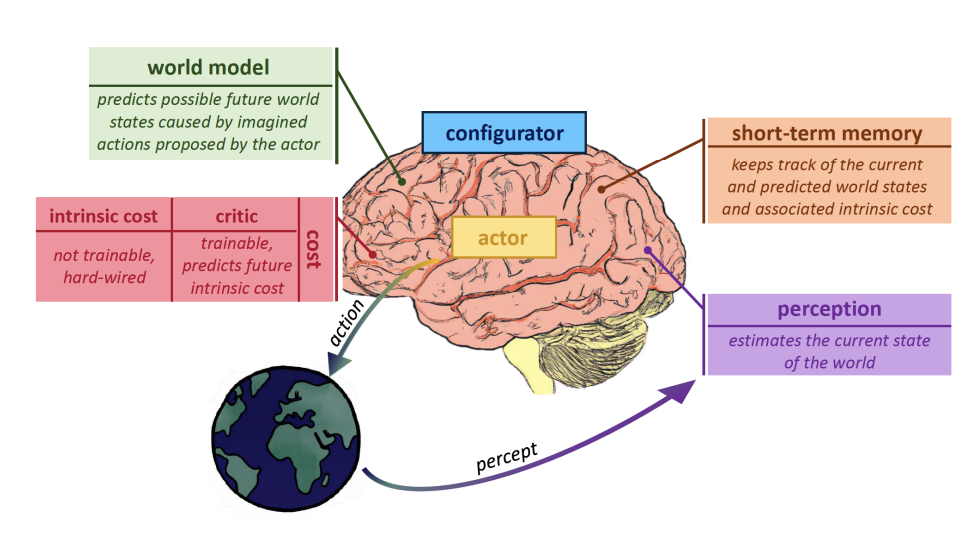
世界模型的核心工作机制
世界模型的工作机制可以分为三个核心阶段:感知编码、状态更新和预测生成。首先,模型将高维的感觉输入(如图像、声音)编码为紧凑的潜在表示;然后,基于当前状态和行动,预测下一个时刻的状态;最后,从预测的状态生成对应的感觉观测。
图18:世界模型数据流处理图
这种机制的优势在于,它能够在压缩的潜在空间中进行推理和规划,大大降低了计算复杂度。同时,通过学习状态之间的转换动力学,模型能够进行多步前瞻,支持长期规划和决策。
4.3 世界模型与传统AI方法的根本差异
| 特征 | 传统端到端AI | 世界模型方法 |
|---|---|---|
| 学习方式 | 直接输入-输出映射 | 环境动态建模 |
| 推理能力 | 反应式响应 | 预测式规划 |
| 样本效率 | 需大量标注数据 | 可在想象中学习 |
| 泛化能力 | 局限于训练域 | 更强的跨域泛化 |
| 可解释性 | 黑盒决策 | 可理解的预测过程 |
| 因果理解 | 统计相关性 | 潜在因果建模 |
传统的AI方法往往采用端到端的学习方式,直接从输入映射到输出,缺乏对环境的显式建模。这种方法在特定任务上可能表现良好,但泛化能力有限,且难以进行可解释的推理。
相比之下,世界模型采用了一种更加类似人类认知的方法:首先构建对环境的理解,然后基于这种理解进行决策。这种方法不仅提高了样本效率(因为可以在想象中进行学习),还增强了泛化能力和可解释性。
5. 世界模型核心架构深度解析
世界模型是人工智能中的一个关键框架,灵感来源于人类大脑形成内部世界表征的能力。这些模型使智能体能够预测未来的状态并规划行动,模拟人类在环境中导航和互动的认知过程。2018年,David Ha和Jürgen Schmidhuber首次提出了世界模型的概念,展示了人工智能可以通过学习环境的压缩生成模型来模拟体验,从而在没有与现实世界直接互动的情况下进行强化学习。
随着视频生成模型的进步,世界模型的能力得到了显著提升。2024年初,视频生成模型如Sora和Kling引起了学术界和工业界的广泛关注,因为它们在高保真度视频合成和物理世界的真实建模方面表现出色。Sora的技术报告强调了将视频生成模型用作物理世界强大引擎的潜力。导航世界模型(NWM)采用了条件扩散Transformer(CDiT),基于过去的体验和导航动作预测未来的视觉观察,使智能体能够通过模拟潜在路径并评估其结果来规划导航轨迹。
Yann LeCun也强调了基于视频的世界模型的重要性,指出人类通过视觉体验,特别是通过双眼视觉来发展内部世界模型。他认为,要实现人类水平的认知,人工智能必须以类似人类的方式进行学习,主要通过视觉感知。这一观点强调了将视频数据整合到世界模型中以捕捉空间和时间信息丰富性的重要性。
在此基础上,最近的视频生成模型发展旨在创建更复杂的世界模型,能够代表和理解动态环境。通过利用大规模视频数据集和先进的神经架构,这些模型努力复制人类感知和与世界互动的方式,为更先进和适应性强的人工智能系统铺平了道路。
…详情请参照古月居

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 24
24 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)