
记忆增强的视觉-语言-动作模型MAP-VLA:长程机器人操纵成功率提升25%,仿真超基线7.0%
清华大学&北京邮电大学&华南理工大学&南洋理工大学联合研发的MAP-VLA,一种为预训练 VLA 模型注入演示记忆的轻量级框架。通过 “阶段化记忆提示构建→实时记忆检索→动态提示融合” 三步流程,让冻结的 VLA 模型能复用专家演示的阶段化知识,解决传统 VLA 模型 “长程任务易偏离、无记忆依赖即时输入” 的核心痛点。
摘要:清华大学&北京邮电大学&华南理工大学&南洋理工大学联合研发的MAP-VLA《MAP-VLA: Memory-Augmented Prompting for Vision-Language-Action Model in Robotic Manipulation》:这是一种为预训练 VLA 模型注入演示记忆的轻量级框架。通过 “阶段化记忆提示构建→实时记忆检索→动态提示融合” 三步流程,让冻结的 VLA 模型能复用专家演示的阶段化知识,在 LIBERO-Long 仿真长程任务中平均成功率达 83.4%(超基线 π₀ 7.0%),真实机器人完全成功率 48.3%(超基线 25.0%),且抗视觉干扰(污渍、失焦)、少样本场景泛化性强,彻底解决传统 VLA 模型 “长程任务易偏离、无记忆依赖即时输入” 的核心痛点。
一、VLA 模型长程操纵的核心技术瓶颈
现有预训练 VLA 模型在长程机器人操纵中面临的关键挑战:
-
缺乏记忆机制:仅依赖即时感官输入,无法复用专家演示的阶段化经验,长程任务中易偏离轨迹;
-
长程稳定性差:多步骤任务中无历史引导,累计误差导致后期动作失效,完全成功率低;
-
适配性不足:对视觉干扰(如镜头污渍、光照变化)鲁棒性弱,少样本场景下泛化能力有限;
-
部署灵活性低:传统记忆增强需修改模型权重,计算成本高,无法作为插件模块适配现有 VLA 模型。
二、核心创新:MAP-VLA 的三大技术突破
框架以 “离线记忆构建→在线记忆复用→动态融合优化” 为核心逻辑,三大创新点如下:
1. 记忆提示构建(MPC):阶段化编码专家演示
突破 VLA 模型无法存储阶段化知识的问题,核心流程如图 2 所示:
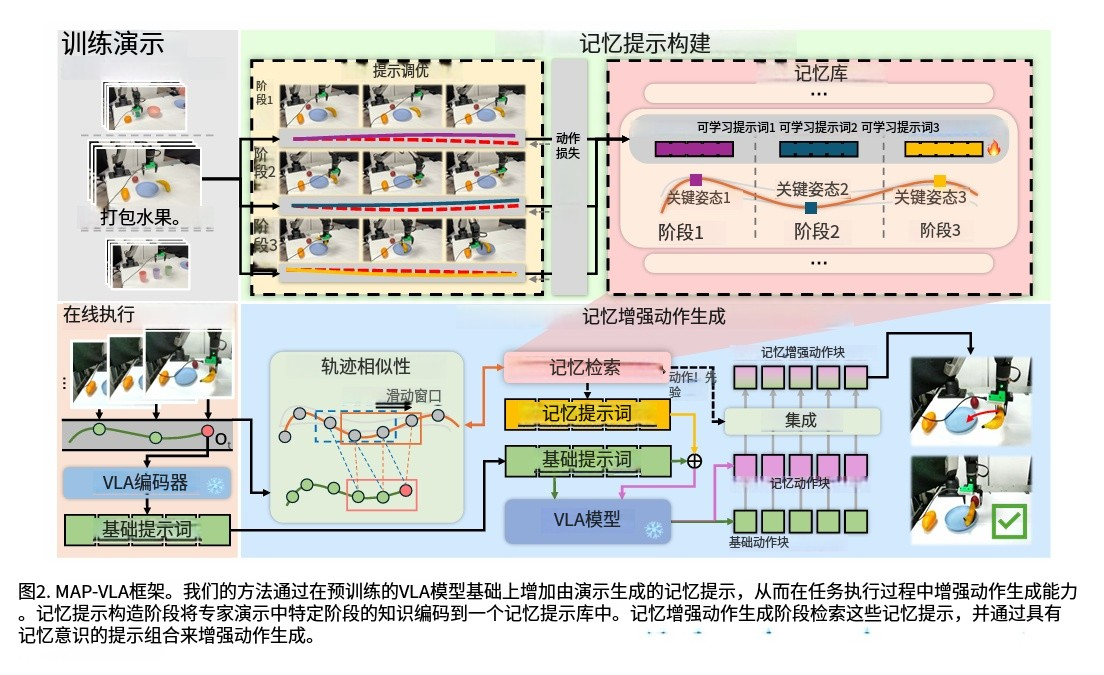
-
任务阶段分割与对齐:用 RDP 算法提取参考演示的关键姿态(如抓取、放置),划分任务阶段;通过 DTW 算法对齐所有演示轨迹,确保同一阶段对应相同任务语义;
-
阶段特异性提示微调:为每个阶段训练可学习的软提示(Soft Prompt),通过流匹配损失将该阶段的专家动作记忆编码到提示中,构建记忆库;
-
核心优势:无需修改 VLA 模型权重,记忆以提示形式存储,可灵活检索,适配不同长程任务。
2. 记忆增强动作生成(MAAG):实时检索与动态融合
解决记忆复用与实时适配的矛盾,核心设计如下:
-
轨迹相似性记忆检索:执行时用滑动窗口截取当前轨迹片段,通过 L₂距离匹配记忆库中最相似的演示阶段,仅检索相邻阶段(减少计算量),确保记忆相关性;
-
动态提示融合机制:同时生成 “基线动作”(仅用当前输入)和 “记忆动作”(用检索提示),参考演示的未来动作序列计算权重 αₜ,动态平衡泛化性与阶段特异性;
-
核心优势:避免纯基线的长程漂移,也解决纯记忆的检索误差问题,动作生成更稳定。
3. 轻量级插件设计:冻结 VLA 模型,灵活部署
突破传统记忆增强需全量微调的局限:
-
仅优化阶段化软提示(参数规模远小于模型权重),VLA 模型权重完全冻结,适配 OpenVLA、π₀等主流预训练模型;
-
记忆检索复杂度 O (N)(N 为演示数量),单步检索仅 21.6ms,满足实时操纵需求;
-
无需额外采集数据,直接复用现有演示轨迹,降低部署成本。
三、实验验证:长程、鲁棒、泛化三重突破
基于 LIBERO 仿真基准和 Galaxea A1 真实机器人,关键结果如下:
1. 长程任务性能:仿真与真实场景双领先
1)仿真场景(LIBERO-Long 10 项任务):
-
MAP-VLA 平均成功率 83.4%,超 OpenVLA(54.0%)29.4%,超 π₀(76.4%)7.0%;
-
所有任务均排名第一,Task3(双物体入篮)成功率 96.0%,Task10(开炉灶放摩卡壶)90.7%;
2)真实机器人场景(3 项长程任务):
-
完全成功率 48.3%(超基线 π₀ 25.0%),部分成功率 68.3%(超基线 15.0%);
-
堆叠杯子、双物体放置等任务中,显著减少 “前期正确、后期偏离” 的问题。
2. 鲁棒性与泛化性:抗干扰、少样本均适配
-
视觉干扰场景:面对镜头污渍、失焦、光照变化(冷 / 暖光),平均成功率仍超 70%,相对增益 9.6%,优于基线的抗干扰能力;
-
少样本场景:10-shot 任务成功率 55.8%(超 π₀ 2.2%),20-shot 达 75.9%(超 π₀ 3.8%),且标准差更低(±0.8%),稳定性更强;
-
消融验证:完整框架(阶段提示 + 动态融合)性能最优,单独阶段提示仅 81.4%,证明动态融合的关键作用。
3. 核心实验结果如下:
|
场景 |
对比对象 |
关键指标 |
MAP-VLA 表现 |
绝对增益 |
|
仿真长程任务 |
π₀ |
平均成功率 |
83.4% |
+7.0% |
|
真实机器人任务 |
π₀ |
完全成功率 |
48.3% |
+25.0% |
|
10-shot 少样本任务 |
π₀ |
平均成功率 |
55.8% |
+2.2% |
|
镜头污渍干扰场景 |
π₀ |
任务成功率 |
72.3% |
+6.9% |
四、核心价值与适用场景
1. 技术突破点
-
轻量级记忆增强:无需微调 VLA 模型权重,仅优化软提示,部署灵活、计算成本低;
-
阶段化记忆复用:将专家演示拆分为可检索的阶段知识,解决长程任务的轨迹连贯性问题;
-
动态平衡机制:融合基线泛化性与记忆特异性,抗检索误差、视觉干扰能力强。
2. 适用场景
-
长程机器人操纵:家庭服务(整理物品、堆叠杯子)、工业装配(多步骤零件组装);
-
复杂环境适配:视觉条件差(镜头脏污、光照变化)的真实场景;
-
少样本部署:难以采集大量演示数据的小众操纵任务(特殊工具使用)。
五、结语
MAP-VLA 通过阶段化记忆提示构建与动态融合,为预训练 VLA 模型提供了 “即插即用” 的记忆增强方案,在长程机器人操纵中实现了性能、鲁棒性、泛化性的三重提升。其轻量级设计与冻结模型的特性,降低了真实场景部署门槛,为服务机器人、工业自动化等领域的长程任务提供了实用范式。
END
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)