具身智能(人形机器人)
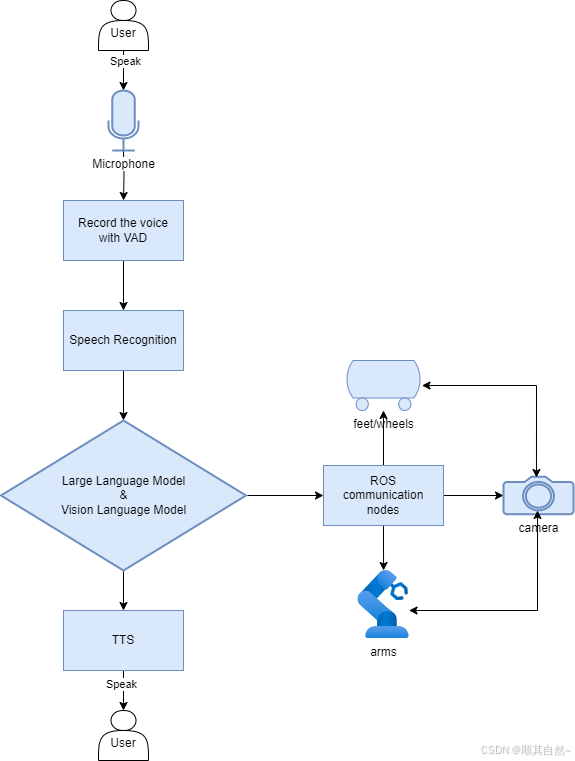
具身智能是指机器人能够在物理世界中自主地感知环境、做出决策、执行动作等。涉及的技术栈中,通过软件和算法开发应用从而无需昂贵或专门化的硬件,比较适合开源社区。申昊科技的人形机器人小昊的具身智能节点是一个由大语言模型(LLM)、视觉语言模型(VLM)、动作控制系统、导航系统相互通信组成的 Multi-agent System;可以调用相机、麦克风等传感器感知环境调用机械臂、轮式底盘等身体部位执行动作。
具身智能是指机器人能够在物理世界中自主地感知环境、做出决策、执行动作等。涉及的技术栈中,通过软件和算法开发应用从而无需昂贵或专门化的硬件,比较适合开源社区。
申昊科技的人形机器人小昊的具身智能节点是一个由大语言模型(LLM)、视觉语言模型(VLM)、动作控制系统、导航系统相互通信组成的 Multi-agent System;可以调用相机、麦克风等传感器感知环境,调用机械臂、轮式底盘等身体部位执行动作。
机器人的记忆系统分为短期记忆和长期记忆。短期记忆由多轮对话内容和动作记录构成。长期记忆由包括了人员、产品、专业知识的向量数据库构成,大模型通过 RAG 获取记忆,作为上下文回答问题。
迎接宾客
1、大语言模型理解语义:判断环境中是否有人,如果有人请招手欢迎。
2、大语言模型判断需要调用相机和视觉语言模型,回复:“我想先拍照。”
3、相机拍照后将图片和用户的提示词输入视觉语言模型,由视觉语言模型判断是否有人站在面前。
4、视觉语言模型判断环境中有人(面前的拍摄者),决定调用招手动作,发送消息给机械臂执行动作。
目标追踪
1、大语言模型理解任务:寻找有椅背的椅子。
2、大语言模型判断需要使用相机和视觉语言模型,并确定目标:有椅背的椅子。回复:“正在定位:有椅背的椅子。”
3、视觉语言模型定位目标,对图片中有椅背的椅子拉框,返回像素坐标。
4、调用深度相机计算角度和距离,驱动轮式底盘到目标(视频中第九秒开始移动)。
展厅讲解
1、大语言模型理解需要前往的点位,将点位发消息给导航系统。
2、导航系统自动规划路径,移动至目标点位。
3、到点位后,系统发送介绍词自动给大模型作为上下文,实现与客人的对答。
一、感知环境
1、 听觉(语音):
机器人在感知用户语音时,通常包括以下步骤:
1)语音唤醒(关键词监测),用于开启录音。
2)语音活性检测(VAD),用于录音时判断是否包含人的声音,从而判断开始和结束录音的时间。
3)语音识别,用于收到录音后将语音转为文字,包括贴合应用场景的热词(专有名词)的识别。
目前已经可以使用魔搭上的paraformer,uniasr等模型开发出成熟的语音识别,Silero VAD等做录音监听、FSMN-CTC等做语音唤醒,实现人机交互时用户的语音转为文字并输入大模型的步骤。
然而在展厅、室外等各种嘈杂环境中,经常伴随着多名用户围绕着机器人,你一言我一语的情况。这使得VAD无法停止录音,语音识别后包含大量来自多人的冗杂问题,表达不够清晰。如何识别主对话人,以及只录主对话人说的话?目前已有软硬一体的闭源的多模态降噪录音算法,通过人脸监测+唇形识别确定主对话人并录音。开源社区开发者可以调用魔搭现有的模型资源,开发在普通摄像头的麦克风阵列通用的多模态降噪录音算法。
2、 视觉:
1)同时定位与地图构建(SLAM): 机器人在探索未知环境时,同时进行自我定位并创建环境的地图。开源社区开发者可以基于现有的开源SLAM框架,对调用各种传感器的组合(深度相机、激光雷达、声纳、轮式编码器)等开发地图构建和自我定位的应用。
2)视觉模型:视觉语言模型(Vision Language Model),可以通过拍摄照片与用户的 prompt 一起理解复杂语义,回答问题。比如:“请定位戴着耐克帽子的人”之类的复杂语义信息,并在同时上传的图片中做目标检测。然而,视觉语言模型的响应速度较慢,且无法处理视频流。一旦对话中物体的位置发生了改变,机器人的定位就无法实时跟进。传统的基于 YOLO 的目标检测模型可以处理视频流,然而无法理解复杂的语义。开源社区开发者可以调用大模型+小模型的方式,使机器人能够对环境进行实时感知。通过人脸识别等模型,让机器人像人一样记住对话人,通过文本向量(text embedding)、多模态向量(multimodal embedding)和 RAG 查询对话人的背景信息,与对话人互动。
3)三维视觉:机器人通过深度相机、豆干相机、鱼眼相机、红外相机等多种视觉传感器,可以获得可见光图、红外图、全景图、深度图以及点云等多种图像信息。机器人可以通过这些信息,构建 3D 视觉,从而测算物体与自己偏离的角度与距离,并做动作规划。开源社区开发者可以根据自身硬件条件设计三维视觉的感知,如用普通相机和现有的模型资源,对普通的 RGB 图进行深度测量、三维建模等。甚至在未来用于与 3D 的视觉语言模型对话。
3、嗅觉、味觉、触觉
目前嗅觉、味觉、触觉主要依赖传感器和内嵌的算法。目前,适合开源社区开发的项目可能还需要等待。
1)嗅觉:电子鼻、气体传感器能够使机器人进行气味识别。通过感受气体体积分数的变化并将其转变为电信号,机器人可以探测在一定区域范围内是否存在特定气体,测量气体成分浓度。
2)味觉:电子舌、盐度传感器能够使机器人进行味觉识别。这些传感器可以检测到食物中的各种化学物质,转化为电信号。再通过算法分析和判断,从而得出食物的味道。
3)触觉:电子皮肤能够使机器人感知温度、压力、湿度感知温度、压力、湿度,在黑暗的环境下也能够感知环境。
二、决策和执行
1、具身智能 Agent框架
具身智能的Agent框架能够支持环境感知、记忆能力、调用物理工具,以及执行任务。区别于现有的基于互联网的 agent 框架,机器人的 agent 框架需要处理多种传感器回传的环境信息,更丰富的动作与对话记忆,更复杂的 multi-agent 和工具调用的通信机制。
以下是其关键组件:
1) 感知器(Perception Module)
此模块的目标是提供有关环境状态的实时信息,负责与外部世界交互的基础,通过视觉、听觉、触觉等传感器接收环境信息。这些信息包括了各种形式的图片、物体的像素坐标和三维坐标、SLAM 建立的地图和机器人的定位等。
2)记忆系统(Memory System)
包括用于底层子任务执行的短期记忆(处理即时任务时的临时信息存储)和高层任务规划的长期记忆(存储技能、任务规则等)。这些记忆包括了各个身体模块(头、手、脚、相机等物理 agent)的任务下发与执行情况。
3)决策引擎(Decision Making Engine)
决策引擎负责处理来自感知器的信息和记忆系统中的数据,用大模型和小模型联动进行决策。这个决策引擎包括了一个大模型的 multi-agent 系统,能够实现大语言模型、视觉语言模型、音视频语言模型之间的协同配合。同时还能与头、手、脚等物理 agent 之间通信。
4)执行器(Actuator Module)
执行器需要与大模型配合进行动作规划,包括控制机械臂、双足或其他移动机制,以及调用激光雷达、相机等感知器,从而执行具体任务。执行器需要精确地响应决策引擎的指令,执行如拾取、移动、导航等操作。
5)通讯接口(Communication Interface)
通讯接口允许AI agent与用户、其他AI系统或机器人进行交流。包括了与人类通讯的自然语言,并能够集成于聊天工具中(微信、钉钉)。同时还有与IoT物联网通讯所用的mqtt, http, websocket的通讯协议等。以及通过 ROS(机器人操作系统)消息,与各个身体模块的通信机制。
2、具身智能数据集
1)离散控制类数据
通过模拟器和实际机器人,记录机器人在不同场景下的离散动作序列,如机械臂关节角度变化、运动轨迹、执行效率和能耗等,使模型学习精准的动作控制能力。
2)图片数据
深度图、红外图、彩色图、点云等多样化视觉输入,包括室内、室外、复杂光照条件下的图像,涵盖常见物体、环境特征、人类行为等元素,以增强模型的视觉理解能力。
3)语言数据
整合自然语言指令、对话历史、情境描述等文本数据,覆盖机器人可能接收到的任务指令、用户交互内容以及对环境的自然语言描述,为模型提供丰富的语言理解和生成素材。
4)机器人传感器数据
收集机器人内部传感器(如IMU、力矩传感器、距离传感器等)以及外部环境传感器(如温度、湿度、光照传感器等)的实时数据,用于模型学习多模态感知和环境适应能力。
5)端到端训练与微调
基于构建的具身智能数据集,进行端到端的大模型训练,或微调已有的视觉语言模型,使其能够理解深度图、红外图、彩色图、点云等多样化视觉输入,并能够推理各个身体模块的动作规划。
3、具身实现
分为上层任务规划和下层技能实现两个层级。
1)上层任务规划:从任务级到技能级
利用预训练的大模型作为核心组件,理解接收到的任务指令和环境信息,生成抽象的任务计划或策略。将高层任务计划转化为一系列具体的子任务或技能需求,并通过优先级排序和资源调度机制,指导机器人有序执行。
2)下层技能实现:从技能级到动作级
小模型与函数调用:针对特定技能(如抓取、行走、导航等),开发或集成专门的小模型或工具库,这些模块应具有高效、精确的运动控制能力,并能与大模型对接。开源社区开发者可以贡献各种任务的小模型或其他需要调用的工具,以及与大模型与下层技能联动的方式。
转自:魔搭社区

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)