RoboBrain 与大小脑协作:通向可落地具身智能的新路径探索
我们可以通过一个例子来深入理解:当向模型发出“我渴了”这样抽象的语言指令时,大脑并不会简单地匹配某一个固定动作,而是会先结合当前视觉输入,对环境进行整体理解,例如在任务规划过程中,模型会识别桌面上存在多个可用杯子,并基于语义与常识推理,选择“重新拿一个新的纸杯去接水”这一更合理的操作方案。从技术目标上看,行业并未放弃对“大小脑模型”的追求,这一模型的目标也正被更清晰地重新定义:如何在统一系统中,让
文末可下载pdf
过去两年,具身智能被反复提及为“大模型之后的下一个浪潮”。然而,当大语言模型和多模态模型开始尝试进入真实物理世界时,一个现实问题迅速浮出水面:通用模型并未自然转化为可落地的通用机器人智能。在复杂、长时序、强约束的物理任务中,传统端到端多模态模型逐渐暴露出泛化能力不足、可解释性差、跨本体迁移困难等系统性瓶颈,也正是在这一背景下,行业开始探索更多解决路径。
在前不久的 OpenLoong 校园行·走进北京系列活动中,来自北京智源研究院具身智能大模型研究中心的技术专家围绕“具身智能系统中的大脑—小脑协同机制”发表了主题演讲,深入讨论了在复杂物理任务中,如何通过层级化建模与模块协作,更好地协调感知、决策与运动控制之间不断放大的尺度差异与时间约束。这场分享也为社区提供了一个重新审视具身智能系统设计逻辑的重要切口。
本文将基于这场分享,以第三方视角对演讲内容以及“具身大小脑协作”这一技术进行技术分析与趋势解读,尝试回答一个核心问题:具身智能如何在保持模型能力持续演进的同时,逐步走向可用、可扩展与可迁移的工程体系。
端到端多模态模型进入物理世界后的新挑战
在通用视觉问答、语言理解与多模态推理等任务中,多模态大模型已经展现出接近“范式跃迁”的能力,这让许多人都开始期待具身智能是不是也能迎来属于自己的“ChatGPT式”高光时刻。
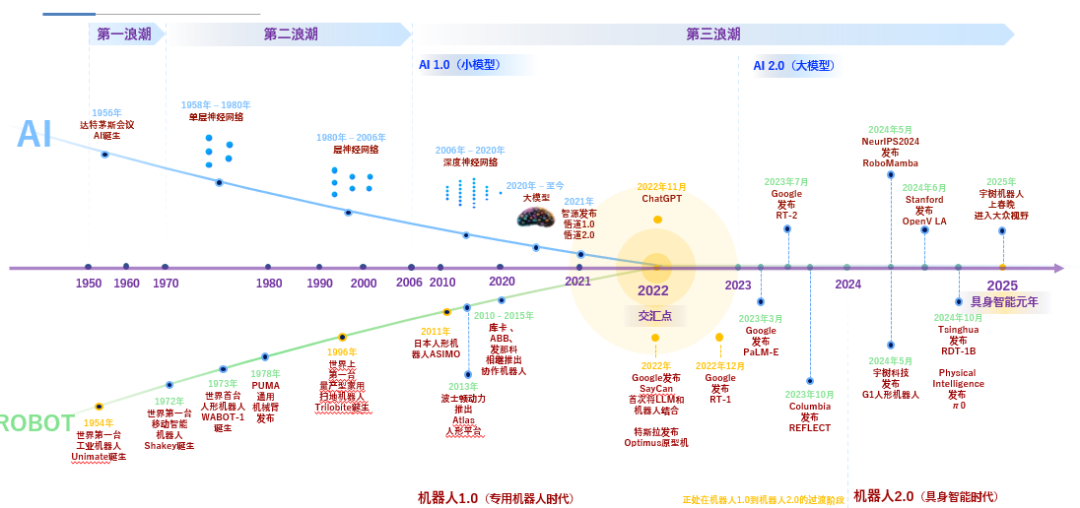
在2023年之前,大多数机器人系统仍主要停留在“单任务能力”阶段。无论是抓取、放置,还是基础的手眼协调,这类能力通常依赖精心设计的控制策略与有限感知输入,并且高度依赖固定环境与先验假设。系统的智能更多体现在局部优化,而非对复杂任务的整体理解。进入2024年,随着多模态模型的引入,机器人开始具备处理多种任务的能力,模型可以在同一环境中完成多样化操作,甚至在一定程度上理解语言指令与视觉信息之间的关系。而2025年之后,大家都在期待下一阶段:面向多机器人、多任务、多环境的通用具身智能。在这一设想中,大型端到端多模态模型将作为统一的智能中枢,能够在不同机器人形态与复杂场景中发挥作用,实现真正意义上的跨本体泛化。
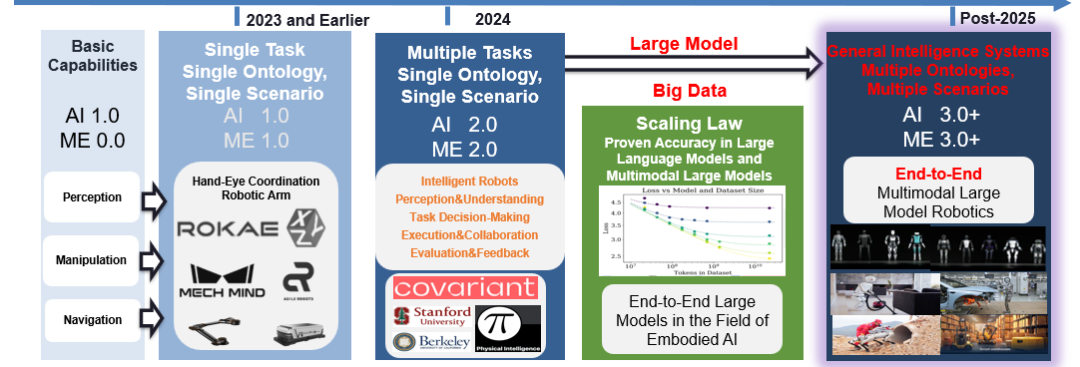
然而,现实挑战恰恰出现在这一“规模扩展”阶段。当前的端到端模型在实际工程中,仍然普遍存在难以使用、难以适应、难以推广的问题,它们在受控演示与学术基准上表现亮眼,但在长期运行、跨场景部署与系统维护成本等方面,尚未形成可复制的工程范式。这也是为什么,具身智能领域至今仍未出现类似“ChatGPT 时刻”的关键原因之一。
从技术目标上看,行业并未放弃对“大小脑模型”的追求,这一模型的目标也正被更清晰地重新定义:如何在统一系统中,让感知、规划与控制以更合理的方式协同工作,使模型能力能够被稳定承载、持续扩展,并适应真实物理世界的复杂性。
大小脑协作:一种更“友好”的具身智能架构选择
“具身大小脑协作”作为一种逐渐被广泛关注的系统框架,其思路是一种面向复杂物理任务的系统分层与职责重组,其核心思想并不复杂:将高层认知与低层执行解耦。在该框架中,具身“大脑”主要负责多模态感知、任务理解、空间推理与高层规划等认知层任务;而具身“小脑”则专注于运动控制、技能执行与实时反馈调节,直接应对物理世界中的不确定性。
这种分层设计,使系统能够在不同时间尺度上运行不同类型的智能:高层决策可以相对缓慢但具备全局视野,而底层控制则能够以毫秒级响应处理物理扰动。两者通过清晰接口形成闭环协作,而非相互替代。
01 模块化
大小脑协同框架赋予具身智能体模块化优势,具备可扩展架构、高效开发与 强适应性三大特性。
02 泛化性
基于VLM开发的大脑具备丰富的多模态认知能力,且不受小脑模型的影响。
03 可解释
决策过程更加透明,提升人机协同效率。
这种结构的价值首先体现在泛化能力与工程可控性上。大脑基于视觉-语言模型构建,能够在不依赖具体硬件的前提下进行任务拆解和决策推理;小脑则针对具体本体进行技能适配,使同一认知模型能够在不同机器人之间复用。同时,模块化设计也使系统在调试、诊断与迭代过程中具备更高的可解释性,有助于定位问题来源并进行针对性优化。
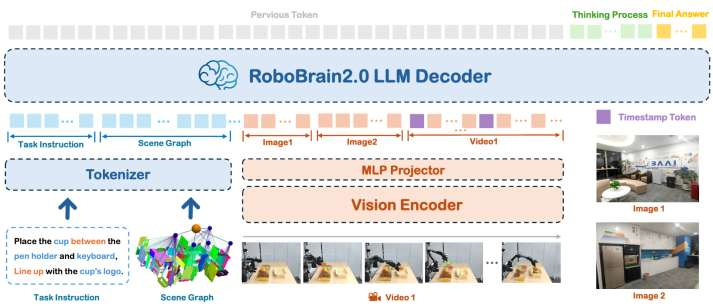
RoboBrain:连接抽象指令与可执行行为的具身大脑模型
如果说具身智能的难点在于“从理解到行动”,那么智源研究院研发的 RoboBrain 正是试图打通这一步的具身大脑模型。它关注的是如何让机器人在复杂环境中真正理解人类的抽象指令,并将这种理解转化为可执行的行动方案。
具体来看,RoboBrain 位于大小脑协作框架中的“大脑”层,负责融合视觉感知与语言理解,对当前场景和任务意图进行整体建模。它并不直接输出底层控制信号,而是生成一系列结构化的中间表达,包括任务规划(Planning)、可操作区域预测(Affordance)以及操作轨迹(Trajectory),为下游执行模块提供清晰、可约束的决策依据。
我们可以通过一个例子来深入理解:当向模型发出“我渴了”这样抽象的语言指令时,大脑并不会简单地匹配某一个固定动作,而是会先结合当前视觉输入,对环境进行整体理解,例如在任务规划过程中,模型会识别桌面上存在多个可用杯子,并基于语义与常识推理,选择“重新拿一个新的纸杯去接水”这一更合理的操作方案。
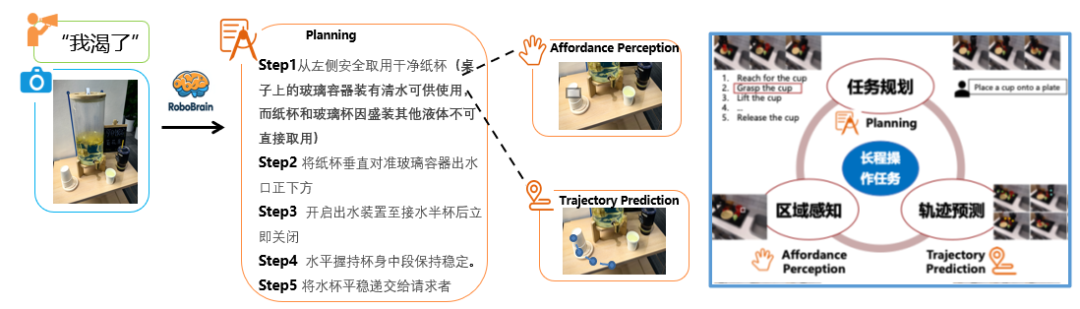
在此过程中,RoboBrain 不仅完成了高层任务拆解,还进一步输出与执行相关的关键信息:包括杯子的可操作区域(Affordance),以及从当前位置到抓取、移动、放置全过程的操作轨迹(Trajectory)。这些中间结果被传递给小脑,使小脑能够结合自身的动力学特性与传感反馈,在具体执行阶段完成更精确、更稳定的动作控制。
在此基础上形成的 RoboBrain 1.0,重点解决的是具身大脑在单体机器人场景中的可用性问题。模型已经能够在高分辨率视觉输入和长时序视频条件下,稳定完成任务分解、可操作区域预测以及轨迹生成,为长程操作任务提供完整支撑。这一能力的关键基础,来自 ShareRobot 数据集所构建的大规模异构数据体系,该数据集覆盖多种机器人本体、多类真实场景与细粒度原子任务,使 RoboBrain 在训练阶段便具备跨场景、跨本体的泛化潜力,为后续能力扩展奠定了数据层基础。
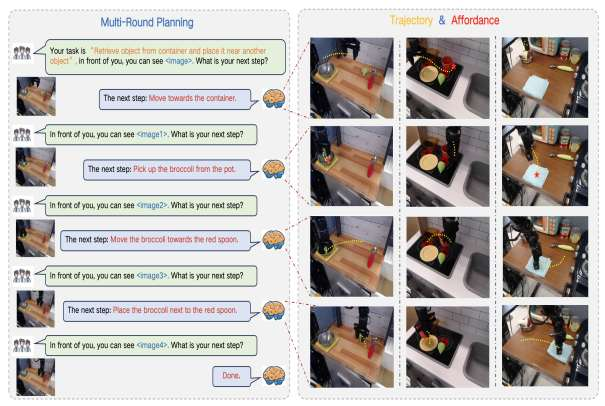
然而,当任务从单机执行走向更复杂的动态环境,仅依赖一次性规划与静态理解已难以满足需求,在真实物理世界中,环境状态会持续变化,任务执行过程往往需要多轮感知—判断—调整,RoboBrain 2.0 便将关注重点转向时空推理以及多机协作规划能力。通过引入更强的空间关系建模机制与动态环境记忆,模型能够在执行过程中持续更新对环境的认知,并对原有规划进行修正,在多项空间推理与任务规划指标上实现显著提升,尤其在跨本体、多机器人协同任务中展现出明显优势。
01 空间维度
相较于仅能识别目标物体的早期模型,RoboBrain 2.0 更强调对复杂三维场景中空间结构与相对关系的整体理解,能够在多物体共存、遮挡与环境持续变化的条件下,稳定解析物体位置、容器结构、可操作区域及任务约束,并将其统一纳入任务规划过程。
02 时间维度
同时,在时间维度上,模型不再局限于单步决策,而是支持跨阶段的长期规划与执行中的闭环调整,能够在任务推进过程中持续更新状态认知,并根据实时反馈修正动作策略。
03 长链推理
RoboBrain 2.0 引入了更清晰的链式任务拆解机制,使抽象指令可以被逐步分解为一系列具备因果关系的原子决策,从而支撑更长时序、更高复杂度的操作任务。
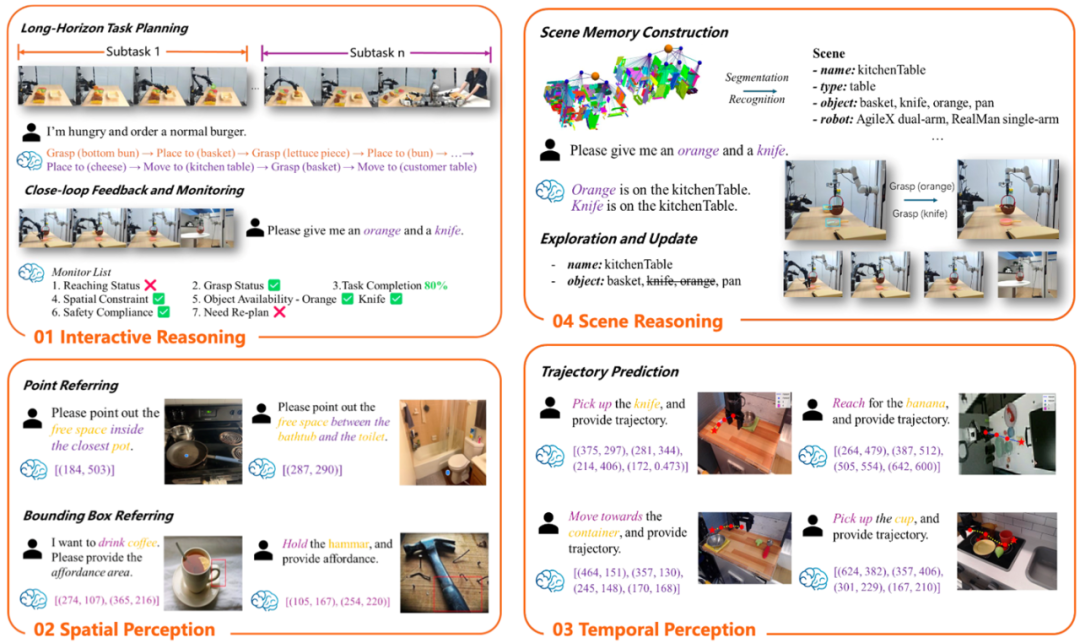
这些能力在多组跨本体 Demo 中得到集中验证:例如在 Franka 机械臂的橱柜操作任务中,机器人需要将苹果放入“第一层柜子中的空位”。这一过程不仅要求识别物体本身,更关键的是理解容器结构、层级关系以及空闲区域的几何约束。RoboBrain 2.0 通过空间关系建模,实现了对“可放置区域”的稳定推理,使操作不再依赖固定模板或人工标定。

在 UR5 桌面操作场景中,系统需要在多个物体并存、部分遮挡的条件下,完成“取最近的汉堡”“将物体移动至指定光照区域”等指令。RoboBrain 2.0 不仅能够准确判断目标物体的空间优先级,还能够解析“最近”“前方”“光线照亮区域”等相对空间描述,并将其映射为可执行的三维操作约束,指导小脑完成精确放置。此外,RoboBrain 2.5 即将发布,欢迎各位关注。

技术观察:具身智能正在从“模型竞赛”走向“系统竞争”
在小Loong看来,技术的演进并不存在一条单一且放之四海而皆准的“正确路线”,无论是端到端多模态模型,还是具身大小脑协作架构,本质上都是在不同问题尺度与工程约束下,对智能系统进行的有效组织方式。在可预见的相当长一段时间内,模型、控制与系统设计,将在很长一段时间内并行演进、相互影响,真正具备生命力的技术路线,往往不是某一能力的极致形态,而是能够支持多种技术形态长期共存、持续协作的系统框架。
作为面向人形机器人和具身智能开发者的开源平台,OpenLoong 开源社区希望能够承载模型、控制、系统、数据与工程经验的持续汇聚,让不同路径的探索能够在真实机器人系统中相互验证、彼此补充,我们更关注如何通过开源协作,让模型能力、控制机制与系统经验在真实机器人场景中不断沉淀与复用。本次分享所使用的演讲 PDF 已同步上传至 OpenLoong 社区论坛,欢迎大家点击阅读原文前往下载查阅、交流讨论,也欢迎加入 OpenLoong 开源社区,与更多同行一起,参与具身智能系统化演进的长期探索。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)