从长视频中探寻世界模型新范式:Emu3.5 的 Next-State Prediction 之路
我们使用 Whisper-large-v2 对每条视频做自动语音识别,获取逐词时间戳的文本,并通过 spaCy 进行停顿切分与句法整理,使视频语言更自然、结构化。长视频蕴含的是更深层次的世界规律,是时空延展的多模态经验(long-horizon multimodal experiences)。这些挑战,本质上也是未来方向:更大规模数据、更先进模型结构、更系统评估方法、更高效 tokenizer,将
悟界·Emu3.5 科研体验版现已开放“文本生图”和“编辑图片”功能,安卓APK、Web端均可体验。
-
文末下载安卓APK
回望过去二十年,AI 的两次重大跃迁,都来自将大规模数据“压缩”进模型参数之中:
-
AlexNet 借助120万张ImageNet图像,开启了深度视觉表征时代;
-
GPT-3 通过300B 互联网文本token的训练,让机器在语言世界中拥有强大的泛化和推理能力。
如果继续追问:下一个被低估、但足以推动AGI进展的数据形态是什么?
我们的答案是:长视频(long videos)。
1、世界 = 时空延展的多模态经验
维特根斯坦说过:“世界是所发生的一切(The world is all that is the case)。”
如果把世界理解为“正在发生的连续经验”,那么它天然由跨时间、跨空间、跨模态的线索共同构成。而在互联网中,最完整、最真实的这类载体,就是:
5 分钟、10 分钟、甚至半小时以上的长视频。
长视频的关键特征包括:
-
时空连续性:事件随时间自然展开,隐含因果与时空一致性。
-
多模态交织:视觉、动作、语言交错出现。
-
真实世界分布:覆盖教学、生活、科技、旅行、体育、游戏等广泛场景。
长视频蕴含的是更深层次的世界规律,是时空延展的多模态经验(long-horizon multimodal experiences)。
但挑战也同样明显:
长视频极长、冗余高、模态多。
我们该如何让模型真正“吃进去”这种复杂经验,让它像GPT学语言一样学习世界?
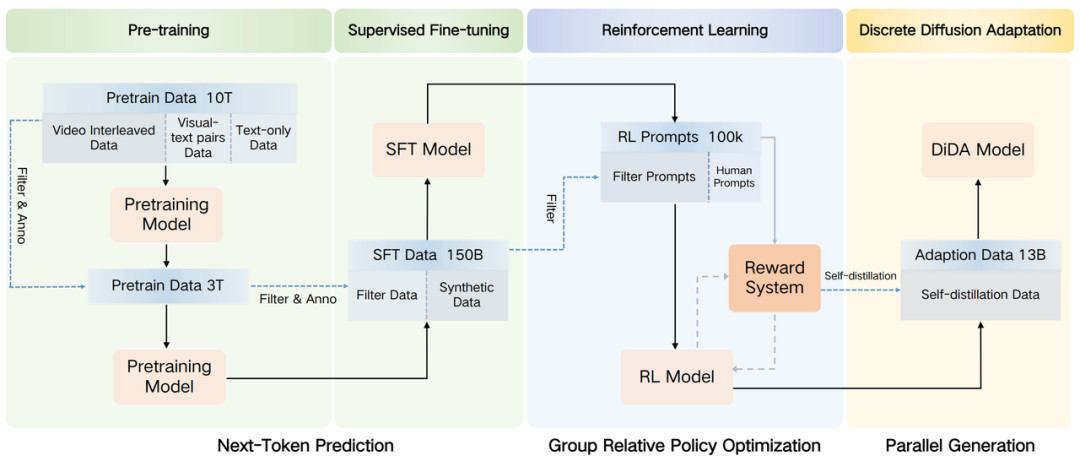
2、Emu3.5 的解法:把长视频变成可学习的“世界 token 序列”
Emu3.5 探索出一条清晰且高效的路径:
ASR(音频→文本)+ 关键帧(视频→视觉片段)→ 跨模态时间序列 → Next-Token Prediction(NTP)
这使模型能够高效地从长视频中学习世界的连续变化。
(1) ASR:把声音变成时间对齐的语言线索
我们使用 Whisper-large-v2 对每条视频做自动语音识别,获取逐词时间戳的文本,并通过 spaCy 进行停顿切分与句法整理,使视频语言更自然、结构化。
语言的加入大幅提升了长视频的语义密度,让模型更容易理解场景、意图与行为。
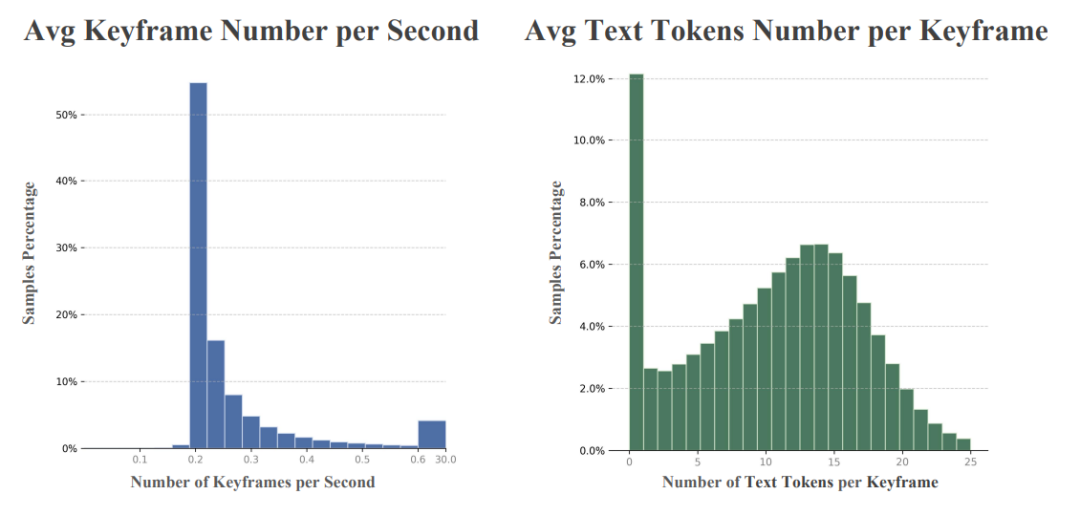
(2) 关键帧抽取:保留信息而不是保留帧率
我们采用 PySceneDetect 进行场景检测,并按内容密度抽取关键帧:
-
短场景 → 取中间帧
-
长场景 → 每若干秒取一帧
最终的关键帧密度约 0.27 frame/s,但足以覆盖主要视觉变化,并保留了时间结构。
Emu3.5 关键帧抽取
(3) 音画对齐 → 图文交错的世界序列
关键帧与 ASR 文本均带时间戳,我们按时间顺序交错合并:
Frame → Text → Frame → Text → …
再经 tokenizer 转化为统一的 token 序列,即 Emu3.5 的世界 token 序列。
模型的任务只有一件:预测下一个 token(next-token prediction)。

Emu3.5视频交错训练数据示例
3、Next Token → Next State:世界模型的基本单元
有了交错的长序列,我们就能像训练 GPT 一样,以统一的 NTP 范式进行训练。
三大核心收益:
-
可扩展性强:直接复用成熟的 LLM 训练基础设施。
-
无需额外任务设计:目标函数始终是下一个 token 的 cross-entropy。
-
从世界中自然学习:为了预测下一帧/下一句,模型必须捕捉时序关系与因果结构。
换句话说:在长视频上做 NTP,本质上就是在做 next-state prediction,而 next-state prediction 是世界模型的核心能力。
Emu3.5 训练 Pipeline
4、数据规模:把“世界”足量呈现给模型
为了让模型看到足够丰富的世界规律,我们构建了大规模长视频语料库:
-
约 6300 万条长视频
-
总计约 790 年的视频时长
-
覆盖教育、科普、How-to、旅行、游戏、体育、生活、动画等多领域
我们采用两阶段质量过滤:
-
基础过滤:时长/分辨率筛选、Talking-head 过滤(人脸检测 + Qwen-VL 分类)、多语言平衡、静音与噪声处理
-
高级过滤:帧质量(DeQA)、冗余去重(DINO + FG-CLIP)、文本质量(LLM 打分)
构建出可规模化训练的大规模图文交错长视频数据集。
5、能力与意义:泛化的世界建模能力
受益于长视频训练,Emu3.5 展现出强大的泛化世界建模能力:
-
开放的场景编辑与时空变换
-
原生的视觉语言生成能力,实现长程图文生成
-
在图文交错序列生成中保持时空一致性
这些能力使 Emu3.5 能够构建连贯的视觉故事、模拟复杂过程,并展现出具身操作、环境探索等世界模型特征,能够对真实或想象环境进行可控交互与推演。

Move the virtual camera down to show a street-level view

将左边的画变成现实世界的样子

生成下一步,并预测花之后的样子

左图中的动物站立起来躲在大红色大门的门口伸个脑袋偷看;预测下一步会发生什么

这是广州的城中村,10年后会变成什么样?再过50年呢?
6、局限与展望
从长视频中学习带来巨大的机遇和挑战:
-
数据规模仍可进一步扩大
790 年的长视频虽然庞大,但距公开数据的最大时长仍有很大差距。
-
下一代模型结构的机会
长视频带来的极长上下文,为超越 Transformer 的结构探索提供空间。
-
Tokenizer 仍有改进空间
提升tokenizer的压缩比和表征能力将进一步提升学习效率。
-
强化学习的系统化设计
如何在长视频的语境下进行可扩展的强化学习是很有潜力的研究问题。
这些挑战,本质上也是未来方向:更大规模数据、更先进模型结构、更系统评估方法、更高效 tokenizer,将推动世界模型迈向下一阶段。
我们相信,长视频将成为通向 AGI 的关键燃料,而悟界·Emu3.5 将为这一探索带来重要的启示。
悟界·Emu3.5 科研体验版目前也已开通移动端(安卓APK),欢迎扫码下载体验:


立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)