自动化所零样本导航新范式!WMNav:融合VLM和世界模型的室内目标导航
WMNav通过在世界模型框架中利用VLMs,提出了一种新的目标导航方向,显著提高了零样本目标导航的性能。在线好奇心图的引入减少了来回冗余移动,子任务分解模块为策略模块提供了更密集的反馈,两阶段动作提议器策略使导航更有目的性和高效。WMNav展示了在未知环境中进行目标导航的新优化方向,为具身机器人与环境互动开辟了新途径。

- 作者:Dujun Nie1^{1}1, Xianda Guo2^{2}2, Yiqun Duan3^{3}3, Ruijun Zhang1^{1}1, Long Chen1,4,5^{1,4,5}1,4,5
- 单位:1^{1}1中科院自动化研究所,2^{2}2武汉大学计算机学院,3^{3}3悉尼科技大学计算机学院,4^{4}4西安交通大学IAIR,5^{5}5Waytous
- 论文标题:WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
- 论文链接:https://arxiv.org/pdf/2503.02247
- 项目主页:https://b0b8k1ng.github.io/WMNav/
- 代码链接:https://github.com/B0B8K1ng/WMNavigation
主要贡献
- 引入基于世界模型的导航框架:WMNav利用视觉语言模型(VLMs)创建了新的世界模型导航框架,以提升在复杂未知环境中进行目标导航的能力。
- 基于好奇心的记忆策略:提出了使用在线维护的好奇心图来预测环境状态的方法,以减少与环境的高风险交互。
- 子任务分解与反馈机制:通过将目标导航任务分解为多个子任务,并结合反馈机制,提高了VLM推理的可靠性和导航效率。
- 两阶段动作提议策略:采用两阶段动作提议策略,首先进行广泛探索,然后进行精确定位,以提高导航的目的性和效率。
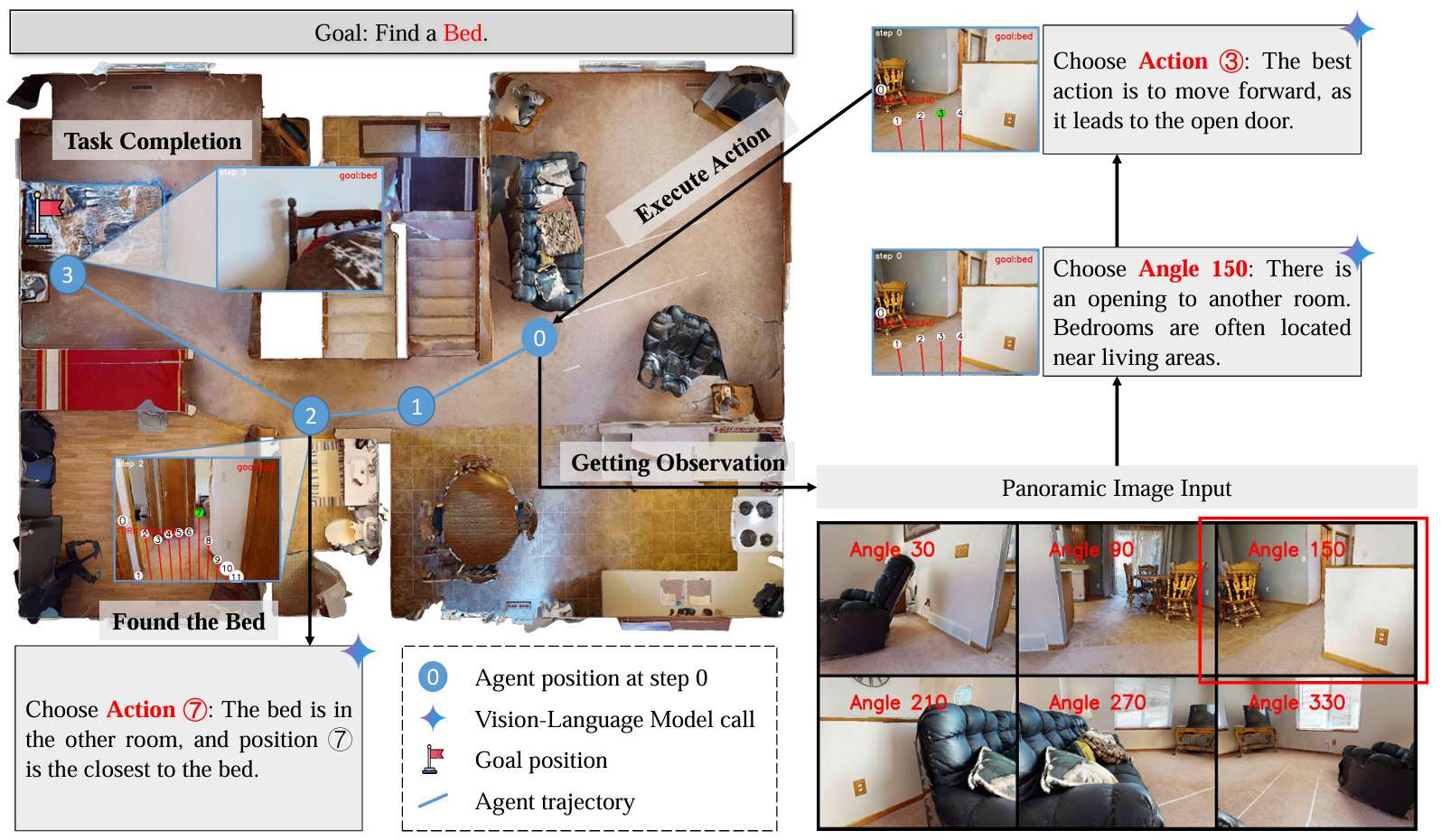
研究背景
研究问题
论文主要解决的问题是零样本目标导航(Zero-Shot Object Navigation, ZSON),即要求智能体在不熟悉的环境中定位并接近一个特定目标物体。
研究难点
该问题的研究难点包括:
- 需要广泛使用语义知识以高效地指导移动,同时精确识别之前未遇到的目标物体;
- 现有方法在处理未见过的物体或房间时表现不佳,依赖于训练数据;
- 大多数方法需要与环境实际交互以实现准确的场景理解,无法利用未来状态和潜在行动结果的预测信息。
相关工作
-
零样本对象目标导航:
- 现有的对象导航方法分为监督方法和零样本方法。监督方法通常依赖于在已知环境中训练的视觉编码器和强化学习/模仿学习策略,但在未见过的对象/房间中表现不佳。
- 零样本方法通过开放词汇的场景理解来解决这个问题,使用图像映射或基于前线的地图来识别目标对象的位置。
-
基础模型引导的导航:
- 视觉语言模型(VLMs)和大语言模型(LLMs)在导航任务中具有互补作用。VLMs通过多模态嵌入直接对齐视觉观察和文本目标,而LLMs则通过对象-房间关联预测和语义映射进行常识推理。
- VLMs在目标驱动的导航中可能比LLMs更高效,因为它们能够更好地处理视觉信息和进行空间推理。
-
世界模型:
- 世界模型起源于经典的强化学习,用于模拟经验以提高样本效率。近年来,研究探索了使用大语言模型作为抽象世界模型,优先考虑任务抽象而非精确模拟。
- 尽管LLMs在简单环境中表现出色,但它们在视觉决策方面存在困难。因此,将VLMs整合到世界模型中在视觉导航任务中更具优势,因为VLMs结合了视觉基础和语义推理能力。
研究方法
任务定义
- 目标:对象目标导航任务要求智能体在一个未知的室内环境中探索,并导航到一个给定类别中的一个任意实例。智能体从指定的初始位置开始,通过RGB-D观测和实时姿态来确定动作,以找到目标。
- 成功标准:如果智能体在距离目标小于预设阈值dthresd_{\text{thres}}dthres的位置停止,则认为任务成功。
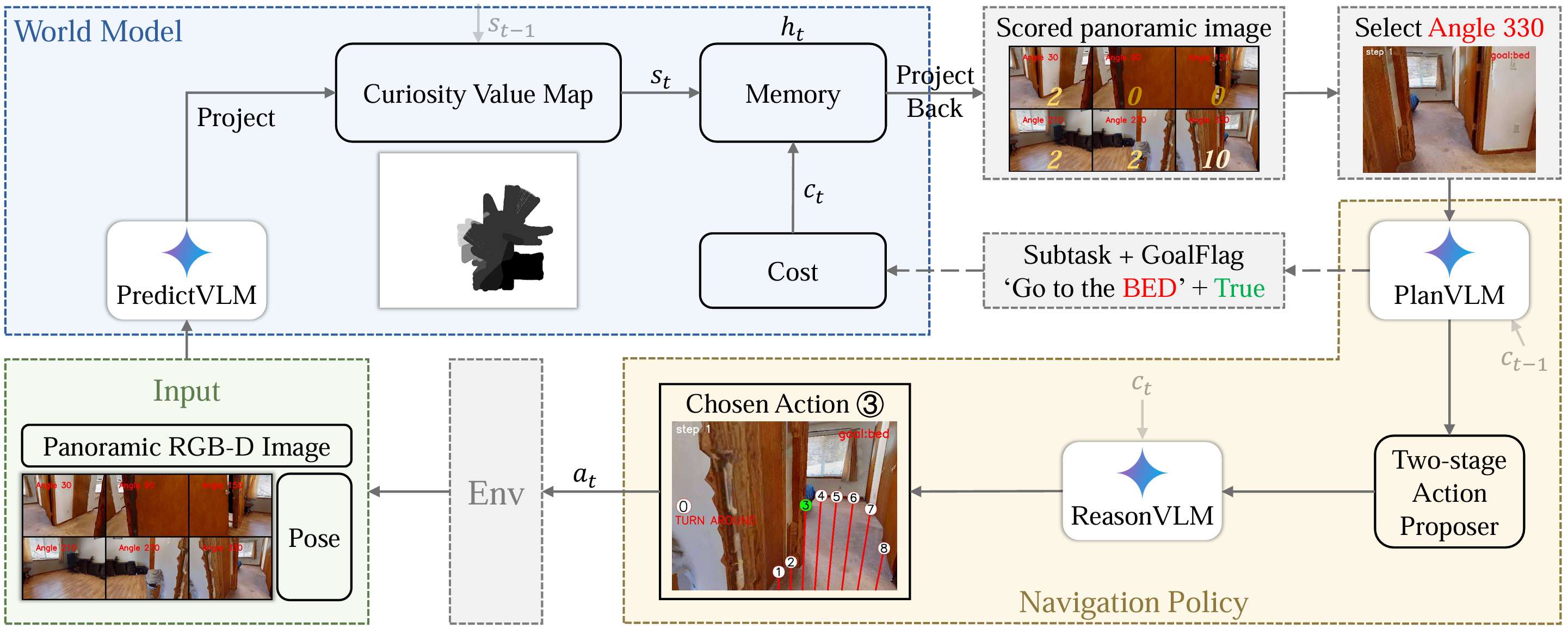
框架概述
- 全景理解:为了实现全面感知,智能体进行一系列旋转并捕获六个不同的RGB-D图像,将其转换为一个全景图像ItpanI_t^{\text{pan}}Itpan。
- 世界模型:由PredictVLM和记忆模块组成,记忆模块包括好奇心图和代价。世界模型不接收环境的实际奖励信号,仅用于预测和简化未来环境状态。
- 导航策略模块:访问环境奖励信息,PlanVLM和ReasonVLM根据代价配置提示来优化整个策略模块的输出。
世界模型
VLM状态预测
- 核心能力:估计世界状态并预测可能的未来状态变化。使用VLM作为预测器,设计了一种新的提示策略来引导VLM对室内场景进行合理预测。
- 好奇心值计算:VLM输出每个方向的好奇心值,表示目标存在的可能性,分数范围为0到10。
Scoret=PredictVLM(Itpan) \text{Score}_t = \text{PredictVLM}(I_t^{\text{pan}}) Scoret=PredictVLM(Itpan)
其中,Scoret\text{Score}_tScoret 是当前全景视图中每个方向的好奇心值。
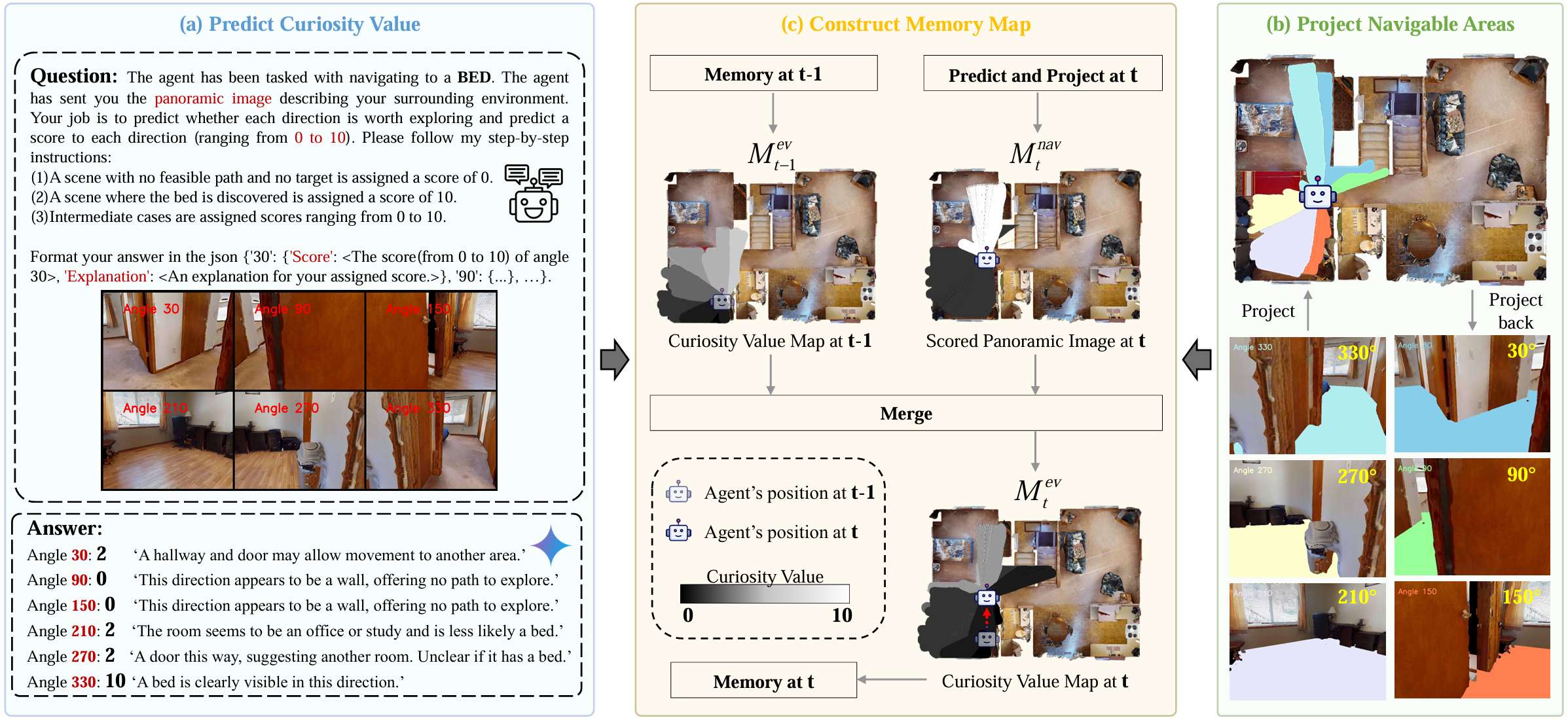
好奇心图构建
- 大小:好奇心图McvM^{\text{cv}}Mcv 的大小为 KaTeX parse error: Expected 'EOF', got '_' at position 10: \text{map_̲size} \times \t…,每个像素值代表场景中位置的好奇心值。
- 更新过程:通过投影变换将自中心视角的分数转换为俯视图,并结合前一步的好奇心图进行更新。
Mtnav=Projection(Scoret) M_t^{\text{nav}} = \text{Projection}(\text{Score}_t) Mtnav=Projection(Scoret)
其中,MtnavM_t^{\text{nav}}Mtnav 是从自中心视角投影到俯视图的好奇心图。
Mtcv(u,v)=min(Mt−1cv(u,v),Mtnav(u,v)) M_t^{\text{cv}}(u, v) = \min(M_{t-1}^{\text{cv}}(u, v), M_t^{\text{nav}}(u, v)) Mtcv(u,v)=min(Mt−1cv(u,v),Mtnav(u,v))
其中,MtcvM_t^{\text{cv}}Mtcv 是更新后的好奇心图。
代价模块
- 代价模块用于提供环境奖励。使用子任务和目标标志作为代价。
- 子任务的生成过程详见子任务分解部分。目标标志指示PlanVLM是否在选定的图像中找到目标,设置为True或False。
- 代价作为提示的一部分输入到PlanVLM和ReasonVLM,以隐式优化导航策略的输出。
子任务分解

- 将最终目标分解为多个中间子任务,每一步识别一个子任务,有助于获得更多的环境反馈。
- 更新后的好奇心值图存储在记忆中后,投影回当前可导航区域,计算每个方向的平均好奇心值以获得最终好奇心值分数 Scoret‾\overline{Score_t}Scoret 。
- 选择具有最高分数的方向 αˉ\bar{\alpha}αˉ ,并在该图像上进行更具体的规划。
- 输入选定图像 It(αˉ)I_t(\bar{\alpha})It(αˉ) 和前一步的子任务SubTask t−1_{t-1}t−1 到PlanVLM,输出新的子任务SubTask t_{t}t 和目标标志GoalFlag t_{t}t:
SubTaskt,GoalFlagt=PlanVLM(It(αˉ),SubTaskt−1) \text{SubTask}_t, \text{GoalFlag}_t = \text{PlanVLM}(I_t(\bar{\alpha}), \text{SubTask}_{t-1}) SubTaskt,GoalFlagt=PlanVLM(It(αˉ),SubTaskt−1)
两阶段动作提议器
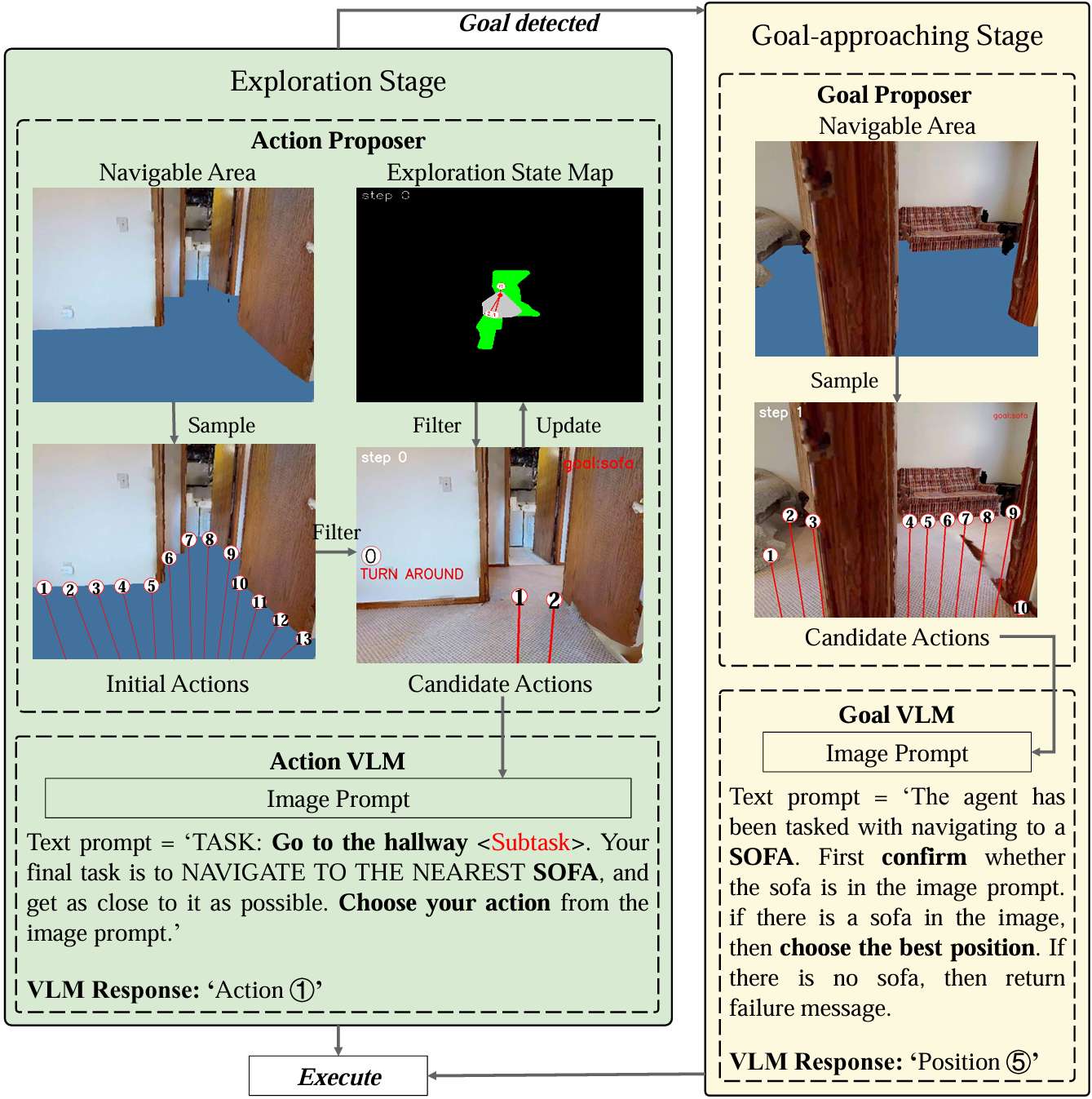
-
使用动作提议器准备ReasonVLM的动作选择。极坐标动作空间从可导航区域采样。
-
第一阶段是探索阶段,任务是探索最可能包含目标的区域,最终发现并准确定位其位置。
a‾t=ReasonVLM(SubTaskt,Goalt,Itann) \overline{a}_t = \text{ReasonVLM}(\text{SubTask}_t, \text{Goal}_t, I_t^{\text{ann}}) at=ReasonVLM(SubTaskt,Goalt,Itann)
其中 a‾t=(r‾t,θ‾t)\overline{a}_t = (\overline{r}_t, \overline{\theta}_t)at=(rt,θt) 是最终选择的动作。 -
第二阶段是目标接近阶段,当目标出现在当前观测中时,使用类似动作提议器的策略来确定目标的精确位置,以使停止条件更可靠。智能体的停止条件设置为:
StopFlag={True,if DistanceToGoal<dthresFalse,else \text{StopFlag} = \begin{cases} \text{True}, & \text{if DistanceToGoal} < d_{\text{thres}} \\ \text{False}, & \text{else} \end{cases} StopFlag={True,False,if DistanceToGoal<dthreselse
其中DistanceToGoal是当前位置和目标位置之间的欧几里得距离。
实验
数据集和评估指标
- 数据集:实验使用了两个主要的数据集:HM3D和MP3D。
- HM3D:用于Habitat 2022 ObjectNav挑战,提供2000个验证集episode,涵盖20个验证环境和6个目标对象类别。HM3D v0.2是HM3D的新版本,具有更高的质量和几何精度。
- MP3D:包含11个高逼真度场景和2195个episode,用于验证,涵盖21个目标对象类别。
- 评估指标:
- 采用成功率(Success Rate, SR)和按路径长度加权的成功率(Success Rate Weighted by Inverse Path Length, SPL)作为评估指标。
- SR表示完成任务的比例,SPL通过计算实际路径长度与最优路径长度的倒数比率来量化智能体的导航效率。
实现细节
- 导航步数:设置智能体的最大导航步数为40。
- 智能体配置:智能体采用圆柱形身体,半径0.18米,高度0.88米,配备640 x 480分辨率的RGB-D相机,水平视场角(HFoV)为79度,俯仰角为14度。
- 停止阈值:设置停止距离阈值为0.1米,即如果智能体在距离目标小于0.1米时停止,则认为任务成功。
- VLM选择:主要使用Gemini VLM进行实验,因其成本低且效果显著。
与其他方法的比较
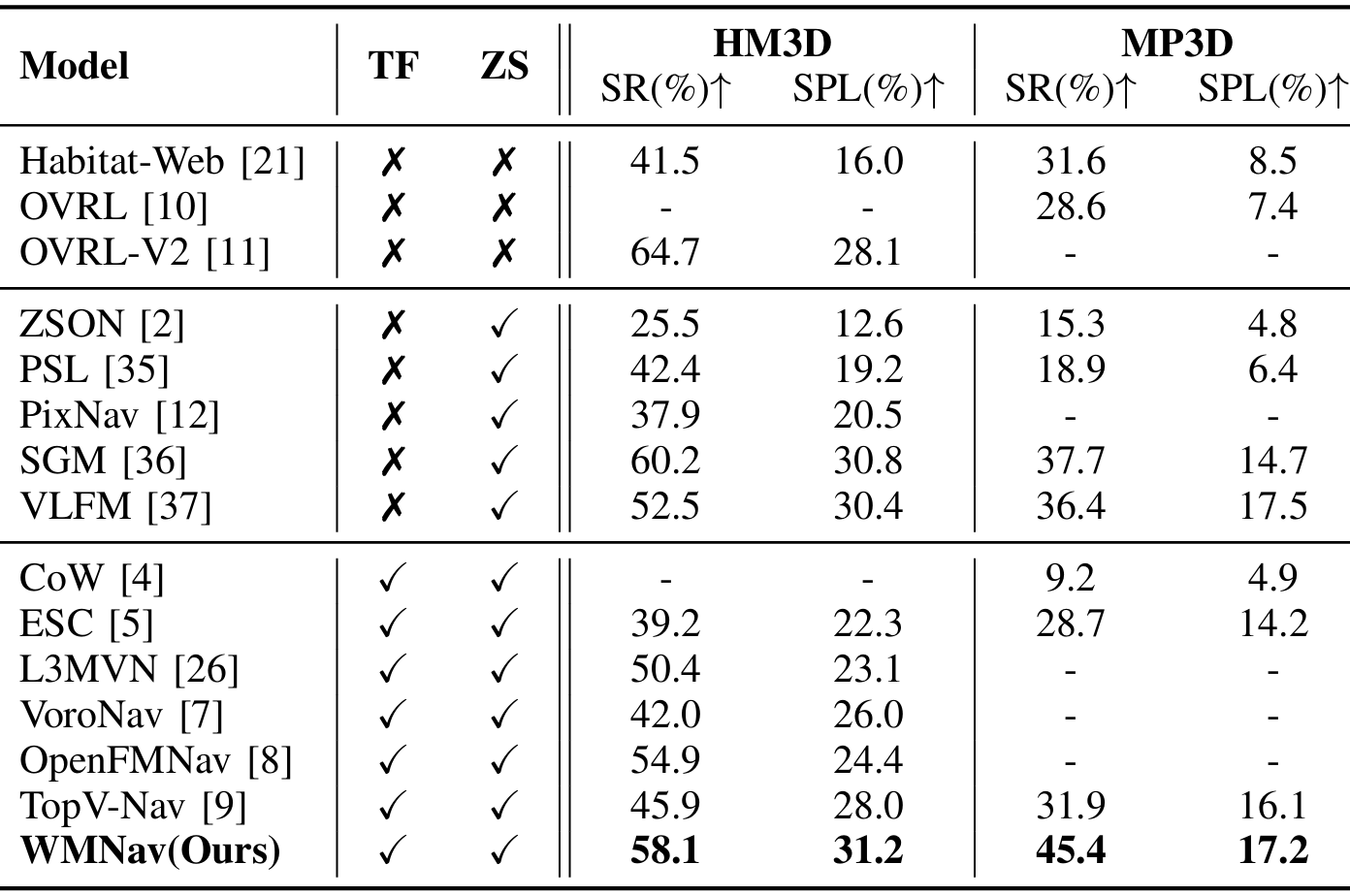
- 比较对象:将WMNav方法与其他代表性的对象导航方法在MP3D和HM3D基准上进行比较。
- 结果:WMNav在所有零样本方法中表现最佳,显示出显著的优越性。具体来说,在HM3D上,WMNav的成功率(SR)提高了3.2%,SPL提高了3.2%;在MP3D上,SR提高了13.5%,SPL提高了1.1%。
- 分析:WMNav通过使用在线好奇心图和两阶段动作提议策略,有效地提高了导航效率和可靠性。
消融研究
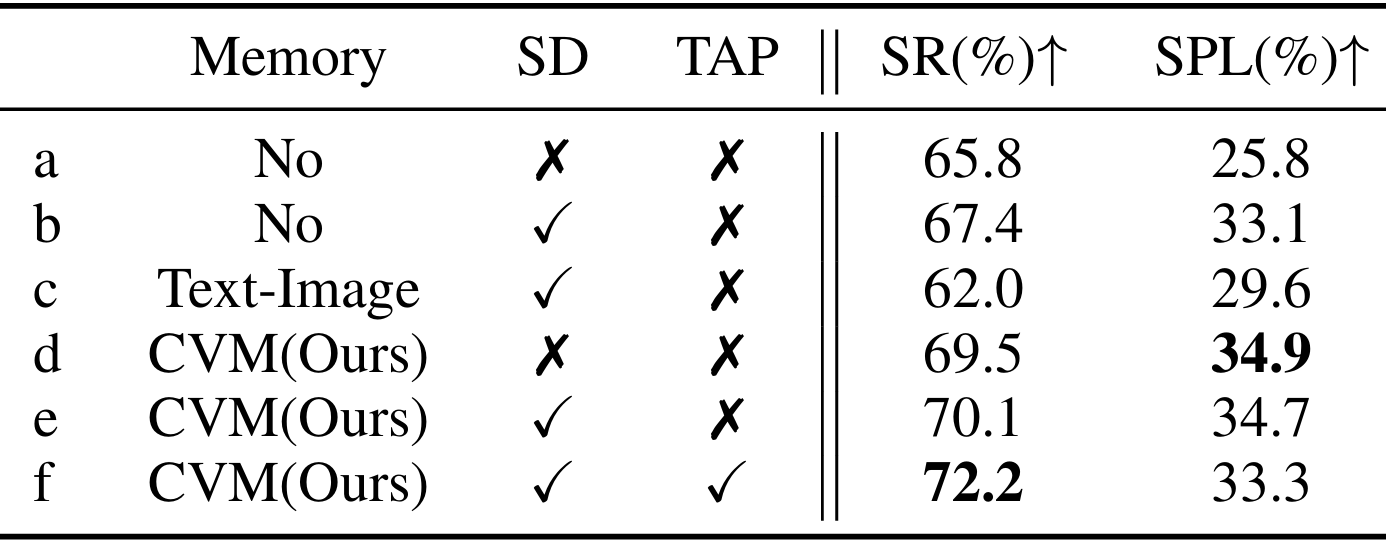
- 不同模块的影响:通过消融研究验证了子任务分解、好奇心图和两阶段动作提议策略对导航性能的提升。

- 不同VLM的影响:评估了不同VLM在导航任务中的能力,结果表明Gemini 1.5 Pro在任务中表现出色。
- 不同记忆策略的影响:比较了无记忆、文本-图像记忆和好奇心图三种策略,结果显示好奇心图在SR和SPL指标上均有改进。
总结
- WMNav通过在世界模型框架中利用VLMs,提出了一种新的目标导航方向,显著提高了零样本目标导航的性能。
- 在线好奇心图的引入减少了来回冗余移动,子任务分解模块为策略模块提供了更密集的反馈,两阶段动作提议器策略使导航更有目的性和高效。
- WMNav展示了在未知环境中进行目标导航的新优化方向,为具身机器人与环境互动开辟了新途径。


立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)