
港科大 & 地平线开源DrivingWorld:构建自动驾驶的世界模型!
综上所述,DrivingWorld通过利用GPT风格框架,生成了更长、更高保真度且具有更好泛化能力的视频预测,从而解决了自动驾驶中先前视频生成模型的局限性。与在传统方法中难以处理长序列连贯性或严重依赖标记数据的情况不同,DrivingWorld能够生成逼真的、结构化的视频序列,同时实现精确的动作控制。与经典的GPT结构相比,我们提出的时空GPT结构采用了下一个状态预测策略来建模连续帧之间的时间连贯
0. 论文信息
标题:DrivingWorld: ConstructingWorld Model for Autonomous Driving via Video GPT
作者:Xiaotao Hu, Wei Yin, Mingkai Jia, Junyuan Deng, Xiaoyang Guo, Qian Zhang, Xiaoxiao Long, Ping Tan
机构:The Hong Kong University of Science and Technology、Horizon Robotics,
原文链接:https://arxiv.org/abs/2412.19505
代码链接:https://github.com/YvanYin/DrivingWorld
1. 导读
最近自回归(AR)生成模型的成功,如自然语言处理中的GPT系列,激励了在视觉任务中复制这一成功的努力。一些工作试图通过建立基于视频的世界模型来将这种方法扩展到自动驾驶,这些模型能够生成现实的未来视频序列并预测自我状态。然而,先前的工作往往产生不令人满意的结果,因为经典的GPT框架被设计成处理1D上下文信息,例如文本,并且缺乏对视频生成所必需的空间和时间动态进行建模的内在能力。在本文中,我们提出了DrivingWorld,这是一个GPT风格的自动驾驶世界模型,具有几个时空融合机制。这种设计支持空间和时间动态的有效建模,有助于高保真、长持续时间的视频生成。具体来说,我们提出了下一状态预测策略来模拟连续帧之间的时间一致性,并应用下一令牌预测策略来捕捉每个帧内的空间信息。为了进一步提高泛化能力,我们提出了一种新的标记预测掩蔽策略和重新加权策略,以减轻长期漂移问题并实现精确控制。我们的工作展示了制作持续时间超过40秒的高保真和一致视频剪辑的能力,这比最先进的驾驶世界模型长2倍以上。实验表明,与以前的工作相比,我们的方法实现了更好的视觉质量和明显更精确可控的未来视频生成。
2. 效果展示
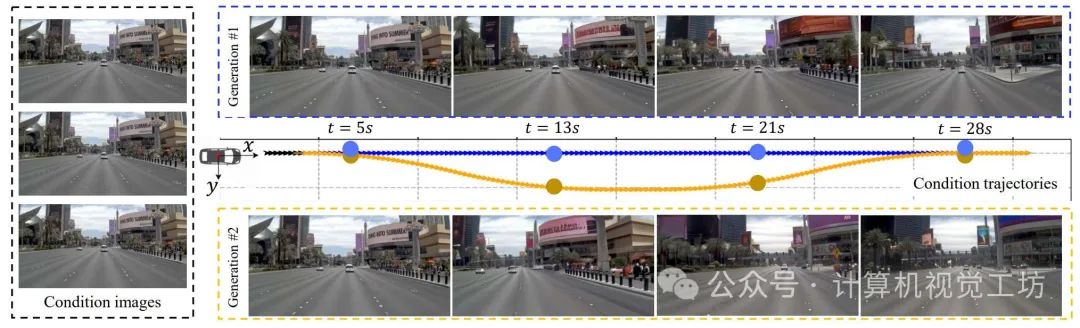
我们方法的可控生成结果。我们的方法以短视频片段作为输入,并根据不同的预定义轨迹路径生成多个可能的未来驾驶场景。我们使用一条直线路径和一条弯曲路径作为示例,结果表明我们的方法实现了准确的控制和未来的预测。
长时间视频生成。我们展示了一些由我们的方法生成的视频,每个视频有640帧,每秒5帧,即128秒。请注意,我们的方法在不同帧之间捕捉到的连贯的3D场景结构(请参见数字版本)。

3. 引言
近年来,自回归(AR)学习方案在自然语言处理领域取得了显著成功,GPT系列模型等便是明证。这些模型根据过往数据预测未来的文本响应,使自回归方法成为追求通用人工智能(AGI)的主要候选方案。受这些进展的启发,许多研究人员试图在视觉任务中复制这种成功,例如为自动驾驶构建基于视觉的世界模型。
自动驾驶系统中的一项关键能力是未来事件预测。然而,许多预测模型严重依赖于大量标记数据,这使得它们容易受到分布外和长尾场景的影响。对于罕见和极端情况(如事故)而言,这尤其成问题,因为很难获得足够的训练数据。一个有望解决该问题的方法是自回归世界模型,这些模型通过无监督学习从大量视频等未标记数据中学习综合信息。这能够使驾驶场景中的决策更加稳健。这些世界模型具有在不确定性下进行推理并减少灾难性错误的能力,从而提高了自动驾驶系统的泛化能力和安全性。
先前的工作GAIA-1首次将GPT框架从语言扩展到视频,旨在开发基于视频的世界模型。与自然语言处理类似,GAIA将4D时间相关帧转换为1D特征标记序列,并采用下一个标记预测策略来生成未来的视频片段。然而,经典的GPT框架主要是为了处理1D上下文信息而设计的,缺乏有效建模视频生成所需的空间和时间动态的固有能力。因此,GAIA-1生成的视频往往质量较低且存在明显瑕疵,这凸显了在GPT风格的视频生成框架中实现保真度和连贯性的挑战。
在本文中,我们介绍了DrivingWorld,一个基于GPT风格视频生成框架的驾驶世界模型。我们的主要目标是增强自回归框架中的时间连贯性建模,以创建更准确和可靠的世界模型。为实现这一目标,我们的模型包含三项关键创新:1)时间感知标记化:我们提出了一种时间感知标记器,将视频帧转换为时间连贯的标记,从而将未来视频预测任务重新定义为预测序列中的未来标记。2)混合标记预测:我们不再仅依赖下一个标记预测策略,而是引入了下一个状态预测策略,以更好地建模连续状态之间的时间连贯性。之后,应用下一个标记预测策略来捕获每个状态内的空间信息。3)长时间可控策略:为提高鲁棒性,我们在自回归训练期间实施了随机标记丢弃和平衡注意力策略,从而能够生成持续时间更长且控制更精确的视频。
4. 主要贡献
我们的工作通过使用自回归(AR)框架增强了视频生成中的时间连贯性,学习了未来演变的有意义表示。实验表明,所提模型具有良好的泛化性能,能够生成超过40秒的视频序列,并提供准确的下一步轨迹预测,同时保持合理的可控性水平。
5. 方法
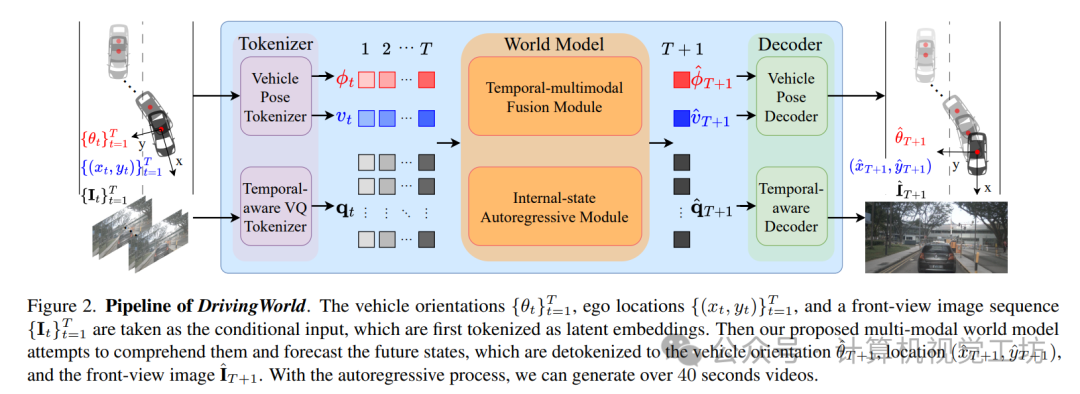
车辆方位、自我位置和前视图像序列被作为条件输入,它们首先被表征为潜在嵌入。然后,我们提出的多模态世界模型试图理解它们并预测未来状态,这些状态被分解为车辆方向、位置和前视图像。通过自回归过程,我们可以生成超过40秒的视频。

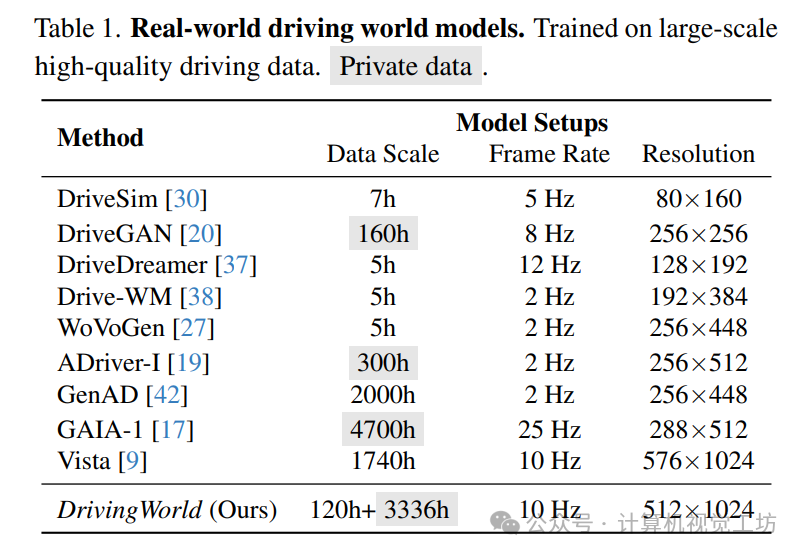
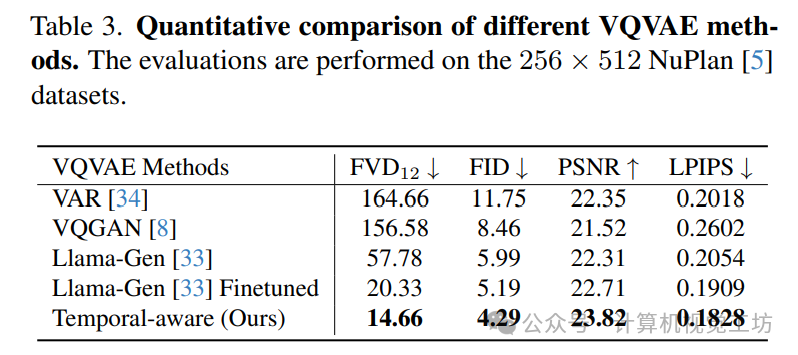
6. 实验结果

7. 总结
综上所述,DrivingWorld通过利用GPT风格框架,生成了更长、更高保真度且具有更好泛化能力的视频预测,从而解决了自动驾驶中先前视频生成模型的局限性。与在传统方法中难以处理长序列连贯性或严重依赖标记数据的情况不同,DrivingWorld能够生成逼真的、结构化的视频序列,同时实现精确的动作控制。与经典的GPT结构相比,我们提出的时空GPT结构采用了下一个状态预测策略来建模连续帧之间的时间连贯性,然后应用下一个标记预测策略来捕获每帧内的空间信息。展望未来,我们计划纳入更多模态信息并整合多个视角输入。通过融合来自不同模态和视角的数据,我们旨在提高动作控制和视频生成的准确性,增强模型理解复杂驾驶环境的能力,并进一步提升自动驾驶系统的整体性能和可靠性。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)