
Mantis:基于解耦视觉前瞻的通用视觉-语言-动作模型,赋能机器人精准执行指令
Mantis 视觉-语言-动作(VLA)模型,通过解耦视觉前瞻(DVF)解决动作监督稀疏问题,结合渐进式训练和自适应时间集成策略,在 LIBERO 基准测试中成功率达 96.7%,机器人指令执行与泛化能力优于主流开源模型。
摘要:Mantis 视觉-语言-动作(VLA)模型,通过解耦视觉前瞻(DVF)解决动作监督稀疏问题,结合渐进式训练和自适应时间集成策略,在 LIBERO 基准测试中成功率达 96.7%,机器人指令执行与泛化能力优于主流开源模型。
一、引言
机器人学习领域已取得显著进展,尤其是针对异构环境下多样化任务的鲁棒控制策略研发。其中,视觉 - 语言 - 动作(VLA)模型是极具潜力的方向 —— 这类模型依托预训练视觉 - 语言模型(VLM),将语言指令和视觉观测转化为机器人可执行的动作。
尽管已有诸多突破,现有 VLA 方法仍面临核心挑战:低维度动作信号过于稀疏,无法充分监督处理高维度感官输入的大型 VLA 模型。这种不匹配导致模型的表征能力未被充分利用,进而限制整体性能。
为解决该问题,研究人员尝试将视觉前瞻预测融入 VLA 训练 —— 模型除预测动作外,还需生成密集的未来视觉状态。但高维度视觉状态含冗余信息,会分散模型对动作预测的注意力,导致训练成本高、下游微调收敛慢;另一种思路是将视觉状态压缩为更紧凑的监督信号,但压缩会丢失表征精细运动的视觉状态细微差异,形成信息瓶颈。此外,现有方法常忽视语言监督,导致模型的上下文理解和推理能力受损。
由上海交通大学&复旦大学&南京邮电大学&中芯国际&博世集团团队联合研发的Mantis《Mantis: A Versatile Vision-Language-Action Model with Disentangled Visual Foresight》:一款搭载解耦视觉前瞻(DVF)的新型 VLA 模型,可有效解决上述问题。Mantis 结合元查询与扩散 Transformer(DiT)头预测未来视觉状态,该设计能解耦动作学习与前瞻预测的强耦合关系;同时通过残差连接将当前视觉状态输入 DiT,让元查询自动捕捉表征视觉轨迹的帧间动态(即潜在动作),辅助显式动作生成。解耦设计降低 VLA 骨干网络的表征负担,使其能通过语言监督维持语义理解和推理能力。
为平衡推理阶段的计算效率与运动稳定性,本文还提出自适应时间集成(ATE)策略,衍生出 Mantis-ATE 变体 —— 在保持性能的前提下,推理次数减少 50%。Mantis 基于人类操纵视频、机器人演示数据和图文对预训练,在 LIBERO 仿真基准微调后成功率达 96.7%,超越主流基线模型且收敛速度更快;真实场景测试表明,其指令执行、未知指令泛化及推理能力均优于领先开源 VLA 模型 π₀.₅。
二、相关工作
2.1 视觉 - 语言 - 动作模型
视觉 - 语言模型(VLM)的快速发展推动了 VLA 模型的诞生。这类模型依托 VLM 的感知和语言表征能力,让机器人能解读文本指令并执行动作,但现有 VLA 模型存在理解能力不足的问题:机器人专属训练常覆盖预训练阶段的视觉 - 文本对齐关系,降低指令跟随性能;部分方法通过辅助损失引入隐式语言监督,但易累积误差且缺乏视觉前瞻能力。本文框架则在融入视觉前瞻的同时,保留模型的语义理解与推理能力。
2.2 视觉增强的动作学习
视觉增强的动作学习可有效补充稀疏的动作信号,充分利用 VLA 模型的表征能力,主要分为三类(见图 1):
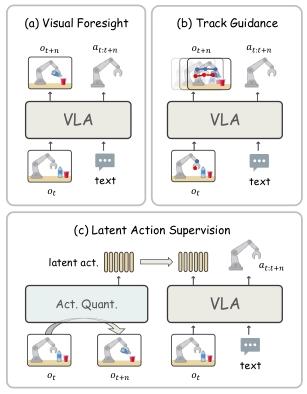
图 1 视觉增强的动作学习范式。(a)视觉前瞻:通过预测未来帧提升动作预测效果;(b)轨迹引导:将压缩后的视觉状态表征用于指导动作预测;(c)潜在动作监督:通过辅助潜在动作优化动作学习效果。
1)视觉前瞻:通过显式 / 隐式方法预测未来帧,辅助动作预测。显式方法通过自回归离散图像令牌或可学习查询令牌 + 视觉解码器生成未来帧;隐式方法联合训练视频生成与动作预测任务。但像素级预测含冗余信息,训练成本高,还可能让模型混淆物理运动与视觉外观变化(如纹理、光照),引发幻觉。
2)轨迹引导:将视觉状态压缩为关键点轨迹等紧凑的控制导向表征,捕捉核心物理动态以辅助动作预测。但压缩会造成信息瓶颈,且视频跟踪提取的点轨迹精度有限,导致动作预测误差升高。
3)潜在动作监督:借助潜在动作监督动作预测 —— 先训练动作量化模型从帧间差异学习离散潜在动作,再让 VLA 模型预测这些潜在动作,最后在机器人操纵数据上微调。该策略需额外训练量化模型,增加计算复杂度。
与现有方法不同,Mantis 将视觉前瞻预测与骨干网络解耦,为动作预测提供更紧凑、准确的辅助信息。
三、方法学
本节先概述 Mantis 的模型架构与规格,再详细说明渐进式训练策略和自适应时间集成机制。
3.1 模型概述
如图 2 所示,Mantis 包含以下组件:骨干模型 P、连接器 c、DVF 头 D、动作头 π、一组可训练的潜在动作查询 [LAT] 和动作查询 [ACT]。任务由语言指令 l 定义,在每个时间步 t,骨干网络 P 接收 l 和视觉状态(如原始图像帧)oₜ,与 [LAT] 打包成序列并映射为特征 hₜ;hₜ与 oₜ拼接后输入连接器 c,投影为 DVF 头 D 的条件输入,生成未来图像帧 oₜ₊ₙ(n 为当前帧与未来帧的时间步间隔)。
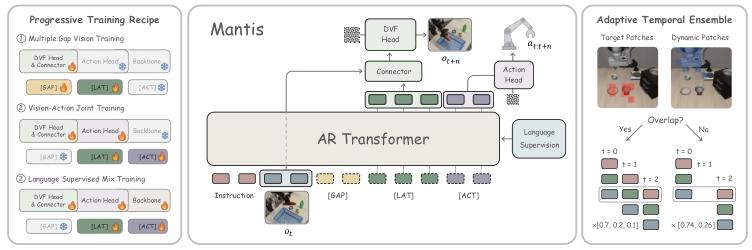
图 2 左:渐进式训练策略——Mantis 逐步整合多模态数据,实现稳定且均衡的优化;中:Mantis 架构概述 —— 包含骨干网络、DVF 头、动作头,DVF 头预测未来帧以辅助潜在动作学习,进而提升动作预测效果,语言监督维持骨干网络的理解与推理能力;右:自适应时间集成 ——Mantis-ATE 基于目标令牌与动态令牌的重叠度动态调整集成强度。
该设计避免 VLA 骨干网络直接生成冗余视觉信息;同时,通过残差连接将 oₜ输入 D,使 [LAT] 查询捕捉表征视觉轨迹的帧间动态(而非重建完整帧),这些动态对应机器人显式运动的视觉表现(潜在动作),可为动作预测提供精准指导。
后续,动作头 π 基于骨干网络输出,结合 [LAT] 和 [ACT] 生成未来 n 个时间步的动作序列。此外,为在训练阶段生成更密集的视觉预测、适配多样化下游任务,本文引入多间隔查询 [GAP],插入至 [LAT] 前,指导不同时间步间隔的未来帧生成(见图 3)。
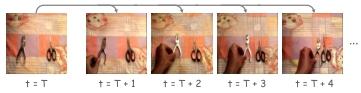
图 3 多间隔未来帧生成可视化。
3.2 模型规格
1)VLM 骨干网络:选用 Qwen2.5-VL 作为骨干,其支持灵活的输入分辨率 —— 可为主相机分配高分辨率,为空间细节少的腕部相机分配低分辨率,兼顾性能与效率。
2)DVF 头:采用 Sana 作为 DVF 头,该模型是高效的扩散 Transformer(DiT),集成深度压缩自编码器。连接器包含 12 层 Transformer 编码器和 1 个投影层,衔接骨干网络输出空间与 DiT 输入空间,遵循 Qwen2.5 LLM 架构并采用双向注意力。动作推理阶段无需视觉状态预测,因此移除 DVF 头以降低计算开销。
3)动作头:参考相关研究设计基于 DiT 的动作头 —— 可学习的动作查询先通过因果注意力从输入和潜在动作查询中聚合信息,再由动作头将高斯噪声去噪为 n 步动作轨迹。
3.3 渐进式训练策略
预训练阶段直接融合视觉、语言、动作模态,易导致学习偏向最易学习的信号(如动作)或过拟合主导模态(如语言),引发跨模态竞争和收敛不稳定。为此,本文设计渐进式训练策略,分阶段引入模态,实现更稳定的优化(见图 2 左):
1)阶段 1:多间隔视觉训练。先在无动作标注的视频(SSV2 数据集,含 22 万条人类操纵视频)上训练,让模型从视觉动态中推断潜在动作,学习通用操纵技能和世界知识。训练时冻结骨干网络(保留预训练语言表征),解冻 DVF 头、潜在动作查询和多间隔查询,优化 DVF 扩散损失。
2)阶段 2:视觉 - 动作联合训练。引入机器人演示数据集(DROID 数据集,含 7.6 万条机器人演示样本),固定时间步间隔以匹配动作块大小,实现视觉与动作流的时间对齐。模型优化目标为视觉损失与动作损失的加权和(权重系数 α=0.1),此阶段解冻动作查询,仍冻结骨干网络。
3)阶段 3:语言监督混合训练。联合训练多模态数据集与机器人演示数据,解冻骨干网络并对语言输出施加交叉熵损失,整体优化目标为视觉损失、动作损失与语言损失的加权和。渐进式融合实现稳定高效的优化,为下游任务构建兼具视觉增强和多模态理解能力的基础模型。
3.4 自适应时间集成(ATE)
推理阶段,Mantis 先引入常用的时间集成方法提升运动稳定性,但该方法计算开销高。为此,本文提出自适应时间集成(ATE)策略,根据每个推理时间步的运动稳定性需求动态调整集成强度:
ATE 在每个时间步维护两组输入视觉补丁(见图 2 右、图 4):
-
目标补丁:与语言指令最相关的图像区域 —— 基于 Mantis 骨干网络交叉注意力模块的文本 - 视觉注意力分数,选取前 τ_target% 的视觉令牌对应区域;
-
动态补丁:视觉变化显著的区域 —— 将当前帧与前一帧划分为与视觉令牌对齐的补丁,计算像素空间中对应补丁的余弦相似度,选取前 τ_dynamic% 相似度最低的区域。

图 4 ATE 可视化。注意力热力图颜色越深表示分值越高,余弦相似度热力图则相反;参数设置为 τ_target=1、τ_dynamic=12。
动态补丁捕捉机械臂和末端执行器的运动,目标补丁聚焦指令相关物体,二者重叠时表明需执行抓取等精细操纵 —— 此时激活时间集成提升运动稳定性;无重叠时关闭集成以提高计算效率。集成 ATE 的 Mantis 变体命名为 Mantis-ATE。
四、实验
4.1 实现细节
1)基础配置:Mantis 总参数量为 58 亿,其中骨干网络 37 亿、DVF 头 14 亿、动作头 3 亿、VAE 3 亿;[LAT] 数量设为 9,[ACT] 为 6,[GAP] 为 6×3(对应 1-6 个时间步间隔);DVF 头扩散过程设 30 步,动作头设 10 步。训练采用 AdamW 优化器,权重衰减 0.1、梯度裁剪 0.5,基于 DeepSpeed 实现高效分布式训练。
2)预训练配置:阶段 1 在 SSV2 数据集预训练,时间步间隔随机采样 1-6;阶段 2 在 DROID 数据集预训练,视觉损失权重 α=0.1;阶段 3 联合 38 个多模态数据集与 DROID 数据集训练 1.5 个 epoch。
3)微调配置:在 LIBERO 基准下游微调时,采用与预训练阶段 1、2 相同的学习率,训练 30 个 epoch(无语言监督),视觉损失权重 α=0.1,选取验证集成功率最高的检查点用于最终评估。
4.2 仿真实验
在主流的 LIBERO 基准上评估 Mantis,该基准包含 Spatial、Object、Goal、Long 四类任务,每类任务 10 个子任务,每个子任务测试 50 次,以成功率(SR)为评价指标。选取有 / 无视觉增强的高性能 VLA 模型作为基线,同时对比收敛速度。
1)核心结果:Mantis 在 4 类任务中的 3 类表现最优,平均成功率达 96.7%,超越所有有 / 无视觉增强的基线模型(非视觉增强模型中 π₀平均成功率 94.2%、OpenVLA 76.5%;视觉增强模型中 UnifiedVLA 95.5%、F1 95.7%),验证了 DVF 辅助动作预测的有效性;视觉增强方法整体优于非视觉增强方法,印证了密集视觉状态可有效补充稀疏动作信号的结论;ATM 性能较差,原因是视频跟踪提取的点轨迹精度有限,导致误差累积。
2)收敛速度:对比 Mantis 与 4 类基线(非视觉增强 OpenVLA、视觉前瞻 UnifiedVLA、轨迹引导 ATM、潜在动作监督 UniVLA)在 LIBERO Spatial 任务上的收敛速度(训练 20 个 epoch,每轮评估成功率)。结果如图 5 所示,Mantis 收敛速度快,与非视觉增强的 OpenVLA、潜在动作监督的 UniVLA 相当;而视觉前瞻耦合的 UnifiedVLA 收敛最慢,前 10 个 epoch 成功率为 0。这验证了将前瞻预测与动作学习解耦对高效优化的必要性。
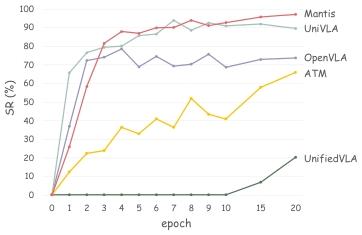
图 5 收敛速度对比。与 UnifiedVLA 等传统视觉前瞻方法相比,Mantis 收敛速度显著更快,印证了解耦前瞻预测与动作学习的必要性。
4.3 真实场景实验
在 Agilex 平台(见图 6a)评估 Mantis,验证语言监督对维持骨干网络能力的作用。设计 3 个实验场景,每个场景含 4 个域内(ID)指令(评估指令跟随能力)和 4 个域外(OOD)指令(评估泛化能力),OOD 指令需模型具备世界知识、算术逻辑推理等能力(见图 6b)。
对比 Mantis 与领先开源 VLA 模型 π₀.₅:两者均在 3 个场景的数据集上微调,Mantis 全程保留语言监督;每个指令执行 10 次,每次最多 5 次连续尝试,以平均成功次数为评价指标。
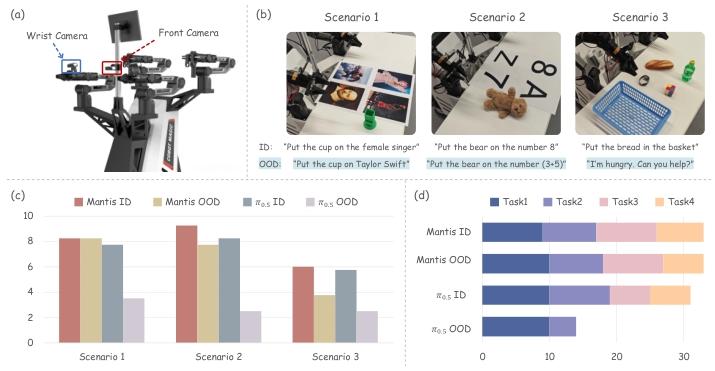
图 6 真实场景实验。(a)Agilex 平台;(b)场景设置与指令示例(每个场景含 1 条 ID 指令和对应 OOD 指令);(c)Mantis 与 π₀.₅在 3 个场景 ID/OOD 任务上的平均成功次数;(d)场景 1 中 Mantis 与 π₀.₅的单任务成功次数。
结果显示:Mantis 在所有场景的 ID、OOD 指令上均优于 π₀.₅,展现出更强的指令跟随、未知指令泛化及核心推理能力;而 π₀.₅指令跟随能力一般,对 OOD 指令几乎无泛化能力。这验证了语言监督对维持骨干网络理解与推理能力的有效性。此外,部分实验激活 DVF 头生成的未来帧序列(见图 7),最终生成帧与真实最终状态高度吻合,印证了 DVF 优化动作预测的效果。

图 7 生成未来帧可视化。最后生成的未来帧与真实最终状态高度一致,验证了 DVF 在多样化操纵任务中优化动作预测的有效性。
4.4 消融实验
1)ATE 分析:在 LIBERO 四类任务上对比标准 Mantis(TE)与 Mantis-ATE 的推理效率,以推理次数(IC,越低越高效)和成功率(SR)为指标,参数设 τ_target=1、τ_dynamic=12。结果显示,Mantis-ATE 推理次数减少近 50%,且成功率基本持平,大幅提升推理效率。
2)DVF 消融:设计 4 种 DVF 变体(vanilla-DVF、flawed-DVF(无残差连接)、no-DVF(仅保留动作头)、pretrained-DVF(在人类 / 机器人视频上预训练)),在 LIBERO 四类任务上评估。结果表明,pretrained-DVF 成功率最高(平均 96.2%),其次是 vanilla-DVF(95.7%)、flawed-DVF(94.4%),no-DVF(91.3%)。结论:①DVF 有助于动作学习;②残差连接让 DVF 更好捕捉潜在动作;③视频预训练进一步提升 DVF 性能。
3)语言监督消融:在多模态基准上评估 Mantis 的理解与推理能力,并在真实场景中测试无语言监督的 Mantis-LU 变体。结果显示:Mantis 在 2/3 多模态基准上表现最优,仅略低于原始骨干网络;Mantis-LU 在 ID 指令上性能尚可,但 OOD 指令表现极差,验证了语言监督对指令泛化的关键作用。
五、结论、局限性与未来工作
本文提出搭载解耦视觉前瞻(DVF)的 Mantis 框架:仿真实验验证 DVF 可提升性能和收敛速度,真实场景实验证实语言监督的有效性。局限性在于,因缺失机器人状态输入,真实场景中存在轻微运动回滚问题。未来将整合 3D 点云等更丰富的输入,并优化推理速度。
六、补充说明
6.1 自适应时间集成(ATE)补充
ATE 将输入图像划分为 18×18 补丁,实验默认 τ_target=1、τ_dynamic=12。计算复杂度分析表明:动态补丁识别和目标补丁选择的额外开销远低于骨干网络计算开销,ATE 可减少 40% 以上推理次数,实现有效加速。
6.2 实现细节补充
视觉输入处理:视频帧和机器人主相机图像裁剪并调整为 512×512 像素,腕部相机图像为 256×256 像素。预训练阶段 1、2 采用余弦学习率调度(500 步预热,基础学习率 1e-4,最低 1e-5),训练 1 个 epoch;阶段 3 采用固定学习率 1e-5,视觉损失权重 α=0.1,语言损失权重 β=0.005。语言监督数据集选自 LLaVA-OneVision-1.5-Instruct 的指令训练集,共 38 个,覆盖视觉问答、OCR 等通用任务,排除图表问答、医学影像等专业领域。
6.3 真实场景实验补充
3 个场景的 ID/OOD 指令涵盖世界知识、算术推理、人类意图理解等维度;每个场景收集 100 条遥操作演示样本(每任务 25 条),Mantis 和 π₀.₅均微调 10 个 epoch,Mantis 额外引入 LLaVA-Instruct 数据集做语言监督。单任务成功次数显示,Mantis 在 ID/OOD 指令上均显著优于 π₀.₅。
END
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)