重磅!阿里达摩院发布首个VLA与世界模型统一架构RynnVLA-002:97.4%成功率刷新认知
《RynnVLA-002:统一视觉-语言-动作与世界模型的创新架构》 摘要:本文提出RynnVLA-002模型,首次将视觉-语言-动作(VLA)模型与世界模型统一于单一框架。该模型通过双向增强机制实现互补:世界模型利用物理规律优化动作生成,而VLA增强视觉理解以提升图像预测精度。创新性地采用混合动作生成策略,包括"动作注意力掩码"解决离散动作误差累积,以及连续ActionTra


论文链接:https://arxiv.org/abs/2511.17502
代码链接:https://github.com/alibaba-damo-academy/RynnVLA-002
亮点直击
统一架构:RynnVLA-002,这是一个将视觉-语言-动作(VLA)模型与世界模型(World Model)统一在单一框架中的“动作世界模型”(Action World Model)。
双向增强:实现了 VLA 与世界模型的互补——世界模型利用物理规律优化动作生成,而 VLA 增强了视觉理解以支持更精准的图像预测。
混合动作生成策略:针对离散动作生成的误差累积问题,提出了“动作注意力掩码”策略;针对实机操作的平滑性与泛化性问题,引入了连续的 Action Transformer 头。
卓越性能:在 LIBERO 仿真基准测试中,在无预训练的情况下达到了 97.4% 的成功率;在真实世界 LeRobot 实验中,集成世界模型使整体成功率提升了50%。
解决的问题
本工作主要针对现有架构的以下局限性进行改进:
- VLA 模型的缺陷:
-
动作理解不足:动作仅作为输出存在,缺乏内部的显式表征。
-
缺乏想象力:无法预测动作执行后的世界状态演变,缺乏前瞻性。
-
缺乏物理常识:无法内化物体交互、接触或稳定性等物理动力学。
-
-
世界模型的缺陷:无法直接生成动作输出,存在功能鸿沟,限制了其在显式动作规划场景中的应用。
-
自回归动作生成的缺陷:离散动作生成容易产生误差传播(Error Propagation),且在真实机器人上容易出现抖动且泛化性差。
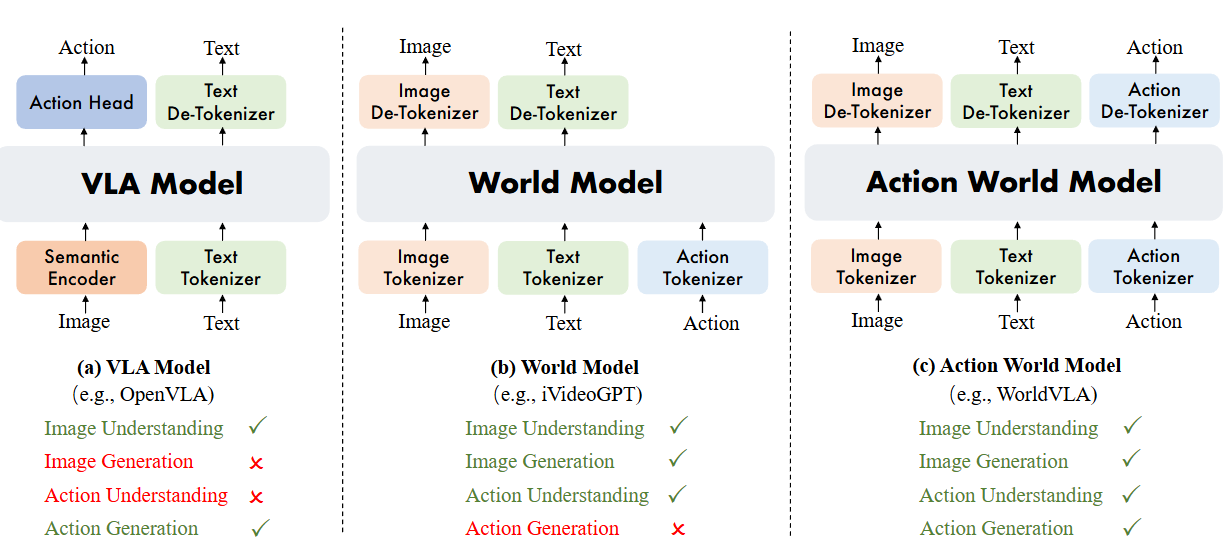
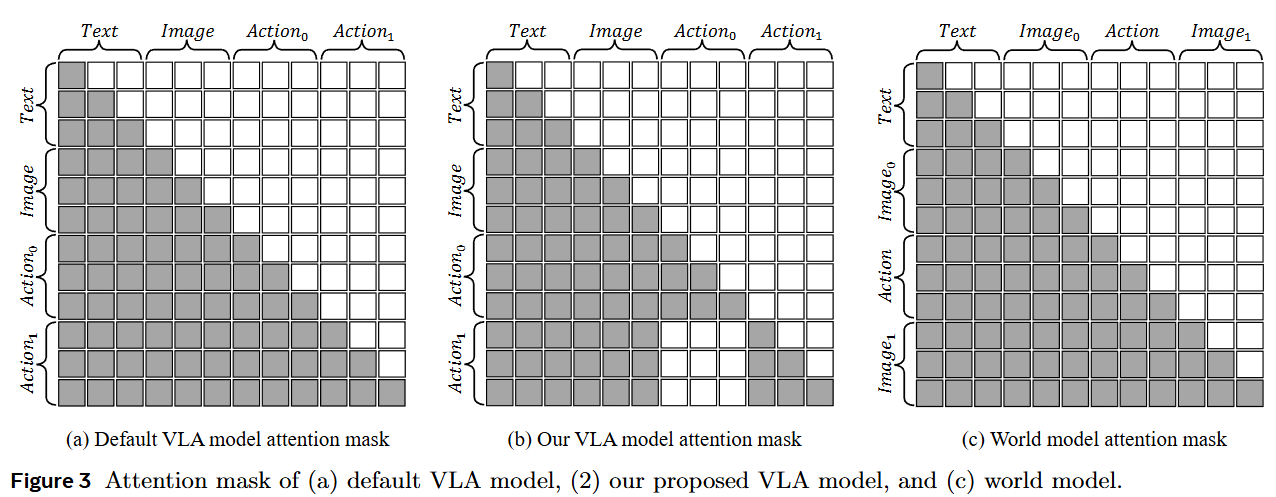
图1(a) VLA 模型根据对图像的理解生成动作;(b) 世界模型根据对图像和动作的理解生成图像;(c) 动作世界模型将对图像和动作的理解与生成统一起来。
提出的方案
本工作提出了 RynnVLA-002,这是一个自回归的动作世界模型。
-
统一词表:使用三个独立的 Tokenizer 分别对图像、文本和动作进行编码,并共享同一个词表,使得不同模态可以在同一个 LLM 架构下统一进行理解和生成。
-
联合训练:模型既可以作为 VLA 根据观察生成动作,也可以作为世界模型根据动作预测未来图像。
-
混合生成机制:保留离散联合建模的同时,加入了一个连续的 Action Transformer 头,以适应真实世界的连续控制需求。
应用的技术
-
基础架构:初始化自 Chameleon 模型(一种统一图像理解与生成的模型)。
- Tokenization(分词技术):
-
图像:使用 VQ-GAN,压缩率 16,码本大小 8192。
-
文本:BPE Tokenizer。
-
动作/状态:将连续维度离散化为 256 个 bin。
-
-
动作注意力掩码(Action Attention Masking):在离散动作生成中,通过修改 Attention Mask,使得当前动作仅依赖于文本和视觉输入,而无法看到之前的动作 Token,从而阻断自回归过程中的误差累积。
-
Action Transformer:引入一个连续动作头(类似于 ACT),通过并行解码生成平滑的动作轨迹,解决离散模型的过拟合与抖动问题。
达到的效果
- 仿真实验(LIBERO):
-
RynnVLA-002-Continuous 取得了 97.4% 的平均成功率,在 Spatial、Object、Goal 和 Long 任务上均表现优异。
-
优于 OpenVLA、SpatialVLA、 等强基线模型,且无需大规模机器人操作预训练数据。
-
- 真机实验(LeRobot SO100):
-
在干扰物(Distractors)和多目标(Multi-Target)场景下表现出极强的鲁棒性。
-
相比 GR00T N1.5 和 ,在复杂场景下的成功率高出 10% 到 30%。
-
-
互补验证:消融实验证明,引入世界模型数据训练显著提升了 VLA 的操作成功率(尤其是抓取任务),反之 VLA 数据也提升了世界模型的视频生成质量。
方法框架
概览
RynnVLA-002 的整体架构旨在统一体现式 AI 的两大基础模型:
-
VLA 模型:策略 根据语言目标 、本体感知状态 和历史观测 生成动作 :
-
世界模型:模型 根据过去观测和动作预测下一个观测 :
本工作混合了 VLA 模型数据和世界模型数据来训练 RynnVLA-002,这是一个整合模型 ,共享参数组 。这种双重特性使得模型可以根据用户查询,灵活地作为 VLA 或世界模型运行。
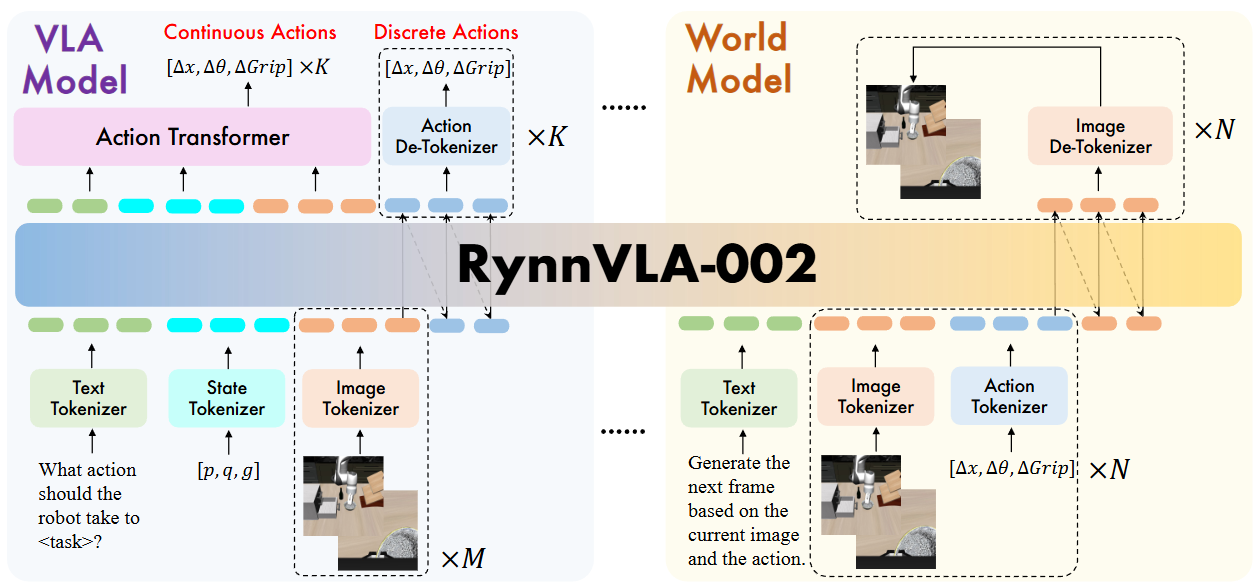
RynnVLA-002 概览。RynnVLA-002 在训练过程中涉及 VLA 模型数据和世界模型数据。
数据Tokenization
-
Tokenizers:模型初始化自 Chameleon。涉及四种 Tokenizer:图像、文本、状态和动作。
-
图像:使用 VQ-GAN,并增加了针对特定区域(如人脸、显著物体)的感知损失。图像被编码为离散 Token( 图像对应 256 个 Token)。
-
文本:BPE Tokenizer。
-
状态与动作:将机器人本体状态和动作的每个连续维度离散化为 256 个区间(bin)之一。
-
词表:所有模态的 Token 共享一个大小为 65536 的词表。连续动作则通过 Action Transformer 生成原始数值,不进行 Token 化。
-
-
VLA 模型数据结构:
Token 序列为
{text} {state} {image-front-wrist} {action}。模型根据指令、状态和 个历史图像生成 个动作块(Action Chunk)。
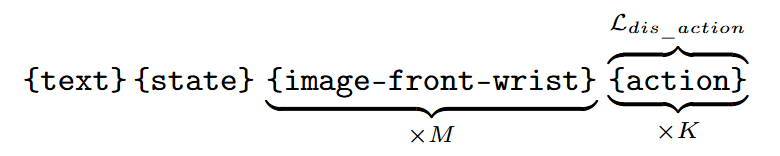
-
世界模型数据结构: Token 序列为
{text} {images-front-wrist} {action} {images-front-wrist}。任务是根据当前图像和动作生成下一帧图像。文本前缀统一为“Generate the next frame based on the current image and the action.”。
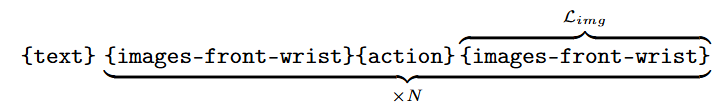
-
训练目标:混合两种数据进行训练,总损失函数为 。
动作块生成
-
离散动作块的注意力掩码 (Attention Mask for Discrete Action Chunk) : 为了提高效率和成功率,模型需要生成多个动作。然而,传统的自回归方式会导致误差传播,即早期动作的错误会影响后续动作。为此,本工作设计了一种特定的 动作注意力掩码 (Action Attention Mask)(如图 3(b) 所示)。该掩码确当前动作的生成仅依赖于文本和视觉输入,而禁止访问先前的动作 Token。这种设计使得自回归框架能够独立生成多个动作,有效缓解了误差累积问题。
-
连续动作块的 Action Transformer (Action Transformer for Continuous Action Chunk) : 尽管离散模型在仿真中表现尚可,但在真实世界中由于光照、物体位置等动态变量,表现不佳且动作不平滑。为此,本工作增加了一个 Action Transformer 模块:
-
原理:处理完整的上下文(语言、图像、状态 Token),并利用可学习的 Action Queries 并行输出整个动作块(Action Chunk)。
-
优势:架构更紧凑,不易在有限数据上过拟合;并行生成所有动作,推理速度显著快于顺序生成的自回归基线;生成的轨迹更平滑稳定。
-
损失函数:使用 L1 回归损失 。
-
最终总损失函数:
实验
指标 (Metrics) 本工作的评估分为两部分。为了评估 VLA 模型,本工作测量其在每个任务 50 次部署展示(rollout)中的成功率,每次都在不同的状态下初始化。为了评估世界模型,本工作使用四个标准指标在保留验证集上测量其视频预测准确性:Fréchet 视频距离 (FVD)、峰值信噪比 (PSNR)、结构相似性指数 (SSIM) 和学习感知图像块相似度 (LPIPS)。
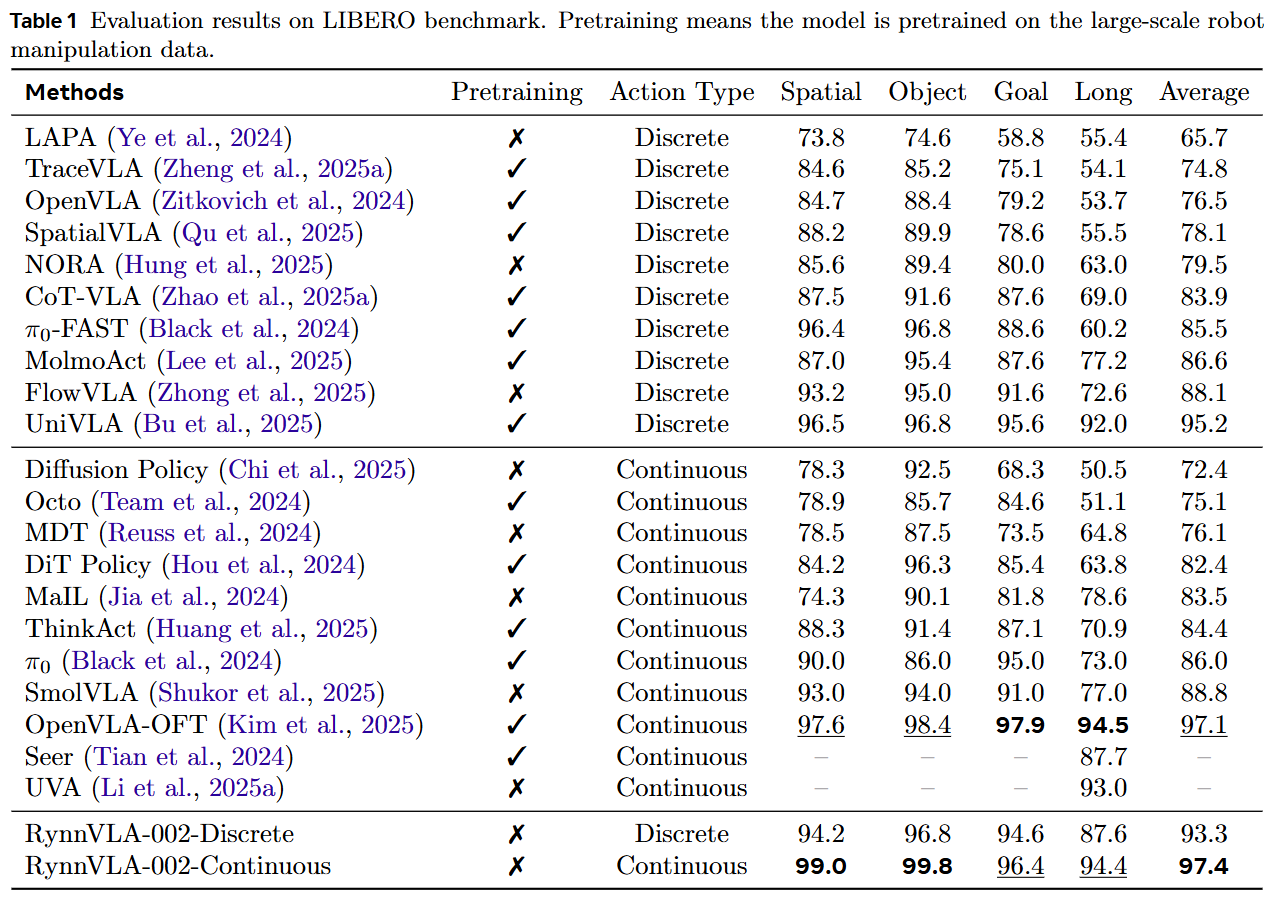
基准测试结果 (Benchmark Results) 本工作分别评估了离散动作和连续动作的性能。如下表1 所示,本工作的 RynnVLA-002 在离散动作下达到了 93.3% 的高成功率,在连续动作下达到了 97.4% 的高成功率,证明了本工作核心设计原则的有效性:联合学习 VLA 建模和世界建模、用于离散动作生成的注意力掩码(attention mask)机制,以及添加的连续动作 Transformer (Action Transformer)。令人惊讶的是,即使没有任何预训练,本工作的 RynnVLA-002 仍然与在 LIBERO-90 或大规模真实机器人数据集上预训练的强基线模型表现相当。
真实世界机器人结果
数据集 (Datasets)
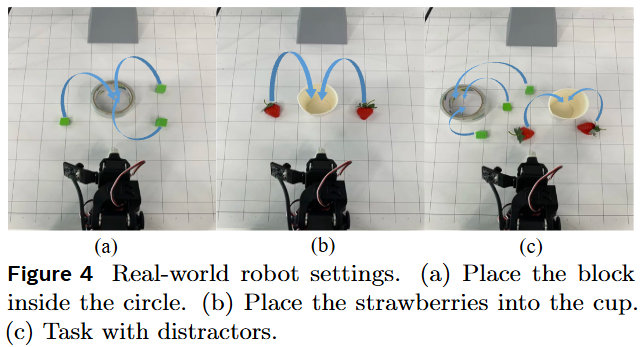
本工作整理了一个使用 LeRobot SO100 机械臂收集的新真实世界操作数据集。所有轨迹均通过人类远程操作获得的专家演示。本工作定义了两个抓取和放置任务进行评估: (1) 将方块放入圆圈内:强调基本的物体检测和抓取执行(248 个演示); (2) 将草莓放入杯子中:需要细粒度的定位和抓取点预测(249 个演示)。
基线 (Baselines)
本工作与两个强大的开源基线进行了比较:GR00T N1.5 和 。对于这两种方法,本工作从官方预训练检查点进行初始化,并在用于本模型的同一 SO100 数据集上对其进行微调。本工作采用这些基线官方代码库中的相同配方进行微调。
评估 (Evaluation)
如图 4 所示,本工作的评估涵盖三种场景:
-
单目标操作 (Single-target) :桌面上仅有一个目标物体;
-
多目标操作 (Multi-target) :存在多个目标物体;
-
带干扰物的指令跟随 (Instruction-following with distractors) :目标物体和干扰物同时出现。
如果机器人在预定义的时间预算内将至少一个目标物体放入指定位置,则视为试验成功。如果发生以下情况,则试验失败:(1) 超出时间限制;(2) 机器人在一个目标上累计超过五次连续的抓取失败尝试;(3) 在带干扰物的指令跟随设置中,智能体尝试操作任何干扰物体。每个任务测试 10 次,本工作报告成功率。
结果
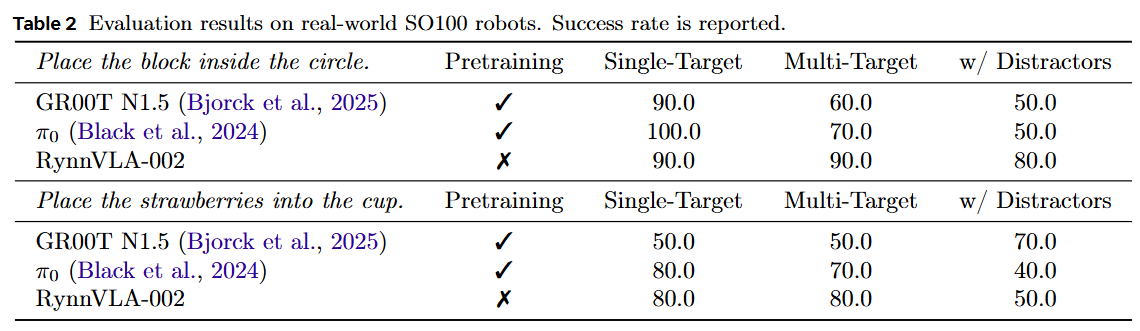
下表 2 展示了真实世界机器人的实验结果。RynnVLA-002 在没有预训练的情况下,取得了与 GR00T N1.5和 具有竞争力的结果。值得注意的是,RynnVLA-002 在杂乱环境中的表现优于基线。例如,在“放置方块”任务的多目标任务和充满干扰物的场景中,RynnVLA-002 的成功率均超过 80%,超过基线 10% 到 30%。
消融实验

-
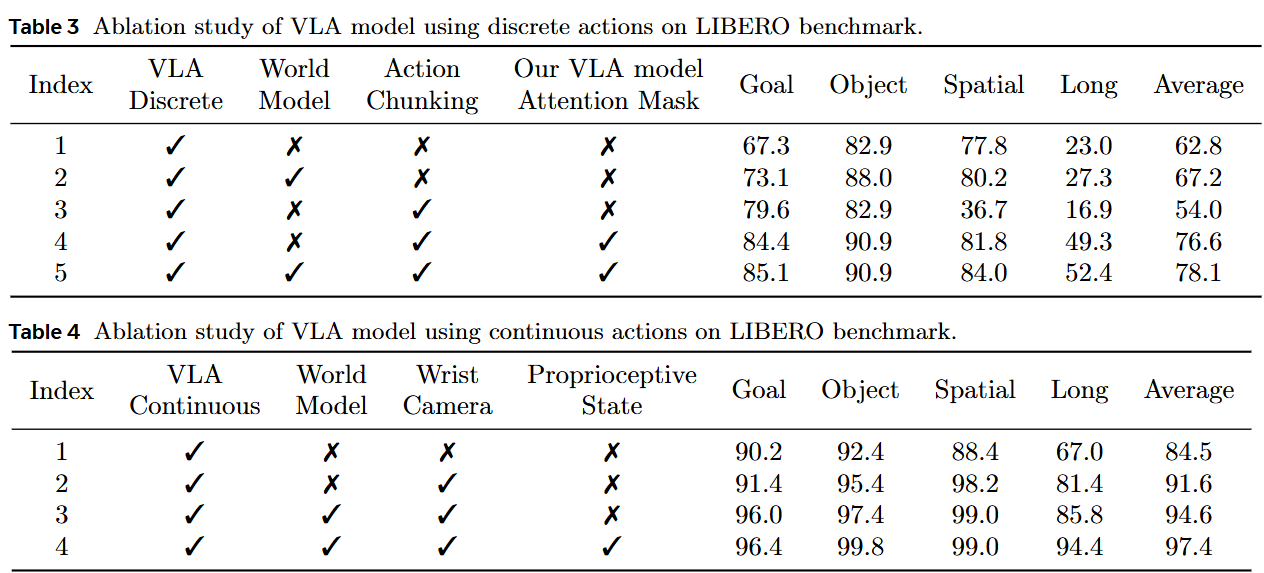
世界模型反哺 VLA:在 LIBERO 上,加入世界数据后,离散动作平均成功率从 62.8% → 78.1%;真实机器人若缺世界数据,成功率直接掉至 30% 以下。可视化发现,联合训练后机械臂会“主动重试”抓取,说明其对物体动态关注度更高。
-
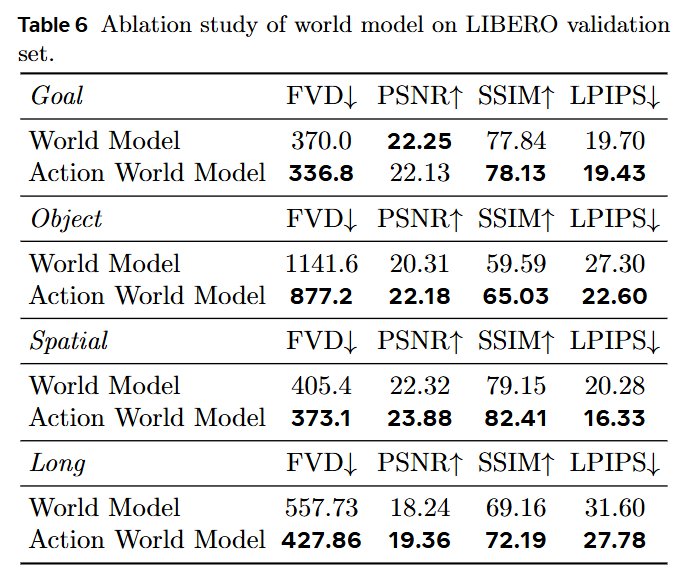
VLA 反哺世界模型:混合训练后的世界模型在 FVD、PSNR、SSIM、LPIPS 上持平或优于纯 World 模型;视频可视化显示,基线世界模型常漏预测“碗被成功抓起”的关键帧,而本文模型能准确生成抓取过程中的接触与抬升。
-
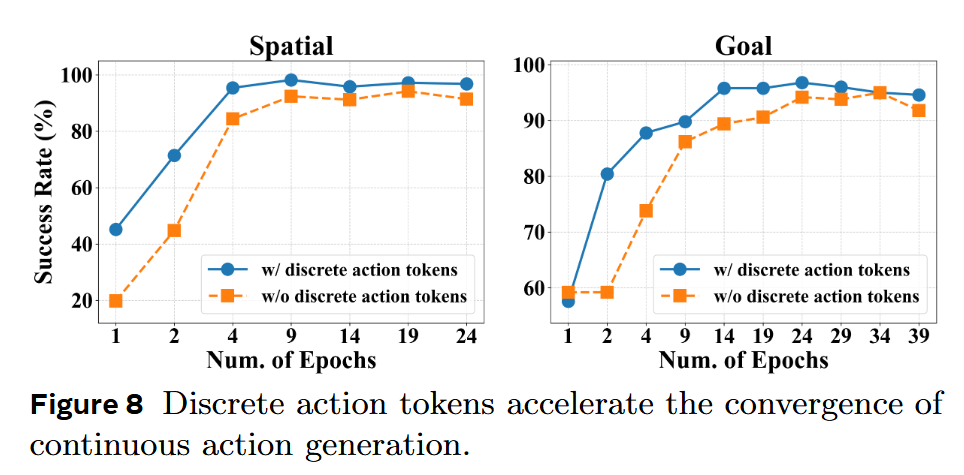
离散动作 token 的预训练作用:把离散动作 token 作为连续头的辅助输入,可显著加速收敛(图 8)。
-
腕部相机 & 本体状态:在真实场景缺一不可;缺失时任一组件都会导致抓取时机错误或完全失败。
-
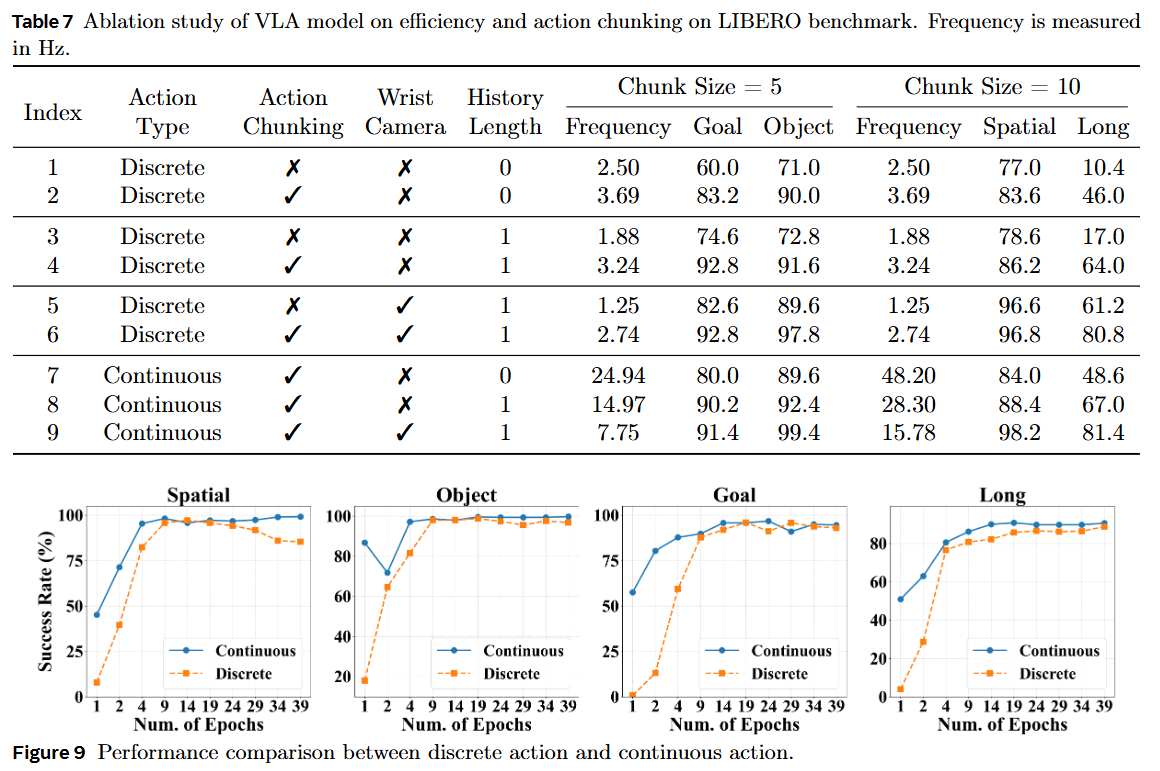
效率与 chunk 长度:连续动作推理频率几乎随 chunk 长度线性增长,48 Hz 下仍保持 97% 成功率;离散动作通过 chunking 也能将单步 2.5 Hz 提升到 3.7 Hz。
-
世界模型预训练:先纯粹用世界数据预训练 1 阶段,再切入 VLA 任务,可将“Goal”类任务从 67.3% 提升到 73.1%,验证“物理知识冷启动”对后续策略学习有效。

总结
RynnVLA-002,一个统一的框架,它将 VLA 和世界模型集成在一起,并证明了它们之间能够相互增强。通过这一贡献,本工作旨在为具身智能(Embodied AI)研究社区提供一种具体的方法论,以实现 VLA 与世界模型之间的协同作用。此外,本工作相信这项研究有助于为跨越文本、视觉和动作的多模态理解与生成奠定统一的基础。
参考文献
[1] RynnVLA-002: A Unified Vision-Language-Action and World Model

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)