
METIS:面向灵巧操作的多源第一视角训练集成式视觉-语言-动作模型
METIS 视觉 - 语言 - 动作(VLA)模型,构建多源第一视角数据集 EgoAtlas(统一人机动作空间),提取运动感知动力学特征,整合推理与执行框架;在 6 项真实灵巧操作任务中获最高平均成功率,泛化至分布外场景及高自由度执行体,突破灵巧操作数据稀缺瓶颈。
摘要:本文提出 METIS 视觉 - 语言 - 动作(VLA)模型,构建多源第一视角数据集 EgoAtlas(统一人机动作空间),提取运动感知动力学特征,整合推理与执行框架;在 6 项真实灵巧操作任务中获最高平均成功率,泛化至分布外场景及高自由度执行体,突破灵巧操作数据稀缺瓶颈。
一、引言
构建能跨多样任务感知、推理、执行的通用机器人是机器人领域的核心挑战,灵巧操作更是其中的难点 —— 高质量的灵巧技能动作标注数据稀缺,遥操作采集成本极高。人类操作数据规模庞大、行为模式丰富,可为机器人动作学习提供宝贵先验,但现有方法受限于场景单一、人机视觉 / 动作空间差距大等问题。
由北京大学&北京人工智能研究院的团队联合研发的METIS《METIS: Multi-Source Egocentric Training for Integrated Dexterous Vision-Language-Action Model》:一款基于多源第一视角数据集预训练的灵巧操作视觉 - 语言 - 动作(VLA)模型。核心创新包括:
-
构建 EgoAtlas 多源第一视角数据集,整合大规模人类 / 机器人数据并统一动作空间;
-
提取运动感知动力学(紧凑离散的运动表征),为 VLA 训练提供高效监督;
-
设计统一推理与执行框架,实现下游灵巧操作任务的高效部署。
METIS 在 6 项真实世界灵巧操作任务中取得最高平均成功率,且在分布外场景(未知背景 / 物体 / 光照、杂乱环境)和跨执行体场景中展现出优异的泛化能力,为通用灵巧操作模型研发提供了新方向。
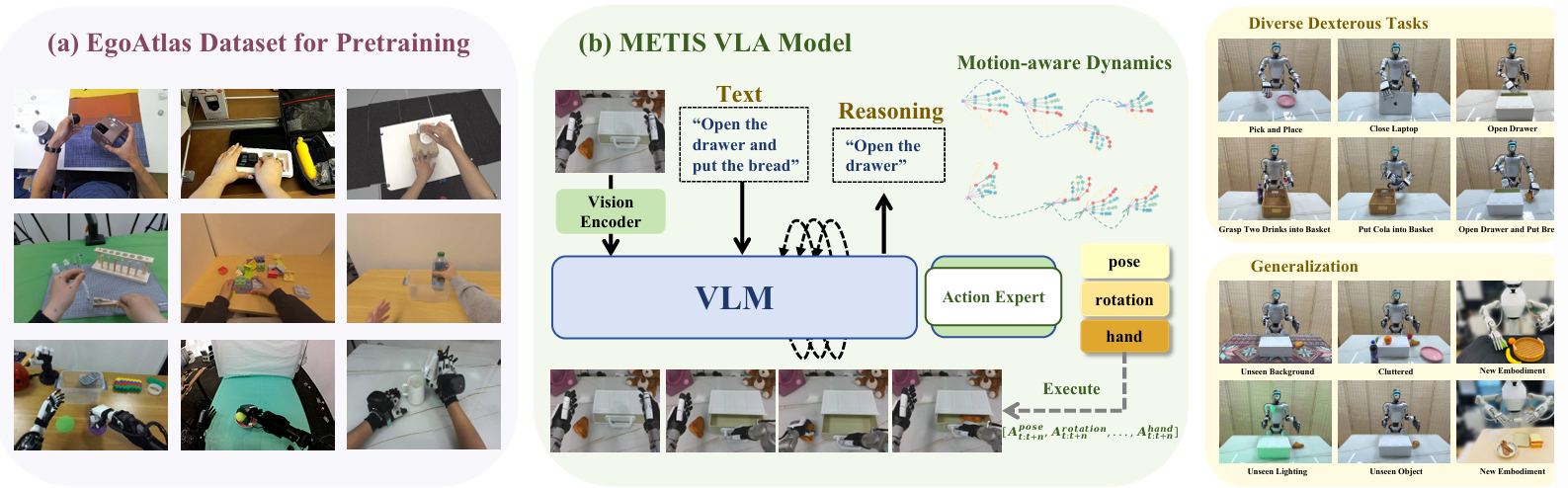
图 1 METIS 核心框架:基于多源第一视角数据集 EgoAtlas 预训练,提取运动感知动力学特征(捕捉灵巧操作关键运动信息),整合推理与执行模块,在多样灵巧操作任务中实现高精度执行与强泛化性。
二、相关工作
2.1 灵巧操作
传统灵巧操作方法依赖优化 / 控制算法,需已知动力学和物体模型,泛化性差;基于学习的方法(强化学习 / 模仿学习)虽有进展,但强化学习存在 “仿真 - 现实” 鸿沟,模仿学习依赖昂贵的遥操作数据。本文通过多源第一视角数据预训练,从人类数据中学习运动先验,突破数据稀缺瓶颈。
2.2 从人类数据学习灵巧性
人类数据包含丰富的手部精细运动和语义信息,现有方法从人类视频中学习可操作表征(如可及性、潜在动作、关键点流),但存在冗余信息多、未聚焦核心手部运动的问题;部分方法采用人机数据联合训练,提升策略鲁棒性,但未充分利用互联网海量人类数据。本文通过视觉 + 运动动力学联合建模,从人类数据中学习动作先验。
2.3 视觉 - 语言 - 动作(VLA)模型
VLA 模型近年进展显著,但多聚焦于夹持器操作,忽视灵巧操作的运动 / 交互动力学;少数扩展至灵巧操作的方法受限于人类视频场景单一、人机视觉差距大的问题。本文通过多源第一视角数据 + 增强人类数据集,构建集成式 VLA 模型,实现推理与执行的统一。
三、EgoAtlas 数据集
EgoAtlas 是面向灵巧操作的大规模多源第一视角数据集,核心目标是弥合人类与机器人灵巧操作的数据差距,统一动作空间以支撑 VLA 训练。
3.1 增强人类数据采集的可穿戴系统
传统人类手部运动数据集受限于视角依赖、遮挡、采集空间有限等问题,本文研发可穿戴手套 - 追踪器系统(图 2),实现便携、高精度的人类运动捕捉:
-
手部捕捉:采用 Manus Quantum Metagloves 记录每只手 25 个关键点的 3D 位置,VIVE Tracker 记录手腕 6 自由度位姿,实现手部全局定位;
-
视觉捕捉:头戴相机记录第一视角操作画面,配合 VIVE Tracker 完成外参标定,确保运动捕捉与视觉坐标系对齐;
-
标注:为轨迹添加语言指令和细粒度子任务标注,支持长时程操作的分层推理。
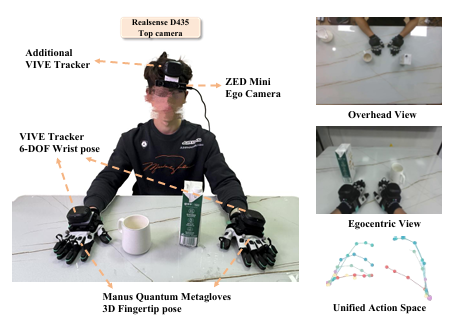
图 2 可穿戴手部运动采集系统:集成手套、追踪器、头戴相机,实现无约束场景下的高精度手部运动 + 第一视角视觉采集。
3.2 数据来源与统计
EgoAtlas 整合 4 大类、8 个数据源的人类 / 机器人数据,覆盖视觉动捕、VR 采集、遥操作机器人数据、自研增强人类数据,总计包含 34.3 万条轨迹、8972 万张图像 - 动作对(表 1)。
表 1 EgoAtlas 数据集统计(In-the-wild 表示无约束真实场景采集)
| 数据源 | 轨迹数 | 帧数 | 子任务标注 | 人类数据占比 | 机器人数据占比 | 无约束场景 |
|
ARCTIC |
296 |
21.45 万 |
无 |
100% |
0% |
否 |
|
H20 |
109 |
6.53 万 |
无 |
100% |
0% |
否 |
|
HoloAssist |
100 |
77.73 万 |
无 |
100% |
0% |
否 |
|
Oakink |
134 |
14.6 万 |
无 |
100% |
0% |
否 |
|
EgoDex |
31.48 万 |
7790 万 |
无 |
100% |
0% |
是 |
|
PH2D |
1.8 万 |
41.65 万 |
无 |
66.1% |
33.9% |
否 |
|
ActionNet |
15.7 万 |
740 万 |
无 |
0% |
100% |
否 |
|
自研增强数据 |
10 万 |
280 万 |
有 |
100% |
0% |
是 |
3.3 数据处理:统一动作空间
为适配不同执行体的 VLA 训练,构建统一的本体感知 - 动作空间:
-
手腕位姿:统一为相机坐标系下的 3D 位置 + 6D 旋转向量(18 维);
-
手部姿态:校准至手腕坐标系下的指尖 3D 位置(30 维);
-
映射:通过正 / 逆运动学,实现灵巧手关节角与指尖位置的双向转换,确保人机手腕坐标系对齐。
四、METIS 模型设计
METIS 基于多源第一视角数据预训练,核心是通过运动感知动力学捕捉灵巧操作的关键特征,整合推理与执行模块,实现高精度、高泛化的灵巧操作。
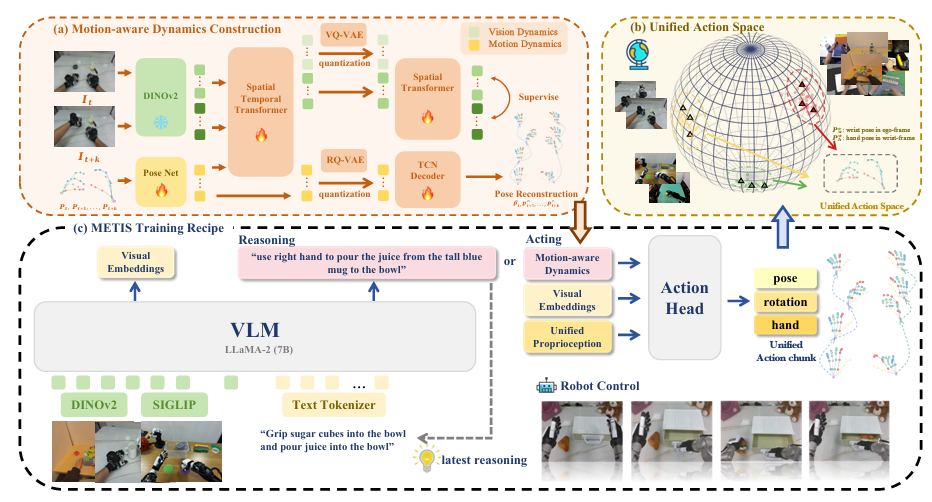
图 3 METIS 整体框架:(a) 构建紧凑的运动感知动力学表征(视觉动力学 + 运动动力学);(b) 基于 EgoAtlas 预训练(统一人机动作空间);(c) 整合推理与执行模块,适配下游灵巧操作任务。
4.1 运动感知动力学构建
现有 VLA 模型的动作离散化方法存在序列长、生成慢、精细运动捕捉不足的问题,本文提出运动感知动力学(紧凑离散表征),为 VLA 预训练提供高效监督:
-
视觉动力学离散化:建模运动与视觉变化的因果关系,通过逆动力学编码器提取运动相关的视觉特征,结合 VQ-VAE 量化为离散码本嵌入,聚焦任务相关的视觉动态(而非原始像素);
-
运动动力学量化:通过 PoseNet 提取 3D 手部运动的时空动力学,结合 RQ-VAE 量化为离散码本嵌入,捕捉从粗到细的层级运动模式,通过时序卷积网络重建运动轨迹以保证监督有效性。
4.2 METIS 核心架构
METIS 基于 Prismatic-7B 初始化,整合 SigLIP+DINOv2 混合视觉编码器(捕捉全局语义 + 精细空间特征),以 7B LLaMA-2 为语言骨干:
-
词汇扩展:为 LLaMA 分词器新增视觉 / 运动动力学码本对应的特殊令牌,将第一视角操作序列离散为动力学令牌,保留语言先验的同时注入运动信息;
-
动作解码器:将动力学令牌、视觉嵌入、当前本体感知融合,预测 1 秒内的连续动作序列(30Hz,30 步);
-
推理 - 执行统一:引入思维链推理,将高层指令分解为子任务,通过特殊令牌自适应切换 “推理模式”/“执行模式”,减少推理延迟,增强推理与控制的协同。
五、实验验证
实验围绕 “真实任务性能、样本效率、泛化性、核心模块贡献” 展开,硬件平台为 Unitree G1 人形机器人(配备 Inspire 6 自由度灵巧手),头载 Intel RealSense D435 相机采集第一视角 RGB 图像。
5.1 实验设置
-
机器人数据:通过可穿戴手套 - 追踪器系统采集遥操作演示数据,将人类手部运动映射为机器人关节配置;
-
测试任务:6 项灵巧操作任务(3 项短时程:拾取放置、合笔记本、开抽屉;3 项长时程:抓取两杯饮料入篮、放可乐入篮、开抽屉放面包,图 4);
-
基线模型:ACT、OpenVLA-OFT、π₀.₅、GR00T N1.5;
-
评估指标:成功率(SR,完整任务完成)、进度成功率(PSR,长时程任务子任务完成率)。

4 灵巧操作任务示例:涵盖短时程(拾取放置、合笔记本、开抽屉)与长时程(抓取两杯饮料入篮等)任务。
5.2 真实任务性能
METIS 在 6 项任务中取得最高平均成功率,显著优于现有 SOTA 模型(表 2):
-
ACT 擅长短时程任务,但长时程任务表现差(缺乏推理能力);
-
π₀.₅未针对灵巧操作预训练,精细操作精度不足;
-
GR00T N1.5 通过大规模预训练取得竞争力,但长时程任务因无显式推理机制表现受限;
-
METIS 依托运动感知动力学 + 推理 - 执行统一框架,在短 / 长时程任务中均表现最优,且长时程任务 PSR 最高(误差累积少)。
表 2 6 项真实任务核心结果(20 次试次)
| 方法 | 拾取放置(SR) | 合笔记本(SR) | 开抽屉(SR) | 抓取两杯饮料入篮(SR/PSR) | 放可乐入篮(SR/PSR) | 开抽屉放面包(SR/PSR) |
|
ACT |
35.0% |
65.0% |
95.0% |
25.0%/40.0% |
50.0%/53.3% |
5.0%/5.0% |
|
OpenVLA-OFT |
50.0% |
80.0% |
10.0% |
40.0%/57.5% |
55.0%/56.7% |
0.0%/1.0% |
|
π₀.₅ |
60.0% |
85.0% |
70.0% |
65.0%/72.5% |
75.0%/76.7% |
60.0%/65.0% |
|
GR00T N1.5 |
70.0% |
80.0% |
80.0% |
65.0%/70.0% |
70.0%/70.0% |
70.0%/73.3% |
|
METIS(本文) |
85.0% |
95.0% |
90.0% |
75.0%/85.0% |
85.0%/82.5% |
75.0%/72.5% |
此外,METIS 展现出优异的指令跟随能力:在多颜色水果拾取任务中,可精准识别目标水果(如 “将红苹果放在盘子里”)并完成抓取操作。
5.3 样本效率
METIS 在有限数据下仍能实现高性能:仅用 10% 的下游训练数据,“拾取放置” 任务成功率达 50%(图 6),证明多源第一视角预训练赋予模型空间推理、视觉 - 手部协调等先验知识,大幅提升下游任务的适配效率。
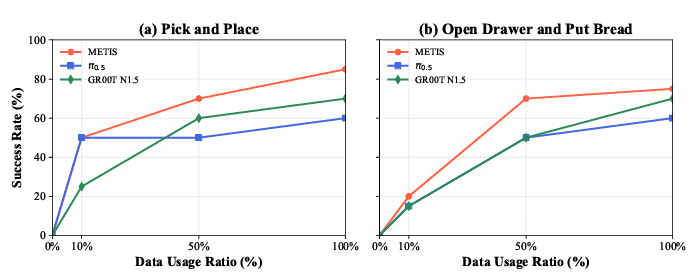
图 6 样本效率实验:随训练数据量增加,METIS 性能快速提升,少量数据即可达到优异效果。
5.4 泛化性
5.4.1 分布外(OOD)场景泛化
METIS 在 4 类分布外场景中保持稳定性能(表 3),显著优于 GR00T N1.5 和 π₀.₅,证明其能适配视觉 / 物理环境的显著变化:
-
未知背景:桌面覆盖彩色花纹桌布;
-
未知光照:彩色闪烁灯光;
-
未知物体:替换目标物体(面包→牛角包);
-
杂乱环境:抽屉旁随机放置干扰物。
表 3 分布外场景泛化结果(开抽屉放面包任务)
| 方法 | 未知背景 | 未知光照 | 未知物体 | 杂乱场景 |
|
π₀.₅ |
50.0% |
70.0% |
65.0% |
55.0% |
|
GR00T N1.5 |
65.0% |
65.0% |
65.0% |
60.0% |
|
METIS(本文) |
70.0% |
70.0% |
65.0% |
70.0% |
5.4.2 跨执行体泛化
METIS 可迁移至 22 自由度 SharpaWave 灵巧手,在 “抓取苹果入篮”(成功率 85.0%)、“工具使用”(成功率 70.0%)任务中表现稳定 —— 因模型预测指尖轨迹而非直接关节角,天然适配不同手部运动学特征。

图 7 跨执行体泛化:METIS 适配 22 自由度灵巧手,在抓取、工具使用任务中保持高性能。
5.5 消融实验
5.5.1 多源第一视角预训练的作用
预训练显著提升下游性能,全量 EgoAtlas 预训练效果最优(表 4),证明多样视觉 / 动作分布能让模型学习更鲁棒的视觉 - 运动先验;无预训练模型虽有基础性能,但训练波动大、真实部署时关节抖动明显。
表 4 多源第一视角预训练消融结果
| 方法 | 拾取放置(SR) | 开抽屉放面包(SR) |
|
METIS - 无预训练 |
60.0% |
35.0% |
|
METIS - 仅人类预训练 |
70.0% |
60.0% |
|
METIS - 全量预训练 |
85.0% |
75.0% |
5.5.2 运动感知动力学的作用
移除运动感知动力学后,METIS 性能大幅下降(表 5),尤其长时程任务完全失效,证明该模块捕捉的紧凑运动表征是学习时序一致性、精细动作预测的核心。
表 5 运动感知动力学消融结果
| 方法 | 拾取放置(SR) | 开抽屉放面包(SR) |
|
METIS - 无运动感知动力学 |
30.0% |
0.0% |
|
METIS - 含运动感知动力学 |
85.0% |
75.0% |
六、结论与局限性
6.1 结论
METIS 通过多源第一视角数据集 EgoAtlas 预训练,结合运动感知动力学和推理 - 执行统一框架,在多样灵巧操作任务中实现最优性能,且具备强泛化性(分布外 / 跨执行体),为通用灵巧操作模型研发提供了可行路径。
6.2 局限性
-
仅依赖第一视角观测,可能无法感知完整物体几何和交互细节,可补充腕部 / 外部相机;
-
预训练未纳入大规模第三人称数据,未来可扩展至多视角操作数据集。
END
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)