
迈向通用具身智能:具身智能的综述与发展路线
论文提出具身AGI的五级分类体系(L1-L5):从仅能完成单一任务的初级阶段(L1)到能够独立完成开放式任务且行为类似人类的高级阶段(L5),为具身AI的发展提供了明确的里程碑!

- 作者: Yequan Wang1^{1}1, AixinSun2^{2}2
- 单位:1^{1}1北京人工智能研究院,2^{2}2南洋理工大学
- 论文标题:Toward Embodied AGI: A Review of Embodied AI and the Road Ahead
- 论文链接:https://arxiv.org/pdf/2505.14235
主要贡献
- 提出具身AGI的五级分类体系(L1-L5):从仅能完成单一任务的初级阶段(L1)到能够独立完成开放式任务且行为类似人类的高级阶段(L5),为具身AI的发展提供了明确的里程碑。
- 评估当前具身AI的发展水平:通过分析现有研究,指出当前具身AI的能力处于L1-L2之间,揭示了在达到更高级别(L3+)时面临的关键挑战。
- 提出L3+机器人大脑的概念框架:包括模型架构和训练范式,旨在满足全模态处理、类人认知能力、实时响应和泛化能力等核心要求,为未来的研究和开发提供了技术展望。
研究背景
- 具身AI与AGI的关系:
- 具身AI被认为是实现人工通用智能(AGI)的关键路径之一,甚至可能是AGI定义的一部分。具身AI强调通过身体与环境的交互来实现智能行为。
- 具身AGI的定义:
- 论文将具身AGI定义为能够以人类水平的熟练度完成多样化、开放式现实世界任务的具身AI系统,强调其人类交互能力和任务执行能力。
通用具身智能路线
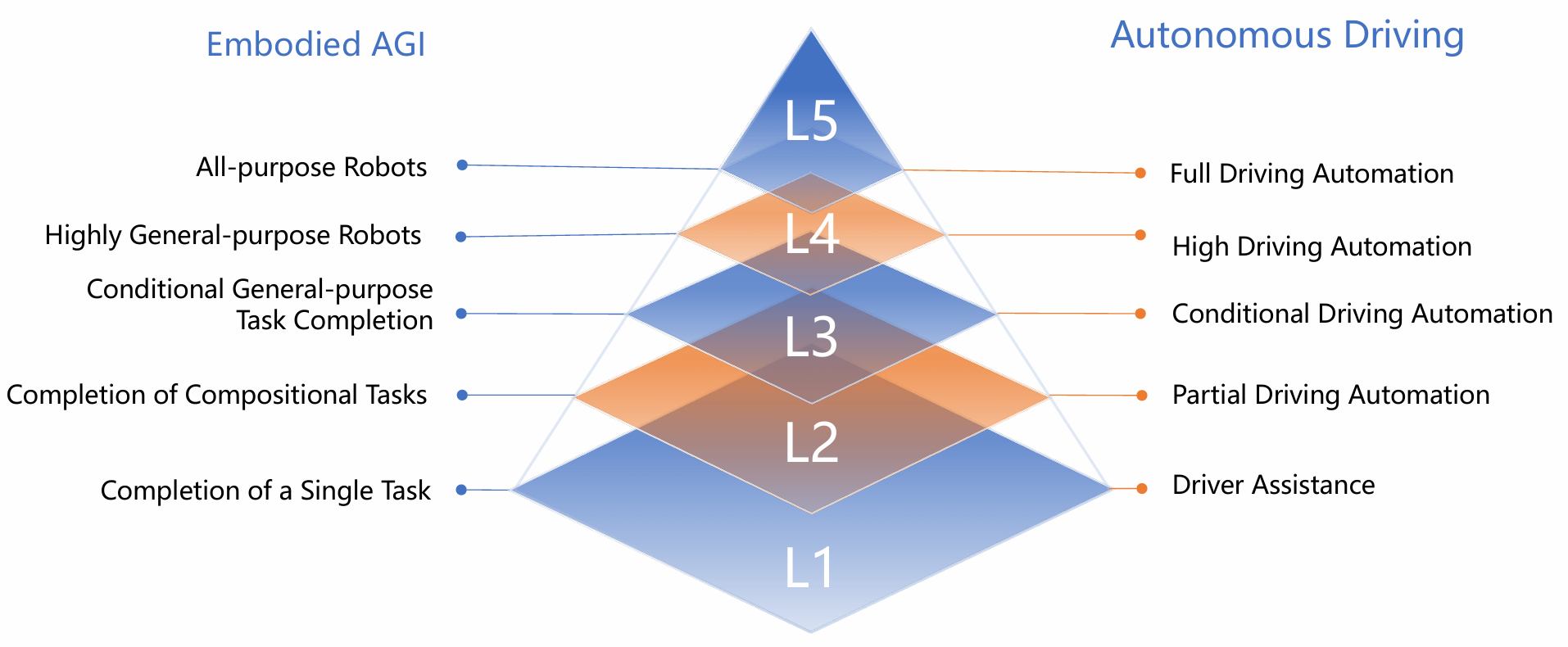
- 论文提出了一个从L1到L5的五级路线图,用于衡量和指导具身AGI的发展,每个级别基于四个核心维度:模态(Modalities)、类人认知能力(Humanoid Cognitive Abilities)、实时响应能力(Real-time Responsiveness)和泛化能力(Generalization Capability)。
| 级别 | 模态 | 类人认知 | 实时响应 | 泛化能力 | 身体与控制 | 自动驾驶类比 |
|---|---|---|---|---|---|---|
| L1 | 部分 | 否 | 否 | 未见环境 | 鲁棒性 | 简单任务(如速度控制) |
| L2 | 部分 | 否 | 否 | 相似任务 | 响应性 | 组合任务(如泊车) |
| L3 | 全部 | 否 | 部分 | 有限任务类型 | 感知完整 | 复杂任务(需人类监控) |
| L4 | 全部 | 部分 | 是 | 开放任务 | 精确性 | 广泛任务(接近人类精度) |
| L5 | 全部 | 是 | 是 | 开放任务 | 安全性 | 所有任务(无需人类干预) |
- L1(单一任务完成):机器人能够可靠地完成单一、明确定义的任务(如抓取物体),但功能局限于特定任务领域。
- L2(组合任务完成):机器人能够处理组合任务,通过将高级人类指令分解为简单动作序列来执行,但能力仍限于预定义任务和技能库。
- L3(有条件的一般任务完成):机器人能够处理多种任务类别,表现出对任务、环境和人类指令的有条件泛化能力,但对全新或开放式任务的可靠性不足。
- L4(高度通用机器人):机器人展现出对广泛未见任务的稳健泛化能力,具备强大的多模态理解和推理能力。
- L5(全功能机器人):这是具身AGI的最终目标,机器人能够满足人类日常生活的广泛需求,展现出类似人类的认知行为。
现状和挑战
当前具身AI的能力处于L1和L2之间,面临以下四个维度的挑战。

缺乏全面的多模态能力
- 现状:
- 现有的具身AI模型(如视觉-语言-动作模型,VLA)大多仅支持视觉和语言输入,并且输出仅限于动作空间。
- 挑战:
- 真正的具身智能需要全面的多模态感知能力,包括理解人类语音的情感和语义,以及处理环境音频输入(如麦克风设备)。此外,还需要多模态响应能力,例如实时语音反馈。
- 缺乏这些模态不仅限制了具身AI在应用中的多功能性,还阻碍了它们对物理世界的全面理解。
类人认知能力不足
- 现状:
- 现有的机器人主要专注于任务特定的操作,缺乏高级的推理和社交互动能力。
- 挑战:
- 具身AI需要在推理和对话智能方面表现出色,类似于复杂的聊天机器人,并展示与人类偏好和伦理价值观的一致性。
- 最终,为了达到L5,具身AI需要表现出类似人类的认知行为和复杂的社会理解能力,这超出了当前学习范式(包括无监督、监督和强化学习)的范围。
实时响应能力有限
- 现状:
- 大多数现有的具身AI系统以半双工方式运行,即在完全接收和处理指令后才开始行动,这使得它们在动态环境中(条件或指令快速变化)表现不佳。
- 挑战:
- 这种局限性严重阻碍了具身AI在现实世界中的部署,尤其是在需要快速适应环境变化或更新指令的应用场景中。
泛化能力受限
- 现状:
- 尽管最近的具身AI模型在多样化环境中的泛化方面取得了显著进展,但仍然存在许多跨环境泛化场景,这些模型难以处理,例如对空间变换(如相机角度)的不变性。
- 挑战:
- 这些问题是实现更高级别能力(如L3+)时需要解决的关键问题。更重要的是,跨任务泛化能力仍然处于发展阶段,但这是实现真正通用能力(L3+)的必要条件。
L3∼L5: 核心能力组件
该部分定义了实现高级别具身AGI(L3-L5)的四大核心能力,并分析了当前技术的不足与未来方向。
全模态能力
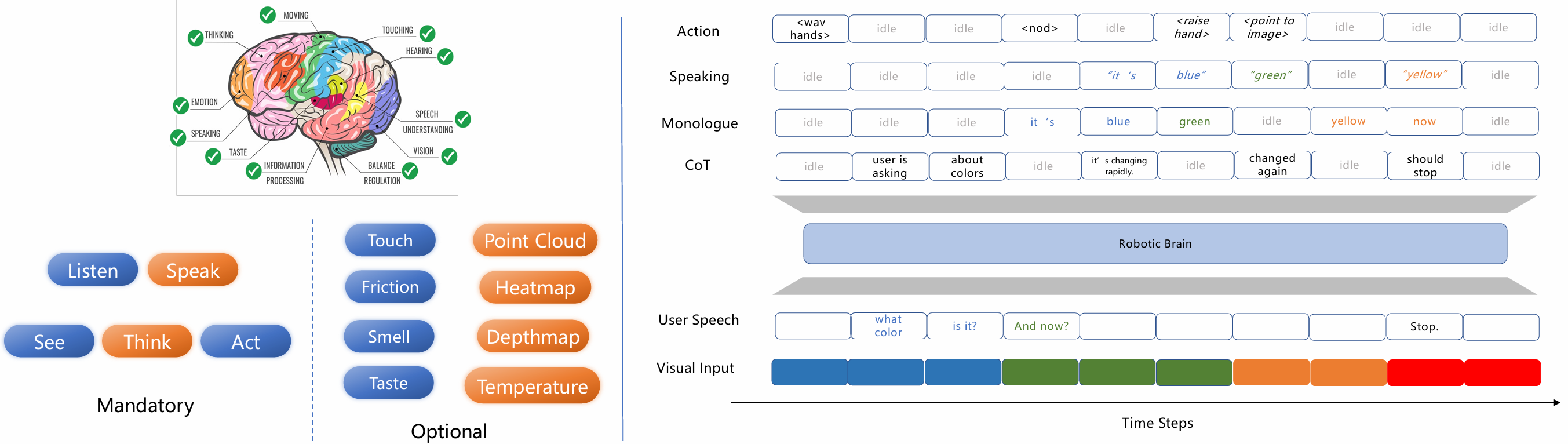
- 要求:
- L3+机器人需处理超越视觉和文本的多模态输入(如听觉、触觉、热感等),并生成多模态响应(动作、语音、推理等)。
- 挑战:
- 模态冲突:多模态融合对模型容量要求极高(如音频-视觉-动作的联合建模)。
- 对齐问题:异构数据分布导致模块间协作困难(如视觉与触觉信号的时序对齐)。
- 解决方案:
- 并行架构(L3+):支持多模态流式输入输出的实时处理(如图3所示)。
- 高级预训练范式(L4+):通过跨模态联合训练提升物理规律内化能力。
类人认知行为
- 四大核心能力:
- 自我意识(:动态理解自身身份、目标与状态(区别于静态LLM提示词)。
- 社会关联理解:识别角色关系(如人类-机器人协作中的责任分配)。
- 程序性记忆:持续积累技能,避免灾难性遗忘(如增量学习)。
- 记忆重组:根据新经验动态更新知识(减少重复训练开销)。
- 实现路径:
- 终身学习:超越传统“预训练-微调”范式,通过持续交互更新内部表征(如用户偏好、环境变化)。
实时交互
- 挑战:
- 现有模型(如VLA)因参数量限制(<5B)难以支持全模态实时响应,且计算复杂度随序列长度平方增长。
- 优化方向:
- 工程优化:如MiniCPM-o2的时序分复用(TDM)技术。
- 新架构:专为多模态并行处理设计的低延迟模型(如RQ-Transformer)。
开放任务泛化
- 瓶颈:
- 当前模型依赖任务特定数据,缺乏物理规律的内化(如虚拟动作结果的因果预测)。
- 改进方法:
- 物理导向训练:通过无监督/合成数据学习世界模型(World Models),增强跨任务推理能力。
L3+ 机器人大脑框架
模型结构
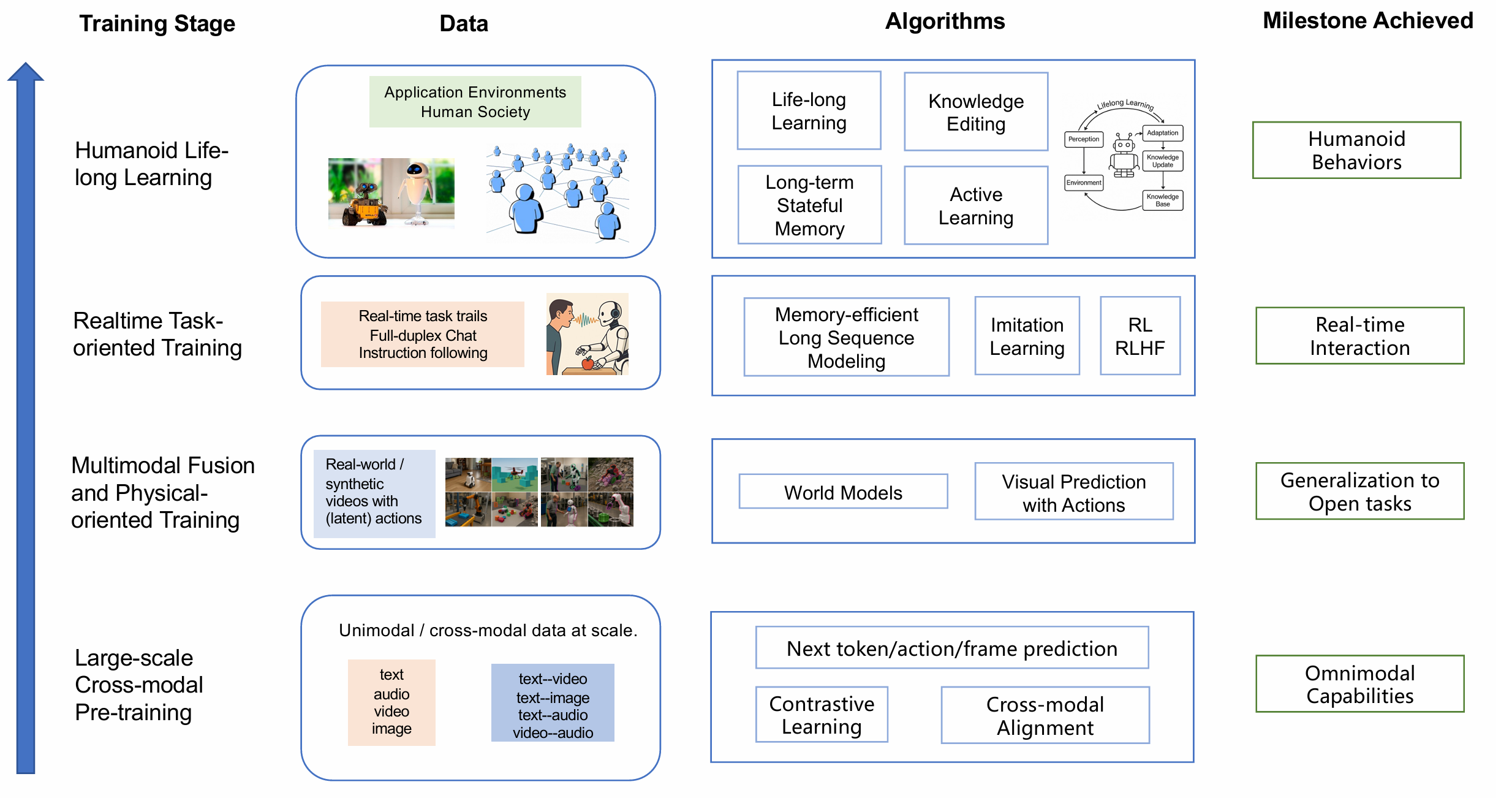
- 设计原则:
- 全模态流式处理:支持任意时刻t+1t+1t+1的输出生成(动作、语音、推理等),基于历史输入0∼t0\sim t0∼t。
- 动态响应:适应环境突变(如指令中断、物理扰动)。
yt+1a1,yt+1a2,…,yt+1an=fθ(x0b1,x0b2,…,x0bm,…,xtb1,xtb2,…,xtbm)y_{t+1}^{a_1}, y_{t+1}^{a_2}, \dots, y_{t+1}^{a_n} = f_\theta(x_0^{b_1}, x_0^{b_2}, \dots, x_0^{b_m}, \dots, x_t^{b_1}, x_t^{b_2}, \dots, x_t^{b_m})yt+1a1,yt+1a2,…,yt+1an=fθ(x0b1,x0b2,…,x0bm,…,xtb1,xtb2,…,xtbm)
ai∈{thoughts,speech,action,mobile,… }a_i \in \{\text{thoughts}, \text{speech}, \text{action}, \text{mobile}, \dots\}ai∈{thoughts,speech,action,mobile,…}
bj∈{text,audio,image,video,heatmap,… }b_j \in \{\text{text}, \text{audio}, \text{image}, \text{video}, \text{heatmap}, \dots\}bj∈{text,audio,image,video,heatmap,…}
- 示例架构:
- 多模态编码器-解码器结构,类似RQ-Transformer的双模态原型。
训练范式
- 全模态从头训练:促进跨模态深度对齐(如视觉-触觉-语言的联合表征)。
-. 终身学习集成:结合主动学习(Active Learning)和知识编辑(Knowledge Editing),实现持续适应。 - 物理导向训练:
- 数据:大规模无监督/合成数据(如模拟器生成的物理交互)。
- 目标:通过动作-结果预测任务内化因果规律(如Hu et al. 2024的预测策略)。
总结与未来挑战
- 总结:
- 尽管随着技术进步,提出的框架可能会演变或被替代,但具身AGI的发展路线图仍然具有长期相关性。
- 未来挑战:
- 除了技术障碍外,具身AGI的发展还将面临伦理、安全和社会影响等方面的挑战,特别是在人类、机器人和人机集体之间的协作和关系方面。

更多推荐
 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)