解锁具身智能时空密码!LLaVA-ST:多模态大模型的细粒度时空理解
论文提出的LLaVA-ST是首个能够端到端处理细粒度时空多模态理解任务的MLLM。通过引入LAPE和STP模块,LLaVA-ST显著提高了模型在多个基准测试中的性能。实验结果表明,LLaVA-ST在处理时空交错任务时具有显著优势,并且在开放式视频问答和多选题视频问答任务中也表现出色。LLaVA-ST的提出为未来的MLLMs在细粒度多模态理解任务上的改进提供了重要的参考。

-
作者: Hongyu Li1, Jinyu Chen1, Ziyu Wei1, Shaofei Huang2,3, Tianrui Hui2, Jialin Gao4, Xiaoming Wei4, Si Liu1
-
单位:1北航人工智能学院,2合肥工业大学,3中科院信息工程研究所,4美团
-
论文标题:LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
-
论文链接:https://arxiv.org/pdf/2501.08282
-
代码链接:https://github.com/appletea233/LLaVA-ST
主要贡献
-
论文提出LLaVA-ST模型,首个能够端到端处理细粒度空间、时间和时空交错多模态理解任务的模型。
-
语言对齐的位置嵌入(LAPF)通过在文本空间中直接嵌入表示空间和时间坐标的特征作为视觉位置嵌入,简化了视觉和语言之间细粒度时空对应关系的对齐。
-
空间时间整合模块通过将视频特征的时空压缩过程解耦为两个独立的点对区域注意力处理流,来保持更多的时空关系。
-
为了支持模型的训练,构建了一个包含430万个样本的ST-Align数据集,并提出了一个渐进的训练策略,使模型能够逐步学习内容对齐、坐标对齐和多任务能力。
研究背景
研究问题
论文主要解决的问题是现有的多模态大模型在处理时空细粒度理解任务时存在困难,主要表现在难以同时有效地进行时间和空间定位。
研究难点
该问题的研究难点包括:
-
多模态坐标对齐的困难,即视觉和文本坐标表示的对齐复杂;
-
视频特征压缩过程中保留细粒度时空信息的挑战。
相关工作
-
多模态理解任务分类:
-
一般视觉理解:包括视频字幕生成和视觉问答等任务,关注于生成与视觉内容相关的文本。
-
细粒度空间理解:涉及识别和定位图像或视频中的具体空间坐标,如指代表达理解和密集接地字幕生成。
-
细粒度时间理解:要求在视频中识别和定位特定时间片段,如时间视频定位和密集视频字幕生成。
-
同时进行细粒度空间和时间理解:要求模型同时进行空间和时间上的细粒度理解,如时空视频定位。
-
-
多模态大模型的发展:
-
现有的MLLMs在视觉和语言任务上取得了一定进展,但通常只能处理一到两类任务。
-
论文扩展了MLLMs的能力,使其能够处理同时需要细粒度时空理解的任务,并引入了新的任务类型。
-
-
现有模型的局限性:
-
现有模型在同时进行细粒度时空理解方面存在挑战,难以实现端到端的处理。
-
论文提出的LLaVA-ST模型通过统一处理时空细粒度理解任务,展示了其在这些任务上的优越能力。
-
模型架构
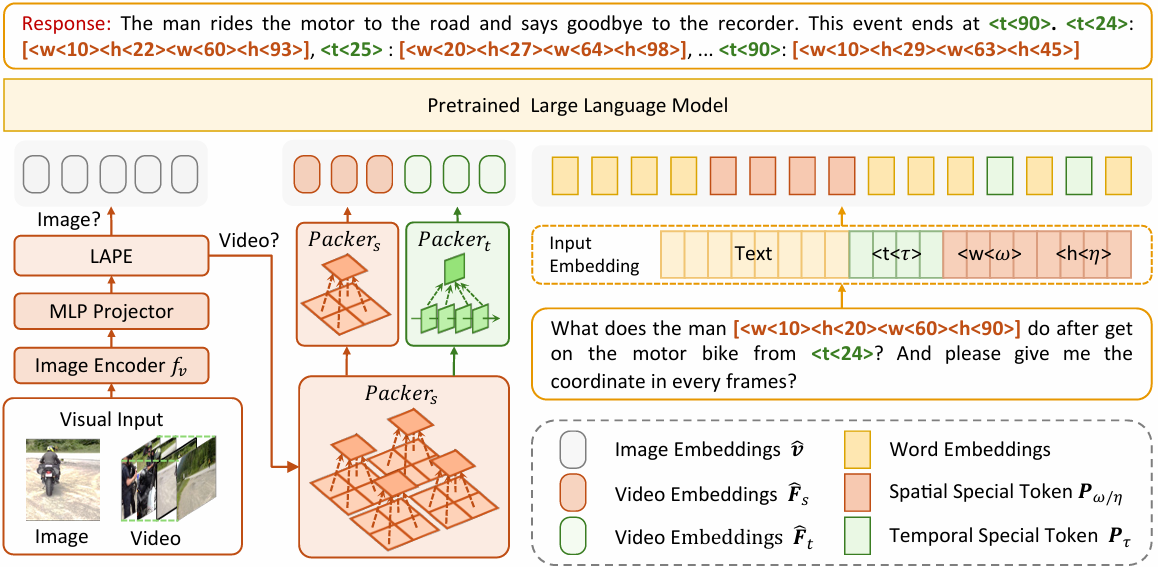
整体架构概述
-
LLaVA-ST的设计旨在处理视频和图像输入。对于视频输入,模型从视频的每帧中采样一定数量的帧(例如,每隔几帧采样一帧),然后通过视觉编码器提取特征。对于图像输入,模型直接处理单个图像。
-
提取的特征通过多层感知机(MLP)映射到文本空间,以便与语言模型进行交互。
语言对齐的位置嵌入
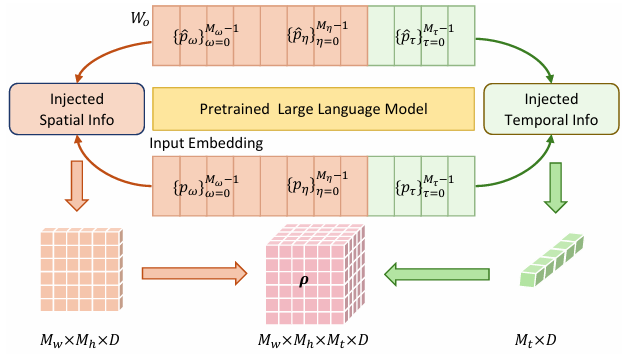
-
LAPF模块通过将文本输入中的坐标信息嵌入到视觉特征中,以简化视觉和语言之间的坐标对齐。
-
具体来说,LAPF使用特殊标记来表示空间和时间坐标,并将这些坐标嵌入到视觉特征中作为位置嵌入。
-
这种方法避免了复杂的跨模态坐标对齐问题,使得模型能够更好地理解文本和视觉特征之间的关系。
p^ω,η,τ=p^ω+pω2+p^η+pη2+p^τ+pτ2
其中,p^ω/η/τ 和 pω/η/τ分别是文本和视觉特征中的行向量。
时空关系整合
-
STP模块用于高效地压缩视频特征,特别是在时间和空间维度上进行压缩。它采用两步过程:首先减少特征的空间分辨率,然后在空间和时间维度上分别进行压缩。
-
第一步,将视频特征的空间分辨率降低,得到区域特征序列:
F^=packers(v^,k1×k1)
-
第二步,分别沿时间和空间维度压缩区域特征,得到压缩后的特征:
F^s=packers(F^,k2×k2)F^t=packert(F^,σ)
-
在每个步骤中,STP使用点对区域的注意力机制来保留更多的细节信息,从而在压缩过程中保持细粒度的时空关系。
特征处理流程
-
对于视频输入,经过LAPF和STP处理的特征被展平并输入到语言模型中。语言模型结合视觉特征和语言嵌入来处理细粒度多模态理解任务。
-
对于图像输入,经过LAPF处理的特征可以直接展平并输入到语言模型中。
通过这些组件,LLaVA-ST能够有效地处理细粒度的空间和时间多模态理解任务,展示了其在复杂任务中的强大能力。
ST-Align和训练策略
ST-Align 数据集
ST-Align 是一个专为细粒度时空多模态理解设计的训练数据集,旨在解决当前数据集中缺乏细粒度时空交错多模态理解任务的问题。该数据集包含大约430万个训练样本,涵盖了多种任务:
-
Spatio-Temporal Video Grounding:根据事件描述定位视频中事件主体的时空位置。
-
Event Localization and Captioning:给定事件的起始位置和边界框,定位事件的结束位置并提供描述。
-
Spatial Video Grounding:根据事件持续时间和文本描述,定位事件主体的轨迹。
此外,每个任务还提供了2000个验证样本,用于评估模型在细粒度时空理解方面的能力。
训练策略
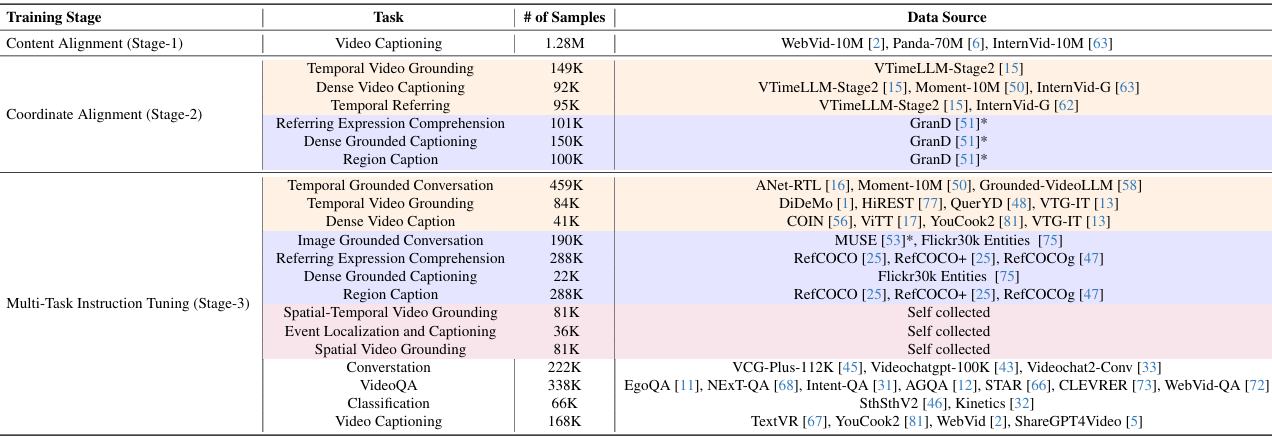
为了增强训练过程的稳定性和提高模型的最终性能,论文提出了一个渐进的训练策略,分为三个阶段:
-
内容对齐:
-
在这一阶段,使用视频字幕数据来初步实现视觉和语言的内容对齐。固定语言模型的参数,仅训练STP模块的参数。由于缺乏细粒度多模态理解数据,设置扰动最小化。
-
使用的学习率为 1×10−3。
-
-
坐标对齐:
-
在这一阶段,使用需要细粒度视觉理解的任务来对齐视觉和文本空间中的时空坐标。数据主要来自通过自动生成方法构建的细粒度多模态理解数据集。
-
包括三种类型的任务:REC(指代表达理解)、DGC(密集接地字幕生成)和TR(时间参考),用于训练空间位置嵌入的对齐。还包括TVG(时间视频定位)、DVC(密集视频字幕生成)和TR(时间参考),用于沿时间维度对齐坐标。
-
使用的学习率为 2×10−4,并使用LoRA技术微调LLM的主网络。
-
-
多任务指令微调:
-
在这一阶段,引入39个高质量的标注数据集,赋予模型一般的视觉问答和细粒度多模态理解能力。包括空间和时间细粒度理解任务以及文本响应任务,如REC、TVG和视频问答。
-
还包括新的LoRA参数,采用与阶段2相同的训练策略。
-
实验
实现细节
-
模型配置:
-
LLaVA-ST使用SigLIP-400M作为视觉编码器,分辨率为384x384。
-
预训练模型为Llava-onevision 7B。模型参数包括Mw、Mh、Mt(分别为100)、k1(9)、k2(3)和σ(20)。
-
训练批次大小在不同阶段有所不同,第一阶段为384,第二和第三阶段为192。
-
训练在ST-Align上进行1个epoch,使用AdamW优化器和余弦学习率衰减。
-
-
硬件:在48个A100 GPU上训练72小时。
主要结果

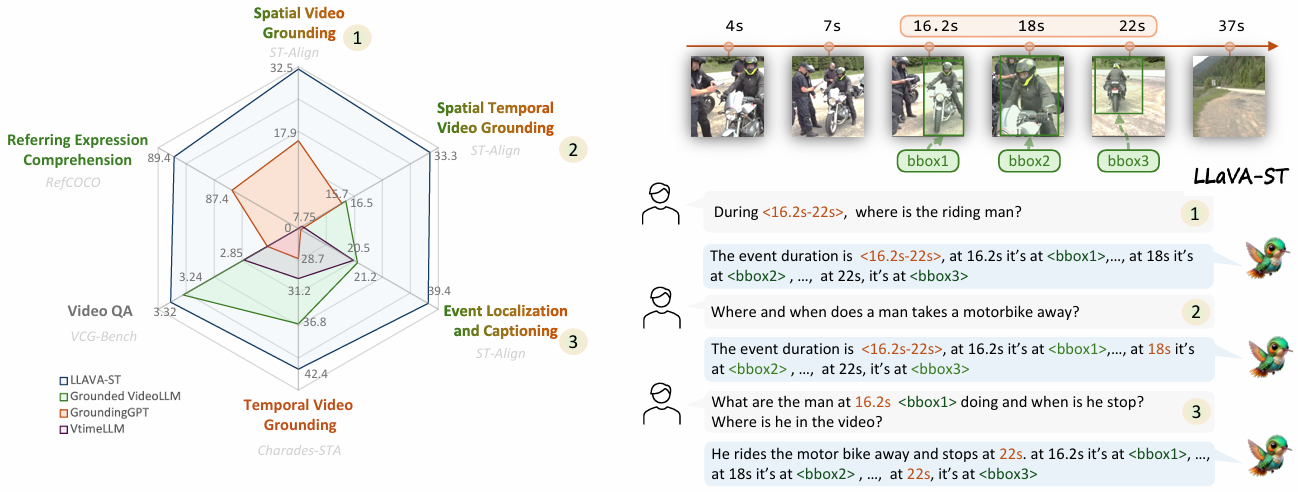
- 时空交错任务:
-
LLaVA-ST在ST-Align基准测试中表现出色,特别是在STVG、ELC和SVG任务上。
-
与其他模型相比,LLaVA-ST在这些任务上取得了显著的性能提升。
-
例如,在STVG任务中,LLaVA-ST在mtIoU上达到了43.8,优于Grounded-VideoLLM的33.0,并且在msIoU上达到了22.8,优于GroundingGPT的9.2。
-
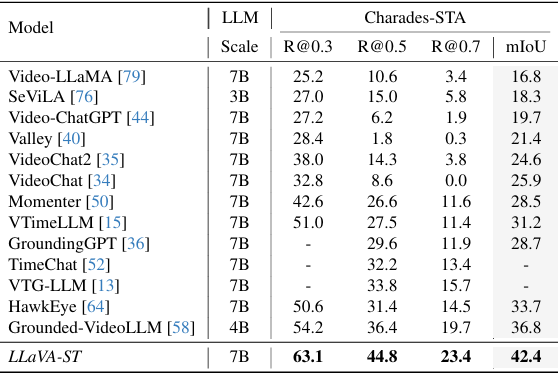
- 时间视频定位:
-
在Charades-STA基准测试中,LLaVA-ST在mIoU上表现优异,达到了31.2,优于Grounded-VideoLLM的28.7。
-
这表明LLaVA-ST在时间定位任务上具有强大的能力。
-
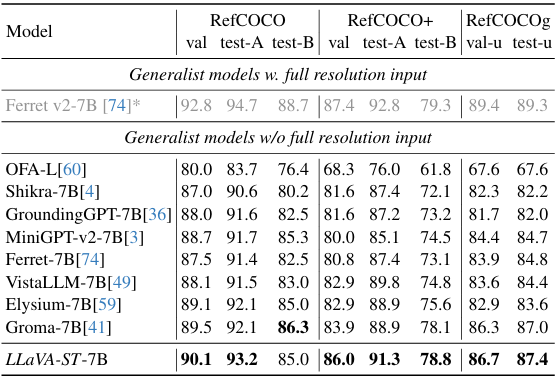
- 指代表达理解:
-
在RefCOCO、RefCOCO+和RefCOCOg数据集上,LLaVA-ST在细粒度空间理解任务上表现出色,尤其是在RefCOCO+数据集上,验证集和测试-A集的准确率分别提高了2.1%和2.4%。
-
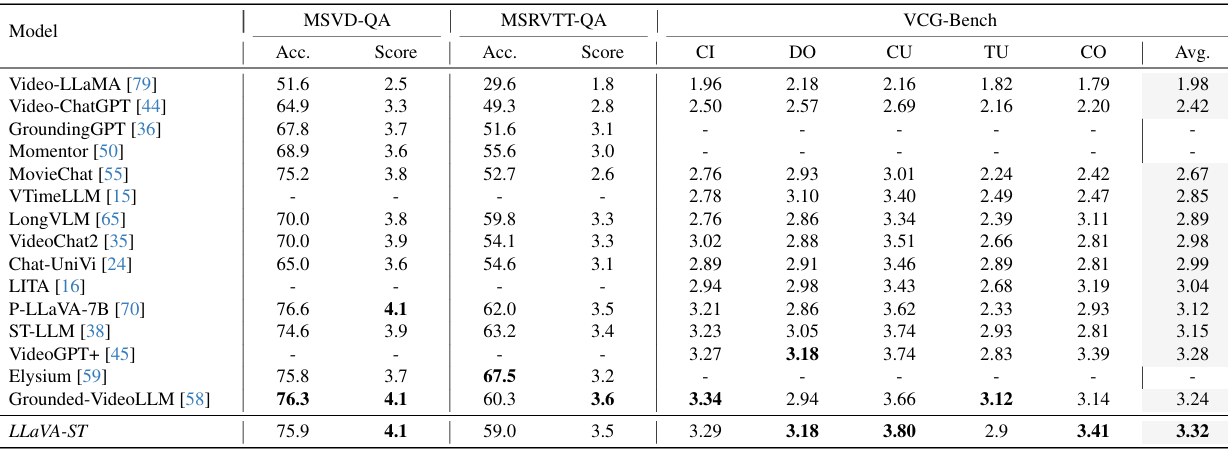
- 开放式视频问答:
-
在VCG-Bench数据集上,LLaVA-ST取得了最高的平均分数3.32,并在MSVD-QA和MSRVTT-QA基准测试中也表现出色。
-
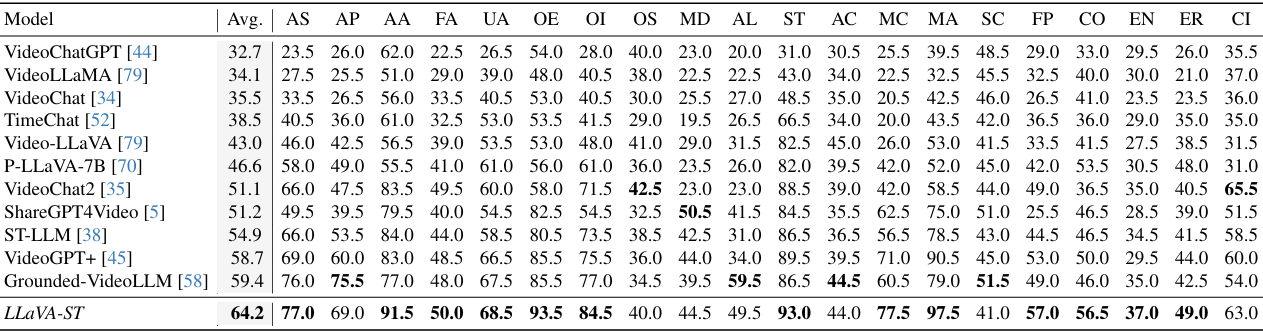
- 多选视频问答:
-
在MVBench数据集上,LLaVA-ST取得了当前最佳的平均分数,显示出在需要高时空细节信息的任务上的显著改进。
-
消融研究
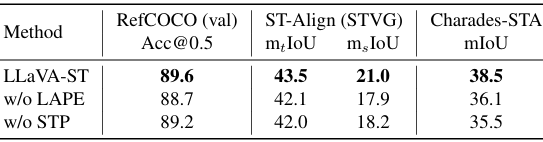
- 模块消融:
-
通过移除LAPF和STP模块,研究了它们对模型性能的影响。
-
结果表明,LAPF和STP模块对模型的贡献显著,特别是在处理复杂的时空对齐任务时。
-
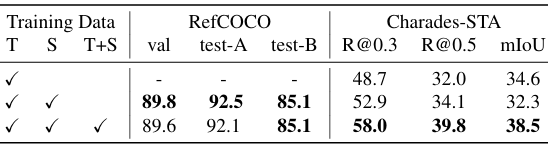
- 训练数据消融:
-
研究了不同类型训练数据对模型性能的影响。
-
结果表明,时空交错数据对于提高模型的时空定位能力至关重要。
-
总结
-
论文提出的LLaVA-ST是首个能够端到端处理细粒度时空多模态理解任务的MLLM。
-
通过引入LAPE和STP模块,LLaVA-ST显著提高了模型在多个基准测试中的性能。
-
实验结果表明,LLaVA-ST在处理时空交错任务时具有显著优势,并且在开放式视频问答和多选题视频问答任务中也表现出色。
-
LLaVA-ST的提出为未来的MLLMs在细粒度多模态理解任务上的改进提供了重要的参考。


立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)