veRL 训推一致性工作及重要性采样代码演进分析
在强化学习领域,目前主流RL算法是基于On-Policy前提展开的,On-Policy理论要求采样数据的行为策略与梯度计算的目标策略保持一致,才能确保梯度估计是无偏的,朝则梯度最陡峭的方向优化,使得训练过程更平稳。关于On-Policy和Off-Policy的区别,On-Policy就是与环境交互产生数据的策略和要更新的策略是同一个策略,Off-Policy就是两者策略存在不同。以PPO为例,Cl
作者:昇腾实战派
知识地图链接:强化学习知识地图
背景概述
在强化学习领域,目前主流RL算法是基于On-Policy前提展开的,On-Policy理论要求采样数据的行为策略与梯度计算的目标策略保持一致,才能确保梯度估计是无偏的,朝则梯度最陡峭的方向优化,使得训练过程更平稳。关于On-Policy和Off-Policy的区别,On-Policy就是与环境交互产生数据的策略和要更新的策略是同一个策略,Off-Policy就是两者策略存在不同。以PPO为例,Clipped目标函数为:
目前主流高效的RL训练框架中(VeRL、ms-Swift等),训推一般采用不同的引擎。通常会采用像vLLM、SGLang这样高度优化的推理引擎做数据采样,FSDP或Megatron等框架进行模型训练。
•采样策略 π_sampler:推理引擎负责生成采样数据。
•目标策略 π_learner:训练引擎负责计算梯度并更新模型参数。
On-Policy RL系统要求采样分布π_sampler与梯度计算的目标策略π_learner 需要一致,由于训推存在差异,例如典型情况为训推算子实现精度不一致、训推采用的量化精度FP8/BF16不一致,异步强化学习算法中训推模型不处于同一状态等,使得算法潜藏Off-Policy的“陷阱”,不满足无偏估计的前提,导致出现以下两种典型场景。
场景1: 训练不稳定,训练过程直接出现Reward崩溃情况,图例为训练Reward突然崩溃情况,grad norm爆炸情况。
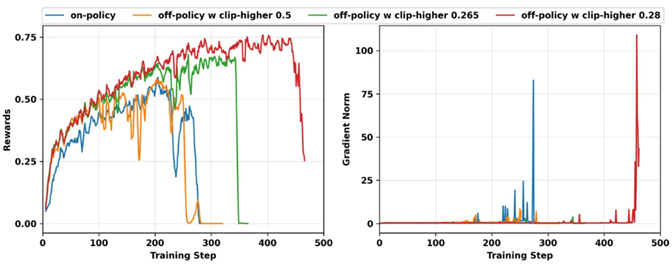
场景2: 收敛效果差,无法朝梯度最佳方向优化。图例为添加了TIS(Truncated Importance Sampling)取得了更优的效果
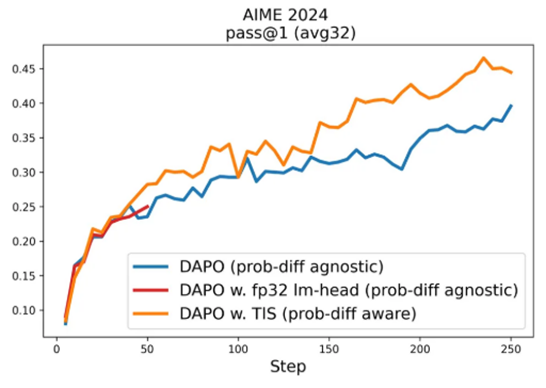
在两种场景中,训练崩溃场景更加重要,将直接导致训练无法继续进行。
TIS 初始实现
TIS最新相关消息:

关键链接:
TIS的原始脚本:
TIS的原始PR:
https://github.com/volcengine/verl/pull/2953
关键:此PR目前已经基本被重构,参数接口都已经废弃。
MIS 演进与重构
TIS最新相关消息:

releases Tag:
https://github.com/volcengine/verl/releases/tag/v0.6.0
Token-Level TIS对应上面的PR #2953
Sequence-Level TIS对应下面的PR #3694
第一次重构:MIS的原始PR,重构TIS
PR:https://github.com/volcengine/verl/pull/3694
PR解读:
- 三种维度的计算方式,这个PR相对于Token-level,额外增加了Sequence-level,Geometric-level
- 控制策略:上界截断TIS,双边掩码MIS
- 加了一堆监控指标
- 加了vote token
Geometric-level:几何平均数,对pre-token的比值
- Flexible Aggregation Levels
Three methods for calculating IS weights:
-
-
- **
token**: Per-token importance ratios - **
sequence**: Product of per-token ratios - **
geometric**: Geometric mean of ratios
- **
-
- Advanced Bounding Modes
Two strategies to control weight variance:
-
-
truncate(TIS): Caps weights at upper threshold only, preserving gradientsmask(MIS): Zeros out weights outside bounds, more aggressive filtering
-
- Comprehensive Diagnostics
Detailed metrics to monitor distribution mismatch and training health:
Rollout IS Metrics (automatically prefixed with mismatch/):
-
-
- Health indicators:
rollout_is_eff_sample_size,rollout_is_mean - Distribution statistics:
rollout_is_p25,rollout_is_p50,rollout_is_p75,rollout_is_p95,rollout_is_p99,rollout_is_max,rollout_is_min,rollout_is_std - Diagnostics:
rollout_is_veto_fraction,rollout_is_catastrophic_token_fraction,rollout_is_masked_fraction(mask mode) - Sequence-level statistics (for sequence/geometric modes):
rollout_is_seq_mean,rollout_is_seq_std,rollout_is_seq_max,rollout_is_seq_min, etc.
- Health indicators:
-
Mismatch Metrics (computed efficiently within IS weight computation):
-
-
- KL Divergence:
mismatch_kl(forward KL),mismatch_k3_kl(K3 estimator for stability) - Perplexity:
mismatch_training_ppl,mismatch_rollout_ppl,mismatch_ppl_ratio - Log perplexity statistics:
mismatch_log_ppl_diff,mismatch_log_ppl_abs_diff,mismatch_log_ppl_diff_max,mismatch_log_ppl_diff_min
- KL Divergence:
-
- Outlier Mitigation
-
-
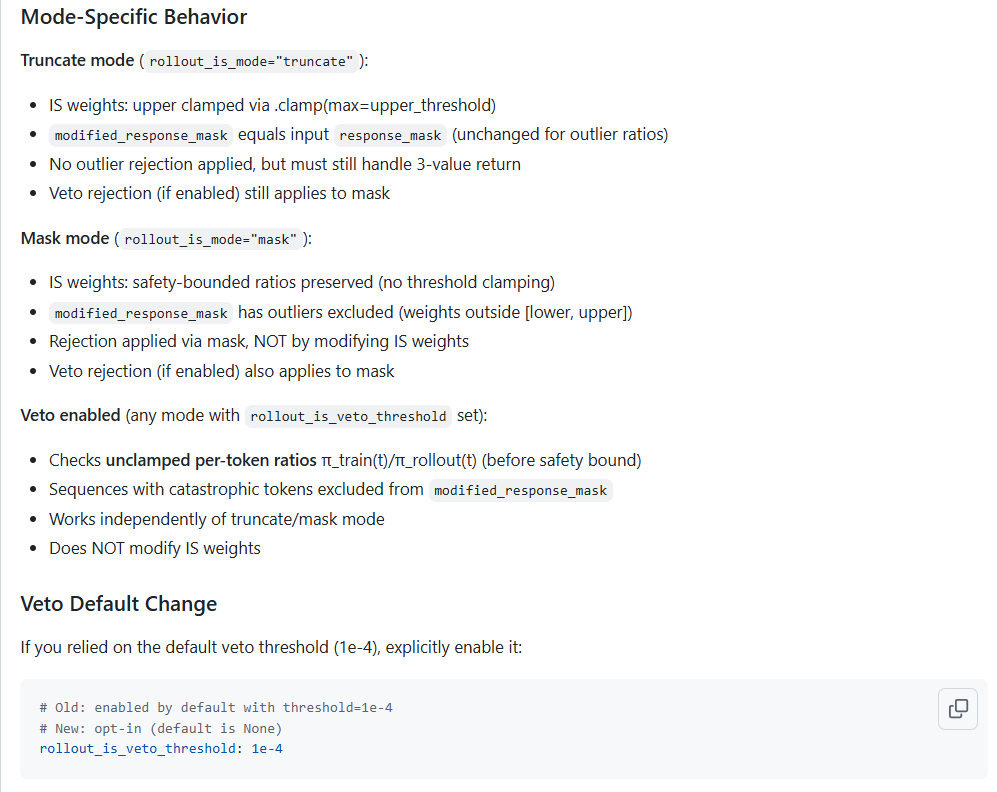
- Veto mechanism: Automatically discards samples with catastrophic importance weights (per-token ratios below threshold)
Prevents gradient corruption from extreme outliers
Configurable threshold (default: 1e-4)
- Veto mechanism: Automatically discards samples with catastrophic importance weights (per-token ratios below threshold)
-
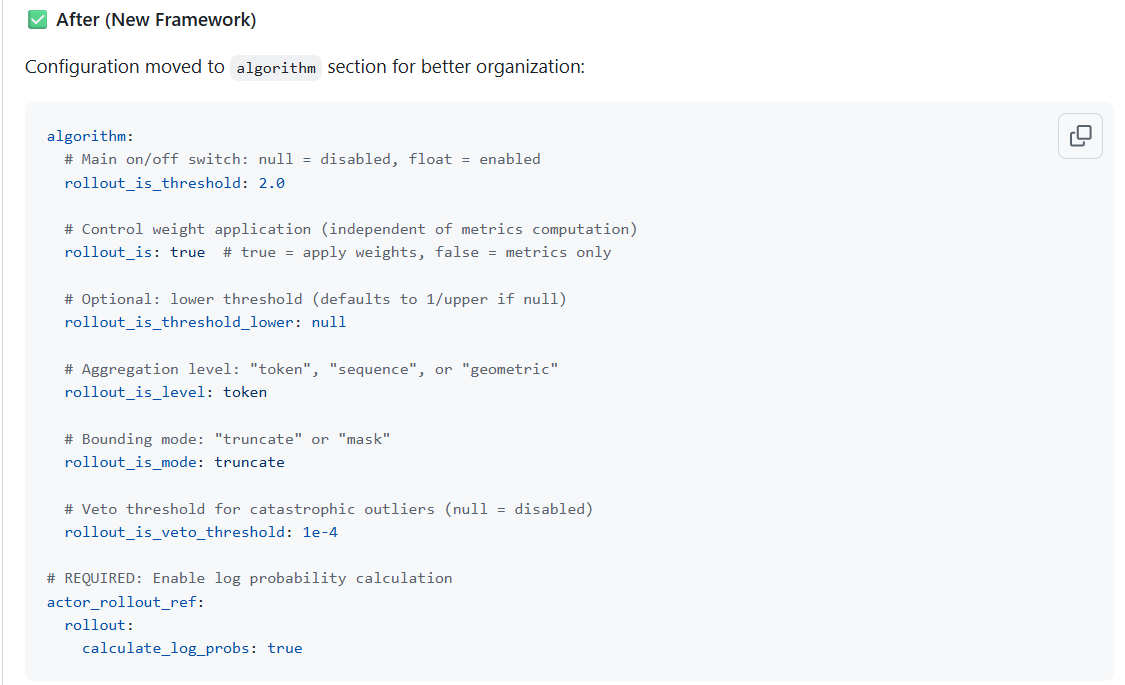
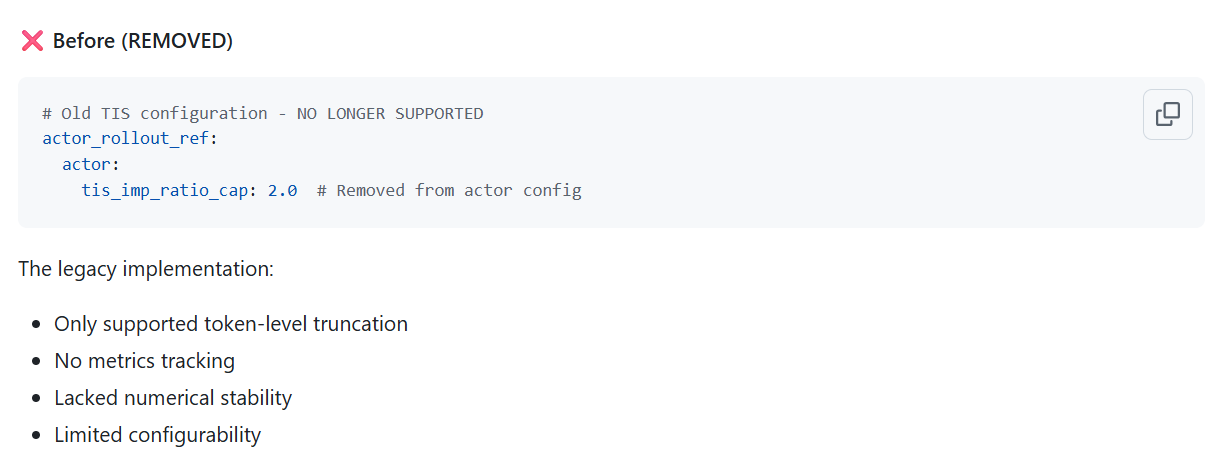
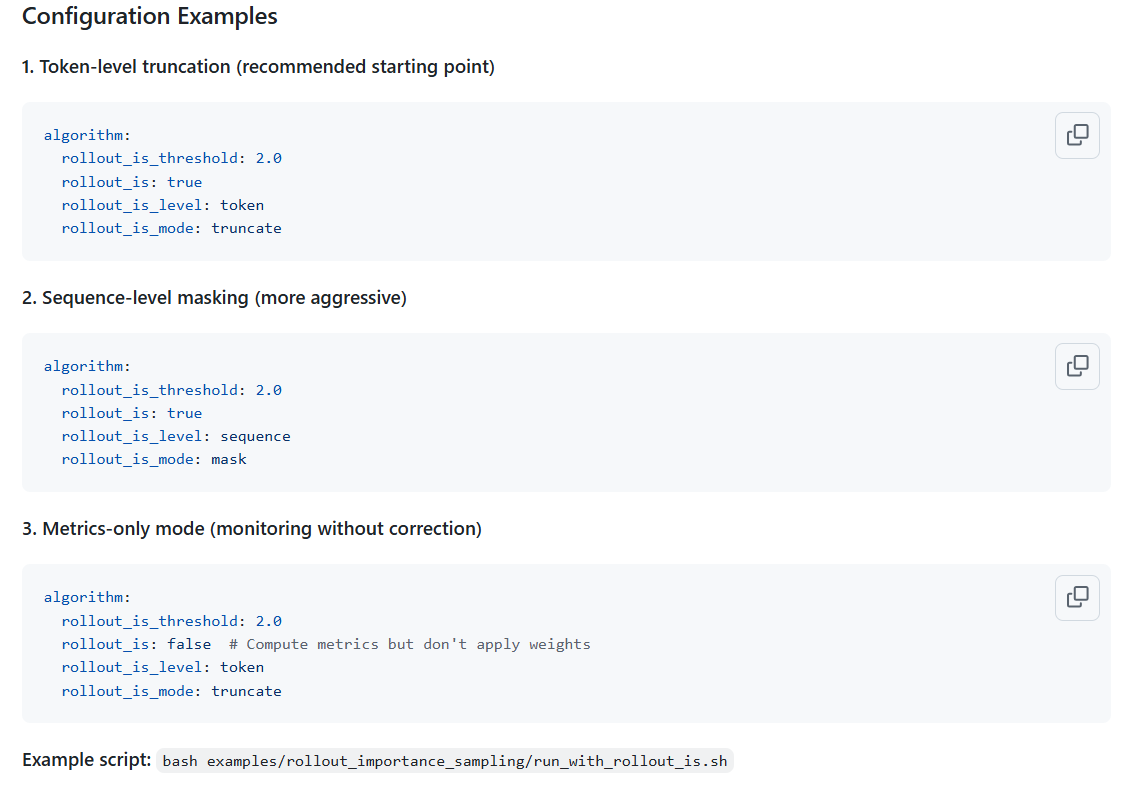
第二次重构:分离了重要性采样和拒绝采样逻辑
PR:https://github.com/volcengine/verl/pull/3915
这里有个点,Mask掩码模式,其实本质上是一种拒绝采样方式,以及veto token,分离出来,后续又针对重构了一次,区分了IS(Importance Sampling)和RS(rejection sampling)的两个概念。
Fully async 集成IS
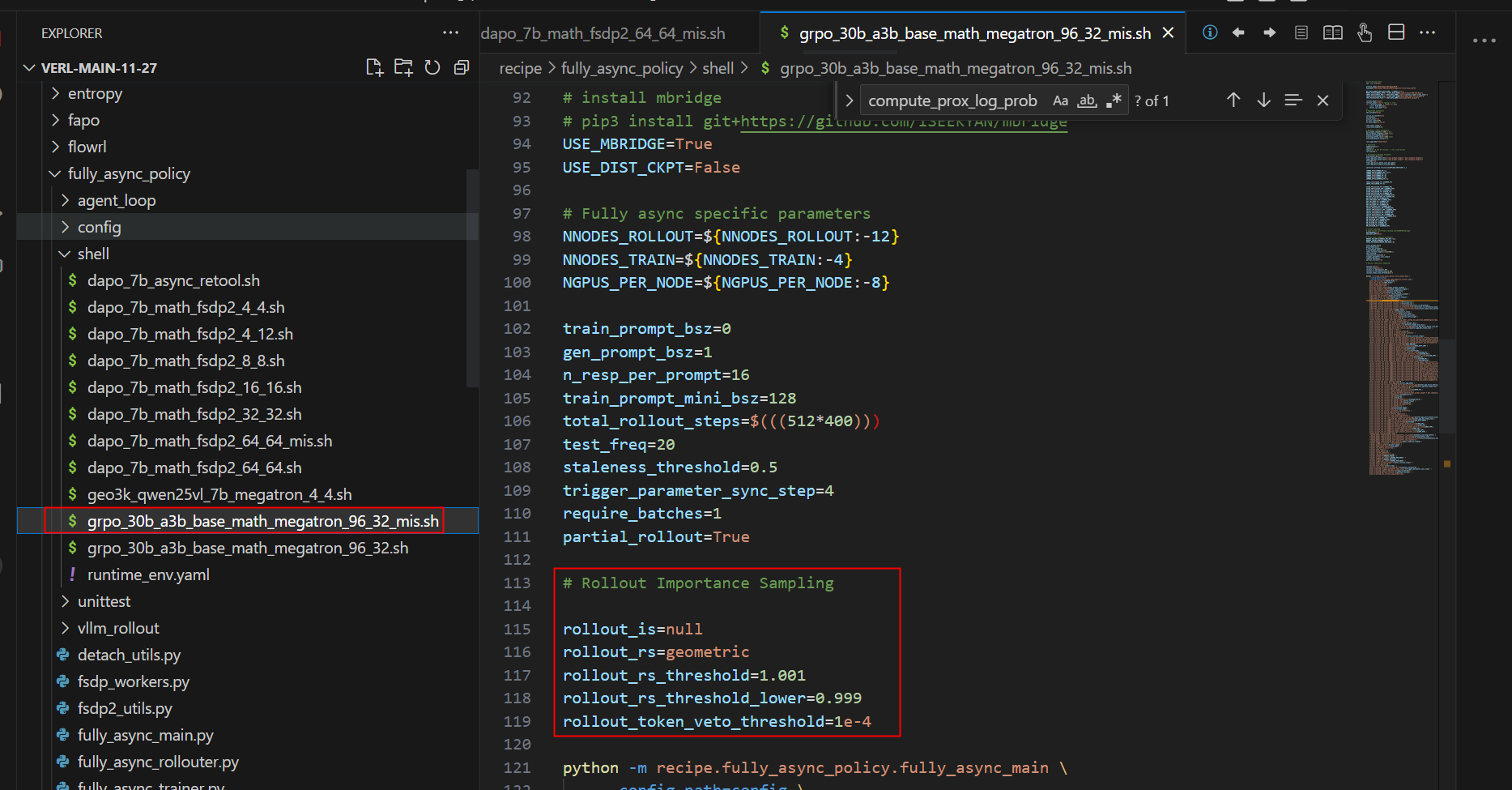
PR:https://github.com/volcengine/verl/pull/3955
类似于decoupled PPO
脚本:
第三次重构:重构整合off-policy问题,IS和RS解耦
PR: https://github.com/volcengine/verl/pull/3984
把RS和IS都彻底,并且重构了api和核心文档,同时也重构了Fully async、DAPO等前面涉及到的代码

文档1:基本说明,使用的话直接看这个。
https://verl.readthedocs.io/en/latest/algo/rollout_corr.html
文档2:包括完整的数学理论分析。
https://verl.readthedocs.io/en/latest/algo/rollout_corr_math.html
DAPO中的脚本:
https://github.com/volcengine/verl/blob/main/recipe/dapo/run_dapo_qwen2.5_32b_rollout_corr.sh
一致性指标
在VeRL框架中,除了直接观测Reward、Grad Norm等异常指标,目前集成了简单的训推分布一致性统计值指标:
指标包括:
- rollout_probs_diff_max:训推的数值差异最大值
- rollout_probs_diff_mean:训推的数值差异平均值
- rollout_probs_diff_std:训推的数值的标准差
- rollout_actor_probs_pearson_corr:训推分布的皮尔森相关系数,越接近一表示两个分布更加接近。
目前只在在依赖于PPO ray trainer verl\trainer\ppo\ray_trainer.py中保有该输出,如DAPO ray trainer已经移除,若要开启该参数指标,需在启动脚本中添加:
actor_rollout_ref.rollout.calculate_log_probs=True
在0.7x最新代码中,集成了高阶的Off-Policy观测指标,开启上述配置后输出:
def compute_offpolicy_metrics(
old_log_prob: torch.Tensor,
rollout_log_prob: Optional[torch.Tensor],
response_mask: torch.Tensor,
) -> dict[str, Any]:
"""Compute off-policy diagnostic metrics (helper function).
This helper function operates on raw tensors and is used internally by:
- compute_rollout_correction_and_rejection_mask() in this module (automatically included)
- Tests (test_rollout_corr.py, test_rollout_corr_integration.py)
These metrics help diagnose the off-policy gap between rollout and training policies,
which can arise from:
- Policy mismatch (e.g., vLLM BF16 vs FSDP FP32)
- Model staleness (training on trajectories from older checkpoints)
- General distribution shifts
Key metrics:
- kl: Direct KL divergence estimator KL(π_rollout || π_training)
- k3_kl: K3 KL estimator for stability (more stable for small KL)
- training_ppl: Perplexity of training policy
- rollout_ppl: Perplexity of rollout policy
- log_ppl_diff: Difference in log perplexities
- ppl_ratio: Ratio of training PPL to rollout PPL
- chi2_token: Token-level χ² divergence E[ρ²] - 1
- chi2_seq: Sequence-level χ² divergence E[(∏ρ_t)²] - 1
Args:
old_log_prob: Log probabilities from training policy, shape (batch_size, seq_length)
rollout_log_prob: Log probabilities from rollout policy, shape (batch_size, seq_length)
response_mask: Mask for valid tokens, shape (batch_size, seq_length)
Returns:
Dictionary of off-policy metrics (without prefix)
"""
# Validate that we have at least one valid token
assert response_mask.any(), "Expected at least one valid token in response_mask"
metrics = {}
# 1. Training policy perplexity (always available)
# Formula: exp(-1/|T| * Σ log π_training(y_t|y_<t))
# where |T| is the number of tokens generated by the model
mean_log_prob_training = verl_F.masked_mean(old_log_prob, response_mask, axis=-1) # (batch_size,)
training_ppl = torch.exp(-mean_log_prob_training).mean() # Batch mean of per-sequence PPL
metrics["training_ppl"] = training_ppl.detach().item()
# Also log log-ppl for easier analysis (avoids exponential scale)
metrics["training_log_ppl"] = (-mean_log_prob_training).mean().detach().item()
# 2. Compute rollout off-policy metrics (only if rollout_log_probs available)
if rollout_log_prob is not None:
# 2a. kl: Direct estimator for KL(π_rollout || π_training)
# This is the standard KL divergence: E[log(π_rollout) - log(π_training)]
# Positive value means rollout policy is more confident than training policy
metrics["kl"] = verl_F.masked_mean(rollout_log_prob - old_log_prob, response_mask).detach().item()
# 2b. k3_kl: K3 estimator for KL(π_rollout || π_training)
# More stable for small KL values using: E[exp(log_ratio) - log_ratio - 1]
# Formula: KL ≈ E[r - log(r) - 1] where r = π_training/π_rollout
log_ratio = old_log_prob - rollout_log_prob
k3_kl_matrix = torch.exp(log_ratio) - log_ratio - 1
metrics["k3_kl"] = verl_F.masked_mean(k3_kl_matrix, response_mask).detach().item()
# 2c. Rollout policy perplexity
mean_log_prob_rollout = verl_F.masked_mean(rollout_log_prob, response_mask, axis=-1) # (batch_size,)
rollout_ppl = torch.exp(-mean_log_prob_rollout).mean() # Batch mean of per-sequence PPL
metrics["rollout_ppl"] = rollout_ppl.detach().item()
metrics["rollout_log_ppl"] = (-mean_log_prob_rollout).mean().detach().item()
# 2d. Log PPL difference (sequence-level perplexity difference)
# log_ppl_diff = mean_log_prob_rollout - mean_log_prob_training
# Since ppl = exp(-log_prob), we have:
# log(ppl_ratio) = log(training_ppl/rollout_ppl) = log_ppl_diff
# Positive value means training assigns lower probability (higher PPL) than rollout
log_ppl_diff = mean_log_prob_rollout - mean_log_prob_training
metrics["log_ppl_diff"] = log_ppl_diff.mean().detach().item()
metrics["log_ppl_abs_diff"] = log_ppl_diff.abs().mean().detach().item()
metrics["log_ppl_diff_max"] = log_ppl_diff.max().detach().item()
metrics["log_ppl_diff_min"] = log_ppl_diff.min().detach().item()
# 2e. PPL ratio (how much higher is training PPL vs rollout PPL)
# IMPORTANT: Compute per-sequence ratio first, then average
# For numerical stability, compute in log space using log_ppl_diff
# Note: log_ppl_diff = log(ppl_ratio), so ppl_ratio = exp(log_ppl_diff)
# This is the inverse of geometric IS: ppl_ratio_i = 1 / geometric_is_i for each sequence
ppl_ratio = torch.exp(log_ppl_diff).mean() # mean(exp(log_ppl_diff)) = mean(ppl_ratio_i)
metrics["ppl_ratio"] = ppl_ratio.detach().item()
# 2f. Chi-squared divergence: χ²(π_training || π_rollout) = E_μ[ρ²] - 1
# where ρ = π_training / π_rollout and μ = π_rollout (rollout distribution)
# This measures the variance of importance sampling weights
# Token-level: E_token[ρ²] - 1 (averaged over all tokens)
log_ratio_safe = torch.clamp(log_ratio, min=-SAFETY_BOUND, max=SAFETY_BOUND)
rho_token = torch.exp(log_ratio_safe) # ρ = π_training / π_rollout (token-level)
rho_squared_token = rho_token.square()
chi2_token = verl_F.masked_mean(rho_squared_token, response_mask) - 1.0
metrics["chi2_token"] = chi2_token.detach().item()
# Sequence-level: E_seq[(Π ρ_t)²] - 1 = E_seq[exp(2 * Σ log ρ_t)] - 1
log_ratio_sum = verl_F.masked_sum(log_ratio, response_mask, axis=-1) # Σ log ρ_t per sequence
log_ratio_sum_safe = torch.clamp(log_ratio_sum, min=-SAFETY_BOUND, max=SAFETY_BOUND)
rho_squared_seq = torch.exp(2.0 * log_ratio_sum_safe) # (Π ρ_t)²
chi2_seq = rho_squared_seq.mean() - 1.0
metrics["chi2_seq"] = chi2_seq.detach().item()
return metrics
关键指标包括:
- kl: 训推分布的KL散度
- k3_kl: 训推分布的K3_KL散度
- training_ppl: 训练分布的PPL困惑度
- rollout_ppl: 推理分布的PPL困惑度
- log_ppl_diff: 训推PPL的对数差异
- ppl_ratio: 训推PPL的比值
- chi2_token: Token级的概率卡方分布
- chi2_seq: Sequence级的概率卡方分布
使能Rollout correction
VeRL框架在经过多轮重构后,目前实现了Rollout correction的一整套算法,包括:
- 重要性采样加权(Importance Sampling weights, IS)
- 拒绝抽样(Rejection sampling, RS)
- 否决机制(veto mechanism)
Yaml Config使能方式:
algorithm:
rollout_correction:
rollout_is: token # IS权重计算方式:可选"token"(按token计算)、"sequence"(按序列计算)或null(不使用)
rollout_is_threshold: 2.0 # IS权重的上阈值,用于限制权重的最大值
rollout_is_batch_normalize: false # 是否对IS权重进行批归一化,使其均值为1.0
rollout_rs: null # 拒绝采样策略:可选"token"、"sequence"、"geometric"或null
rollout_rs_threshold: null # 拒绝采样的上阈值,使用RS时必须设置
rollout_rs_threshold_lower: null # 拒绝采样的下阈值,若未指定则自动设为上阈值的倒数
rollout_token_veto_threshold: null # 每个token的否决阈值,若为null则不启用
bypass_mode: false # 是否跳过旧策略概率的计算
use_policy_gradient: false # 是否使用策略梯度损失(而非PPO损失)
# 必填项:启用对数概率计算
actor_rollout_ref:
rollout:
calculate_log_probs: true # 是否计算对数概率,策略优化算法通常需要此步骤
目前重要性加权、拒绝采样等策略,在昇腾上还未有具体的实践案例和明确效果影响分析结论。在项目在如涉及到训推不一致问题,可以尝试开启IS或者RS等措施,具体参数配置业界案例在VeRL上有已经探索的配置

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)